Poster Session 48 Fri 17 Jul 12:00 a.m.
[ Virtual ]
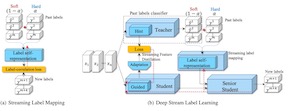
In multi-label learning, each instance can be associated with multiple and non-exclusive labels. Previous studies assume that all the labels in the learning process are fixed and static; however, they ignore the fact that the labels will emerge continuously in changing environments. In order to fill in these research gaps, we propose a novel deep neural network (DNN) based framework, Deep Streaming Label Learning (DSLL), to classify instances with newly emerged labels effectively. DSLL can explore and incorporate the knowledge from past labels and historical models to understand and develop emerging new labels. DSLL consists of three components: 1) a streaming label mapping to extract deep relationships between new labels and past labels with a novel label-correlation aware loss; 2) a streaming feature distillation propagating feature-level knowledge from the historical model to a new model; 3) a senior student network to model new labels with the help of knowledge learned from the past. Theoretically, we prove that DSLL admits tight generalization error bounds for new labels in the DNN framework. Experimentally, extensive empirical results show that the proposed method performs significantly better than the existing state-of-the-art multi-label learning methods to handle the continually emerging new labels.
[ Virtual ]

Optimal transport is a foundational problem in optimization, that allows to compare probability distributions while taking into account geometric aspects. Its optimal objective value, the Wasserstein distance, provides an important loss between distributions that has been used in many applications throughout machine learning and statistics. Recent algorithmic progress on this problem and its regularized versions have made these tools increasingly popular. However, existing techniques require solving an optimization problem to obtain a single gradient of the loss, thus slowing down first-order methods to minimize the sum of losses, that require many such gradient computations. In this work, we introduce an algorithm to solve a regularized version of this problem of Wasserstein estimators, with a time per step which is sublinear in the natural dimensions of the problem. We introduce a dual formulation, and optimize it with stochastic gradient steps that can be computed directly from samples, without solving additional optimization problems at each step. Doing so, the estimation and computation tasks are performed jointly. We show that this algorithm can be extended to other tasks, including estimation of Wasserstein barycenters. We provide theoretical guarantees and illustrate the performance of our algorithm with experiments on synthetic data.

Joint filtering is a fundamental problem in computer vision with applications in many different areas. Most existing algorithms solve this problem with a weighted averaging process to aggregate input pixels. However, the weight matrix of this process is often empirically designed and not robust to complex input. In this work, we propose to learn the weight matrix for joint image filtering. This is a challenging problem, as directly learning a large weight matrix is computationally intractable. To address this issue, we introduce the correlation of deep features to approximate the aggregation weights. However, this strategy only uses inner product for the weight matrix estimation, which limits the performance of the proposed algorithm. Therefore, we further propose to learn a nonlinear function to predict sparse residuals of the feature correlation matrix. Note that the proposed method essentially factorizes the weight matrix into a low-rank and a sparse matrix and then learn both of them simultaneously with deep neural networks. Extensive experiments show that the proposed algorithm compares favorably against the state-of-the-art approaches on a wide variety of joint filtering tasks.
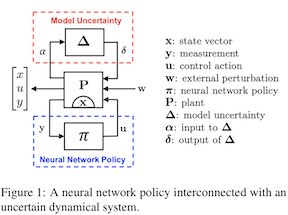
Deep neural networks are known to be fragile to small adversarial perturbations, which raises serious concerns when a neural network policy is interconnected with a physical system in a closed loop. In this paper, we show how to combine recent works on static neural network certification tools with robust control theory to certify a neural network policy in a control loop. We give a sufficient condition and an algorithm to ensure that the closed loop state and control constraints are satisfied when the persistent adversarial perturbation is l-infinity norm bounded. Our method is based on finding a positively invariant set of the closed loop dynamical system, and thus we do not require the continuity of the neural network policy. Along with the verification result, we also develop an effective attack strategy for neural network control systems that outperforms exhaustive Monte-Carlo search significantly. We show that our certification algorithm works well on learned models and could achieve 5 times better result than the traditional Lipschitz-based method to certify the robustness of a neural network policy on the cart-pole balance control problem.

We investigate the combination of actor-critic reinforcement learning algorithms with a uniform large-scale experience replay and propose solutions for two ensuing challenges: (a) efficient actor-critic learning with experience replay (b) the stability of off-policy learning where agents learn from other agents behaviour. To this end we analyze the bias-variance tradeoffs in V-trace, a form of importance sampling for actor-critic methods. Based on our analysis, we then argue for mixing experience sampled from replay with on-policy experience, and propose a new trust region scheme that scales effectively to data distributions where V-trace becomes unstable. We provide extensive empirical validation of the proposed solutions on DMLab-30 and further show the benefits of this setup in two training regimes for Atari: (1) a single agent is trained up until 200M environment frames per game (2) a population of agents is trained up until 200M environment frames each and may share experience. We demonstrate state-of-the-art data efficiency among model-free agents in both regimes.
\emph{Is there a classifier that ensures optimal robustness against all adversarial attacks?} This paper tackles the question by adopting a game-theoretic point of view. We present the adversarial attacks and defenses problem as an \emph{infinite} zero-sum game where classical results (\emph{e.g.} Nash or Sion theorems) do not apply. We demonstrate the non-existence of a Nash equilibrium in our game when the classifier and the Adversary are both deterministic, hence giving a negative answer to the above question in the deterministic regime. Nonetheless, the question remains open in the randomized regime. We tackle this problem by showing that, under mild conditions on the dataset distribution, any deterministic classifier can be outperformed by a randomized one. This gives arguments for using randomization, and leads us to a simple method for building randomized classifiers that are robust to state-or-the-art adversarial attacks. Empirical results validate our theoretical analysis, and show that our defense method considerably outperforms Adversarial Training against strong adaptive attacks, by achieving 0.55 accuracy under adaptive PGD-attack on CIFAR10, compared to 0.42 for Adversarial training.

Devising indicative evaluation metrics for the image generation task remains an open problem. The most widely used metric for measuring the similarity between real and generated images has been the Frechet Inception Distance (FID) score. Since it does not differentiate the fidelity and diversity aspects of the generated images, recent papers have introduced variants of precision and recall metrics to diagnose those properties separately. In this paper, we show that even the latest version of the precision and recall metrics are not reliable yet. For example, they fail to detect the match between two identical distributions, they are not robust against outliers, and the evaluation hyperparameters are selected arbitrarily. We propose density and coverage metrics that solve the above issues. We analytically and experimentally show that density and coverage provide more interpretable and reliable signals for practitioners than the existing metrics.

Bayesian inference using Markov Chain Monte Carlo (MCMC) on large datasets has developed rapidly in recent years. However, the underlying methods are generally limited to relatively simple settings where the data have specific forms of independence. We propose a novel technique for speeding up MCMC for time series data by efficient data subsampling in the frequency domain. For several challenging time series models, we demonstrate a speedup of up to two orders of magnitude while incurring negligible bias compared to MCMC on the full dataset. We also propose alternative control variates for variance reduction based on data grouping and coreset constructions.
Poster Session 49 Fri 17 Jul 02:00 a.m.
[ Virtual ]
Node classification in attributed graphs is an important task in multiple practical settings, but it can often be difficult or expensive to obtain labels. Active learning can improve the achieved classification performance for a given budget on the number of queried labels. The best existing methods are based on graph neural networks, but they often perform poorly unless a sizeable validation set of labelled nodes is available in order to choose good hyperparameters. We propose a novel graph-based active learning algorithm for the task of node classification in attributed graphs; our algorithm uses graph cognizant logistic regression, equivalent to a linearized graph-convolutional neural network (GCN), for the prediction phase and maximizes the expected error reduction in the query phase. To reduce the delay experienced by a labeller interacting with the system, we derive a preemptive querying system that calculates a new query during the labelling process, and to address the setting where learning starts with almost no labelled data, we also develop a hybrid algorithm that performs adaptive model averaging of label propagation and linearized GCN inference. We conduct experiments on five public benchmark datasets, demonstrating a significant improvement over state-of-the-art approaches and illustrate the practical value of the method …
[ Virtual ]

The empirical performance of neural ordinary differential equations (NODEs) is significantly inferior to discrete-layer models on benchmark tasks (e.g. image classification). We demonstrate an explanation is the inaccuracy of existing gradient estimation methods: the adjoint method has numerical errors in reverse-mode integration; the naive method suffers from a redundantly deep computation graph. We propose the Adaptive Checkpoint Adjoint (ACA) method: ACA applies a trajectory checkpoint strategy which records the forward- mode trajectory as the reverse-mode trajectory to guarantee accuracy; ACA deletes redundant components for shallow computation graphs; and ACA supports adaptive solvers. On image classification tasks, compared with the adjoint and naive method, ACA achieves half the error rate in half the training time; NODE trained with ACA outperforms ResNet in both accuracy and test-retest reliability. On time-series modeling, ACA outperforms competing methods. Furthermore, NODE with ACA can incorporate physical knowledge to achieve better accuracy.
[ Virtual ]

The use of machine learning algorithms in finance, medicine, and criminal justice can deeply impact human lives. As a consequence, research into interpretable machine learning has rapidly grown in an attempt to better control and fix possible sources of mistakes and biases. Tree ensembles, in particular, offer a good prediction quality in various domains, but the concurrent use of multiple trees reduces the interpretability of the ensemble. Against this background, we study born-again tree ensembles, i.e., the process of constructing a single decision tree of minimum size that reproduces the exact same behavior as a given tree ensemble in its entire feature space. To find such a tree, we develop a dynamic-programming based algorithm that exploits sophisticated pruning and bounding rules to reduce the number of recursive calls. This algorithm generates optimal born-again trees for many datasets of practical interest, leading to classifiers which are typically simpler and more interpretable without any other form of compromise.
[ Virtual ]
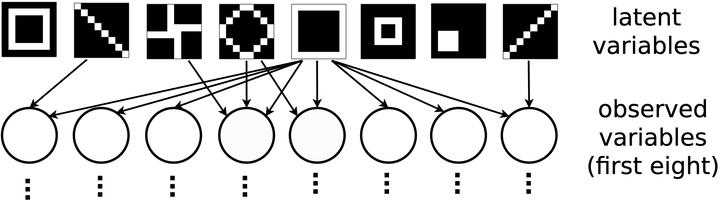
One of the most surprising and exciting discoveries in supervised learning was the benefit of overparameterization (i.e. training a very large model) to improving the optimization landscape of a problem, with minimal effect on statistical performance (i.e. generalization). In contrast, unsupervised settings have been under-explored, despite the fact that it was observed that overparameterization can be helpful as early as Dasgupta & Schulman (2007). We perform an empirical study of different aspects of overparameterization in unsupervised learning of latent variable models via synthetic and semi-synthetic experiments. We discuss benefits to different metrics of success (recovering the parameters of the ground-truth model, held-out log-likelihood), sensitivity to variations of the training algorithm, and behavior as the amount of overparameterization increases. We find that across a variety of models (noisy-OR networks, sparse coding, probabilistic context-free grammars) and training algorithms (variational inference, alternating minimization, expectation-maximization), overparameterization can significantly increase the number of ground truth latent variables recovered.
[ Virtual ]
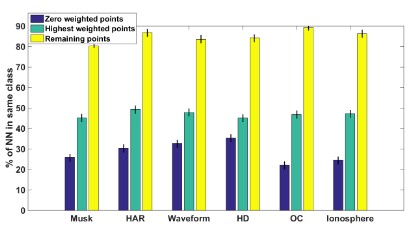
There has been recent interest in improving performance of simple models for multiple reasons such as interpretability, robust learning from small data, deployment in memory constrained settings as well as environmental considerations. In this paper, we propose a novel method SRatio that can utilize information from high performing complex models (viz. deep neural networks, boosted trees, random forests) to reweight a training dataset for a potentially low performing simple model of much lower complexity such as a decision tree or a shallow network enhancing its performance. Our method also leverages the per sample hardness estimate of the simple model which is not the case with the prior works which primarily consider the complex model's confidences/predictions and is thus conceptually novel. Moreover, we generalize and formalize the concept of attaching probes to intermediate layers of a neural network to other commonly used classifiers and incorporate this into our method. The benefit of these contributions is witnessed in the experiments where on 6 UCI datasets and CIFAR-10 we outperform competitors in a majority (16 out of 27) of the cases and tie for best performance in the remaining cases. In fact, in a couple of cases, we even approach the complex model's …
[ Virtual ]
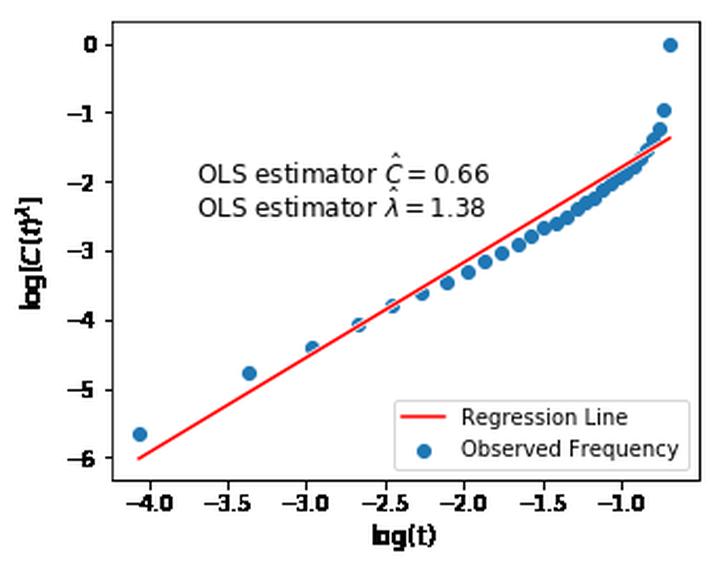
To collect large scale annotated data, it is inevitable to introduce label noise, i.e., incorrect class labels. To be robust against label noise, many successful methods rely on the noisy classifiers (i.e., models trained on the noisy training data) to determine whether a label is trustworthy. However, it remains unknown why this heuristic works well in practice. In this paper, we provide the first theoretical explanation for these methods. We prove that the prediction of a noisy classifier can indeed be a good indicator of whether the label of a training data is clean. Based on the theoretical result, we propose a novel algorithm that corrects the labels based on the noisy classifier prediction. The corrected labels are consistent with the true Bayesian optimal classifier with high probability. We incorporate our label correction algorithm into the training of deep neural networks and train models that achieve superior testing performance on multiple public datasets.
[ Virtual ]
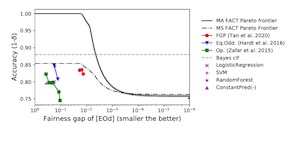
Group fairness, a class of fairness notions that measure how different groups of individuals are treated differently according to their protected attributes, has been shown to conflict with one another, often with a necessary cost in loss of model's predictive performance. We propose a general diagnostic that enables systematic characterization of these trade-offs in group fairness. We observe that the majority of group fairness notions can be expressed via the fairness-confusion tensor, which is the confusion matrix split according to the protected attribute values. We frame several optimization problems that directly optimize both accuracy and fairness objectives over the elements of this tensor, which yield a general perspective for understanding multiple trade-offs including group fairness incompatibilities. It also suggests an alternate post-processing method for designing fair classifiers. On synthetic and real datasets, we demonstrate the use cases of our diagnostic, particularly on understanding the trade-off landscape between accuracy and fairness.
[ Virtual ]
Deep-learning-based methods for various applications have been shown vulnerable to adversarial examples. Here we address the use of deep-learning networks as inverse problem solvers, which has generated much excitement and even adoption efforts by the main equipment vendors for medical imaging including computed tomography (CT) and MRI. However, the recent demonstration that such networks suffer from a similar vulnerability to adversarial attacks potentially undermines their future. We propose to modify the training strategy of end-to-end deep-learning-based inverse problem solvers to improve robustness. To this end, we introduce an auxiliary net-work to generate adversarial examples, which is used in a min-max formulation to build robust image reconstruction networks. Theoretically, we argue that for such inverse problem solvers, one should analyze and study the effect of adversaries in the measurement-space, instead of in the signal-space used in previous work. We show for a linear reconstruction scheme that our min-max formulation results in a singular-value filter regularized solution, which suppresses the effect of adversarial examples. Numerical experiments using the proposed min-max scheme confirm convergence to this solution. We complement the theory by experiments on non-linear Compressive Sensing(CS) reconstruction by a deep neural network on two standard datasets, and, using anonymized clinical data, on …
[ Virtual ]
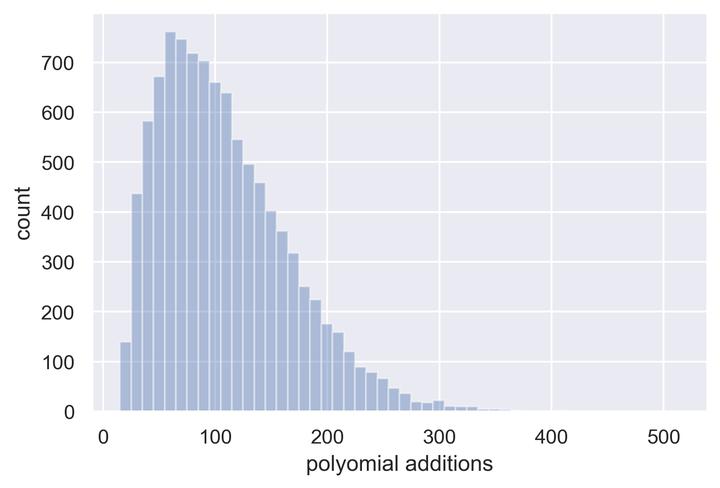
Studying the set of exact solutions of a system of polynomial equations largely depends on a single iterative algorithm, known as Buchberger’s algorithm. Optimized versions of this algorithm are crucial for many computer algebra systems (e.g., Mathematica, Maple, Sage). We introduce a new approach to Buchberger’s algorithm that uses reinforcement learning agents to perform S-pair selection, a key step in the algorithm. We then study how the difficulty of the problem depends on the choices of domain and distribution of polynomials, about which little is known. Finally, we train a policy model using proximal policy optimization (PPO) to learn S-pair selection strategies for random systems of binomial equations. In certain domains, the trained model outperforms state-of-the-art selection heuristics in total number of polynomial additions performed, which provides a proof-of-concept that recent developments in machine learning have the potential to improve performance of algorithms in symbolic computation.
[ Virtual ]
[ Virtual ]
Linear constrained convex programming (LCCP) has many practical applications, including support vector machine (SVM) and machine learning portfolio (MLP) problems. We propose the randomized primal-dual coordinate (RPDC) method, a randomized coordinate extension of the first-order primal-dual method by Cohen and Zhu, 1984 and Zhao and Zhu, 2019, to solve LCCP. We randomly choose a block of variables based on the uniform distribution and apply linearization and a Bregman-like function (core function) to the selected block to obtain simple parallel primal-dual decomposition for LCCP. We establish almost surely convergence and expected O(1/t) convergence rate. Under global strong metric subregularity, we establish the linear convergence of RPDC. Finally, we discuss the implementation details of RPDC and present numerical experiments on SVM and MLP problems to verify the linear convergence.
[ Virtual ]
[ Virtual ]
[ Virtual ]
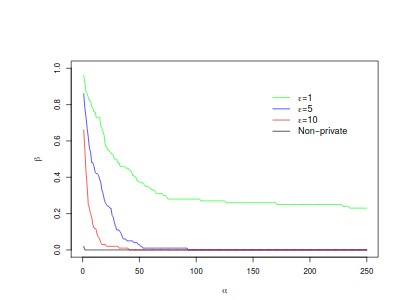
The change-point detection problem seeks to identify distributional changes in streams of data. Increasingly, tools for change-point detection are applied in settings where data may be highly sensitive and formal privacy guarantees are required, such as identifying disease outbreaks based on hospital records, or IoT devices detecting activity within a home. Differential privacy has emerged as a powerful technique for enabling data analysis while preventing information leakage about individuals. Much of the prior work on change-point detection---including the only private algorithms for this problem---requires complete knowledge of the pre-change and post-change distributions, which is an unrealistic assumption for many practical applications of interest. This work develops differentially private algorithms for solving the change-point detection problem when the data distributions are unknown. Additionally, the data may be sampled from distributions that change smoothly over time, rather than fixed pre-change and post-change distributions. We apply our algorithms to detect changes in the linear trends of such data streams. Finally, we also provide experimental results to empirically validate the performance of our algorithms.
[ Virtual ]

Motivated by the repeated sale of online ads via auctions, optimal pricing in repeated auctions has attracted a large body of research. While dynamic mechanisms offer powerful techniques to improve on both revenue and efficiency by optimizing auctions across different items, their reliance on exact distributional information of buyers' valuations (present and future) limits their use in practice. In this paper, we propose robust dynamic mechanism design. We develop a new framework to design dynamic mechanisms that are robust to both estimation errors in value distributions and strategic behavior. We apply the framework in learning environments, leading to the first policy that achieves provably low regret against the optimal dynamic mechanism in contextual auctions, where the dynamic benchmark has full and accurate distributional information.
[ Virtual ]
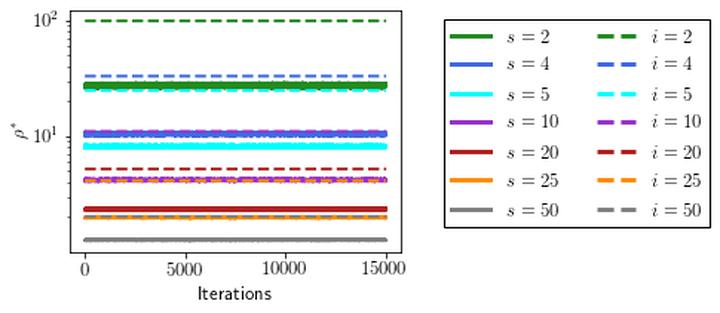
We present a new class of stochastic, geometrically-driven optimization algorithms on the orthogonal group O(d) and naturally reductive homogeneous manifolds obtained from the action of the rotation group SO(d). We theoretically and experimentally demonstrate that our methods can be applied in various fields of machine learning including deep, convolutional and recurrent neural networks, reinforcement learning, normalizing flows and metric learning. We show an intriguing connection between efficient stochastic optimization on the orthogonal group and graph theory (e.g. matching problem, partition functions over graphs, graph-coloring). We leverage the theory of Lie groups and provide theoretical results for the designed class of algorithms. We demonstrate broad applicability of our methods by showing strong performance on the seemingly unrelated tasks of learning world models to obtain stable policies for the most difficult Humanoid agent from OpenAI Gym and improving convolutional neural networks.
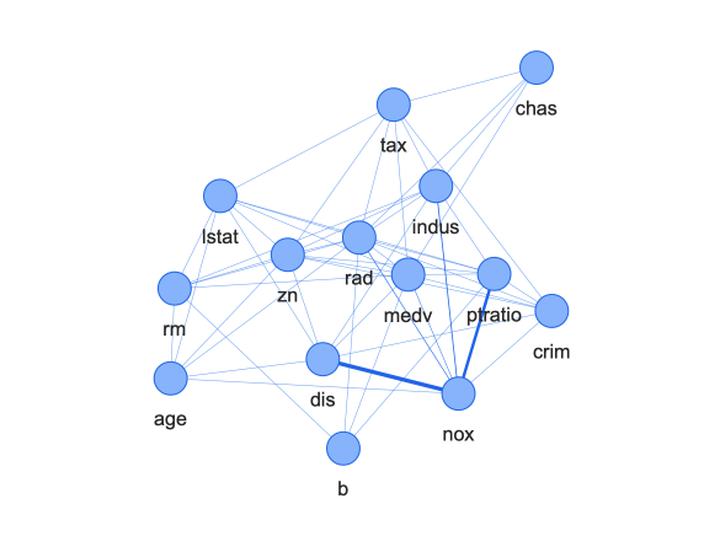
Graphical modeling has been broadly useful for exploring the dependence structure among features in a dataset. However, the strength of graphical modeling hinges on our ability to encode and estimate conditional dependencies. In particular, commonly used measures such as partial correlation are only meaningful under strongly parametric (in this case, multivariate Gaussian) assumptions. These assumptions are unverifiable, and there is often little reason to believe they hold in practice. In this paper, we instead consider 3 non-parametric measures of conditional dependence. These measures are meaningful without structural assumptions on the multivariate distribution of the data. In addition, we show that for 2 of these measures there are simple, strong plug-in estimators that require only the estimation of a conditional mean. These plug-in estimators (1) are asymptotically linear and non-parametrically efficient, (2) allow incorporation of flexible machine learning techniques for conditional mean estimation, and (3) enable the construction of valid Wald-type confidence intervals. In addition, by leveraging the influence function of these estimators, one can obtain intervals with simultaneous coverage guarantees for all pairs of features.
The variance reduction class of algorithms including the representative ones, SVRG and SARAH, have well documented merits for empirical risk minimization problems. However, they require grid search to tune parameters (step size and the number of iterations per inner loop) for optimal performance. This work introduces almost tune-free' SVRG and SARAH schemes equipped with i) Barzilai-Borwein (BB) step sizes; ii) averaging; and, iii) the inner loop length adjusted to the BB step sizes. In particular, SVRG, SARAH, and their BB variants are first reexamined through anestimate sequence' lens to enable new averaging methods that tighten their convergence rates theoretically, and improve their performance empirically when the step size or the inner loop length is chosen large. Then a simple yet effective means to adjust the number of iterations per inner loop is developed to enhance the merits of the proposed averaging schemes and BB step sizes. Numerical tests corroborate the proposed methods.
Finite-horizon sequential experimental design (SED) arises naturally in many contexts, including hyperparameter tuning in machine learning among more traditional settings. Computing the optimal policy for such problems requires solving Bellman equations, which are generally intractable. Most existing work resorts to severely myopic approximations by limiting the decision horizon to only a single time-step, which can underweight exploration in favor of exploitation. We present BINOCULARS: Batch-Informed NOnmyopic Choices, Using Long-horizons for Adaptive, Rapid SED, a general framework for deriving efficient, nonmyopic approximations to the optimal experimental policy. Our key idea is simple and surprisingly effective: we first compute a one-step optimal batch of experiments, then select a single point from this batch to evaluate. We realize BINOCULARS for Bayesian optimization and Bayesian quadrature -- two notable example problems with radically different objectives -- and demonstrate that BINOCULARS significantly outperforms significantly outperforms myopic alternatives in real-world scenarios.
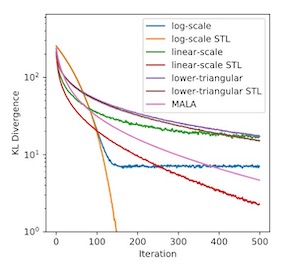
Variational inference (VI) and Markov chain Monte Carlo (MCMC) are approximate posterior inference algorithms that are often said to have complementary strengths, with VI being fast but biased and MCMC being slower but asymptotically unbiased. In this paper, we analyze gradient-based MCMC and VI procedures and find theoretical and empirical evidence that these procedures are not as different as one might think. In particular, a close examination of the Fokker-Planck equation that governs the Langevin dynamics (LD) MCMC procedure reveals that LD implicitly follows a gradient flow that corresponds to an VI procedure based on optimizing a nonparametric normalizing flow. The evolution under gradient descent of real-world VI approximations that use tractable, parametric flows can thus be seen as an approximation to the evolution of a population of LD-MCMC chains. This result suggests that the transient bias of LD (due to the Markov chain not having burned in) may track that of VI (due to the optimizer not having converged), up to differences due to VI’s asymptotic bias and parameter geometry. Empirically, we find that the transient biases of these algorithms (and their momentum-accelerated counterparts) do evolve similarly. This suggests that practitioners with a limited time budget may get more …
Building accurate language models that capture meaningful long-term dependencies is a core challenge in natural language processing. Towards this end, we present a calibration-based approach to measure long-term discrepancies between a generative sequence model and the true distribution, and use these discrepancies to improve the model. Empirically, we show that state-of-the-art language models, including LSTMs and Transformers, are miscalibrated: the entropy rates of their generations drift dramatically upward over time. We then provide provable methods to mitigate this phenomenon. Furthermore, we show how this calibration-based approach can also be used to measure the amount of memory that language models use for prediction.

There has been considerable recent interest in mutual information (MI) minimization for various machine learning tasks. However, estimating and minimizing MI in high-dimensional spaces remains a challenging problem, especially when only samples are accessible, rather than the underlying distribution forms. Previous works mainly focus on MI lower bound approximation, which is not applicable to MI minimization problems. In this paper, we propose a novel Contrastive Log-ratio Upper Bound (CLUB) of mutual information. We provide a theoretical analysis of the properties of CLUB and its variational approximation. Based on this upper bound, we introduce an accelerated MI minimization training scheme, that bridges MI minimization with negative sampling. Simulation studies on Gaussian distributions show that CLUB provides reliable estimates. Real-world MI minimization experiments, including domain adaptation and the information bottleneck, further demonstrate the effectiveness of the proposed method.

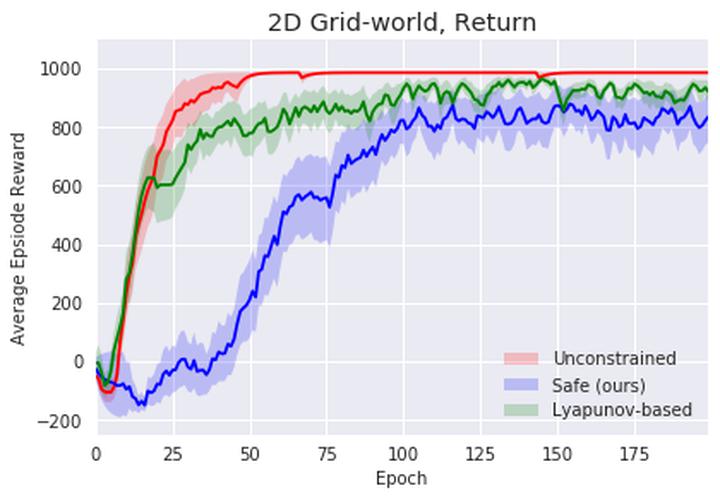
Although Reinforcement Learning (RL) algorithms have found tremendous success in simulated domains, they often cannot directly be applied to physical systems, especially in cases where there are hard constraints to satisfy (e.g. on safety or resources). In standard RL, the agent is incentivized to explore any behavior as long as it maximizes rewards, but in the real world, undesired behavior can damage either the system or the agent in a way that breaks the learning process itself. In this work, we model the problem of learning with constraints as a Constrained Markov Decision Process and provide a new on-policy formulation for solving it. A key contribution of our approach is to translate cumulative cost constraints into state-based constraints. Through this, we define a safe policy improvement method which maximizes returns while ensuring that the constraints are satisfied at every step. We provide theoretical guarantees under which the agent converges while ensuring safety over the course of training. We also highlight the computational advantages of this approach. The effectiveness of our approach is demonstrated on safe navigation tasks and in safety-constrained versions of MuJoCo environments, with deep neural networks.
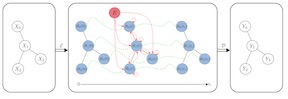
This paper builds on the connection between graph neural networks and traditional dynamical systems. We propose continuous graph neural networks (CGNN), which generalise existing graph neural networks with discrete dynamics in that they can be viewed as a specific discretisation scheme. The key idea is how to characterise the continuous dynamics of node representations, i.e. the derivatives of node representations, w.r.t. time.Inspired by existing diffusion-based methods on graphs (e.g. PageRank and epidemic models on social networks), we define the derivatives as a combination of the current node representations,the representations of neighbors, and the initial values of the nodes. We propose and analyse two possible dynamics on graphs—including each dimension of node representations (a.k.a. the feature channel) change independently or interact with each other—both with theoretical justification. The proposed continuous graph neural net-works are robust to over-smoothing and hence allow us to build deeper networks, which in turn are able to capture the long-range dependencies between nodes. Experimental results on the task of node classification demonstrate the effectiveness of our proposed approach over competitive baselines.
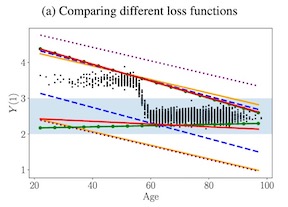
Estimation of individual treatment effects is commonly used as the basis for contextual decision making in fields such as healthcare, education, and economics. However, it is often sufficient for the decision maker to have estimates of upper and lower bounds on the potential outcomes of decision alternatives to assess risks and benefits. We show that, in such cases, we can improve sample efficiency by estimating simple functions that bound these outcomes instead of estimating their conditional expectations, which may be complex and hard to estimate. Our analysis highlights a trade-off between the complexity of the learning task and the confidence with which the learned bounds hold. Guided by these findings, we develop an algorithm for learning upper and lower bounds on potential outcomes which optimize an objective function defined by the decision maker, subject to the probability that bounds are violated being small. Using a clinical dataset and a well-known causality benchmark, we demonstrate that our algorithm outperforms baselines, providing tighter, more reliable bounds.
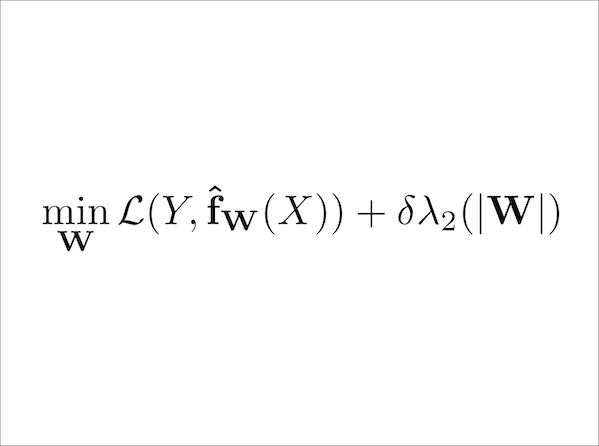
We introduce a novel regularization approach for deep learning that incorporates and respects the underlying graphical structure of the neural network. Existing regularization methods often focus on penalizing weights in a global/uniform manner that ignores the connectivity structure of the neural network. We propose to use the Fiedler value of the neural network's underlying graph as a tool for regularization. We provide theoretical support for this approach via spectral graph theory. We show several useful properties of the Fiedler value that makes it suitable for regularization. We provide an approximate, variational approach for faster computation during training. We provide bounds on such approximations. We provide an alternative formulation of this framework in the form of a structurally weighted L1 penalty, thus linking our approach to sparsity induction. We performed experiments on datasets that compare Fiedler regularization with traditional regularization methods such as Dropout and weight decay. Results demonstrate the efficacy of Fiedler regularization.
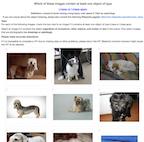
Building rich machine learning datasets in a scalable manner often necessitates a crowd-sourced data collection pipeline. In this work, we use human studies to investigate the consequences of employing such a pipeline, focusing on the popular ImageNet dataset. We study how specific design choices in the ImageNet creation process impact the fidelity of the resulting dataset---including the introduction of biases that state-of-the-art models exploit. Our analysis pinpoints how a noisy data collection pipeline can lead to a systematic misalignment between the resulting benchmark and the real-world task it serves as a proxy for. Finally, our findings emphasize the need to augment our current model training and evaluation toolkit to take such misalignment into account.
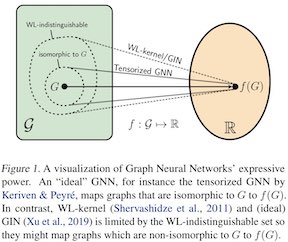
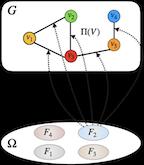
Formation mechanisms are fundamental to the study of complex networks, but learning them from observations is challenging. In real-world domains, one often has access only to the final constructed graph, instead of the full construction process, and observed graphs exhibit complex structural properties. In this work, we propose GraphOpt, an end-to-end framework that jointly learns an implicit model of graph structure formation and discovers an underlying optimization mechanism in the form of a latent objective function. The learned objective can serve as an explanation for the observed graph properties, thereby lending itself to transfer across different graphs within a domain. GraphOpt poses link formation in graphs as a sequential decision-making process and solves it using maximum entropy inverse reinforcement learning algorithm. Further, it employs a novel continuous latent action space that aids scalability. Empirically, we demonstrate that GraphOpt discovers a latent objective transferable across graphs with different characteristics. GraphOpt also learns a robust stochastic policy that achieves competitive link prediction performance without being explicitly trained on this task and further enables construction of graphs with properties similar to those of the observed graph.

Variance-reduced algorithms, although achieve great theoretical performance, can run slowly in practice due to the periodic gradient estimation with a large batch of data. Batch-size adaptation thus arises as a promising approach to accelerate such algorithms. However, existing schemes either apply prescribed batch-size adaption rule or exploit the information along optimization path via additional backtracking and condition verification steps. In this paper, we propose a novel scheme, which eliminates backtracking line search but still exploits the information along optimization path by adapting the batch size via history stochastic gradients. We further theoretically show that such a scheme substantially reduces the overall complexity for popular variance-reduced algorithms SVRG and SARAH/SPIDER for both conventional nonconvex optimization and reinforcement learning problems. To this end, we develop a new convergence analysis framework to handle the dependence of the batch size on history stochastic gradients. Extensive experiments validate the effectiveness of the proposed batch-size adaptation scheme.
Training neural ODEs on large datasets has not been tractable due to the necessity of allowing the adaptive numerical ODE solver to refine its step size to very small values. In practice this leads to dynamics equivalent to many hundreds or even thousands of layers. In this paper, we overcome this apparent difficulty by introducing a theoretically-grounded combination of both optimal transport and stability regularizations which encourage neural ODEs to prefer simpler dynamics out of all the dynamics that solve a problem well. Simpler dynamics lead to faster convergence and to fewer discretizations of the solver, considerably decreasing wall-clock time without loss in performance. Our approach allows us to train neural ODE-based generative models to the same performance as the unregularized dynamics, with significant reductions in training time. This brings neural ODEs closer to practical relevance in large-scale applications.
Robust optimization has been widely used in nowadays data science, especially in adversarial training. However, little research has been done to quantify how robust optimization changes the optimizers and the prediction losses comparing to standard training. In this paper, inspired by the influence function in robust statistics, we introduce the Adversarial Influence Function (AIF) as a tool to investigate the solution produced by robust optimization. The proposed AIF enjoys a closed-form and can be calculated efficiently. To illustrate the usage of AIF, we apply it to study model sensitivity -- a quantity defined to capture the change of prediction losses on the natural data after implementing robust optimization. We use AIF to analyze how model complexity and randomized smoothing affect the model sensitivity with respect to specific models. We further derive AIF for kernel regressions, with a particular application to neural tangent kernels, and experimentally demonstrate the effectiveness of the proposed AIF. Lastly, the theories of AIF will be extended to distributional robust optimization.
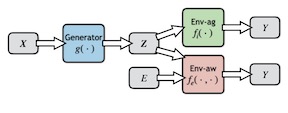
Selective rationalization improves neural network interpretability by identifying a small subset of input features — the rationale — that best explains or supports the prediction. A typical rationalization criterion, i.e. maximum mutual information (MMI), finds the rationale that maximizes the prediction performance based only on the rationale. However, MMI can be problematic because it picks up spurious correlations between the input features and the output. Instead, we introduce a game-theoretic invariant rationalization criterion where the rationales are constrained to enable the same predictor to be optimal across different environments. We show both theoretically and empirically that the proposed rationales can rule out spurious correlations and generalize better to different test scenarios. The resulting explanations also align better with human judgments. Our implementations are publicly available at https://github.com/code-terminator/invariant_rationalization.
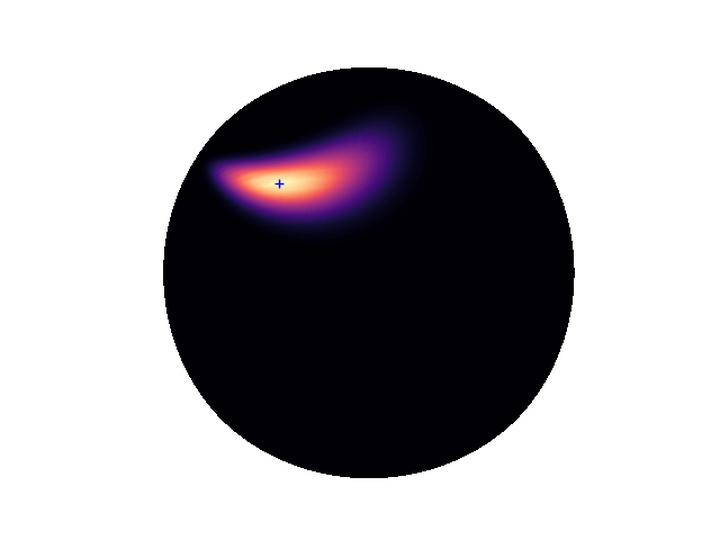
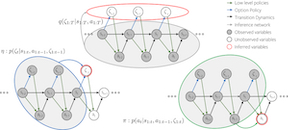
In this paper, we address the discovery of robotic options from demonstrations in an unsupervised manner. Specifically, we present a framework to jointly learn low-level control policies and higher-level policies of how to use them from demonstrations of a robot performing various tasks. By representing options as continuous latent variables, we frame the problem of learning these options as latent variable inference. We then present a temporally causal variant of variational inference based on a temporal factorization of trajectory likelihoods, that allows us to infer options in an unsupervised manner. We demonstrate the ability of our framework to learn such options across three robotic demonstration datasets.

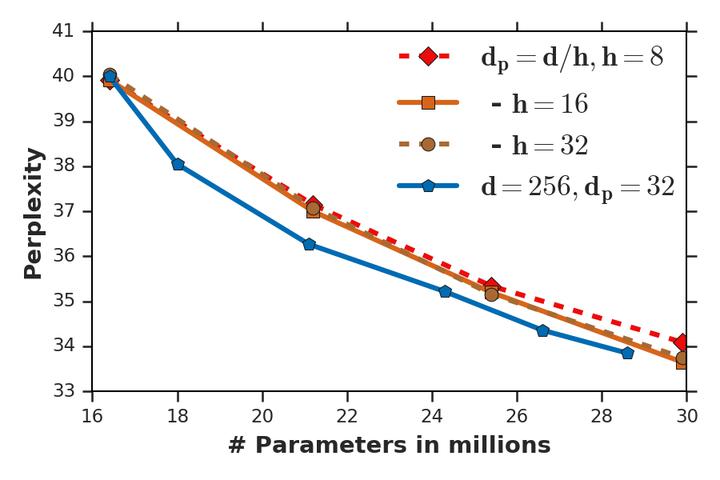
Attention based Transformer architecture has enabled significant advances in the field of natural language processing. In addition to new pre-training techniques, recent improvements crucially rely on working with a relatively larger embedding dimension for tokens. Unfortunately, this leads to models that are prohibitively large to be employed in the downstream tasks. In this paper we identify one of the important factors contributing to the large embedding size requirement. In particular, our analysis highlights that the scaling between the number of heads and the size of each head in the current architecture gives rise to a low-rank bottleneck in attention heads, causing this limitation. We further validate this in our experiments. As a solution we propose to set the head size of an attention unit to input sequence length, and independent of the number of heads, resulting in multi-head attention layers with provably more expressive power. We empirically show that this allows us to train models with a relatively smaller embedding dimension and with better performance scaling.

What goals should a multi-goal reinforcement learning agent pursue during training in long-horizon tasks? When the desired (test time) goal distribution is too distant to offer a useful learning signal, we argue that the agent should not pursue unobtainable goals. Instead, it should set its own intrinsic goals that maximize the entropy of the historical achieved goal distribution. We propose to optimize this objective by having the agent pursue past achieved goals in sparsely explored areas of the goal space, which focuses exploration on the frontier of the achievable goal set. We show that our strategy achieves an order of magnitude better sample efficiency than the prior state of the art on long-horizon multi-goal tasks including maze navigation and block stacking.

In this paper we tackle the problem of routing multiple agents in a coordinated manner. This is a complex problem that has a wide range of applications in fleet management to achieve a common goal, such as mapping from a swarm of robots and ride sharing. Traditional methods are typically not designed for realistic environments which contain sparsely connected graphs and unknown traffic, and are often too slow in runtime to be practical. In contrast, we propose a graph neural network based model that is able to perform multi-agent routing based on learned value iteration in a sparsely connected graph with dynamically changing traffic conditions. Moreover, our learned communication module enables the agents to coordinate online and adapt to changes more effectively. We created a simulated environment to mimic realistic mapping performed by autonomous vehicles with unknown minimum edge coverage and traffic conditions; our approach significantly outperforms traditional solvers both in terms of total cost and runtime. We also show that our model trained with only two agents on graphs with a maximum of 25 nodes can easily generalize to situations with more agents and/or nodes.
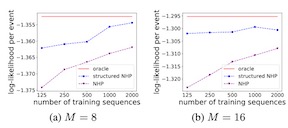
Learning how to predict future events from patterns of past events is difficult when the set of possible event types is large. Training an unrestricted neural model might overfit to spurious patterns. To exploit domain-specific knowledge of how past events might affect an event's present probability, we propose using a temporal deductive database to track structured facts over time. Rules serve to prove facts from other facts and from past events. Each fact has a time-varying state---a vector computed by a neural net whose topology is determined by the fact's provenance, including its experience of past events. The possible event types at any time are given by special facts, whose probabilities are neurally modeled alongside their states. In both synthetic and real-world domains, we show that neural probabilistic models derived from concise Datalog programs improve prediction by encoding appropriate domain knowledge in their architecture.
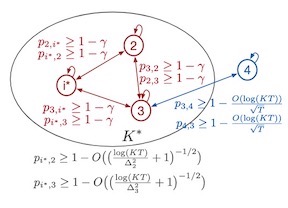
A general framework for online learning with partial information is one where feedback graphs specify which losses can be observed by the learner. We study a challenging scenario where feedback graphs vary stochastically with time and, more importantly, where graphs and losses are dependent. This scenario appears in several real-world applications that we describe where the outcome of actions are correlated. We devise a new algorithm for this setting that exploits the stochastic properties of the graphs and that benefits from favorable regret guarantees. We present a detailed theoretical analysis of this algorithm, and also report the result of a series of experiments on real-world datasets, which show that our algorithm outperforms standard baselines for online learning with feedback graphs.
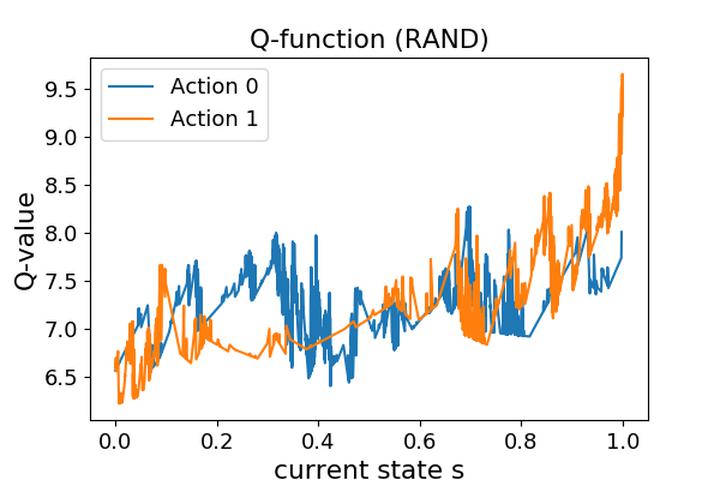
We compare the model-free reinforcement learning with the model-based approaches through the lens of the expressive power of neural networks for policies, Q-functions, and dynamics. We show, theoretically and empirically, that even for one-dimensional continuous state space, there are many MDPs whose optimal Q-functions and policies are much more complex than the dynamics. For these MDPs, model-based planning is a favorable algorithm, because the resulting policies can approximate the optimal policy significantly better than a neural network parameterization can, and model-free or model-based policy optimization rely on policy parameterization. Motivated by the theory, we apply a simple multi-step model-based bootstrapping planner (BOOTS) to bootstrap a weak Q-function into a stronger policy. Empirical results show that applying BOOTS on top of model-based or model-free policy optimization algorithms at the test time improves the performance on benchmark tasks.

Kernel selection for kernel-based methods is prohibitively expensive due to the NP-hard nature of discrete optimization. Since gradient-based optimizers are not applicable due to the lack of a differentiable objective function, many state-of-the-art solutions resort to heuristic search or gradient-free optimization. These approaches, however, require imposing restrictive assumptions on the explorable space of structures such as limiting the active candidate pool, thus depending heavily on the intuition of domain experts. This paper instead proposes \textbf{DTERGENS}, a novel generative search framework that constructs and optimizes a high-performance composite kernel expressions generator. \textbf{DTERGENS} does not restrict the space of candidate kernels and is capable of obtaining flexible length expressions by jointly optimizing a generative termination criterion. We demonstrate that our framework explores more diverse kernels and obtains better performance than state-of-the-art approaches on many real-world predictive tasks.

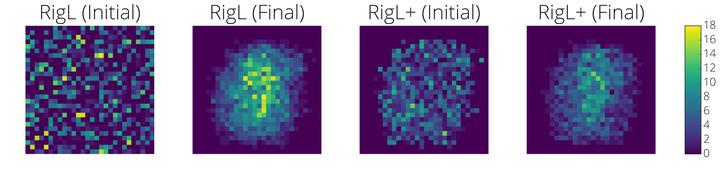
Many applications require sparse neural networks due to space or inference time restrictions. There is a large body of work on training dense networks to yield sparse networks for inference, but this limits the size of the largest trainable sparse model to that of the largest trainable dense model. In this paper we introduce a method to train sparse neural networks with a fixed parameter count and a fixed computational cost throughout training, without sacrificing accuracy relative to existing dense-to-sparse training methods. Our method updates the topology of the sparse network during training by using parameter magnitudes and infrequent gradient calculations. We show that this approach requires fewer floating-point operations (FLOPs) to achieve a given level of accuracy compared to prior techniques. We demonstrate state-of-the-art sparse training results on a variety of networks and datasets, including ResNet-50, MobileNets on Imagenet-2012, and RNNs on WikiText-103. Finally, we provide some insights into why allowing the topology to change during the optimization can overcome local minima encountered when the topology remains static.

Differentiable physics is a powerful approach to learning and control problems that involve physical objects and environments. While notable progress has been made, the capabilities of differentiable physics solvers remain limited. We develop a scalable framework for differentiable physics that can support a large number of objects and their interactions. To accommodate objects with arbitrary geometry and topology, we adopt meshes as our representation and leverage the sparsity of contacts for scalable differentiable collision handling. Collisions are resolved in localized regions to minimize the number of optimization variables even when the number of simulated objects is high. We further accelerate implicit differentiation of optimization with nonlinear constraints. Experiments demonstrate that the presented framework requires up to two orders of magnitude less memory and computation in comparison to recent particle-based methods. We further validate the approach on inverse problems and control scenarios, where it outperforms derivative-free and model-free baselines by at least an order of magnitude.

Autonomous agents that must exhibit flexible and broad capabilities will need to be equipped with large repertoires of skills. Defining each skill with a manually-designed reward function limits this repertoire and imposes a manual engineering burden. Self-supervised agents that set their own goals can automate this process, but designing appropriate goal setting objectives can be difficult, and often involves heuristic design decisions. In this paper, we propose a formal exploration objective for goal-reaching policies that maximizes state coverage. We show that this objective is equivalent to maximizing goal reaching performance together with the entropy of the goal distribution, where goals correspond to full state observations. To instantiate this principle, we present an algorithm called Skew-Fit for learning a maximum-entropy goal distributions. We prove that, under regularity conditions, Skew-Fit converges to a uniform distribution over the set of valid states, even when we do not know this set beforehand. Our experiments show that combining Skew-Fit for learning goal distributions with existing goal-reaching methods outperforms a variety of prior methods on open-sourced visual goal-reaching tasks. Moreover, we demonstrate that Skew-Fit enables a real-world robot to learn to open a door, entirely from scratch, from pixels, and without any manually-designed reward function.
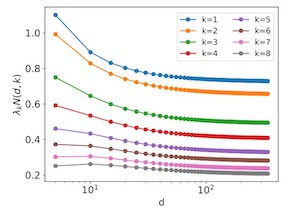
We derive analytical expressions for the generalization performance of kernel regression as a function of the number of training samples using theoretical methods from Gaussian processes and statistical physics. Our expressions apply to wide neural networks due to an equivalence between training them and kernel regression with the Neural Tangent Kernel (NTK). By computing the decomposition of the total generalization error due to different spectral components of the kernel, we identify a new spectral principle: as the size of the training set grows, kernel machines and neural networks fit successively higher spectral modes of the target function. When data are sampled from a uniform distribution on a high-dimensional hypersphere, dot product kernels, including NTK, exhibit learning stages where different frequency modes of the target function are learned. We verify our theory with simulations on synthetic data and MNIST dataset.
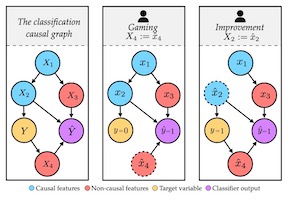
Consequential decision-making incentivizes individuals to strategically adapt their behavior to the specifics of the decision rule. While a long line of work has viewed strategic adaptation as gaming and attempted to mitigate its effects, recent work has instead sought to design classifiers that incentivize individuals to improve a desired quality. Key to both accounts is a cost function that dictates which adaptations are rational to undertake. In this work, we develop a causal framework for strategic adaptation. Our causal perspective clearly distinguishes between gaming and improvement and reveals an important obstacle to incentive design. We prove any procedure for designing classifiers that incentivize improvement must inevitably solve a non-trivial causal inference problem. We show a similar result holds for designing cost functions that satisfy the requirements of previous work. With the benefit of hindsight, our results show much of the prior work on strategic classification is causal modeling in disguise.
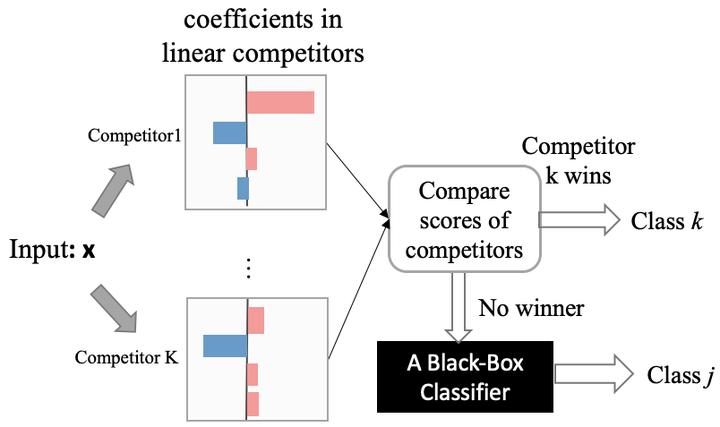
We propose a novel type of hybrid model for multi-class classification, which utilizes competing linear models to collaborate with an existing black-box model, promoting transparency in the decision-making process. Our proposed hybrid model, Model-Agnostic Linear Competitors (MALC), brings together the interpretable power of linear models and the good predictive performance of the state-of-the-art black-box models. We formulate the training of a MALC model as a convex optimization problem, optimizing the predictive accuracy and transparency (defined as the percentage of data captured by the linear models) in the objective function. Experiments show that MALC offers more model flexibility for users to balance transparency and accuracy, in contrast to the currently available choice of either a pure black-box model or a pure interpretable model. The human evaluation also shows that more users are likely to choose MALC for this model flexibility compared with interpretable models and black-box models.

Contrastive representation learning has been outstandingly successful in practice. In this work, we identify two key properties related to the contrastive loss: (1) alignment (closeness) of features from positive pairs, and (2) uniformity of the induced distribution of the (normalized) features on the hypersphere. We prove that, asymptotically, the contrastive loss optimizes these properties, and analyze their positive effects on downstream tasks. Empirically, we introduce an optimizable metric to quantify each property. Extensive experiments on standard vision and language datasets confirm the strong agreement between both metrics and downstream task performance. Directly optimizing for these two metrics leads to representations with comparable or better performance at downstream tasks than contrastive learning.
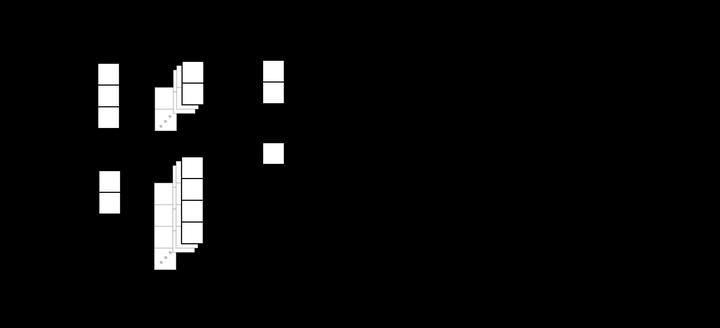
Group invariant and equivariant Multilayer Perceptrons (MLP), also known as Equivariant Networks, have achieved remarkable success in learning on a variety of data structures, such as sequences, images, sets, and graphs. Using tools from group theory, this paper proves the universality of a broad class of equivariant MLPs with a single hidden layer. In particular, it is shown that having a hidden layer on which the group acts regularly is sufficient for universal equivariance (invariance). A corollary is unconditional universality of equivariant MLPs for Abelian groups, such as CNNs with a single hidden layer. A second corollary is the universality of equivariant MLPs with a high-order hidden layer, where we give both group-agnostic bounds and means for calculating group-specific bounds on the order of hidden layer that guarantees universal equivariance (invariance).
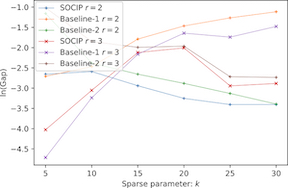
Sparse principal component analysis (PCA) is a widely-used dimensionality reduction tool in statistics and machine learning. Most methods mentioned in literature are either heuristics for good primal feasible solutions under statistical assumptions or ADMM-type algorithms with stationary/critical points convergence property for the regularized reformulation of sparse PCA. However, none of these methods can efficiently verify the quality of the solutions via comparing current objective values with their dual bounds, especially in model-free case. We propose a new framework that finds out upper (dual) bounds for the sparse PCA within polynomial time via solving a convex integer program (IP). We show that, in the worst-case, the dual bounds provided by the convex IP is within an affine function of the global optimal value. Moreover, in contrast to the semi-definition relaxation, this framework is much easier to scale on large cases. Numerical results on both artificial and real cases are reported to demonstrate the advantages of our method.
[ Virtual ]
[ Virtual ]
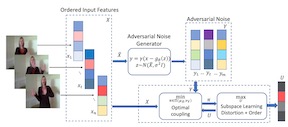
In this paper, we study the problem of learning compact (low-dimensional) representations for sequential data that captures its implicit spatio-temporal cues. To maximize extraction of such informative cues from the data, we set the problem within the context of contrastive representation learning and to that end propose a novel objective via optimal transport. Specifically, our formulation seeks a low-dimensional subspace representation of the data that jointly (i) maximizes the distance of the data (embedded in this subspace) from an adversarial data distribution under the optimal transport, a.k.a. the Wasserstein distance, (ii) captures the temporal order, and (iii) minimizes the data distortion. To generate the adversarial distribution, we propose a novel framework connecting Wasserstein GANs with a classifier, allowing a principled mechanism for producing good negative distributions for contrastive learning, which is currently a challenging problem. Our full objective is cast as a subspace learning problem on the Grassmann manifold and solved via Riemannian optimization. To empirically study our formulation, we provide experiments on the task of human action recognition in video sequences. Our results demonstrate competitive performance against challenging baselines.
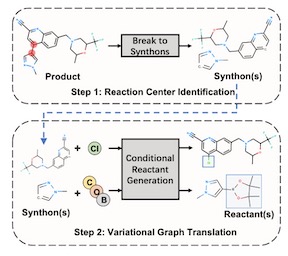
A fundamental problem in computational chemistry is to find a set of reactants to synthesize a target molecule, a.k.a. retrosynthesis prediction. Existing state-of-the-art methods rely on matching the target molecule with a large set of reaction templates, which are very computationally expensive and also suffer from the problem of coverage. In this paper, we propose a novel template-free approach called G2Gs by transforming a target molecular graph into a set of reactant molecular graphs. G2Gs first splits the target molecular graph into a set of synthons by identifying the reaction centers, and then translates the synthons to the final reactant graphs via a variational graph translation framework. Experimental results show that G2Gs significantly outperforms existing template-free approaches by up to 63% in terms of the top-1 accuracy and achieves a performance close to that of state-of-the-art template-based approaches, but does not require domain knowledge and is much more scalable.
Recent encoder-decoder approaches typically employ string decoders to convert images into serialized strings for image-to-markup. However, for tree-structured representational markup, string representations can hardly cope with the structural complexity. In this work, we first show via a set of toy problems that string decoders struggle to decode tree structures, especially as structural complexity increases, we then propose a tree-structured decoder that specifically aims at generating a tree-structured markup. Our decoders works sequentially, where at each step a child node and its parent node are simultaneously generated to form a sub-tree. This sub-tree is consequently used to construct the final tree structure in a recurrent manner. Key to the success of our tree decoder is twofold, (i) it strictly respects the parent-child relationship of trees, and (ii) it explicitly outputs trees as oppose to a linear string. Evaluated on both math formula recognition and chemical formula recognition, the proposed tree decoder is shown to greatly outperform strong string decoder baselines.
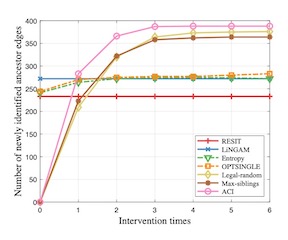
In many real tasks, we care about how to make decisions rather than mere predictions on an event, e.g. how to increase the revenue next month instead of merely knowing it will drop. The key is to identify the causal effects on the desired event. It is achievable with do-calculus if the causal structure is known; however, in many real tasks it is not easy to infer the whole causal structure with the observational data. Introducing external interventions is needed to achieve it. In this paper, we study the situation where only the response variable is observable under intervention. We propose a novel approach which is able to cost-effectively identify the causal effects, by an active strategy introducing limited interventions, and thus guide decision-making. Theoretical analysis and empirical studies validate the effectiveness of the proposed approach.

The Markov assumption (MA) is fundamental to the empirical validity of reinforcement learning. In this paper, we propose a novel Forward-Backward Learning procedure to test MA in sequential decision making. The proposed test does not assume any parametric form on the joint distribution of the observed data and plays an important role for identifying the optimal policy in high-order Markov decision processes (MDPs) and partially observable MDPs. Theoretically, we establish the validity of our test. Empirically, we apply our test to both synthetic datasets and a real data example from mobile health studies to illustrate its usefulness.
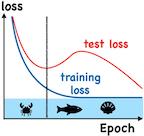
Overparameterized deep networks have the capacity to memorize training data with zero \emph{training error}. Even after memorization, the \emph{training loss} continues to approach zero, making the model overconfident and the test performance degraded. Since existing regularizers do not directly aim to avoid zero training loss, it is hard to tune their hyperparameters in order to maintain a fixed/preset level of training loss. We propose a direct solution called \emph{flooding} that intentionally prevents further reduction of the training loss when it reaches a reasonably small value, which we call the \emph{flood level}. Our approach makes the loss float around the flood level by doing mini-batched gradient descent as usual but gradient ascent if the training loss is below the flood level. This can be implemented with one line of code and is compatible with any stochastic optimizer and other regularizers. With flooding, the model will continue to ``random walk'' with the same non-zero training loss, and we expect it to drift into an area with a flat loss landscape that leads to better generalization. We experimentally show that flooding improves performance and, as a byproduct, induces a double descent curve of the test loss.
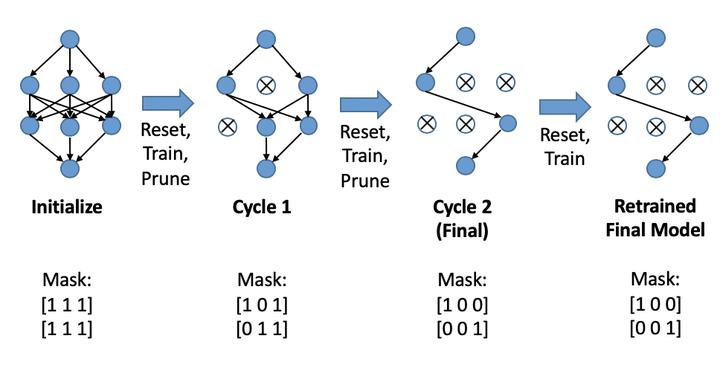
Modern deep neural networks require a significant amount of computing time and power to train and deploy, which limits their usage on edge devices. Inspired by the iterative weight pruning in the Lottery Ticket Hypothesis, we propose DropNet, an iterative pruning method which prunes nodes/filters to reduce network complexity. DropNet iteratively removes nodes/filters with the lowest average post-activation value across all training samples. Empirically, we show that DropNet is robust across a wide range of scenarios, including MLPs and CNNs using the MNIST and CIFAR datasets. We show that up to 90% of the nodes/filters can be removed without any significant loss of accuracy. The final pruned network performs well even with reinitialisation of the weights and biases. DropNet also achieves similar accuracy to an oracle which greedily removes nodes/filters one at a time to minimise training loss, highlighting its effectiveness.
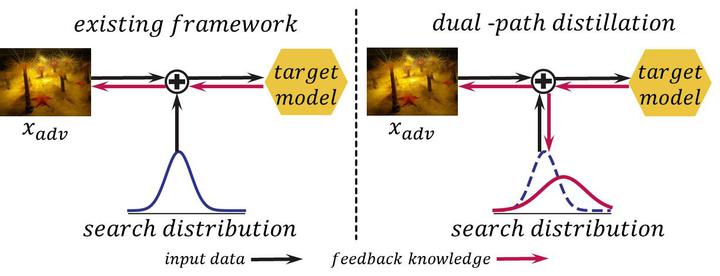
We study the problem of constructing black-box adversarial attacks, where no model information is revealed except for the feedback knowledge of the given inputs. To obtain sufficient knowledge for crafting adversarial examples, previous methods query the target model with inputs that are perturbed with different searching directions. However, these methods suffer from poor query efficiency since the employed searching directions are sampled randomly. To mitigate this issue, we formulate the goal of mounting efficient attacks as an optimization problem in which the adversary tries to fool the target model with a limited number of queries. Under such settings, the adversary has to select appropriate searching directions to reduce the number of model queries. By solving the efficient-attack problem, we find that we need to distill the knowledge in both the path of the adversarial examples and the path of the searching directions. Therefore, we propose a novel framework, dual-path distillation, that utilizes the feedback knowledge not only to craft adversarial examples but also to alter the searching directions to achieve efficient attacks. Experimental results suggest that our framework can significantly increase the query efficiency.
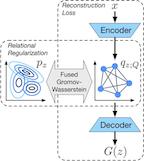
We propose a new algorithmic framework for learning autoencoders of data distributions. In this framework, we minimize the discrepancy between the model distribution and the target one, with relational regularization on learnable latent prior. This regularization penalizes the fused Gromov-Wasserstein (FGW) distance between the latent prior and its corresponding posterior, which allows us to learn a structured prior distribution associated with the generative model in a flexible way. Moreover, it helps us co-train multiple autoencoders even if they are with heterogeneous architectures and incomparable latent spaces. We implement the framework with two scalable algorithms, making it applicable for both probabilistic and deterministic autoencoders. Our relational regularized autoencoder (RAE) outperforms existing methods, e.g., variational autoencoder, Wasserstein autoencoder, and their variants, on generating images. Additionally, our relational co-training strategy of autoencoders achieves encouraging results in both synthesis and real-world multi-view learning tasks.
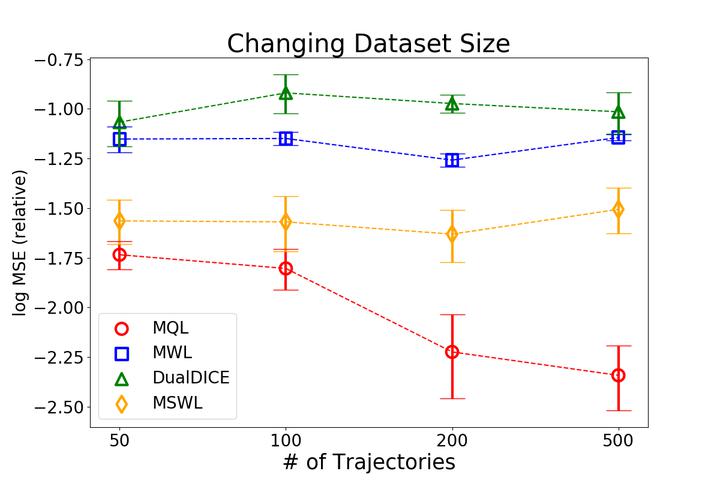
We provide theoretical investigations into off-policy evaluation in reinforcement learning using function approximators for (marginalized) importance weights and value functions. Our contributions include: (1) A new estimator, MWL, that directly estimates importance ratios over the state-action distributions, removing the reliance on knowledge of the behavior policy as in prior work (Liu et.al, 2018), (2) Another new estimator, MQL, obtained by swapping the roles of importance weights and value-functions in MWL. MQL has an intuitive interpretation of minimizing average Bellman errors and can be combined with MWL in a doubly robust manner, (3) Several additional results that offer further insights, including the sample complexities of MWL and MQL, their asymptotic optimality in the tabular setting, how the learned importance weights depend the choice of the discriminator class, and how our methods provide a unified view of some old and new algorithms in RL.

Researches using margin based comparison loss demonstrate the effectiveness of penalizing the distance between face feature and their corresponding class centers. Despite their popularity and excellent performance, they do not explicitly encourage the generic embedding learning for an open set recognition problem. In this paper, we analyse margin based softmax loss in probability view. With this perspective, we propose two general principles: 1) monotonically decreasing and 2) margin probability penalty, for designing new margin loss functions. Unlike methods optimized with single comparison metric, we provide a new perspective to treat open set face recognition as a problem of information transmission. And the generalization capability for face embedding is gained with more clean information. An auto-encoder architecture called Linear-Auto-TS-Encoder(LATSE) is proposed to corroborate this finding. Extensive experiments on several benchmarks demonstrate that LATSE help face embedding to gain more generalization capability and it boost the single model performance with open training dataset to more than 99% on MegaFace test.
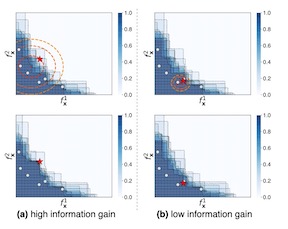
This paper studies an entropy-based multi-objective Bayesian optimization (MBO). Existing entropy-based MBO methods need complicated approximations to evaluate entropy or employ over-simplification that ignores trade-off among objectives. We propose a novel entropy-based MBO called Pareto-frontier entropy search (PFES), which is based on the information gain of Pareto-frontier. We show that our entropy evaluation can be reduced to a closed form whose computation is quite simple while capturing the trade-off relation in Pareto-frontier. We further propose an extension for the ``decoupled'' setting, in which each objective function can be observed separately, and show that the PFES-based approach derives a natural extension of the original acquisition function which can also be evaluated simply. Our numerical experiments show effectiveness of PFES through several benchmark datasets, and real-word datasets from materials science.
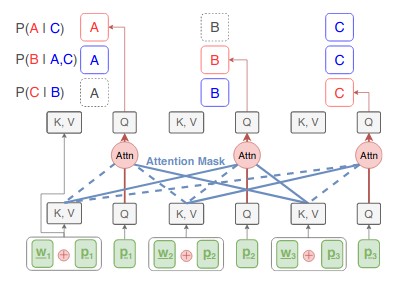
State-of-the-art neural machine translation models generate a translation from left to right and every step is conditioned on the previously generated tokens. The sequential nature of this generation process causes fundamental latency in inference since we cannot generate multiple tokens in each sentence in parallel. We propose an attention-masking based model, called Disentangled Context (DisCo) transformer, that simultaneously generates all tokens given different contexts. The DisCo transformer is trained to predict every output token given an arbitrary subset of the other reference tokens. We also develop the parallel easy-first inference algorithm, which iteratively refines every token in parallel and reduces the number of required iterations. Our extensive experiments on 7 translation directions with varying data sizes demonstrate that our model achieves competitive, if not better, performance compared to the state of the art in non-autoregressive machine translation while significantly reducing decoding time on average.

While deep neural networks achieve great performance on fitting the training distribution, the learned networks are prone to overfitting and are susceptible to adversarial attacks. In this regard, a number of mixup based augmentation methods have been recently proposed. However, these approaches mainly focus on creating previously unseen virtual examples and can sometimes provide misleading supervisory signal to the network. To this end, we propose Puzzle Mix, a mixup method for explicitly utilizing the saliency information and the underlying statistics of the natural examples. This leads to an interesting optimization problem alternating between the multi-label objective for optimal mixing mask and saliency discounted optimal transport objective. Our experiments show Puzzle Mix achieves the state of the art generalization and the adversarial robustness results compared to other mixup methods on CIFAR-100, Tiny-ImageNet, and ImageNet datasets, and the source code is available at https://github.com/snu-mllab/PuzzleMix.


Heretofore, neural networks with external memory are restricted to single memory with lossy representations of memory interactions. A rich representation of relationships between memory pieces urges a high-order and segregated relational memory. In this paper, we propose to separate the storage of individual experiences (item memory) and their occurring relationships (relational memory). The idea is implemented through a novel Self-attentive Associative Memory (SAM) operator. Found upon outer product, SAM forms a set of associative memories that represent the hypothetical high-order relationships between arbitrary pairs of memory elements, through which a relational memory is constructed from an item memory. The two memories are wired into a single sequential model capable of both memorization and relational reasoning. We achieve competitive results with our proposed two-memory model in a diversity of machine learning tasks, from challenging synthetic problems to practical testbeds such as geometry, graph, reinforcement learning, and question answering.
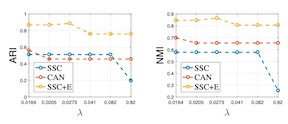
In this paper, we provide an explicit theoretical connection between Sparse subspace clustering (SSC) and spectral clustering (SC) from the perspective of learning a data similarity matrix. We show that spectral clustering with Gaussian kernel can be viewed as sparse subspace clustering with entropy-norm (SSC+E). Compared to SSC, SSC+E can obtain an analytical, symmetrical, nonnegative and nonlinearly-representational similarity matrix. Besides, SSC+E makes use of Gaussian kernel to compute the sparse similarity matrix of objects, which can avoid the complex computation of the sparse optimization program of SSC. Finally, we provide the experimental analysis to compare the efficiency and effectiveness of sparse subspace clustering and spectral clustering on ten benchmark data sets. The theoretical and experimental analysis can well help users for the selection of high-dimensional data clustering algorithms.
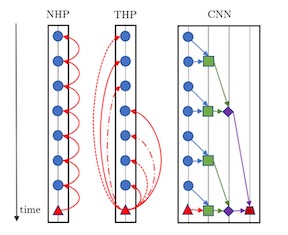
Modern data acquisition routinely produce massive amounts of event sequence data in various domains, such as social media, healthcare, and financial markets. These data often exhibit complicated short-term and long-term temporal dependencies. However, most of the existing recurrent neural network based point process models fail to capture such dependencies, and yield unreliable prediction performance. To address this issue, we propose a Transformer Hawkes Process (THP) model, which leverages the self-attention mechanism to capture long-term dependencies and meanwhile enjoys computational efficiency. Numerical experiments on various datasets show that THP outperforms existing models in terms of both likelihood and event prediction accuracy by a notable margin. Moreover, THP is quite general and can incorporate additional structural knowledge. We provide a concrete example, where THP achieves improved prediction performance for learning multiple point processes when incorporating their relational information.
Poster Session 50 Fri 17 Jul 03:00 a.m.
[ Virtual ]
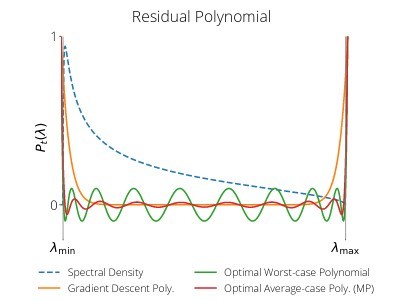
We develop a framework for the average-case analysis of random quadratic problems and derive algorithms that are optimal under this analysis. This yields a new class of methods that achieve acceleration given a model of the Hessian's eigenvalue distribution. We develop explicit algorithms for the uniform, Marchenko-Pastur, and exponential distributions. These methods are momentum-based algorithms, whose hyper-parameters can be estimated without knowledge of the Hessian's smallest singular value, in contrast with classical accelerated methods like Nesterov acceleration and Polyak momentum. Through empirical benchmarks on quadratic and logistic regression problems, we identify regimes in which the the proposed methods improve over classical (worst-case) accelerated methods.
[ Virtual ]
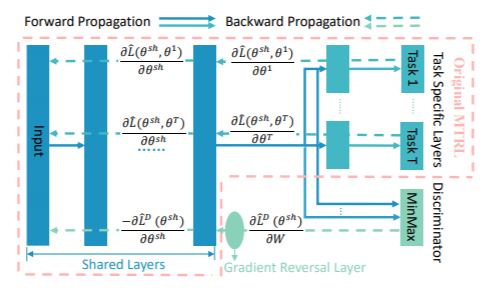
Adversarial Multi-task Representation Learning (AMTRL) methods are able to boost the performance of Multi-task Representation Learning (MTRL) models. However, the theoretical mechanism behind AMTRL is less investigated. To fill this gap, we study the generalization error bound of AMTRL through the lens of Lagrangian duality . Based on the duality, we proposed an novel adaptive AMTRL algorithm which improves the performance of original AMTRL methods. The extensive experiments back up our theoretical analysis and validate the superiority of our proposed algorithm.
[ Virtual ]
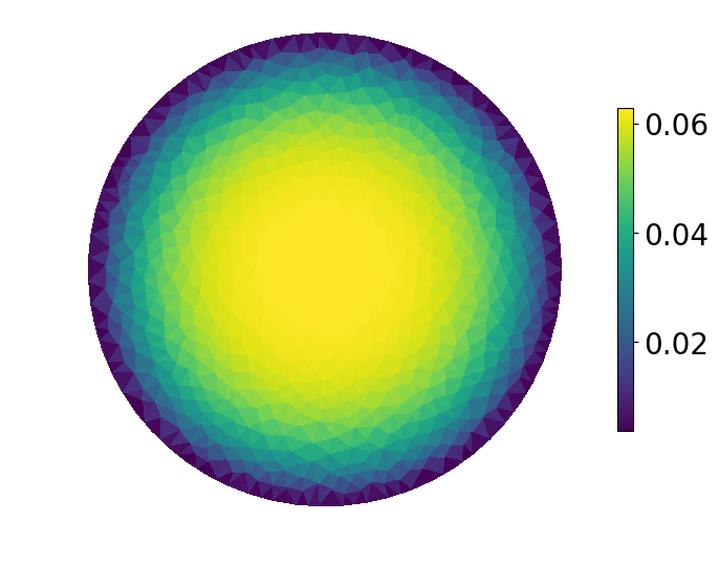
Optimizing the parameters of partial differential equations (PDEs), i.e., PDE-constrained optimization (PDE-CO), allows us to model natural systems from observations or perform rational design of structures with complicated mechanical, thermal, or electromagnetic properties. However, PDE-CO is often computationally prohibitive due to the need to solve the PDE---typically via finite element analysis (FEA)---at each step of the optimization procedure. In this paper we propose amortized finite element analysis (AmorFEA), in which a neural network learns to produce accurate PDE solutions, while preserving many of the advantages of traditional finite element methods. This network is trained to directly minimize the potential energy from which the PDE and finite element method are derived, avoiding the need to generate costly supervised training data by solving PDEs with traditional FEA. As FEA is a variational procedure, AmorFEA is a direct analogue to popular amortized inference approaches in latent variable models, with the finite element basis acting as the variational family. AmorFEA can perform PDE-CO without the need to repeatedly solve the associated PDE, accelerating optimization when compared to a traditional workflow using FEA and the adjoint method.
[ Virtual ]
This paper studies a problem of learning surface mesh via implicit functions in an emerging field of deep learning surface reconstruction, where implicit functions are popularly implemented as multi-layer perceptrons (MLPs) with rectified linear units (ReLU). To achieve meshing from the learned implicit functions, existing methods adopt the de-facto standard algorithm of marching cubes; while promising, they suffer from loss of precision learned in the MLPs, due to the discretization nature of marching cubes. Motivated by the knowledge that a ReLU based MLP partitions its input space into a number of linear regions, we identify from these regions analytic cells and faces that are associated with zero-level isosurface of the implicit function, and characterize the conditions under which the identified faces are guaranteed to connect and form a closed, piecewise planar surface. We propose a naturally parallelizable algorithm of analytic marching to exactly recover the mesh captured by a learned MLP. Experiments on deep learning mesh reconstruction verify the advantages of our algorithm over existing ones.
[ Virtual ]
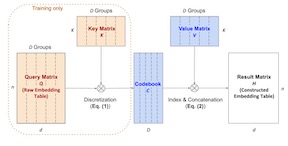
Embedding layers are commonly used to map discrete symbols into continuous embedding vectors that reflect their semantic meanings. Despite their effectiveness, the number of parameters in an embedding layer increases linearly with the number of symbols and poses a critical challenge on memory and storage constraints. In this work, we propose a generic and end-to-end learnable compression framework termed differentiable product quantization (DPQ). We present two instantiations of DPQ that leverage different approximation techniques to enable differentiability in end-to-end learning. Our method can readily serve as a drop-in alternative for any existing embedding layer. Empirically, DPQ offers significant compression ratios (14-238X) at negligible or no performance cost on 10 datasets across three different language tasks.
[ Virtual ]

Generative adversarial networks (GANs) represent a zero-sum game between two machine players, a generator and a discriminator, designed to learn the distribution of data. While GANs have achieved state-of-the-art performance in several benchmark learning tasks, GAN minimax optimization still poses great theoretical and empirical challenges. GANs trained using first-order optimization methods commonly fail to converge to a stable solution where the players cannot improve their objective, i.e., the Nash equilibrium of the underlying game. Such issues raise the question of the existence of Nash equilibria in GAN zero-sum games. In this work, we show through theoretical and numerical results that indeed GAN zero-sum games may have no Nash equilibria. To characterize an equilibrium notion applicable to GANs, we consider the equilibrium of a new zero-sum game with an objective function given by a proximal operator applied to the original objective, a solution we call the proximal equilibrium. Unlike the Nash equilibrium, the proximal equilibrium captures the sequential nature of GANs, in which the generator moves first followed by the discriminator. We prove that the optimal generative model in Wasserstein GAN problems provides a proximal equilibrium. Inspired by these results, we propose a new approach, which we call proximal training, for …
[ Virtual ]
Trustworthy AI is a critical issue in machine learning where, in addition to training a model that is accurate, one must consider both fair and robust training in the presence of data bias and poisoning. However, the existing model fairness techniques mistakenly view poisoned data as an additional bias to be fixed, resulting in severe performance degradation. To address this problem, we propose FR-Train, which holistically performs fair and robust model training. We provide a mutual information-based interpretation of an existing adversarial training-based fairness-only method, and apply this idea to architect an additional discriminator that can identify poisoned data using a clean validation set and reduce its influence. In our experiments, FR-Train shows almost no decrease in fairness and accuracy in the presence of data poisoning by both mitigating the bias and defending against poisoning. We also demonstrate how to construct clean validation sets using crowdsourcing, and release new benchmark datasets.
[ Virtual ]
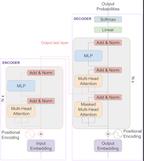
The Transformer architecture has achieved considerable success recently; the key component of the Transformer is the attention layer that enables the model to focus on important regions within an input sequence. Gradient optimization with attention layers can be notoriously difficult requiring tricks such as learning rate warmup to prevent divergence. As Transformer models are becoming larger and more expensive to train, recent research has focused on understanding and improving optimization in these architectures. In this work our contributions are two-fold: we first investigate and empirically validate the source of optimization problems in the encoder-decoder Transformer architecture; we then propose a new weight initialization scheme with theoretical justification, that enables training without warmup or layer normalization. Empirical results on public machine translation benchmarks show that our approach achieves leading accuracy, allowing to train deep Transformer models with 200 layers in both encoder and decoder (over 1000 attention/MLP blocks) without difficulty. Code for this work is available here:~\url{https://github.com/layer6ai-labs/T-Fixup}.
[ Virtual ]

In this work, we propose a robust test for the multivariate two-sample problem through projective ensemble, which is a generalization of the Cramer-von Mises statistic. The proposed test statistic has a simple closed-form expression without any tuning parameters involved, it is easy to implement can be computed in quadratic time. Moreover, our test is insensitive to the dimension and consistent against all fixed alternatives, it does not require the moment assumption and is robust to the presence of outliers. We study the asymptotic behaviors of the test statistic under the null and two kinds of alternative hypotheses. We also suggest a permutation procedure to approximate critical values and employ its consistency. We demonstrate the effectiveness of our test through extensive simulation studies and a real data application.
[ Virtual ]

[ Virtual ]
Computational equilibrium finding in large zero-sum extensive-form imperfect-information games has led to significant recent AI breakthroughs. The fastest algorithms for the problem are new forms of counterfactual regret minimization (Brown & Sandholm, 2019). In this paper we present a totally different approach to the problem, which is competitive and often orders of magnitude better than the prior state of the art. The equilibrium-finding problem can be formulated as a linear program (LP) (Koller et al., 1994), but solving it as an LP has not been scalable due to the memory requirements of LP solvers, which can often be quadratically worse than CFR-based algorithms. We give an efficient practical algorithm that factors a large payoff matrix into a product of two matrices that are typically dramatically sparser. This allows us to express the equilibrium-finding problem as a linear program with size only a logarithmic factor worse than CFR, and thus allows linear program solvers to run on such games. With experiments on poker endgames, we demonstrate in practice, for the first time, that modern linear program solvers are competitive against even game-specific modern variants of CFR in solving large extensive-form games, and can be used to compute exact solutions unlike iterative …
[ Virtual ]

Beyond machine learning's success in the specific tasks, research for learning multiple tasks simultaneously is referred to as multi-task learning. However, existing multi-task learning needs manual definition of tasks and manual task annotation. A crucial problem for advanced intelligence is how to understand the human task concept using basic input-output pairs. Without task definition, samples from multiple tasks are mixed together and result in a confusing mapping challenge. We propose Confusing Supervised Learning (CSL) that takes these confusing samples and extracts task concepts by differentiating between these samples. We theoretically proved the feasibility of the CSL framework and designed an iterative algorithm to distinguish between tasks. The experiments demonstrate that our CSL methods could achieve a human-like task understanding without task labeling in multi-function regression problems and multi-task recognition problems.
[ Virtual ]
Meta-learning algorithms produce feature extractors which achieve state-of-the-art performance on few-shot classification. While the literature is rich with meta-learning methods, little is known about why the resulting feature extractors perform so well. We develop a better understanding of the underlying mechanics of meta-learning and the difference between models trained using meta-learning and models which are trained classically. In doing so, we introduce and verify several hypotheses for why meta-learned models perform better. Furthermore, we develop a regularizer which boosts the performance of standard training routines for few-shot classification. In many cases, our routine outperforms meta-learning while simultaneously running an order of magnitude faster.
We present a new active learning algorithm that adaptively partitions the input space into a finite number of regions, and subsequently seeks a distinct predictor for each region, while actively requesting labels. We prove theoretical guarantees for both the generalization error and the label complexity of our algorithm, and analyze the number of regions defined by the algorithm under some mild assumptions. We also report the results of an extensive suite of experiments on several real-world datasets demonstrating substantial empirical benefits over existing single-region and non-adaptive region-based active learning baselines.

In recent years, a variety of gradient-based bi-level optimization methods have been developed for learning tasks. However, theoretical guarantees of these existing approaches often heavily rely on the simplification that for each fixed upper-level variable, the lower-level solution must be a singleton (a.k.a., Lower-Level Singleton, LLS). In this work, by formulating bi-level models from the optimistic viewpoint and aggregating hierarchical objective information, we establish Bi-level Descent Aggregation (BDA), a flexible and modularized algorithmic framework for bi-level programming. Theoretically, we derive a new methodology to prove the convergence of BDA without the LLS condition. Furthermore, we improve the convergence properties of conventional first-order bi-level schemes (under the LLS simplification) based on our proof recipe. Extensive experiments justify our theoretical results and demonstrate the superiority of the proposed BDA for different tasks, including hyper-parameter optimization and meta learning.
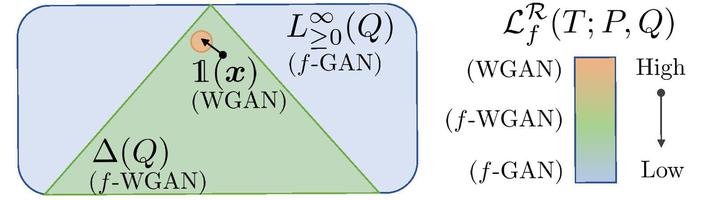
Generative adversarial networks (GANs) variants approximately minimize divergences between the model and the data distribution using a discriminator. Wasserstein GANs (WGANs) enjoy superior empirical performance, however, unlike in f-GANs, the discriminator does not provide an estimate for the ratio between model and data densities, which is useful in applications such as inverse reinforcement learning. To overcome this limitation, we propose an new training objective where we additionally optimize over a set of importance weights over the generated samples. By suitably constraining the feasible set of importance weights, we obtain a family of objectives which includes and generalizes the original f-GAN and WGAN objectives. We show that a natural extension outperforms WGANs while providing density ratios as in f-GAN, and demonstrate empirical success on distribution modeling, density ratio estimation and image generation.
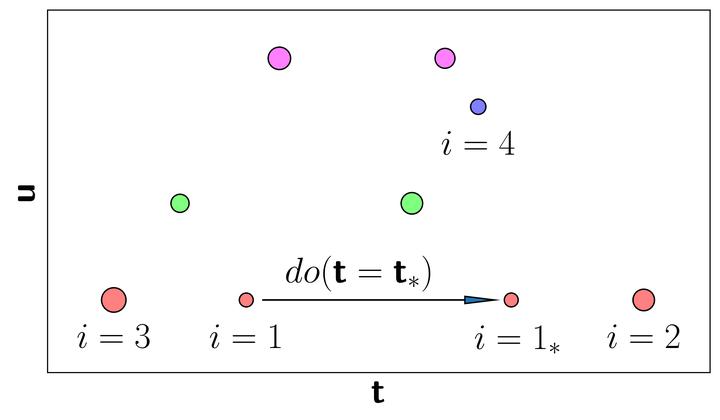
Latent confounders---unobserved variables that influence both treatment and outcome---can bias estimates of causal effects. In some cases, these confounders are shared across observations, e.g. all students in a school are influenced by the school's culture in addition to any educational interventions they receive individually. This paper shows how to model latent confounders that have this structure and thereby improve estimates of causal effects. The key innovations are a hierarchical Bayesian model, Gaussian processes with structured latent confounders (GP-SLC), and a Monte Carlo inference algorithm for this model based on elliptical slice sampling. GP-SLC provides principled Bayesian uncertainty estimates of individual treatment effect with minimal assumptions about the functional forms relating confounders, covariates, treatment, and outcomes. This paper also proves that, for linear functional forms, accounting for the structure in latent confounders is sufficient for asymptotically consistent estimates of causal effect. Finally, this paper shows GP-SLC is competitive with or more accurate than widely used causal inference techniques such as multi-level linear models and Bayesian additive regression trees. Benchmark datasets include the Infant Health and Development Program and a dataset showing the effect of changing temperatures on state-wide energy consumption across New England.

Invariance (defined in a general sense) has been one of the most effective priors for representation learning. Direct factorization of parametric models is feasible only for a small range of invariances, while regularization approaches, despite improved generality, lead to nonconvex optimization. In this work, we develop a \emph{convex} representation learning algorithm for a variety of generalized invariances that can be modeled as semi-norms. Novel Euclidean embeddings are introduced for kernel representers in a semi-inner-product space, and approximation bounds are established. This allows invariant representations to be learned efficiently and effectively as confirmed in our experiments, along with accurate predictions.
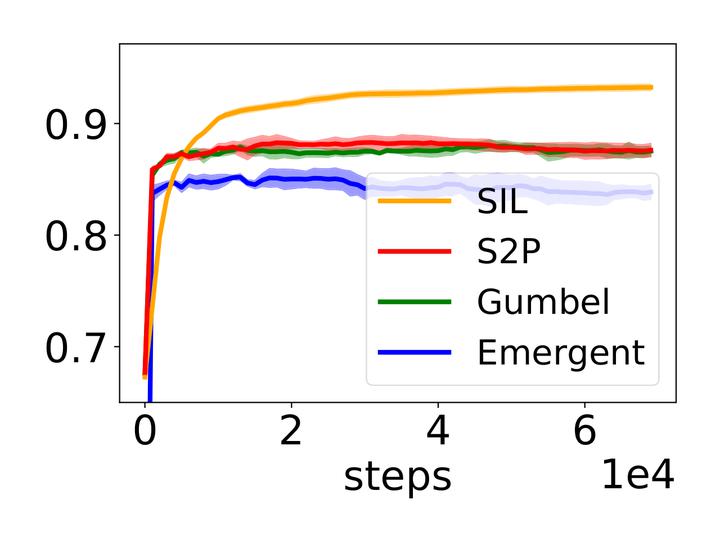
Supervised learning methods excel at capturing statistical properties of language when trained over large text corpora. Yet, these models often produce inconsistent outputs in goal-oriented language settings as they are not trained to complete the underlying task. Moreover, as soon as the agents are finetuned to maximize task completion, they suffer from the so-called language drift phenomenon: they slowly lose syntactic and semantic properties of language as they only focus on solving the task. In this paper, we propose a generic approach to counter language drift called Seeded iterated learning(SIL). We periodically refine a pretrained student agent by imitating data sampled from a newly generated teacher agent. At each time step, the teacher is created by copying the student agent, before being finetuned to maximize task completion.SIL does not require external syntactic constraint nor semantic knowledge, making it a valuable task-agnostic finetuning protocol. We evaluate SIL in a toy-setting Lewis Game, and then scale it up to the translation game with natural language. In both settings, SIL helps counter language drift as well as it improves the task completion compared to baselines.
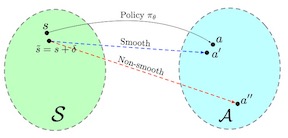
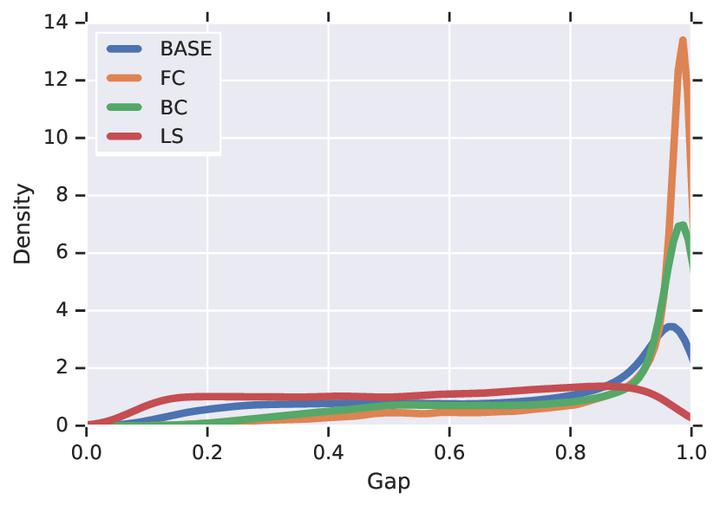
Label smoothing is commonly used in training deep learning models, wherein one-hot training labels are mixed with uniform label vectors. Empirically, smoothing has been shown to improve both predictive performance and model calibration. In this paper, we study whether label smoothing is also effective as a means of coping with label noise. While label smoothing apparently amplifies this problem --- being equivalent to injecting symmetric noise to the labels --- we show how it relates to a general family of loss-correction techniques from the label noise literature. Building on this connection, we show that label smoothing is competitive with loss-correction under label noise. Further, we show that when distilling models from noisy data, label smoothing of the teacher is beneficial; this is in contrast to recent findings for noise-free problems, and sheds further light on settings where label smoothing is beneficial.

The deterministic CUR matrix decomposition is a low-rank approximation method to analyze a data matrix. It has attracted considerable attention due to its high interpretability, which results from the fact that the decomposed matrices consist of subsets of the original columns and rows of the data matrix. The subset is obtained by optimizing an objective function with sparsity-inducing norms via coordinate descent. However, the existing algorithms for optimization incur high computation costs. This is because coordinate descent iteratively updates all the parameters in the objective until convergence. This paper proposes a fast deterministic CUR matrix decomposition. Our algorithm safely skips unnecessary updates by efficiently evaluating the optimality conditions for the parameters to be zeros. In addition, we preferentially update the parameters that must be nonzeros. Theoretically, our approach guarantees the same result as the original approach. Experiments demonstrate that our algorithm speeds up the deterministic CUR while achieving the same accuracy.

\textbf{G}raph \textbf{C}onvolutional \textbf{N}etwork (\textbf{GCN}) is widely used in graph data learning tasks such as recommendation. However, when facing a large graph, the graph convolution is very computationally expensive thus is simplified in all existing GCNs, yet is seriously impaired due to the oversimplification. To address this gap, we leverage the \textit{original graph convolution} in GCN and propose a \textbf{L}ow-pass \textbf{C}ollaborative \textbf{F}ilter (\textbf{LCF}) to make it applicable to the large graph. LCF is designed to remove the noise caused by exposure and quantization in the observed data, and it also reduces the complexity of graph convolution in an unscathed way. Experiments show that LCF improves the effectiveness and efficiency of graph convolution and our GCN outperforms existing GCNs significantly. Codes are available on \url{https://github.com/Wenhui-Yu/LCFN}.
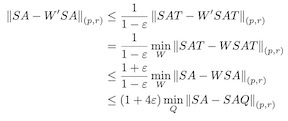
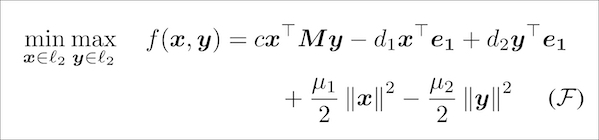
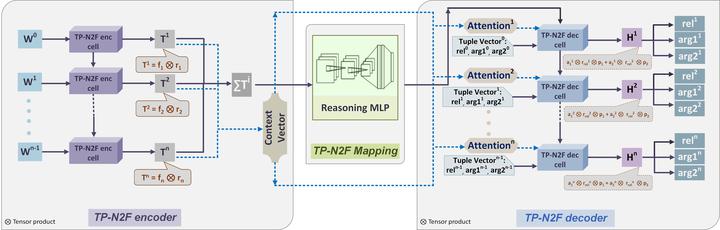
Generating formal-language programs represented by relational tuples, such as Lisp programs or mathematical operations, to solve problems stated in natural language is a challenging task because it requires explicitly capturing discrete symbolic structural information implicit in the input. However, most general neural sequence models do not explicitly capture such structural information, limiting their performance on these tasks. In this paper, we propose a new encoder-decoder model based on a structured neural representation, Tensor Product Representations (TPRs), for mapping Natural-language problems to Formal-language solutions, called TPN2F. The encoder of TP-N2F employs TPR ‘binding’ to encode natural-language symbolic structure in vector space and the decoder uses TPR ‘unbinding’ to generate, in symbolic space, a sequential program represented by relational tuples, each consisting of a relation (or operation) and a number of arguments. TP-N2F considerably outperforms LSTM-based seq2seq models on two benchmarks and creates new state-of-the-art results. Ablation studies show that improvements can be attributed to the use of structured TPRs explicitly in both the encoder and decoder. Analysis of the learned structures shows how TPRs enhance the interpretability of TP-N2F.

Humans have the ability to robustly recognize objects with various factors of variations such as nonrigid transformations, background noises, and changes in lighting conditions. However, training deep learning models generally require huge amount of data instances under diverse variations, to ensure its robustness. To alleviate the need of collecting large amount of data and better learn to generalize with scarce data instances, we propose a novel meta-learning method which learns to transfer factors of variations from one class to another, such that it can improve the classification performance on unseen examples. Transferred variations generate virtual samples that augment the feature space of the target class during training, simulating upcoming query samples with similar variations. By sharing the factors of variations across different classes, the model becomes more robust to variations in the unseen examples and tasks using small number of examples per class. We validate our model on multiple benchmark datasets for few-shot classification and face recognition, on which our model significantly improves the performance of the base model, outperforming relevant baselines.
Multi-Task Learning (MTL) is a well established paradigm for jointly learning models for multiple correlated tasks. Often the tasks conflict, requiring trade-offs between them during optimization. In such cases, multi-objective optimization based MTL methods can be used to find one or more Pareto optimal solutions. A common requirement in MTL applications, that cannot be addressed by these methods, is to find a solution satisfying userspecified preferences with respect to task-specific losses. We advance the state-of-the-art by developing the first gradient-based multi-objective MTL algorithm to solve this problem. Our unique approach combines multiple gradient descent with carefully controlled ascent to traverse the Pareto front in a principled manner, which also makes it robust to initialization. The scalability of our algorithm enables its use in large-scale deep networks for MTL. Assuming only differentiability of the task-specific loss functions, we provide theoretical guarantees for convergence. Our experiments show that our algorithm outperforms the best competing methods on benchmark datasets.
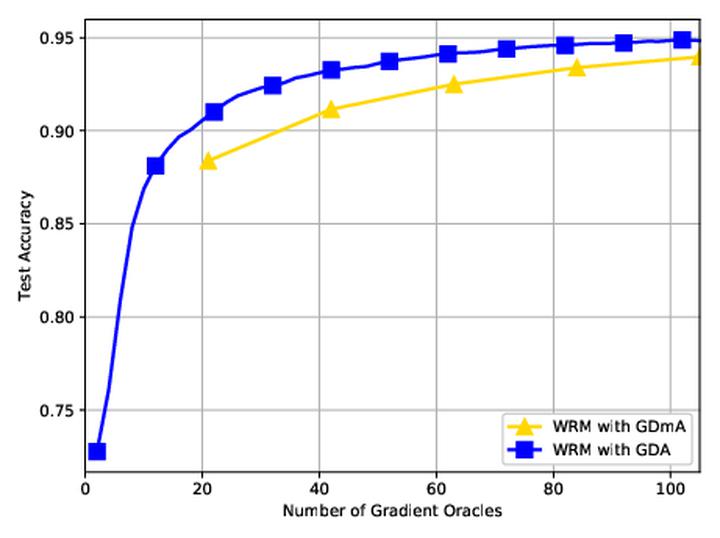

Automating algorithm configuration is growing increasingly necessary as algorithms come with more and more tunable parameters. It is common to tune parameters using machine learning, optimizing algorithmic performance (runtime or solution quality, for example) using a training set of problem instances from the specific domain at hand. We investigate a fundamental question about these techniques: how large should the training set be to ensure that a parameter’s average empirical performance over the training set is close to its expected, future performance? We answer this question for algorithm configuration problems that exhibit a widely-applicable structure: the algorithm's performance as a function of its parameters can be approximated by a “simple” function. We show that if this approximation holds under the L∞-norm, we can provide strong sample complexity bounds, but if the approximation holds only under the Lp-norm for p < ∞, it is not possible to provide meaningful sample complexity bounds in the worst case. We empirically evaluate our bounds in the context of integer programming, obtaining sample complexity bounds that are up to 700 times smaller than the previously best-known bounds.
When tasks change over time, meta-transfer learning seeks to improve the efficiency of learning a new task via both meta-learning and transfer-learning. While the standard attention has been effective in a variety of settings, we question its effectiveness in improving meta-transfer learning since the tasks being learned are dynamic and the amount of context can be substantially smaller. In this paper, using a recently proposed meta-transfer learning model, Sequential Neural Processes (SNP), we first empirically show that it suffers from a similar underfitting problem observed in the functions inferred by Neural Processes. However, we further demonstrate that unlike the meta-learning setting, the standard attention mechanisms are not effective in meta-transfer setting. To resolve, we propose a new attention mechanism, Recurrent Memory Reconstruction (RMR), and demonstrate that providing an imaginary context that is recurrently updated and reconstructed with interaction is crucial in achieving effective attention for meta-transfer learning. Furthermore, incorporating RMR into SNP, we propose Attentive Sequential Neural Processes-RMR (ASNP-RMR) and demonstrate in various tasks that ASNP-RMR significantly outperforms the baselines.
Deep neural networks for natural language processing tasks are vulnerable to adversarial input perturbations. In this paper, we present a versatile language for programmatically specifying string transformations---e.g., insertions, deletions, substitutions, swaps, etc.---that are relevant to the task at hand. We then present an approach to adversarially training models that are robust to such user-defined string transformations. Our approach combines the advantages of search-based techniques for adversarial training with abstraction-based techniques. Specifically, we show how to decompose a set of user-defined string transformations into two component specifications, one that benefits from search and another from abstraction. We use our technique to train models on the AG and SST2 datasets and show that the resulting models are robust to combinations of user-defined transformations mimicking spelling mistakes and other meaning-preserving transformations.

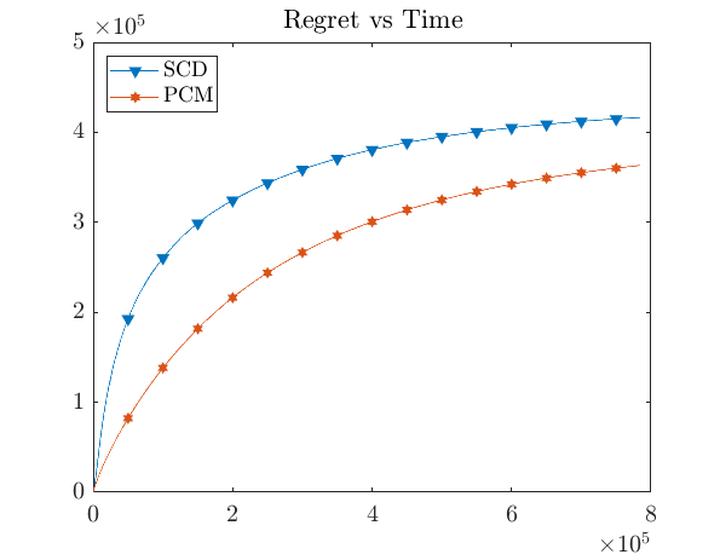
A framework based on iterative coordinate minimization (CM) is developed for stochastic convex optimization. Given that exact coordinate minimization is impossible due to the unknown stochastic nature of the objective function, the crux of the proposed optimization algorithm is an optimal control of the minimization precision in each iteration. We establish the optimal precision control and the resulting order-optimal regret performance for strongly convex and separably nonsmooth functions. An interesting finding is that the optimal progression of precision across iterations is independent of the low-dimension CM routine employed, suggesting a general framework for extending low-dimensional optimization routines to high-dimensional problems. The proposed algorithm is amenable to online implementation and inherits the scalability and parallelizability properties of CM for large-scale optimization. Requiring only a sublinear order of message exchanges, it also lends itself well to distributed computing as compared with the alternative approach of coordinate gradient descent.
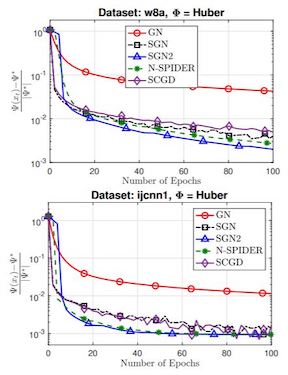

Although SGD with random reshuffle has been widely-used in machine learning applications, there is a limited understanding of how model characteristics affect the convergence of the algorithm. In this work, we introduce model incoherence to characterize the diversity of model characteristics and study its impact on convergence of SGD with random reshuffle \shaocong{under weak strong convexity}. Specifically, {\em minimizer incoherence} measures the discrepancy between the global minimizers of a sample loss and those of the total loss and affects the convergence error of SGD with random reshuffle. In particular, we show that the variable sequence generated by SGD with random reshuffle converges to a certain global minimizer of the total loss under full minimizer coherence. The other {\em curvature incoherence} measures the quality of condition numbers of the sample losses and determines the convergence rate of SGD. With model incoherence, our results show that SGD has a faster convergence rate and smaller convergence error under random reshuffle than those under random sampling, and hence provide justifications to the superior practical performance of SGD with random reshuffle.
[ Virtual ]
Standard reinforcement learning (RL) aims to find an optimal policy that identifies the best action for each state. However, in healthcare settings, many actions may be near-equivalent with respect to the reward (e.g., survival). We consider an alternative objective -- learning set-valued policies to capture near-equivalent actions that lead to similar cumulative rewards. We propose a model-free algorithm based on temporal difference learning and a near-greedy heuristic for action selection. We analyze the theoretical properties of the proposed algorithm, providing optimality guarantees and demonstrate our approach on simulated environments and a real clinical task. Empirically, the proposed algorithm exhibits good convergence properties and discovers meaningful near-equivalent actions. Our work provides theoretical, as well as practical, foundations for clinician/human-in-the-loop decision making, in which humans (e.g., clinicians, patients) can incorporate additional knowledge (e.g., side effects, patient preference) when selecting among near-equivalent actions.
[ Virtual ]

Delusional bias is a fundamental source of error in approximate Q-learning. To date, the only techniques that explicitly address delusion require comprehensive search using tabular value estimates. In this paper, we develop efficient methods to mitigate delusional bias by training Q-approximators with labels that are "consistent" with the underlying greedy policy class. We introduce a simple penalization scheme that encourages Q-labels used across training batches to remain (jointly) consistent with the expressible policy class. We also propose a search framework that allows multiple Q-approximators to be generated and tracked, thus mitigating the effect of premature (implicit) policy commitments. Experimental results demonstrate that these methods can improve the performance of Q-learning in a variety of Atari games, sometimes dramatically.
[ Virtual ]
Generative autoencoders offer a promising approach for controllable text generation by leveraging their learned sentence representations. However, current models struggle to maintain coherent latent spaces required to perform meaningful text manipulations via latent vector operations. Specifically, we demonstrate by example that neural encoders do not necessarily map similar sentences to nearby latent vectors. A theoretical explanation for this phenomenon establishes that high-capacity autoencoders can learn an arbitrary mapping between sequences and associated latent representations. To remedy this issue, we augment adversarial autoencoders with a denoising objective where original sentences are reconstructed from perturbed versions (referred to as DAAE). We prove that this simple modification guides the latent space geometry of the resulting model by encouraging the encoder to map similar texts to similar latent representations. In empirical comparisons with various types of autoencoders, our model provides the best trade-off between generation quality and reconstruction capacity. Moreover, the improved geometry of the DAAE latent space enables \textit{zero-shot} text style transfer via simple latent vector arithmetic.
[ Virtual ]
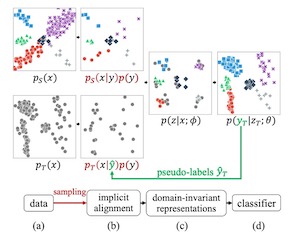
We present an approach for unsupervised domain adaptation—with a strong focus on practical considerations of within-domain class imbalance and between-domain class distribution shift—from a class-conditioned domain alignment perspective. Current methods for class-conditioned domain alignment aim to explicitly minimize a loss function based on pseudo-label estimations of the target domain. However, these methods suffer from pseudo-label bias in the form of error accumulation. We propose a method that removes the need for explicit optimization of model parameters from pseudo-labels. Instead, we present a sampling-based implicit alignment approach, where the sample selection is implicitly guided by the pseudo-labels. Theoretical analysis reveals the existence of a domain-discriminator shortcut in misaligned classes, which is addressed by the proposed approach to facilitate domain-adversarial learning. Empirical results and ablation studies confirm the effectiveness of the proposed approach, especially in the presence of within-domain class imbalance and between-domain class distribution shift.
[ Virtual ]

A trade-off between accuracy and fairness is almost taken as a given in the existing literature on fairness in machine learning. Yet, it is not preordained that accuracy should decrease with increased fairness. Novel to this work, we examine fair classification through the lens of mismatched hypothesis testing: trying to find a classifier that distinguishes between two ideal distributions when given two mismatched distributions that are biased. Using Chernoff information, a tool in information theory, we theoretically demonstrate that, contrary to popular belief, there always exist ideal distributions such that optimal fairness and accuracy (with respect to the ideal distributions) are achieved simultaneously: there is no trade-off. Moreover, the same classifier yields the lack of a trade-off with respect to ideal distributions while yielding a trade-off when accuracy is measured with respect to the given (possibly biased) dataset. To complement our main result, we formulate an optimization to find ideal distributions and derive fundamental limits to explain why a trade-off exists on the given biased dataset. We also derive conditions under which active data collection can alleviate the fairness-accuracy trade-off in the real world. Our results lead us to contend that it is problematic to measure accuracy with respect to …
[ Virtual ]
Drug discovery aims to find novel compounds with specified chemical property profiles. In terms of generative modeling, the goal is to learn to sample molecules in the intersection of multiple property constraints. This task becomes increasingly challenging when there are many property constraints. We propose to offset this complexity by composing molecules from a vocabulary of substructures that we call molecular rationales. These rationales are identified from molecules as substructures that are likely responsible for each property of interest. We then learn to expand rationales into a full molecule using graph generative models. Our final generative model composes molecules as mixtures of multiple rationale completions, and this mixture is fine-tuned to preserve the properties of interest. We evaluate our model on various drug design tasks and demonstrate significant improvements over state-of-the-art baselines in terms of accuracy, diversity, and novelty of generated compounds.
[ Virtual ]
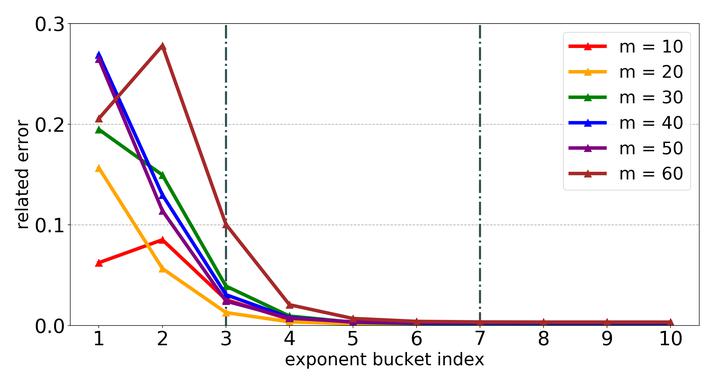
Efficient construction of checkpoints/snapshots is a critical tool for training and diagnosing deep learning models. In this paper, we propose a lossy compression scheme for checkpoint constructions (called LC-Checkpoint). LC-Checkpoint simultaneously maximizes the compression rate and optimizes the recovery speed, under the assumption that SGD is used to train the model. LC-Checkpoint uses quantization and priority promotion to store the most crucial information for SGD to recover, and then uses a Huffman coding to leverage the non-uniform distribution of the gradient scales. Our extensive experiments show that LC-Checkpoint achieves a compression rate up to 28× and recovery speedup up to 5.77× over a state-of-the-art algorithm (SCAR).
[ Virtual ]
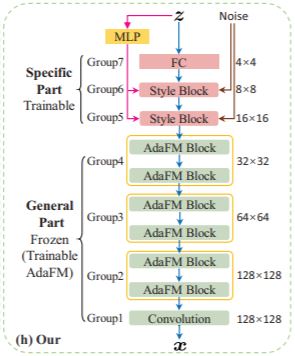
Recent work has shown generative adversarial networks (GANs) can generate highly realistic images, that are often indistinguishable (by humans) from real images. Most images so generated are not contained in the training dataset, suggesting potential for augmenting training sets with GAN-generated data. While this scenario is of particular relevance when there are limited data available, there is still the issue of training the GAN itself based on that limited data. To facilitate this, we leverage existing GAN models pretrained on large-scale datasets (like ImageNet) to introduce additional knowledge (which may not exist within the limited data), following the concept of transfer learning. Demonstrated by natural-image generation, we reveal that low-level filters (those close to observations) of both the generator and discriminator of pretrained GANs can be transferred to facilitate generation in a perceptually-distinct target domain with limited training data. To further adapt the transferred filters to the target domain, we propose adaptive filter modulation (AdaFM). An extensive set of experiments is presented to demonstrate the effectiveness of the proposed techniques on generation with limited data.
[ Virtual ]

We propose a new framework, called Poisson learning, for graph based semi-supervised learning at very low label rates. Poisson learning is motivated by the need to address the degeneracy of Laplacian semi-supervised learning in this regime. The method replaces the assignment of label values at training points with the placement of sources and sinks, and solves the resulting Poisson equation on the graph. The outcomes are provably more stable and informative than those of Laplacian learning. Poisson learning is efficient and simple to implement, and we present numerical experiments showing the method is superior to other recent approaches to semi-supervised learning at low label rates on MNIST, FashionMNIST, and Cifar-10. We also propose a graph-cut enhancement of Poisson learning, called Poisson MBO, that gives higher accuracy and can incorporate prior knowledge of relative class sizes.
[ Virtual ]
In this paper, we propose a bootstrap method applied to massive data processed distributedly in a large number of machines. This new method is computationally efficient in that we bootstrap on the master machine without over-resampling, typically required by existing methods \cite{kleiner2014scalable,sengupta2016subsampled}, while provably achieving optimal statistical efficiency with minimal communication. Our method does not require repeatedly re-fitting the model but only applies multiplier bootstrap in the master machine on the gradients received from the worker machines. Simulations validate our theory.
[ Virtual ]

We develop a novel variant of the classical Frank-Wolfe algorithm, which we call spectral Frank-Wolfe, for convex optimization over a spectrahedron. The spectral Frank-Wolfe algorithm has a novel ingredient: it computes a few eigenvectors of the gradient and solves a small-scale subproblem in each iteration. Such a procedure overcomes the slow convergence of the classical Frank-Wolfe algorithm due to ignoring eigenvalue coalescence. We demonstrate that strict complementarity of the optimization problem is key to proving linear convergence of various algorithms, such as the spectral Frank-Wolfe algorithm as well as the projected gradient method and its accelerated version. We showcase that the strict complementarity is equivalent to the eigengap assumption on the gradient at the optimal solution considered in the literature. As a byproduct of this observation, we also develop a generalized block Frank-Wolfe algorithm and prove its linear convergence.
[ Virtual ]
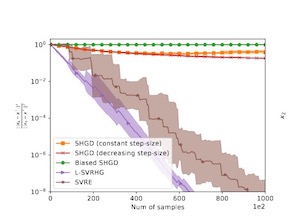
The success of adversarial formulations in machine learning has brought renewed motivation for smooth games. In this work, we focus on the class of stochastic Hamiltonian methods and provide the first convergence guarantees for certain classes of stochastic smooth games. We propose a novel unbiased estimator for the stochastic Hamiltonian gradient descent (SHGD) and highlight its benefits. Using tools from the optimization literature we show that SHGD converges linearly to the neighbourhood of a stationary point. To guarantee convergence to the exact solution, we analyze SHGD with a decreasing step-size and we also present the first stochastic variance reduced Hamiltonian method. Our results provide the first global non-asymptotic last-iterate convergence guarantees for the class of stochastic unconstrained bilinear games and for the more general class of stochastic games that satisfy a ``sufficiently bilinear" condition, notably including some non-convex non-concave problems. We supplement our analysis with experiments on stochastic bilinear and sufficiently bilinear games, where our theory is shown to be tight, and on simple adversarial machine learning formulations.
[ Virtual ]
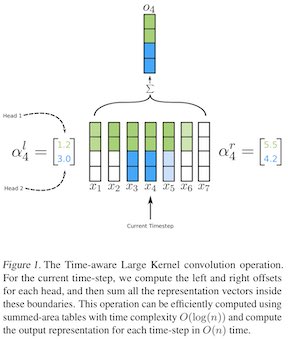


It is well-known that many machine learning models are susceptible to adversarial attacks, in which an attacker evades a classifier by making small perturbations to inputs. This paper discusses how industrial copyright detection tools, which serve a central role on the web, are susceptible to adversarial attacks. As proof of concept, we describe a well-known music identification method and implement this system in the form of a neural net. We then attack this system using simple gradient methods and show that it is easily broken with white-box attacks. By scaling these perturbations up, we can create transfer attacks on industrial systems, such as the AudioTag copyright detector and YouTube's Content ID system, using perturbations that are audible but significantly smaller than a random baseline. Our goal is to raise awareness of the threats posed by adversarial examples in this space and to highlight the importance of hardening copyright detection systems to attacks.
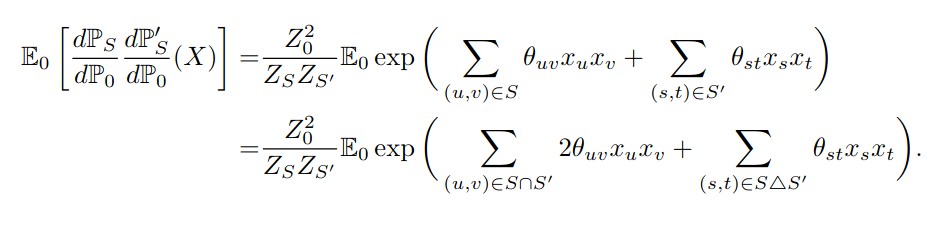
We study the computational and statistical tradeoffs in inferring combinatorial structures of high dimensional simple zero-field ferromagnetic Ising model. Under the framework of oracle computational model where an algorithm interacts with an oracle that discourses a randomized version of truth, we characterize the computational lower bounds of learning combinatorial structures in polynomial time, under which no algorithms within polynomial-time can distinguish between graphs with and without certain structures. This hardness of learning with limited computational budget is shown to be characterized by a novel quantity called vertex overlap ratio. Such quantity is universally valid for many specific graph structures including cliques and nearest neighbors. On the other side, we attain the optimal rates for testing these structures against empty graph by proposing the quadratic testing statistics to match the lower bounds. We also investigate the relationship between computational bounds and information-theoretic bounds for such problems, and found gaps between the two boundaries in inferring some particular structures, especially for those with dense edges.
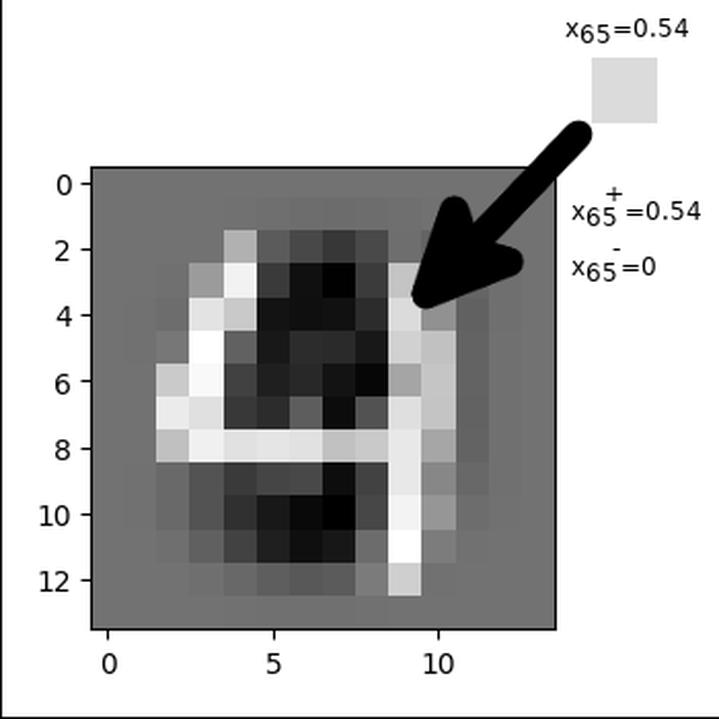
Embedding computation in molecular contexts incompatible with traditional electronics is expected to have wide ranging impact in synthetic biology, medicine, nanofabrication and other fields. A key remaining challenge lies in developing programming paradigms for molecular computation that are well-aligned with the underlying chemical hardware and do not attempt to shoehorn ill-fitting electronics paradigms. We discover a surprisingly tight connection between a popular class of neural networks (binary-weight ReLU aka BinaryConnect) and a class of coupled chemical reactions that are absolutely robust to reaction rates. The robustness of rate-independent chemical computation makes it a promising target for bioengineering implementation. We show how a BinaryConnect neural network trained in silico using well-founded deep learning optimization techniques, can be compiled to an equivalent chemical reaction network, providing a novel molecular programming paradigm. We illustrate such translation on the paradigmatic IRIS and MNIST datasets. Toward intended applications of chemical computation, we further use our method to generate a chemical reaction network that can discriminate between different virus types based on gene expression levels. Our work sets the stage for rich knowledge transfer between neural network and molecular programming communities.

Differentiable renderers have been used successfully for unsupervised 3D structure learning from 2D images because they can bridge the gap between 3D and 2D. To optimize 3D shape parameters, current renderers rely on pixel-wise losses between rendered images of 3D reconstructions and ground truth images from corresponding viewpoints. Hence they require interpolation of the recovered 3D structure at each pixel, visibility handling, and optionally evaluating a shading model. In contrast, here we propose a Differentiable Renderer Without Rendering (DRWR) that omits these steps. DRWR only relies on a simple but effective loss that evaluates how well the projections of reconstructed 3D point clouds cover the ground truth object silhouette. Specifically, DRWR employs a smooth silhouette loss to pull the projection of each individual 3D point inside the object silhouette, and a structure-aware repulsion loss to push each pair of projections that fall inside the silhouette far away from each other. Although we omit surface interpolation, visibility handling, and shading, our results demonstrate that DRWR achieves state-of-the-art accuracies under widely used benchmarks, outperforming previous methods both qualitatively and quantitatively. In addition, our training times are significantly lower due to the simplicity of DRWR.
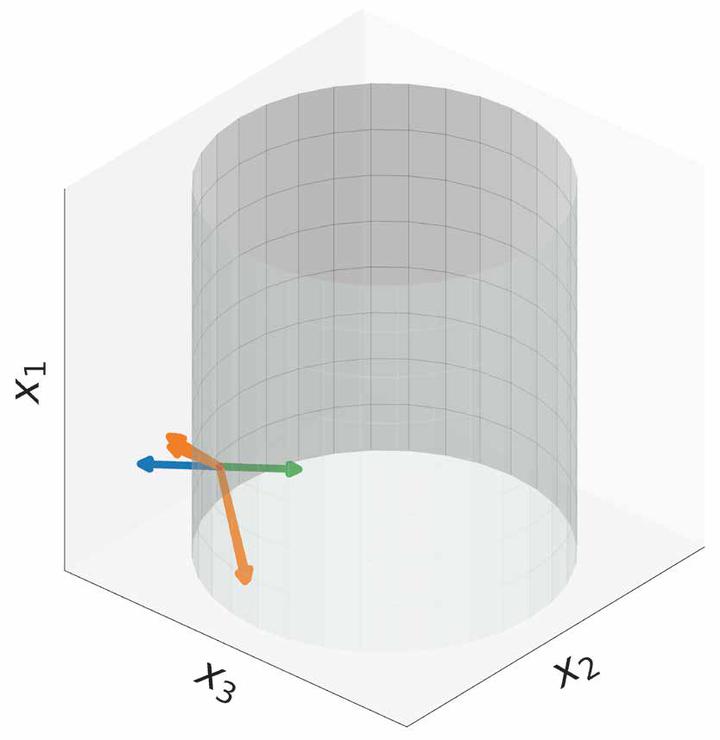
Tasks in multi-task learning often correlate, conflict, or even compete with each other. As a result, a single solution that is optimal for all tasks rarely exists. Recent papers introduced the concept of Pareto optimality to this field and directly cast multi-task learning as multi-objective optimization problems, but solutions returned by existing methods are typically finite, sparse, and discrete. We present a novel, efficient method that generates locally continuous Pareto sets and Pareto fronts, which opens up the possibility of continuous analysis of Pareto optimal solutions in machine learning problems. We scale up theoretical results in multi-objective optimization to modern machine learning problems by proposing a sample-based sparse linear system, for which standard Hessian-free solvers in machine learning can be applied. We compare our method to the state-of-the-art algorithms and demonstrate its usage of analyzing local Pareto sets on various multi-task classification and regression problems. The experimental results confirm that our algorithm reveals the primary directions in local Pareto sets for trade-off balancing, finds more solutions with different trade-offs efficiently, and scales well to tasks with millions of parameters.

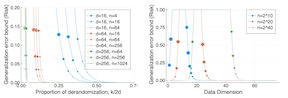
We propose to study the generalization error of a learned predictor h^ in terms of that of a surrogate (potentially randomized) classifier that is coupled to h^ and designed to trade empirical risk for control of generalization error. In the case where h^ interpolates the data, it is interesting to consider theoretical surrogate classifiers that are partially derandomized or rerandomized, e.g., fit to the training data but with modified label noise. We show that replacing h^ by its conditional distribution with respect to an arbitrary sigma-field is a viable method to derandomize. We give an example, inspired by the work of Nagarajan and Kolter (2019), where the learned classifier h^ interpolates the training data with high probability, has small risk, and, yet, does not belong to a nonrandom class with a tight uniform bound on two-sided generalization error. At the same time, we bound the risk of h^ in terms of a surrogate that is constructed by conditioning and shown to belong to a nonrandom class with uniformly small generalization error.

Learned dynamics models combined with both planning and policy learning algorithms have shown promise in enabling artificial agents to learn to perform many diverse tasks with limited supervision. However, one of the fundamental challenges in using a learned forward dynamics model is the mismatch between the objective of the learned model (future state reconstruction), and that of the downstream planner or policy (completing a specified task). This issue is exacerbated by vision-based control tasks in diverse real-world environments, where the complexity of the real world dwarfs model capacity. In this paper, we propose to direct prediction towards task relevant information, enabling the model to be aware of the current task and encouraging it to only model relevant quantities of the state space, resulting in a learning objective that more closely matches the downstream task. Further, we do so in an entirely self-supervised manner, without the need for a reward function or image labels. We find that our method more effectively models the relevant parts of the scene conditioned on the goal, and as a result outperforms standard task-agnostic dynamics models and model-free reinforcement learning.
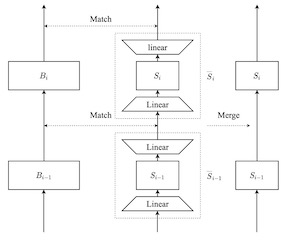
For deploying a deep learning model into production, it needs to be both accurate and compact to meet the latency and memory constraints. This usually results in a network that is deep (to ensure performance) and yet thin (to improve computational efficiency). In this paper, we propose an efficient method to train a deep thin network with a theoretic guarantee. Our method is motivated by model compression. It consists of three stages. In the first stage, we sufficiently widen the deep thin network and train it until convergence. In the second stage, we use this well-trained deep wide network to warm up (or initialize) the original deep thin network. This is achieved by letting the thin network imitate the immediate outputs of the wide network from layer to layer. In the last stage, we further fine tune this well initialized deep thin network. The theoretical guarantee is established by using mean field analysis. It shows the advantage of layerwise imitation over traditional training deep thin networks from scratch by backpropagation. We also conduct large-scale empirical experiments to validate our approach. By training with our method, ResNet50 can outperform ResNet101, and BERTBASE can be comparable with BERTLARGE, where both …
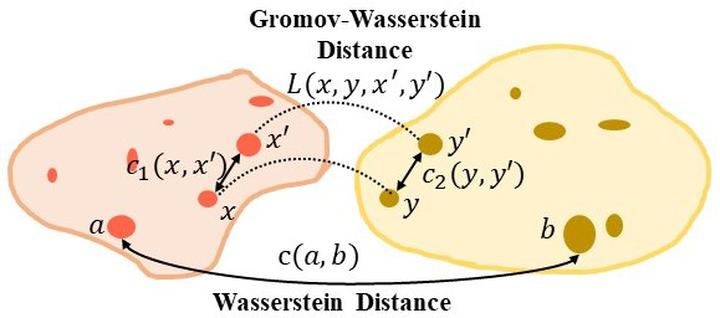
Cross-domain alignment between two sets of entities (e.g., objects in an image, words in a sentence) is fundamental to both computer vision and natural language processing. Existing methods mainly focus on designing advanced attention mechanisms to simulate soft alignment, where no training signals are provided to explicitly encourage alignment. Plus, the learned attention matrices are often dense and difficult to interpret. We propose Graph Optimal Transport (GOT), a principled framework that builds upon recent advances in Optimal Transport (OT). In GOT, cross-domain alignment is formulated as a graph matching problem, by representing entities as a dynamically-constructed graph. Two types of OT distances are considered: (i) Wasserstein distance (WD) for node (entity) matching; and (ii) Gromov-Wasserstein distance (GWD) for edge (structure) matching. Both WD and GWD can be incorporated into existing neural network models, effectively acting as a drop-in regularizer.
The inferred transport plan also yields sparse and self-normalized alignment, enhancing the interpretability of the learned model. Experiments show consistent outperformance of GOT over baselines across a wide range of tasks, including image-text retrieval, visual question answering, image captioning, machine translation, and text summarization.


We propose learning discrete structured representations from unlabeled data by maximizing the mutual information between a structured latent variable and a target variable. Calculating mutual information is intractable in this setting. Our key technical contribution is an adversarial objective that can be used to tractably estimate mutual information assuming only the feasibility of cross entropy calculation. We develop a concrete realization of this general formulation with Markov distributions over binary encodings. We report critical and unexpected findings on practical aspects of the objective such as the choice of variational priors. We apply our model on document hashing and show that it outperforms current best baselines based on discrete and vector quantized variational autoencoders. It also yields highly compressed interpretable representations.

We study online learning settings in which experts act strategically to maximize their influence on the learning algorithm's predictions by potentially misreporting their beliefs about a sequence of binary events. Our goal is twofold. First, we want the learning algorithm to be no-regret with respect to the best fixed expert in hindsight. Second, we want incentive compatibility, a guarantee that each expert's best strategy is to report his true beliefs about the realization of each event. To achieve this goal, we build on the literature on wagering mechanisms, a type of multi-agent scoring rule. We provide algorithms that achieve no regret and incentive compatibility for myopic experts for both the full and partial information settings. In experiments on datasets from FiveThirtyEight, our algorithms have regret comparable to classic no-regret algorithms, which are not incentive-compatible. Finally, we identify an incentive-compatible algorithm for forward-looking strategic agents that exhibits diminishing regret in practice.
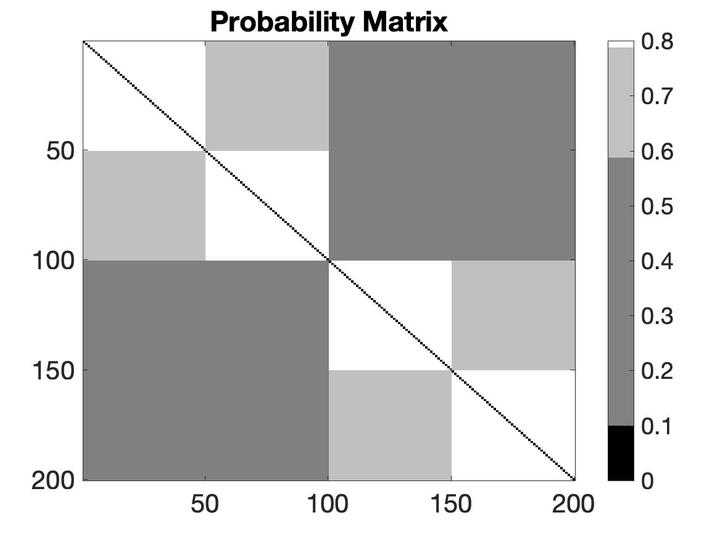
Tuning hyperparameters for unsupervised learning problems is difficult in general due to the lack of ground truth for validation. However, the success of most clustering methods depends heavily on the correct choice of the involved hyperparameters. Take for example the Lagrange multipliers of penalty terms in semidefinite programming (SDP) relaxations of community detection in networks, or the bandwidth parameter needed in the Gaussian kernel used to construct similarity matrices for spectral clustering. Despite the popularity of these clustering algorithms, there are not many provable methods for tuning these hyperparameters. In this paper, we provide an overarching framework with provable guarantees for tuning hyperparameters in the above class of problems under two different models. Our framework can be augmented with a cross validation procedure to do model selection as well. In a variety of simulation and real data experiments, we show that our framework outperforms other widely used tuning procedures in a broad range of parameter settings.

We introduce and study the problem of Online Continual Compression, where one attempts to simultaneously learn to compress and store a representative dataset from a non i.i.d data stream, while only observing each sample once. A naive application of auto-encoder in this setting encounters a major challenge: representations derived from earlier encoder states must be usable by later decoder states. We show how to use discrete auto-encoders to effectively address this challenge and introduce Adaptive Quantization Modules (AQM) to control variation in the compression ability of the module at any given stage of learning. This enables selecting an appropriate compression for incoming samples, while taking into account overall memory constraints and current progress of the learned compression. Unlike previous methods, our approach does not require any pretraining, even on challenging datasets. We show that using AQM to replace standard episodic memory in continual learning settings leads to significant gains on continual learning benchmarks with images, LiDAR, and reinforcement learning agents.


Black-box variational inference tries to approximate a complex target distribution through a gradient-based optimization of the parameters of a simpler distribution. Provable convergence guarantees require structural properties of the objective. This paper shows that for location-scale family approximations, if the target is M-Lipschitz smooth, then so is the “energy” part of the variational objective. The key proof idea is to describe gradients in a certain inner-product space, thus permitting the use of Bessel’s inequality. This result gives bounds on the location of the optimal parameters, and is a key ingredient for convergence guarantees.

Stochastic optimization algorithms have become indispensable in modern machine learning. An unresolved foundational question in this area is the difference between with-replacement sampling and without-replacement sampling — does the latter have superior convergence rate compared to the former? A groundbreaking result of Recht and Re reduces the problem to a noncommutative analogue of the arithmetic-geometric mean inequality where n positive numbers are replaced by n positive definite matrices. If this inequality holds for all n, then without-replacement sampling indeed outperforms with-replacement sampling in some important optimization problems. The conjectured Recht–Re inequality has so far only been established for n = 2 and a special case of n = 3. We will show that the Recht–Re conjecture is false for general n. Our approach relies on the noncommutative Positivstellensatz, which allows us to reduce the conjectured inequality to a semidefinite program and the validity of the conjecture to certain bounds for the optimum values, which we show are false as soon as n = 5.

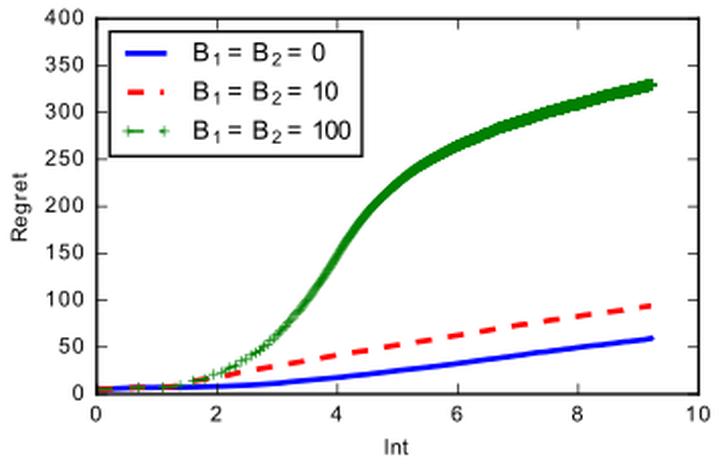
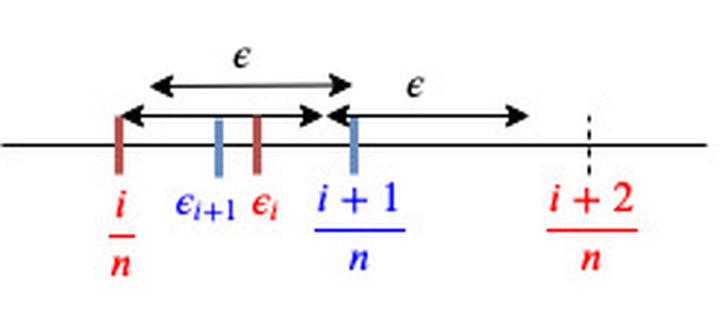
The decision-theoretic foundations of classical machine learning models have largely focused on estimating model parameters that minimize the expectation of a given loss function. However, as machine learning models are deployed in varied contexts, such as in high-stakes decision-making and societal settings, it is clear that these models are not just evaluated by their average performances. In this work, we study a novel notion of L-Risk based on the classical idea of rank-weighted learning. These L-Risks, induced by rank-dependent weighting functions with bounded variation, is a unification of popular risk measures such as conditional value-at-risk and those defined by cumulative prospect theory. We give uniform convergence bounds of this broad class of risk measures and study their consequences on a logistic regression example.
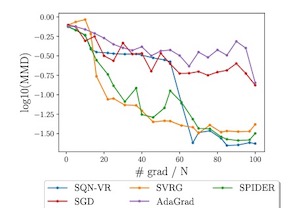
Particle-based Variational Inference methods (ParVIs), like Stein Variational Gradient Descent, are nonparametric variational inference methods that optimize a set of particles to best approximate a target distribution. ParVIs have been proposed as efficient approximate inference algorithms and as potential alternatives to MCMC methods. However, to our knowledge, the quality of the posterior approximation of particles from ParVIs has not been examined before for large-scale Bayesian inference problems. We conduct this analysis and evaluate the sample quality of particles produced by ParVIs, and we find that existing ParVI approaches using stochastic gradients converge insufficiently fast under sample quality metrics. We propose a novel variance reduction and quasi-Newton preconditioning framework for ParVIs, by leveraging the Riemannian structure of the Wasserstein space and advanced Riemannian optimization algorithms. Experimental results demonstrate the accelerated convergence of variance reduction and quasi-Newton methods for ParVIs for accurate posterior inference in large-scale and ill-conditioned problems.
[ Virtual ]
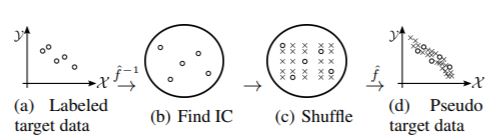
We study few-shot supervised domain adaptation (DA) for regression problems, where only a few labeled target domain data and many labeled source domain data are available. Many of the current DA methods base their transfer assumptions on either parametrized distribution shift or apparent distribution similarities, e.g., identical conditionals or small distributional discrepancies. However, these assumptions may preclude the possibility of adaptation from intricately shifted and apparently very different distributions. To overcome this problem, we propose mechanism transfer, a meta-distributional scenario in which a data generating mechanism is invariant among domains. This transfer assumption can accommodate nonparametric shifts resulting in apparently different distributions while providing a solid statistical basis for DA. We take the structural equations in causal modeling as an example and propose a novel DA method, which is shown to be useful both theoretically and experimentally. Our method can be seen as the first attempt to fully leverage the invariance of structural causal models for DA.
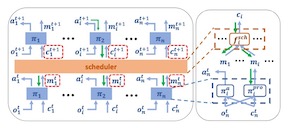
We consider the problem of the limited-bandwidth communication for multi-agent reinforcement learning, where agents cooperate with the assistance of a communication protocol and a scheduler. The protocol and scheduler jointly determine which agent is communicating what message and to whom. Under the limited bandwidth constraint, a communication protocol is required to generate informative messages. Meanwhile, an unnecessary communication connection should not be established because it occupies limited resources in vain. In this paper, we develop an Informative Multi-Agent Communication (IMAC) method to learn efficient communication protocols as well as scheduling. First, from the perspective of communication theory, we prove that the limited bandwidth constraint requires low-entropy messages throughout the transmission. Then inspired by the information bottleneck principle, we learn a valuable and compact communication protocol and a weight-based scheduler. To demonstrate the efficiency of our method, we conduct extensive experiments in various cooperative and competitive multi-agent tasks with different numbers of agents and different bandwidths. We show that IMAC converges faster and leads to efficient communication among agents under the limited bandwidth as compared to many baseline methods.
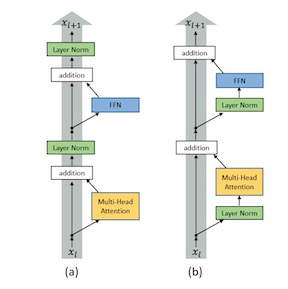
The Transformer is widely used in natural language processing tasks. To train a Transformer however, one usually needs a carefully designed learning rate warm-up stage, which is shown to be crucial to the final performance but will slow down the optimization and bring more hyper-parameter tunings. In this paper, we first study theoretically why the learning rate warm-up stage is essential and show that the location of layer normalization matters. Specifically, we prove with mean field theory that at initialization, for the original-designed Post-LN Transformer, which places the layer normalization between the residual blocks, the expected gradients of the parameters near the output layer are large. Therefore, using a large learning rate on those gradients makes the training unstable. The warm-up stage is practically helpful for avoiding this problem. On the other hand, our theory also shows that if the layer normalization is put inside the residual blocks (recently proposed as Pre-LN Transformer), the gradients are well-behaved at initialization. This motivates us to remove the warm-up stage for the training of Pre-LN Transformers. We show in our experiments that Pre-LN Transformers without the warm-up stage can reach comparable results with baselines while requiring significantly less training time and hyper-parameter tuning …
Many real-world applications have to tackle the Positive-Unlabeled (PU) learning problem, i.e., learning binary classifiers from a large amount of unlabeled data and a few labeled positive examples. While current state-of-the-art methods employ importance reweighting to design various biased or unbiased risk estimators, they completely ignored the learning capability of the model itself, which could provide reliable supervision. This motivates us to propose a novel Self-PU learning framework, which seamlessly integrates PU learning and self-training. Self-PU highlights three ``self''-oriented building blocks: a self-paced training algorithm that adaptively discovers and augments confident positive/negative examples as the training proceeds; a self-reweighted, instance-aware loss; and a self-distillation scheme that introduces teacher-students learning as an effective regularization for PU learning. We demonstrate the state-of-the-art performance of Self-PU on common PU learning benchmarks (MNIST and CIFAR10), which compare favorably against the latest competitors. Moreover, we study a real-world application of PU learning, i.e., classifying brain images of Alzheimer's Disease. Self-PU obtains significantly improved results on the renowned Alzheimer's Disease Neuroimaging Initiative (ADNI) database over existing methods.
Poster Session 51 Fri 17 Jul 04:00 a.m.
[ Virtual ]
Lying at the core of human intelligence, relational thinking is characterized by initially relying on innumerable unconscious percepts pertaining to relations between new sensory signals and prior knowledge, consequently becoming a recognizable concept or object through coupling and transformation of these percepts. Such mental processes are difficult to model in real-world problems such as in conversational automatic speech recognition (ASR), as the percepts (if they are modelled as graphs indicating relationships among utterances) are supposed to be innumerable and not directly observable. In this paper, we present a Bayesian nonparametric deep learning method called deep graph random process (DGP) that can generate an infinite number of probabilistic graphs representing percepts. We further provide a closed-form solution for coupling and transformation of these percept graphs for acoustic modeling. Our approach is able to successfully infer relations among utterances without using any relational data during training. Experimental evaluations on ASR tasks including CHiME-2 and CHiME-5 demonstrate the effectiveness and benefits of our method.
[ Virtual ]
Temporal difference (TD) learning is one of the main foundations of modern reinforcement learning. This paper studies the use of TD(0), a canonical TD algorithm, to estimate the value function of a given policy from a batch of data. In this batch setting, we show that TD(0) may converge to an inaccurate value function because the update following an action is weighted according to the number of times that action occurred in the batch -- not the true probability of the action under the given policy. To address this limitation, we introduce \textit{policy sampling error corrected}-TD(0) (PSEC-TD(0)). PSEC-TD(0) first estimates the empirical distribution of actions in each state in the batch and then uses importance sampling to correct for the mismatch between the empirical weighting and the correct weighting for updates following each action. We refine the concept of a certainty-equivalence estimate and argue that PSEC-TD(0) is a more data efficient estimator than TD(0) for a fixed batch of data. Finally, we conduct an empirical evaluation of PSEC-TD(0) on three batch value function learning tasks, with a hyperparameter sensitivity analysis, and show that PSEC-TD(0) produces value function estimates with lower mean squared error than TD(0).
[ Virtual ]
Network quantization is essential for deploying deep models to IoT devices due to its high efficiency. Most existing quantization approaches rely on the full training datasets and the time-consuming fine-tuning to retain accuracy. Post-training quantization does not have these problems, however, it has mainly been shown effective for 8-bit quantization due to the simple optimization strategy. In this paper, we propose a Bit-Split and Stitching framework (Bit-split) for lower-bit post-training quantization with minimal accuracy degradation. The proposed framework is validated on a variety of computer vision tasks, including image classification, object detection, instance segmentation, with various network architectures. Specifically, Bit-split can achieve near-original model performance even when quantizing FP32 models to INT3 without fine-tuning.
[ Virtual ]
Polyak momentum (PM), also known as the heavy-ball method, is a widely used optimization method that enjoys an asymptotic optimal worst-case complexity on quadratic objectives. However, its remarkable empirical success is not fully explained by this optimality, as the worst-case analysis --contrary to the average-case-- is not representative of the expected complexity of an algorithm. In this work we establish a novel link between PM and the average-case analysis. Our main contribution is to prove that \emph{any} optimal average-case method converges in the number of iterations to PM, under mild assumptions. This brings a new perspective on this classical method, showing that PM is asymptotically both worst-case and average-case optimal.
The LSTM network was proposed to overcome the difficulty in learning long-term dependence, and has made significant advancements in applications. With its success and drawbacks in mind, this paper raises the question -do RNN and LSTM have long memory? We answer it partially by proving that RNN and LSTM do not have long memory from a statistical perspective. A new definition for long memory networks is further introduced, and it requires the model weights to decay at a polynomial rate. To verify our theory, we convert RNN and LSTM into long memory networks by making a minimal modification, and their superiority is illustrated in modeling longterm dependence of various datasets.

Survival Analysis and Reliability Theory are concerned with the analysis of time-to-event data, in which observations correspond to waiting times until an event of interest, such as death from a particular disease or failure of a component in a mechanical system. This type of data is unique due to the presence of censoring, a type of missing data that occurs when we do not observe the actual time of the event of interest but instead we have access to an approximation for it given by random interval in which the observation is known to belong.
Most traditional methods are not designed to deal with censoring, and thus we need to adapt them to censored time-to-event data. In this paper, we focus on non-parametric Goodness-of-Fit testing procedures based on combining the Stein's method and kernelized discrepancies. While for uncensored data, there is a natural way of implementing a kernelized Stein discrepancy test, for censored data there are several options, each of them with different advantages and disadvantages. In this paper we propose a collection of kernelized Stein discrepancy tests for time-to-event data, and we study each of them theoretically and empirically. Our experimental results show that our proposed methods perform better …
Retrieving relevant targets from an extremely large target set under computational limits is a common challenge for information retrieval and recommendation systems. Tree models, which formulate targets as leaves of a tree with trainable node-wise scorers, have attracted a lot of interests in tackling this challenge due to their logarithmic computational complexity in both training and testing. Tree-based deep models (TDMs) and probabilistic label trees (PLTs) are two representative kinds of them. Though achieving many practical successes, existing tree models suffer from the training-testing discrepancy, where the retrieval performance deterioration caused by beam search in testing is not considered in training. This leads to an intrinsic gap between the most relevant targets and those retrieved by beam search with even the optimally trained node-wise scorers. We take a first step towards understanding and analyzing this problem theoretically, and develop the concept of Bayes optimality under beam search and calibration under beam search as general analyzing tools for this purpose. Moreover, to eliminate the discrepancy, we propose a novel algorithm for learning optimal tree models under beam search. Experiments on both synthetic and real data verify the rationality of our theoretical analysis and demonstrate the superiority of our algorithm compared to …

Deep neural networks have been proven to be vulnerable to the so-called adversarial attacks. Recently there have been efforts to defend such attacks with deep generative models. These defense often predict by inverting the deep generative models rather than simple feedforward propagation. Such defenses are difficult to attack due to obfuscated gradient. In this work, we develop a new gradient approximation attack to break these defenses. The idea is to view the inversion phase as a dynamical system, through which we extract the gradient w.r.t the input by tracing its recent trajectory. An amortized strategy is further developed to accelerate the attack. Experiments show that our attack breaks state-of-the-art defenses (e.g DefenseGAN, ABS) much more effectively than other attacks. Additionally, our empirical results provide insights for understanding the weaknesses of deep generative model-based defenses.
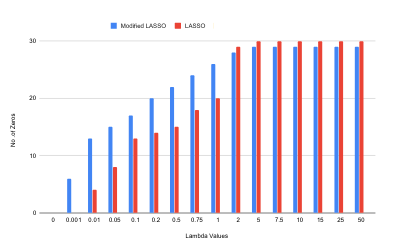
When predictions support decisions they may influence the outcome they aim to predict. We call such predictions performative; the prediction influences the target. Performativity is a well-studied phenomenon in policy-making that has so far been neglected in supervised learning. When ignored, performativity surfaces as undesirable distribution shift, routinely addressed with retraining. We develop a risk minimization framework for performative prediction bringing together concepts from statistics, game theory, and causality. A conceptual novelty is an equilibrium notion we call performative stability. Performative stability implies that the predictions are calibrated not against past outcomes, but against the future outcomes that manifest from acting on the prediction. Our main results are necessary and sufficient conditions for the convergence of retraining to a performatively stable point of nearly minimal loss. In full generality, performative prediction strictly subsumes the setting known as strategic classification. We thus also give the first sufficient conditions for retraining to overcome strategic feedback effects.

The high sample complexity of reinforcement learning challenges its use in practice. A promising approach is to quickly adapt pre-trained policies to new environments. Existing methods for this policy adaptation problem typically rely on domain randomization and meta-learning, by sampling from some distribution of target environments during pre-training, and thus face difficulty on out-of-distribution target environments. We propose new model-based mechanisms that are able to make online adaptation in unseen target environments, by combining ideas from no-regret online learning and adaptive control. We prove that the approach learns policies in the target environment that can quickly recover trajectories from the source environment, and establish the rate of convergence in general settings. We demonstrate the benefits of our approach for policy adaptation in a diverse set of continuous control tasks, achieving the performance of state-of-the-art methods with much lower sample complexity. Our project website, including code, can be found at https://yudasong.github.io/PADA.
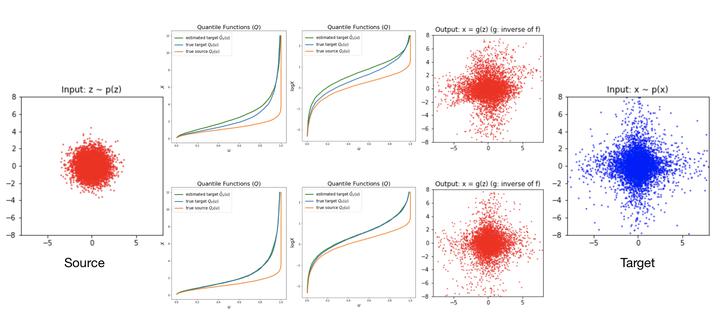
We investigate the ability of popular flow models to capture tail-properties of a target density by studying the increasing triangular maps used in these flow methods acting on a tractable source density. We show that the density quantile functions of the source and target density provide a precise characterization of the slope of transformation required to capture tails in a target density. We further show that any Lipschitz-continuous transport map acting on a source density will result in a density with similar tail properties as the source, highlighting the trade-off between the importance of choosing a complex source density and a sufficiently expressive transformation to capture desirable properties of a target density. Subsequently, we illustrate that flow models like Real-NVP, MAF, and Glow as implemented lack the ability to capture a distribution with non-Gaussian tails. We circumvent this problem by proposing tail-adaptive flows consisting of a source distribution that can be learned simultaneously with the triangular map to capture tail-properties of a target density. We perform several synthetic and real-world experiments to complement our theoretical findings.

Recent advancements in Generative Adversarial Networks (GANs) enable the generation of highly realistic images, raising concerns about their misuse for malicious purposes. Detecting these GAN-generated images (GAN-images) becomes increasingly challenging due to the significant reduction of underlying artifacts and specific patterns. The absence of such traces can hinder detection algorithms from identifying GAN-images and transferring knowledge to identify other types of GAN-images as well. In this work, we present the Transferable GAN-images Detection framework T-GD, a robust transferable framework for an effective detection of GAN-images. T-GD is composed of a teacher and a student model that can iteratively teach and evaluate each other to improve the detection performance. First, we train the teacher model on the source dataset and use it as a starting point for learning the target dataset. To train the student model, we inject noise by mixing up the source and target datasets, while constraining the weight variation to preserve the starting point. Our approach is a self-training method, but distinguishes itself from prior approaches by focusing on improving the transferability of GAN-image detection. T-GD achieves high performance on the source dataset by overcoming catastrophic forgetting and effectively detecting state-of-the-art GAN-images with only a small volume of …

[ Virtual ]
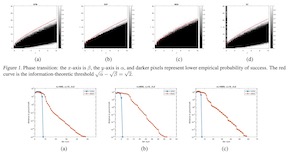
[ Virtual ]

Model fusion is an emerging study in collective learning where heterogeneous experts with private data and learning architectures need to combine their black-box knowledge for better performance. Existing literature achieves this via a local knowledge distillation scheme that transfuses the predictive patterns of each pre-trained expert onto a white-box imitator model, which can be incorporated efficiently into a global model. This scheme however does not extend to multi-task scenarios where different experts were trained to solve different tasks and only part of their distilled knowledge is relevant to a new task. To address this multi-task challenge, we develop a new fusion paradigm that represents each expert as a distribution over a spectrum of predictive prototypes, which are isolated from task-specific information encoded within the prototype distribution. The task-agnostic prototypes can then be reintegrated to generate a new model that solves a new task encoded with a different prototype distribution. The fusion and adaptation performance of the proposed framework is demonstrated empirically on several real-world benchmark datasets.
[ Virtual ]

This paper studies model-based reinforcement learning (RL) for regret minimization. We focus on finite-horizon episodic RL where the transition model P belongs to a known family of models, a special case of which is when models in the model class take the form of linear mixtures. We propose a model based RL algorithm that is based on the optimism principle: In each episode, the set of models that are `consistent' with the data collected is constructed. The criterion of consistency is based on the total squared error that the model incurs on the task of predicting state values as determined by the last value estimate along the transitions. The next value function is then chosen by solving the optimistic planning problem with the constructed set of models. We derive a bound on the regret, which, in the special case of linear mixtures, takes the form O(d (H^3 T)^(1/2) ), where H, T and d are the horizon, the total number of steps and the dimension of the parameter vector, respectively. In particular, this regret bound is independent of the total number of states or actions, and is close to a lower bound Omega( (HdT)^(1/2) ). For a general model family, …
[ Virtual ]

This paper presents a recursive reasoning formalism of Bayesian optimization (BO) to model the reasoning process in the interactions between boundedly rational, self-interested agents with unknown, complex, and costly-to-evaluate payoff functions in repeated games, which we call Recursive Reasoning-Based BO (R2-B2). Our R2-B2 algorithm is general in that it does not constrain the relationship among the payoff functions of different agents and can thus be applied to various types of games such as constant-sum, general-sum, and common-payoff games. We prove that by reasoning at level 2 or more and at one level higher than the other agents, our R2-B2 agent can achieve faster asymptotic convergence to no regret than that without utilizing recursive reasoning. We also propose a computationally cheaper variant of R2-B2 called R2-B2-Lite at the expense of a weaker convergence guarantee. The performance and generality of our R2-B2 algorithm are empirically demonstrated using synthetic games, adversarial machine learning, and multi-agent reinforcement learning.

We present distribution augmentation (DistAug), a simple and powerful method of regularizing generative models. Our approach applies augmentation functions to data and, importantly, conditions the generative model on the specific function used. Unlike typical data augmentation, DistAug allows usage of functions which modify the target density, enabling aggressive augmentations more commonly seen in supervised and self-supervised learning. We demonstrate this is a more effective regularizer than standard methods, and use it to train a 152M parameter autoregressive model on CIFAR-10 to 2.56 bits per dim (relative to the state-of-the-art 2.80). Samples from this model attain FID 12.75 and IS 8.40, outperforming the majority of GANs. We further demonstrate the technique is broadly applicable across model architectures and problem domains.

[ Virtual ]

Program execution speed critically depends on increasing cache hits, as cache hits are orders of magnitude faster than misses. To increase cache hits, we focus on the problem of cache replacement: choosing which cache line to evict upon inserting a new line. This is challenging because it requires planning far ahead and currently there is no known practical solution. As a result, current replacement policies typically resort to heuristics designed for specific common access patterns, which fail on more diverse and complex access patterns. In contrast, we propose an imitation learning approach to automatically learn cache access patterns by leveraging Belady’s, an oracle policy that computes the optimal eviction decision given the future cache accesses. While directly applying Belady’s is infeasible since the future is unknown, we train a policy conditioned only on past accesses that accurately approximates Belady’s even on diverse and complex access patterns, and call this approach Parrot. When evaluated on 13 of the most memory-intensive SPEC applications, Parrot increases cache miss rates by 20% over the current state of the art. In addition, on a large-scale web search benchmark, Parrot increases cache hit rates by 61% over a conventional LRU policy. We release a Gym environment …
[ Virtual ]

Performing controlled experiments on noisy data is essential in understanding deep learning across noise levels. Due to the lack of suitable datasets, previous research has only examined deep learning on controlled synthetic label noise, and real-world label noise has never been studied in a controlled setting. This paper makes three contributions. First, we establish the first benchmark of controlled real-world label noise from the web. This new benchmark enables us to study the web label noise in a controlled setting for the first time. The second contribution is a simple but effective method to overcome both synthetic and real noisy labels. We show that our method achieves the best result on our dataset as well as on two public benchmarks (CIFAR and WebVision). Third, we conduct the largest study by far into understanding deep neural networks trained on noisy labels across different noise levels, noise types, network architectures, and training settings.
[ Virtual ]

Incremental gradient (IG) methods, such as stochastic gradient descent and its variants are commonly used for large scale optimization in machine learning. Despite the sustained effort to make IG methods more data-efficient, it remains an open question how to select a training data subset that can theoretically and practically perform on par with the full dataset. Here we develop CRAIG, a method to select a weighted subset (or coreset) of training data that closely estimates the full gradient by maximizing a submodular function. We prove that applying IG to this subset is guaranteed to converge to the (near)optimal solution with the same convergence rate as that of IG for convex optimization. As a result, CRAIG achieves a speedup that is inversely proportional to the size of the subset. To our knowledge, this is the first rigorous method for data-efficient training of general machine learning models. Our extensive set of experiments show that CRAIG, while achieving practically the same solution, speeds up various IG methods by up to 6x for logistic regression and 3x for training deep neural networks.
[ Virtual ]

In this work we formulate and formally characterize group fairness as a multi-objective optimization problem, where each sensitive group risk is a separate objective. We propose a fairness criterion where a classifier achieves minimax risk and is Pareto-efficient w.r.t. all groups, avoiding unnecessary harm, and can lead to the best zero-gap model if policy dictates so. We provide a simple optimization algorithm compatible with deep neural networks to satisfy these constraints. Since our method does not require test-time access to sensitive attributes, it can be applied to reduce worst-case classification errors between outcomes in unbalanced classification problems. We test the proposed methodology on real case-studies of predicting income, ICU patient mortality, skin lesions classification, and assessing credit risk, demonstrating how our framework compares favorably to other approaches.
[ Virtual ]
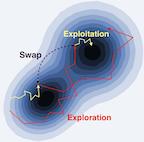
Replica exchange Monte Carlo (reMC), also known as parallel tempering, is an important technique for accelerating the convergence of the conventional Markov Chain Monte Carlo (MCMC) algorithms. However, such a method requires the evaluation of the energy function based on the full dataset and is not scalable to big data. The na\"ive implementation of reMC in mini-batch settings introduces large biases, which cannot be directly extended to the stochastic gradient MCMC (SGMCMC), the standard sampling method for simulating from deep neural networks (DNNs). In this paper, we propose an adaptive replica exchange SGMCMC (reSGMCMC) to automatically correct the bias and study the corresponding properties. The analysis implies an acceleration-accuracy trade-off in the numerical discretization of a Markov jump process in a stochastic environment. Empirically, we test the algorithm through extensive experiments on various setups and obtain the state-of-the-art results on CIFAR10, CIFAR100, and SVHN in both supervised learning and semi-supervised learning tasks.
[ Virtual ]

Wasserstein distributionally robust optimization (WDRO) attempts to learn a model that minimizes the local worst-case risk in the vicinity of the empirical data distribution defined by Wasserstein ball. While WDRO has received attention as a promising tool for inference since its introduction, its theoretical understanding has not been fully matured. Gao et al. (2017) proposed a minimizer based on a tractable approximation of the local worst-case risk, but without showing risk consistency. In this paper, we propose a minimizer based on a novel approximation theorem and provide the corresponding risk consistency results. Furthermore, we develop WDRO inference for locally perturbed data that include the Mixup (Zhang et al., 2017) as a special case. We show that our approximation and risk consistency results naturally extend to the cases when data are locally perturbed. Numerical experiments demonstrate robustness of the proposed method using image classification datasets. Our results show that the proposed method achieves significantly higher accuracy than baseline models on noisy datasets.
[ Virtual ]
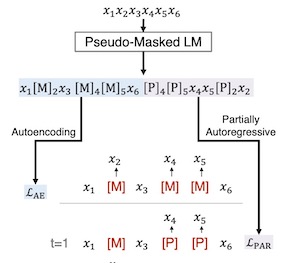
We propose to pre-train a unified language model for both autoencoding and partially autoregressive language modeling tasks using a novel training procedure, referred to as a pseudo-masked language model (PMLM). Given an input text with masked tokens, we rely on conventional masks to learn inter-relations between corrupted tokens and context via autoencoding, and pseudo masks to learn intra-relations between masked spans via partially autoregressive modeling. With well-designed position embeddings and self-attention masks, the context encodings are reused to avoid redundant computation. Moreover, conventional masks used for autoencoding provide global masking information, so that all the position embeddings are accessible in partially autoregressive language modeling. In addition, the two tasks pre-train a unified language model as a bidirectional encoder and a sequence-to-sequence decoder, respectively. Our experiments show that the unified language models pre-trained using PMLM achieve new state-of-the-art results on a wide range of language understanding and generation tasks across several widely used benchmarks. The code and pre-trained models are available at https://github.com/microsoft/unilm.
[ Virtual ]
Humans intuitively recognize objects' physical properties and predict their motion, even when the objects are engaged in complicated interactions. The abilities to perform physical reasoning and to adapt to new environments, while intrinsic to humans, remain challenging to state-of-the-art computational models. In this work, we present a neural model that simultaneously reasons about physics and makes future predictions based on visual and dynamics priors. The visual prior predicts a particle-based representation of the system from visual observations. An inference module operates on those particles, predicting and refining estimates of particle locations, object states, and physical parameters, subject to the constraints imposed by the dynamics prior, which we refer to as visual grounding. We demonstrate the effectiveness of our method in environments involving rigid objects, deformable materials, and fluids. Experiments show that our model can infer the physical properties within a few observations, which allows the model to quickly adapt to unseen scenarios and make accurate predictions into the future.

Entropy is ubiquitous in machine learning, but it is in general intractable to compute the entropy of the distribution of an arbitrary continuous random variable. In this paper, we propose the amortized residual denoising autoencoder (AR-DAE) to approximate the gradient of the log density function, which can be used to estimate the gradient of entropy. Amortization allows us to significantly reduce the error of the gradient approximator by approaching asymptotic optimality of a regular DAE, in which case the estimation is in theory unbiased. We conduct theoretical and experimental analyses on the approximation error of the proposed method, as well as extensive studies on heuristics to ensure its robustness. Finally, using the proposed gradient approximator to estimate the gradient of entropy, we demonstrate state-of-the-art performance on density estimation with variational autoencoders and continuous control with soft actor-critic.

Good data stewardship requires removal of data at the request of the data's owner. This raises the question if and how a trained machine-learning model, which implicitly stores information about its training data, should be affected by such a removal request. Is it possible to ``remove'' data from a machine-learning model? We study this problem by defining certified removal: a very strong theoretical guarantee that a model from which data is removed cannot be distinguished from a model that never observed the data to begin with. We develop a certified-removal mechanism for linear classifiers and empirically study learning settings in which this mechanism is practical.
We propose an efficient inference method for switching nonlinear dynamical systems. The key idea is to learn an inference network which can be used as a proposal distribution for the continuous latent variables, while performing exact marginalization of the discrete latent variables. This allows us to use the reparameterization trick, and apply end-to-end training with stochastic gradient descent. We show that the proposed method can successfully segment time series data, including videos and 3D human pose, into meaningful ``regimes'' by using the piece-wise nonlinear dynamics.

In this paper, we study distributed algorithms for large-scale AUC maximization with a deep neural network as a predictive model.
Although distributed learning techniques have been investigated extensively in deep learning, they are not directly applicable to stochastic AUC maximization with deep neural networks due to its striking differences from standard loss minimization problems (e.g., cross-entropy). Towards addressing this challenge, we propose and analyze a communication-efficient distributed optimization algorithm based on a {\it non-convex concave} reformulation of the AUC maximization, in which the communication of both the primal variable and the dual variable between each worker and the parameter server only occurs after multiple steps of gradient-based updates in each worker. Compared with the naive parallel version of an existing algorithm that computes stochastic gradients at individual machines and averages them for updating the model parameter, our algorithm requires a much less number of communication rounds and still achieves linear speedup in theory. To the best of our knowledge, this is the \textbf{first} work that solves the {\it non-convex concave min-max} problem for AUC maximization with deep neural networks in a communication-efficient distributed manner while still maintaining the linear speedup property in theory. Our experiments on several benchmark datasets show …

We propose a novel interactive learning framework which we refer to as Interactive Attention Learning (IAL), in which the human supervisors interactively manipulate the allocated attentions, to correct the model's behaviour by updating the attention-generating network. However, such a model is prone to overfitting due to scarcity of human annotations, and requires costly retraining. Moreover, it is almost infeasible for the human annotators to examine attentions on tons of instances and features. We tackle these challenges by proposing a sample-efficient attention mechanism and a cost-effective reranking algorithm for instances and features. First, we propose Neural Attention Processes (NAP), which is an attention generator that can update its behaviour by incorporating new attention-level supervisions without any retraining. Secondly, we propose an algorithm which prioritizes the instances and the features by their negative impacts, such that the model can yield large improvements with minimal human feedback. We validate IAL on various time-series datasets from multiple domains (healthcare, real-estate, and computer vision) on which it significantly outperforms baselines with conventional attention mechanisms, or without cost-effective reranking, with substantially less retraining and human-model interaction cost.

In this work we develop a novel Bayesian neural network methodology to achieve strong adversarial robustness without the need for online adversarial training. Unlike previous efforts in this direction, we do not rely solely on the stochasticity of network weights by minimizing the divergence between the learned parameter distribution and a prior. Instead, we additionally require that the model maintain some expected uncertainty with respect to all input covariates. We demonstrate that by encouraging the network to distribute evenly across inputs, the network becomes less susceptible to localized, brittle features which imparts a natural robustness to targeted perturbations. We show empirical robustness on several benchmark datasets.
In many real-world applications, we want to exploit multiple source datasets to build a model for a different but related target dataset. Despite the recent empirical success, most existing research has used ad-hoc methods to combine multiple sources, leading to a gap between theory and practice. In this paper, we develop a finite-sample generalization bound based on domain discrepancy and accordingly propose a theoretically justified optimization procedure. Our algorithm, Domain AggRegation Network (DARN), can automatically and dynamically balance between including more data to increase effective sample size and excluding irrelevant data to avoid negative effects during training. We find that DARN can significantly outperform the state-of-the-art alternatives on multiple real-world tasks, including digit/object recognition and sentiment analysis.
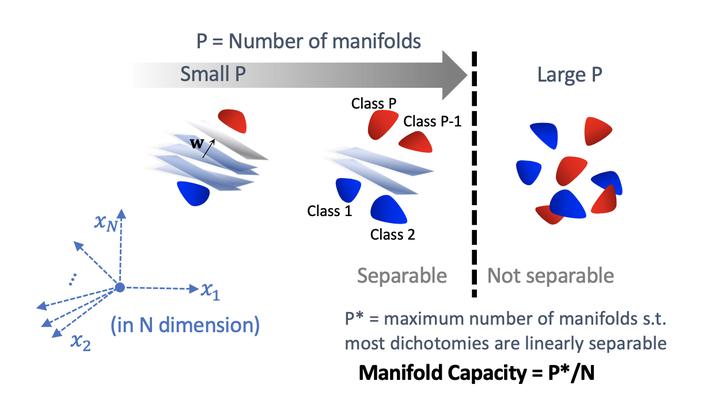
Deep neural networks (DNNs) have shown much empirical success in solving perceptual tasks across various cognitive modalities. While they are only loosely inspired by the biological brain, recent studies report considerable similarities between representations extracted from task-optimized DNNs and neural populations in the brain. DNNs have subsequently become a popular model class to infer computational principles underlying complex cognitive functions, and in turn, they have also emerged as a natural testbed for applying methods originally developed to probe information in neural populations. In this work, we utilize mean-field theoretic manifold analysis, a recent technique from computational neuroscience that connects geometry of feature representations with linear separability of classes, to analyze language representations from large-scale contextual embedding models. We explore representations from different model families (BERT, RoBERTa, GPT, etc.) and find evidence for emergence of linguistic manifolds across layer depth (e.g., manifolds for part-of-speech tags), especially in ambiguous data (i.e, words with multiple part-of-speech tags, or part-of-speech classes including many words). In addition, we find that the emergence of linear separability in these manifolds is driven by a combined reduction of manifolds’ radius, dimensionality and inter-manifold correlations.
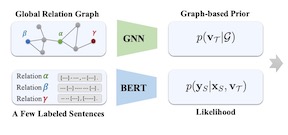
This paper studies few-shot relation extraction, which aims at predicting the relation for a pair of entities in a sentence by training with a few labeled examples in each relation. To more effectively generalize to new relations, in this paper we study the relationships between different relations and propose to leverage a global relation graph. We propose a novel Bayesian meta-learning approach to effectively learn the posterior distribution of the prototype vectors of relations, where the initial prior of the prototype vectors is parameterized with a graph neural network on the global relation graph. Moreover, to effectively optimize the posterior distribution of the prototype vectors, we propose to use the stochastic gradient Langevin dynamics, which is related to the MAML algorithm but is able to handle the uncertainty of the prototype vectors. The whole framework can be effectively and efficiently optimized in an end-to-end fashion. Experiments on two benchmark datasets prove the effectiveness of our proposed approach against competitive baselines in both the few-shot and zero-shot settings.
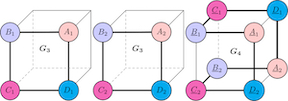
We address two fundamental questions about graph neural networks (GNNs). First, we prove that several important graph properties cannot be discriminated by GNNs that rely entirely on local information. Such GNNs include the standard message passing models, and more powerful spatial variants that exploit local graph structure (e.g., via relative orientation of messages, or local port ordering) to distinguish neighbors of each node. Our treatment includes a novel graph-theoretic formalism. Second, we provide the first data dependent generalization bounds for message passing GNNs. This analysis explicitly accounts for the local permutation invariance of GNNs. Our bounds are much tighter than existing VC-dimension based guarantees for GNNs, and are comparable to Rademacher bounds for recurrent neural networks.

Decision tree optimization is notoriously difficult from a computational perspective but essential for the field of interpretable machine learning. Despite efforts over the past 40 years, only recently have optimization breakthroughs been made that have allowed practical algorithms to find optimal decision trees. These new techniques have the potential to trigger a paradigm shift, where, it is possible to construct sparse decision trees to efficiently optimize a variety of objective functions, without relying on greedy splitting and pruning heuristics that often lead to suboptimal solutions. The contribution in this work is to provide a general framework for decision tree optimization that addresses the two significant open problems in the area: treatment of imbalanced data and fully optimizing over continuous variables. We present techniques that produce optimal decision trees over variety of objectives including F-score, AUC, and partial area under the ROC convex hull. We also introduce a scalable algorithm that produces provably optimal results in the presence of continuous variables and speeds up decision tree construction by several order of magnitude relative to the state-of-the art.

It is still common to use Q-learning and temporal difference (TD) learning—even though they have divergence issues and sound Gradient TD alternatives exist—because divergence seems rare and they typically perform well. However, recent work with large neural network learning systems reveals that instability is more common than previously thought. Practitioners face a difficult dilemma: choose an easy to use and performant TD method, or a more complex algorithm that is more sound but harder to tune and all but unexplored with non-linear function approximation or control. In this paper, we introduce a new method called TD with Regularized Corrections (TDRC), that attempts to balance ease of use, soundness, and performance. It behaves as well as TD, when TD performs well, but is sound in cases where TD diverges. We empirically investigate TDRC across a range of problems, for both prediction and control, and for both linear and non-linear function approximation, and show, potentially for the first time, that gradient TD methods could be a better alternative to TD and Q-learning.
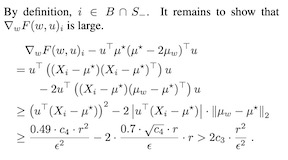
We study the problem of high-dimensional robust mean estimation in the presence of a constant fraction of adversarial outliers. A recent line of work has provided sophisticated polynomial-time algorithms for this problem with dimension-independent error guarantees for a range of natural distribution families. In this work, we show that a natural non-convex formulation of the problem can be solved directly by gradient descent. Our approach leverages a novel structural lemma, roughly showing that any approximate stationary point of our non-convex objective gives a near-optimal solution to the underlying robust estimation task. Our work establishes an intriguing connection between algorithmic high-dimensional robust statistics and non-convex optimization, which may have broader applications to other robust estimation tasks.
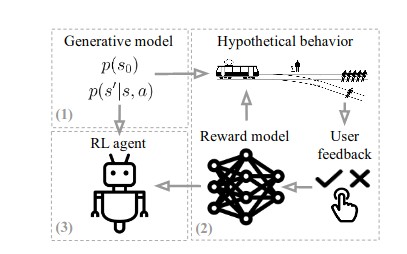
We seek to align agent behavior with a user's objectives in a reinforcement learning setting with unknown dynamics, an unknown reward function, and unknown unsafe states. The user knows the rewards and unsafe states, but querying the user is expensive. We propose an algorithm that safely and efficiently learns a model of the user's reward function by posing 'what if?' questions about hypothetical agent behavior. We start with a generative model of initial states and a forward dynamics model trained on off-policy data. Our method uses these models to synthesize hypothetical behaviors, asks the user to label the behaviors with rewards, and trains a neural network to predict the rewards. The key idea is to actively synthesize the hypothetical behaviors from scratch by maximizing tractable proxies for the value of information, without interacting with the environment. We call this method reward query synthesis via trajectory optimization (ReQueST). We evaluate ReQueST with simulated users on a state-based 2D navigation task and the image-based Car Racing video game. The results show that ReQueST significantly outperforms prior methods in learning reward models that transfer to new environments with different initial state distributions. Moreover, ReQueST safely trains the reward model to detect unsafe states, …
We consider the problem of learning the weighted edges of a balanced mixture of two undirected graphs from epidemic cascades. While mixture models are popular modeling tools, algorithmic development with rigorous guarantees has lagged. Graph mixtures are apparently no exception: until now, very little is known about whether this problem is solvable.
To the best of our knowledge, we establish the first necessary and sufficient conditions for this problem to be solvable in polynomial time on edge-separated graphs. When the conditions are met, i.e., when the graphs are connected with at least three edges, we give an efficient algorithm for learning the weights of both graphs with optimal sample complexity (up to log factors).
We give complementary results and provide sample-optimal (up to log factors) algorithms for mixtures of directed graphs of out-degree at least three, and for mixture of undirected graphs of unbalanced and/or unknown priors.

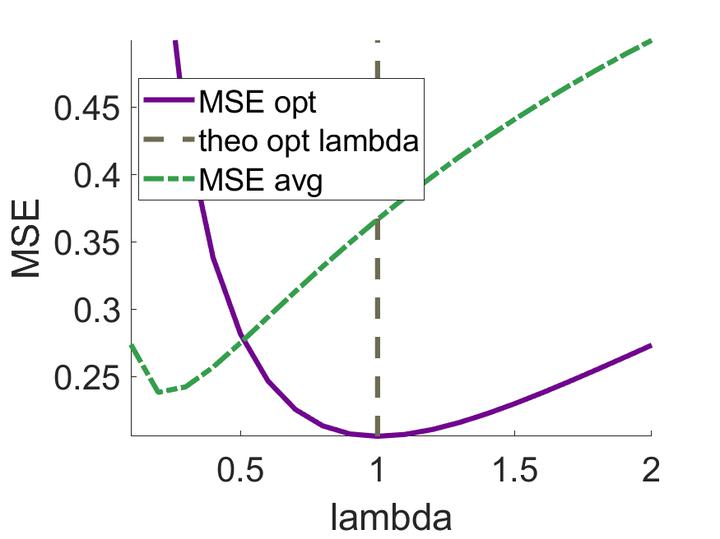
To scale up data analysis, distributed and parallel computing approaches are increasingly needed. Here we study a fundamental problem in this area: How to do ridge regression in a distributed computing environment? We study one-shot methods constructing weighted combinations of ridge regression estimators computed on each machine. By analyzing the mean squared error in a high dimensional model where each predictor has a small effect, we discover several new phenomena including that the efficiency depends strongly on the signal strength, but does not degrade with many workers, the risk decouples over machines, and the unexpected consequence that the optimal weights do not sum to unity. We also propose a new optimally weighted one-shot ridge regression algorithm. Our results are supported by simulations and real data analysis.

To acquire a new skill, humans learn better and faster if a tutor, based on their current knowledge level, informs them of how much attention they should pay to particular content or practice problems. Similarly, a machine learning model could potentially be trained better with a scorer that ``adapts'' to its current learning state and estimates the importance of each training data instance. Training such an adaptive scorer efficiently is a challenging problem; in order to precisely quantify the effect of a data instance at a given time during the training, it is typically necessary to first complete the entire training process. To efficiently optimize data usage, we propose a reinforcement learning approach called Differentiable Data Selection (DDS). In DDS, we formulate a scorer network as a learnable function of the training data, which can be efficiently updated along with the main model being trained. Specifically, DDS updates the scorer with an intuitive reward signal: it should up-weigh the data that has a similar gradient with a dev set upon which we would finally like to perform well. Without significant computing overhead, DDS delivers strong and consistent improvements over several strong baselines on two very different tasks of machine translation …

Partial-label learning (PLL) is a typical weakly supervised learning problem, where each training instance is equipped with a set of candidate labels among which only one is the true label. Most existing methods elaborately designed learning objectives as constrained optimizations that must be solved in specific manners, making their computational complexity a bottleneck for scaling up to big data. The goal of this paper is to propose a novel framework of PLL with flexibility on the model and optimization algorithm. More specifically, we propose a novel estimator of the classification risk, theoretically analyze the classifier-consistency, and establish an estimation error bound. Then we propose a progressive identification algorithm for approximately minimizing the proposed risk estimator, where the update of the model and identification of true labels are conducted in a seamless manner. The resulting algorithm is model-independent and loss-independent, and compatible with stochastic optimization. Thorough experiments demonstrate it sets the new state of the art.
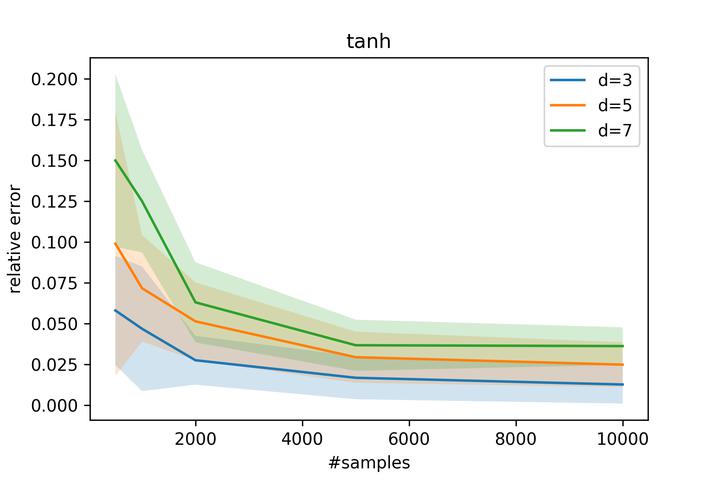
Generative adversarial networks (GANs) are a widely used framework for learning generative models. Wasserstein GANs (WGANs), one of the most successful variants of GANs, require solving a minmax optimization problem to global optimality, but are in practice successfully trained using stochastic gradient descent-ascent. In this paper, we show that, when the generator is a one-layer network, stochastic gradient descent-ascent converges to a global solution with polynomial time and sample complexity.

We propose Sparse Sinkhorn Attention, a new efficient and sparse method for learning to attend. Our method is based on differentiable sorting of internal representations. Concretely, we introduce a meta sorting network that learns to generate latent permutations over sequences. Given sorted sequences, we are then able to compute quasi-global attention with only local windows, improving the memory efficiency of the attention module. To this end, we propose new algorithmic innovations such as Causal Sinkhorn Balancing and SortCut, a dynamic sequence truncation method for tailoring Sinkhorn Attention for encoding and/or decoding purposes. Via extensive experiments on algorithmic seq2seq sorting, language modeling, pixel-wise image generation, document classification and natural language inference, we demonstrate that our memory efficient Sinkhorn Attention method is competitive with vanilla attention and consistently outperforms recently proposed efficient Transformer models such as Sparse Transformers.
Logistic models are commonly used for binary classification tasks. The success of such models has often been attributed to their connection to maximum-likelihood estimators. It has been shown that SGD algorithms , when applied on the logistic loss, converge to the max-margin classifier (a.k.a. hard-margin SVM). The performance of hard-margin SVM has been recently analyzed in~\cite{montanari2019generalization, deng2019model}. Inspired by these results, in this paper, we present and study a more general setting, where the underlying parameters of the logistic model possess certain structures (sparse, block-sparse, low-rank, etc.) and introduce a more general framework (which is referred to as “Generalized Margin Maximizer”, GMM). While classical max-margin classifiers minimize the 2-norm of the parameter vector subject to linearly separating the data, GMM minimizes any arbitrary convex function of the parameter vector. We provide a precise performance analysis of the generalization error of such methods and show improvement over the max-margin method which does not take into account the structure of the model. In future work we show that mirror descent algorithms, with a properly tuned step size, can be exploited to achieve GMM classifiers. Our theoretical results are validated by extensive simulation results across a range of parameter values, problem instances, and …
Poster Session 52 Fri 17 Jul 05:00 a.m.
[ Virtual ]

Multi-agent reinforcement learning (MARL) achieves significant empirical successes. However, MARL suffers from the curse of many agents. In this paper, we exploit the symmetry of agents in MARL. In the most generic form, we study a mean-field MARL problem. Such a mean-field MARL is defined on mean-field states, which are distributions that are supported on continuous space. Based on the mean embedding of the distributions, we propose MF-FQI algorithm, which solves the mean-field MARL and establishes a non-asymptotic analysis for MF-FQI algorithm. We highlight that MF-FQI algorithm enjoys a ``blessing of many agents'' property in the sense that a larger number of observed agents improves the performance of MF-FQI algorithm.

Efficiently computing equilibria for multiplayer games is still an open challenge in computational game theory. This paper focuses on computing Team-Maxmin Equilibria (TMEs), which is an important solution concept for zero-sum multiplayer games where players in a team having the same utility function play against an adversary independently. Existing algorithms are inefficient to compute TMEs in large games, especially when the strategy space is too large to be represented due to limited memory. In two-player games, the Incremental Strategy Generation (ISG) algorithm is an efficient approach to avoid enumerating all pure strategies. However, the study of ISG for computing TMEs is completely unexplored. To fill this gap, we first study the properties of ISG for multiplayer games, showing that ISG converges to a Nash equilibrium (NE) but may not converge to a TME. Second, we design an ISG variant for TMEs (ISGT) by exploiting that a TME is an NE maximizing the team’s utility and show that ISGT converges to a TME and the impossibility of relaxing conditions in ISGT. Third, to further improve the scalability, we design an ISGT variant (CISGT) by using the strategy space for computing an equilibrium that is close to a TME but is easier …

We propose a new framework for designing estimators for off-policy evaluation in contextual bandits. Our approach is based on the asymptotically optimal doubly robust estimator, but we shrink the importance weights to minimize a bound on the mean squared error, which results in a better bias-variance tradeoff in finite samples. We use this optimization-based framework to obtain three estimators: (a) a weight-clipping estimator, (b) a new weight-shrinkage estimator, and (c) the first shrinkage-based estimator for combinatorial action sets. Extensive experiments in both standard and combinatorial bandit benchmark problems show that our estimators are highly adaptive and typically outperform state-of-the-art methods.
Neural networks are often represented as graphs of connections between neurons. However, despite their wide use, there is currently little understanding of the relationship between the graph structure of the neural network and its predictive performance. Here we systematically investigate how does the graph structure of neural networks affect their predictive performance. To this end, we develop a novel graph-based representation of neural networks called relational graph, where layers of neural network computation correspond to rounds of message exchange along the graph structure. Using this representation we show that: (1) graph structure of neural networks matters; (2) a “sweet spot” of relational graphs lead to neural networks with significantly improved predictive performance; (3) neural network’s performance is approximately a smooth function of the clustering coefficient and average path length of its relational graph; (4) our findings are consistent across many different tasks and datasets; (5) top architectures can be identified efficiently; (6) well-performing neural networks have graph structure surprisingly similar to those of real biological neural networks. Our work opens new directions for the design of neural architectures and the understanding on neural networks in general.
We present an algorithm, HOMER, for exploration and reinforcement learning in rich observation environments that are summarizable by an unknown latent state space. The algorithm interleaves representation learning to identify a new notion of kinematic state abstraction with strategic exploration to reach new states using the learned abstraction. The algorithm provably explores the environment with sample complexity scaling polynomially in the number of latent states and the time horizon, and, crucially, with no dependence on the size of the observation space, which could be infinitely large. This exploration guarantee further enables sample-efficient global policy optimization for any reward function. On the computational side, we show that the algorithm can be implemented efficiently whenever certain supervised learning problems are tractable. Empirically, we evaluate HOMER on a challenging exploration problem, where we show that the algorithm is more sample efficient than standard reinforcement learning baselines.
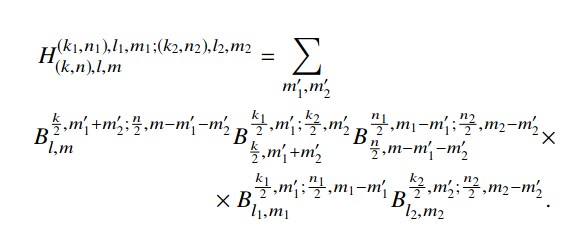
We present a neural network architecture that is fully equivariant with respect to transformations under the Lorentz group, a fundamental symmetry of space and time in physics. The architecture is based on the theory of the finite-dimensional representations of the Lorentz group and the equivariant nonlinearity involves the tensor product. For classification tasks in particle physics, we show that such an equivariant architecture leads to drastically simpler models that have relatively few learnable parameters and are much more physically interpretable than leading approaches that use CNNs and point cloud approaches. The performance of the network is tested on a public classification dataset [https://zenodo.org/record/2603256] for tagging top quark decays given energy-momenta of jet constituents produced in proton-proton collisions.
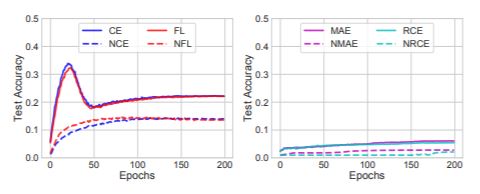
Robust loss functions are essential for training accurate deep neural networks (DNNs) in the presence of noisy (incorrect) labels. It has been shown that the commonly used Cross Entropy (CE) loss is not robust to noisy labels. Whilst new loss functions have been designed, they are only partially robust. In this paper, we theoretically show by applying a simple normalization that: \emph{any loss can be made robust to noisy labels}. However, in practice, simply being robust is not sufficient for a loss function to train accurate DNNs. By investigating several robust loss functions, we find that they suffer from a problem of {\em underfitting}. To address this, we propose a framework to build robust loss functions called \emph{Active Passive Loss} (APL). APL combines two robust loss functions that mutually boost each other. Experiments on benchmark datasets demonstrate that the family of new loss functions created by our APL framework can consistently outperform state-of-the-art methods by large margins, especially under large noise rates such as 60\% or 80\% incorrect labels.
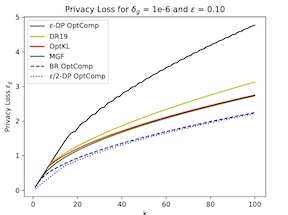
Composition is one of the most important properties of differential privacy (DP), as it allows algorithm designers to build complex private algorithms from DP primitives. We consider precise composition bounds of the overall privacy loss for exponential mechanisms, one of the fundamental classes of mechanisms in DP. Exponential mechanism has also become a fundamental building block in private machine learning, e.g. private PCA and hyper-parameter selection. We give explicit formulations of the optimal privacy loss for both the adaptive and non-adaptive composition of exponential mechanism. For the non-adaptive setting in which each mechanism has the same privacy parameter, we give an efficiently computable formulation of the optimal privacy loss. In the adaptive case, we derive a recursive formula and an efficiently computable upper bound. These precise understandings about the problem lead to a 40\% saving of the privacy budget in a practical application. Furthermore, the algorithm-specific analysis shows a difference in privacy parameters of adaptive and non-adaptive composition, which was widely believed to not exist based on the evidence from general analysis.

Modern generative models are usually designed to match target distributions directly in the data space, where the intrinsic dimension of data can be much lower than the ambient dimension. We argue that this discrepancy may contribute to the difficulties in training generative models. We therefore propose to map both the generated and target distributions to the latent space using the encoder of a standard autoencoder, and train the generator (or decoder) to match the target distribution in the latent space. Specifically, we enforce the consistency in both the data space and the latent space with theoretically justified data and latent reconstruction losses. The resulting generative model, which we call a perceptual generative autoencoder (PGA), is then trained with a maximum likelihood or variational autoencoder (VAE) objective. With maximum likelihood, PGAs generalize the idea of reversible generative models to unrestricted neural network architectures and arbitrary number of latent dimensions. When combined with VAEs, PGAs substantially improve over the baseline VAEs in terms of sample quality. Compared to other autoencoder-based generative models using simple priors, PGAs achieve state-of-the-art FID scores on CIFAR-10 and CelebA.

Normalizing flows transform a latent distribution through an invertible neural network for a flexible and pleasingly simple approach to generative modelling, while preserving an exact likelihood. We propose FlowGMM, an end-to-end approach to generative semi supervised learning with normalizing flows, using a latent Gaussian mixture model. FlowGMM is distinct in its simplicity, unified treatment of labelled and unlabelled data with an exact likelihood, interpretability, and broad applicability beyond image data. We show promising results on a wide range of applications, including AG-News and Yahoo Answers text data, tabular data, and semi-supervised image classification. We also show that FlowGMM can discover interpretable structure, provide real-time optimization-free feature visualizations, and specify well calibrated predictive distributions.

Disentanglement learning is crucial for obtaining disentangled representations and controllable generation. Current disentanglement methods face several inherent limitations: difficulty with high-resolution images, primarily focusing on learning disentangled representations, and non-identifiability due to the unsupervised setting. To alleviate these limitations, we design new architectures and loss functions based on StyleGAN (Karras et al., 2019), for semi-supervised high-resolution disentanglement learning. We create two complex high-resolution synthetic datasets for systematic testing. We investigate the impact of limited supervision and find that using only 0.25%~2.5% of labeled data is sufficient for good disentanglement on both synthetic and real datasets. We propose new metrics to quantify generator controllability, and observe there may exist a crucial trade-off between disentangled representation learning and controllable generation. We also consider semantic fine-grained image editing to achieve better generalization to unseen images.

Generative adversarial networks (GANs) are effective in generating realistic images but the training is often unstable. There are existing efforts that model the training dynamics of GANs in the parameter space but the analysis cannot directly motivate practically effective stabilizing methods. To this end, we present a conceptually novel perspective from control theory to directly model the dynamics of GANs in the frequency domain and provide simple yet effective methods to stabilize GAN's training. We first analyze the training dynamic of a prototypical Dirac GAN and adopt the widely-used closed-loop control (CLC) to improve its stability. We then extend CLC to stabilize the training dynamic of normal GANs, which can be implemented as an L2 regularizer on the output of the discriminator. Empirical results show that our method can effectively stabilize the training and obtain state-of-the-art performance on data generation tasks.
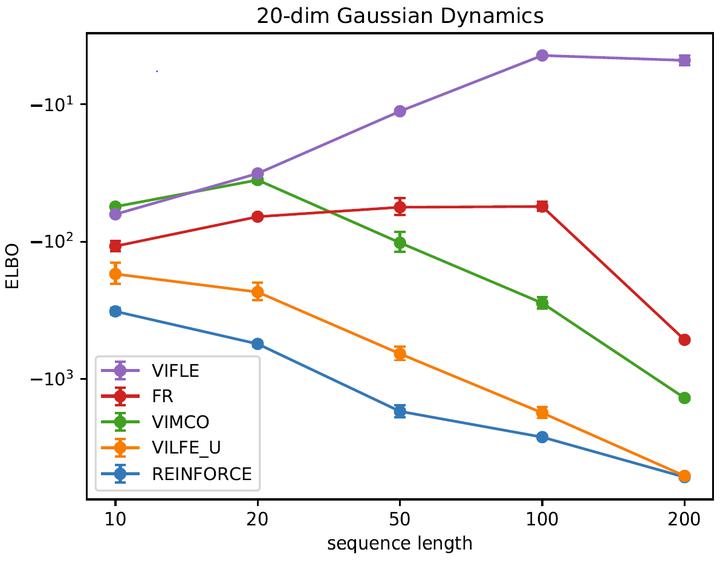
The recent development of flexible and scalable variational inference algorithms has popularized the use of deep probabilistic models in a wide range of applications. However, learning and reasoning about high-dimensional models with nondifferentiable densities are still a challenge. For such a model, inference algorithms struggle to estimate the gradients of variational objectives accurately, due to high variance in their estimates. To tackle this challenge, we present a novel variational inference algorithm for sequential data, which performs well even when the density from the model is not differentiable, for instance, due to the use of discrete random variables. The key feature of our algorithm is that it estimates future likelihoods at all time steps. The estimated future likelihoods form the core of our new low-variance gradient estimator. We formally analyze our gradient estimator from the perspective of variational objective, and show the effectiveness of our algorithm with synthetic and real datasets.

[ Virtual ]
Reinforcement learning is typically concerned with learning control policies tailored to a particular agent. We investigate whether there exists a single policy that generalizes to controlling a wide variety of agent morphologies -- ones in which even dimensionality of state and action spaces changes. Such a policy would distill general and modular sensorimotor patterns that can be applied to control arbitrary agents. We propose a policy expressed as a collection of identical modular neural networks for each of the agent's actuators. Every module is only responsible for controlling its own actuator and receives information from its local sensors. In addition, messages are passed between modules, propagating information between distant modules. A single modular policy can successfully generate locomotion behaviors for over 20 planar agents with different skeletal structures such as monopod hoppers, quadrupeds, bipeds, and generalize to variants not seen during training -- a process that would normally require training and manual hyperparameter tuning for each morphology. We observe a wide variety of drastically diverse locomotion styles across morphologies as well as centralized coordination emerging via message passing between decentralized modules purely from the reinforcement learning objective. Video and code: https://huangwl18.github.io/modular-rl/
[ Virtual ]
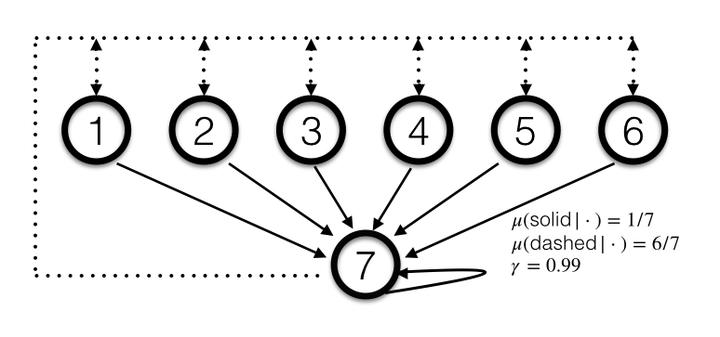
We present the first provably convergent two-timescale off-policy actor-critic algorithm (COF-PAC) with function approximation. Key to COF-PAC is the introduction of a new critic, the emphasis critic, which is trained via Gradient Emphasis Learning (GEM), a novel combination of the key ideas of Gradient Temporal Difference Learning and Emphatic Temporal Difference Learning. With the help of the emphasis critic and the canonical value function critic, we show convergence for COF-PAC, where the critics are linear and the actor can be nonlinear.
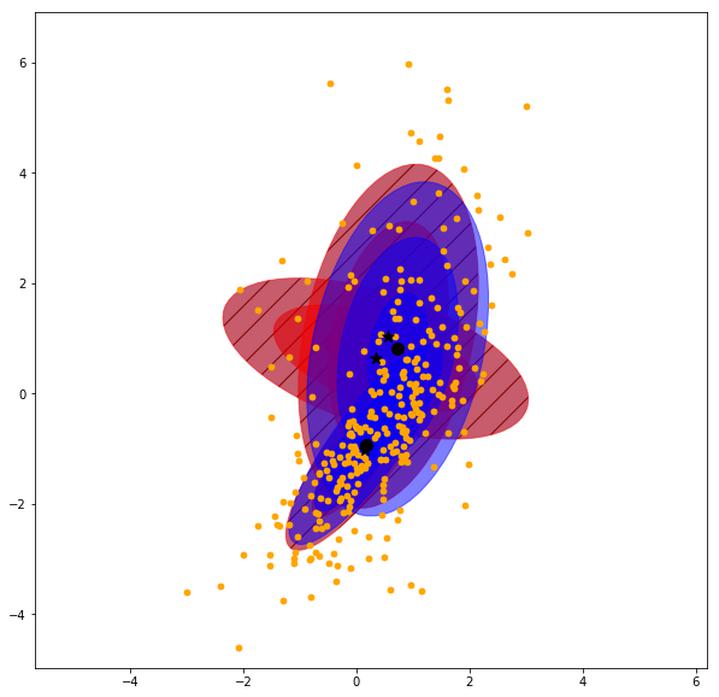
We propose a method to fuse posterior distributions learned from heterogeneous datasets. Our algorithm relies on a mean field assumption for both the fused model and the individual dataset posteriors and proceeds using a simple assign-and-average approach. The components of the dataset posteriors are assigned to the proposed global model components by solving a regularized variant of the assignment problem. The global components are then updated based on these assignments by their mean under a KL divergence. For exponential family variational distributions, our formulation leads to an efficient non-parametric algorithm for computing the fused model. Our algorithm is easy to describe and implement, efficient, and competitive with state-of-the-art on motion capture analysis, topic modeling, and federated learning of Bayesian neural networks.

[ Virtual ]
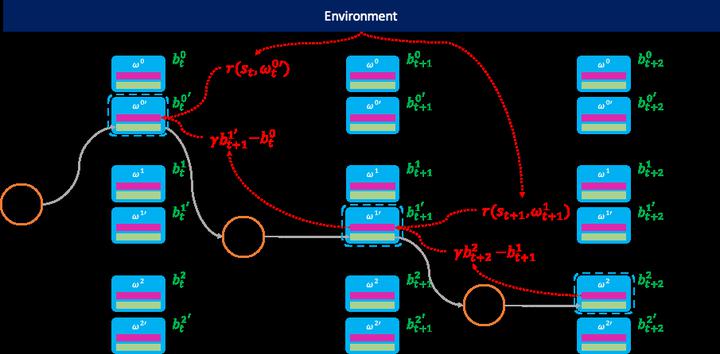
This paper seeks to establish a framework for directing a society of simple, specialized, self-interested agents to solve what traditionally are posed as monolithic single-agent sequential decision problems. What makes it challenging to use a decentralized approach to collectively optimize a central objective is the difficulty in characterizing the equilibrium strategy profile of non-cooperative games. To overcome this challenge, we design a mechanism for defining the learning environment of each agent for which we know that the optimal solution for the global objective coincides with a Nash equilibrium strategy profile of the agents optimizing their own local objectives. The society functions as an economy of agents that learn the credit assignment process itself by buying and selling to each other the right to operate on the environment state. We derive a class of decentralized reinforcement learning algorithms that are broadly applicable not only to standard reinforcement learning but also for selecting options in semi-MDPs and dynamically composing computation graphs. Lastly, we demonstrate the potential advantages of a society's inherent modular structure for more efficient transfer learning.
[ Virtual ]

[ Virtual ]

The role concept provides a useful tool to design and understand complex multi-agent systems, which allows agents with a similar role to share similar behaviors. However, existing role-based methods use prior domain knowledge and predefine role structures and behaviors. In contrast, multi-agent reinforcement learning (MARL) provides flexibility and adaptability, but less efficiency in complex tasks. In this paper, we synergize these two paradigms and propose a role-oriented MARL framework (ROMA). In this framework, roles are emergent, and agents with similar roles tend to share their learning and to be specialized on certain sub-tasks. To this end, we construct a stochastic role embedding space by introducing two novel regularizers and conditioning individual policies on roles. Experiments show that our method can learn specialized, dynamic, and identifiable roles, which help our method push forward the state of the art on the StarCraft II micromanagement benchmark. Demonstrative videos are available at https://sites.google.com/view/romarl/.
[ Virtual ]
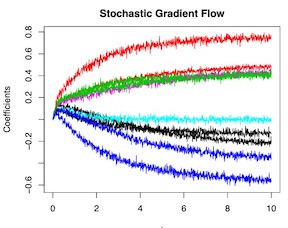
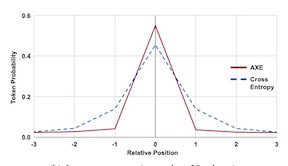
Non-autoregressive machine translation models significantly speed up decoding by allowing for parallel prediction of the entire target sequence. However, modeling word order is more challenging due to the lack of autoregressive factors in the model. This difficultly is compounded during training with cross entropy loss, which can highly penalize small shifts in word order. In this paper, we propose aligned cross entropy (AXE) as an alternative loss function for training of non-autoregressive models. AXE uses a differentiable dynamic program to assign loss based on the best possible monotonic alignment between target tokens and model predictions. AXE-based training of conditional masked language models (CMLMs) substantially improves performance on major WMT benchmarks, while setting a new state of the art for non-autoregressive models.
The fruit fly Drosophila's olfactory circuit has inspired a new locality sensitive hashing (LSH) algorithm, FlyHash. In contrast with classical LSH algorithms that produce low dimensional hash codes, FlyHash produces sparse high-dimensional hash codes and has also been shown to have superior empirical performance compared to classical LSH algorithms in similarity search. However, FlyHash uses random projections and cannot learn from data. Building on inspiration from FlyHash and the ubiquity of sparse expansive representations in neurobiology, our work proposes a novel hashing algorithm BioHash that produces sparse high dimensional hash codes in a data-driven manner. We show that BioHash outperforms previously published benchmarks for various hashing methods. Since our learning algorithm is based on a local and biologically plausible synaptic plasticity rule, our work provides evidence for the proposal that LSH might be a computational reason for the abundance of sparse expansive motifs in a variety of biological systems. We also propose a convolutional variant BioConvHash that further improves performance. From the perspective of computer science, BioHash and BioConvHash are fast, scalable and yield compressed binary representations that are useful for similarity search.
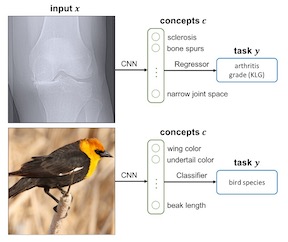
We seek to learn models that we can interact with using high-level concepts: would the model predict severe arthritis if it thinks there is a bone spur in the x-ray? State-of-the-art models today do not typically support the manipulation of concepts like "the existence of bone spurs'', as they are trained end-to-end to go directly from raw input (e.g., pixels) to output (e.g., arthritis severity). We revisit the classic idea of first predicting concepts that are provided at training time, and then using these concepts to predict the label. By construction, we can intervene on these concept bottleneck models by editing their predicted concept values and propagating these changes to the final prediction. On x-ray grading and bird identification, concept bottleneck models achieve competitive accuracy with standard end-to-end models, while enabling interpretation in terms of high-level clinical concepts ("bone spurs") or bird attributes ("wing color"). These models also allow for richer human-model interaction: accuracy improves significantly if we can correct model mistakes on concepts at test time.
We present CURL: Contrastive Unsupervised Representations for Reinforcement Learning. CURL extracts high-level features from raw pixels using contrastive learning and performs off-policy control on top of the extracted features. CURL outperforms prior pixel-based methods, both model-based and model-free, on complex tasks in the DeepMind Control Suite and Atari Games showing 1.9x and 1.2x performance gains at the 100K environment and interaction steps benchmarks respectively. On the DeepMind Control Suite, CURL is the first image-based algorithm to nearly match the sample-efficiency of methods that use state-based features. Our code is open-sourced and available at https://www.github.com/MishaLaskin/curl.
We consider the use of decision trees for decision-making problems under the predict-then-optimize framework. That is, we would like to first use a decision tree to predict unknown input parameters of an optimization problem, and then make decisions by solving the optimization problem using the predicted parameters. A natural loss function in this framework is to measure the suboptimality of the decisions induced by the predicted input parameters, as opposed to measuring loss using input parameter prediction error. This natural loss function is known in the literature as the Smart Predict-then-Optimize (SPO) loss, and we propose a tractable methodology called SPO Trees (SPOTs) for training decision trees under this loss. SPOTs benefit from the interpretability of decision trees, providing an interpretable segmentation of contextual features into groups with distinct optimal solutions to the optimization problem of interest. We conduct several numerical experiments on synthetic and real data including the prediction of travel times for shortest path problems and predicting click probabilities for news article recommendation. We demonstrate on these datasets that SPOTs simultaneously provide higher quality decisions and significantly lower model complexity than other machine learning approaches (e.g., CART) trained to minimize prediction error.

We evaluate a wide range of ImageNet models with five trained human labelers. In our year-long experiment, trained humans first annotated 40,000 images from the ImageNet and ImageNetV2 test sets with multi-class labels to enable a semantically coherent evaluation. Then we measured the classification accuracy of the five trained humans on the full task with 1,000 classes. Only the latest models from 2020 are on par with our best human labeler, and human accuracy on the 590 object classes is still 4% and 10% higher than the best model on ImageNet and ImageNetV2, respectively. Moreover, humans achieve the same accuracy on ImageNet and ImageNetV2, while all models see a consistent accuracy drop. Overall, our results show that there is still substantial room for improvement on ImageNet and direct accuracy comparisons between humans and machines may overstate machine performance.
At the heart of machine learning lies the question of generalizability of learned rules over previously unseen data.
While over-parameterized models based on neural networks are now ubiquitous in machine learning applications, our understanding of their generalization capabilities is incomplete and this task is made harder by the non-convexity of the underlying learning problems.
We provide a general framework to characterize the asymptotic generalization error for single-layer neural networks (i.e., generalized linear models) with arbitrary non-linearities,
making it applicable to regression as well as classification problems.
This framework enables analyzing the effect of (i) over-parameterization and non-linearity during modeling; (ii) choices of loss function, initialization, and regularizer during learning; and (iii) mismatch between training and test distributions. As examples, we analyze a few special cases, namely linear regression and logistic regression. We are also able to rigorously and analytically explain the \emph{double descent} phenomenon in generalized linear models.

Recent empirical works show that large deep neural networks are often highly redundant and one can find much smaller subnetworks without a significant drop of accuracy. However, most existing methods of network pruning are empirical and heuristic, leaving it open whether good subnetworks provably exist, how to find them efficiently, and if network pruning can be provably better than direct training using gradient descent. We answer these problems positively by proposing a simple greedy selection approach for finding good subnetworks, which starts from an empty network and greedily adds important neurons from the large network. This differs from the existing methods based on backward elimination, which remove redundant neurons from the large network. Theoretically, applying the greedy selection strategy on sufficiently large {pre-trained} networks guarantees to find small subnetworks with lower loss than networks directly trained with gradient descent. Our results also apply to pruning randomly weighted networks. Practically, we improve prior arts of network pruning on learning compact neural architectures on ImageNet, including ResNet, MobilenetV2/V3, and ProxylessNet. Our theory and empirical results on MobileNet suggest that we should fine-tune the pruned subnetworks to leverage the information from the large model, instead of re-training from new random initialization as suggested …

The success of GANs is usually attributed to properties of the divergence obtained by an optimal discriminator. In this work we show that this approach has a fundamental flaw:\ If we do not impose regularity of the discriminator, it can exploit visually imperceptible errors of the generator to always achieve the maximal generator loss. In practice, gradient penalties are used to regularize the discriminator. However, this needs a metric on the space of images that captures visual similarity. Such a metric is not known, which explains the limited success of gradient penalties in stabilizing GANs.\ Instead, we argue that the implicit competitive regularization (ICR) arising from the simultaneous optimization of generator and discriminator enables GANs performance. We show that opponent-aware modelling of generator and discriminator, as present in competitive gradient descent (CGD), can significantly strengthen ICR and thus stabilize GAN training without explicit regularization. In our experiments, we use an existing implementation of WGAN-GP and show that by training it with CGD without any explicit regularization, we can improve the inception score (IS) on CIFAR10, without any hyperparameter tuning.
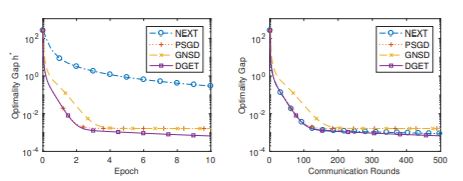
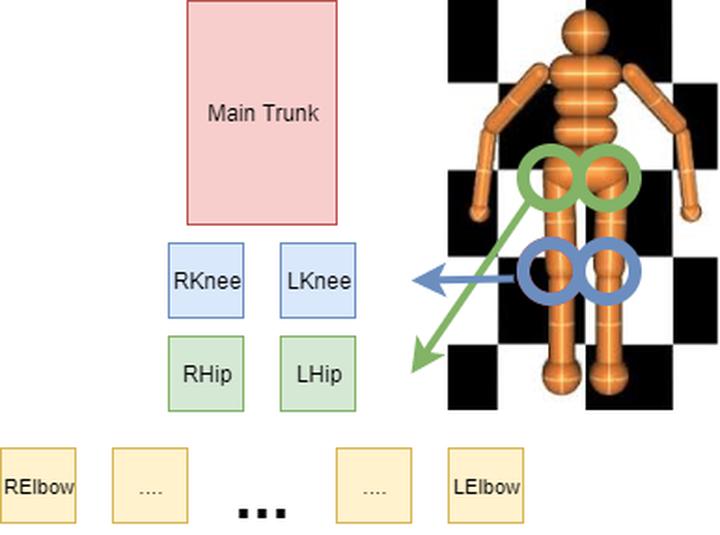
Despite recent advancements in the field of Deep Reinforcement Learning, Deep Q-network (DQN) models still show lackluster performance on problems with high-dimensional action spaces. The problem is even more pronounced for cases with high-dimensional continuous action spaces due to a combinatorial increase in the number of the outputs. Recent works approach the problem by dividing the network into multiple parallel or sequential (action) modules responsible for different discretized actions. However, there are drawbacks to both the parallel and the sequential approaches. Parallel module architectures lack coordination between action modules, leading to extra complexity in the task, while a sequential structure can result in the vanishing gradients problem and exploding parameter space. In this work, we show that the compositional structure of the action modules has a significant impact on model performance. We propose a novel approach to infer the network structure for DQN models operating with high-dimensional continuous actions. Our method is based on the uncertainty estimation techniques introduced in the paper. Our approach achieves state-of-the-art performance on MuJoCo environments with high-dimensional continuous action spaces. Furthermore, we demonstrate the improvement of the introduced approach on a realistic AAA sailing simulator game.
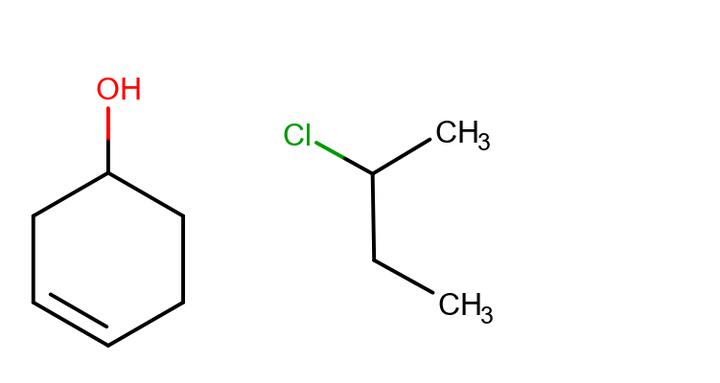
Over the last decade, there has been significant progress in the field of machine learning for de novo drug design, particularly in generative modeling of novel chemical structures. However, current generative approaches exhibit a significant challenge: they do not ensure that the proposed molecular structures can be feasibly synthesized nor do they provide the synthesis routes of the proposed small molecules, thereby seriously limiting their practical applicability. In this work, we propose a novel reinforcement learning (RL) setup for de novo drug design: Policy Gradient for Forward Synthesis (PGFS), that addresses this challenge by embedding the concept of synthetic accessibility directly into the de novo drug design system. In this setup, the agent learns to navigate through the immense synthetically accessible chemical space by subjecting initial commercially available molecules to valid chemical reactions at every time step of the iterative virtual synthesis process. The proposed environment for drug discovery provides a highly challenging test-bed for RL algorithms owing to the large state space and high-dimensional continuous action space with hierarchical actions. PGFS achieves state-of-the-art performance in generating structures with high QED and logP. Moreover, we put to test PGFS in an in-silico proof-of-concept associated with three HIV targets, and the …

In video prediction tasks, one major challenge is to capture the multi-modal nature of future contents and dynamics. In this work, we propose a simple yet effective framework that can efficiently predict plausible future states. The key insight is that the potential distribution of a sequence could be approximated with analogous ones in a repertoire of training pool, namely, expert examples. By further incorporating a novel optimization scheme into the training procedure, plausible predictions can be sampled efficiently from distribution constructed from the retrieved examples. Meanwhile, our method could be seamlessly integrated with existing stochastic predictive models; significant enhancement is observed with comprehensive experiments in both quantitative and qualitative aspects. We also demonstrate the generalization ability to predict the motion of unseen class, i.e., without access to corresponding data during training phase.
Self-supervision as an emerging technique has been employed to train convolutional neural networks (CNNs) for more transferrable, generalizable, and robust representation learning of images. Its introduction to graph convolutional networks (GCNs) operating on graph data is however rarely explored. In this study, we report the first systematic exploration and assessment of incorporating self-supervision into GCNs. We first elaborate three mechanisms to incorporate self-supervision into GCNs, analyze the limitations of pretraining & finetuning and self-training, and proceed to focus on multi-task learning. Moreover, we propose to investigate three novel self-supervised learning tasks for GCNs with theoretical rationales and numerical comparisons. Lastly, we further integrate multi-task self-supervision into graph adversarial training. Our results show that, with properly designed task forms and incorporation mechanisms, self-supervision benefits GCNs in gaining more generalizability and robustness. Our codes are available at https://github.com/Shen-Lab/SS-GCNs.
Poster Session 53 Fri 17 Jul 08:00 a.m.
[ Virtual ]
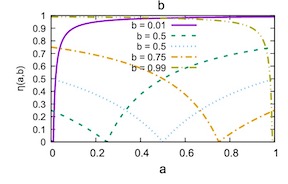
We consider the study of a classification model whose properties are impossible to estimate using a validation set, either due to the absence of such a set or because access to the classifier, even as a black-box, is impossible. Instead, only aggregate statistics on the rate of positive predictions in each of several sub-populations are available, as well as the true rates of positive labels in each of these sub-populations. We show that these aggregate statistics can be used to lower-bound the discrepancy of a classifier, which is a measure that balances inaccuracy and unfairness. To this end, we define a new measure of unfairness, equal to the fraction of the population on which the classifier behaves differently, compared to its global, ideally fair behavior, as defined by the measure of equalized odds. We propose an efficient and practical procedure for finding the best possible lower bound on the discrepancy of the classifier, given the aggregate statistics, and demonstrate in experiments the empirical tightness of this lower bound, as well as its possible uses on various types of problems, ranging from estimating the quality of voting polls to measuring the effectiveness of patient identification from internet search queries. The code …
[ Virtual ]
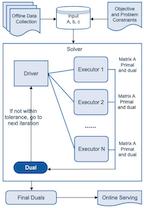
[ Virtual ]
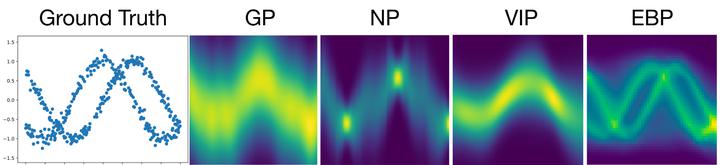
Recently there has been growing interest in modeling sets with exchangeability such as point clouds. A shortcoming of current approaches is that they restrict the cardinality of the sets considered or can only express limited forms of distribution over unobserved data. To overcome these limitations, we introduce Energy-Based Processes (EBPs), which extend energy based models to exchangeable data while allowing neural network parameterizations of the energy function. A key advantage of these models is the ability to express more flexible distributions over sets without restricting their cardinality. We develop an efficient training procedure for EBPs that demonstrates state-of-the-art performance on a variety of tasks such as point cloud generation, classification, denoising, and image completion
[ Virtual ]
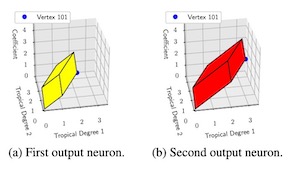
The field of tropical algebra is closely linked with the domain of neural networks with piecewise linear activations, since their output can be described via tropical polynomials in the max-plus semiring. In this work, we attempt to make use of methods stemming from a form of approximate division of such polynomials, which relies on the approximation of their Newton Polytopes, in order to minimize networks trained for multiclass classification problems. We make theoretical contributions in this domain, by proposing and analyzing methods which seek to reduce the size of such networks. In addition, we make experimental evaluations on the MNIST and Fashion-MNIST datasets, with our results demonstrating a significant reduction in network size, while retaining adequate performance.

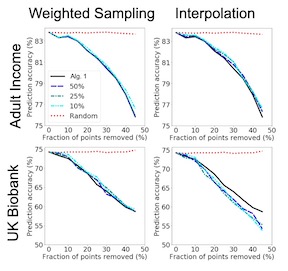
Shapley value is a classic notion from game theory, historically used to quantify the contributions of individuals within groups, and more recently applied to assign values to data points when training machine learning models. Despite its foundational role, a key limitation of the data Shapley framework is that it only provides valuations for points within a fixed data set. It does not account for statistical aspects of the data and does not give a way to reason about points outside the data set. To address these limitations, we propose a novel framework -- distributional Shapley -- where the value of a point is defined in the context of an underlying data distribution. We prove that distributional Shapley has several desirable statistical properties; for example, the values are stable under perturbations to the data points themselves and to the underlying data distribution. We leverage these properties to develop a new algorithm for estimating values from data, which comes with formal guarantees and runs two orders of magnitude faster than state-of-the-art algorithms for computing the (non-distributional) data Shapley values. We apply distributional Shapley to diverse data sets and demonstrate its utility in a data market setting.
Unsupervised domain adaptation (UDA) aims to leverage the knowledge learned from a labeled source dataset to solve similar tasks in a new unlabeled domain. Prior UDA methods typically require to access the source data when learning to adapt the model, making them risky and inefficient for decentralized private data. This work tackles a novel setting where only a trained source model is available and investigates how we can effectively utilize such a model without source data to solve UDA problems. We propose a simple yet generic representation learning framework, named Source HypOthesis Transfer (SHOT). SHOT freezes the classifier module (hypothesis) of the source model and learns the target-specific feature extraction module by exploiting both information maximization and self-supervised pseudo-labeling to implicitly align representations from the target domains to the source hypothesis. To verify its versatility, we evaluate SHOT in a variety of adaptation cases including closed-set, partial-set, and open-set domain adaptation. Experiments indicate that SHOT yields state-of-the-art results among multiple domain adaptation benchmarks.
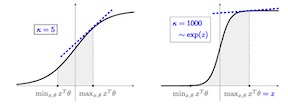
In this work, we propose WaveFlow, a small-footprint generative flow for raw audio, which is directly trained with maximum likelihood. It handles the long-range structure of 1-D waveform with a dilated 2-D convolutional architecture, while modeling the local variations using expressive autoregressive functions. WaveFlow provides a unified view of likelihood-based models for 1-D data, including WaveNet and WaveGlow as special cases. It generates high-fidelity speech as WaveNet, while synthesizing several orders of magnitude faster as it only requires a few sequential steps to generate very long waveforms with hundreds of thousands of time-steps. Furthermore, it can significantly reduce the likelihood gap that has existed between autoregressive models and flow-based models for efficient synthesis. Finally, our small-footprint WaveFlow has only 5.91M parameters, which is 15× smaller than WaveGlow. It can generate 22.05 kHz high-fidelity audio 42.6× faster than real-time (at a rate of 939.3 kHz) on a V100 GPU without engineered inference kernels.
[ Virtual ]

Inter-domain Gaussian processes (GPs) allow for high flexibility and low computational cost when performing approximate inference in GP models. They are particularly suitable for modeling data exhibiting global structure but are limited to stationary covariance functions and thus fail to model non-stationary data effectively. We propose Inter-domain Deep Gaussian Processes, an extension of inter-domain shallow GPs that combines the advantages of inter-domain and deep Gaussian processes (DGPs), and demonstrate how to leverage existing approximate inference methods to perform simple and scalable approximate inference using inter-domain features in DGPs. We assess the performance of our method on a range of regression tasks and demonstrate that it outperforms inter-domain shallow GPs and conventional DGPs on challenging large-scale real-world datasets exhibiting both global structure as well as a high-degree of non-stationarity.
[ Virtual ]
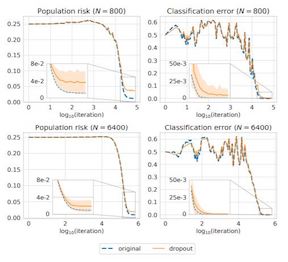
The optimization of multilayer neural networks typically leads to a solution with zero training error, yet the landscape can exhibit spurious local minima and the minima can be disconnected. In this paper, we shed light on this phenomenon: we show that the combination of stochastic gradient descent (SGD) and over-parameterization makes the landscape of multilayer neural networks approximately connected and thus more favorable to optimization. More specifically, we prove that SGD solutions are connected via a piecewise linear path, and the increase in loss along this path vanishes as the number of neurons grows large. This result is a consequence of the fact that the parameters found by SGD are increasingly dropout stable as the network becomes wider. We show that, if we remove part of the neurons (and suitably rescale the remaining ones), the change in loss is independent of the total number of neurons, and it depends only on how many neurons are left. Our results exhibit a mild dependence on the input dimension: they are dimension-free for two-layer networks and require the number of neurons to scale linearly with the dimension for multilayer networks. We validate our theoretical findings with numerical experiments for different architectures and classification …
[ Virtual ]
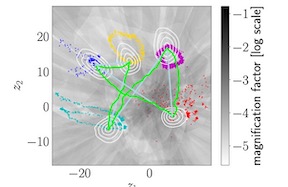
Measuring the similarity between data points often requires domain knowledge, which can in parts be compensated by relying on unsupervised methods such as latent-variable models, where similarity/distance is estimated in a more compact latent space. Prevalent is the use of the Euclidean metric, which has the drawback of ignoring information about similarity of data stored in the decoder, as captured by the framework of Riemannian geometry. We propose an extension to the framework of variational auto-encoders allows learning flat latent manifolds, where the Euclidean metric is a proxy for the similarity between data points. This is achieved by defining the latent space as a Riemannian manifold and by regularising the metric tensor to be a scaled identity matrix. Additionally, we replace the compact prior typically used in variational auto-encoders with a recently presented, more expressive hierarchical one---and formulate the learning problem as a constrained optimisation problem. We evaluate our method on a range of data-sets, including a video-tracking benchmark, where the performance of our unsupervised approach nears that of state-of-the-art supervised approaches, while retaining the computational efficiency of straight-line-based approaches.
[ Virtual ]
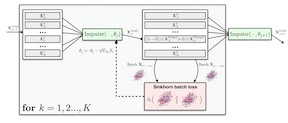
Missing data is a crucial issue when applying machine learning algorithms to real-world datasets. Starting from the simple assumption that two batches extracted randomly from the same dataset should share the same distribution, we leverage optimal transport distances to quantify that criterion and turn it into a loss function to impute missing data values. We propose practical methods to minimize these losses using end-to-end learning, that can exploit or not parametric assumptions on the underlying distributions of values. We evaluate our methods on datasets from the UCI repository, in MCAR, MAR and MNAR settings. These experiments show that OT-based methods match or out-perform state-of-the-art imputation methods, even for high percentages of missing values.
[ Virtual ]
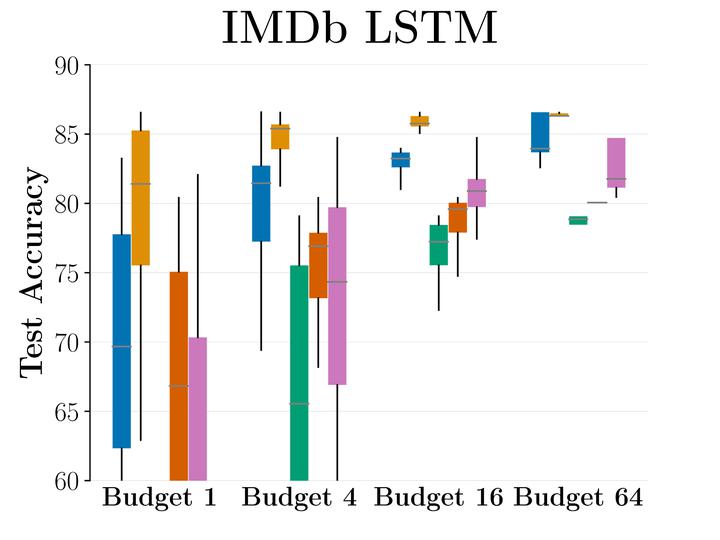
The performance of optimizers, particularly in deep learning, depends considerably on their chosen hyperparameter configuration. The efficacy of optimizers is often studied under near-optimal problem-specific hyperparameters, and finding these settings may be prohibitively costly for practitioners. In this work, we argue that a fair assessment of optimizers' performance must take the computational cost of hyperparameter tuning into account, i.e., how easy it is to find good hyperparameter configurations using an automatic hyperparameter search. Evaluating a variety of optimizers on an extensive set of standard datasets and architectures, our results indicate that Adam is the most practical solution, particularly in low-budget scenarios.
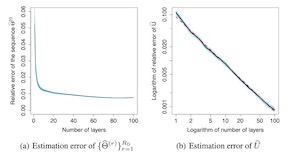
Entities often interact with each other through multiple types of relations, which are often represented as multilayer networks. Multilayer networks among the same set of nodes usually share common structures, while each layer can possess its distinct node connecting behaviors. This paper proposes a flexible latent space model for multilayer networks for the purpose of capturing such characteristics. Specifically, the proposed model embeds each node with a latent vector shared among layers and a layer-specific effect for each layer; both elements together with a layer-specific connectivity matrix determine edge formations. To fit the model, we develop a projected gradient descent algorithm for efficient parameter estimation. We also establish theoretical properties of the maximum likelihood estimators and show that the upper bound of the common latent structure's estimation error is inversely proportional to the number of layers under mild conditions. The superior performance of the proposed model is demonstrated through simulation studies and applications to two real-world data examples.

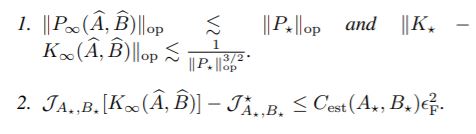

A well-documented weakness of neural networks is the fact that they suffer from catastrophic forgetting when trained on data provided by a non-stationary distribution. Recent work in the field of continual learning attempts to understand and overcome this issue. Unfortunately, the majority of relevant work embraces the implicit assumption that the distribution of observed data is perfectly balanced, despite the fact that, in the real world, humans and animals learn from observations that are temporally correlated and severely imbalanced. Motivated by this remark, we aim to evaluate memory population methods that are used in online continual learning, when dealing with highly imbalanced and temporally correlated streams of data. More importantly, we introduce a new memory population approach, which we call class-balancing reservoir sampling (CBRS). We demonstrate that CBRS outperforms the state-of-the-art memory population algorithms in a considerably challenging learning setting, over a range of different datasets, and for multiple architectures.
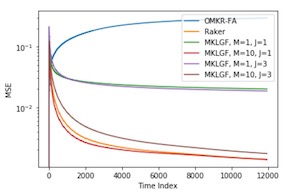
Multi-kernel learning (MKL) exhibits reliable performance in nonlinear function approximation tasks. Instead of using one kernel, it learns the optimal kernel from a pre-selected dictionary of kernels. The selection of the dictionary has crucial impact on both the performance and complexity of MKL. Specifically, inclusion of a large number of irrelevant kernels may impair the accuracy, and increase the complexity of MKL algorithms. To enhance the accuracy, and alleviate the computational burden, the present paper develops a novel scheme which actively chooses relevant kernels. The proposed framework models the pruned kernel combination as feedback collected from a graph, that is refined 'on the fly.' Leveraging the random feature approximation, we propose an online scalable multi-kernel learning approach with graph feedback, and prove that the proposed algorithm enjoys sublinear regret. Numerical tests on real datasets demonstrate the effectiveness of the novel approach.

Thompson sampling for multi-armed bandit problems is known to enjoy favorable performance in both theory and practice, though it suffers from a significant limitation computationally arising from the need for samples from posterior distributions at every iteration. To address this issue, we propose two Markov Chain Monte Carlo (MCMC) methods tailored to Thompson sampling. We construct quickly converging Langevin algorithms to generate approximate samples that have accuracy guarantees, and leverage novel posterior concentration rates to analyze the regret of the resulting approximate Thompson sampling algorithm. Further, we specify the necessary hyperparameters for the MCMC procedure to guarantee optimal instance-dependent frequentist regret while having low computational complexity. In particular, our algorithms take advantage of both posterior concentration and a sample reuse mechanism to ensure that only a constant number of iterations and a constant amount of data is needed in each round. The resulting approximate Thompson sampling algorithm has logarithmic regret and its computational complexity does not scale with the time horizon of the algorithm.
We study regularization in the context of small sample-size learning with over-parametrized neural networks. Specifically, we shift focus from architectural properties, such as norms on the network weights, to properties of the internal representations before a linear classifier. Specifically, we impose a topological constraint on samples drawn from the probability measure induced in that space. This provably leads to mass concentration effects around the representations of training instances, i.e., a property beneficial for generalization. By leveraging previous work to impose topological constrains in a neural network setting, we provide empirical evidence (across various vision benchmarks) to support our claim for better generalization.
Poster Session 54 Fri 17 Jul 09:00 a.m.
[ Virtual ]
A Relational Markov Decision Process (RMDP) is a first-order representation to express all instances of a single probabilistic planning domain with possibly unbounded number of objects. Early work in RMDPs outputs generalized (instance-independent) first-order policies or value functions as a means to solve all instances of a domain at once. Unfortunately, this line of work met with limited success due to inherent limitations of the representation space used in such policies or value functions. Can neural models provide the missing link by easily representing more complex generalized policies, thus making them effective on all instances of a given domain?
We present SymNet, the first neural approach for solving RMDPs that are expressed in the probabilistic planning language of RDDL. SymNet trains a set of shared parameters for an RDDL domain using training instances from that domain. For each instance, SymNet first converts it to an instance graph and then uses relational neural models to compute node embeddings. It then scores each ground action as a function over the first-order action symbols and node embeddings related to the action. Given a new test instance from the same domain, SymNet architecture with pre-trained parameters scores each ground action and chooses the best …

The latent spaces of GAN models often have semantically meaningful directions. Moving in these directions corresponds to human-interpretable image transformations, such as zooming or recoloring, enabling a more controllable generation process. However, the discovery of such directions is currently performed in a supervised manner, requiring human labels, pretrained models, or some form of self-supervision. These requirements severely restrict a range of directions existing approaches can discover. In this paper, we introduce an unsupervised method to identify interpretable directions in the latent space of a pretrained GAN model. By a simple model-agnostic procedure, we find directions corresponding to sensible semantic manipulations without any form of (self-)supervision. Furthermore, we reveal several non-trivial findings, which would be difficult to obtain by existing methods, e.g., a direction corresponding to background removal. As an immediate practical benefit of our work, we show how to exploit this finding to achieve competitive performance for weakly-supervised saliency detection. The implementation of our method is available online.
[ Virtual ]
Planning in Partially Observable Markov Decision Processes (POMDPs) inherently gathers the information necessary to act optimally under uncertainties. The framework can be extended to model pure information gathering tasks by considering belief-based rewards. This allows us to use reward shaping to guide POMDP planning to informative beliefs by using a weighted combination of the original reward and the expected information gain as the objective. In this work we propose a novel online algorithm, Information Particle Filter Tree (IPFT), to solve problems with belief-dependent rewards on continuous domains. It simulates particle-based belief trajectories in a Monte Carlo Tree Search (MCTS) approach to construct a search tree in the belief space. The evaluation shows that the consideration of information gain greatly improves the performance in problems where information gathering is an essential part of the optimal policy.
[ Virtual ]

Sparsity in Deep Neural Networks (DNNs) is studied extensively with the focus of maximizing prediction accuracy given an overall parameter budget. Existing methods rely on uniform or heuristic non-uniform sparsity budgets which have sub-optimal layer-wise parameter allocation resulting in a) lower prediction accuracy or b) higher inference cost (FLOPs). This work proposes Soft Threshold Reparameterization (STR), a novel use of the soft-threshold operator on DNN weights. STR smoothly induces sparsity while learning pruning thresholds thereby obtaining a non-uniform sparsity budget. Our method achieves state-of-the-art accuracy for unstructured sparsity in CNNs (ResNet50 and MobileNetV1 on ImageNet-1K), and, additionally, learns non-uniform budgets that empirically reduce the FLOPs by up to 50%. Notably, STR boosts the accuracy over existing results by up to 10% in the ultra sparse (99%) regime and can also be used to induce low-rank (structured sparsity) in RNNs. In short, STR is a simple mechanism which learns effective sparsity budgets that contrast with popular heuristics. Code, pretrained models and sparsity budgets are at https://github.com/RAIVNLab/STR.
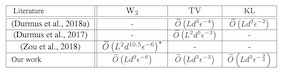
Motivated by applications to online advertising and recommender systems, we consider a game-theoretic model with delayed rewards and asynchronous, payoff-based feedback. In contrast to previous work on delayed multi-armed bandits, we focus on games with continuous action spaces, and we examine the long-run behavior of strategic agents that follow a no-regret learning policy (but are otherwise oblivious to the game being played, the objectives of their opponents, etc.). To account for the lack of a consistent stream of information (for instance, rewards can arrive out of order and with an a priori unbounded delay), we introduce a gradient-free learning policy where payoff information is placed in a priority queue as it arrives. Somewhat surprisingly, we find that under a standard diagonal concavity assumption, the induced sequence of play converges to Nash Equilibrium (NE) with probability 1, even if the delay between choosing an action and receiving the corresponding reward is unbounded.
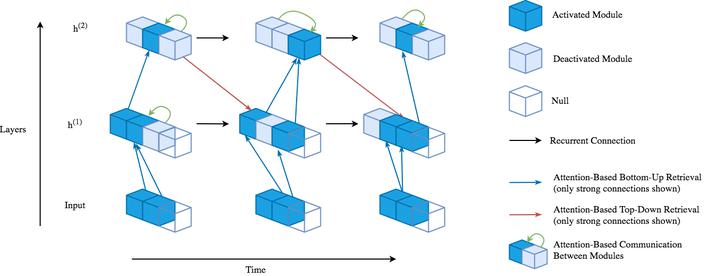
Robust perception relies on both bottom-up and top-down signals. Bottom-up signals consist of what's directly observed through sensation. Top-down signals consist of beliefs and expectations based on past experience and the current reportable short-term memory, such as how the phrase `peanut butter and ...' will be completed. The optimal combination of bottom-up and top-down information remains an open question, but the manner of combination must be dynamic and both context and task dependent. To effectively utilize the wealth of potential top-down information available, and to prevent the cacophony of intermixed signals in a bidirectional architecture, mechanisms are needed to restrict information flow. We explore deep recurrent neural net architectures in which bottom-up and top-down signals are dynamically combined using attention. Modularity of the architecture further restricts the sharing and communication of information. Together, attention and modularity direct information flow, which leads to reliable performance improvements in perceptual and language tasks, and in particular improves robustness to distractions and noisy data. We demonstrate on a variety of benchmarks in language modeling, sequential image classification, video prediction and reinforcement learning that the \emph{bidirectional} information flow can improve results over strong baselines.
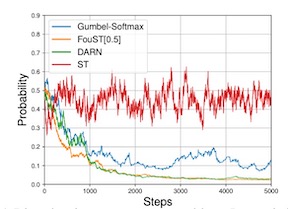
Stochastic neural networks with discrete random variables are an important class of models for their expressiveness and interpretability. Since direct differentiation and backpropagation is not possible, Monte Carlo gradient estimation techniques are a popular alternative. Efficient stochastic gradient estimators, such Straight-Through and Gumbel-Softmax, work well for shallow stochastic models. Their performance, however, suffers with hierarchical, more complex models.
We focus on hierarchical stochastic networks with multiple layers of Boolean latent variables. To analyze such networks, we introduce the framework of harmonic analysis for Boolean functions to derive an analytic formulation for the bias and variance in the Straight-Through estimator. Exploiting these formulations, we propose \emph{FouST}, a low-bias and low-variance gradient estimation algorithm that is just as efficient. Extensive experiments show that FouST performs favorably compared to state-of-the-art biased estimators and is much faster than unbiased ones.
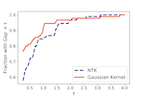
We investigate the connections between neural networks and simple building blocks in kernel space. In particular, using well established feature space tools such as direct sum, averaging, and moment lifting, we present an algebra for creating “compositional” kernels from bags of features. We show that these operations correspond to many of the building blocks of “neural tangent kernels (NTK)”. Experimentally, we show that there is a correlation in test error between neural network architectures and the associated kernels. We construct a simple neural network architecture using only 3x3 convolutions, 2x2 average pooling, ReLU, and optimized with SGD and MSE loss that achieves 96% accuracy on CIFAR10, and whose corresponding compositional kernel achieves 90% accuracy. We also use our constructions to investigate the relative performance of neural networks, NTKs, and compositional kernels in the small dataset regime. In particular, we find that compositional kernels outperform NTKs and neural networks outperform both kernel methods.
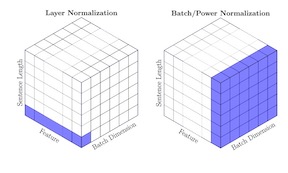
The standard normalization method for neural network (NN) models used in Natural Language Processing (NLP) is layer normalization (LN).This is different than batch normalization (BN), which is widely-adopted in Computer Vision. The preferred use of LN in NLP is principally due to the empirical observation that a (naive/vanilla) use of BN leads to significant performance degradation for NLP tasks; however, a thorough understanding of the underlying reasons for this is not always evident. In this paper, we perform a systematic study of NLP transformer models to understand why BN has a poor performance, as compared to LN. We find that the statistics of NLP data across the batch dimension exhibit large fluctuations throughout training. This results in instability, if BN is naively implemented. To address this, we propose Power Normalization (PN), a novel normalization scheme that resolves this issue by (i) relaxing zero-mean normalization in BN, (ii) incorporating a running quadratic mean instead of per batch statistics to stabilize fluctuations, and (iii) using an approximate backpropagation for incorporating the running statistics in the forward pass. We show theoretically, under mild assumptions, that PN leads to a smaller Lipschitz constant for the loss, compared with BN. Furthermore, we prove that the …
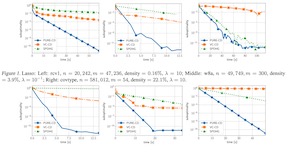
We introduce a randomly extrapolated primal-dual coordinate descent method that adapts to sparsity of the data matrix and the favorable structures of the objective function. Our method updates only a subset of primal and dual variables with sparse data, and it uses large step sizes with dense data, retaining the benefits of the specific methods designed for each case. In addition to adapting to sparsity, our method attains fast convergence guarantees in favorable cases \textit{without any modifications}. In particular, we prove linear convergence under metric subregularity, which applies to strongly convex-strongly concave problems, linear programs and piecewise linear quadratic functions. We show almost sure convergence of the sequence and optimal sublinear convergence rates for the primal-dual gap and objective values, in the general convex-concave case. Numerical evidence demonstrates the state-of-the-art empirical performance of our method in sparse and dense settings, matching and improving the existing methods.
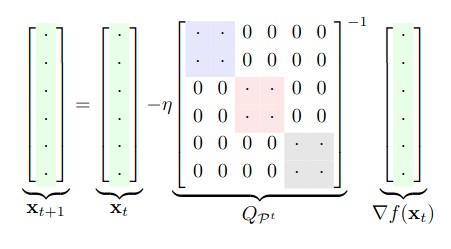
We study preconditioned gradient-based optimization methods where the preconditioning matrix has block-diagonal form. Such a structural constraint comes with the advantage that the update computation can be parallelized across multiple independent tasks. Our main contribution is to demonstrate that the convergence of these methods can significantly be improved by a randomization technique which corresponds to repartitioning coordinates across tasks during the optimization procedure. We provide a theoretical analysis that accurately characterizes the expected convergence gains of repartitioning and validate our findings empirically on various traditional machine learning tasks. From an implementation perspective, block-separable models are well suited for parallelization and, when shared memory is available, randomization can be implemented on top of existing methods very efficiently to improve convergence.
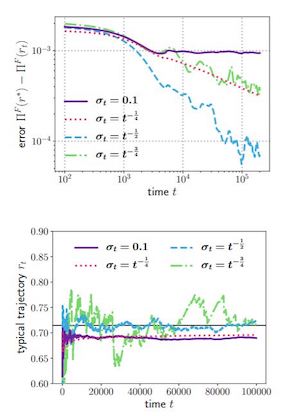
In display advertising, a small group of sellers and bidders face each other in up to 10^{12} auctions a day. In this context, revenue maximisation via monopoly price learning is a high-value problem for sellers. By nature, these auctions are online and produce a very high frequency stream of data. This results in a computational strain that requires algorithms be real-time. Unfortunately, existing methods, inherited from the batch setting, suffer O(\sqrt(t)) time/memory complexity at each update, prohibiting their use. In this paper, we provide the first algorithm for online learning of monopoly prices in online auctions whose update is constant in time and memory.
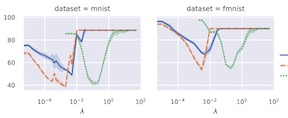
We demonstrate two new important properties of the 1-path-norm of shallow neural networks. First, despite its non-smoothness and non-convexity it allows a closed form proximal operator which can be efficiently computed, allowing the use of stochastic proximal-gradient-type methods for regularized empirical risk minimization. Second, when the activation functions is differentiable, it provides an upper bound on the Lipschitz constant of the network. Such bound is tighter than the trivial layer-wise product of Lipschitz constants, motivating its use for training networks robust to adversarial perturbations. In practical experiments we illustrate the advantages of using the proximal mapping and we compare the robustness-accuracy trade-off induced by the 1-path-norm, L1-norm and layer-wise constraints on the Lipschitz constant (Parseval networks).
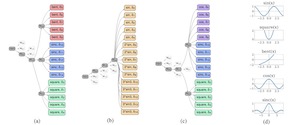
Training multiple tasks jointly in one deep network yields reduced latency during inference and better performance over the single-task counterpart by sharing certain layers of a network. However, over-sharing a network could erroneously enforce over-generalization, causing negative knowledge transfer across tasks. Prior works rely on human intuition or pre-computed task relatedness scores for ad hoc branching structures. They provide sub-optimal end results and often require huge efforts for the trial-and-error process.
In this work, we present an automated multi-task learning algorithm that learns where to share or branch within a network, designing an effective network topology that is directly optimized for multiple objectives across tasks. Specifically, we propose a novel tree-structured design space that casts a tree branching operation as a gumbel-softmax sampling procedure. This enables differentiable network splitting that is end-to-end trainable. We validate the proposed method on controlled synthetic data, CelebA, and Taskonomy.



In this paper we introduce a new approach to topic modelling that scales to
large datasets by using a compact representation of the data and by
leveraging the GPU architecture.
In this approach, topics are learned directly from the
co-occurrence data of the corpus. In particular, we introduce a novel
mixture model which we term the Full Dependence Mixture (FDM) model.
FDMs model second moment under general generative
assumptions on the data. While there is previous work on topic
modeling using second moments, we develop a direct stochastic
optimization procedure for fitting an FDM with a single Kullback
Leibler objective. Moment methods in general have the benefit that
an iteration no longer needs to scale with the size of the corpus.
Our approach allows us to leverage standard
optimizers and GPUs for the problem of topic modeling. In
particular, we evaluate the approach on two large datasets,
NeurIPS papers and a Twitter corpus, with a large number of
topics, and show that the approach performs comparably or better than the standard benchmarks.
Poster Session 55 Fri 17 Jul 10:00 a.m.
[ Virtual ]
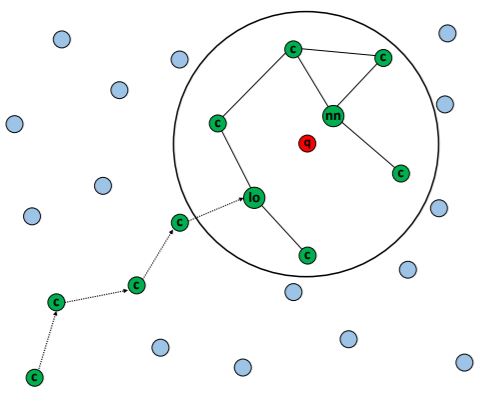

We develop an extension of the knockoff inference procedure, introduced by Barber & Candes (2015). This new method, called Aggregation of Multiple Knockoffs (AKO), addresses the instability inherent to the random nature of knockoff-based inference. Specifically, AKO improves both the stability and power compared with the original knockoff algorithm while still maintaining guarantees for false discovery rate control. We provide a new inference procedure, prove its core properties, and demonstrate its benefits in a set of experiments on synthetic and real datasets.
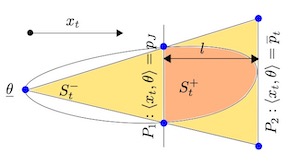
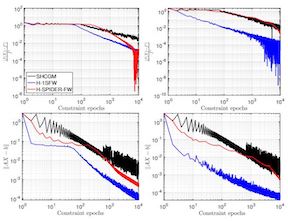
We propose two novel conditional gradient-based methods for solving structured stochastic convex optimization problems with a large number of linear constraints. Instances of this template naturally arise from SDP-relaxations of combinatorial problems, which involve a number of constraints that is polynomial in the problem dimension. The most important feature of our framework is that only a subset of the constraints is processed at each iteration, thus gaining a computational advantage over prior works that require full passes. Our algorithms rely on variance reduction and smoothing used in conjunction with conditional gradient steps, and are accompanied by rigorous convergence guarantees. Preliminary numerical experiments are provided for illustrating the practical performance of the methods.
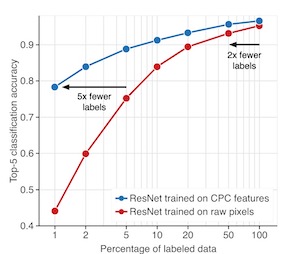
Human observers can learn to recognize new categories of images from a handful of examples, yet doing so with artificial ones remains an open challenge. We hypothesize that data-efficient recognition is enabled by representations which make the variability in natural signals more predictable. We therefore revisit and improve Contrastive Predictive Coding, an unsupervised objective for learning such representations. This new implementation produces features which support state-of-the-art linear classification accuracy on the ImageNet dataset. When used as input for non-linear classification with deep neural networks, this representation allows us to use 2-5x less labels than classifiers trained directly on image pixels. Finally, this unsupervised representation substantially improves transfer learning to object detection on the PASCAL VOC dataset, surpassing fully supervised pre-trained ImageNet classifiers.

Deep learning models achieve high predictive accuracy across a broad spectrum of tasks, but rigorously quantifying their predictive uncertainty remains challenging. Usable estimates of predictive uncertainty should (1) cover the true prediction targets with high probability, and (2) discriminate between high- and low confidence prediction instances. Existing methods for uncertainty quantification are based predominantly on Bayesian neural networks; these may fall short of (1) and (2) — i.e., Bayesian credible intervals do not guarantee frequentist coverage, and approximate posterior inference undermines discriminative accuracy. In this paper, we develop the discriminative jackknife (DJ), a frequentist procedure that utilizes influence functions of a model’s loss functional to construct a jackknife (or leave one-out) estimator of predictive confidence intervals. The DJ satisfies (1) and (2), is applicable to a wide range of deep learning models, is easy to implement, and can be applied in a post-hoc fashion without interfering with model training or compromising its accuracy. Experiments demonstrate that DJ performs competitively compared to existing Bayesian and non-Bayesian regression baselines.
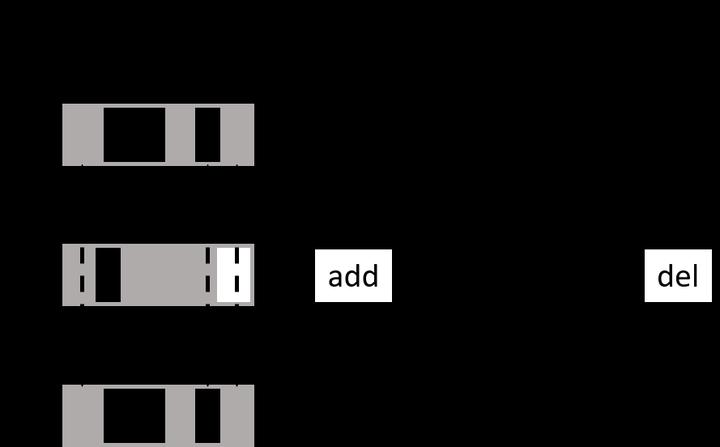
Existing techniques for certifying the robustness of models for discrete data either work only for a small class of models or are general at the expense of efficiency or tightness. Moreover, they do not account for sparsity in the input which, as our findings show, is often essential for obtaining non-trivial guarantees. We propose a model-agnostic certificate based on the randomized smoothing framework which subsumes earlier work and is tight, efficient, and sparsity-aware. Its computational complexity does not depend on the number of discrete categories or the dimension of the input (e.g. the graph size), making it highly scalable. We show the effectiveness of our approach on a wide variety of models, datasets, and tasks -- specifically highlighting its use for Graph Neural Networks. So far, obtaining provable guarantees for GNNs has been difficult due to the discrete and non-i.i.d. nature of graph data. Our method can certify any GNN and handles perturbations to both the graph structure and the node attributes.
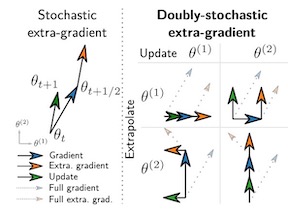
Data-driven modeling increasingly requires to find a Nash equilibrium in multi-player games, e.g. when training GANs. In this paper, we analyse a new extra-gradient method for Nash equilibrium finding, that performs gradient extrapolations and updates on a random subset of players at each iteration. This approach provably exhibits a better rate of convergence than full extra-gradient for non-smooth convex games with noisy gradient oracle. We propose an additional variance reduction mechanism to obtain speed-ups in smooth convex games. Our approach makes extrapolation amenable to massive multiplayer settings, and brings empirical speed-ups, in particular when using a heuristic cyclic sampling scheme. Most importantly, it allows to train faster and better GANs and mixtures of GANs.
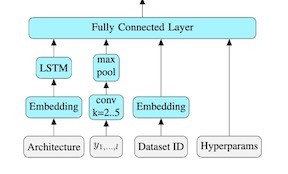
Many automated machine learning methods, such as those for hyperparameter and neural architecture optimization, are computationally expensive because they involve training many different model configurations. In this work, we present a new method that saves computational budget by terminating poor configurations early on in the training. In contrast to existing methods, we consider this task as a ranking and transfer learning problem. We qualitatively show that by optimizing a pairwise ranking loss and leveraging learning curves from other data sets, our model is able to effectively rank learning curves without having to observe many or very long learning curves. We further demonstrate that our method can be used to accelerate a neural architecture search by a factor of up to 100 without a significant performance degradation of the discovered architecture. In further experiments we analyze the quality of ranking, the influence of different model components as well as the predictive behavior of the model.
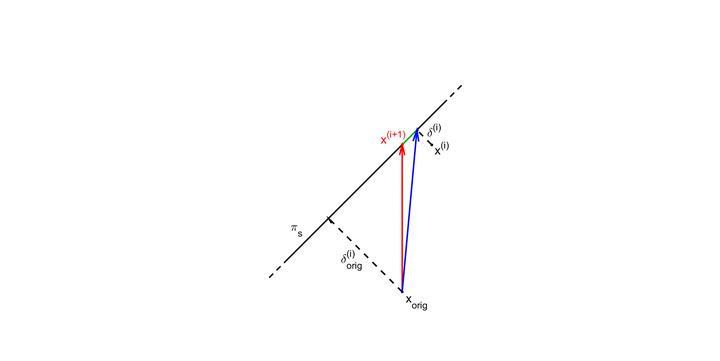
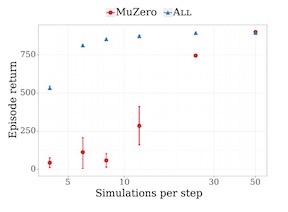
The combination of Monte-Carlo tree search (MCTS) with deep reinforcement learning has led to groundbreaking results in artificial intelligence. However, AlphaZero, the current state-of-the-art MCTS algorithm still relies on handcrafted heuristics that are only partially understood. In this paper, we show that AlphaZero's search heuristic, along with other common ones, can be interpreted as an approximation to the solution of a specific regularized policy optimization problem. With this insight, we propose a variant of AlphaZero which uses the exact solution to this policy optimization problem, and show experimentally that it reliably outperforms the original algorithm in multiple domains.
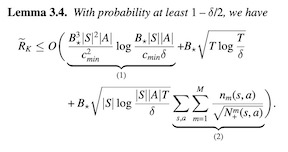
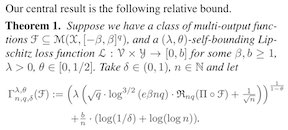
We investigate the challenge of multi-output learning, where the goal is to learn a vector-valued function based on a supervised data set. This includes a range of important problems in Machine Learning including multi-target regression, multi-class classification and multi-label classification. We begin our analysis by introducing the self-bounding Lipschitz condition for multi-output loss functions, which interpolates continuously between a classical Lipschitz condition and a multi-dimensional analogue of a smoothness condition. We then show that the self-bounding Lipschitz condition gives rise to optimistic bounds for multi-output learning, which attain the minimax optimal rate up to logarithmic factors. The proof exploits local Rademacher complexity combined with a powerful minoration inequality due to Srebro, Sridharan and Tewari. As an application we derive a state-of-the-art generalisation bound for multi-class gradient boosting.

Recent work pre-training Transformers with self-supervised objectives on large text corpora has shown great success when fine-tuned on downstream NLP tasks including text summarization. However, pre-training objectives tailored for abstractive text summarization have not been explored. Furthermore there is a lack of systematic evaluation across diverse domains. In this work, we propose pre-training large Transformer-based encoder-decoder models on massive text corpora with a new self-supervised objective. In PEGASUS, important sentences are removed/masked from an input document and are generated together as one output sequence from the remaining sentences, similar to an extractive summary. We evaluated our best PEGASUS model on 12 downstream summarization tasks spanning news, science, stories, instructions, emails, patents, and legislative bills. Experiments demonstrate it achieves state-of-the-art performance on all 12 downstream datasets measured by ROUGE scores. Our model also shows surprising performance on low-resource summarization, surpassing previous state-of-the-art results on 6 datasets with only 1000 examples. Finally we validated our results using human evaluation and show that our model summaries achieve human performance on multiple datasets.
High-dimensional observations and unknown dynamics are major challenges when applying optimal control to many real-world decision making tasks. The Learning Controllable Embedding (LCE) framework addresses these challenges by embedding the observations into a lower dimensional latent space, estimating the latent dynamics, and then performing control directly in the latent space. To ensure the learned latent dynamics are predictive of next-observations, all existing LCE approaches decode back into the observation space and explicitly perform next-observation prediction---a challenging high-dimensional task that furthermore introduces a large number of nuisance parameters (i.e., the decoder) which are discarded during control. In this paper, we propose a novel information-theoretic LCE approach and show theoretically that explicit next-observation prediction can be replaced with predictive coding. We then use predictive coding to develop a decoder-free LCE model whose latent dynamics are amenable to locally-linear control. Extensive experiments on benchmark tasks show that our model reliably learns a controllable latent space that leads to superior performance when compared with state-of-the-art LCE baselines.

Deep Metric Learning (DML) is arguably one of the most influential lines of research for learning visual similarities with many proposed approaches every year. Although the field benefits from the rapid progress, the divergence in training protocols, architectures, and parameter choices make an unbiased comparison difficult. To provide a consistent reference point, we revisit the most widely used DML objective functions and conduct a study of the crucial parameter choices as well as the commonly neglected mini-batch sampling process. Under consistent comparison, DML objectives show much higher saturation than indicated by literature. Further based on our analysis, we uncover a correlation between the embedding space density and compression to the generalization performance of DML models. Exploiting these insights, we propose a simple, yet effective, training regularization to reliably boost the performance of ranking-based DML models on various standard benchmark datasets; code and a publicly accessible WandB-repo are available at https://github.com/Confusezius/RevisitingDeepMetricLearningPyTorch.
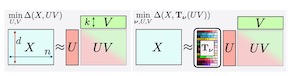
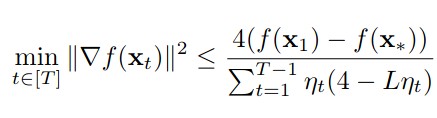
Variational Bayesian Inference is a popular methodology for approximating posterior distributions over Bayesian neural network weights. Recent work developing this class of methods has explored ever richer parameterizations of the approximate posterior in the hope of improving performance. In contrast, here we share a curious experimental finding that suggests instead restricting the variational distribution to a more compact parameterization. For a variety of deep Bayesian neural networks trained using Gaussian mean-field variational inference, we find that the posterior standard deviations consistently exhibit strong low-rank structure after convergence. This means that by decomposing these variational parameters into a low-rank factorization, we can make our variational approximation more compact without decreasing the models' performance. Furthermore, we find that such factorized parameterizations improve the signal-to-noise ratio of stochastic gradient estimates of the variational lower bound, resulting in faster convergence.
[ Virtual ]

Designing video prediction models that account for the inherent uncertainty of the future is challenging. Most works in the literature are based on stochastic image-autoregressive recurrent networks, which raises several performance and applicability issues. An alternative is to use fully latent temporal models which untie frame synthesis and temporal dynamics. However, no such model for stochastic video prediction has been proposed in the literature yet, due to design and training difficulties. In this paper, we overcome these difficulties by introducing a novel stochastic temporal model whose dynamics are governed in a latent space by a residual update rule. This first-order scheme is motivated by discretization schemes of differential equations. It naturally models video dynamics as it allows our simpler, more interpretable, latent model to outperform prior state-of-the-art methods on challenging datasets.

Bayesian optimization (BO) is a popular methodology to tune the hyperparameters of expensive black-box functions. Traditionally, BO focuses on a single task at a time and is not designed to leverage information from related functions, such as tuning performance objectives of the same algorithm across multiple datasets. In this work, we introduce a novel approach to achieve transfer learning across different datasets as well as different objectives. The main idea is to regress the mapping from hyperparameter to objective quantiles with a semi-parametric Gaussian Copula distribution, which provides robustness against different scales or outliers that can occur in different tasks. We introduce two methods to leverage this estimation: a Thompson sampling strategy as well as a Gaussian Copula process using such quantile estimate as a prior. We show that these strategies can combine the estimation of multiple objectives such as latency and accuracy, steering the optimization toward faster predictions for the same level of accuracy. Experiments on an extensive set of hyperparameter tuning tasks demonstrate significant improvements over state-of-the-art methods for both hyperparameter optimization and neural architecture search.
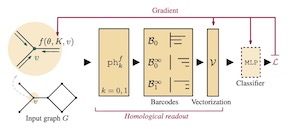
We propose an approach to learning with graph-structured data in the problem domain of graph classification. In particular, we present a novel type of readout operation to aggregate node features into a graph-level representation. To this end, we leverage persistent homology computed via a real-valued, learnable, filter function. We establish the theoretical foundation for differentiating through the persistent homology computation. Empirically, we show that this type of readout operation compares favorably to previous techniques, especially when the graph connectivity structure is informative for the learning problem.
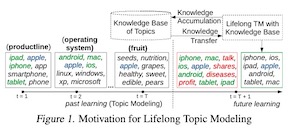
Lifelong learning has recently attracted attention in building machine learning systems that continually accumulate and transfer knowledge to help future learning. Unsupervised topic modeling has been popularly used to discover topics from document collections. However, the application of topic modeling is challenging due to data sparsity, e.g., in a small collection of (short) documents and thus, generate incoherent topics and sub-optimal document representations. To address the problem, we propose a lifelong learning framework for neural topic modeling that can continuously process streams of document collections, accumulate topics and guide future topic modeling tasks by knowledge transfer from several sources to better deal with the sparse data. In the lifelong process, we particularly investigate jointly: (1) sharing generative homologies (latent topics) over lifetime to transfer prior knowledge, and (2) minimizing catastrophic forgetting to retain the past learning via novel selective data augmentation, co-training and topic regularization approaches. Given a stream of document collections, we apply the proposed Lifelong Neural Topic Modeling (LNTM) framework in modeling three sparse document collections as future tasks and demonstrate improved performance quantified by perplexity, topic coherence and information retrieval task. Code: https://github.com/pgcool/Lifelong-Neural-Topic-Modeling
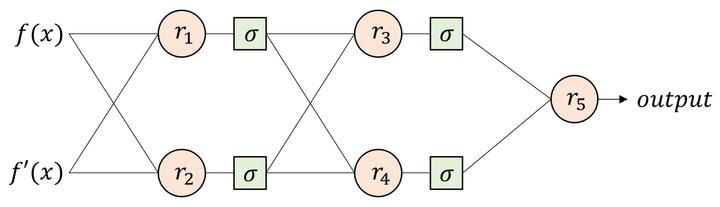
Providing users with alternatives to choose from is an essential component of many online platforms, making the accurate prediction of choice vital to their success. A renewed interest in learning choice models has led to improved modeling power, but most current methods are either limited in the type of choice behavior they capture, cannot be applied to large-scale data, or both.
Here we propose a learning framework for predicting choice that is accurate, versatile, and theoretically grounded. Our key modeling point is that to account for how humans choose, predictive models must be expressive enough to accommodate complex choice patterns but structured enough to retain statistical efficiency. Building on recent results in economics, we derive a class of models that achieves this balance, and propose a neural implementation that allows for scalable end-to-end training. Experiments on three large choice datasets demonstrate the utility of our approach.
Spectral clustering (SC) is a popular clustering technique to find strongly connected communities on a graph. SC can be used in Graph Neural Networks (GNNs) to implement pooling operations that aggregate nodes belonging to the same cluster. However, the eigendecomposition of the Laplacian is expensive and, since clustering results are graph-specific, pooling methods based on SC must perform a new optimization for each new sample. In this paper, we propose a graph clustering approach that addresses these limitations of SC. We formulate a continuous relaxation of the normalized minCUT problem and train a GNN to compute cluster assignments that minimize this objective. Our GNN-based implementation is differentiable, does not require to compute the spectral decomposition, and learns a clustering function that can be quickly evaluated on out-of-sample graphs. From the proposed clustering method, we design a graph pooling operator that overcomes some important limitations of state-of-the-art graph pooling techniques and achieves the best performance in several supervised and unsupervised tasks.
We present a Bayesian non-parametric way of inferring stochastic differential equations for both regression tasks and continuous-time dynamical modelling. The work has high emphasis on the stochastic part of the differential equation, also known as the diffusion, and modelling it by means of Wishart processes. Further, we present a semiparametric approach that allows the framework to scale to high dimensions. This successfully leads us onto how to model both latent and autoregressive temporal systems with conditional heteroskedastic noise. We provide experimental evidence that modelling diffusion often improves performance and that this randomness in the differential equation can be essential to avoid overfitting.
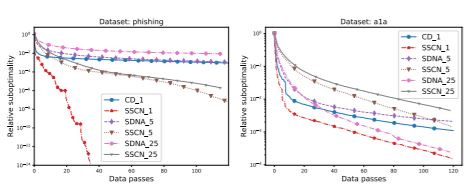
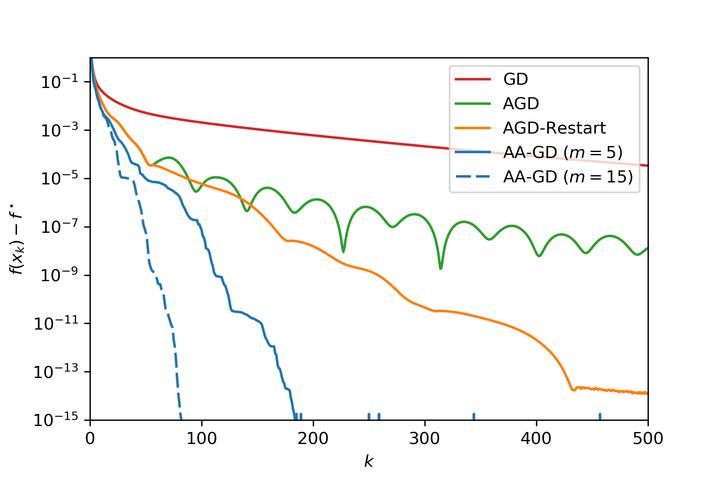
Anderson acceleration is a well-established and simple technique for speeding up fixed-point computations with countless applications. This work introduces novel methods for adapting Anderson acceleration to proximal gradient algorithms. Under some technical conditions, we extend existing local convergence results of Anderson acceleration for smooth fixed-point mappings to the proposed non-smooth setting. We also prove analytically that it is in general, impossible to guarantee global convergence of native Anderson acceleration. We therefore propose a simple scheme for stabilization that combines the global worst-case guarantees of proximal gradient methods with the local adaptation and practical speed-up of Anderson acceleration. Finally, we provide the first applications of Anderson acceleration to non-Euclidean geometry.
Deep learning networks are typically trained by Stochastic Gradient Descent (SGD) methods that iteratively improve the model parameters by estimating a gradient on a very small fraction of the training data. A major roadblock faced when increasing the batch size to a substantial fraction of the training data for reducing training time is the persistent degradation in performance (generalization gap). To address this issue, recent work propose to add small perturbations to the model parameters when computing the stochastic gradients and report improved generalization performance due to smoothing effects. However, this approach is poorly understood; it requires often model-specific noise and fine-tuning. To alleviate these drawbacks, we propose to use instead computationally efficient extrapolation (extragradient) to stabilize the optimization trajectory while still benefiting from smoothing to avoid sharp minima. This principled approach is well grounded from an optimization perspective and we show that a host of variations can be covered in a unified framework that we propose. We prove the convergence of this novel scheme and rigorously evaluate its empirical performance on ResNet, LSTM, and Transformer. We demonstrate that in a variety of experiments the scheme allows scaling to much larger batch sizes than before whilst reaching or surpassing SOTA …
Optimizing convolutional neural networks for fast inference has recently become an extremely active area of research. One of the go-to solutions in this context is weight pruning, which aims to reduce computational and memory footprint by removing large subsets of the connections in a neural network. Surprisingly, much less attention has been given to exploiting sparsity in the activation maps, which tend to be naturally sparse in many settings thanks to the structure of rectified linear (ReLU) activation functions. In this paper, we present an in-depth analysis of methods for maximizing the sparsity of the activations in a trained neural network, and show that, when coupled with an efficient sparse-input convolution algorithm, we can leverage this sparsity for significant performance gains. To induce highly sparse activation maps without accuracy loss, we introduce a new regularization technique, coupled with a new threshold-based sparsification method based on a parameterized activation function called Forced-Activation-Threshold Rectified Linear Unit (FATReLU). We examine the impact of our methods on popular image classification models, showing that most architectures can adapt to significantly sparser activation maps without any accuracy loss. Our second contribution is showing that these these compression gains can be translated into inference speedups: we provide …
The application of Gaussian processes (GPs) to large data sets is limited due to heavy memory and computational requirements. A variety of methods has been proposed to enable scalability, one of which is to exploit structure in the kernel matrix. Previous methods, however, cannot easily deal with mixtures of non-stationary processes. This paper investigates an efficient GP framework, that extends structured kernel interpolation methods to GPs with a non-stationary phase. We particularly treat the separation of nonstationary sources, which is a problem that commonly arises e.g. in spatio-temporal biomedical datasets. Our approach employs multiple sets of non-equidistant inducing points to account for the non-stationarity and retrieve Toeplitz and Kronecker structure in the kernel matrix allowing for efficient inference and kernel learning. Our approach is demonstrated on numerical examples and large spatio-temporal biomedical problems.
Poster Session 56 Fri 17 Jul 11:00 a.m.
[ Virtual ]

Models that employ latent variables to capture structure in observed data lie at the heart of many current unsupervised learning algorithms, but exact maximum-likelihood learning for powerful and flexible latent-variable models is almost always intractable. Thus, state-of-the-art approaches either abandon the maximum-likelihood framework entirely, or else rely on a variety of variational approximations to the posterior distribution over the latents. Here, we propose an alternative approach that we call amortised learning. Rather than computing an approximation to the posterior over latents, we use a wake-sleep Monte-Carlo strategy to learn a function that directly estimates the maximum-likelihood parameter updates. Amortised learning is possible whenever samples of latents and observations can be simulated from the generative model, treating the model as a ``black box''. We demonstrate its effectiveness on a wide range of complex models, including those with latents that are discrete or supported on non-Euclidean spaces.
[ Virtual ]
We introduce a family of multilayer graph kernels and establish new links between graph convolutional neural networks and kernel methods. Our approach generalizes convolutional kernel networks to graph-structured data, by representing graphs as a sequence of kernel feature maps, where each node carries information about local graph substructures. On the one hand, the kernel point of view offers an unsupervised, expressive, and easy-to-regularize data representation, which is useful when limited samples are available. On the other hand, our model can also be trained end-to-end on large-scale data, leading to new types of graph convolutional neural networks. We show that our method achieves state-of-the-art performance on several graph classification benchmarks, while offering simple model interpretation. Our code is freely available at https://github.com/claying/GCKN.
[ Virtual ]

In this work, we pose the question whether it is possible to design and train an autoencoder model in an end-to-end fashion to learn representations in the multivariate Bernoulli latent space, and achieve performance comparable with the state-of-the-art variational methods. Moreover, we investigate how to generate novel samples and perform smooth interpolation and attributes modification in the binary latent space. To meet our objective, we propose a simplified, deterministic model with a straight-through gradient estimator to learn the binary latents and show its competitiveness with the latest VAE methods. Furthermore, we propose a novel method based on a random hyperplane rounding for sampling and smooth interpolation in the latent space. Our method performs on a par or better than the current state-of-the-art methods on common CelebA, CIFAR-10 and MNIST datasets.
[ Virtual ]
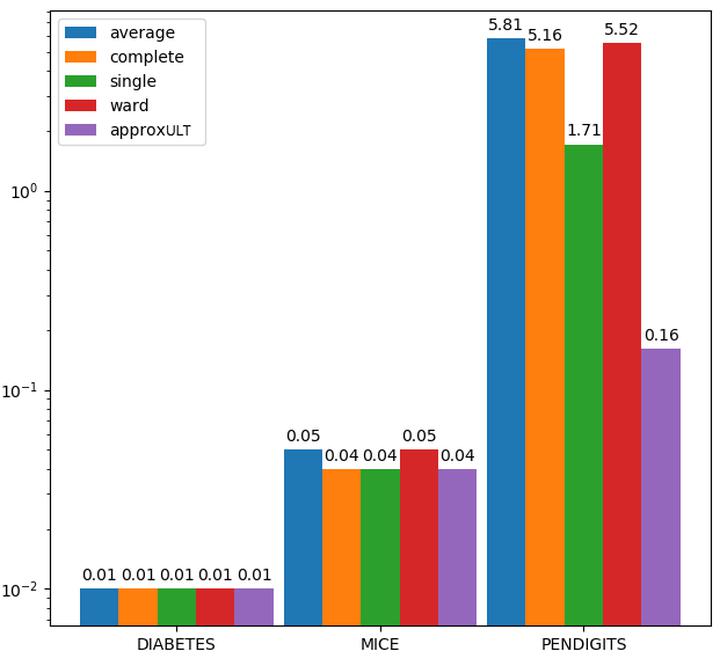
[ Virtual ]
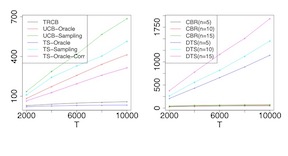
In this paper, we introduce the Preselection Bandit problem, in which the learner preselects a subset of arms (choice alternatives) for a user, which then chooses the final arm from this subset. The learner is not aware of the user's preferences, but can learn them from observed choices. In our concrete setting, we allow these choices to be stochastic and model the user's actions by means of the Plackett-Luce model. The learner's main task is to preselect subsets that eventually lead to highly preferred choices. To formalize this goal, we introduce a reasonable notion of regret and derive lower bounds on the expected regret. Moreover, we propose algorithms for which the upper bound on expected regret matches the lower bound up to a logarithmic term of the time horizon.

Computing equilibrium states for many-body systems, such as molecules, is a long-standing challenge. In the absence of methods for generating statistically independent samples, great computational effort is invested in simulating these systems using, for example, Markov chain Monte Carlo. We present a probabilistic model that generates such samples for molecules from their graph representations. Our model learns a low-dimensional manifold that preserves the geometry of local atomic neighborhoods through a principled learning representation that is based on Euclidean distance geometry. In a new benchmark for molecular conformation generation, we show experimentally that our generative model achieves state-of-the-art accuracy. Finally, we show how to use our model as a proposal distribution in an importance sampling scheme to compute molecular properties.
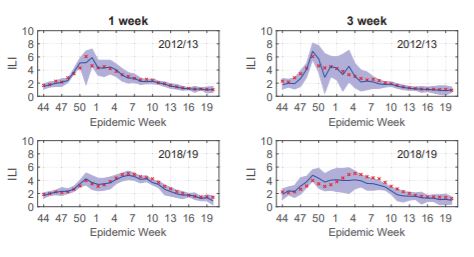
The seasonal epidemic of influenza costs thousands of lives each year in the US. While influenza epidemics occur every year, timing and size of the epidemic vary strongly from season to season. This complicates the public health efforts to adequately respond to such epidemics. Forecasting techniques to predict the development of seasonal epidemics such as influenza, are of great help to public health decision making. Therefore, the US Center for Disease Control and Prevention (CDC) has initiated a yearly challenge to forecast influenza-like illness. Here, we propose a new framework based on Gaussian process (GP) for seasonal epidemics forecasting and demonstrate its capability on the CDC reference data on influenza like illness: our framework leads to accurate forecasts with small but reliable uncertainty estimation. We compare our framework to several state of the art benchmarks and show competitive performance. We, therefore, believe that our GP based framework for seasonal epidemics forecasting will play a key role for future influenza forecasting and, lead to further research in the area.
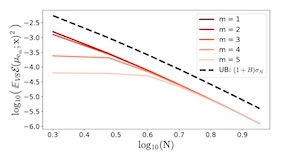
A fundamental task in kernel methods is to pick nodes and weights, so as to approximate a given function from an RKHS by the weighted sum of kernel translates located at the nodes. This is the crux of kernel density estimation, kernel quadrature, or interpolation from discrete samples. Furthermore, RKHSs offer a convenient mathematical and computational framework. We introduce and analyse continuous volume sampling (VS), the continuous counterpart -for choosing node locations- of a discrete distribution introduced in (Deshpande & Vempala, 2006). Our contribution is theoretical: we prove almost optimal bounds for interpolation and quadrature under VS. While similar bounds already exist for some specific RKHSs using ad-hoc node constructions, VS offers bounds that apply to any Mercer kernel and depend on the spectrum of the associated integration operator. We emphasize that, unlike previous randomized approaches that rely on regularized leverage scores or determinantal point processes, evaluating the pdf of VS only requires pointwise evaluations of the kernel. VS is thus naturally amenable to MCMC samplers.
Bayesian optimization (BO) methods often rely on the assumption that the objective function is well-behaved, but in practice, this is seldom true for real-world objectives even if noise-free observations can be collected. Common approaches, which try to model the objective as precisely as possible, often fail to make progress by spending too many evaluations modeling irrelevant details. We address this issue by proposing surrogate models that focus on the well-behaved structure in the objective function, which is informative for search, while ignoring detrimental structure that is challenging to model from few observations. First, we demonstrate that surrogate models with appropriate noise distributions can absorb challenging structures in the objective function by treating them as irreducible uncertainty. Secondly, we show that a latent Gaussian process is an excellent surrogate for this purpose, comparing with Gaussian processes with standard noise distributions. We perform numerous experiments on a range of BO benchmarks and find that our approach improves reliability and performance when faced with challenging objective functions.
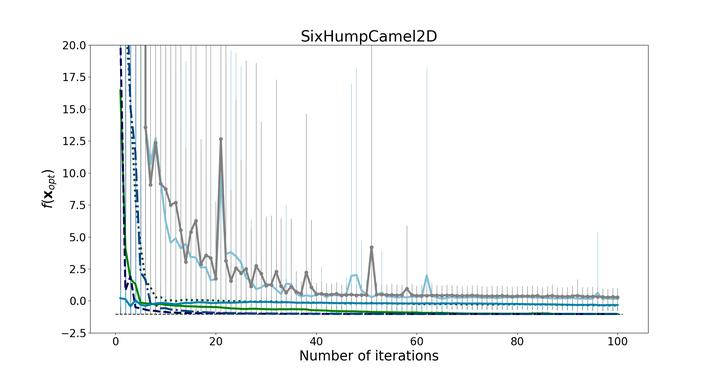
Bayesian optimization is an effective method for finding extrema of a black-box function. We propose a new type of Bayesian optimization for learning user preferences in high-dimensional spaces. The central assumption is that the underlying objective function cannot be evaluated directly, but instead a minimizer along a projection can be queried, which we call a projective preferential query. The form of the query allows for feedback that is natural for a human to give, and which enables interaction. This is demonstrated in a user experiment in which the user feedback comes in the form of optimal position and orientation of a molecule adsorbing to a surface. We demonstrate that our framework is able to find a global minimum of a high-dimensional black-box function, which is an infeasible task for existing preferential Bayesian optimization frameworks that are based on pairwise comparisons.
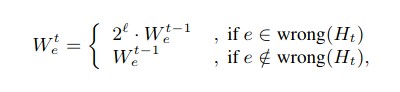

In this paper we describe a new parallel algorithm called Fast Adaptive Sequencing Technique (FAST) for maximizing a monotone submodular function under a cardinality constraint k. This algorithm achieves the optimal 1-1/e approximation guarantee and is orders of magnitude faster than the state-of-the-art on a variety of experiments over real-world data sets. Following recent work by Balkanski and Singer (2018), there has been a great deal of research on algorithms whose theoretical parallel runtime is exponentially faster than algorithms used for submodular maximization over the past 40 years. However, while these new algorithms are fast in terms of asymptotic worst-case guarantees, it is computationally infeasible to use them in practice even on small data sets because the number of rounds and queries they require depend on large constants and high-degree polynomials in terms of precision and confidence. The design principles behind the FAST algorithm we present here are a significant departure from those of recent theoretically fast algorithms. Rather than optimize for asymptotic theoretical guarantees, the design of FAST introduces several new techniques that achieve remarkable practical and theoretical parallel runtimes. The approximation guarantee obtained by FAST is arbitrarily close to 1 - 1/e, and its asymptotic parallel runtime (adaptivity) …
In pursuit of resource-economical machine learning, attempts have been made to dynamically adjust computation workloads in different training stages, i.e., starting with a shallow network and gradually increasing the model depth (and computation workloads) during training. However, there is neither guarantee nor guidance on designing such network grow, due to the lack of its theoretical underpinnings. In this work, to explore the theory behind, we conduct theoretical analyses from an ordinary differential equation perspective. Specifically, we illustrate the dynamics of network growth and propose a novel performance measure specific to the depth increase. Illuminated by our analyses, we move towards theoretically sound growing operations and schedulers, giving rise to an adaptive training algorithm for residual networks, LipGrow, which automatically increases network depth thus accelerates training. In our experiments, it achieves comparable performance while reducing ∼ 50% of training time.
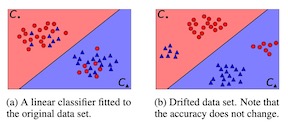
The notion of concept drift refers to the phenomenon that the distribution, which is underlying the observed data, changes over time; as a consequence machine learning models may become inaccurate and need adjustment. Many online learning schemes include drift detection to actively detect and react to observed changes. Yet, reliable drift detection constitutes a challenging problem in particular in the context of high dimensional data, varying drift characteristics, and the absence of a parametric model such as a classification scheme which reflects the drift. In this paper we present a novel concept drift detection method, Dynamic Adapting Window Independence Drift Detection (DAWIDD), which aims for non-parametric drift detection of diverse drift characteristics. For this purpose, we establish a mathematical equivalence of the presence of drift to the dependency of specific random variables in an according drift process. This allows us to rely on independence tests rather than parametric models or the classification loss, resulting in a fairly robust scheme to universally detect different types of drift, as it is also confirmed in experiments.
[ Virtual ]
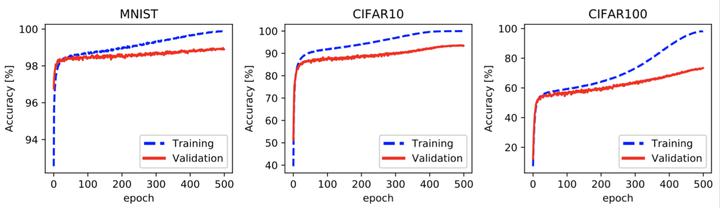
Neural networks with binary weights are computation-efficient and hardware-friendly, but their training is challenging because it involves a discrete optimization problem. Surprisingly, ignoring the discrete nature of the problem and using gradient-based methods, such as Straight-Through Estimator, still works well in practice. This raises the question: are there principled approaches which justify such methods? In this paper, we propose such an approach using the Bayesian learning rule. The rule, when applied to estimate a Bernoulli distribution over the binary weights, results in an algorithm which justifies some of the algorithmic choices made by the previous approaches. The algorithm not only obtains state-of-the-art performance, but also enables uncertainty estimation and continual learning to avoid catastrophic forgetting. Our work provides a principled approach for training binary neural networks which also justifies and extends existing approaches.
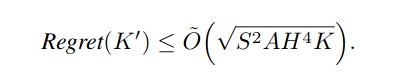
[ Virtual ]
Optimal transport is a foundational problem in optimization, that allows to compare probability distributions while taking into account geometric aspects. Its optimal objective value, the Wasserstein distance, provides an important loss between distributions that has been used in many applications throughout machine learning and statistics. Recent algorithmic progress on this problem and its regularized versions have made these tools increasingly popular. However, existing techniques require solving an optimization problem to obtain a single gradient of the loss, thus slowing down first-order methods to minimize the sum of losses, that require many such gradient computations. In this work, we introduce an algorithm to solve a regularized version of this problem of Wasserstein estimators, with a time per step which is sublinear in the natural dimensions of the problem. We introduce a dual formulation, and optimize it with stochastic gradient steps that can be computed directly from samples, without solving additional optimization problems at each step. Doing so, the estimation and computation tasks are performed jointly. We show that this algorithm can be extended to other tasks, including estimation of Wasserstein barycenters. We provide theoretical guarantees and illustrate the performance of our algorithm with experiments on synthetic data.
Devising indicative evaluation metrics for the image generation task remains an open problem. The most widely used metric for measuring the similarity between real and generated images has been the Frechet Inception Distance (FID) score. Since it does not differentiate the fidelity and diversity aspects of the generated images, recent papers have introduced variants of precision and recall metrics to diagnose those properties separately. In this paper, we show that even the latest version of the precision and recall metrics are not reliable yet. For example, they fail to detect the match between two identical distributions, they are not robust against outliers, and the evaluation hyperparameters are selected arbitrarily. We propose density and coverage metrics that solve the above issues. We analytically and experimentally show that density and coverage provide more interpretable and reliable signals for practitioners than the existing metrics.
Workshops Fri Fri 17 Jul 11:00 a.m.
Even though supervised learning using large annotated corpora is still the dominant approach in machine learning, self-supervised learning is gaining considerable popularity. Applying self-supervised learning to audio and speech sequences, however, remains particularly challenging. Speech signals, in fact, are not only high-dimensional, long, and variable-length sequences, but also entail a complex hierarchical structure that is difficult to infer without supervision (e.g.phonemes, syllables, words). Moreover, speech is characterized by an important variability due to different speaker identities, accents, recording conditions and noises that highly increase the level of complexity.
We believe that self-supervised learning will play a crucial role in the future of artificial intelligence, and we think that great research effort is needed to efficiently take advantage of it in audio and speech applications. With our initiative, we wish to foster more progress in the field, and we hope to encourage a discussion amongst experts and practitioners from both academia and industry that might bring different points of view on this topic. Furthermore, we plan to extend the debate to multiple disciplines, encouraging discussions on how insights from other fields (e.g., computer vision and robotics) can be applied to speech, and how findings on speech can be used on other …
This workshop will bring together artificial intelligence (AI) researchers who study the interpretability of AI systems, develop interpretable machine learning algorithms, and develop methodology to interpret black-box machine learning models (e.g., post-hoc interpretations). This is a very exciting time to study interpretable machine learning, as the advances in large-scale optimization and Bayesian inference that have enabled the rise of black-box machine learning are now also starting to be exploited to develop principled approaches to large-scale interpretable machine learning. Interpretability also forms a key bridge between machine learning and other AI research directions such as machine reasoning and planning. Participants in the workshop will exchange ideas on these and allied topics.
Description: the workshop proposal in “Law and Machine Learning” aims to contribute to the research on social and legal risks of the deployment of AI systems using machine learning based decisions. Today, algorithms have been infiltrating and governing every aspect of our lives as individuals and as a society. Specifically, Algorithmic Decision Systems (ADS) are involved in many social decisions. For instance, such systems are increasingly used to support decision-making in fields, such as child welfare, criminal justice, school assignment, teacher evaluation, fire risk assessment, homelessness prioritization, healthcare, Medicaid benefit, immigration decision systems or risk assessment, and predictive policing, among other things. Law enforcement agencies are increasingly using facial recognition, algorithmic predictive policing systems to forecast criminal activity and allocate police resources. However, these predictive systems challenge fundamental rights and guarantees of the criminal procedure. For several years, numerous studies have revealed, social risks of ML, especially the risks of opacity, bias, manipulation of information.
While it is only the starting point of the deployment of such systems, more interdisciplinary research is needed. Our purpose is to contribute to this new field which brings together legal researchers, mathematicians and computer scientists, by bridging the gap between the performance of algorithmic …
Analysis of large amounts of data offers new opportunities to understand many processes better. Yet, data accumulation often implies relaxing acquisition procedures or compounding diverse sources, leading to many observations with missing features. From questionnaires to collaborative filtering, from electronic health records to single-cell analysis, missingness is everywhere at play and is rather the norm than the exception. Even “clean” data sets are often barely “cleaned” versions of incomplete data sets—with all the unfortunate biases this cleaning process may have created.
Despite this ubiquity, tackling missing values is often overlooked. Handling missing values poses many challenges, and there is a vast literature in the statistical community, with many implementations available. Yet, there are still many open issues and the need to design new methods or to introduce new point of views: for missing values in a supervised-learning setting, in deep learning architectures, to adapt available methods for high dimensional observed data with different type of missing values, deal with feature mismatch and distribution mismatch. Missing data is one of the eight pillars of causal wisdom for Judea Pearl who brought graphical model reasoning to tackle some missing not at random values.
To the best of our knowledge, this is the …
A person’s health is determined by a variety of factors beyond those captured by electronic health records or the genome. Many healthcare organizations recognize the importance of the social determinants of health (SDH) such as socioeconomic status, employment, food security, education, and community cohesion. Capturing such comprehensive portraits of patient data is necessary to transform a healthcare system and improve population health while simultaneously delivering personalized healthcare provisions. Machine learning (ML) is well-positioned to transform system-level healthcare through the design of intelligent algorithms that incorporate SDH into clinical and policy interventions, such as population health programs and clinical decision support systems. Innovations in health-tech through wearable devices and mobile health, among others, provide rich sources of data, including those characterizing SDH. The guiding metric of success should be health outcomes: the improvement of health and care at both the individual and population levels. This workshop will identify the needs of system-level healthcare transformation that ML may satisfy. We will bring together ML researchers, health policy practitioners, clinical organization experts, and individuals from all areas of clinic-, hospital-, and community-based healthcare.
Until recently, Machine Learning has been mostly applied in industry by consulting academics, data scientists within larger companies, and a number of dedicated Machine Learning research labs within a few of the world’s most innovative tech companies. Over the last few years we have seen the dramatic rise of companies dedicated to providing Machine Learning software-as-a-service tools, with the aim of democratizing access to the benefits of Machine Learning. All these efforts have revealed major hurdles to ensuring the continual delivery of good performance from deployed Machine Learning systems. These hurdles range from challenges in MLOps, to fundamental problems with deploying certain algorithms, to solving the legal issues surrounding the ethics involved in letting algorithms make decisions for your business.
This workshop will invite papers related to the challenges in deploying and monitoring ML systems. It will encourage submission on: subjects related to MLOps for deployed ML systems (such as testing ML systems, debugging ML systems, monitoring ML systems, debugging ML Models, deploying ML at scale); subjects related to the ethics around deploying ML systems (such as ensuring fairness, trust and transparency of ML systems, providing privacy and security on ML Systems); useful tools and programming languages for deploying ML …
Self-driving cars and advanced safety features present one of today’s greatest challenges and opportunities for Artificial Intelligence (AI). Despite billions of dollars of investments and encouraging progress under certain operational constraints, there are no driverless cars on public roads today without human safety drivers. Autonomous Driving research spans a wide spectrum, from modular architectures -- composed of hardcoded or independently learned sub-systems -- to end-to-end deep networks with a single model from sensors to controls. In any system, Machine Learning is a key component. However, there are formidable learning challenges due to safety constraints, the need for large-scale manual labeling, and the complex high dimensional structure of driving data, whether inputs (from cameras, HD maps, inertial measurement units, wheel encoders, LiDAR, radar, etc.) or predictions (e.g., world state representations, behavior models, trajectory forecasts, plans, controls). The goal of this workshop is to explore the frontier of learning approaches for safe, robust, and efficient Autonomous Driving (AD) at scale. The workshop will span both theoretical frameworks and practical issues especially in the area of deep learning.
Website: https://sites.google.com/view/aiad2020
The ICML Workshop on Retrospectives in Machine Learning will build upon the success of the 2019 NeurIPS Retrospectives workshop to further encourage the publication of retrospectives. A retrospective of a paper or a set of papers, by its author, takes the form of an informal paper. It provides a venue for authors to reflect on their previous publications, to talk about how their thoughts have changed following publication, to identify shortcomings in their analysis or results, and to discuss resulting extensions. The overarching goal of MLRetrospectives is to improve the science, openness, and accessibility of the machine learning field, by widening what is publishable and helping to identify opportunities for improvement. Retrospectives also give researchers and practitioners unable to attend conferences access to the author’s updated understanding of their work, which would otherwise only be accessible to their immediate circle. The machine learning community would benefit from retrospectives on much of the research which shapes our field, and this workshop will present an opportunity for a few retrospectives to be presented.
The workshop will showcase recent research in the field of Computational Biology. Computational biology is an interdisciplinary field that develops and applies analytical methods, mathematical and statistical modeling and simulation to analyze and interpret vast collections of biological data, such as genetic sequences, cellular features or protein structures, and imaging datasets to make new predictions towards clinical response, discover new biology or aid drug discovery. The availability of high-dimensional data, at multiple spatial and temporal resolutions has made machine learning and deep learning methods increasingly critical for computational analysis and interpretation of the data. Conversely, biological data has also exposed unique challenges and problems that call for the development of new machine learning methods.
This workshop aims to bring together researchers working at the unique intersection of Machine Learning and Biology that include areas (and not limited to) such as computational genomics, neuroscience, pathology, radiology, evolutionary biology, population genomics, phenomics, ecology, cancer biology, causality, and representation learning and disentanglement to present recent advances and open questions to the ML community.
The workshop is a sequel to the WCB workshops we organized in the last four years ICML 2019, Long Beach , Joint ICML and IJCAI 2018, Stockholm , ICML 2017, …
The designers of a machine learning (ML) system typically have far more power over the system than the individuals who are ultimately impacted by the system and its decisions. Recommender platforms shape the users’ preferences; the individuals classified by a model often do not have means to contest a decision; and the data required by supervised ML systems necessitates that the privacy and labour of many yield to the design choices of a few.
The fields of algorithmic fairness and human-centered ML often focus on centralized solutions, lending increasing power to system designers and operators, and less to users and affected populations. In response to the growing social-science critique of the power imbalance present in the research, design, and deployment of ML systems, we wish to consider a new set of technical formulations for the ML community on the subject of more democratic, cooperative, and participatory ML systems.
Our workshop aims to explore methods that, by design, enable and encourage the perspectives of those impacted by an ML system to shape the system and its decisions. By involving affected populations in shaping the goals of the overall system, we hope to move beyond just tools for enabling human participation and …
Machine learning systems are commonly applied to isolated tasks or narrow domains (e.g. control over similar robotic bodies). It is further assumed that the learning system has simultaneous access to all the data points of the tasks at hand. In contrast, Continual Learning (CL) studies the problem of learning from a stream of data from changing domains, each connected to a different learning task. The objective of CL is to quickly adapt to new situations or tasks by exploiting previously acquired knowledge, while protecting previous learning from being erased. Meeting the objectives of CL will provide an opportunity for systems to quickly learn new skills given knowledge accumulated in the past and continually extend their capabilities to changing environments, a hallmark of natural intelligence.
Extreme classification is a rapidly growing research area focusing on multi-class and multi-label problems, where the label space is extremely large. It brings many diverse approaches under the same umbrella including natural language processing (NLP), computer vision, information retrieval, recommendation systems, computational advertising, and embedding methods. Extreme classifiers have been deployed in many real-world applications in the industry ranging from language modelling to document tagging in NLP, face recognition to learning universal feature representations in computer vision, etc. Moreover, extreme classification finds application in recommendation, tagging, and ranking systems since these problems can be reformulated as multi-label learning tasks where each item to be ranked or recommended is treated as a separate label. Such reformulations have led to significant gains over traditional collaborative filtering and content-based recommendation techniques.
The proposed workshop aims to offer a timely collection of information to benefit the researchers and practitioners working in the aforementioned research fields of core supervised learning, theory of extreme classification, as well as application domains. These issues are well-covered by the Topics of Interest in ICML 2020. The workshop aims to bring together researchers interested in these areas to encourage discussion, facilitate interaction and collaboration and improve upon the state-of-the-art in …
Objects, and the interactions between them, are the foundations on which our understanding of the world is built. Similarly, abstractions centered around the perception and representation of objects play a key role in building human-like AI, supporting high-level cognitive abilities like causal reasoning, object-centric exploration, and problem solving. Indeed, prior works have shown how relational reasoning and control problems can greatly benefit from having object descriptions. Yet, many of the current methods in machine learning focus on a less structured approach in which objects are only implicitly represented, posing a challenge for interpretability and the reuse of knowledge across tasks. Motivated by the above observations, there has been a recent effort to reinterpret various learning problems from the perspective of object-oriented representations.
In this workshop, we will showcase a variety of approaches in object-oriented learning, with three particular emphases. Our first interest is in learning object representations in an unsupervised manner. Although computer vision has made an enormous amount of progress in learning about objects via supervised methods, we believe that learning about objects with little to no supervision is preferable: it minimizes labeling costs, and also supports adaptive representations that can be changed depending on the particular situation and …
In many settings such as education, healthcare, drug design, robotics, transportation, and achieving better-than-human performance in strategic games, it is important to make decisions sequentially. This poses two interconnected algorithmic and statistical challenges: effectively exploring to learn information about the underlying dynamics and effectively planning using this information. Reinforcement Learning (RL) is the main paradigm tackling both of these challenges simultaneously which is essential in the aforementioned applications. Over the last years, reinforcement learning has seen enormous progress both in solidifying our understanding on its theoretical underpinnings and in applying these methods in practice.
This workshop aims to highlight recent theoretical contributions, with an emphasis on addressing significant challenges on the road ahead. Such theoretical understanding is important in order to design algorithms that have robust and compelling performance in real-world applications. As part of the ICML 2020 conference, this workshop will be held virtually. It will feature keynote talks from six reinforcement learning experts tackling different significant facets of RL. It will also offer the opportunity for contributed material (see below the call for papers and our outstanding program committee). The authors of each accepted paper will prerecord a 10-minute presentation and will also appear in a poster session. …
ML has shown great promise in modeling and predicting complex phenomenon in many scientificdisciples such as predicting cardiovascular risk factors from retinal images, understanding howelectrons behave at the atomic level [3], identifying patterns of weather and climate phenomena, etc. Further, models are able to learn directly (and better) from raw data as opposed to human selected features. The ability to interpret the model and find significant predictors couldprovide new scientific insights.Traditionally, the scientific discovery process has been based on careful observations of nat-ural phenomenon, followed by systematic human analysis (of hypothesis generation and ex-perimental validation). ML interpretability has the potential to bring a radically different yetprincipled approach. While general interpretability relies on ‘human parsing’ (common sense),scientific domains have semi-structured and highly structured bases for interpretation. Thus,despite differences in data modalities and domains, be it brain sciences, the behavioral sciences,or material sciences, there is a need for a common set of tools that address a similar flavor of problem, one of interpretability or fitting models to a known structure. This workshop aims to bring together members from the ML and physical sciences communities to introduce exciting problems to the broader community, and stimulate the productionof new approaches towards solving open scientific …
There has been growing interest in rectifying deep neural network instabilities. Challenges arise when models receive samples drawn from outside the training distribution. For example, a neural network tasked with classifying handwritten digits may assign high confidence predictions to cat images. Anomalies are frequently encountered when deploying ML models in the real world. Well-calibrated predictive uncertainty estimates are indispensable for many machine learning applications, such as self-driving vehicles and medical diagnosis systems. Generalization to unseen and worst-case inputs is also essential for robustness to distributional shift. In order to have ML models reliably predict in open environment, we must deepen technical understanding in the emerging areas of: (1) learning algorithms that can detect changes in data distribution (e.g. out-of-distribution examples); (2) mechanisms to estimate and calibrate confidence produced by neural networks in typical and unforeseen scenarios; (3) methods to improve out-of-distribution generalization, including generalization to temporal, geographical, hardware, adversarial, and image-quality changes; (4) benchmark datasets and protocols for evaluating model performance under distribution shift; and (5) key applications of robust and uncertainty-aware deep learning (e.g., computer vision, robotics, self-driving vehicles, medical imaging) as well as broader machine learning tasks.
This workshop will bring together researchers and practitioners from the machine …
Optimization lies at the heart of many exciting developments in machine learning, statistics and signal processing. As models become more complex and datasets get larger, finding efficient, reliable and provable methods is one of the primary goals in these fields.
In the last few decades, much effort has been devoted to the development of first-order methods. These methods enjoy a low per-iteration cost and have optimal complexity, are easy to implement, and have proven to be effective for most machine learning applications. First-order methods, however, have significant limitations: (1) they require fine hyper-parameter tuning, (2) they do not incorporate curvature information, and thus are sensitive to ill-conditioning, and (3) they are often unable to fully exploit the power of distributed computing architectures.
Higher-order methods, such as Newton, quasi-Newton and adaptive gradient descent methods, are extensively used in many scientific and engineering domains. At least in theory, these methods possess several nice features: they exploit local curvature information to mitigate the effects of ill-conditioning, they avoid or diminish the need for hyper-parameter tuning, and they have enough concurrency to take advantage of distributed computing environments. Researchers have even developed stochastic versions of higher-order methods, that feature speed and scalability by incorporating …
Poster Session 57 Fri 17 Jul 12:00 p.m.
[ Virtual ]

Recent work has shown how predictive modeling can endow agents with rich knowledge of their surroundings, improving their ability to act in complex environments. We propose question-answering as a general paradigm to decode and understand the representations that such agents develop, applying our method to two recent approaches to predictive modelling - action-conditional CPC (Guo et al., 2018) and SimCore (Gregor et al., 2019). After training agents with these predictive objectives in a visually-rich, 3D environment with an assortment of objects, colors, shapes, and spatial configurations, we probe their internal state representations with a host of synthetic (English) questions, without backpropagating gradients from the question-answering decoder into the agent. The performance of different agents when probed in this way reveals that they learn to encode factual, and seemingly compositional, information about objects, properties and spatial relations from their physical environment. Our approach is intuitive, i.e. humans can easily interpret the responses of the model as opposed to inspecting continuous vectors, and model-agnostic, i.e. applicable to any modeling approach. By revealing the implicit knowledge of objects, quantities, properties and relations acquired by agents as they learn, question-conditional agent probing can stimulate the design and development of stronger predictive learning objectives.
[ Virtual ]
Simplex-valued data appear throughout statistics and machine learning, for example in the context of transfer learning and compression of deep networks. Existing models for this class of data rely on the Dirichlet distribution or other related loss functions; here we show these standard choices suffer systematically from a number of limitations, including bias and numerical issues that frustrate the use of flexible network models upstream of these distributions. We resolve these limitations by introducing a novel exponential family of distributions for modeling simplex-valued data – the continuous categorical, which arises as a nontrivial multivariate generalization of the recently discovered continuous Bernoulli. Unlike the Dirichlet and other typical choices, the continuous categorical results in a well-behaved probabilistic loss function that produces unbiased estimators, while preserving the mathematical simplicity of the Dirichlet. As well as exploring its theoretical properties, we introduce sampling methods for this distribution that are amenable to the reparameterization trick, and evaluate their performance. Lastly, we demonstrate that the continuous categorical outperforms standard choices empirically, across a simulation study, an applied example on multi-party elections, and a neural network compression task.

Gaussian processes are the gold standard for many real-world modeling problems, especially in cases where a model's success hinges upon its ability to faithfully represent predictive uncertainty. These problems typically exist as parts of larger frameworks, wherein quantities of interest are ultimately defined by integrating over posterior distributions. These quantities are frequently intractable, motivating the use of Monte Carlo methods. Despite substantial progress in scaling up Gaussian processes to large training sets, methods for accurately generating draws from their posterior distributions still scale cubically in the number of test locations. We identify a decomposition of Gaussian processes that naturally lends itself to scalable sampling by separating out the prior from the data. Building off of this factorization, we propose an easy-to-use and general-purpose approach for fast posterior sampling, which seamlessly pairs with sparse approximations to afford scalability both during training and at test time. In a series of experiments designed to test competing sampling schemes' statistical properties and practical ramifications, we demonstrate how decoupled sample paths accurately represent Gaussian process posteriors at a fraction of the usual cost.

Recurrent neural networks are widely used on time series data, yet such models often ignore the underlying physical structures in such sequences. A new class of physics-based methods related to Koopman theory has been introduced, offering an alternative for processing nonlinear dynamical systems. In this work, we propose a novel Consistent Koopman Autoencoder model which, unlike the majority of existing work, leverages the forward and backward dynamics. Key to our approach is a new analysis which explores the interplay between consistent dynamics and their associated Koopman operators. Our network is directly related to the derived analysis, and its computational requirements are comparable to other baselines. We evaluate our method on a wide range of high-dimensional and short-term dependent problems, and it achieves accurate estimates for significant prediction horizons, while also being robust to noise.
Submodular functions have been studied extensively in machine learning and data mining. In particular, the optimization of submodular functions over the integer lattice (integer submodular functions) has recently attracted much interest, because this domain relates naturally to many practical problem settings, such as multilabel graph cut, budget allocation and revenue maximization with discrete assignments. In contrast, the use of these functions for probabilistic modeling has received surprisingly little attention so far. In this work, we firstly propose the Generalized Multilinear Extension, a continuous DR-submodular extension for integer submodular functions. We study central properties of this extension and formulate a new probabilistic model which is defined through integer submodular functions. Then, we introduce a block-coordinate ascent algorithm to perform approximate inference for this class of models and finally, we demonstrate its effectiveness and viability on several real-world social connection graph datasets with integer submodular objectives.
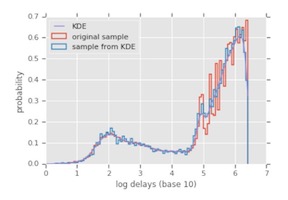
Stochastic linear bandits are a natural and well-studied model for structured exploration/exploitation problems and are widely used in applications such as on-line marketing and recommendation. One of the main challenges faced by practitioners hoping to apply existing algorithms is that usually the feedback is randomly delayed and delays are only partially observable. For example, while a purchase is usually observable some time after the display, the decision of not buying is never explicitly sent to the system. In other words, the learner only observes delayed positive events. We formalize this problem as a novel stochastic delayed linear bandit and propose OTFLinUCB and OTFLinTS, two computationally efficient algorithms able to integrate new information as it becomes available and to deal with the permanently censored feedback. We prove optimal O(d\sqrt{T}) bounds on the regret of the first algorithm and study the dependency on delay-dependent parameters. Our model, assumptions and results are validated by experiments on simulated and real data.

Centralized training with decentralized execution has become an important paradigm in multi-agent learning. Though practical, current methods rely on restrictive assumptions to decompose the centralized value function across agents for execution. In this paper, we eliminate this restriction by proposing multi-agent determinantal Q-learning. Our method is established on Q-DPP, a novel extension of determinantal point process (DPP) to multi-agent setting. Q-DPP promotes agents to acquire diverse behavioral models; this allows a natural factorization of the joint Q-functions with no need for \emph{a priori} structural constraints on the value function or special network architectures. We demonstrate that Q-DPP generalizes major solutions including VDN, QMIX, and QTRAN on decentralizable cooperative tasks. To efficiently draw samples from Q-DPP, we develop a linear-time sampler with theoretical approximation guarantee. Our sampler also benefits exploration by coordinating agents to cover orthogonal directions in the state space during training. We evaluate our algorithm on multiple cooperative benchmarks; its effectiveness has been demonstrated when compared with the state-of-the-art.
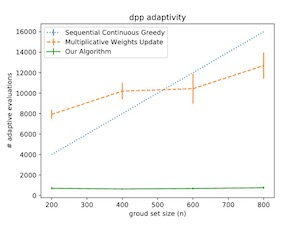
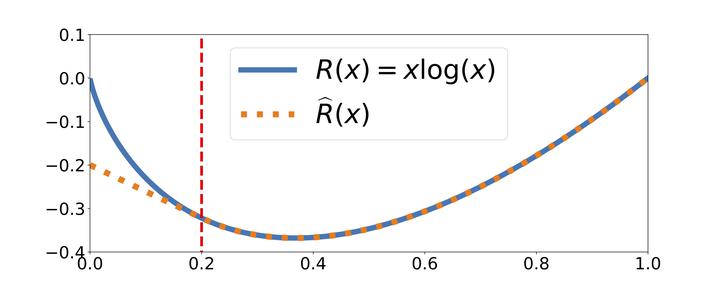
Regularizing Wasserstein distances has proved to be the key in the recent advances of optimal transport (OT) in machine learning. Most prominent is the entropic regularization of OT, which not only allows for fast computations and differentiation using Sinkhorn algorithm, but also improves stability with respect to data and accuracy in many numerical experiments. Theoretical understanding of these benefits remains unclear, although recent statistical works have shown that entropy-regularized OT mitigates classical OT's curse of dimensionality. In this paper, we adopt a more geometrical point of view, and show using Fenchel duality that any convex regularization of OT can be interpreted as ground cost adversarial. This incidentally gives access to a robust dissimilarity measure on the ground space, which can in turn be used in other applications. We propose algorithms to compute this robust cost, and illustrate the interest of this approach empirically.
Automating molecular design using deep reinforcement learning (RL) holds the promise of accelerating the discovery of new chemical compounds. Existing approaches work with molecular graphs and thus ignore the location of atoms in space, which restricts them to 1) generating single organic molecules and 2) heuristic reward functions. To address this, we present a novel RL formulation for molecular design in Cartesian coordinates, thereby extending the class of molecules that can be built. Our reward function is directly based on fundamental physical properties such as the energy, which we approximate via fast quantum-chemical methods. To enable progress towards de-novo molecular design, we introduce MolGym, an RL environment comprising several challenging molecular design tasks along with baselines. In our experiments, we show that our agent can efficiently learn to solve these tasks from scratch by working in a translation and rotation invariant state-action space.
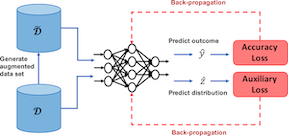
Modern neural networks have proven to be powerful function approximators, providing state-of-the-art performance in a multitude of applications. They however fall short in their ability to quantify confidence in their predictions --- this is crucial in high-stakes applications that involve critical decision-making. Bayesian neural networks (BNNs) aim at solving this problem by placing a prior distribution over the network's parameters, thereby inducing a posterior distribution that encapsulates predictive uncertainty. While existing variants of BNNs based on Monte Carlo dropout produce reliable (albeit approximate) uncertainty estimates over in-distribution data, they tend to exhibit over-confidence in predictions made on target data whose feature distribution differs from the training data, i.e., the covariate shift setup. In this paper, we develop an approximate Bayesian inference scheme based on posterior regularisation, wherein unlabelled target data are used as ``pseudo-labels'' of model confidence that are used to regularise the model's loss on labelled source data. We show that this approach significantly improves the accuracy of uncertainty quantification on covariate-shifted data sets, with minimal modification to the underlying model architecture. We demonstrate the utility of our method in the context of transferring prognostic models of prostate cancer across globally diverse populations.

Variational Autoencoders (VAEs) represent the given data in a low-dimensional latent space, which is generally assumed to be Euclidean. This assumption naturally leads to the common choice of a standard Gaussian prior over continuous latent variables. Recent work has, however, shown that this prior has a detrimental effect on model capacity, leading to subpar performance. We propose that the Euclidean assumption lies at the heart of this failure mode. To counter this, we assume a Riemannian structure over the latent space, which constitutes a more principled geometric view of the latent codes, and replace the standard Gaussian prior with a Riemannian Brownian motion prior. We propose an efficient inference scheme that does not rely on the unknown normalizing factor of this prior. Finally, we demonstrate that this prior significantly increases model capacity using only one additional scalar parameter.
Bayesian inference using Markov Chain Monte Carlo (MCMC) on large datasets has developed rapidly in recent years. However, the underlying methods are generally limited to relatively simple settings where the data have specific forms of independence. We propose a novel technique for speeding up MCMC for time series data by efficient data subsampling in the frequency domain. For several challenging time series models, we demonstrate a speedup of up to two orders of magnitude while incurring negligible bias compared to MCMC on the full dataset. We also propose alternative control variates for variance reduction based on data grouping and coreset constructions.
Poster Session 58 Fri 17 Jul 01:00 p.m.
[ Virtual ]
In multi-label learning, each instance can be associated with multiple and non-exclusive labels. Previous studies assume that all the labels in the learning process are fixed and static; however, they ignore the fact that the labels will emerge continuously in changing environments. In order to fill in these research gaps, we propose a novel deep neural network (DNN) based framework, Deep Streaming Label Learning (DSLL), to classify instances with newly emerged labels effectively. DSLL can explore and incorporate the knowledge from past labels and historical models to understand and develop emerging new labels. DSLL consists of three components: 1) a streaming label mapping to extract deep relationships between new labels and past labels with a novel label-correlation aware loss; 2) a streaming feature distillation propagating feature-level knowledge from the historical model to a new model; 3) a senior student network to model new labels with the help of knowledge learned from the past. Theoretically, we prove that DSLL admits tight generalization error bounds for new labels in the DNN framework. Experimentally, extensive empirical results show that the proposed method performs significantly better than the existing state-of-the-art multi-label learning methods to handle the continually emerging new labels.
Joint filtering is a fundamental problem in computer vision with applications in many different areas. Most existing algorithms solve this problem with a weighted averaging process to aggregate input pixels. However, the weight matrix of this process is often empirically designed and not robust to complex input. In this work, we propose to learn the weight matrix for joint image filtering. This is a challenging problem, as directly learning a large weight matrix is computationally intractable. To address this issue, we introduce the correlation of deep features to approximate the aggregation weights. However, this strategy only uses inner product for the weight matrix estimation, which limits the performance of the proposed algorithm. Therefore, we further propose to learn a nonlinear function to predict sparse residuals of the feature correlation matrix. Note that the proposed method essentially factorizes the weight matrix into a low-rank and a sparse matrix and then learn both of them simultaneously with deep neural networks. Extensive experiments show that the proposed algorithm compares favorably against the state-of-the-art approaches on a wide variety of joint filtering tasks.
Deep neural networks are known to be fragile to small adversarial perturbations, which raises serious concerns when a neural network policy is interconnected with a physical system in a closed loop. In this paper, we show how to combine recent works on static neural network certification tools with robust control theory to certify a neural network policy in a control loop. We give a sufficient condition and an algorithm to ensure that the closed loop state and control constraints are satisfied when the persistent adversarial perturbation is l-infinity norm bounded. Our method is based on finding a positively invariant set of the closed loop dynamical system, and thus we do not require the continuity of the neural network policy. Along with the verification result, we also develop an effective attack strategy for neural network control systems that outperforms exhaustive Monte-Carlo search significantly. We show that our certification algorithm works well on learned models and could achieve 5 times better result than the traditional Lipschitz-based method to certify the robustness of a neural network policy on the cart-pole balance control problem.
We investigate the combination of actor-critic reinforcement learning algorithms with a uniform large-scale experience replay and propose solutions for two ensuing challenges: (a) efficient actor-critic learning with experience replay (b) the stability of off-policy learning where agents learn from other agents behaviour. To this end we analyze the bias-variance tradeoffs in V-trace, a form of importance sampling for actor-critic methods. Based on our analysis, we then argue for mixing experience sampled from replay with on-policy experience, and propose a new trust region scheme that scales effectively to data distributions where V-trace becomes unstable. We provide extensive empirical validation of the proposed solutions on DMLab-30 and further show the benefits of this setup in two training regimes for Atari: (1) a single agent is trained up until 200M environment frames per game (2) a population of agents is trained up until 200M environment frames each and may share experience. We demonstrate state-of-the-art data efficiency among model-free agents in both regimes.
\emph{Is there a classifier that ensures optimal robustness against all adversarial attacks?} This paper tackles the question by adopting a game-theoretic point of view. We present the adversarial attacks and defenses problem as an \emph{infinite} zero-sum game where classical results (\emph{e.g.} Nash or Sion theorems) do not apply. We demonstrate the non-existence of a Nash equilibrium in our game when the classifier and the Adversary are both deterministic, hence giving a negative answer to the above question in the deterministic regime. Nonetheless, the question remains open in the randomized regime. We tackle this problem by showing that, under mild conditions on the dataset distribution, any deterministic classifier can be outperformed by a randomized one. This gives arguments for using randomization, and leads us to a simple method for building randomized classifiers that are robust to state-or-the-art adversarial attacks. Empirical results validate our theoretical analysis, and show that our defense method considerably outperforms Adversarial Training against strong adaptive attacks, by achieving 0.55 accuracy under adaptive PGD-attack on CIFAR10, compared to 0.42 for Adversarial training.
[ Virtual ]
[ Virtual ]
In this paper, we study the problem of learning compact (low-dimensional) representations for sequential data that captures its implicit spatio-temporal cues. To maximize extraction of such informative cues from the data, we set the problem within the context of contrastive representation learning and to that end propose a novel objective via optimal transport. Specifically, our formulation seeks a low-dimensional subspace representation of the data that jointly (i) maximizes the distance of the data (embedded in this subspace) from an adversarial data distribution under the optimal transport, a.k.a. the Wasserstein distance, (ii) captures the temporal order, and (iii) minimizes the data distortion. To generate the adversarial distribution, we propose a novel framework connecting Wasserstein GANs with a classifier, allowing a principled mechanism for producing good negative distributions for contrastive learning, which is currently a challenging problem. Our full objective is cast as a subspace learning problem on the Grassmann manifold and solved via Riemannian optimization. To empirically study our formulation, we provide experiments on the task of human action recognition in video sequences. Our results demonstrate competitive performance against challenging baselines.
A fundamental problem in computational chemistry is to find a set of reactants to synthesize a target molecule, a.k.a. retrosynthesis prediction. Existing state-of-the-art methods rely on matching the target molecule with a large set of reaction templates, which are very computationally expensive and also suffer from the problem of coverage. In this paper, we propose a novel template-free approach called G2Gs by transforming a target molecular graph into a set of reactant molecular graphs. G2Gs first splits the target molecular graph into a set of synthons by identifying the reaction centers, and then translates the synthons to the final reactant graphs via a variational graph translation framework. Experimental results show that G2Gs significantly outperforms existing template-free approaches by up to 63% in terms of the top-1 accuracy and achieves a performance close to that of state-of-the-art template-based approaches, but does not require domain knowledge and is much more scalable.
Recent encoder-decoder approaches typically employ string decoders to convert images into serialized strings for image-to-markup. However, for tree-structured representational markup, string representations can hardly cope with the structural complexity. In this work, we first show via a set of toy problems that string decoders struggle to decode tree structures, especially as structural complexity increases, we then propose a tree-structured decoder that specifically aims at generating a tree-structured markup. Our decoders works sequentially, where at each step a child node and its parent node are simultaneously generated to form a sub-tree. This sub-tree is consequently used to construct the final tree structure in a recurrent manner. Key to the success of our tree decoder is twofold, (i) it strictly respects the parent-child relationship of trees, and (ii) it explicitly outputs trees as oppose to a linear string. Evaluated on both math formula recognition and chemical formula recognition, the proposed tree decoder is shown to greatly outperform strong string decoder baselines.
In many real tasks, we care about how to make decisions rather than mere predictions on an event, e.g. how to increase the revenue next month instead of merely knowing it will drop. The key is to identify the causal effects on the desired event. It is achievable with do-calculus if the causal structure is known; however, in many real tasks it is not easy to infer the whole causal structure with the observational data. Introducing external interventions is needed to achieve it. In this paper, we study the situation where only the response variable is observable under intervention. We propose a novel approach which is able to cost-effectively identify the causal effects, by an active strategy introducing limited interventions, and thus guide decision-making. Theoretical analysis and empirical studies validate the effectiveness of the proposed approach.
The Markov assumption (MA) is fundamental to the empirical validity of reinforcement learning. In this paper, we propose a novel Forward-Backward Learning procedure to test MA in sequential decision making. The proposed test does not assume any parametric form on the joint distribution of the observed data and plays an important role for identifying the optimal policy in high-order Markov decision processes (MDPs) and partially observable MDPs. Theoretically, we establish the validity of our test. Empirically, we apply our test to both synthetic datasets and a real data example from mobile health studies to illustrate its usefulness.
Overparameterized deep networks have the capacity to memorize training data with zero \emph{training error}. Even after memorization, the \emph{training loss} continues to approach zero, making the model overconfident and the test performance degraded. Since existing regularizers do not directly aim to avoid zero training loss, it is hard to tune their hyperparameters in order to maintain a fixed/preset level of training loss. We propose a direct solution called \emph{flooding} that intentionally prevents further reduction of the training loss when it reaches a reasonably small value, which we call the \emph{flood level}. Our approach makes the loss float around the flood level by doing mini-batched gradient descent as usual but gradient ascent if the training loss is below the flood level. This can be implemented with one line of code and is compatible with any stochastic optimizer and other regularizers. With flooding, the model will continue to ``random walk'' with the same non-zero training loss, and we expect it to drift into an area with a flat loss landscape that leads to better generalization. We experimentally show that flooding improves performance and, as a byproduct, induces a double descent curve of the test loss.
Modern deep neural networks require a significant amount of computing time and power to train and deploy, which limits their usage on edge devices. Inspired by the iterative weight pruning in the Lottery Ticket Hypothesis, we propose DropNet, an iterative pruning method which prunes nodes/filters to reduce network complexity. DropNet iteratively removes nodes/filters with the lowest average post-activation value across all training samples. Empirically, we show that DropNet is robust across a wide range of scenarios, including MLPs and CNNs using the MNIST and CIFAR datasets. We show that up to 90% of the nodes/filters can be removed without any significant loss of accuracy. The final pruned network performs well even with reinitialisation of the weights and biases. DropNet also achieves similar accuracy to an oracle which greedily removes nodes/filters one at a time to minimise training loss, highlighting its effectiveness.
We study the problem of constructing black-box adversarial attacks, where no model information is revealed except for the feedback knowledge of the given inputs. To obtain sufficient knowledge for crafting adversarial examples, previous methods query the target model with inputs that are perturbed with different searching directions. However, these methods suffer from poor query efficiency since the employed searching directions are sampled randomly. To mitigate this issue, we formulate the goal of mounting efficient attacks as an optimization problem in which the adversary tries to fool the target model with a limited number of queries. Under such settings, the adversary has to select appropriate searching directions to reduce the number of model queries. By solving the efficient-attack problem, we find that we need to distill the knowledge in both the path of the adversarial examples and the path of the searching directions. Therefore, we propose a novel framework, dual-path distillation, that utilizes the feedback knowledge not only to craft adversarial examples but also to alter the searching directions to achieve efficient attacks. Experimental results suggest that our framework can significantly increase the query efficiency.
We propose a new algorithmic framework for learning autoencoders of data distributions. In this framework, we minimize the discrepancy between the model distribution and the target one, with relational regularization on learnable latent prior. This regularization penalizes the fused Gromov-Wasserstein (FGW) distance between the latent prior and its corresponding posterior, which allows us to learn a structured prior distribution associated with the generative model in a flexible way. Moreover, it helps us co-train multiple autoencoders even if they are with heterogeneous architectures and incomparable latent spaces. We implement the framework with two scalable algorithms, making it applicable for both probabilistic and deterministic autoencoders. Our relational regularized autoencoder (RAE) outperforms existing methods, e.g., variational autoencoder, Wasserstein autoencoder, and their variants, on generating images. Additionally, our relational co-training strategy of autoencoders achieves encouraging results in both synthesis and real-world multi-view learning tasks.
We provide theoretical investigations into off-policy evaluation in reinforcement learning using function approximators for (marginalized) importance weights and value functions. Our contributions include: (1) A new estimator, MWL, that directly estimates importance ratios over the state-action distributions, removing the reliance on knowledge of the behavior policy as in prior work (Liu et.al, 2018), (2) Another new estimator, MQL, obtained by swapping the roles of importance weights and value-functions in MWL. MQL has an intuitive interpretation of minimizing average Bellman errors and can be combined with MWL in a doubly robust manner, (3) Several additional results that offer further insights, including the sample complexities of MWL and MQL, their asymptotic optimality in the tabular setting, how the learned importance weights depend the choice of the discriminator class, and how our methods provide a unified view of some old and new algorithms in RL.
Researches using margin based comparison loss demonstrate the effectiveness of penalizing the distance between face feature and their corresponding class centers. Despite their popularity and excellent performance, they do not explicitly encourage the generic embedding learning for an open set recognition problem. In this paper, we analyse margin based softmax loss in probability view. With this perspective, we propose two general principles: 1) monotonically decreasing and 2) margin probability penalty, for designing new margin loss functions. Unlike methods optimized with single comparison metric, we provide a new perspective to treat open set face recognition as a problem of information transmission. And the generalization capability for face embedding is gained with more clean information. An auto-encoder architecture called Linear-Auto-TS-Encoder(LATSE) is proposed to corroborate this finding. Extensive experiments on several benchmarks demonstrate that LATSE help face embedding to gain more generalization capability and it boost the single model performance with open training dataset to more than 99% on MegaFace test.
This paper studies an entropy-based multi-objective Bayesian optimization (MBO). Existing entropy-based MBO methods need complicated approximations to evaluate entropy or employ over-simplification that ignores trade-off among objectives. We propose a novel entropy-based MBO called Pareto-frontier entropy search (PFES), which is based on the information gain of Pareto-frontier. We show that our entropy evaluation can be reduced to a closed form whose computation is quite simple while capturing the trade-off relation in Pareto-frontier. We further propose an extension for the ``decoupled'' setting, in which each objective function can be observed separately, and show that the PFES-based approach derives a natural extension of the original acquisition function which can also be evaluated simply. Our numerical experiments show effectiveness of PFES through several benchmark datasets, and real-word datasets from materials science.
State-of-the-art neural machine translation models generate a translation from left to right and every step is conditioned on the previously generated tokens. The sequential nature of this generation process causes fundamental latency in inference since we cannot generate multiple tokens in each sentence in parallel. We propose an attention-masking based model, called Disentangled Context (DisCo) transformer, that simultaneously generates all tokens given different contexts. The DisCo transformer is trained to predict every output token given an arbitrary subset of the other reference tokens. We also develop the parallel easy-first inference algorithm, which iteratively refines every token in parallel and reduces the number of required iterations. Our extensive experiments on 7 translation directions with varying data sizes demonstrate that our model achieves competitive, if not better, performance compared to the state of the art in non-autoregressive machine translation while significantly reducing decoding time on average.
While deep neural networks achieve great performance on fitting the training distribution, the learned networks are prone to overfitting and are susceptible to adversarial attacks. In this regard, a number of mixup based augmentation methods have been recently proposed. However, these approaches mainly focus on creating previously unseen virtual examples and can sometimes provide misleading supervisory signal to the network. To this end, we propose Puzzle Mix, a mixup method for explicitly utilizing the saliency information and the underlying statistics of the natural examples. This leads to an interesting optimization problem alternating between the multi-label objective for optimal mixing mask and saliency discounted optimal transport objective. Our experiments show Puzzle Mix achieves the state of the art generalization and the adversarial robustness results compared to other mixup methods on CIFAR-100, Tiny-ImageNet, and ImageNet datasets, and the source code is available at https://github.com/snu-mllab/PuzzleMix.
Heretofore, neural networks with external memory are restricted to single memory with lossy representations of memory interactions. A rich representation of relationships between memory pieces urges a high-order and segregated relational memory. In this paper, we propose to separate the storage of individual experiences (item memory) and their occurring relationships (relational memory). The idea is implemented through a novel Self-attentive Associative Memory (SAM) operator. Found upon outer product, SAM forms a set of associative memories that represent the hypothetical high-order relationships between arbitrary pairs of memory elements, through which a relational memory is constructed from an item memory. The two memories are wired into a single sequential model capable of both memorization and relational reasoning. We achieve competitive results with our proposed two-memory model in a diversity of machine learning tasks, from challenging synthetic problems to practical testbeds such as geometry, graph, reinforcement learning, and question answering.
In this paper, we provide an explicit theoretical connection between Sparse subspace clustering (SSC) and spectral clustering (SC) from the perspective of learning a data similarity matrix. We show that spectral clustering with Gaussian kernel can be viewed as sparse subspace clustering with entropy-norm (SSC+E). Compared to SSC, SSC+E can obtain an analytical, symmetrical, nonnegative and nonlinearly-representational similarity matrix. Besides, SSC+E makes use of Gaussian kernel to compute the sparse similarity matrix of objects, which can avoid the complex computation of the sparse optimization program of SSC. Finally, we provide the experimental analysis to compare the efficiency and effectiveness of sparse subspace clustering and spectral clustering on ten benchmark data sets. The theoretical and experimental analysis can well help users for the selection of high-dimensional data clustering algorithms.
Modern data acquisition routinely produce massive amounts of event sequence data in various domains, such as social media, healthcare, and financial markets. These data often exhibit complicated short-term and long-term temporal dependencies. However, most of the existing recurrent neural network based point process models fail to capture such dependencies, and yield unreliable prediction performance. To address this issue, we propose a Transformer Hawkes Process (THP) model, which leverages the self-attention mechanism to capture long-term dependencies and meanwhile enjoys computational efficiency. Numerical experiments on various datasets show that THP outperforms existing models in terms of both likelihood and event prediction accuracy by a notable margin. Moreover, THP is quite general and can incorporate additional structural knowledge. We provide a concrete example, where THP achieves improved prediction performance for learning multiple point processes when incorporating their relational information.
[ Virtual ]
We study few-shot supervised domain adaptation (DA) for regression problems, where only a few labeled target domain data and many labeled source domain data are available. Many of the current DA methods base their transfer assumptions on either parametrized distribution shift or apparent distribution similarities, e.g., identical conditionals or small distributional discrepancies. However, these assumptions may preclude the possibility of adaptation from intricately shifted and apparently very different distributions. To overcome this problem, we propose mechanism transfer, a meta-distributional scenario in which a data generating mechanism is invariant among domains. This transfer assumption can accommodate nonparametric shifts resulting in apparently different distributions while providing a solid statistical basis for DA. We take the structural equations in causal modeling as an example and propose a novel DA method, which is shown to be useful both theoretically and experimentally. Our method can be seen as the first attempt to fully leverage the invariance of structural causal models for DA.
We consider the problem of the limited-bandwidth communication for multi-agent reinforcement learning, where agents cooperate with the assistance of a communication protocol and a scheduler. The protocol and scheduler jointly determine which agent is communicating what message and to whom. Under the limited bandwidth constraint, a communication protocol is required to generate informative messages. Meanwhile, an unnecessary communication connection should not be established because it occupies limited resources in vain. In this paper, we develop an Informative Multi-Agent Communication (IMAC) method to learn efficient communication protocols as well as scheduling. First, from the perspective of communication theory, we prove that the limited bandwidth constraint requires low-entropy messages throughout the transmission. Then inspired by the information bottleneck principle, we learn a valuable and compact communication protocol and a weight-based scheduler. To demonstrate the efficiency of our method, we conduct extensive experiments in various cooperative and competitive multi-agent tasks with different numbers of agents and different bandwidths. We show that IMAC converges faster and leads to efficient communication among agents under the limited bandwidth as compared to many baseline methods.
The Transformer is widely used in natural language processing tasks. To train a Transformer however, one usually needs a carefully designed learning rate warm-up stage, which is shown to be crucial to the final performance but will slow down the optimization and bring more hyper-parameter tunings. In this paper, we first study theoretically why the learning rate warm-up stage is essential and show that the location of layer normalization matters. Specifically, we prove with mean field theory that at initialization, for the original-designed Post-LN Transformer, which places the layer normalization between the residual blocks, the expected gradients of the parameters near the output layer are large. Therefore, using a large learning rate on those gradients makes the training unstable. The warm-up stage is practically helpful for avoiding this problem. On the other hand, our theory also shows that if the layer normalization is put inside the residual blocks (recently proposed as Pre-LN Transformer), the gradients are well-behaved at initialization. This motivates us to remove the warm-up stage for the training of Pre-LN Transformers. We show in our experiments that Pre-LN Transformers without the warm-up stage can reach comparable results with baselines while requiring significantly less training time and hyper-parameter tuning …
Many real-world applications have to tackle the Positive-Unlabeled (PU) learning problem, i.e., learning binary classifiers from a large amount of unlabeled data and a few labeled positive examples. While current state-of-the-art methods employ importance reweighting to design various biased or unbiased risk estimators, they completely ignored the learning capability of the model itself, which could provide reliable supervision. This motivates us to propose a novel Self-PU learning framework, which seamlessly integrates PU learning and self-training. Self-PU highlights three ``self''-oriented building blocks: a self-paced training algorithm that adaptively discovers and augments confident positive/negative examples as the training proceeds; a self-reweighted, instance-aware loss; and a self-distillation scheme that introduces teacher-students learning as an effective regularization for PU learning. We demonstrate the state-of-the-art performance of Self-PU on common PU learning benchmarks (MNIST and CIFAR10), which compare favorably against the latest competitors. Moreover, we study a real-world application of PU learning, i.e., classifying brain images of Alzheimer's Disease. Self-PU obtains significantly improved results on the renowned Alzheimer's Disease Neuroimaging Initiative (ADNI) database over existing methods.