Mentoring Social Thu 22 Jul 12:30 a.m.
As a part of the WiML Un-Workshop at ICML 2021, on July 21, 2:30 - 3:30 pm EDT, we will host a Mentoring Social, virtually on GatherTown.
The social includes six mentoring roundtables hosted in parallel, where the mentors will target a diverse set of non-technical topics, such as advice on conducting research in both academia and industry, addressing the two-body problem, grant writing strategies, and career paths including non-linear trajectory to Machine Learning. We are excited to have mentors from industry and academia, including Been Kim, Shakir Mohamed, Lalana Kagal, Dina Obeid, Angelique Taylor, and Anna Goldenberg.
In addition, we created a general space/hall in GatherTown, where attendees can socialize with each other. Feel free to reach out to our volunteers in GatherTown for any questions or comments. We look forward to seeing you there!
Oral: Learning Theory 7 Thu 22 Jul 02:00 a.m.

In single-item auction design, it is well known due to Cremer and McLean that when bidders’ valuations are drawn from a correlated prior distribution, the auctioneer can extract full social surplus as revenue. However, in most real-world applications, the prior is usually unknown and can only be learned from historical data. In this work, we investigate the robustness of the optimal auction with correlated valuations via sample complexity analysis. We prove upper and lower bounds on the number of samples from the unknown prior required to learn a (1-epsilon)-approximately optimal auction. Our results reinforce the common belief that optimal correlated auctions are sensitive to the distribution parameters and hard to learn unless the prior distribution is well-behaved.

When reasoning about strategic behavior in a machine learning context it is tempting to combine standard microfoundations of rational agents with the statistical decision theory underlying classification. In this work, we argue that a direct combination of these ingredients leads to brittle solution concepts of limited descriptive and prescriptive value. First, we show that rational agents with perfect information produce discontinuities in the aggregate response to a decision rule that we often do not observe empirically. Second, when any positive fraction of agents is not perfectly strategic, desirable stable points---where the classifier is optimal for the data it entails---no longer exist. Third, optimal decision rules under standard microfoundations maximize a measure of negative externality known as social burden within a broad class of assumptions about agent behavior. Recognizing these limitations we explore alternatives to standard microfoundations for binary classification. We describe desiderata that help navigate the space of possible assumptions about agent responses, and we then propose the noisy response model. Inspired by smoothed analysis and empirical observations, noisy response incorporates imperfection in the agent responses, which we show mitigates the limitations of standard microfoundations. Our model retains analytical tractability, leads to more robust insights about stable points, and imposes …

Bayesian persuasion studies how an informed sender should partially disclose information to influence the behavior of a self-interested receiver. Classical models make the stringent assumption that the sender knows the receiver’s utility. This can be relaxed by considering an online learning framework in which the sender repeatedly faces a receiver of an unknown, adversarially selected type. We study, for the first time, an online Bayesian persuasion setting with multiple receivers. We focus on the case with no externalities and binary actions, as customary in offline models. Our goal is to design no-regret algorithms for the sender with polynomial per-iteration running time. First, we prove a negative result: for any 0 < α ≤ 1, there is no polynomial-time no-α-regret algorithm when the sender’s utility function is supermodular or anonymous. Then, we focus on the setting of submodular sender’s utility functions and we show that, in this case, it is possible to design a polynomial-time no-(1-1/e)-regret algorithm. To do so, we introduce a general online gradient descent framework to handle online learning problems with a finite number of possible loss functions. This requires the existence of an approximate projection oracle. We show that, in our setting, there exists one such projection …

Consider N players that each uses a mixture of K resources. Each of the players' reward functions includes a linear pricing term for each resource that is controlled by the game manager. We assume that the game is strongly monotone, so if each player runs gradient descent, the dynamics converge to a unique Nash equilibrium (NE). Unfortunately, this NE can be inefficient since the total load on a given resource can be very high. In principle, we can control the total loads by tuning the coefficients of the pricing terms. However, finding pricing coefficients that balance the loads requires knowing the players' reward functions and their action sets. Obtaining this game structure information is infeasible in a large-scale network and violates the users' privacy. To overcome this, we propose a simple algorithm that learns to shift the NE of the game to meet the total load constraints by adjusting the pricing coefficients in an online manner. Our algorithm only requires the total load per resource as feedback and does not need to know the reward functions or the action sets. We prove that our algorithm guarantees convergence in L2 to a NE that meets target total load constraints. Simulations show …



Understanding generalization and estimation error of estimators for simple models such as linear and generalized linear models has attracted a lot of attention recently. This is in part due to an interesting observation made in machine learning community that highly over-parameterized neural networks achieve zero training error, and yet they are able to generalize well over the test samples. This phenomenon is captured by the so called double descent curve, where the generalization error starts decreasing again after the interpolation threshold. A series of recent works tried to explain such phenomenon for simple models. In this work, we analyze the asymptotics of estimation error in ridge estimators for convolutional linear models. These convolutional inverse problems, also known as deconvolution, naturally arise in different fields such as seismology, imaging, and acoustics among others. Our results hold for a large class of input distributions that include i.i.d. features as a special case. We derive exact formulae for estimation error of ridge estimators that hold in a certain high-dimensional regime. We show the double descent phenomenon in our experiments for convolutional models and show that our theoretical results match the experiments.
Oral: Supervised Learning 3 Thu 22 Jul 02:00 a.m.
Although Label Distribution Learning (LDL) has witnessed extensive classification applications, it faces the challenge of objective mismatch -- the objective of LDL mismatches that of classification, which has seldom been noticed in existing studies. Our goal is to solve the objective mismatch and improve the classification performance of LDL. Specifically, we extend the margin theory to LDL and propose a new LDL method called \textbf{L}abel \textbf{D}istribution \textbf{L}earning \textbf{M}achine (LDLM). First, we define the label distribution margin and propose the \textbf{S}upport \textbf{V}ector \textbf{R}egression \textbf{M}achine (SVRM) to learn the optimal label. Second, we propose the adaptive margin loss to learn label description degrees. In theoretical analysis, we develop a generalization theory for the SVRM and analyze the generalization of LDLM. Experimental results validate the better classification performance of LDLM.

Collecting more diverse and representative training data is often touted as a remedy for the disparate performance of machine learning predictors across subpopulations. However, a precise framework for understanding how dataset properties like diversity affect learning outcomes is largely lacking. By casting data collection as part of the learning process, we demonstrate that diverse representation in training data is key not only to increasing subgroup performances, but also to achieving population-level objectives. Our analysis and experiments describe how dataset compositions influence performance and provide constructive results for using trends in existing data, alongside domain knowledge, to help guide intentional, objective-aware dataset design

Machine learning algorithms with empirical risk minimization usually suffer from poor generalization performance due to the greedy exploitation of correlations among the training data, which are not stable under distributional shifts. Recently, some invariant learning methods for out-of-distribution (OOD) generalization have been proposed by leveraging multiple training environments to find invariant relationships. However, modern datasets are frequently assembled by merging data from multiple sources without explicit source labels. The resultant unobserved heterogeneity renders many invariant learning methods inapplicable. In this paper, we propose Heterogeneous Risk Minimization (HRM) framework to achieve joint learning of latent heterogeneity among the data and invariant relationship, which leads to stable prediction despite distributional shifts. We theoretically characterize the roles of the environment labels in invariant learning and justify our newly proposed HRM framework. Extensive experimental results validate the effectiveness of our HRM framework.

We consider learning to optimize a classification metric defined by a black-box function of the confusion matrix. Such black-box learning settings are ubiquitous, for example, when the learner only has query access to the metric of interest, or in noisy-label and domain adaptation applications where the learner must evaluate the metric via performance evaluation using a small validation sample. Our approach is to adaptively learn example weights on the training dataset such that the resulting weighted objective best approximates the metric on the validation sample. We show how to model and estimate the example weights and use them to iteratively post-shift a pre-trained class probability estimator to construct a classifier. We also analyze the resulting procedure's statistical properties. Experiments on various label noise, domain shift, and fair classification setups confirm that our proposal compares favorably to the state-of-the-art baselines for each application.

The performance of neural networks depends on precise relationships between four distinct ingredients: the architecture, the loss function, the statistical structure of inputs, and the ground truth target function.
Much theoretical work has focused on understanding the role of the first two ingredients under highly simplified models of random uncorrelated data and target functions.
In contrast, performance likely relies on a conspiracy between the statistical structure of the input distribution and the structure of the function to be learned.
To understand this better we revisit ridge regression in high dimensions, which corresponds to an exceedingly simple architecture and loss function, but we analyze its performance under arbitrary correlations between input features and the target function.
We find a rich mathematical structure that includes: (1) a dramatic reduction in sample complexity when the target function aligns with data anisotropy; (2) the existence of multiple descent curves; (3) a sequence of phase transitions in the performance, loss landscape, and optimal regularization as a function of the amount of data that explains the first two effects.

Good generalization performance across a wide variety of domains caused by many external and internal factors is the fundamental goal of any machine learning algorithm. This paper theoretically proves that the choice of loss function matters for improving the generalization performance of deep learning-based systems. By deriving the generalization error bound for deep neural models trained by stochastic gradient descent, we pinpoint the characteristics of the loss function that is linked to the generalization error and can therefore be used for guiding the loss function selection process. In summary, our main statement in this paper is: choose a stable loss function, generalize better. Focusing on human age estimation from the face which is a challenging topic in computer vision, we then propose a novel loss function for this learning problem. We theoretically prove that the proposed loss function achieves stronger stability, and consequently a tighter generalization error bound, compared to the other common loss functions for this problem. We have supported our findings theoretically, and demonstrated the merits of the guidance process experimentally, achieving significant improvements.

We consider a popular family of constrained optimization problems arising in machine learning that involve optimizing a non-decomposable evaluation metric with a certain thresholded form, while constraining another metric of interest. Examples of such problems include optimizing false negative rate at a fixed false positive rate, optimizing precision at a fixed recall, optimizing the area under the precision-recall or ROC curves, etc. Our key idea is to formulate a rate-constrained optimization that expresses the threshold parameter as a function of the model parameters via the Implicit Function theorem. We show how the resulting optimization problem can be solved using standard gradient based methods. Experiments on benchmark datasets demonstrate the effectiveness of our proposed method over existing state-of-the-art approaches for these problems.
Oral: Reinforcement Learning Theory 2 Thu 22 Jul 02:00 a.m.

Several practical applications of reinforcement learning involve an agent learning from past data without the possibility of further exploration. Often these applications require us to 1) identify a near optimal policy or to 2) estimate the value of a target policy. For both tasks we derive exponential information-theoretic lower bounds in discounted infinite horizon MDPs with a linear function representation for the action value function even if 1) realizability holds, 2) the batch algorithm observes the exact reward and transition functions, and 3) the batch algorithm is given the best a priori data distribution for the problem class. Our work introduces a new `oracle + batch algorithm' framework to prove lower bounds that hold for every distribution. The work shows an exponential separation between batch and online reinforcement learning.

A core element in decision-making under uncertainty is the feedback on the quality of the performed actions. However, in many applications, such feedback is restricted. For example, in recommendation systems, repeatedly asking the user to provide feedback on the quality of recommendations will annoy them. In this work, we formalize decision-making problems with querying budget, where there is a (possibly time-dependent) hard limit on the number of reward queries allowed. Specifically, we focus on multi-armed bandits, linear contextual bandits, and reinforcement learning problems. We start by analyzing the performance of `greedy' algorithms that query a reward whenever they can. We show that in fully stochastic settings, doing so performs surprisingly well, but in the presence of any adversity, this might lead to linear regret. To overcome this issue, we propose the Confidence-Budget Matching (CBM) principle that queries rewards when the confidence intervals are wider than the inverse square root of the available budget. We analyze the performance of CBM based algorithms in different settings and show that it performs well in the presence of adversity in the contexts, initial states, and budgets.

Reinforcement learning (RL) is empirically successful in complex nonlinear Markov decision processes (MDPs) with continuous state spaces. By contrast, the majority of theoretical RL literature requires the MDP to satisfy some form of linear structure, in order to guarantee sample efficient RL. Such efforts typically assume the transition dynamics or value function of the MDP are described by linear functions of the state features. To resolve this discrepancy between theory and practice, we introduce the Effective Planning Window (EPW) condition, a structural condition on MDPs that makes no linearity assumptions. We demonstrate that the EPW condition permits sample efficient RL, by providing an algorithm which provably solves MDPs satisfying this condition. Our algorithm requires minimal assumptions on the policy class, which can include multi-layer neural networks with nonlinear activation functions. Notably, the EPW condition is directly motivated by popular gaming benchmarks, and we show that many classic Atari games satisfy this condition. We additionally show the necessity of conditions like EPW, by demonstrating that simple MDPs with slight nonlinearities cannot be solved sample efficiently.
This paper provides a statistical analysis of high-dimensional batch reinforcement learning (RL) using sparse linear function approximation. When there is a large number of candidate features, our result sheds light on the fact that sparsity-aware methods can make batch RL more sample efficient. We first consider the off-policy policy evaluation problem. To evaluate a new target policy, we analyze a Lasso fitted Q-evaluation method and establish a finite-sample error bound that has no polynomial dependence on the ambient dimension. To reduce the Lasso bias, we further propose a post model-selection estimator that applies fitted Q-evaluation to the features selected via group Lasso. Under an additional signal strength assumption, we derive a sharper instance-dependent error bound that depends on a divergence function measuring the distribution mismatch between the data distribution and occupancy measure of the target policy. Further, we study the Lasso fitted Q-iteration for batch policy optimization and establish a finite-sample error bound depending on the ratio between the number of relevant features and restricted minimal eigenvalue of the data's covariance. In the end, we complement the results with minimax lower bounds for batch-data policy evaluation/optimization that nearly match our upper bounds. The results suggest that having well-conditioned data is …


Oral: Learning Theory 8 Thu 22 Jul 02:00 a.m.


Transfer learning is essential when sufficient data comes from the source domain, with scarce labeled data from the target domain. We develop estimators that achieve minimax linear risk for linear regression problems under distribution shift. Our algorithms cover different transfer learning settings including covariate shift and model shift. We also consider when data are generated from either linear or general nonlinear models. We show that linear minimax estimators are within an absolute constant of the minimax risk even among nonlinear estimators for various source/target distributions.

We consider the problem of detecting signals in the rank-one signal-plus-noise data matrix models that generalize the spiked Wishart matrices. We show that the principal component analysis can be improved by pre-transforming the matrix entries if the noise is non-Gaussian. As an intermediate step, we prove a sharp phase transition of the largest eigenvalues of spiked rectangular matrices, which extends the Baik--Ben Arous--P\'ech\'e (BBP) transition. We also propose a hypothesis test to detect the presence of signal with low computational complexity, based on the linear spectral statistics, which minimizes the sum of the Type-I and Type-II errors when the noise is Gaussian.

A key problem in the theory of meta-learning is to understand how the task distributions influence transfer risk, the expected error of a meta-learner on a new task drawn from the unknown task distribution. In this paper, focusing on fixed design linear regression with Gaussian noise and a Gaussian task (or parameter) distribution, we give distribution-dependent lower bounds on the transfer risk of any algorithm, while we also show that a novel, weighted version of the so-called biased regularized regression method is able to match these lower bounds up to a fixed constant factor. Notably, the weighting is derived from the covariance of the Gaussian task distribution. Altogether, our results provide a precise characterization of the difficulty of meta-learning in this Gaussian setting. While this problem setting may appear simple, we show that it is rich enough to unify the “parameter sharing” and “representation learning” streams of meta-learning; in particular, representation learning is obtained as the special case when the covariance matrix of the task distribution is unknown. For this case we propose to adopt the EM method, which is shown to enjoy efficient updates in our case. The paper is completed by an empirical study of EM. In particular, …

Meta-learning aims to perform fast adaptation on a new task through learning a “prior” from multiple existing tasks. A common practice in meta-learning is to perform a train-validation split (\emph{train-val method}) where the prior adapts to the task on one split of the data, and the resulting predictor is evaluated on another split. Despite its prevalence, the importance of the train-validation split is not well understood either in theory or in practice, particularly in comparison to the more direct \emph{train-train method}, which uses all the per-task data for both training and evaluation.
We provide a detailed theoretical study on whether and when the train-validation split is helpful in the linear centroid meta-learning problem. In the agnostic case, we show that the expected loss of the train-val method is minimized at the optimal prior for meta testing, and this is not the case for the train-train method in general without structural assumptions on the data. In contrast, in the realizable case where the data are generated from linear models, we show that both the train-val and train-train losses are minimized at the optimal prior in expectation. Further, perhaps surprisingly, our main result shows that the train-train method achieves a \emph{strictly better} …


One of the central problems in machine learning is domain adaptation. Different from past theoretical works, we consider a new model of subpopulation shift in the input or representation space. In this work, we propose a provably effective framework based on label propagation by using an input consistency loss. In our analysis we used a simple but realistic “expansion” assumption, which has been proposed in \citet{wei2021theoretical}. It turns out that based on a teacher classifier on the source domain, the learned classifier can not only propagate to the target domain but also improve upon the teacher. By leveraging existing generalization bounds, we also obtain end-to-end finite-sample guarantees on deep neural networks. In addition, we extend our theoretical framework to a more general setting of source-to-target transfer based on an additional unlabeled dataset, which can be easily applied to various learning scenarios. Inspired by our theory, we adapt consistency-based semi-supervised learning methods to domain adaptation settings and gain significant improvements.
Oral: Reinforcement Learning Theory 3 Thu 22 Jul 02:00 a.m.






We tackle the problem of conditioning probabilistic programs on distributions of observable variables. Probabilistic programs are usually conditioned on samples from the joint data distribution, which we refer to as deterministic conditioning. However, in many real-life scenarios, the observations are given as marginal distributions, summary statistics, or samplers. Conventional probabilistic programming systems lack adequate means for modeling and inference in such scenarios. We propose a generalization of deterministic conditioning to stochastic conditioning, that is, conditioning on the marginal distribution of a variable taking a particular form. To this end, we first define the formal notion of stochastic conditioning and discuss its key properties. We then show how to perform inference in the presence of stochastic conditioning. We demonstrate potential usage of stochastic conditioning on several case studies which involve various kinds of stochastic conditioning and are difficult to solve otherwise. Although we present stochastic conditioning in the context of probabilistic programming, our formalization is general and applicable to other settings.
Oral: Deep Learning Optimization Thu 22 Jul 02:00 a.m.


Descent methods for deep networks are notoriously capricious: they require careful tuning of step size, momentum and weight decay, and which method will work best on a new benchmark is a priori unclear. To address this problem, this paper conducts a combined study of neural architecture and optimisation, leading to a new optimiser called Nero: the neuronal rotator. Nero trains reliably without momentum or weight decay, works in situations where Adam and SGD fail, and requires little to no learning rate tuning. Also, Nero's memory footprint is ~ square root that of Adam or LAMB. Nero combines two ideas: (1) projected gradient descent over the space of balanced networks; (2) neuron-specific updates, where the step size sets the angle through which each neuron's hyperplane turns. The paper concludes by discussing how this geometric connection between architecture and optimisation may impact theories of generalisation in deep learning.
Decentralized training of deep learning models enables on-device learning over networks, as well as efficient scaling to large compute clusters. Experiments in earlier works reveal that, even in a data-center setup, decentralized training often suffers from the degradation in the quality of the model: the training and test performance of models trained in a decentralized fashion is in general worse than that of models trained in a centralized fashion, and this performance drop is impacted by parameters such as network size, communication topology and data partitioning. We identify the changing consensus distance between devices as a key parameter to explain the gap between centralized and decentralized training. We show in theory that when the training consensus distance is lower than a critical quantity, decentralized training converges as fast as the centralized counterpart. We empirically validate that the relation between generalization performance and consensus distance is consistent with this theoretical observation. Our empirical insights allow the principled design of better decentralized training schemes that mitigate the performance drop. To this end, we provide practical training guidelines and exemplify its effectiveness on the data-center setup as the important first step.

Sparse neural networks have been widely applied to reduce the computational demands of training and deploying over-parameterized deep neural networks. For inference acceleration, methods that discover a sparse network from a pre-trained dense network (dense-to-sparse training) work effectively. Recently, dynamic sparse training (DST) has been proposed to train sparse neural networks without pre-training a dense model (sparse-to-sparse training), so that the training process can also be accelerated. However, previous sparse-to-sparse methods mainly focus on Multilayer Perceptron Networks (MLPs) and Convolutional Neural Networks (CNNs), failing to match the performance of dense-to-sparse methods in the Recurrent Neural Networks (RNNs) setting. In this paper, we propose an approach to train intrinsically sparse RNNs with a fixed parameter count in one single run, without compromising performance. During training, we allow RNN layers to have a non-uniform redistribution across cell gates for better regularization. Further, we propose SNT-ASGD, a novel variant of the averaged stochastic gradient optimizer, which significantly improves the performance of all sparse training methods for RNNs. Using these strategies, we achieve state-of-the-art sparse training results, better than the dense-to-sparse methods, with various types of RNNs on Penn TreeBank and Wikitext-2 datasets. Our codes are available at https://github.com/Shiweiliuiiiiiii/Selfish-RNN.

The early phase of training a deep neural network has a dramatic effect on the local curvature of the loss function. For instance, using a small learning rate does not guarantee stable optimization because the optimization trajectory has a tendency to steer towards regions of the loss surface with increasing local curvature. We ask whether this tendency is connected to the widely observed phenomenon that the choice of the learning rate strongly influences generalization. We first show that stochastic gradient descent (SGD) implicitly penalizes the trace of the Fisher Information Matrix (FIM), a measure of the local curvature, from the start of training. We argue it is an implicit regularizer in SGD by showing that explicitly penalizing the trace of the FIM can significantly improve generalization. We highlight that poor final generalization coincides with the trace of the FIM attaining a large value early in training, to which we refer as catastrophic Fisher explosion. Finally, to gain insight into the regularization effect of penalizing the trace of the FIM, we show that it limits memorization by reducing the learning speed of examples with noisy labels more than that of the examples with clean labels.

Decentralized training of deep learning models is a key element for enabling data privacy and on-device learning over networks. In realistic learning scenarios, the presence of heterogeneity across different clients' local datasets poses an optimization challenge and may severely deteriorate the generalization performance. In this paper, we investigate and identify the limitation of several decentralized optimization algorithms for different degrees of data heterogeneity. We propose a novel momentum-based method to mitigate this decentralized training difficulty. We show in extensive empirical experiments on various CV/NLP datasets (CIFAR-10, ImageNet, and AG News) and several network topologies (Ring and Social Network) that our method is much more robust to the heterogeneity of clients' data than other existing methods, by a significant improvement in test performance (1%-20%).

We provide a detailed analysis of the dynamics ofthe gradient flow in overparameterized two-layerlinear models. A particularly interesting featureof this model is that its nonlinear dynamics can beexactly solved as a consequence of a large num-ber of conservation laws that constrain the systemto follow particular trajectories. More precisely,the gradient flow preserves the difference of theGramian matrices of the input and output weights,and its convergence to equilibrium depends onboth the magnitude of that difference (which isfixed at initialization) and the spectrum of the data.In addition, and generalizing prior work, we proveour results without assuming small, balanced orspectral initialization for the weights. Moreover,we establish interesting mathematical connectionsbetween matrix factorization problems and differ-ential equations of the Riccati type.
Social: The moral (and morale) compass: A search for meaning in AI research Thu 22 Jul 02:00 a.m.
This social will focus on a discussion on finding a balance between the good and the ugly side of AI research. On one side, AI promises automation and availability that can relieve humans from mundane tasks. On the other, the power of AI in society comes with the price of systematic bias, misinformation, and disruption in the labor market. In this fast approaching field of research, how to find meaning in our research that can serve as a moral compass so that we don’t lose focus on problems that can make a true positive impact on society? The social will be interactive where participants will share their thoughts and experiences on societal impact, public opinion of AI, and AI ethics in connection to finding purpose in research and works on AI.
Oral: Deep Learning Theory 4 Thu 22 Jul 02:00 a.m.

Despite their overwhelming capacity to overfit, deep neural networks trained by specific optimization algorithms tend to generalize relatively well to unseen data. Recently, researchers explained it by investigating the implicit bias of optimization algorithms. A remarkable progress is the work (Lyu & Li, 2019), which proves gradient descent (GD) maximizes the margin of homogeneous deep neural networks. Except the first-order optimization algorithms like GD, adaptive algorithms such as AdaGrad, RMSProp and Adam are popular owing to their rapid training process. Mean-while, numerous works have provided empirical evidence that adaptive methods may suffer from poor generalization performance. However, theoretical explanation for the generalization of adaptive optimization algorithms is still lacking. In this paper, we study the implicit bias of adaptive optimization algorithms on homogeneous neural networks. In particular, we study the convergent direction of parameters when they are optimizing the logistic loss. We prove that the convergent direction of Adam and RMSProp is the same as GD, while for AdaGrad, the convergent direction depends on the adaptive conditioner. Technically, we provide a unified framework to analyze convergent direction of adaptive optimization algorithms by constructing novel and nontrivial adaptive gradient flow and surrogate margin. The theoretical findings explain the superiority on generalization …

Gaussian noise injections (GNIs) are a family of simple and widely-used regularisation methods for training neural networks, where one injects additive or multiplicative Gaussian noise to the network activations at every iteration of the optimisation algorithm, which is typically chosen as stochastic gradient descent (SGD). In this paper, we focus on the so-called implicit effect' of GNIs, which is the effect of the injected noise on the dynamics of SGD. We show that this effect induces an \emph{asymmetric heavy-tailed noise} on SGD gradient updates. In order to model this modified dynamics, we first develop a Langevin-like stochastic differential equation that is driven by a general family of \emph{asymmetric} heavy-tailed noise. Using this model we then formally prove that GNIs induce animplicit bias', which varies depending on the heaviness of the tails and the level of asymmetry. Our empirical results confirm that different types of neural networks trained with GNIs are well-modelled by the proposed dynamics and that the implicit effect of these injections induces a bias that degrades the performance of networks.

Noise injection is an effective way of circumventing overfitting and enhancing generalization in machine learning, the rationale of which has been validated in deep learning as well. Recently, noise injection exhibits surprising effectiveness when generating high-fidelity images in Generative Adversarial Networks (GANs) (e.g. StyleGAN). Despite its successful applications in GANs, the mechanism of its validity is still unclear. In this paper, we propose a geometric framework to theoretically analyze the role of noise injection in GANs. First, we point out the existence of the adversarial dimension trap inherent in GANs, which leads to the difficulty of learning a proper generator. Second, we successfully model the noise injection framework with exponential maps based on Riemannian geometry. Guided by our theories, we propose a general geometric realization for noise injection. Under our novel framework, the simple noise injection used in StyleGAN reduces to the Euclidean case. The goal of our work is to make theoretical steps towards understanding the underlying mechanism of state-of-the-art GAN algorithms. Experiments on image generation and GAN inversion validate our theory in practice.

Federated Learning (FL) is an emerging learning scheme that allows different distributed clients to train deep neural networks together without data sharing. Neural networks have become popular due to their unprecedented success. To the best of our knowledge, the theoretical guarantees of FL concerning neural networks with explicit forms and multi-step updates are unexplored. Nevertheless, training analysis of neural networks in FL is non-trivial for two reasons: first, the objective loss function we are optimizing is non-smooth and non-convex, and second, we are even not updating in the gradient direction. Existing convergence results for gradient descent-based methods heavily rely on the fact that the gradient direction is used for updating. The current paper presents a new class of convergence analysis for FL, Federated Neural Tangent Kernel (FL-NTK), which corresponds to overparamterized ReLU neural networks trained by gradient descent in FL and is inspired by the analysis in Neural Tangent Kernel (NTK). Theoretically, FL-NTK converges to a global-optimal solution at a linear rate with properly tuned learning parameters. Furthermore, with proper distributional assumptions, FL-NTK can also achieve good generalization. The proposed theoretical analysis scheme can be generalized to more complex neural networks.

Recently, learning a model that generalizes well on out-of-distribution (OOD) data has attracted great attention in the machine learning community. In this paper, after defining OOD generalization by Wasserstein distance, we theoretically justify that a model robust to input perturbation also generalizes well on OOD data. Inspired by previous findings that adversarial training helps improve robustness, we show that models trained by adversarial training have converged excess risk on OOD data. Besides, in the paradigm of pre-training then fine-tuning, we theoretically justify that the input perturbation robust model in the pre-training stage provides an initialization that generalizes well on downstream OOD data. Finally, various experiments conducted on image classification and natural language understanding tasks verify our theoretical findings.

Generative adversarial networks (GAN) are a widely used class of deep generative models, but their minimax training dynamics are not understood very well. In this work, we show that GANs with a 2-layer infinite-width generator and a 2-layer finite-width discriminator trained with stochastic gradient ascent-descent have no spurious stationary points. We then show that when the width of the generator is finite but wide, there are no spurious stationary points within a ball whose radius becomes arbitrarily large (to cover the entire parameter space) as the width goes to infinity.

Oral: Bandits 2 Thu 22 Jul 02:00 a.m.



We introduce a new graphical bilinear bandit problem where a learner (or a \emph{central entity}) allocates arms to the nodes of a graph and observes for each edge a noisy bilinear reward representing the interaction between the two end nodes. We study the best arm identification problem in which the learner wants to find the graph allocation maximizing the sum of the bilinear rewards. By efficiently exploiting the geometry of this bandit problem, we propose a \emph{decentralized} allocation strategy based on random sampling with theoretical guarantees. In particular, we characterize the influence of the graph structure (e.g. star, complete or circle) on the convergence rate and propose empirical experiments that confirm this dependency.

In this work, we develop linear bandit algorithms that automatically adapt to different environments. By plugging a novel loss estimator into the optimization problem that characterizes the instance-optimal strategy, our first algorithm not only achieves nearly instance-optimal regret in stochastic environments, but also works in corrupted environments with additional regret being the amount of corruption, while the state-of-the-art (Li et al., 2019) achieves neither instance-optimality nor the optimal dependence on the corruption amount. Moreover, by equipping this algorithm with an adversarial component and carefully-designed testings, our second algorithm additionally enjoys minimax-optimal regret in completely adversarial environments, which is the first of this kind to our knowledge. Finally, all our guarantees hold with high probability, while existing instance-optimal guarantees only hold in expectation.


The RKHS bandit problem (also called kernelized multi-armed bandit problem) is an online optimization problem of non-linear functions with noisy feedback. Although the problem has been extensively studied, there are unsatisfactory results for some problems compared to the well-studied linear bandit case. Specifically, there is no general algorithm for the adversarial RKHS bandit problem. In addition, high computational complexity of existing algorithms hinders practical application. We address these issues by considering a novel amalgamation of approximation theory and the misspecified linear bandit problem. Using an approximation method, we propose efficient algorithms for the stochastic RKHS bandit problem and the first general algorithm for the adversarial RKHS bandit problem. Furthermore, we empirically show that one of our proposed methods has comparable cumulative regret to IGP-UCB and its running time is much shorter.
We propose a framework for model selection by combining base algorithms in stochastic bandits and reinforcement learning. We require a candidate regret bound for each base algorithm that may or may not hold. We select base algorithms to play in each round using a ``balancing condition'' on the candidate regret bounds. Our approach simultaneously recovers previous worst-case regret bounds, while also obtaining much smaller regret in natural scenarios when some base learners significantly exceed their candidate bounds. Our framework is relevant in many settings, including linear bandits and MDPs with nested function classes, linear bandits with unknown misspecification, and tuning confidence parameters of algorithms such as LinUCB. Moreover, unlike recent efforts in model selection for linear stochastic bandits, our approach can be extended to consider adversarial rather than stochastic contexts.
Oral: Online Learning 2 Thu 22 Jul 02:00 a.m.


Online allocation problems with resource constraints have a rich history in computer science and operations research. In this paper, we introduce the regularized online allocation problem, a variant that includes a non-linear regularizer acting on the total resource consumption. In this problem, requests repeatedly arrive over time and, for each request, a decision maker needs to take an action that generates a reward and consumes resources. The objective is to simultaneously maximize total rewards and the value of the regularizer subject to the resource constraints. Our primary motivation is the online allocation of internet advertisements wherein firms seek to maximize additive objectives such as the revenue or efficiency of the allocation. By introducing a regularizer, firms can account for the fairness of the allocation or, alternatively, punish under-delivery of advertisements---two common desiderata in internet advertising markets. We design an algorithm when arrivals are drawn independently from a distribution that is unknown to the decision maker. Our algorithm is simple, fast, and attains the optimal order of sub-linear regret compared to the optimal allocation with the benefit of hindsight. Numerical experiments confirm the effectiveness of the proposed algorithm and of the regularizers in an internet advertising application.



When learning from streaming data, a change in the data distribution, also known as concept drift, can render a previously-learned model inaccurate and require training a new model. We present an adaptive learning algorithm that extends previous drift-detection-based methods by incorporating drift detection into a broader stable-state/reactive-state process. The advantage of our approach is that we can use aggressive drift detection in the stable state to achieve a high detection rate, but mitigate the false positive rate of standalone drift detection via a reactive state that reacts quickly to true drifts while eliminating most false positives. The algorithm is generic in its base learner and can be applied across a variety of supervised learning problems. Our theoretical analysis shows that the risk of the algorithm is (i) statistically better than standalone drift detection and (ii) competitive to an algorithm with oracle knowledge of when (abrupt) drifts occur. Experiments on synthetic and real datasets with concept drifts confirm our theoretical analysis.

Motivated by applications in shared mobility, we address the problem of allocating a group of agents to a set of resources to maximize a cumulative welfare objective. We model the welfare obtainable from each resource as a monotone DR-submodular function which is a-priori unknown and can only be learned by observing the welfare of selected allocations. Moreover, these functions can depend on time-varying contextual information. We propose a distributed scheme to maximize the cumulative welfare by designing a repeated game among the agents, who learn to act via regret minimization. We propose two design choices for the game rewards based on upper confidence bounds built around the unknown welfare functions. We analyze them theoretically, bounding the gap between the cumulative welfare of the game and the highest cumulative welfare obtainable in hindsight. Finally, we evaluate our approach in a realistic case study of rebalancing a shared mobility system (i.e., positioning vehicles in strategic areas). From observed trip data, our algorithm gradually learns the users' demand pattern and improves the overall system operation.
Social: Yoga+Meditation Hour Thu 22 Jul 02:15 a.m.
Join us for 40 minutes of Power Vinyasa yoga, followed by a guided meditation. The event will last 1 hour to 1 hour 15 minutes. It will be held twice during ICML, once in a morning session and once in an evening session. Pick the one that works best for your schedule, or come to both!
Oral: Supervised Learning 4 Thu 22 Jul 03:00 a.m.


The great success of modern machine learning models on large datasets is contingent on extensive computational resources with high financial and environmental costs. One way to address this is by extracting subsets that generalize on par with the full data. In this work, we propose a general framework, GRAD-MATCH, which finds subsets that closely match the gradient of the \emph{training or validation} set. We find such subsets effectively using an orthogonal matching pursuit algorithm. We show rigorous theoretical and convergence guarantees of the proposed algorithm and, through our extensive experiments on real-world datasets, show the effectiveness of our proposed framework. We show that GRAD-MATCH significantly and consistently outperforms several recent data-selection algorithms and achieves the best accuracy-efficiency trade-off. GRAD-MATCH is available as a part of the CORDS toolkit: \url{https://github.com/decile-team/cords}.

We present an optimization framework for learning a fair classifier in the presence of noisy perturbations in the protected attributes. Compared to prior work, our framework can be employed with a very general class of linear and linear-fractional fairness constraints, can handle multiple, non-binary protected attributes, and outputs a classifier that comes with provable guarantees on both accuracy and fairness. Empirically, we show that our framework can be used to attain either statistical rate or false positive rate fairness guarantees with a minimal loss in accuracy, even when the noise is large, in two real-world datasets.

Training deep neural network models in the presence of corrupted supervision is challenging as the corrupted data points may significantly impact generalization performance. To alleviate this problem, we present an efficient robust algorithm that achieves strong guarantees without any assumption on the type of corruption and provides a unified framework for both classification and regression problems. Unlike many existing approaches that quantify the quality of the data points (e.g., based on their individual loss values), and filter them accordingly, the proposed algorithm focuses on controlling the collective impact of data points on the average gradient. Even when a corrupted data point failed to be excluded by our algorithm, the data point will have a very limited impact on the overall loss, as compared with state-of-the-art filtering methods based on loss values. Extensive experiments on multiple benchmark datasets have demonstrated the robustness of our algorithm under different types of corruption. Our code is available at \url{https://github.com/illidanlab/PRL}.

In many machine learning applications, each record represents a set of items. For example, when making predictions from medical records, the medications prescribed to a patient are a set whose size is not fixed and whose order is arbitrary. However, most machine learning algorithms are not designed to handle set structures and are limited to processing records of fixed size. Set-Tree, presented in this work, extends the support for sets to tree-based models, such as Random-Forest and Gradient-Boosting, by introducing an attention mechanism and set-compatible split criteria. We evaluate the new method empirically on a wide range of problems ranging from making predictions on sub-atomic particle jets to estimating the redshift of galaxies. The new method outperforms existing tree-based methods consistently and significantly. Moreover, it is competitive and often outperforms Deep Learning. We also discuss the theoretical properties of Set-Trees and explain how they enable item-level explainability.


We study image inverse problems with a normalizing flow prior. Our formulation views the solution as the maximum a posteriori estimate of the image conditioned on the measurements. This formulation allows us to use noise models with arbitrary dependencies as well as non-linear forward operators. We empirically validate the efficacy of our method on various inverse problems, including compressed sensing with quantized measurements and denoising with highly structured noise patterns. We also present initial theoretical recovery guarantees for solving inverse problems with a flow prior.
Oral: Time Series 2 Thu 22 Jul 03:00 a.m.
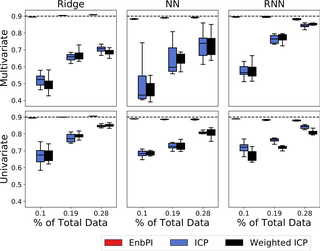
We develop a method to construct distribution-free prediction intervals for dynamic time-series, called \Verb|EnbPI| that wraps around any bootstrap ensemble estimator to construct sequential prediction intervals. \Verb|EnbPI| is closely related to the conformal prediction (CP) framework but does not require data exchangeability. Theoretically, these intervals attain finite-sample, \textit{approximately valid} marginal coverage for broad classes of regression functions and time-series with strongly mixing stochastic errors. Computationally, \Verb|EnbPI| avoids overfitting and requires neither data-splitting nor training multiple ensemble estimators; it efficiently aggregates bootstrap estimators that have been trained. In general, \Verb|EnbPI| is easy to implement, scalable to producing arbitrarily many prediction intervals sequentially, and well-suited to a wide range of regression functions. We perform extensive real-data analyses to demonstrate its effectiveness.

This paper presents a novel approach for hierarchical time series forecasting that produces coherent, probabilistic forecasts without requiring any explicit post-processing reconciliation. Unlike the state-of-the-art, the proposed method simultaneously learns from all time series in the hierarchy and incorporates the reconciliation step into a single trainable model. This is achieved by applying the reparameterization trick and casting reconciliation as an optimization problem with a closed-form solution. These model features make end-to-end learning of hierarchical forecasts possible, while accomplishing the challenging task of generating forecasts that are both probabilistic and coherent. Importantly, our approach also accommodates general aggregation constraints including grouped and temporal hierarchies. An extensive empirical evaluation on real-world hierarchical datasets demonstrates the advantages of the proposed approach over the state-of-the-art.

Smooth dynamics interrupted by discontinuities are known as hybrid systems and arise commonly in nature. Latent ODEs allow for powerful representation of irregularly sampled time series but are not designed to capture trajectories arising from hybrid systems. Here, we propose the Latent Segmented ODE (LatSegODE), which uses Latent ODEs to perform reconstruction and changepoint detection within hybrid trajectories featuring jump discontinuities and switching dynamical modes. Where it is possible to train a Latent ODE on the smooth dynamical flows between discontinuities, we apply the pruned exact linear time (PELT) algorithm to detect changepoints where latent dynamics restart, thereby maximizing the joint probability of a piece-wise continuous latent dynamical representation. We propose usage of the marginal likelihood as a score function for PELT, circumventing the need for model-complexity-based penalization. The LatSegODE outperforms baselines in reconstructive and segmentation tasks including synthetic data sets of sine waves, Lotka Volterra dynamics, and UCI Character Trajectories.

There recently has been a surge of interest in developing a new class of deep learning (DL) architectures that integrate an explicit time dimension as a fundamental building block of learning and representation mechanisms. In turn, many recent results show that topological descriptors of the observed data, encoding information on the shape of the dataset in a topological space at different scales, that is, persistent homology of the data, may contain important complementary information, improving both performance and robustness of DL. As convergence of these two emerging ideas, we propose to enhance DL architectures with the most salient time-conditioned topological information of the data and introduce the concept of zigzag persistence into time-aware graph convolutional networks (GCNs). Zigzag persistence provides a systematic and mathematically rigorous framework to track the most important topological features of the observed data that tend to manifest themselves over time. To integrate the extracted time-conditioned topological descriptors into DL, we develop a new topological summary, zigzag persistence image, and derive its theoretical stability guarantees. We validate the new GCNs with a time-aware zigzag topological layer (Z-GCNETs), in application to traffic forecasting and Ethereum blockchain price prediction. Our results indicate that Z-GCNET outperforms 13 state-of-the-art methods on …

Continuous-time event sequences represent discrete events occurring in continuous time. Such sequences arise frequently in real-life. Usually we expect the sequences to follow some regular pattern over time. However, sometimes these patterns may be interrupted by unexpected absence or occurrences of events. Identification of these unexpected cases can be very important as they may point to abnormal situations that need human attention. In this work, we study and develop methods for detecting outliers in continuous-time event sequences, including unexpected absence and unexpected occurrences of events. Since the patterns that event sequences tend to follow may change in different contexts, we develop outlier detection methods based on point processes that can take context information into account. Our methods are based on Bayesian decision theory and hypothesis testing with theoretical guarantees. To test the performance of the methods, we conduct experiments on both synthetic data and real-world clinical data and show the effectiveness of the proposed methods.

In this work, we propose TimeGrad, an autoregressive model for multivariate probabilistic time series forecasting which samples from the data distribution at each time step by estimating its gradient. To this end, we use diffusion probabilistic models, a class of latent variable models closely connected to score matching and energy-based methods. Our model learns gradients by optimizing a variational bound on the data likelihood and at inference time converts white noise into a sample of the distribution of interest through a Markov chain using Langevin sampling. We demonstrate experimentally that the proposed autoregressive denoising diffusion model is the new state-of-the-art multivariate probabilistic forecasting method on real-world data sets with thousands of correlated dimensions. We hope that this method is a useful tool for practitioners and lays the foundation for future research in this area.

Multivariate Hawkes processes (MHPs) are widely used in a variety of fields to model the occurrence of causally related discrete events in continuous time. Most state-of-the-art approaches address the problem of learning MHPs from perfect traces without noise. In practice, the process through which events are collected might introduce noise in the timestamps. In this work, we address the problem of learning the causal structure of MHPs when the observed timestamps of events are subject to random and unknown shifts, also known as random translations. We prove that the cumulants of MHPs are invariant to random translations, and therefore can be used to learn their underlying causal structure. Furthermore, we empirically characterize the effect of random translations on state-of-the-art learning methods. We show that maximum likelihood-based estimators are brittle, while cumulant-based estimators remain stable even in the presence of significant time shifts.
Oral: Learning Theory 9 Thu 22 Jul 03:00 a.m.

Landmark codes underpin reliable physical layer communication, e.g., Reed-Muller, BCH, Convolution, Turbo, LDPC, and Polar codes: each is a linear code and represents a mathematical breakthrough. The impact on humanity is huge: each of these codes has been used in global wireless communication standards (satellite, WiFi, cellular). Reliability of communication over the classical additive white Gaussian noise (AWGN) channel enables benchmarking and ranking of the different codes. In this paper, we construct KO codes, a computationally efficient family of deep-learning driven (encoder, decoder) pairs that outperform the state-of-the-art reliability performance on the standardized AWGN channel. KO codes beat state-of-the-art Reed-Muller and Polar codes, under the low-complexity successive cancellation decoding, in the challenging short-to-medium block length regime on the AWGN channel. We show that the gains of KO codes are primarily due to the nonlinear mapping of information bits directly to transmit symbols (bypassing modulation) and yet possess an efficient, high-performance decoder. The key technical innovation that renders this possible is design of a novel family of neural architectures inspired by the computation tree of the {\bf K}ronecker {\bf O}peration (KO) central to Reed-Muller and Polar codes. These architectures pave way for the discovery of a much richer class of hitherto …
This paper prescribes a distance between learning tasks modeled as joint distributions on data and labels. Using tools in information geometry, the distance is defined to be the length of the shortest weight trajectory on a Riemannian manifold as a classifier is fitted on an interpolated task. The interpolated task evolves from the source to the target task using an optimal transport formulation. This distance, which we call the "coupled transfer distance" can be compared across different classifier architectures. We develop an algorithm to compute the distance which iteratively transports the marginal on the data of the source task to that of the target task while updating the weights of the classifier to track this evolving data distribution. We develop theory to show that our distance captures the intuitive idea that a good transfer trajectory is the one that keeps the generalization gap small during transfer, in particular at the end on the target task. We perform thorough empirical validation and analysis across diverse image classification datasets to show that the coupled transfer distance correlates strongly with the difficulty of fine-tuning.

Lossy compression algorithms are typically designed to achieve the lowest possible distortion at a given bit rate. However, recent studies show that pursuing high perceptual quality would lead to increase of the lowest achievable distortion (e.g., MSE). This paper provides nontrivial results theoretically revealing that, 1) the cost of achieving perfect perception quality is exactly a doubling of the lowest achievable MSE distortion, 2) an optimal encoder for the “classic” rate-distortion problem is also optimal for the perceptual compression problem, 3) distortion loss is unnecessary for training a perceptual decoder. Further, we propose a novel training framework to achieve the lowest MSE distortion under perfect perception constraint at a given bit rate. This framework uses a GAN with discriminator conditioned on an MSE-optimized encoder, which is superior over the traditional framework using distortion plus adversarial loss. Experiments are provided to verify the theoretical finding and demonstrate the superiority of the proposed training framework.

Incorporating graph side information into recommender systems has been widely used to better predict ratings, but relatively few works have focused on theoretical guarantees. Ahn et al. (2018) firstly characterized the optimal sample complexity in the presence of graph side information, but the results are limited due to strict, unrealistic assumptions made on the unknown latent preference matrix and the structure of user clusters. In this work, we propose a new model in which 1) the unknown latent preference matrix can have any discrete values, and 2) users can be clustered into multiple clusters, thereby relaxing the assumptions made in prior work. Under this new model, we fully characterize the optimal sample complexity and develop a computationally-efficient algorithm that matches the optimal sample complexity. Our algorithm is robust to model errors and outperforms the existing algorithms in terms of prediction performance on both synthetic and real data.

0-1 knapsack is of fundamental importance across many fields. In this paper, we present a game-theoretic method to solve 0-1 knapsack problems (KPs) where the number of items (products) is large and the values of items are not predetermined but decided by an external value assignment function (e.g., a neural network in our case) during the optimization process. While existing papers are interested in predicting solutions with neural networks for classical KPs whose objective functions are mostly linear functions, we are interested in solving KPs whose objective functions are neural networks. In other words, we choose a subset of items that maximize the sum of the values predicted by neural networks. Its key challenge is how to optimize the neural network-based non-linear KP objective with a budget constraint. Our solution is inspired by game-theoretic approaches in deep learning, e.g., generative adversarial networks. After formally defining our two-player game, we develop an adaptive gradient ascent method to solve it. In our experiments, our method successfully solves two neural network-based non-linear KPs and conventional linear KPs with 1 million items.
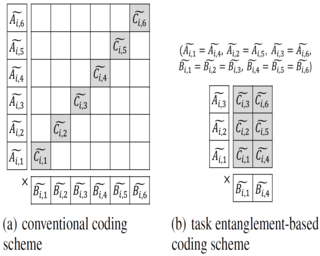
Distributed computing has been a prominent solution to efficiently process massive datasets in parallel. However, the existence of stragglers is one of the major concerns that slows down the overall speed of distributed computing. To deal with this problem, we consider a distributed matrix multiplication scenario where a master assigns multiple tasks to each worker to exploit stragglers' computing ability (which is typically wasted in conventional distributed computing). We propose Chebyshev polynomial codes, which can achieve order-wise improvement in encoding complexity at the master and communication load in distributed matrix multiplication using task entanglement. The key idea of task entanglement is to reduce the number of encoded matrices for multiple tasks assigned to each worker by intertwining encoded matrices. We experimentally demonstrate that, in cloud environments, Chebyshev polynomial codes can provide significant reduction in overall processing time in distributed computing for matrix multiplication, which is a key computational component in modern deep learning.
Oral: Bandits 3 Thu 22 Jul 03:00 a.m.
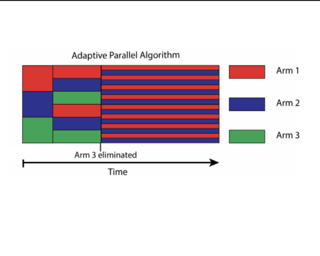
We study exploration in stochastic multi-armed bandits when we have access to a divisible resource that can be allocated in varying amounts to arm pulls. We focus in particular on the allocation of distributed computing resources, where we may obtain results faster by allocating more resources per pull, but might have reduced throughput due to nonlinear scaling. For example, in simulation-based scientific studies, an expensive simulation can be sped up by running it on multiple cores. This speed-up however, is partly offset by the communication among cores, which results in lower throughput than if fewer cores were allocated to run more trials in parallel. In this paper, we explore these trade-offs in two settings. First, in a fixed confidence setting, we need to find the best arm with a given target success probability as quickly as possible. We propose an algorithm which trades off between information accumulation and throughput and show that the time taken can be upper bounded by the solution of a dynamic program whose inputs are the gaps between the sub-optimal and optimal arms. We also prove a matching hardness result. Second, we present an algorithm for a fixed deadline setting, where we are given a time …

This paper studies two variants of the best arm identification (BAI) problem under the streaming model, where we have a stream of n arms with reward distributions supported on [0,1] with unknown means. The arms in the stream are arriving one by one, and the algorithm cannot access an arm unless it is stored in a limited size memory.
We first study the streaming \epslion-topk-arms identification problem, which asks for k arms whose reward means are lower than that of the k-th best arm by at most \epsilon with probability at least 1-\delta. For general \epsilon \in (0,1), the existing solution for this problem assumes k = 1 and achieves the optimal sample complexity O(\frac{n}{\epsilon^2} \log \frac{1}{\delta}) using O(\log^*(n)) memory and a single pass of the stream. We propose an algorithm that works for any k and achieves the optimal sample complexity O(\frac{n}{\epsilon^2} \log\frac{k}{\delta}) using a single-arm memory and a single pass of the stream.
Second, we study the streaming BAI problem, where the objective is to identify the arm with the maximum reward mean with at least 1-\delta probability, using a single-arm memory and as few passes of the input stream as possible. We present a single-arm-memory algorithm that …



Consider a prosthetic arm, learning to adapt to its user's control signals. We propose \emph{Interaction-Grounded Learning} for this novel setting, in which a learner's goal is to interact with the environment with no grounding or explicit reward to optimize its policies. Such a problem evades common RL solutions which require an explicit reward. The learning agent observes a multidimensional \emph{context vector}, takes an \emph{action}, and then observes a multidimensional \emph{feedback vector}. This multidimensional feedback vector has \emph{no} explicit reward information. In order to succeed, the algorithm must learn how to evaluate the feedback vector to discover a latent reward signal, with which it can ground its policies without supervision. We show that in an Interaction-Grounded Learning setting, with certain natural assumptions, a learner can discover the latent reward and ground its policy for successful interaction. We provide theoretical guarantees and a proof-of-concept empirical evaluation to demonstrate the effectiveness of our proposed approach.

In batched multi-armed bandit problems, the learner can adaptively pull arms and adjust strategy in batches. In many real applications, not only the regret but also the batch complexity need to be optimized. Existing batched bandit algorithms usually assume that the time horizon T is known in advance. However, many applications involve an unpredictable stopping time. In this paper, we study the anytime batched multi-armed bandit problem. We propose an anytime algorithm that achieves the asymptotically optimal regret for exponential families of reward distributions with O(\log \log T \ilog^{\alpha} (T)) \footnote{Notation \ilog^{\alpha} (T) is the result of iteratively applying the logarithm function on T for \alpha times, e.g., \ilog^{3} (T)=\log\log\log T.} batches, where $\alpha\in O_{T}(1). Moreover, we prove that for any constant c>0, no algorithm can achieve the asymptotically optimal regret within c\log\log T batches.

Finding an optimal matching in a weighted graph is a standard combinatorial problem. We consider its semi-bandit version where either a pair or a full matching is sampled sequentially. We prove that it is possible to leverage a rank-1 assumption on the adjacency matrix to reduce the sample complexity and the regret of off-the-shelf algorithms up to reaching a linear dependency in the number of vertices (up to to poly-log terms).
Oral: Learning Theory 10 Thu 22 Jul 03:00 a.m.

To assess generalization, machine learning scientists typically either (i) bound the generalization gap and then (after training) plug in the empirical risk to obtain a bound on the true risk; or (ii) validate empirically on holdout data. However, (i) typically yields vacuous guarantees for overparameterized models; and (ii) shrinks the training set and its guarantee erodes with each re-use of the holdout set. In this paper, we leverage unlabeled data to produce generalization bounds. After augmenting our (labeled) training set with randomly labeled data, we train in the standard fashion. Whenever classifiers achieve low error on the clean data but high error on the random data, our bound ensures that the true risk is low. We prove that our bound is valid for 0-1 empirical risk minimization and with linear classifiers trained by gradient descent. Our approach is especially useful in conjunction with deep learning due to the early learning phenomenon whereby networks fit true labels before noisy labels but requires one intuitive assumption. Empirically, on canonical computer vision and NLP tasks, our bound provides non-vacuous generalization guarantees that track actual performance closely. This work enables practitioners to certify generalization even when (labeled) holdout data is unavailable and provides insights …

We study the approximation properties of convolutional architectures applied to time series modelling, which can be formulated mathematically as a functional approximation problem. In the recurrent setting, recent results reveal an intricate connection between approximation efficiency and memory structures in the data generation process. In this paper, we derive parallel results for convolutional architectures, with WaveNet being a prime example. Our results reveal that in this new setting, approximation efficiency is not only characterised by memory, but also additional fine structures in the target relationship. This leads to a novel definition of spectrum-based regularity that measures the complexity of temporal relationships under the convolutional approximation scheme. These analyses provide a foundation to understand the differences between architectural choices for time series modelling and can give theoretically grounded guidance for practical applications.



Neural networks trained via gradient descent with random initialization and without any regularization enjoy good generalization performance in practice despite being highly overparametrized. A promising direction to explain this phenomenon is to study how initialization and overparametrization affect convergence and implicit bias of training algorithms. In this paper, we present a novel analysis of single-hidden-layer linear networks trained under gradient flow, which connects initialization, optimization, and overparametrization. Firstly, we show that the squared loss converges exponentially to its optimum at a rate that depends on the level of imbalance of the initialization. Secondly, we show that proper initialization constrains the dynamics of the network parameters to lie within an invariant set. In turn, minimizing the loss over this set leads to the min-norm solution. Finally, we show that large hidden layer width, together with (properly scaled) random initialization, ensures proximity to such an invariant set during training, allowing us to derive a novel non-asymptotic upper-bound on the distance between the trained network and the min-norm solution.


For machine learning systems to be reliable, we must understand their performance in unseen, out- of-distribution environments. In this paper, we empirically show that out-of-distribution performance is strongly correlated with in-distribution performance for a wide range of models and distribution shifts. Specifically, we demonstrate strong correlations between in-distribution and out-of- distribution performance on variants of CIFAR- 10 & ImageNet, a synthetic pose estimation task derived from YCB objects, FMoW-WILDS satellite imagery classification, and wildlife classification in iWildCam-WILDS. The correlation holds across model architectures, hyperparameters, training set size, and training duration, and is more precise than what is expected from existing domain adaptation theory. To complete the picture, we also investigate cases where the correlation is weaker, for instance some synthetic distribution shifts from CIFAR-10-C and the tissue classification dataset Camelyon17-WILDS. Finally, we provide a candidate theory based on a Gaussian data model that shows how changes in the data covariance arising from distribution shift can affect the observed correlations.
Oral: Deep Learning Theory 5 Thu 22 Jul 03:00 a.m.

Minimizing cross-entropy over the softmax scores of a linear map composed with a high-capacity encoder is arguably the most popular choice for training neural networks on supervised learning tasks. However, recent works show that one can directly optimize the encoder instead, to obtain equally (or even more) discriminative representations via a supervised variant of a contrastive objective. In this work, we address the question whether there are fundamental differences in the sought-for representation geometry in the output space of the encoder at minimal loss. Specifically, we prove, under mild assumptions, that both losses attain their minimum once the representations of each class collapse to the vertices of a regular simplex, inscribed in a hypersphere. We provide empirical evidence that this configuration is attained in practice and that reaching a close-to-optimal state typically indicates good generalization performance. Yet, the two losses show remarkably different optimization behavior. The number of iterations required to perfectly fit to data scales superlinearly with the amount of randomly flipped labels for the supervised contrastive loss. This is in contrast to the approximately linear scaling previously reported for networks trained with cross-entropy.
In the vanishing learning rate regime, stochastic gradient descent (SGD) is now relatively well understood. In this work, we propose to study the basic properties of SGD and its variants in the non-vanishing learning rate regime. The focus is on deriving exactly solvable results and discussing their implications. The main contributions of this work are to derive the stationary distribution for discrete-time SGD in a quadratic loss function with and without momentum; in particular, one implication of our result is that the fluctuation caused by discrete-time dynamics takes a distorted shape and is dramatically larger than a continuous-time theory could predict. Examples of applications of the proposed theory considered in this work include the approximation error of variants of SGD, the effect of minibatch noise, the optimal Bayesian inference, the escape rate from a sharp minimum, and the stationary covariance of a few second-order methods including damped Newton's method, natural gradient descent, and Adam.

As its width tends to infinity, a deep neural network's behavior under gradient descent can become simplified and predictable (e.g. given by the Neural Tangent Kernel (NTK)), if it is parametrized appropriately (e.g. the NTK parametrization). However, we show that the standard and NTK parametrizations of a neural network do not admit infinite-width limits that can learn features, which is crucial for pretraining and transfer learning such as with BERT. We propose simple modifications to the standard parametrization to allow for feature learning in the limit. Using the Tensor Programs technique, we derive explicit formulas for such limits. On Word2Vec and few-shot learning on Omniglot via MAML, two canonical tasks that rely crucially on feature learning, we compute these limits exactly. We find that they outperform both NTK baselines and finite-width networks, with the latter approaching the infinite-width feature learning performance as width increases.

Residual networks (ResNets) have displayed impressive results in pattern recognition and, recently, have garnered considerable theoretical interest due to a perceived link with neural ordinary differential equations (neural ODEs). This link relies on the convergence of network weights to a smooth function as the number of layers increases. We investigate the properties of weights trained by stochastic gradient descent and their scaling with network depth through detailed numerical experiments. We observe the existence of scaling regimes markedly different from those assumed in neural ODE literature. Depending on certain features of the network architecture, such as the smoothness of the activation function, one may obtain an alternative ODE limit, a stochastic differential equation or neither of these. These findings cast doubts on the validity of the neural ODE model as an adequate asymptotic description of deep ResNets and point to an alternative class of differential equations as a better description of the deep network limit.

Contrastive learning has recently seen tremendous success in self-supervised learning. So far, however, it is largely unclear why the learned representations generalize so effectively to a large variety of downstream tasks. We here prove that feedforward models trained with objectives belonging to the commonly used InfoNCE family learn to implicitly invert the underlying generative model of the observed data. While the proofs make certain statistical assumptions about the generative model, we observe empirically that our findings hold even if these assumptions are severely violated. Our theory highlights a fundamental connection between contrastive learning, generative modeling, and nonlinear independent component analysis, thereby furthering our understanding of the learned representations as well as providing a theoretical foundation to derive more effective contrastive losses.

Yang (2020) recently showed that the Neural Tangent Kernel (NTK) at initialization has an infinite-width limit for a large class of architectures including modern staples such as ResNet and Transformers. However, their analysis does not apply to training. Here, we show the same neural networks (in the so-called NTK parametrization) during training follow a kernel gradient descent dynamics in function space, where the kernel is the infinite-width NTK. This completes the proof of the architectural universality of NTK behavior. To achieve this result, we apply the Tensor Programs technique: Write the entire SGD dynamics inside a Tensor Program and analyze it via the Master Theorem. To facilitate this proof, we develop a graphical notation for Tensor Programs, which we believe is also an important contribution toward the pedagogy and exposition of the Tensor Programs technique.

In this paper, we introduce a new perspective on training deep neural networks capable of state-of-the-art performance without the need for the expensive over-parameterization by proposing the concept of In-Time Over-Parameterization (ITOP) in sparse training. By starting from a random sparse network and continuously exploring sparse connectivities during training, we can perform an Over-Parameterization over the course of training, closing the gap in the expressibility between sparse training and dense training. We further use ITOP to understand the underlying mechanism of Dynamic Sparse Training (DST) and discover that the benefits of DST come from its ability to consider across time all possible parameters when searching for the optimal sparse connectivity. As long as sufficient parameters have been reliably explored, DST can outperform the dense neural network by a large margin. We present a series of experiments to support our conjecture and achieve the state-of-the-art sparse training performance with ResNet-50 on ImageNet. More impressively, ITOP achieves dominant performance over the overparameterization-based sparse methods at extreme sparsities. When trained with ResNet-34 on CIFAR-100, ITOP can match the performance of the dense model at an extreme sparsity 98%.
Oral: Reinforcement Learning Theory 4 Thu 22 Jul 03:00 a.m.

We study multi-objective reinforcement learning (RL) where an agent's reward is represented as a vector. In settings where an agent competes against opponents, its performance is measured by the distance of its average return vector to a target set. We develop statistically and computationally efficient algorithms to approach the associated target set. Our results extend Blackwell's approachability theorem~\citep{blackwell1956analog} to tabular RL, where strategic exploration becomes essential. The algorithms presented are adaptive; their guarantees hold even without Blackwell's approachability condition. If the opponents use fixed policies, we give an improved rate of approaching the target set while also tackling the more ambitious goal of simultaneously minimizing a scalar cost function. We discuss our analysis for this special case by relating our results to previous works on constrained RL. To our knowledge, this work provides the first provably efficient algorithms for vector-valued Markov games and our theoretical guarantees are near-optimal.





Oral: Reinforcement Learning 14 Thu 22 Jul 03:00 a.m.

Exploration in unknown environments is a fundamental problem in reinforcement learning and control. In this work, we study task-guided exploration and determine what precisely an agent must learn about their environment in order to complete a particular task. Formally, we study a broad class of decision-making problems in the setting of linear dynamical systems, a class that includes the linear quadratic regulator problem. We provide instance- and task-dependent lower bounds which explicitly quantify the difficulty of completing a task of interest. Motivated by our lower bound, we propose a computationally efficient experiment-design based exploration algorithm. We show that it optimally explores the environment, collecting precisely the information needed to complete the task, and provide finite-time bounds guaranteeing that it achieves the instance- and task-optimal sample complexity, up to constant factors. Through several examples of the linear quadratic regulator problem, we show that performing task-guided exploration provably improves on exploration schemes which do not take into account the task of interest. Along the way, we establish that certainty equivalence decision making is instance- and task-optimal, and obtain the first algorithm for the linear quadratic regulator problem which is instance-optimal. We conclude with several experiments illustrating the effectiveness of our approach in …

The safe operation of physical systems typically relies on high-quality models. Since a continuous stream of data is generated during run-time, such models are often obtained through the application of Gaussian process regression because it provides guarantees on the prediction error. Due to its high computational complexity, Gaussian process regression must be used offline on batches of data, which prevents applications, where a fast adaptation through online learning is necessary to ensure safety. In order to overcome this issue, we propose the LoG-GP. It achieves a logarithmic update and prediction complexity in the number of training points through the aggregation of locally active Gaussian process models. Under weak assumptions on the aggregation scheme, it inherits safety guarantees from exact Gaussian process regression. These theoretical advantages are exemplarily exploited in the design of a safe and data-efficient, online-learning control policy. The efficiency and performance of the proposed real-time learning approach is demonstrated in a comparison to state-of-the-art methods.



In policy search methods for reinforcement learning (RL), exploration is often performed by injecting noise either in action space at each step independently or in parameter space over each full trajectory. In prior work, it has been shown that with linear policies, a more balanced trade-off between these two exploration strategies is beneficial. However, that method did not scale to policies using deep neural networks. In this paper, we introduce deep coherent exploration, a general and scalable exploration framework for deep RL algorithms for continuous control, that generalizes step-based and trajectory-based exploration. This framework models the last layer parameters of the policy network as latent variables and uses a recursive inference step within the policy update to handle these latent variables in a scalable manner. We find that deep coherent exploration improves the speed and stability of learning of A2C, PPO, and SAC on several continuous control tasks.

In active visual tracking, it is notoriously difficult when distracting objects appear, as distractors often mislead the tracker by occluding the target or bringing a confusing appearance. To address this issue, we propose a mixed cooperative-competitive multi-agent game, where a target and multiple distractors form a collaborative team to play against a tracker and make it fail to follow. Through learning in our game, diverse distracting behaviors of the distractors naturally emerge, thereby exposing the tracker's weakness, which helps enhance the distraction-robustness of the tracker. For effective learning, we then present a bunch of practical methods, including a reward function for distractors, a cross-modal teacher-student learning strategy, and a recurrent attention mechanism for the tracker. The experimental results show that our tracker performs desired distraction-robust active visual tracking and can be well generalized to unseen environments. We also show that the multi-agent game can be used to adversarially test the robustness of trackers.
Oral: Learning Theory 11 Thu 22 Jul 03:00 a.m.

Many machine learning problems can be formulated as minimax problems such as Generative Adversarial Networks (GANs), AUC maximization and robust estimation, to mention but a few. A substantial amount of studies are devoted to studying the convergence behavior of their stochastic gradient-type algorithms. In contrast, there is relatively little work on understanding their generalization, i.e., how the learning models built from training examples would behave on test examples. In this paper, we provide a comprehensive generalization analysis of stochastic gradient methods for minimax problems under both convex-concave and nonconvex-nonconcave cases through the lens of algorithmic stability. We establish a quantitative connection between stability and several generalization measures both in expectation and with high probability. For the convex-concave setting, our stability analysis shows that stochastic gradient descent ascent attains optimal generalization bounds for both smooth and nonsmooth minimax problems. We also establish generalization bounds for both weakly-convex-weakly-concave and gradient-dominated problems. We report preliminary experimental results to verify our theory.

In performative prediction, predictions guide decision-making and hence can influence the distribution of future data. To date, work on performative prediction has focused on finding performatively stable models, which are the fixed points of repeated retraining. However, stable solutions can be far from optimal when evaluated in terms of the performative risk, the loss experienced by the decision maker when deploying a model. In this paper, we shift attention beyond performative stability and focus on optimizing the performative risk directly. We identify a natural set of properties of the loss function and model-induced distribution shift under which the performative risk is convex, a property which does not follow from convexity of the loss alone. Furthermore, we develop algorithms that leverage our structural assumptions to optimize the performative risk with better sample efficiency than generic methods for derivative-free convex optimization.

This paper quantifies the uncertainty of prediction risk for the min-norm least squares estimator in high-dimensional linear regression models. We establish the asymptotic normality of prediction risk when both the sample size and the number of features tend to infinity. Based on the newly established central limit theorems(CLTs), we derive the confidence intervals of the prediction risk under various scenarios. Our results demonstrate the sample-wise non-monotonicity of the prediction risk and confirm ``more data hurt" phenomenon. Furthermore, the width of confidence intervals indicates that over-parameterization would enlarge the randomness of prediction performance.

Meta-learning, or learning-to-learn, seeks to design algorithms that can utilize previous experience to rapidly learn new skills or adapt to new environments. Representation learning---a key tool for performing meta-learning---learns a data representation that can transfer knowledge across multiple tasks, which is essential in regimes where data is scarce. Despite a recent surge of interest in the practice of meta-learning, the theoretical underpinnings of meta-learning algorithms are lacking, especially in the context of learning transferable representations. In this paper, we focus on the problem of multi-task linear regression---in which multiple linear regression models share a common, low-dimensional linear representation. Here, we provide provably fast, sample-efficient algorithms to address the dual challenges of (1) learning a common set of features from multiple, related tasks, and (2) transferring this knowledge to new, unseen tasks. Both are central to the general problem of meta-learning. Finally, we complement these results by providing information-theoretic lower bounds on the sample complexity of learning these linear features.


There has been recently a significant boost to machine learning with distributed data, in particular with the success of federated learning. A common and very challenging setting is that of vertical or feature partitioned data, when multiple data providers hold different features about common entities. In general, training needs to be preceded by record linkage (RL), a step that finds the correspondence between the observations of the datasets. RL is prone to mistakes in the real world. Despite the importance of the problem, there has been so far no formal assessment of the way in which RL errors impact learning models. Work in the area either use heuristics or assume that the optimal RL is known in advance. In this paper, we provide the first assessment of the problem for supervised learning. For wide sets of losses, we provide technical conditions under which the classifier learned after noisy RL converges (with the data size) to the best classifier that would be learned from mistake-free RL. This yields new insights on the way the pipeline RL + ML operates, from the role of large margin classification on dampening the impact of RL mistakes to clues on how to further optimize RL …

The success of minimax learning problems of generative adversarial networks (GANs) has been observed to depend on the minimax optimization algorithm used for their training. This dependence is commonly attributed to the convergence speed and robustness properties of the underlying optimization algorithm. In this paper, we show that the optimization algorithm also plays a key role in the generalization performance of the trained minimax model. To this end, we analyze the generalization properties of standard gradient descent ascent (GDA) and proximal point method (PPM) algorithms through the lens of algorithmic stability as defined by Bousquet & Elisseeff, 2002 under both convex-concave and nonconvex-nonconcave minimax settings. While the GDA algorithm is not guaranteed to have a vanishing excess risk in convex-concave problems, we show the PPM algorithm enjoys a bounded excess risk in the same setup. For nonconvex-nonconcave problems, we compare the generalization performance of stochastic GDA and GDmax algorithms where the latter fully solves the maximization subproblem at every iteration. Our generalization analysis suggests the superiority of GDA provided that the minimization and maximization subproblems are solved simultaneously with similar learning rates. We discuss several numerical results indicating the role of optimization algorithms in the generalization of learned minimax models.
Oral: Reinforcement Learning Theory 5 Thu 22 Jul 04:00 a.m.




Many sequential decision problems involve finding a policy that maximizes total reward while obeying safety constraints. Although much recent research has focused on the development of safe reinforcement learning (RL) algorithms that produce a safe policy after training, ensuring safety during training as well remains an open problem. A fundamental challenge is performing exploration while still satisfying constraints in an unknown Markov decision process (MDP). In this work, we address this problem for the chance-constrained setting.We propose a new algorithm, SAILR, that uses an intervention mechanism based on advantage functions to keep the agent safe throughout training and optimizes the agent's policy using off-the-shelf RL algorithms designed for unconstrained MDPs. Our method comes with strong guarantees on safety during "both" training and deployment (i.e., after training and without the intervention mechanism) and policy performance compared to the optimal safety-constrained policy. In our experiments, we show that SAILR violates constraints far less during training than standard safe RL and constrained MDP approaches and converges to a well-performing policy that can be deployed safely without intervention. Our code is available at https://github.com/nolanwagener/safe_rl.

We consider the pure exploration problem in the fixed-budget linear bandit setting. We provide a new algorithm that identifies the best arm with high probability while being robust to unknown levels of observation noise as well as to moderate levels of misspecification in the linear model. Our technique combines prior approaches to pure exploration in the multi-armed bandit problem with optimal experimental design algorithms to obtain both problem dependent and problem independent bounds. Our success probability is never worse than that of an algorithm that ignores the linear structure, but seamlessly takes advantage of such structure when possible. Furthermore, we only need the number of samples to scale with the dimension of the problem rather than the number of arms. We complement our theoretical results with empirical validation.

We provide a unifying view of a large family of previous imitation learning algorithms through the lens of moment matching. At its core, our classification scheme is based on whether the learner attempts to match (1) reward or (2) action-value moments of the expert's behavior, with each option leading to differing algorithmic approaches. By considering adversarially chosen divergences between learner and expert behavior, we are able to derive bounds on policy performance that apply for all algorithms in each of these classes, the first to our knowledge. We also introduce the notion of moment recoverability, implicit in many previous analyses of imitation learning, which allows us to cleanly delineate how well each algorithmic family is able to mitigate compounding errors. We derive three novel algorithm templates (AdVIL, AdRIL, and DAeQuIL) with strong guarantees, simple implementation, and competitive empirical performance.
Spotlight: Supervised Learning 5 Thu 22 Jul 04:00 a.m.

Deep learning for graph matching (GM) has emerged as an important research topic due to its superior performance over traditional methods and insights it provides for solving other combinatorial problems on graph. While recent deep methods for GM extensively investigated effective node/edge feature learning or downstream GM solvers given such learned features, there is little existing work questioning if the fixed connectivity/topology typically constructed using heuristics (e.g., Delaunay or k-nearest) is indeed suitable for GM. From a learning perspective, we argue that the fixed topology may restrict the model capacity and thus potentially hinder the performance. To address this, we propose to learn the (distribution of) latent topology, which can better support the downstream GM task. We devise two latent graph generation procedures, one deterministic and one generative. Particularly, the generative procedure emphasizes the across-graph consistency and thus can be viewed as a matching-guided co-generative model. Our methods deliver superior performance over previous state-of-the-arts on public benchmarks, hence supporting our hypothesis.

Robust loss functions are essential for training deep neural networks with better generalization power in the presence of noisy labels. Symmetric loss functions are confirmed to be robust to label noise. However, the symmetric condition is overly restrictive. In this work, we propose a new class of loss functions, namely asymmetric loss functions, which are robust to learning from noisy labels for arbitrary noise type. Subsequently, we investigate general theoretical properties of asymmetric loss functions, including classification-calibration, excess risk bound, and noise-tolerance. Meanwhile, we introduce the asymmetry ratio to measure the asymmetry of a loss function, and the empirical results show that a higher ratio will provide better robustness. Moreover, we modify several common loss functions, and establish the necessary and sufficient conditions for them to be asymmetric. Experiments on benchmark datasets demonstrate that asymmetric loss functions can outperform state-of-the-art methods.

The label noise transition matrix, characterizing the probabilities of a training instance being wrongly annotated, is crucial to designing popular solutions to learning with noisy labels. Existing works heavily rely on finding ``anchor points'' or their approximates, defined as instances belonging to a particular class almost surely. Nonetheless, finding anchor points remains a non-trivial task, and the estimation accuracy is also often throttled by the number of available anchor points. In this paper, we propose an alternative option to the above task. Our main contribution is the discovery of an efficient estimation procedure based on a clusterability condition. We prove that with clusterable representations of features, using up to third-order consensuses of noisy labels among neighbor representations is sufficient to estimate a unique transition matrix. Compared with methods using anchor points, our approach uses substantially more instances and benefits from a much better sample complexity. We demonstrate the estimation accuracy and advantages of our estimates using both synthetic noisy labels (on CIFAR-10/100) and real human-level noisy labels (on Clothing1M and our self-collected human-annotated CIFAR-10). Our code and human-level noisy CIFAR-10 labels are available at https://github.com/UCSC-REAL/HOC.

Conditional selective inference (SI) has been actively studied as a new statistical inference framework for data-driven hypotheses. The basic idea of conditional SI is to make inferences conditional on the selection event characterized by a set of linear and/or quadratic inequalities. Conditional SI has been mainly studied in the context of feature selection such as stepwise feature selection (SFS). The main limitation of the existing conditional SI methods is the loss of power due to over-conditioning, which is required for computational tractability. In this study, we develop a more powerful and general conditional SI method for SFS using the homotopy method which enables us to overcome this limitation. The homotopy-based SI is especially effective for more complicated feature selection algorithms. As an example, we develop a conditional SI method for forward-backward SFS with AIC-based stopping criteria and show that it is not adversely affected by the increased complexity of the algorithm. We conduct several experiments to demonstrate the effectiveness and efficiency of the proposed method.

Despite their widespread success, the application of deep neural networks to functional data remains scarce today. The infinite dimensionality of functional data means standard learning algorithms can be applied only after appropriate dimension reduction, typically achieved via basis expansions. Currently, these bases are chosen a priori without the information for the task at hand and thus may not be effective for the designated task. We instead propose to adaptively learn these bases in an end-to-end fashion. We introduce neural networks that employ a new Basis Layer whose hidden units are each basis functions themselves implemented as a micro neural network. Our architecture learns to apply parsimonious dimension reduction to functional inputs that focuses only on information relevant to the target rather than irrelevant variation in the input function. Across numerous classification/regression tasks with functional data, our method empirically outperforms other types of neural networks, and we prove that our approach is statistically consistent with low generalization error.

Structured output prediction problems (e.g., sequential tagging, hierarchical multi-class classification) often involve constraints over the output space. These constraints interact with the learned models to filter infeasible solutions and facilitate in building an accountable system. However, despite constraints are useful, they are often based on hand-crafted rules. This raises a question -- can we mine constraints and rules from data based on a learning algorithm?
In this paper, we present a general framework for mining constraints from data. In particular, we consider the inference in structured output prediction as an integer linear programming (ILP) problem. Then, given the coefficients of the objective function and the corresponding solution, we mine the underlying constraints by estimating the outer and inner polytopes of the feasible set. We verify the proposed constraint mining algorithm in various synthetic and real-world applications and demonstrate that the proposed approach successfully identifies the feasible set at scale.
In particular, we show that our approach can learn to solve 9x9 Sudoku puzzles and minimal spanning tree problems from examples without providing the underlying rules. Our algorithm can also integrate with a neural network model to learn the hierarchical label structure of a multi-label classification task. Besides, we provide theoretical …
The goal of classification with rejection is to avoid risky misclassification in error-critical applications such as medical diagnosis and product inspection. In this paper, based on the relationship between classification with rejection and cost-sensitive classification, we propose a novel method of classification with rejection by learning an ensemble of cost-sensitive classifiers, which satisfies all the following properties: (i) it can avoid estimating class-posterior probabilities, resulting in improved classification accuracy. (ii) it allows a flexible choice of losses including non-convex ones, (iii) it does not require complicated modifications when using different losses, (iv) it is applicable to both binary and multiclass cases, and (v) it is theoretically justifiable for any classification-calibrated loss. Experimental results demonstrate the usefulness of our proposed approach in clean-labeled, noisy-labeled, and positive-unlabeled classification.

Machine learned models often must abide by certain requirements (e.g., fairness or legal). This has spurred interested in developing approaches that can provably verify whether a model satisfies certain properties. This paper introduces a generic algorithm called Veritas that enables tackling multiple different verification tasks for tree ensemble models like random forests (RFs) and gradient boosted decision trees (GBDTs). This generality contrasts with previous work, which has focused exclusively on either adversarial example generation or robustness checking. Veritas formulates the verification task as a generic optimization problem and introduces a novel search space representation. Veritas offers two key advantages. First, it provides anytime lower and upper bounds when the optimization problem cannot be solved exactly. In contrast, many existing methods have focused on exact solutions and are thus limited by the verification problem being NP-complete. Second, Veritas produces full (bounded suboptimal) solutions that can be used to generate concrete examples. We experimentally show that our method produces state-of-the-art robustness estimates, especially when executed with strict time constraints. This is exceedingly important when checking the robustness of large datasets. Additionally, we show that Veritas enables tackling more real-world verification scenarios.
Oral: Learning Theory 13 Thu 22 Jul 04:00 a.m.



We study the problem of robust mean estimation and introduce a novel Hamming distance-based measure of distribution shift for coordinate-level corruptions. We show that this measure yields adversary models that capture more realistic corruptions than those used in prior works, and present an information-theoretic analysis of robust mean estimation in these settings. We show that for structured distributions, methods that leverage the structure yield information theoretically more accurate mean estimation. We also focus on practical algorithms for robust mean estimation and study when data cleaning-inspired approaches that first fix corruptions in the input data and then perform robust mean estimation can match the information theoretic bounds of our analysis. We finally demonstrate experimentally that this two-step approach outperforms structure-agnostic robust estimation and provides accurate mean estimation even for high-magnitude corruption.

Metric Multidimensional scaling (MDS) is a classical method for generating meaningful (non-linear) low-dimensional embeddings of high-dimensional data. MDS has a long history in the statistics, machine learning, and graph drawing communities. In particular, the Kamada-Kawai force-directed graph drawing method is equivalent to MDS and is one of the most popular ways in practice to embed graphs into low dimensions. Despite its ubiquity, our theoretical understanding of MDS remains limited as its objective function is highly non-convex. In this paper, we prove that minimizing the Kamada-Kawai objective is NP-hard and give a provable approximation algorithm for optimizing it, which in particular is a PTAS on low-diameter graphs. We supplement this result with experiments suggesting possible connections between our greedy approximation algorithm and gradient-based methods.

Algorithmic stability is a key characteristic to ensure the generalization ability of a learning algorithm. Among different notions of stability, \emph{uniform stability} is arguably the most popular one, which yields exponential generalization bounds. However, uniform stability only considers the worst-case loss change (or so-called sensitivity) by removing a single data point, which is distribution-independent and therefore undesirable. There are many cases that the worst-case sensitivity of the loss is much larger than the average sensitivity taken over the single data point that is removed, especially in some advanced models such as random feature models or neural networks. Many previous works try to mitigate the distribution independent issue by proposing weaker notions of stability, however, they either only yield polynomial bounds or the bounds derived do not vanish as sample size goes to infinity. Given that, we propose \emph{locally elastic stability} as a weaker and distribution-dependent stability notion, which still yields exponential generalization bounds. We further demonstrate that locally elastic stability implies tighter generalization bounds than those derived based on uniform stability in many situations by revisiting the examples of bounded support vector machines, regularized least square regressions, and stochastic gradient descent.

We propose a randomized algorithm with quadratic convergence rate for convex optimization problems with a self-concordant, composite, strongly convex objective function. Our method is based on performing an approximate Newton step using a random projection of the Hessian. Our first contribution is to show that, at each iteration, the embedding dimension (or sketch size) can be as small as the effective dimension of the Hessian matrix. Leveraging this novel fundamental result, we design an algorithm with a sketch size proportional to the effective dimension and which exhibits a quadratic rate of convergence. This result dramatically improves on the classical linear-quadratic convergence rates of state-of-the-art sub-sampled Newton methods. However, in most practical cases, the effective dimension is not known beforehand, and this raises the question of how to pick a sketch size as small as the effective dimension while preserving a quadratic convergence rate. Our second and main contribution is thus to propose an adaptive sketch size algorithm with quadratic convergence rate and which does not require prior knowledge or estimation of the effective dimension: at each iteration, it starts with a small sketch size, and increases it until quadratic progress is achieved. Importantly, we show that the embedding dimension remains …
This paper aims to define, visualize, and analyze the feature complexity that is learned by a DNN. We propose a generic definition for the feature complexity. Given the feature of a certain layer in the DNN, our method decomposes and visualizes feature components of different complexity orders from the feature. The feature decomposition enables us to evaluate the reliability, the effectiveness, and the significance of over-fitting of these feature components. Furthermore, such analysis helps to improve the performance of DNNs. As a generic method, the feature complexity also provides new insights into existing deep-learning techniques, such as network compression and knowledge distillation.
Oral: Learning Theory 12 Thu 22 Jul 04:00 a.m.


This paper discusses the problem of weakly supervised classification, in which instances are given weak labels that are produced by some label-corruption process. The goal is to derive conditions under which loss functions for weak-label learning are proper and lower-bounded---two essential requirements for the losses used in class-probability estimation. To this end, we derive a representation theorem for proper losses in supervised learning, which dualizes the Savage representation. We use this theorem to characterize proper weak-label losses and find a condition for them to be lower-bounded. From these theoretical findings, we derive a novel regularization scheme called generalized logit squeezing, which makes any proper weak-label loss bounded from below, without losing properness. Furthermore, we experimentally demonstrate the effectiveness of our proposed approach, as compared to improper or unbounded losses. The results highlight the importance of properness and lower-boundedness.

Biclustering structures exist ubiquitously in data matrices and the biclustering problem was first formalized by John Hartigan (1972) to cluster rows and columns simultaneously. In this paper, we develop a theory for the estimation of general biclustering models, where the data is assumed to follow certain statistical distribution with underlying biclustering structure. Due to the existence of latent variables, directly computing the maximal likelihood estimator is prohibitively difficult in practice and we instead consider the variational inference (VI) approach to solve the parameter estimation problem. Although variational inference method generally has good empirical performance, there are very few theoretical results around VI. In this paper, we obtain the precise estimation bound of variational estimator and show that it matches the minimax rate in terms of estimation error under mild assumptions in biclustering setting. Furthermore, we study the convergence property of the coordinate ascent variational inference algorithm, where both local and global convergence results have been provided. Numerical results validate our new theories.
Game optimization has been extensively studied when decision variables lie in a finite-dimensional space, of which solutions correspond to pure strategies at the Nash equilibrium (NE), and the gradient descent-ascent (GDA) method works widely in practice. In this paper, we consider infinite-dimensional zero-sum games by a min-max distributional optimization problem over a space of probability measures defined on a continuous variable set, which is inspired by finding a mixed NE for finite-dimensional zero-sum games. We then aim to answer the following question: \textit{Will GDA-type algorithms still be provably efficient when extended to infinite-dimensional zero-sum games?} To answer this question, we propose a particle-based variational transport algorithm based on GDA in the functional spaces. Specifically, the algorithm performs multi-step functional gradient descent-ascent in the Wasserstein space via pushing two sets of particles in the variable space. By characterizing the gradient estimation error from variational form maximization and the convergence behavior of each player with different objective landscapes, we prove rigorously that the generalized GDA algorithm converges to the NE or the value of the game efficiently for a class of games under the Polyak-\L ojasiewicz (PL) condition. To conclude, we provide complete statistical and convergence guarantees for solving an infinite-dimensional zero-sum …

We investigate the capacity control provided by dropout in various machine learning problems. First, we study dropout for matrix completion, where it induces a distribution-dependent regularizer that equals the weighted trace-norm of the product of the factors. In deep learning, we show that the distribution-dependent regularizer due to dropout directly controls the Rademacher complexity of the underlying class of deep neural networks. These developments enable us to give concrete generalization error bounds for the dropout algorithm in both matrix completion as well as training deep neural networks.

A fundamental obstacle in learning information from data is the presence of nonlinear redundancies and dependencies in it. To address this, we propose a Fourier-based approach to extract relevant information in the supervised setting. We first develop a novel Fourier expansion for functions of correlated binary random variables. This expansion is a generalization of the standard Fourier analysis on the Boolean cube beyond product probability spaces. We further extend our Fourier analysis to stochastic mappings. As an important application of this analysis, we investigate learning with feature subset selection. We reformulate this problem in the Fourier domain and introduce a computationally efficient measure for selecting features. Bridging the Bayesian error rate with the Fourier coefficients, we demonstrate that the Fourier expansion provides a powerful tool to characterize nonlinear dependencies in the features-label relation. Via theoretical analysis, we show that our proposed measure finds provably asymptotically optimal feature subsets. Lastly, we present an algorithm based on our measure and verify our findings via numerical experiments on various datasets.

Randomly perturbing networks during the training process is a commonly used approach to improving generalization performance. In this paper, we present a theoretical study of one particular way of random perturbation, which corresponds to injecting artificial noise to the training data. We provide a precise asymptotic characterization of the training and generalization errors of such randomly perturbed learning problems on a random feature model. Our analysis shows that Gaussian noise injection in the training process is equivalent to introducing a weighted ridge regularization, when the number of noise injections tends to infinity. The explicit form of the regularization is also given. Numerical results corroborate our asymptotic predictions, showing that they are accurate even in moderate problem dimensions. Our theoretical predictions are based on a new correlated Gaussian equivalence conjecture that generalizes recent results in the study of random feature models.
Oral: Supervised Learning 6 Thu 22 Jul 04:00 a.m.

In multi-dimensional classification (MDC), there are multiple class variables in the output space with each of them corresponding to one heterogeneous class space. Due to the heterogeneity of class spaces, it is quite challenging to consider the dependencies among class variables when learning from MDC examples. In this paper, we propose a novel MDC approach named SLEM which learns the predictive model in an encoded label space instead of the original heterogeneous one. Specifically, SLEM works in an encoding-training-decoding framework. In the encoding phase, each class vector is mapped into a real-valued one via three cascaded operations including pairwise grouping, one-hot conversion and sparse linear encoding. In the training phase, a multi-output regression model is learned within the encoded label space. In the decoding phase, the predicted class vector is obtained by adapting orthogonal matching pursuit over outputs of the learned multi-output regression model. Experimental results clearly validate the superiority of SLEM against state-of-the-art MDC approaches.

A key problem in program synthesis is searching over the large space of possible programs. Human programmers might decide the high-level structure of the desired program before thinking about the details; motivated by this intuition, we consider two-level search for program synthesis, in which the synthesizer first generates a plan, a sequence of symbols that describes the desired program at a high level, before generating the program. We propose to learn representations of programs that can act as plans to organize such a two-level search. Discrete latent codes are appealing for this purpose, and can be learned by applying recent work on discrete autoencoders. Based on these insights, we introduce the Latent Programmer (LP), a program synthesis method that first predicts a discrete latent code from input/output examples, and then generates the program in the target language. We evaluate the LP on two domains, demonstrating that it yields an improvement in accuracy, especially on longer programs for which search is most difficult.
Answering complex natural language questions on knowledge graphs (KGQA) is a challenging task. It requires reasoning with the input natural language questions as well as a massive, incomplete heterogeneous KG. Prior methods obtain an abstract structured query graph/tree from the input question and traverse the KG for answers following the query tree. However, they inherently cannot deal with missing links in the KG. Here we present LEGO, a Latent Execution-Guided reasOning framework to handle this challenge in KGQA. LEGO works in an iterative way, which alternates between (1) a Query Synthesizer, which synthesizes a reasoning action and grows the query tree step-by-step, and (2) a Latent Space Executor that executes the reasoning action in the latent embedding space to combat against the missing information in KG. To learn the synthesizer without step-wise supervision, we design a generic latent execution guided bottom-up search procedure to find good execution traces efficiently in the vast query space. Experimental results on several KGQA benchmarks demonstrate the effectiveness of our framework compared with previous state of the art.

Spreadsheet formula prediction has been an important program synthesis problem with many real-world applications. Previous works typically utilize input-output examples as the specification for spreadsheet formula synthesis, where each input-output pair simulates a separate row in the spreadsheet. However, this formulation does not fully capture the rich context in real-world spreadsheets. First, spreadsheet data entries are organized as tables, thus rows and columns are not necessarily independent from each other. In addition, many spreadsheet tables include headers, which provide high-level descriptions of the cell data. However, previous synthesis approaches do not consider headers as part of the specification. In this work, we present the first approach for synthesizing spreadsheet formulas from tabular context, which includes both headers and semi-structured tabular data. In particular, we propose SpreadsheetCoder, a BERT-based model architecture to represent the tabular context in both row-based and column-based formats. We train our model on a large dataset of spreadsheets, and demonstrate that SpreadsheetCoder achieves top-1 prediction accuracy of 42.51%, which is a considerable improvement over baselines that do not employ rich tabular context. Compared to the rule-based system, SpreadsheetCoder assists 82% more users in composing formulas on Google Sheets.
Oral: Applications 2 Thu 22 Jul 04:00 a.m.

Spatio-temporal forecasting has numerous applications in analyzing wireless, traffic, and financial networks. Many classical statistical models often fall short in handling the complexity and high non-linearity present in time-series data. Recent advances in deep learning allow for better modelling of spatial and temporal dependencies. While most of these models focus on obtaining accurate point forecasts, they do not characterize the prediction uncertainty. In this work, we consider the time-series data as a random realization from a nonlinear state-space model and target Bayesian inference of the hidden states for probabilistic forecasting. We use particle flow as the tool for approximating the posterior distribution of the states, as it is shown to be highly effective in complex, high-dimensional settings. Thorough experimentation on several real world time-series datasets demonstrates that our approach provides better characterization of uncertainty while maintaining comparable accuracy to the state-of-the-art point forecasting methods.

This paper is concerned about a learning algorithm for a probabilistic model of spiking neural networks (SNNs). Jimenez Rezende & Gerstner (2014) proposed a stochastic variational inference algorithm to train SNNs with hidden neurons. The algorithm updates the variational distribution using the score function gradient estimator, whose high variance often impedes the whole learning algorithm. This paper presents an alternative gradient estimator for SNNs based on the path-wise gradient estimator. The main technical difficulty is a lack of a general method to differentiate a realization of an arbitrary point process, which is necessary to derive the path-wise gradient estimator. We develop a differentiable point process, which is the technical highlight of this paper, and apply it to derive the path-wise gradient estimator for SNNs. We investigate the effectiveness of our gradient estimator through numerical simulation.

Diffusion source identification on networks is a problem of fundamental importance in a broad class of applications, including controlling the spreading of rumors on social media, identifying a computer virus over cyber networks, or identifying the disease center during epidemiology. Though this problem has received significant recent attention, most known approaches are well-studied in only very restrictive settings and lack theoretical guarantees for more realistic networks. We introduce a statistical framework for the study of this problem and develop a confidence set inference approach inspired by hypothesis testing. Our method efficiently produces a small subset of nodes, which provably covers the source node with any pre-specified confidence level without restrictive assumptions on network structures. To our knowledge, this is the first diffusion source identification method with a practically useful theoretical guarantee on general networks. We demonstrate our approach via extensive synthetic experiments on well-known random network models, a large data set of real-world networks as well as a mobility network between cities concerning the COVID-19 spreading in January 2020.

We study the problem of learning conditional average treatment effects (CATE) from high-dimensional, observational data with unobserved confounders. Unobserved confounders introduce ignorance---a level of unidentifiability---about an individual's response to treatment by inducing bias in CATE estimates. We present a new parametric interval estimator suited for high-dimensional data, that estimates a range of possible CATE values when given a predefined bound on the level of hidden confounding. Further, previous interval estimators do not account for ignorance about the CATE associated with samples that may be underrepresented in the original study, or samples that violate the overlap assumption. Our interval estimator also incorporates model uncertainty so that practitioners can be made aware of such out-of-distribution data. We prove that our estimator converges to tight bounds on CATE when there may be unobserved confounding and assess it using semi-synthetic, high-dimensional datasets.

Most computer science conferences rely on paper bidding to assign reviewers to papers. Although paper bidding enables high-quality assignments in days of unprecedented submission numbers, it also opens the door for dishonest reviewers to adversarially influence paper reviewing assignments. Anecdotal evidence suggests that some reviewers bid on papers by "friends" or colluding authors, even though these papers are outside their area of expertise, and recommend them for acceptance without considering the merit of the work. In this paper, we study the efficacy of such bid manipulation attacks and find that, indeed, they can jeopardize the integrity of the review process. We develop a novel approach for paper bidding and assignment that is much more robust against such attacks. We show empirically that our approach provides robustness even when dishonest reviewers collude, have full knowledge of the assignment system's internal workings, and have access to the system's inputs. In addition to being more robust, the quality of our paper review assignments is comparable to that of current, non-robust assignment approaches.
Data-driven pricing strategies are becoming increasingly common, where customers are offered a personalized price based on features that are predictive of their valuation of a product. It is desirable for this pricing policy to be simple and interpretable, so it can be verified, checked for fairness, and easily implemented. However, efforts to incorporate machine learning into a pricing framework often lead to complex pricing policies that are not interpretable, resulting in slow adoption in practice. We present a novel, customized, prescriptive tree-based algorithm that distills knowledge from a complex black-box machine learning algorithm, segments customers with similar valuations and prescribes prices in such a way that maximizes revenue while maintaining interpretability. We quantify the regret of a resulting policy and demonstrate its efficacy in applications with both synthetic and real-world datasets.

Intersection over union (IoU) score, also named Jaccard Index, is one of the most fundamental evaluation methods in machine learning. The original IoU computation cannot provide non-zero gradients and thus cannot be directly optimized by nowadays deep learning methods. Several recent works generalized IoU for bounding box regression, but they are not straightforward to adapt for pixelwise prediction. In particular, the original IoU fails to provide effective gradients for the non-overlapping and location-deviation cases, which results in performance plateau. In this paper, we propose PixIoU, a generalized IoU for pixelwise prediction that is sensitive to the distance for non-overlapping cases and the locations in prediction. We provide proofs that PixIoU holds many nice properties as the original IoU. To optimize the PixIoU, we also propose a loss function that is proved to be submodular, hence we can apply the Lov\'asz functions, the efficient surrogates for submodular functions for learning this loss. Experimental results show consistent performance improvements by learning PixIoU over the original IoU for several different pixelwise prediction tasks on Pascal VOC, VOT-2020 and Cityscapes.
Oral: Applications (Bio) 2 Thu 22 Jul 04:00 a.m.

We study a fundamental problem in computational chemistry known as molecular conformation generation, trying to predict stable 3D structures from 2D molecular graphs. Existing machine learning approaches usually first predict distances between atoms and then generate a 3D structure satisfying the distances, where noise in predicted distances may induce extra errors during 3D coordinate generation. Inspired by the traditional force field methods for molecular dynamics simulation, in this paper, we propose a novel approach called ConfGF by directly estimating the gradient fields of the log density of atomic coordinates. The estimated gradient fields allow directly generating stable conformations via Langevin dynamics. However, the problem is very challenging as the gradient fields are roto-translation equivariant. We notice that estimating the gradient fields of atomic coordinates can be translated to estimating the gradient fields of interatomic distances, and hence develop a novel algorithm based on recent score-based generative models to effectively estimate these gradients. Experimental results across multiple tasks show that ConfGF outperforms previous state-of-the-art baselines by a significant margin.

Predicting molecular conformations (or 3D structures) from molecular graphs is a fundamental problem in many applications. Most existing approaches are usually divided into two steps by first predicting the distances between atoms and then generating a 3D structure through optimizing a distance geometry problem. However, the distances predicted with such two-stage approaches may not be able to consistently preserve the geometry of local atomic neighborhoods, making the generated structures unsatisfying. In this paper, we propose an end-to-end solution for molecular conformation prediction called ConfVAE based on the conditional variational autoencoder framework. Specifically, the molecular graph is first encoded in a latent space, and then the 3D structures are generated by solving a principled bilevel optimization program. Extensive experiments on several benchmark data sets prove the effectiveness of our proposed approach over existing state-of-the-art approaches. Code is available at \url{https://github.com/MinkaiXu/ConfVAE-ICML21}.

The scarcity of available samples and the high annotation cost of medical data cause a bottleneck in many digital diagnosis tasks based on deep learning. This problem is especially severe in pediatric tumor tasks, due to the small population base of children and high sample diversity caused by the high metastasis rate of related tumors. Targeted research on pediatric tumors is urgently needed but lacks sufficient attention. In this work, we propose a novel model to solve the diagnosis task of small round blue cell tumors (SRBCTs). To solve the problem of high noise and high diversity in the small sample scenario, the model is constrained to pay attention to the valid areas in the pathological image with a masking mechanism, and a length-aware loss is proposed to improve the tolerance to feature diversity. We evaluate this framework on a challenging small sample SRBCTs dataset, whose classification is difficult even for professional pathologists. The proposed model shows the best performance compared with state-of-the-art deep models and generalization on another pathological dataset, which illustrates the potentiality of deep learning applications in difficult small sample medical tasks.
A common workflow in single-cell RNA-seq analysis is to project the data to a latent space, cluster the cells in that space, and identify sets of marker genes that explain the differences among the discovered clusters. A primary drawback to this three-step procedure is that each step is carried out independently, thereby neglecting the effects of the nonlinear embedding and inter-gene dependencies on the selection of marker genes. Here we propose an integrated deep learning framework, Adversarial Clustering Explanation (ACE), that bundles all three steps into a single workflow. The method thus moves away from the notion of "marker genes" to instead identify a panel of explanatory genes. This panel may include genes that are not only enriched but also depleted relative to other cell types, as well as genes that exhibit differences between closely related cell types. Empirically, we demonstrate that ACE is able to identify gene panels that are both highly discriminative and nonredundant, and we demonstrate the applicability of ACE to an image recognition task.

Designing novel protein sequences for a desired 3D topological fold is a fundamental yet non-trivial task in protein engineering. Challenges exist due to the complex sequence--fold relationship, as well as the difficulties to capture the diversity of the sequences (therefore structures and functions) within a fold. To overcome these challenges, we propose Fold2Seq, a novel transformer-based generative framework for designing protein sequences conditioned on a specific target fold. To model the complex sequence--structure relationship, Fold2Seq jointly learns a sequence embedding using a transformer and a fold embedding from the density of secondary structural elements in 3D voxels. On test sets with single, high-resolution and complete structure inputs for individual folds, our experiments demonstrate improved or comparable performance of Fold2Seq in terms of speed, coverage, and reliability for sequence design, when compared to existing state-of-the-art methods that include data-driven deep generative models and physics-based RosettaDesign. The unique advantages of fold-based Fold2Seq, in comparison to a structure-based deep model and RosettaDesign, become more evident on three additional real-world challenges originating from low-quality, incomplete, or ambiguous input structures. Source code and data are available at https://github.com/IBM/fold2seq.

Feedforward computation, such as evaluating a neural network or sampling from an autoregressive model, is ubiquitous in machine learning. The sequential nature of feedforward computation, however, requires a strict order of execution and cannot be easily accelerated with parallel computing. To enable parallelization, we frame the task of feedforward computation as solving a system of nonlinear equations. We then propose to find the solution using a Jacobi or Gauss-Seidel fixed-point iteration method, as well as hybrid methods of both. Crucially, Jacobi updates operate independently on each equation and can be executed in parallel. Our method is guaranteed to give exactly the same values as the original feedforward computation with a reduced (or equal) number of parallelizable iterations, and hence reduced time given sufficient parallel computing power. Experimentally, we demonstrate the effectiveness of our approach in accelerating (i) backpropagation of RNNs, (ii) evaluation of DenseNets, and (iii) autoregressive sampling of MADE and PixelCNN++, with speedup factors between 2.1 and 26 under various settings.
Reliably predicting the products of chemical reactions presents a fundamental challenge in synthetic chemistry. Existing machine learning approaches typically produce a reaction product by sequentially forming its subparts or intermediate molecules. Such autoregressive methods, however, not only require a pre-defined order for the incremental construction but preclude the use of parallel decoding for efficient computation. To address these issues, we devise a non-autoregressive learning paradigm that predicts reaction in one shot. Leveraging the fact that chemical reactions can be described as a redistribution of electrons in molecules, we formulate a reaction as an arbitrary electron flow and predict it with a novel multi-pointer decoding network. Experiments on the USPTO-MIT dataset show that our approach has established a new state-of-the-art top-1 accuracy and achieves at least 27 times inference speedup over the state-of-the-art methods. Also, our predictions are easier for chemists to interpret owing to predicting the electron flows.
Oral: Bandits 4 Thu 22 Jul 04:00 a.m.


Recent work has considered natural variations of the {\em multi-armed bandit} problem, where the reward distribution of each arm is a special function of the time passed since its last pulling. In this direction, a simple (yet widely applicable) model is that of {\em blocking bandits}, where an arm becomes unavailable for a deterministic number of rounds after each play. In this work, we extend the above model in two directions: (i) We consider the general combinatorial setting where more than one arms can be played at each round, subject to feasibility constraints. (ii) We allow the blocking time of each arm to be stochastic. We first study the computational/unconditional hardness of the above setting and identify the necessary conditions for the problem to become tractable (even in an approximate sense). Based on these conditions, we provide a tight analysis of the approximation guarantee of a natural greedy heuristic that always plays the maximum expected reward feasible subset among the available (non-blocked) arms. When the arms' expected rewards are unknown, we adapt the above heuristic into a bandit algorithm, based on UCB, for which we provide sublinear (approximate) regret guarantees, matching the theoretical lower bounds in the limiting case of …



Using logical clauses to represent patterns, Tsetlin Machine (TM) have recently obtained competitive performance in terms of accuracy, memory footprint, energy, and learning speed on several benchmarks. Each TM clause votes for or against a particular class, with classification resolved using a majority vote. While the evaluation of clauses is fast, being based on binary operators, the voting makes it necessary to synchronize the clause evaluation, impeding parallelization. In this paper, we propose a novel scheme for desynchronizing the evaluation of clauses, eliminating the voting bottleneck. In brief, every clause runs in its own thread for massive native parallelism. For each training example, we keep track of the class votes obtained from the clauses in local voting tallies. The local voting tallies allow us to detach the processing of each clause from the rest of the clauses, supporting decentralized learning. This means that the TM most of the time will operate on outdated voting tallies. We evaluated the proposed parallelization across diverse learning tasks and it turns out that our decentralized TM learning algorithm copes well with working on outdated data, resulting in no significant loss in learning accuracy. Furthermore, we show that the approach provides up to 50 times …

Computationally efficient contextual bandits are often based on estimating a predictive model of rewards given contexts and arms using past data. However, when the reward model is not well-specified, the bandit algorithm may incur unexpected regret, so recent work has focused on algorithms that are robust to misspecification. We propose a simple family of contextual bandit algorithms that adapt to misspecification error by reverting to a good safe policy when there is evidence that misspecification is causing a regret increase. Our algorithm requires only an offline regression oracle to ensure regret guarantees that gracefully degrade in terms of a measure of the average misspecification level. Compared to prior work, we attain similar regret guarantees, but we do no rely on a master algorithm, and do not require more robust oracles like online or constrained regression oracles (e.g., Foster et al. (2020), Krishnamurthy et al. (2020)). This allows us to design algorithms for more general function approximation classes.
Oral: Applications 1 Thu 22 Jul 04:00 a.m.

We consider repair tasks: given a critic (e.g., compiler) that assesses the quality of an input, the goal is to train a fixer that converts a bad example (e.g., code with syntax errors) into a good one (e.g., code with no errors). Existing works create training data consisting of (bad, good) pairs by corrupting good examples using heuristics (e.g., dropping tokens). However, fixers trained on this synthetically-generated data do not extrapolate well to the real distribution of bad inputs. To bridge this gap, we propose a new training approach, Break-It-Fix-It (BIFI), which has two key ideas: (i) we use the critic to check a fixer's output on real bad inputs and add good (fixed) outputs to the training data, and (ii) we train a breaker to generate realistic bad code from good code. Based on these ideas, we iteratively update the breaker and the fixer while using them in conjunction to generate more paired data. We evaluate BIFI on two code repair datasets: GitHub-Python, a new dataset we introduce where the goal is to repair Python code with AST parse errors; and DeepFix, where the goal is to repair C code with compiler errors. BIFI outperforms existing methods, obtaining 90.5% …
Counterfactual estimation using synthetic controls is one of the most successful recent methodological developments in causal inference. Despite its popularity, the current description only considers time series aligned across units and synthetic controls expressed as linear combinations of observed control units. We propose a continuous-time alternative that models the latent counterfactual path explicitly using the formalism of controlled differential equations. This model is directly applicable to the general setting of irregularly-aligned multivariate time series and may be optimized in rich function spaces -- thereby improving on some limitations of existing approaches.

The success of Convolutional Neural Networks (CNNs) in computer vision is mainly driven by their strong inductive bias, which is strong enough to allow CNNs to solve vision-related tasks with random weights, meaning without learning. Similarly, Long Short-Term Memory (LSTM) has a strong inductive bias towards storing information over time. However, many real-world systems are governed by conservation laws, which lead to the redistribution of particular quantities — e.g.in physical and economical systems. Our novel Mass-Conserving LSTM (MC-LSTM) adheres to these conservation laws by extending the inductive bias of LSTM to model the redistribution of those stored quantities. MC-LSTMs set a new state-of-the-art for neural arithmetic units at learning arithmetic operations, such as addition tasks,which have a strong conservation law, as the sum is constant over time. Further, MC-LSTM is applied to traffic forecasting, modeling a pendulum, and a large benchmark dataset in hydrology, where it sets a new state-of-the-art for predicting peak flows. In the hydrology example, we show that MC-LSTM states correlate with real world processes and are therefore interpretable.

We present deep learning methods for the design of arrays and single instances of small antennas. Each design instance is conditioned on a target radiation pattern and is required to conform to specific spatial dimensions and to include, as part of its metallic structure, a set of predetermined locations. The solution, in the case of a single antenna, is based on a composite neural network that combines a simulation network, a hypernetwork, and a refinement network. In the design of the antenna array, we add an additional design level and employ a hypernetwork within a hypernetwork. The learning objective is based on measuring the similarity of the obtained radiation pattern to the desired one. Our experiments demonstrate that our approach is able to design novel antennas and antenna arrays that are compliant with the design requirements, considerably better than the baseline methods. We compare the solutions obtained by our method to existing designs and demonstrate a high level of overlap. When designing the antenna array of a cellular phone, the obtained solution displays improved properties over the existing one.

We present a novel adaptive cruise control (ACC) system namely SAINT-ACC: {S}afety-{A}ware {Int}elligent {ACC} system (SAINT-ACC) that is designed to achieve simultaneous optimization of traffic efficiency, driving safety, and driving comfort through dynamic adaptation of the inter-vehicle gap based on deep reinforcement learning (RL). A novel dual RL agent-based approach is developed to seek and adapt the optimal balance between traffic efficiency and driving safety/comfort by effectively controlling the driving safety model parameters and inter-vehicle gap based on macroscopic and microscopic traffic information collected from dynamically changing and complex traffic environments. Results obtained through over 12,000 simulation runs with varying traffic scenarios and penetration rates demonstrate that SAINT-ACC significantly enhances traffic flow, driving safety and comfort compared with a state-of-the-art approach.

32% of all global deaths in the world are caused by cardiovascular diseases. Early detection, especially for patients with ischemia or cardiac arrhythmia, is crucial. To reduce the time between symptoms onset and treatment, wearable ECG sensors were developed to allow for the recording of the full 12-lead ECG signal at home. However, if even a single lead is not correctly positioned on the body that lead becomes corrupted, making automatic diagnosis on the basis of the full signal impossible. In this work, we present a methodology to reconstruct missing or noisy leads using the theory of Koopman Operators. Given a dataset consisting of full 12-lead ECGs, we learn a dynamical system describing the evolution of the 12 individual signals together in time. The Koopman theory indicates that there exists a high-dimensional embedding space in which the operator which propagates from one time instant to the next is linear. We therefore learn both the mapping to this embedding space, as well as the corresponding linear operator. Armed with this representation, we are able to impute missing leads by solving a least squares system in the embedding space, which can be achieved efficiently due to the sparse structure of the system. …

A landmark challenge for AI is to learn flexible, powerful representations from small numbers of examples. On an important class of tasks, hypotheses in the form of programs provide extreme generalization capabilities from surprisingly few examples. However, whereas large natural few-shot learning image benchmarks have spurred progress in meta-learning for deep networks, there is no comparably big, natural program-synthesis dataset that can play a similar role. This is because, whereas images are relatively easy to label from internet meta-data or annotated by non-experts, generating meaningful input-output examples for program induction has proven hard to scale. In this work, we propose a new way of leveraging unit tests and natural inputs for small programs as meaningful input-output examples for each sub-program of the overall program. This allows us to create a large-scale naturalistic few-shot program-induction benchmark and propose new challenges in this domain. The evaluation of multiple program induction and synthesis algorithms points to shortcomings of current methods and suggests multiple avenues for future work.
Oral: Algorithms 2 Thu 22 Jul 04:00 a.m.

Can models with particular structure avoid being biased towards spurious correlation in out-of-distribution (OOD) generalization? Peters et al. (2016) provides a positive answer for linear cases. In this paper, we use a functional modular probing method to analyze deep model structures under OOD setting. We demonstrate that even in biased models (which focus on spurious correlation) there still exist unbiased functional subnetworks. Furthermore, we articulate and confirm the functional lottery ticket hypothesis: the full network contains a subnetwork with proper structure that can achieve better OOD performance. We then propose Modular Risk Minimization to solve the subnetwork selection problem. Our algorithm learns the functional structure from a given dataset, and can be combined with any other OOD regularization methods. Experiments on various OOD generalization tasks corroborate the effectiveness of our method.


In real-world applications, data often come in a growing manner, where the data volume and the number of classes may increase dynamically. This will bring a critical challenge for learning: given the increasing data volume or the number of classes, one has to instantaneously adjust the neural model capacity to obtain promising performance. Existing methods either ignore the growing nature of data or seek to independently search an optimal architecture for a given dataset, and thus are incapable of promptly adjusting the architectures for the changed data. To address this, we present a neural architecture adaptation method, namely Adaptation eXpert (AdaXpert), to efficiently adjust previous architectures on the growing data. Specifically, we introduce an architecture adjuster to generate a suitable architecture for each data snapshot, based on the previous architecture and the different extent between current and previous data distributions. Furthermore, we propose an adaptation condition to determine the necessity of adjustment, thereby avoiding unnecessary and time-consuming adjustments. Extensive experiments on two growth scenarios (increasing data volume and number of classes) demonstrate the effectiveness of the proposed method.
Stochastic differential equations (SDEs) are a staple of mathematical modelling of temporal dynamics. However, a fundamental limitation has been that such models have typically been relatively inflexible, which recent work introducing Neural SDEs has sought to solve. Here, we show that the current classical approach to fitting SDEs may be approached as a special case of (Wasserstein) GANs, and in doing so the neural and classical regimes may be brought together. The input noise is Brownian motion, the output samples are time-evolving paths produced by a numerical solver, and by parameterising a discriminator as a Neural Controlled Differential Equation (CDE), we obtain Neural SDEs as (in modern machine learning parlance) continuous-time generative time series models. Unlike previous work on this problem, this is a direct extension of the classical approach without reference to either prespecified statistics or density functions. Arbitrary drift and diffusions are admissible, so as the Wasserstein loss has a unique global minima, in the infinite data limit \textit{any} SDE may be learnt.

Conformal Predictors (CP) are wrappers around ML models, providing error guarantees under weak assumptions on the data distribution. They are suitable for a wide range of problems, from classification and regression to anomaly detection. Unfortunately, their very high computational complexity limits their applicability to large datasets. In this work, we show that it is possible to speed up a CP classifier considerably, by studying it in conjunction with the underlying ML method, and by exploiting incremental\&decremental learning. For methods such as k-NN, KDE, and kernel LS-SVM, our approach reduces the running time by one order of magnitude, whilst producing exact solutions. With similar ideas, we also achieve a linear speed up for the harder case of bootstrapping. Finally, we extend these techniques to improve upon an optimization of k-NN CP for regression. We evaluate our findings empirically, and discuss when methods are suitable for CP optimization.

Machine learning models are often deployed in different settings than they were trained and validated on, posing a challenge to practitioners who wish to predict how well the deployed model will perform on a target distribution. If an unlabeled sample from the target distribution is available, along with a labeled sample from a possibly different source distribution, standard approaches such as importance weighting can be applied to estimate performance on the target. However, importance weighting struggles when the source and target distributions have non-overlapping support or are high-dimensional. Taking inspiration from fields such as epidemiology and polling, we develop Mandoline, a new evaluation framework that mitigates these issues. Our key insight is that practitioners may have prior knowledge about the ways in which the distribution shifts, which we can use to better guide the importance weighting procedure. Specifically, users write simple "slicing functions" – noisy, potentially correlated binary functions intended to capture possible axes of distribution shift – to compute reweighted performance estimates. We further describe a density ratio estimation framework for the slices and show how its estimation error scales with slice quality and dataset size. Empirical validation on NLP and vision tasks shows that Mandoline can estimate performance …

Methods that infer causal dependence from observational data are central to many areas of science, including medicine, economics, and the social sciences. A variety of theoretical properties of these methods have been proven, but empirical evaluation remains a challenge, largely due to the lack of observational data sets for which treatment effect is known. We describe and analyze observational sampling from randomized controlled trials (OSRCT), a method for evaluating causal inference methods using data from randomized controlled trials (RCTs). This method can be used to create constructed observational data sets with corresponding unbiased estimates of treatment effect, substantially increasing the number of data sets available for evaluating causal inference methods. We show that, in expectation, OSRCT creates data sets that are equivalent to those produced by randomly sampling from empirical data sets in which all potential outcomes are available. We then perform a large-scale evaluation of seven causal inference methods over 37 data sets, drawn from RCTs, as well as simulators, real-world computational systems, and observational data sets augmented with a synthetic response variable. We find notable performance differences when comparing across data from different sources, demonstrating the importance of using data from a variety of sources when evaluating any …
Invited Talk: Edward Chang
Encoding and Decoding Speech From the Human Brain
This talk will review recent advances to understand how speech, a unique and defining human behavior, is processed by the cerebral cortex. We will discuss new neuroscientific knowledge on how the brain represents vocal tract movements to give rise to all consonants and vowels, and how this knowledge has been applied to development of a “speech neuroprosthesis” to restore communication for persons living with paralysis.
Bio :Poster Session 4 Thu 22 Jul 06:00 a.m.
[ Virtual ]
We propose a randomized algorithm with quadratic convergence rate for convex optimization problems with a self-concordant, composite, strongly convex objective function. Our method is based on performing an approximate Newton step using a random projection of the Hessian. Our first contribution is to show that, at each iteration, the embedding dimension (or sketch size) can be as small as the effective dimension of the Hessian matrix. Leveraging this novel fundamental result, we design an algorithm with a sketch size proportional to the effective dimension and which exhibits a quadratic rate of convergence. This result dramatically improves on the classical linear-quadratic convergence rates of state-of-the-art sub-sampled Newton methods. However, in most practical cases, the effective dimension is not known beforehand, and this raises the question of how to pick a sketch size as small as the effective dimension while preserving a quadratic convergence rate. Our second and main contribution is thus to propose an adaptive sketch size algorithm with quadratic convergence rate and which does not require prior knowledge or estimation of the effective dimension: at each iteration, it starts with a small sketch size, and increases it until quadratic progress is achieved. Importantly, we show that the embedding dimension remains …
[ Virtual ]
This paper is concerned about a learning algorithm for a probabilistic model of spiking neural networks (SNNs). Jimenez Rezende & Gerstner (2014) proposed a stochastic variational inference algorithm to train SNNs with hidden neurons. The algorithm updates the variational distribution using the score function gradient estimator, whose high variance often impedes the whole learning algorithm. This paper presents an alternative gradient estimator for SNNs based on the path-wise gradient estimator. The main technical difficulty is a lack of a general method to differentiate a realization of an arbitrary point process, which is necessary to derive the path-wise gradient estimator. We develop a differentiable point process, which is the technical highlight of this paper, and apply it to derive the path-wise gradient estimator for SNNs. We investigate the effectiveness of our gradient estimator through numerical simulation.
[ Virtual ]
A key problem in the theory of meta-learning is to understand how the task distributions influence transfer risk, the expected error of a meta-learner on a new task drawn from the unknown task distribution. In this paper, focusing on fixed design linear regression with Gaussian noise and a Gaussian task (or parameter) distribution, we give distribution-dependent lower bounds on the transfer risk of any algorithm, while we also show that a novel, weighted version of the so-called biased regularized regression method is able to match these lower bounds up to a fixed constant factor. Notably, the weighting is derived from the covariance of the Gaussian task distribution. Altogether, our results provide a precise characterization of the difficulty of meta-learning in this Gaussian setting. While this problem setting may appear simple, we show that it is rich enough to unify the “parameter sharing” and “representation learning” streams of meta-learning; in particular, representation learning is obtained as the special case when the covariance matrix of the task distribution is unknown. For this case we propose to adopt the EM method, which is shown to enjoy efficient updates in our case. The paper is completed by an empirical study of EM. In particular, …
[ Virtual ]
[ Virtual ]
[ Virtual ]
Predicting molecular conformations (or 3D structures) from molecular graphs is a fundamental problem in many applications. Most existing approaches are usually divided into two steps by first predicting the distances between atoms and then generating a 3D structure through optimizing a distance geometry problem. However, the distances predicted with such two-stage approaches may not be able to consistently preserve the geometry of local atomic neighborhoods, making the generated structures unsatisfying. In this paper, we propose an end-to-end solution for molecular conformation prediction called ConfVAE based on the conditional variational autoencoder framework. Specifically, the molecular graph is first encoded in a latent space, and then the 3D structures are generated by solving a principled bilevel optimization program. Extensive experiments on several benchmark data sets prove the effectiveness of our proposed approach over existing state-of-the-art approaches. Code is available at \url{https://github.com/MinkaiXu/ConfVAE-ICML21}.
[ Virtual ]
This paper prescribes a distance between learning tasks modeled as joint distributions on data and labels. Using tools in information geometry, the distance is defined to be the length of the shortest weight trajectory on a Riemannian manifold as a classifier is fitted on an interpolated task. The interpolated task evolves from the source to the target task using an optimal transport formulation. This distance, which we call the "coupled transfer distance" can be compared across different classifier architectures. We develop an algorithm to compute the distance which iteratively transports the marginal on the data of the source task to that of the target task while updating the weights of the classifier to track this evolving data distribution. We develop theory to show that our distance captures the intuitive idea that a good transfer trajectory is the one that keeps the generalization gap small during transfer, in particular at the end on the target task. We perform thorough empirical validation and analysis across diverse image classification datasets to show that the coupled transfer distance correlates strongly with the difficulty of fine-tuning.
[ Virtual ]
The RKHS bandit problem (also called kernelized multi-armed bandit problem) is an online optimization problem of non-linear functions with noisy feedback. Although the problem has been extensively studied, there are unsatisfactory results for some problems compared to the well-studied linear bandit case. Specifically, there is no general algorithm for the adversarial RKHS bandit problem. In addition, high computational complexity of existing algorithms hinders practical application. We address these issues by considering a novel amalgamation of approximation theory and the misspecified linear bandit problem. Using an approximation method, we propose efficient algorithms for the stochastic RKHS bandit problem and the first general algorithm for the adversarial RKHS bandit problem. Furthermore, we empirically show that one of our proposed methods has comparable cumulative regret to IGP-UCB and its running time is much shorter.
[ Virtual ]
Robust loss functions are essential for training deep neural networks with better generalization power in the presence of noisy labels. Symmetric loss functions are confirmed to be robust to label noise. However, the symmetric condition is overly restrictive. In this work, we propose a new class of loss functions, namely asymmetric loss functions, which are robust to learning from noisy labels for arbitrary noise type. Subsequently, we investigate general theoretical properties of asymmetric loss functions, including classification-calibration, excess risk bound, and noise-tolerance. Meanwhile, we introduce the asymmetry ratio to measure the asymmetry of a loss function, and the empirical results show that a higher ratio will provide better robustness. Moreover, we modify several common loss functions, and establish the necessary and sufficient conditions for them to be asymmetric. Experiments on benchmark datasets demonstrate that asymmetric loss functions can outperform state-of-the-art methods.
[ Virtual ]
One of the central problems in machine learning is domain adaptation. Different from past theoretical works, we consider a new model of subpopulation shift in the input or representation space. In this work, we propose a provably effective framework based on label propagation by using an input consistency loss. In our analysis we used a simple but realistic “expansion” assumption, which has been proposed in \citet{wei2021theoretical}. It turns out that based on a teacher classifier on the source domain, the learned classifier can not only propagate to the target domain but also improve upon the teacher. By leveraging existing generalization bounds, we also obtain end-to-end finite-sample guarantees on deep neural networks. In addition, we extend our theoretical framework to a more general setting of source-to-target transfer based on an additional unlabeled dataset, which can be easily applied to various learning scenarios. Inspired by our theory, we adapt consistency-based semi-supervised learning methods to domain adaptation settings and gain significant improvements.
[ Virtual ]
In this work, we propose TimeGrad, an autoregressive model for multivariate probabilistic time series forecasting which samples from the data distribution at each time step by estimating its gradient. To this end, we use diffusion probabilistic models, a class of latent variable models closely connected to score matching and energy-based methods. Our model learns gradients by optimizing a variational bound on the data likelihood and at inference time converts white noise into a sample of the distribution of interest through a Markov chain using Langevin sampling. We demonstrate experimentally that the proposed autoregressive denoising diffusion model is the new state-of-the-art multivariate probabilistic forecasting method on real-world data sets with thousands of correlated dimensions. We hope that this method is a useful tool for practitioners and lays the foundation for future research in this area.
[ Virtual ]
[ Virtual ]
The goal of classification with rejection is to avoid risky misclassification in error-critical applications such as medical diagnosis and product inspection. In this paper, based on the relationship between classification with rejection and cost-sensitive classification, we propose a novel method of classification with rejection by learning an ensemble of cost-sensitive classifiers, which satisfies all the following properties: (i) it can avoid estimating class-posterior probabilities, resulting in improved classification accuracy. (ii) it allows a flexible choice of losses including non-convex ones, (iii) it does not require complicated modifications when using different losses, (iv) it is applicable to both binary and multiclass cases, and (v) it is theoretically justifiable for any classification-calibrated loss. Experimental results demonstrate the usefulness of our proposed approach in clean-labeled, noisy-labeled, and positive-unlabeled classification.
[ Virtual ]
The label noise transition matrix, characterizing the probabilities of a training instance being wrongly annotated, is crucial to designing popular solutions to learning with noisy labels. Existing works heavily rely on finding ``anchor points'' or their approximates, defined as instances belonging to a particular class almost surely. Nonetheless, finding anchor points remains a non-trivial task, and the estimation accuracy is also often throttled by the number of available anchor points. In this paper, we propose an alternative option to the above task. Our main contribution is the discovery of an efficient estimation procedure based on a clusterability condition. We prove that with clusterable representations of features, using up to third-order consensuses of noisy labels among neighbor representations is sufficient to estimate a unique transition matrix. Compared with methods using anchor points, our approach uses substantially more instances and benefits from a much better sample complexity. We demonstrate the estimation accuracy and advantages of our estimates using both synthetic noisy labels (on CIFAR-10/100) and real human-level noisy labels (on Clothing1M and our self-collected human-annotated CIFAR-10). Our code and human-level noisy CIFAR-10 labels are available at https://github.com/UCSC-REAL/HOC.
[ Virtual ]
[ Virtual ]
Contrastive learning has recently seen tremendous success in self-supervised learning. So far, however, it is largely unclear why the learned representations generalize so effectively to a large variety of downstream tasks. We here prove that feedforward models trained with objectives belonging to the commonly used InfoNCE family learn to implicitly invert the underlying generative model of the observed data. While the proofs make certain statistical assumptions about the generative model, we observe empirically that our findings hold even if these assumptions are severely violated. Our theory highlights a fundamental connection between contrastive learning, generative modeling, and nonlinear independent component analysis, thereby furthering our understanding of the learned representations as well as providing a theoretical foundation to derive more effective contrastive losses.
[ Virtual ]
[ Virtual ]
[ Virtual ]
In policy search methods for reinforcement learning (RL), exploration is often performed by injecting noise either in action space at each step independently or in parameter space over each full trajectory. In prior work, it has been shown that with linear policies, a more balanced trade-off between these two exploration strategies is beneficial. However, that method did not scale to policies using deep neural networks. In this paper, we introduce deep coherent exploration, a general and scalable exploration framework for deep RL algorithms for continuous control, that generalizes step-based and trajectory-based exploration. This framework models the last layer parameters of the policy network as latent variables and uses a recursive inference step within the policy update to handle these latent variables in a scalable manner. We find that deep coherent exploration improves the speed and stability of learning of A2C, PPO, and SAC on several continuous control tasks.
[ Virtual ]
Despite their widespread success, the application of deep neural networks to functional data remains scarce today. The infinite dimensionality of functional data means standard learning algorithms can be applied only after appropriate dimension reduction, typically achieved via basis expansions. Currently, these bases are chosen a priori without the information for the task at hand and thus may not be effective for the designated task. We instead propose to adaptively learn these bases in an end-to-end fashion. We introduce neural networks that employ a new Basis Layer whose hidden units are each basis functions themselves implemented as a micro neural network. Our architecture learns to apply parsimonious dimension reduction to functional inputs that focuses only on information relevant to the target rather than irrelevant variation in the input function. Across numerous classification/regression tasks with functional data, our method empirically outperforms other types of neural networks, and we prove that our approach is statistically consistent with low generalization error.
[ Virtual ]
We consider the problem of detecting signals in the rank-one signal-plus-noise data matrix models that generalize the spiked Wishart matrices. We show that the principal component analysis can be improved by pre-transforming the matrix entries if the noise is non-Gaussian. As an intermediate step, we prove a sharp phase transition of the largest eigenvalues of spiked rectangular matrices, which extends the Baik--Ben Arous--P\'ech\'e (BBP) transition. We also propose a hypothesis test to detect the presence of signal with low computational complexity, based on the linear spectral statistics, which minimizes the sum of the Type-I and Type-II errors when the noise is Gaussian.
[ Virtual ]
[ Virtual ]
Minimizing cross-entropy over the softmax scores of a linear map composed with a high-capacity encoder is arguably the most popular choice for training neural networks on supervised learning tasks. However, recent works show that one can directly optimize the encoder instead, to obtain equally (or even more) discriminative representations via a supervised variant of a contrastive objective. In this work, we address the question whether there are fundamental differences in the sought-for representation geometry in the output space of the encoder at minimal loss. Specifically, we prove, under mild assumptions, that both losses attain their minimum once the representations of each class collapse to the vertices of a regular simplex, inscribed in a hypersphere. We provide empirical evidence that this configuration is attained in practice and that reaching a close-to-optimal state typically indicates good generalization performance. Yet, the two losses show remarkably different optimization behavior. The number of iterations required to perfectly fit to data scales superlinearly with the amount of randomly flipped labels for the supervised contrastive loss. This is in contrast to the approximately linear scaling previously reported for networks trained with cross-entropy.
[ Virtual ]
When learning from streaming data, a change in the data distribution, also known as concept drift, can render a previously-learned model inaccurate and require training a new model. We present an adaptive learning algorithm that extends previous drift-detection-based methods by incorporating drift detection into a broader stable-state/reactive-state process. The advantage of our approach is that we can use aggressive drift detection in the stable state to achieve a high detection rate, but mitigate the false positive rate of standalone drift detection via a reactive state that reacts quickly to true drifts while eliminating most false positives. The algorithm is generic in its base learner and can be applied across a variety of supervised learning problems. Our theoretical analysis shows that the risk of the algorithm is (i) statistically better than standalone drift detection and (ii) competitive to an algorithm with oracle knowledge of when (abrupt) drifts occur. Experiments on synthetic and real datasets with concept drifts confirm our theoretical analysis.
[ Virtual ]
We investigate the capacity control provided by dropout in various machine learning problems. First, we study dropout for matrix completion, where it induces a distribution-dependent regularizer that equals the weighted trace-norm of the product of the factors. In deep learning, we show that the distribution-dependent regularizer due to dropout directly controls the Rademacher complexity of the underlying class of deep neural networks. These developments enable us to give concrete generalization error bounds for the dropout algorithm in both matrix completion as well as training deep neural networks.
[ Virtual ]
Continuous-time event sequences represent discrete events occurring in continuous time. Such sequences arise frequently in real-life. Usually we expect the sequences to follow some regular pattern over time. However, sometimes these patterns may be interrupted by unexpected absence or occurrences of events. Identification of these unexpected cases can be very important as they may point to abnormal situations that need human attention. In this work, we study and develop methods for detecting outliers in continuous-time event sequences, including unexpected absence and unexpected occurrences of events. Since the patterns that event sequences tend to follow may change in different contexts, we develop outlier detection methods based on point processes that can take context information into account. Our methods are based on Bayesian decision theory and hypothesis testing with theoretical guarantees. To test the performance of the methods, we conduct experiments on both synthetic data and real-world clinical data and show the effectiveness of the proposed methods.
[ Virtual ]
We present an optimization framework for learning a fair classifier in the presence of noisy perturbations in the protected attributes. Compared to prior work, our framework can be employed with a very general class of linear and linear-fractional fairness constraints, can handle multiple, non-binary protected attributes, and outputs a classifier that comes with provable guarantees on both accuracy and fairness. Empirically, we show that our framework can be used to attain either statistical rate or false positive rate fairness guarantees with a minimal loss in accuracy, even when the noise is large, in two real-world datasets.
[ Virtual ]
A fundamental obstacle in learning information from data is the presence of nonlinear redundancies and dependencies in it. To address this, we propose a Fourier-based approach to extract relevant information in the supervised setting. We first develop a novel Fourier expansion for functions of correlated binary random variables. This expansion is a generalization of the standard Fourier analysis on the Boolean cube beyond product probability spaces. We further extend our Fourier analysis to stochastic mappings. As an important application of this analysis, we investigate learning with feature subset selection. We reformulate this problem in the Fourier domain and introduce a computationally efficient measure for selecting features. Bridging the Bayesian error rate with the Fourier coefficients, we demonstrate that the Fourier expansion provides a powerful tool to characterize nonlinear dependencies in the features-label relation. Via theoretical analysis, we show that our proposed measure finds provably asymptotically optimal feature subsets. Lastly, we present an algorithm based on our measure and verify our findings via numerical experiments on various datasets.
[ Virtual ]
[ Virtual ]
The great success of modern machine learning models on large datasets is contingent on extensive computational resources with high financial and environmental costs. One way to address this is by extracting subsets that generalize on par with the full data. In this work, we propose a general framework, GRAD-MATCH, which finds subsets that closely match the gradient of the \emph{training or validation} set. We find such subsets effectively using an orthogonal matching pursuit algorithm. We show rigorous theoretical and convergence guarantees of the proposed algorithm and, through our extensive experiments on real-world datasets, show the effectiveness of our proposed framework. We show that GRAD-MATCH significantly and consistently outperforms several recent data-selection algorithms and achieves the best accuracy-efficiency trade-off. GRAD-MATCH is available as a part of the CORDS toolkit: \url{https://github.com/decile-team/cords}.
[ Virtual ]
Machine learning algorithms with empirical risk minimization usually suffer from poor generalization performance due to the greedy exploitation of correlations among the training data, which are not stable under distributional shifts. Recently, some invariant learning methods for out-of-distribution (OOD) generalization have been proposed by leveraging multiple training environments to find invariant relationships. However, modern datasets are frequently assembled by merging data from multiple sources without explicit source labels. The resultant unobserved heterogeneity renders many invariant learning methods inapplicable. In this paper, we propose Heterogeneous Risk Minimization (HRM) framework to achieve joint learning of latent heterogeneity among the data and invariant relationship, which leads to stable prediction despite distributional shifts. We theoretically characterize the roles of the environment labels in invariant learning and justify our newly proposed HRM framework. Extensive experimental results validate the effectiveness of our HRM framework.
[ Virtual ]
Methods that infer causal dependence from observational data are central to many areas of science, including medicine, economics, and the social sciences. A variety of theoretical properties of these methods have been proven, but empirical evaluation remains a challenge, largely due to the lack of observational data sets for which treatment effect is known. We describe and analyze observational sampling from randomized controlled trials (OSRCT), a method for evaluating causal inference methods using data from randomized controlled trials (RCTs). This method can be used to create constructed observational data sets with corresponding unbiased estimates of treatment effect, substantially increasing the number of data sets available for evaluating causal inference methods. We show that, in expectation, OSRCT creates data sets that are equivalent to those produced by randomly sampling from empirical data sets in which all potential outcomes are available. We then perform a large-scale evaluation of seven causal inference methods over 37 data sets, drawn from RCTs, as well as simulators, real-world computational systems, and observational data sets augmented with a synthetic response variable. We find notable performance differences when comparing across data from different sources, demonstrating the importance of using data from a variety of sources when evaluating any …
[ Virtual ]
Good generalization performance across a wide variety of domains caused by many external and internal factors is the fundamental goal of any machine learning algorithm. This paper theoretically proves that the choice of loss function matters for improving the generalization performance of deep learning-based systems. By deriving the generalization error bound for deep neural models trained by stochastic gradient descent, we pinpoint the characteristics of the loss function that is linked to the generalization error and can therefore be used for guiding the loss function selection process. In summary, our main statement in this paper is: choose a stable loss function, generalize better. Focusing on human age estimation from the face which is a challenging topic in computer vision, we then propose a novel loss function for this learning problem. We theoretically prove that the proposed loss function achieves stronger stability, and consequently a tighter generalization error bound, compared to the other common loss functions for this problem. We have supported our findings theoretically, and demonstrated the merits of the guidance process experimentally, achieving significant improvements.
[ Virtual ]
We consider a popular family of constrained optimization problems arising in machine learning that involve optimizing a non-decomposable evaluation metric with a certain thresholded form, while constraining another metric of interest. Examples of such problems include optimizing false negative rate at a fixed false positive rate, optimizing precision at a fixed recall, optimizing the area under the precision-recall or ROC curves, etc. Our key idea is to formulate a rate-constrained optimization that expresses the threshold parameter as a function of the model parameters via the Implicit Function theorem. We show how the resulting optimization problem can be solved using standard gradient based methods. Experiments on benchmark datasets demonstrate the effectiveness of our proposed method over existing state-of-the-art approaches for these problems.
[ Virtual ]
[ Virtual ]
[ Virtual ]
[ Virtual ]
Consider a prosthetic arm, learning to adapt to its user's control signals. We propose \emph{Interaction-Grounded Learning} for this novel setting, in which a learner's goal is to interact with the environment with no grounding or explicit reward to optimize its policies. Such a problem evades common RL solutions which require an explicit reward. The learning agent observes a multidimensional \emph{context vector}, takes an \emph{action}, and then observes a multidimensional \emph{feedback vector}. This multidimensional feedback vector has \emph{no} explicit reward information. In order to succeed, the algorithm must learn how to evaluate the feedback vector to discover a latent reward signal, with which it can ground its policies without supervision. We show that in an Interaction-Grounded Learning setting, with certain natural assumptions, a learner can discover the latent reward and ground its policy for successful interaction. We provide theoretical guarantees and a proof-of-concept empirical evaluation to demonstrate the effectiveness of our proposed approach.
[ Virtual ]
Landmark codes underpin reliable physical layer communication, e.g., Reed-Muller, BCH, Convolution, Turbo, LDPC, and Polar codes: each is a linear code and represents a mathematical breakthrough. The impact on humanity is huge: each of these codes has been used in global wireless communication standards (satellite, WiFi, cellular). Reliability of communication over the classical additive white Gaussian noise (AWGN) channel enables benchmarking and ranking of the different codes. In this paper, we construct KO codes, a computationally efficient family of deep-learning driven (encoder, decoder) pairs that outperform the state-of-the-art reliability performance on the standardized AWGN channel. KO codes beat state-of-the-art Reed-Muller and Polar codes, under the low-complexity successive cancellation decoding, in the challenging short-to-medium block length regime on the AWGN channel. We show that the gains of KO codes are primarily due to the nonlinear mapping of information bits directly to transmit symbols (bypassing modulation) and yet possess an efficient, high-performance decoder. The key technical innovation that renders this possible is design of a novel family of neural architectures inspired by the computation tree of the {\bf K}ronecker {\bf O}peration (KO) central to Reed-Muller and Polar codes. These architectures pave way for the discovery of a much richer class of hitherto …
[ Virtual ]
A key problem in program synthesis is searching over the large space of possible programs. Human programmers might decide the high-level structure of the desired program before thinking about the details; motivated by this intuition, we consider two-level search for program synthesis, in which the synthesizer first generates a plan, a sequence of symbols that describes the desired program at a high level, before generating the program. We propose to learn representations of programs that can act as plans to organize such a two-level search. Discrete latent codes are appealing for this purpose, and can be learned by applying recent work on discrete autoencoders. Based on these insights, we introduce the Latent Programmer (LP), a program synthesis method that first predicts a discrete latent code from input/output examples, and then generates the program in the target language. We evaluate the LP on two domains, demonstrating that it yields an improvement in accuracy, especially on longer programs for which search is most difficult.
[ Virtual ]
Intersection over union (IoU) score, also named Jaccard Index, is one of the most fundamental evaluation methods in machine learning. The original IoU computation cannot provide non-zero gradients and thus cannot be directly optimized by nowadays deep learning methods. Several recent works generalized IoU for bounding box regression, but they are not straightforward to adapt for pixelwise prediction. In particular, the original IoU fails to provide effective gradients for the non-overlapping and location-deviation cases, which results in performance plateau. In this paper, we propose PixIoU, a generalized IoU for pixelwise prediction that is sensitive to the distance for non-overlapping cases and the locations in prediction. We provide proofs that PixIoU holds many nice properties as the original IoU. To optimize the PixIoU, we also propose a loss function that is proved to be submodular, hence we can apply the Lov\'asz functions, the efficient surrogates for submodular functions for learning this loss. Experimental results show consistent performance improvements by learning PixIoU over the original IoU for several different pixelwise prediction tasks on Pascal VOC, VOT-2020 and Cityscapes.
[ Virtual ]
We study a fundamental problem in computational chemistry known as molecular conformation generation, trying to predict stable 3D structures from 2D molecular graphs. Existing machine learning approaches usually first predict distances between atoms and then generate a 3D structure satisfying the distances, where noise in predicted distances may induce extra errors during 3D coordinate generation. Inspired by the traditional force field methods for molecular dynamics simulation, in this paper, we propose a novel approach called ConfGF by directly estimating the gradient fields of the log density of atomic coordinates. The estimated gradient fields allow directly generating stable conformations via Langevin dynamics. However, the problem is very challenging as the gradient fields are roto-translation equivariant. We notice that estimating the gradient fields of atomic coordinates can be translated to estimating the gradient fields of interatomic distances, and hence develop a novel algorithm based on recent score-based generative models to effectively estimate these gradients. Experimental results across multiple tasks show that ConfGF outperforms previous state-of-the-art baselines by a significant margin.
[ Virtual ]
In single-item auction design, it is well known due to Cremer and McLean that when bidders’ valuations are drawn from a correlated prior distribution, the auctioneer can extract full social surplus as revenue. However, in most real-world applications, the prior is usually unknown and can only be learned from historical data. In this work, we investigate the robustness of the optimal auction with correlated valuations via sample complexity analysis. We prove upper and lower bounds on the number of samples from the unknown prior required to learn a (1-epsilon)-approximately optimal auction. Our results reinforce the common belief that optimal correlated auctions are sensitive to the distribution parameters and hard to learn unless the prior distribution is well-behaved.
[ Virtual ]
[ Virtual ]
Machine learning models are often deployed in different settings than they were trained and validated on, posing a challenge to practitioners who wish to predict how well the deployed model will perform on a target distribution. If an unlabeled sample from the target distribution is available, along with a labeled sample from a possibly different source distribution, standard approaches such as importance weighting can be applied to estimate performance on the target. However, importance weighting struggles when the source and target distributions have non-overlapping support or are high-dimensional. Taking inspiration from fields such as epidemiology and polling, we develop Mandoline, a new evaluation framework that mitigates these issues. Our key insight is that practitioners may have prior knowledge about the ways in which the distribution shifts, which we can use to better guide the importance weighting procedure. Specifically, users write simple "slicing functions" – noisy, potentially correlated binary functions intended to capture possible axes of distribution shift – to compute reweighted performance estimates. We further describe a density ratio estimation framework for the slices and show how its estimation error scales with slice quality and dataset size. Empirical validation on NLP and vision tasks shows that Mandoline can estimate performance …
[ Virtual ]
[ Virtual ]
In multi-dimensional classification (MDC), there are multiple class variables in the output space with each of them corresponding to one heterogeneous class space. Due to the heterogeneity of class spaces, it is quite challenging to consider the dependencies among class variables when learning from MDC examples. In this paper, we propose a novel MDC approach named SLEM which learns the predictive model in an encoded label space instead of the original heterogeneous one. Specifically, SLEM works in an encoding-training-decoding framework. In the encoding phase, each class vector is mapped into a real-valued one via three cascaded operations including pairwise grouping, one-hot conversion and sparse linear encoding. In the training phase, a multi-output regression model is learned within the encoded label space. In the decoding phase, the predicted class vector is obtained by adapting orthogonal matching pursuit over outputs of the learned multi-output regression model. Experimental results clearly validate the superiority of SLEM against state-of-the-art MDC approaches.
[ Virtual ]
[ Virtual ]
Transfer learning is essential when sufficient data comes from the source domain, with scarce labeled data from the target domain. We develop estimators that achieve minimax linear risk for linear regression problems under distribution shift. Our algorithms cover different transfer learning settings including covariate shift and model shift. We also consider when data are generated from either linear or general nonlinear models. We show that linear minimax estimators are within an absolute constant of the minimax risk even among nonlinear estimators for various source/target distributions.
[ Virtual ]
[ Virtual ]
Reliably predicting the products of chemical reactions presents a fundamental challenge in synthetic chemistry. Existing machine learning approaches typically produce a reaction product by sequentially forming its subparts or intermediate molecules. Such autoregressive methods, however, not only require a pre-defined order for the incremental construction but preclude the use of parallel decoding for efficient computation. To address these issues, we devise a non-autoregressive learning paradigm that predicts reaction in one shot. Leveraging the fact that chemical reactions can be described as a redistribution of electrons in molecules, we formulate a reaction as an arbitrary electron flow and predict it with a novel multi-pointer decoding network. Experiments on the USPTO-MIT dataset show that our approach has established a new state-of-the-art top-1 accuracy and achieves at least 27 times inference speedup over the state-of-the-art methods. Also, our predictions are easier for chemists to interpret owing to predicting the electron flows.
[ Virtual ]
[ Virtual ]
We provide a unifying view of a large family of previous imitation learning algorithms through the lens of moment matching. At its core, our classification scheme is based on whether the learner attempts to match (1) reward or (2) action-value moments of the expert's behavior, with each option leading to differing algorithmic approaches. By considering adversarially chosen divergences between learner and expert behavior, we are able to derive bounds on policy performance that apply for all algorithms in each of these classes, the first to our knowledge. We also introduce the notion of moment recoverability, implicit in many previous analyses of imitation learning, which allows us to cleanly delineate how well each algorithmic family is able to mitigate compounding errors. We derive three novel algorithm templates (AdVIL, AdRIL, and DAeQuIL) with strong guarantees, simple implementation, and competitive empirical performance.
[ Virtual ]
[ Virtual ]
Neural networks trained via gradient descent with random initialization and without any regularization enjoy good generalization performance in practice despite being highly overparametrized. A promising direction to explain this phenomenon is to study how initialization and overparametrization affect convergence and implicit bias of training algorithms. In this paper, we present a novel analysis of single-hidden-layer linear networks trained under gradient flow, which connects initialization, optimization, and overparametrization. Firstly, we show that the squared loss converges exponentially to its optimum at a rate that depends on the level of imbalance of the initialization. Secondly, we show that proper initialization constrains the dynamics of the network parameters to lie within an invariant set. In turn, minimizing the loss over this set leads to the min-norm solution. Finally, we show that large hidden layer width, together with (properly scaled) random initialization, ensures proximity to such an invariant set during training, allowing us to derive a novel non-asymptotic upper-bound on the distance between the trained network and the min-norm solution.
[ Virtual ]
[ Virtual ]
We consider learning to optimize a classification metric defined by a black-box function of the confusion matrix. Such black-box learning settings are ubiquitous, for example, when the learner only has query access to the metric of interest, or in noisy-label and domain adaptation applications where the learner must evaluate the metric via performance evaluation using a small validation sample. Our approach is to adaptively learn example weights on the training dataset such that the resulting weighted objective best approximates the metric on the validation sample. We show how to model and estimate the example weights and use them to iteratively post-shift a pre-trained class probability estimator to construct a classifier. We also analyze the resulting procedure's statistical properties. Experiments on various label noise, domain shift, and fair classification setups confirm that our proposal compares favorably to the state-of-the-art baselines for each application.
[ Virtual ]
We tackle the problem of conditioning probabilistic programs on distributions of observable variables. Probabilistic programs are usually conditioned on samples from the joint data distribution, which we refer to as deterministic conditioning. However, in many real-life scenarios, the observations are given as marginal distributions, summary statistics, or samplers. Conventional probabilistic programming systems lack adequate means for modeling and inference in such scenarios. We propose a generalization of deterministic conditioning to stochastic conditioning, that is, conditioning on the marginal distribution of a variable taking a particular form. To this end, we first define the formal notion of stochastic conditioning and discuss its key properties. We then show how to perform inference in the presence of stochastic conditioning. We demonstrate potential usage of stochastic conditioning on several case studies which involve various kinds of stochastic conditioning and are difficult to solve otherwise. Although we present stochastic conditioning in the context of probabilistic programming, our formalization is general and applicable to other settings.
[ Virtual ]
[ Virtual ]
Online allocation problems with resource constraints have a rich history in computer science and operations research. In this paper, we introduce the regularized online allocation problem, a variant that includes a non-linear regularizer acting on the total resource consumption. In this problem, requests repeatedly arrive over time and, for each request, a decision maker needs to take an action that generates a reward and consumes resources. The objective is to simultaneously maximize total rewards and the value of the regularizer subject to the resource constraints. Our primary motivation is the online allocation of internet advertisements wherein firms seek to maximize additive objectives such as the revenue or efficiency of the allocation. By introducing a regularizer, firms can account for the fairness of the allocation or, alternatively, punish under-delivery of advertisements---two common desiderata in internet advertising markets. We design an algorithm when arrivals are drawn independently from a distribution that is unknown to the decision maker. Our algorithm is simple, fast, and attains the optimal order of sub-linear regret compared to the optimal allocation with the benefit of hindsight. Numerical experiments confirm the effectiveness of the proposed algorithm and of the regularizers in an internet advertising application.
[ Virtual ]
We study exploration in stochastic multi-armed bandits when we have access to a divisible resource that can be allocated in varying amounts to arm pulls. We focus in particular on the allocation of distributed computing resources, where we may obtain results faster by allocating more resources per pull, but might have reduced throughput due to nonlinear scaling. For example, in simulation-based scientific studies, an expensive simulation can be sped up by running it on multiple cores. This speed-up however, is partly offset by the communication among cores, which results in lower throughput than if fewer cores were allocated to run more trials in parallel. In this paper, we explore these trade-offs in two settings. First, in a fixed confidence setting, we need to find the best arm with a given target success probability as quickly as possible. We propose an algorithm which trades off between information accumulation and throughput and show that the time taken can be upper bounded by the solution of a dynamic program whose inputs are the gaps between the sub-optimal and optimal arms. We also prove a matching hardness result. Second, we present an algorithm for a fixed deadline setting, where we are given a time …
[ Virtual ]
Spatio-temporal forecasting has numerous applications in analyzing wireless, traffic, and financial networks. Many classical statistical models often fall short in handling the complexity and high non-linearity present in time-series data. Recent advances in deep learning allow for better modelling of spatial and temporal dependencies. While most of these models focus on obtaining accurate point forecasts, they do not characterize the prediction uncertainty. In this work, we consider the time-series data as a random realization from a nonlinear state-space model and target Bayesian inference of the hidden states for probabilistic forecasting. We use particle flow as the tool for approximating the posterior distribution of the states, as it is shown to be highly effective in complex, high-dimensional settings. Thorough experimentation on several real world time-series datasets demonstrates that our approach provides better characterization of uncertainty while maintaining comparable accuracy to the state-of-the-art point forecasting methods.
[ Virtual ]
Many sequential decision problems involve finding a policy that maximizes total reward while obeying safety constraints. Although much recent research has focused on the development of safe reinforcement learning (RL) algorithms that produce a safe policy after training, ensuring safety during training as well remains an open problem. A fundamental challenge is performing exploration while still satisfying constraints in an unknown Markov decision process (MDP). In this work, we address this problem for the chance-constrained setting.We propose a new algorithm, SAILR, that uses an intervention mechanism based on advantage functions to keep the agent safe throughout training and optimizes the agent's policy using off-the-shelf RL algorithms designed for unconstrained MDPs. Our method comes with strong guarantees on safety during "both" training and deployment (i.e., after training and without the intervention mechanism) and policy performance compared to the optimal safety-constrained policy. In our experiments, we show that SAILR violates constraints far less during training than standard safe RL and constrained MDP approaches and converges to a well-performing policy that can be deployed safely without intervention. Our code is available at https://github.com/nolanwagener/safe_rl.
[ Virtual ]
Smooth dynamics interrupted by discontinuities are known as hybrid systems and arise commonly in nature. Latent ODEs allow for powerful representation of irregularly sampled time series but are not designed to capture trajectories arising from hybrid systems. Here, we propose the Latent Segmented ODE (LatSegODE), which uses Latent ODEs to perform reconstruction and changepoint detection within hybrid trajectories featuring jump discontinuities and switching dynamical modes. Where it is possible to train a Latent ODE on the smooth dynamical flows between discontinuities, we apply the pruned exact linear time (PELT) algorithm to detect changepoints where latent dynamics restart, thereby maximizing the joint probability of a piece-wise continuous latent dynamical representation. We propose usage of the marginal likelihood as a score function for PELT, circumventing the need for model-complexity-based penalization. The LatSegODE outperforms baselines in reconstructive and segmentation tasks including synthetic data sets of sine waves, Lotka Volterra dynamics, and UCI Character Trajectories.
[ Virtual ]
[ Virtual ]
There has been recently a significant boost to machine learning with distributed data, in particular with the success of federated learning. A common and very challenging setting is that of vertical or feature partitioned data, when multiple data providers hold different features about common entities. In general, training needs to be preceded by record linkage (RL), a step that finds the correspondence between the observations of the datasets. RL is prone to mistakes in the real world. Despite the importance of the problem, there has been so far no formal assessment of the way in which RL errors impact learning models. Work in the area either use heuristics or assume that the optimal RL is known in advance. In this paper, we provide the first assessment of the problem for supervised learning. For wide sets of losses, we provide technical conditions under which the classifier learned after noisy RL converges (with the data size) to the best classifier that would be learned from mistake-free RL. This yields new insights on the way the pipeline RL + ML operates, from the role of large margin classification on dampening the impact of RL mistakes to clues on how to further optimize RL …
[ Virtual ]
Despite their overwhelming capacity to overfit, deep neural networks trained by specific optimization algorithms tend to generalize relatively well to unseen data. Recently, researchers explained it by investigating the implicit bias of optimization algorithms. A remarkable progress is the work (Lyu & Li, 2019), which proves gradient descent (GD) maximizes the margin of homogeneous deep neural networks. Except the first-order optimization algorithms like GD, adaptive algorithms such as AdaGrad, RMSProp and Adam are popular owing to their rapid training process. Mean-while, numerous works have provided empirical evidence that adaptive methods may suffer from poor generalization performance. However, theoretical explanation for the generalization of adaptive optimization algorithms is still lacking. In this paper, we study the implicit bias of adaptive optimization algorithms on homogeneous neural networks. In particular, we study the convergent direction of parameters when they are optimizing the logistic loss. We prove that the convergent direction of Adam and RMSProp is the same as GD, while for AdaGrad, the convergent direction depends on the adaptive conditioner. Technically, we provide a unified framework to analyze convergent direction of adaptive optimization algorithms by constructing novel and nontrivial adaptive gradient flow and surrogate margin. The theoretical findings explain the superiority on generalization …
[ Virtual ]
[ Virtual ]
The success of minimax learning problems of generative adversarial networks (GANs) has been observed to depend on the minimax optimization algorithm used for their training. This dependence is commonly attributed to the convergence speed and robustness properties of the underlying optimization algorithm. In this paper, we show that the optimization algorithm also plays a key role in the generalization performance of the trained minimax model. To this end, we analyze the generalization properties of standard gradient descent ascent (GDA) and proximal point method (PPM) algorithms through the lens of algorithmic stability as defined by Bousquet & Elisseeff, 2002 under both convex-concave and nonconvex-nonconcave minimax settings. While the GDA algorithm is not guaranteed to have a vanishing excess risk in convex-concave problems, we show the PPM algorithm enjoys a bounded excess risk in the same setup. For nonconvex-nonconcave problems, we compare the generalization performance of stochastic GDA and GDmax algorithms where the latter fully solves the maximization subproblem at every iteration. Our generalization analysis suggests the superiority of GDA provided that the minimization and maximization subproblems are solved simultaneously with similar learning rates. We discuss several numerical results indicating the role of optimization algorithms in the generalization of learned minimax models.
[ Virtual ]

A discriminatively trained neural net classifier can fit the training data perfectly if all information about its input other than class membership has been discarded prior to the output layer. Surprisingly, past research has discovered that some extraneous visual detail remains in the unnormalized logits. This finding is based on inversion techniques that map deep embeddings back to images. We explore this phenomenon further using a novel synthesis of methods, yielding a feedforward inversion model that produces remarkably high fidelity reconstructions, qualitatively superior to those of past efforts. When applied to an adversarially robust classifier model, the reconstructions contain sufficient local detail and global structure that they might be confused with the original image in a quick glance, and the object category can clearly be gleaned from the reconstruction. Our approach is based on BigGAN (Brock, 2019), with conditioning on logits instead of one-hot class labels. We use our reconstruction model as a tool for exploring the nature of representations, including: the influence of model architecture and training objectives (specifically robust losses), the forms of invariance that networks achieve, representational differences between correctly and incorrectly classified images, and the effects of manipulating logits and images. We believe that our method …
[ Virtual ]
32% of all global deaths in the world are caused by cardiovascular diseases. Early detection, especially for patients with ischemia or cardiac arrhythmia, is crucial. To reduce the time between symptoms onset and treatment, wearable ECG sensors were developed to allow for the recording of the full 12-lead ECG signal at home. However, if even a single lead is not correctly positioned on the body that lead becomes corrupted, making automatic diagnosis on the basis of the full signal impossible. In this work, we present a methodology to reconstruct missing or noisy leads using the theory of Koopman Operators. Given a dataset consisting of full 12-lead ECGs, we learn a dynamical system describing the evolution of the 12 individual signals together in time. The Koopman theory indicates that there exists a high-dimensional embedding space in which the operator which propagates from one time instant to the next is linear. We therefore learn both the mapping to this embedding space, as well as the corresponding linear operator. Armed with this representation, we are able to impute missing leads by solving a least squares system in the embedding space, which can be achieved efficiently due to the sparse structure of the system. …
Feedforward computation, such as evaluating a neural network or sampling from an autoregressive model, is ubiquitous in machine learning. The sequential nature of feedforward computation, however, requires a strict order of execution and cannot be easily accelerated with parallel computing. To enable parallelization, we frame the task of feedforward computation as solving a system of nonlinear equations. We then propose to find the solution using a Jacobi or Gauss-Seidel fixed-point iteration method, as well as hybrid methods of both. Crucially, Jacobi updates operate independently on each equation and can be executed in parallel. Our method is guaranteed to give exactly the same values as the original feedforward computation with a reduced (or equal) number of parallelizable iterations, and hence reduced time given sufficient parallel computing power. Experimentally, we demonstrate the effectiveness of our approach in accelerating (i) backpropagation of RNNs, (ii) evaluation of DenseNets, and (iii) autoregressive sampling of MADE and PixelCNN++, with speedup factors between 2.1 and 26 under various settings.
For machine learning systems to be reliable, we must understand their performance in unseen, out- of-distribution environments. In this paper, we empirically show that out-of-distribution performance is strongly correlated with in-distribution performance for a wide range of models and distribution shifts. Specifically, we demonstrate strong correlations between in-distribution and out-of- distribution performance on variants of CIFAR- 10 & ImageNet, a synthetic pose estimation task derived from YCB objects, FMoW-WILDS satellite imagery classification, and wildlife classification in iWildCam-WILDS. The correlation holds across model architectures, hyperparameters, training set size, and training duration, and is more precise than what is expected from existing domain adaptation theory. To complete the picture, we also investigate cases where the correlation is weaker, for instance some synthetic distribution shifts from CIFAR-10-C and the tissue classification dataset Camelyon17-WILDS. Finally, we provide a candidate theory based on a Gaussian data model that shows how changes in the data covariance arising from distribution shift can affect the observed correlations.
A common workflow in single-cell RNA-seq analysis is to project the data to a latent space, cluster the cells in that space, and identify sets of marker genes that explain the differences among the discovered clusters. A primary drawback to this three-step procedure is that each step is carried out independently, thereby neglecting the effects of the nonlinear embedding and inter-gene dependencies on the selection of marker genes. Here we propose an integrated deep learning framework, Adversarial Clustering Explanation (ACE), that bundles all three steps into a single workflow. The method thus moves away from the notion of "marker genes" to instead identify a panel of explanatory genes. This panel may include genes that are not only enriched but also depleted relative to other cell types, as well as genes that exhibit differences between closely related cell types. Empirically, we demonstrate that ACE is able to identify gene panels that are both highly discriminative and nonredundant, and we demonstrate the applicability of ACE to an image recognition task.
In this work, we develop linear bandit algorithms that automatically adapt to different environments. By plugging a novel loss estimator into the optimization problem that characterizes the instance-optimal strategy, our first algorithm not only achieves nearly instance-optimal regret in stochastic environments, but also works in corrupted environments with additional regret being the amount of corruption, while the state-of-the-art (Li et al., 2019) achieves neither instance-optimality nor the optimal dependence on the corruption amount. Moreover, by equipping this algorithm with an adversarial component and carefully-designed testings, our second algorithm additionally enjoys minimax-optimal regret in completely adversarial environments, which is the first of this kind to our knowledge. Finally, all our guarantees hold with high probability, while existing instance-optimal guarantees only hold in expectation.
Computationally efficient contextual bandits are often based on estimating a predictive model of rewards given contexts and arms using past data. However, when the reward model is not well-specified, the bandit algorithm may incur unexpected regret, so recent work has focused on algorithms that are robust to misspecification. We propose a simple family of contextual bandit algorithms that adapt to misspecification error by reverting to a good safe policy when there is evidence that misspecification is causing a regret increase. Our algorithm requires only an offline regression oracle to ensure regret guarantees that gracefully degrade in terms of a measure of the average misspecification level. Compared to prior work, we attain similar regret guarantees, but we do no rely on a master algorithm, and do not require more robust oracles like online or constrained regression oracles (e.g., Foster et al. (2020), Krishnamurthy et al. (2020)). This allows us to design algorithms for more general function approximation classes.
In real-world applications, data often come in a growing manner, where the data volume and the number of classes may increase dynamically. This will bring a critical challenge for learning: given the increasing data volume or the number of classes, one has to instantaneously adjust the neural model capacity to obtain promising performance. Existing methods either ignore the growing nature of data or seek to independently search an optimal architecture for a given dataset, and thus are incapable of promptly adjusting the architectures for the changed data. To address this, we present a neural architecture adaptation method, namely Adaptation eXpert (AdaXpert), to efficiently adjust previous architectures on the growing data. Specifically, we introduce an architecture adjuster to generate a suitable architecture for each data snapshot, based on the previous architecture and the different extent between current and previous data distributions. Furthermore, we propose an adaptation condition to determine the necessity of adjustment, thereby avoiding unnecessary and time-consuming adjustments. Extensive experiments on two growth scenarios (increasing data volume and number of classes) demonstrate the effectiveness of the proposed method.
A landmark challenge for AI is to learn flexible, powerful representations from small numbers of examples. On an important class of tasks, hypotheses in the form of programs provide extreme generalization capabilities from surprisingly few examples. However, whereas large natural few-shot learning image benchmarks have spurred progress in meta-learning for deep networks, there is no comparably big, natural program-synthesis dataset that can play a similar role. This is because, whereas images are relatively easy to label from internet meta-data or annotated by non-experts, generating meaningful input-output examples for program induction has proven hard to scale. In this work, we propose a new way of leveraging unit tests and natural inputs for small programs as meaningful input-output examples for each sub-program of the overall program. This allows us to create a large-scale naturalistic few-shot program-induction benchmark and propose new challenges in this domain. The evaluation of multiple program induction and synthesis algorithms points to shortcomings of current methods and suggests multiple avenues for future work.
In batched multi-armed bandit problems, the learner can adaptively pull arms and adjust strategy in batches. In many real applications, not only the regret but also the batch complexity need to be optimized. Existing batched bandit algorithms usually assume that the time horizon T is known in advance. However, many applications involve an unpredictable stopping time. In this paper, we study the anytime batched multi-armed bandit problem. We propose an anytime algorithm that achieves the asymptotically optimal regret for exponential families of reward distributions with O(\log \log T \ilog^{\alpha} (T)) \footnote{Notation \ilog^{\alpha} (T) is the result of iteratively applying the logarithm function on T for \alpha times, e.g., \ilog^{3} (T)=\log\log\log T.} batches, where $\alpha\in O_{T}(1). Moreover, we prove that for any constant c>0, no algorithm can achieve the asymptotically optimal regret within c\log\log T batches.
When reasoning about strategic behavior in a machine learning context it is tempting to combine standard microfoundations of rational agents with the statistical decision theory underlying classification. In this work, we argue that a direct combination of these ingredients leads to brittle solution concepts of limited descriptive and prescriptive value. First, we show that rational agents with perfect information produce discontinuities in the aggregate response to a decision rule that we often do not observe empirically. Second, when any positive fraction of agents is not perfectly strategic, desirable stable points---where the classifier is optimal for the data it entails---no longer exist. Third, optimal decision rules under standard microfoundations maximize a measure of negative externality known as social burden within a broad class of assumptions about agent behavior. Recognizing these limitations we explore alternatives to standard microfoundations for binary classification. We describe desiderata that help navigate the space of possible assumptions about agent responses, and we then propose the noisy response model. Inspired by smoothed analysis and empirical observations, noisy response incorporates imperfection in the agent responses, which we show mitigates the limitations of standard microfoundations. Our model retains analytical tractability, leads to more robust insights about stable points, and imposes …
Structured output prediction problems (e.g., sequential tagging, hierarchical multi-class classification) often involve constraints over the output space. These constraints interact with the learned models to filter infeasible solutions and facilitate in building an accountable system. However, despite constraints are useful, they are often based on hand-crafted rules. This raises a question -- can we mine constraints and rules from data based on a learning algorithm?
In this paper, we present a general framework for mining constraints from data. In particular, we consider the inference in structured output prediction as an integer linear programming (ILP) problem. Then, given the coefficients of the objective function and the corresponding solution, we mine the underlying constraints by estimating the outer and inner polytopes of the feasible set. We verify the proposed constraint mining algorithm in various synthetic and real-world applications and demonstrate that the proposed approach successfully identifies the feasible set at scale.
In particular, we show that our approach can learn to solve 9x9 Sudoku puzzles and minimal spanning tree problems from examples without providing the underlying rules. Our algorithm can also integrate with a neural network model to learn the hierarchical label structure of a multi-label classification task. Besides, we provide theoretical …0-1 knapsack is of fundamental importance across many fields. In this paper, we present a game-theoretic method to solve 0-1 knapsack problems (KPs) where the number of items (products) is large and the values of items are not predetermined but decided by an external value assignment function (e.g., a neural network in our case) during the optimization process. While existing papers are interested in predicting solutions with neural networks for classical KPs whose objective functions are mostly linear functions, we are interested in solving KPs whose objective functions are neural networks. In other words, we choose a subset of items that maximize the sum of the values predicted by neural networks. Its key challenge is how to optimize the neural network-based non-linear KP objective with a budget constraint. Our solution is inspired by game-theoretic approaches in deep learning, e.g., generative adversarial networks. After formally defining our two-player game, we develop an adaptive gradient ascent method to solve it. In our experiments, our method successfully solves two neural network-based non-linear KPs and conventional linear KPs with 1 million items.
We study the approximation properties of convolutional architectures applied to time series modelling, which can be formulated mathematically as a functional approximation problem. In the recurrent setting, recent results reveal an intricate connection between approximation efficiency and memory structures in the data generation process. In this paper, we derive parallel results for convolutional architectures, with WaveNet being a prime example. Our results reveal that in this new setting, approximation efficiency is not only characterised by memory, but also additional fine structures in the target relationship. This leads to a novel definition of spectrum-based regularity that measures the complexity of temporal relationships under the convolutional approximation scheme. These analyses provide a foundation to understand the differences between architectural choices for time series modelling and can give theoretically grounded guidance for practical applications.
Gaussian noise injections (GNIs) are a family of simple and widely-used regularisation methods for training neural networks, where one injects additive or multiplicative Gaussian noise to the network activations at every iteration of the optimisation algorithm, which is typically chosen as stochastic gradient descent (SGD). In this paper, we focus on the so-called implicit effect' of GNIs, which is the effect of the injected noise on the dynamics of SGD. We show that this effect induces an \emph{asymmetric heavy-tailed noise} on SGD gradient updates. In order to model this modified dynamics, we first develop a Langevin-like stochastic differential equation that is driven by a general family of \emph{asymmetric} heavy-tailed noise. Using this model we then formally prove that GNIs induce animplicit bias', which varies depending on the heaviness of the tails and the level of asymmetry. Our empirical results confirm that different types of neural networks trained with GNIs are well-modelled by the proposed dynamics and that the implicit effect of these injections induces a bias that degrades the performance of networks.
This paper quantifies the uncertainty of prediction risk for the min-norm least squares estimator in high-dimensional linear regression models. We establish the asymptotic normality of prediction risk when both the sample size and the number of features tend to infinity. Based on the newly established central limit theorems(CLTs), we derive the confidence intervals of the prediction risk under various scenarios. Our results demonstrate the sample-wise non-monotonicity of the prediction risk and confirm ``more data hurt" phenomenon. Furthermore, the width of confidence intervals indicates that over-parameterization would enlarge the randomness of prediction performance.
Understanding generalization and estimation error of estimators for simple models such as linear and generalized linear models has attracted a lot of attention recently. This is in part due to an interesting observation made in machine learning community that highly over-parameterized neural networks achieve zero training error, and yet they are able to generalize well over the test samples. This phenomenon is captured by the so called double descent curve, where the generalization error starts decreasing again after the interpolation threshold. A series of recent works tried to explain such phenomenon for simple models. In this work, we analyze the asymptotics of estimation error in ridge estimators for convolutional linear models. These convolutional inverse problems, also known as deconvolution, naturally arise in different fields such as seismology, imaging, and acoustics among others. Our results hold for a large class of input distributions that include i.i.d. features as a special case. We derive exact formulae for estimation error of ridge estimators that hold in a certain high-dimensional regime. We show the double descent phenomenon in our experiments for convolutional models and show that our theoretical results match the experiments.
The performance of neural networks depends on precise relationships between four distinct ingredients: the architecture, the loss function, the statistical structure of inputs, and the ground truth target function.
Much theoretical work has focused on understanding the role of the first two ingredients under highly simplified models of random uncorrelated data and target functions.
In contrast, performance likely relies on a conspiracy between the statistical structure of the input distribution and the structure of the function to be learned.
To understand this better we revisit ridge regression in high dimensions, which corresponds to an exceedingly simple architecture and loss function, but we analyze its performance under arbitrary correlations between input features and the target function.
We find a rich mathematical structure that includes: (1) a dramatic reduction in sample complexity when the target function aligns with data anisotropy; (2) the existence of multiple descent curves; (3) a sequence of phase transitions in the performance, loss landscape, and optimal regularization as a function of the amount of data that explains the first two effects.
We introduce a new graphical bilinear bandit problem where a learner (or a \emph{central entity}) allocates arms to the nodes of a graph and observes for each edge a noisy bilinear reward representing the interaction between the two end nodes. We study the best arm identification problem in which the learner wants to find the graph allocation maximizing the sum of the bilinear rewards. By efficiently exploiting the geometry of this bandit problem, we propose a \emph{decentralized} allocation strategy based on random sampling with theoretical guarantees. In particular, we characterize the influence of the graph structure (e.g. star, complete or circle) on the convergence rate and propose empirical experiments that confirm this dependency.

We consider repair tasks: given a critic (e.g., compiler) that assesses the quality of an input, the goal is to train a fixer that converts a bad example (e.g., code with syntax errors) into a good one (e.g., code with no errors). Existing works create training data consisting of (bad, good) pairs by corrupting good examples using heuristics (e.g., dropping tokens). However, fixers trained on this synthetically-generated data do not extrapolate well to the real distribution of bad inputs. To bridge this gap, we propose a new training approach, Break-It-Fix-It (BIFI), which has two key ideas: (i) we use the critic to check a fixer's output on real bad inputs and add good (fixed) outputs to the training data, and (ii) we train a breaker to generate realistic bad code from good code. Based on these ideas, we iteratively update the breaker and the fixer while using them in conjunction to generate more paired data. We evaluate BIFI on two code repair datasets: GitHub-Python, a new dataset we introduce where the goal is to repair Python code with AST parse errors; and DeepFix, where the goal is to repair C code with compiler errors. BIFI outperforms existing methods, obtaining 90.5% …
Can models with particular structure avoid being biased towards spurious correlation in out-of-distribution (OOD) generalization? Peters et al. (2016) provides a positive answer for linear cases. In this paper, we use a functional modular probing method to analyze deep model structures under OOD setting. We demonstrate that even in biased models (which focus on spurious correlation) there still exist unbiased functional subnetworks. Furthermore, we articulate and confirm the functional lottery ticket hypothesis: the full network contains a subnetwork with proper structure that can achieve better OOD performance. We then propose Modular Risk Minimization to solve the subnetwork selection problem. Our algorithm learns the functional structure from a given dataset, and can be combined with any other OOD regularization methods. Experiments on various OOD generalization tasks corroborate the effectiveness of our method.
The early phase of training a deep neural network has a dramatic effect on the local curvature of the loss function. For instance, using a small learning rate does not guarantee stable optimization because the optimization trajectory has a tendency to steer towards regions of the loss surface with increasing local curvature. We ask whether this tendency is connected to the widely observed phenomenon that the choice of the learning rate strongly influences generalization. We first show that stochastic gradient descent (SGD) implicitly penalizes the trace of the Fisher Information Matrix (FIM), a measure of the local curvature, from the start of training. We argue it is an implicit regularizer in SGD by showing that explicitly penalizing the trace of the FIM can significantly improve generalization. We highlight that poor final generalization coincides with the trace of the FIM attaining a large value early in training, to which we refer as catastrophic Fisher explosion. Finally, to gain insight into the regularization effect of penalizing the trace of the FIM, we show that it limits memorization by reducing the learning speed of examples with noisy labels more than that of the examples with clean labels.
Distributed computing has been a prominent solution to efficiently process massive datasets in parallel. However, the existence of stragglers is one of the major concerns that slows down the overall speed of distributed computing. To deal with this problem, we consider a distributed matrix multiplication scenario where a master assigns multiple tasks to each worker to exploit stragglers' computing ability (which is typically wasted in conventional distributed computing). We propose Chebyshev polynomial codes, which can achieve order-wise improvement in encoding complexity at the master and communication load in distributed matrix multiplication using task entanglement. The key idea of task entanglement is to reduce the number of encoded matrices for multiple tasks assigned to each worker by intertwining encoded matrices. We experimentally demonstrate that, in cloud environments, Chebyshev polynomial codes can provide significant reduction in overall processing time in distributed computing for matrix multiplication, which is a key computational component in modern deep learning.
Recent work has considered natural variations of the {\em multi-armed bandit} problem, where the reward distribution of each arm is a special function of the time passed since its last pulling. In this direction, a simple (yet widely applicable) model is that of {\em blocking bandits}, where an arm becomes unavailable for a deterministic number of rounds after each play. In this work, we extend the above model in two directions: (i) We consider the general combinatorial setting where more than one arms can be played at each round, subject to feasibility constraints. (ii) We allow the blocking time of each arm to be stochastic. We first study the computational/unconditional hardness of the above setting and identify the necessary conditions for the problem to become tractable (even in an approximate sense). Based on these conditions, we provide a tight analysis of the approximation guarantee of a natural greedy heuristic that always plays the maximum expected reward feasible subset among the available (non-blocked) arms. When the arms' expected rewards are unknown, we adapt the above heuristic into a bandit algorithm, based on UCB, for which we provide sublinear (approximate) regret guarantees, matching the theoretical lower bounds in the limiting case of …
A core element in decision-making under uncertainty is the feedback on the quality of the performed actions. However, in many applications, such feedback is restricted. For example, in recommendation systems, repeatedly asking the user to provide feedback on the quality of recommendations will annoy them. In this work, we formalize decision-making problems with querying budget, where there is a (possibly time-dependent) hard limit on the number of reward queries allowed. Specifically, we focus on multi-armed bandits, linear contextual bandits, and reinforcement learning problems. We start by analyzing the performance of `greedy' algorithms that query a reward whenever they can. We show that in fully stochastic settings, doing so performs surprisingly well, but in the presence of any adversity, this might lead to linear regret. To overcome this issue, we propose the Confidence-Budget Matching (CBM) principle that queries rewards when the confidence intervals are wider than the inverse square root of the available budget. We analyze the performance of CBM based algorithms in different settings and show that it performs well in the presence of adversity in the contexts, initial states, and budgets.
We develop a method to construct distribution-free prediction intervals for dynamic time-series, called \Verb|EnbPI| that wraps around any bootstrap ensemble estimator to construct sequential prediction intervals. \Verb|EnbPI| is closely related to the conformal prediction (CP) framework but does not require data exchangeability. Theoretically, these intervals attain finite-sample, \textit{approximately valid} marginal coverage for broad classes of regression functions and time-series with strongly mixing stochastic errors. Computationally, \Verb|EnbPI| avoids overfitting and requires neither data-splitting nor training multiple ensemble estimators; it efficiently aggregates bootstrap estimators that have been trained. In general, \Verb|EnbPI| is easy to implement, scalable to producing arbitrarily many prediction intervals sequentially, and well-suited to a wide range of regression functions. We perform extensive real-data analyses to demonstrate its effectiveness.
Decentralized training of deep learning models enables on-device learning over networks, as well as efficient scaling to large compute clusters. Experiments in earlier works reveal that, even in a data-center setup, decentralized training often suffers from the degradation in the quality of the model: the training and test performance of models trained in a decentralized fashion is in general worse than that of models trained in a centralized fashion, and this performance drop is impacted by parameters such as network size, communication topology and data partitioning. We identify the changing consensus distance between devices as a key parameter to explain the gap between centralized and decentralized training. We show in theory that when the training consensus distance is lower than a critical quantity, decentralized training converges as fast as the centralized counterpart. We empirically validate that the relation between generalization performance and consensus distance is consistent with this theoretical observation. Our empirical insights allow the principled design of better decentralized training schemes that mitigate the performance drop. To this end, we provide practical training guidelines and exemplify its effectiveness on the data-center setup as the important first step.
Multivariate Hawkes processes (MHPs) are widely used in a variety of fields to model the occurrence of causally related discrete events in continuous time. Most state-of-the-art approaches address the problem of learning MHPs from perfect traces without noise. In practice, the process through which events are collected might introduce noise in the timestamps. In this work, we address the problem of learning the causal structure of MHPs when the observed timestamps of events are subject to random and unknown shifts, also known as random translations. We prove that the cumulants of MHPs are invariant to random translations, and therefore can be used to learn their underlying causal structure. Furthermore, we empirically characterize the effect of random translations on state-of-the-art learning methods. We show that maximum likelihood-based estimators are brittle, while cumulant-based estimators remain stable even in the presence of significant time shifts.
Deep learning for graph matching (GM) has emerged as an important research topic due to its superior performance over traditional methods and insights it provides for solving other combinatorial problems on graph. While recent deep methods for GM extensively investigated effective node/edge feature learning or downstream GM solvers given such learned features, there is little existing work questioning if the fixed connectivity/topology typically constructed using heuristics (e.g., Delaunay or k-nearest) is indeed suitable for GM. From a learning perspective, we argue that the fixed topology may restrict the model capacity and thus potentially hinder the performance. To address this, we propose to learn the (distribution of) latent topology, which can better support the downstream GM task. We devise two latent graph generation procedures, one deterministic and one generative. Particularly, the generative procedure emphasizes the across-graph consistency and thus can be viewed as a matching-guided co-generative model. Our methods deliver superior performance over previous state-of-the-arts on public benchmarks, hence supporting our hypothesis.
Diffusion source identification on networks is a problem of fundamental importance in a broad class of applications, including controlling the spreading of rumors on social media, identifying a computer virus over cyber networks, or identifying the disease center during epidemiology. Though this problem has received significant recent attention, most known approaches are well-studied in only very restrictive settings and lack theoretical guarantees for more realistic networks. We introduce a statistical framework for the study of this problem and develop a confidence set inference approach inspired by hypothesis testing. Our method efficiently produces a small subset of nodes, which provably covers the source node with any pre-specified confidence level without restrictive assumptions on network structures. To our knowledge, this is the first diffusion source identification method with a practically useful theoretical guarantee on general networks. We demonstrate our approach via extensive synthetic experiments on well-known random network models, a large data set of real-world networks as well as a mobility network between cities concerning the COVID-19 spreading in January 2020.
Incorporating graph side information into recommender systems has been widely used to better predict ratings, but relatively few works have focused on theoretical guarantees. Ahn et al. (2018) firstly characterized the optimal sample complexity in the presence of graph side information, but the results are limited due to strict, unrealistic assumptions made on the unknown latent preference matrix and the structure of user clusters. In this work, we propose a new model in which 1) the unknown latent preference matrix can have any discrete values, and 2) users can be clustered into multiple clusters, thereby relaxing the assumptions made in prior work. Under this new model, we fully characterize the optimal sample complexity and develop a computationally-efficient algorithm that matches the optimal sample complexity. Our algorithm is robust to model errors and outperforms the existing algorithms in terms of prediction performance on both synthetic and real data.
In this paper, we introduce a new perspective on training deep neural networks capable of state-of-the-art performance without the need for the expensive over-parameterization by proposing the concept of In-Time Over-Parameterization (ITOP) in sparse training. By starting from a random sparse network and continuously exploring sparse connectivities during training, we can perform an Over-Parameterization over the course of training, closing the gap in the expressibility between sparse training and dense training. We further use ITOP to understand the underlying mechanism of Dynamic Sparse Training (DST) and discover that the benefits of DST come from its ability to consider across time all possible parameters when searching for the optimal sparse connectivity. As long as sufficient parameters have been reliably explored, DST can outperform the dense neural network by a large margin. We present a series of experiments to support our conjecture and achieve the state-of-the-art sparse training performance with ResNet-50 on ImageNet. More impressively, ITOP achieves dominant performance over the overparameterization-based sparse methods at extreme sparsities. When trained with ResNet-34 on CIFAR-100, ITOP can match the performance of the dense model at an extreme sparsity 98%.
We propose a framework for model selection by combining base algorithms in stochastic bandits and reinforcement learning. We require a candidate regret bound for each base algorithm that may or may not hold. We select base algorithms to play in each round using a ``balancing condition'' on the candidate regret bounds. Our approach simultaneously recovers previous worst-case regret bounds, while also obtaining much smaller regret in natural scenarios when some base learners significantly exceed their candidate bounds. Our framework is relevant in many settings, including linear bandits and MDPs with nested function classes, linear bandits with unknown misspecification, and tuning confidence parameters of algorithms such as LinUCB. Moreover, unlike recent efforts in model selection for linear stochastic bandits, our approach can be extended to consider adversarial rather than stochastic contexts.
This paper presents a novel approach for hierarchical time series forecasting that produces coherent, probabilistic forecasts without requiring any explicit post-processing reconciliation. Unlike the state-of-the-art, the proposed method simultaneously learns from all time series in the hierarchy and incorporates the reconciliation step into a single trainable model. This is achieved by applying the reparameterization trick and casting reconciliation as an optimization problem with a closed-form solution. These model features make end-to-end learning of hierarchical forecasts possible, while accomplishing the challenging task of generating forecasts that are both probabilistic and coherent. Importantly, our approach also accommodates general aggregation constraints including grouped and temporal hierarchies. An extensive empirical evaluation on real-world hierarchical datasets demonstrates the advantages of the proposed approach over the state-of-the-art.
Several practical applications of reinforcement learning involve an agent learning from past data without the possibility of further exploration. Often these applications require us to 1) identify a near optimal policy or to 2) estimate the value of a target policy. For both tasks we derive exponential information-theoretic lower bounds in discounted infinite horizon MDPs with a linear function representation for the action value function even if 1) realizability holds, 2) the batch algorithm observes the exact reward and transition functions, and 3) the batch algorithm is given the best a priori data distribution for the problem class. Our work introduces a new `oracle + batch algorithm' framework to prove lower bounds that hold for every distribution. The work shows an exponential separation between batch and online reinforcement learning.
Federated Learning (FL) is an emerging learning scheme that allows different distributed clients to train deep neural networks together without data sharing. Neural networks have become popular due to their unprecedented success. To the best of our knowledge, the theoretical guarantees of FL concerning neural networks with explicit forms and multi-step updates are unexplored. Nevertheless, training analysis of neural networks in FL is non-trivial for two reasons: first, the objective loss function we are optimizing is non-smooth and non-convex, and second, we are even not updating in the gradient direction. Existing convergence results for gradient descent-based methods heavily rely on the fact that the gradient direction is used for updating. The current paper presents a new class of convergence analysis for FL, Federated Neural Tangent Kernel (FL-NTK), which corresponds to overparamterized ReLU neural networks trained by gradient descent in FL and is inspired by the analysis in Neural Tangent Kernel (NTK). Theoretically, FL-NTK converges to a global-optimal solution at a linear rate with properly tuned learning parameters. Furthermore, with proper distributional assumptions, FL-NTK can also achieve good generalization. The proposed theoretical analysis scheme can be generalized to more complex neural networks.
Designing novel protein sequences for a desired 3D topological fold is a fundamental yet non-trivial task in protein engineering. Challenges exist due to the complex sequence--fold relationship, as well as the difficulties to capture the diversity of the sequences (therefore structures and functions) within a fold. To overcome these challenges, we propose Fold2Seq, a novel transformer-based generative framework for designing protein sequences conditioned on a specific target fold. To model the complex sequence--structure relationship, Fold2Seq jointly learns a sequence embedding using a transformer and a fold embedding from the density of secondary structural elements in 3D voxels. On test sets with single, high-resolution and complete structure inputs for individual folds, our experiments demonstrate improved or comparable performance of Fold2Seq in terms of speed, coverage, and reliability for sequence design, when compared to existing state-of-the-art methods that include data-driven deep generative models and physics-based RosettaDesign. The unique advantages of fold-based Fold2Seq, in comparison to a structure-based deep model and RosettaDesign, become more evident on three additional real-world challenges originating from low-quality, incomplete, or ambiguous input structures. Source code and data are available at https://github.com/IBM/fold2seq.
The safe operation of physical systems typically relies on high-quality models. Since a continuous stream of data is generated during run-time, such models are often obtained through the application of Gaussian process regression because it provides guarantees on the prediction error. Due to its high computational complexity, Gaussian process regression must be used offline on batches of data, which prevents applications, where a fast adaptation through online learning is necessary to ensure safety. In order to overcome this issue, we propose the LoG-GP. It achieves a logarithmic update and prediction complexity in the number of training points through the aggregation of locally active Gaussian process models. Under weak assumptions on the aggregation scheme, it inherits safety guarantees from exact Gaussian process regression. These theoretical advantages are exemplarily exploited in the design of a safe and data-efficient, online-learning control policy. The efficiency and performance of the proposed real-time learning approach is demonstrated in a comparison to state-of-the-art methods.
Meta-learning aims to perform fast adaptation on a new task through learning a “prior” from multiple existing tasks. A common practice in meta-learning is to perform a train-validation split (\emph{train-val method}) where the prior adapts to the task on one split of the data, and the resulting predictor is evaluated on another split. Despite its prevalence, the importance of the train-validation split is not well understood either in theory or in practice, particularly in comparison to the more direct \emph{train-train method}, which uses all the per-task data for both training and evaluation.
We provide a detailed theoretical study on whether and when the train-validation split is helpful in the linear centroid meta-learning problem. In the agnostic case, we show that the expected loss of the train-val method is minimized at the optimal prior for meta testing, and this is not the case for the train-train method in general without structural assumptions on the data. In contrast, in the realizable case where the data are generated from linear models, we show that both the train-val and train-train losses are minimized at the optimal prior in expectation. Further, perhaps surprisingly, our main result shows that the train-train method achieves a \emph{strictly better} …
We present deep learning methods for the design of arrays and single instances of small antennas. Each design instance is conditioned on a target radiation pattern and is required to conform to specific spatial dimensions and to include, as part of its metallic structure, a set of predetermined locations. The solution, in the case of a single antenna, is based on a composite neural network that combines a simulation network, a hypernetwork, and a refinement network. In the design of the antenna array, we add an additional design level and employ a hypernetwork within a hypernetwork. The learning objective is based on measuring the similarity of the obtained radiation pattern to the desired one. Our experiments demonstrate that our approach is able to design novel antennas and antenna arrays that are compliant with the design requirements, considerably better than the baseline methods. We compare the solutions obtained by our method to existing designs and demonstrate a high level of overlap. When designing the antenna array of a cellular phone, the obtained solution displays improved properties over the existing one.
Recently, learning a model that generalizes well on out-of-distribution (OOD) data has attracted great attention in the machine learning community. In this paper, after defining OOD generalization by Wasserstein distance, we theoretically justify that a model robust to input perturbation also generalizes well on OOD data. Inspired by previous findings that adversarial training helps improve robustness, we show that models trained by adversarial training have converged excess risk on OOD data. Besides, in the paradigm of pre-training then fine-tuning, we theoretically justify that the input perturbation robust model in the pre-training stage provides an initialization that generalizes well on downstream OOD data. Finally, various experiments conducted on image classification and natural language understanding tasks verify our theoretical findings.
Game optimization has been extensively studied when decision variables lie in a finite-dimensional space, of which solutions correspond to pure strategies at the Nash equilibrium (NE), and the gradient descent-ascent (GDA) method works widely in practice. In this paper, we consider infinite-dimensional zero-sum games by a min-max distributional optimization problem over a space of probability measures defined on a continuous variable set, which is inspired by finding a mixed NE for finite-dimensional zero-sum games. We then aim to answer the following question: \textit{Will GDA-type algorithms still be provably efficient when extended to infinite-dimensional zero-sum games?} To answer this question, we propose a particle-based variational transport algorithm based on GDA in the functional spaces. Specifically, the algorithm performs multi-step functional gradient descent-ascent in the Wasserstein space via pushing two sets of particles in the variable space. By characterizing the gradient estimation error from variational form maximization and the convergence behavior of each player with different objective landscapes, we prove rigorously that the generalized GDA algorithm converges to the NE or the value of the game efficiently for a class of games under the Polyak-\L ojasiewicz (PL) condition. To conclude, we provide complete statistical and convergence guarantees for solving an infinite-dimensional zero-sum …
This paper aims to define, visualize, and analyze the feature complexity that is learned by a DNN. We propose a generic definition for the feature complexity. Given the feature of a certain layer in the DNN, our method decomposes and visualizes feature components of different complexity orders from the feature. The feature decomposition enables us to evaluate the reliability, the effectiveness, and the significance of over-fitting of these feature components. Furthermore, such analysis helps to improve the performance of DNNs. As a generic method, the feature complexity also provides new insights into existing deep-learning techniques, such as network compression and knowledge distillation.
Although Label Distribution Learning (LDL) has witnessed extensive classification applications, it faces the challenge of objective mismatch -- the objective of LDL mismatches that of classification, which has seldom been noticed in existing studies. Our goal is to solve the objective mismatch and improve the classification performance of LDL. Specifically, we extend the margin theory to LDL and propose a new LDL method called \textbf{L}abel \textbf{D}istribution \textbf{L}earning \textbf{M}achine (LDLM). First, we define the label distribution margin and propose the \textbf{S}upport \textbf{V}ector \textbf{R}egression \textbf{M}achine (SVRM) to learn the optimal label. Second, we propose the adaptive margin loss to learn label description degrees. In theoretical analysis, we develop a generalization theory for the SVRM and analyze the generalization of LDLM. Experimental results validate the better classification performance of LDLM.
Descent methods for deep networks are notoriously capricious: they require careful tuning of step size, momentum and weight decay, and which method will work best on a new benchmark is a priori unclear. To address this problem, this paper conducts a combined study of neural architecture and optimisation, leading to a new optimiser called Nero: the neuronal rotator. Nero trains reliably without momentum or weight decay, works in situations where Adam and SGD fail, and requires little to no learning rate tuning. Also, Nero's memory footprint is ~ square root that of Adam or LAMB. Nero combines two ideas: (1) projected gradient descent over the space of balanced networks; (2) neuron-specific updates, where the step size sets the angle through which each neuron's hyperplane turns. The paper concludes by discussing how this geometric connection between architecture and optimisation may impact theories of generalisation in deep learning.
Training deep neural network models in the presence of corrupted supervision is challenging as the corrupted data points may significantly impact generalization performance. To alleviate this problem, we present an efficient robust algorithm that achieves strong guarantees without any assumption on the type of corruption and provides a unified framework for both classification and regression problems. Unlike many existing approaches that quantify the quality of the data points (e.g., based on their individual loss values), and filter them accordingly, the proposed algorithm focuses on controlling the collective impact of data points on the average gradient. Even when a corrupted data point failed to be excluded by our algorithm, the data point will have a very limited impact on the overall loss, as compared with state-of-the-art filtering methods based on loss values. Extensive experiments on multiple benchmark datasets have demonstrated the robustness of our algorithm under different types of corruption. Our code is available at \url{https://github.com/illidanlab/PRL}.
Answering complex natural language questions on knowledge graphs (KGQA) is a challenging task. It requires reasoning with the input natural language questions as well as a massive, incomplete heterogeneous KG. Prior methods obtain an abstract structured query graph/tree from the input question and traverse the KG for answers following the query tree. However, they inherently cannot deal with missing links in the KG. Here we present LEGO, a Latent Execution-Guided reasOning framework to handle this challenge in KGQA. LEGO works in an iterative way, which alternates between (1) a Query Synthesizer, which synthesizes a reasoning action and grows the query tree step-by-step, and (2) a Latent Space Executor that executes the reasoning action in the latent embedding space to combat against the missing information in KG. To learn the synthesizer without step-wise supervision, we design a generic latent execution guided bottom-up search procedure to find good execution traces efficiently in the vast query space. Experimental results on several KGQA benchmarks demonstrate the effectiveness of our framework compared with previous state of the art.
This paper discusses the problem of weakly supervised classification, in which instances are given weak labels that are produced by some label-corruption process. The goal is to derive conditions under which loss functions for weak-label learning are proper and lower-bounded---two essential requirements for the losses used in class-probability estimation. To this end, we derive a representation theorem for proper losses in supervised learning, which dualizes the Savage representation. We use this theorem to characterize proper weak-label losses and find a condition for them to be lower-bounded. From these theoretical findings, we derive a novel regularization scheme called generalized logit squeezing, which makes any proper weak-label loss bounded from below, without losing properness. Furthermore, we experimentally demonstrate the effectiveness of our proposed approach, as compared to improper or unbounded losses. The results highlight the importance of properness and lower-boundedness.
Most computer science conferences rely on paper bidding to assign reviewers to papers. Although paper bidding enables high-quality assignments in days of unprecedented submission numbers, it also opens the door for dishonest reviewers to adversarially influence paper reviewing assignments. Anecdotal evidence suggests that some reviewers bid on papers by "friends" or colluding authors, even though these papers are outside their area of expertise, and recommend them for acceptance without considering the merit of the work. In this paper, we study the efficacy of such bid manipulation attacks and find that, indeed, they can jeopardize the integrity of the review process. We develop a novel approach for paper bidding and assignment that is much more robust against such attacks. We show empirically that our approach provides robustness even when dishonest reviewers collude, have full knowledge of the assignment system's internal workings, and have access to the system's inputs. In addition to being more robust, the quality of our paper review assignments is comparable to that of current, non-robust assignment approaches.
Using logical clauses to represent patterns, Tsetlin Machine (TM) have recently obtained competitive performance in terms of accuracy, memory footprint, energy, and learning speed on several benchmarks. Each TM clause votes for or against a particular class, with classification resolved using a majority vote. While the evaluation of clauses is fast, being based on binary operators, the voting makes it necessary to synchronize the clause evaluation, impeding parallelization. In this paper, we propose a novel scheme for desynchronizing the evaluation of clauses, eliminating the voting bottleneck. In brief, every clause runs in its own thread for massive native parallelism. For each training example, we keep track of the class votes obtained from the clauses in local voting tallies. The local voting tallies allow us to detach the processing of each clause from the rest of the clauses, supporting decentralized learning. This means that the TM most of the time will operate on outdated voting tallies. We evaluated the proposed parallelization across diverse learning tasks and it turns out that our decentralized TM learning algorithm copes well with working on outdated data, resulting in no significant loss in learning accuracy. Furthermore, we show that the approach provides up to 50 times …
Data-driven pricing strategies are becoming increasingly common, where customers are offered a personalized price based on features that are predictive of their valuation of a product. It is desirable for this pricing policy to be simple and interpretable, so it can be verified, checked for fairness, and easily implemented. However, efforts to incorporate machine learning into a pricing framework often lead to complex pricing policies that are not interpretable, resulting in slow adoption in practice. We present a novel, customized, prescriptive tree-based algorithm that distills knowledge from a complex black-box machine learning algorithm, segments customers with similar valuations and prescribes prices in such a way that maximizes revenue while maintaining interpretability. We quantify the regret of a resulting policy and demonstrate its efficacy in applications with both synthetic and real-world datasets.
Conditional selective inference (SI) has been actively studied as a new statistical inference framework for data-driven hypotheses. The basic idea of conditional SI is to make inferences conditional on the selection event characterized by a set of linear and/or quadratic inequalities. Conditional SI has been mainly studied in the context of feature selection such as stepwise feature selection (SFS). The main limitation of the existing conditional SI methods is the loss of power due to over-conditioning, which is required for computational tractability. In this study, we develop a more powerful and general conditional SI method for SFS using the homotopy method which enables us to overcome this limitation. The homotopy-based SI is especially effective for more complicated feature selection algorithms. As an example, we develop a conditional SI method for forward-backward SFS with AIC-based stopping criteria and show that it is not adversely affected by the increased complexity of the algorithm. We conduct several experiments to demonstrate the effectiveness and efficiency of the proposed method.
Metric Multidimensional scaling (MDS) is a classical method for generating meaningful (non-linear) low-dimensional embeddings of high-dimensional data. MDS has a long history in the statistics, machine learning, and graph drawing communities. In particular, the Kamada-Kawai force-directed graph drawing method is equivalent to MDS and is one of the most popular ways in practice to embed graphs into low dimensions. Despite its ubiquity, our theoretical understanding of MDS remains limited as its objective function is highly non-convex. In this paper, we prove that minimizing the Kamada-Kawai objective is NP-hard and give a provable approximation algorithm for optimizing it, which in particular is a PTAS on low-diameter graphs. We supplement this result with experiments suggesting possible connections between our greedy approximation algorithm and gradient-based methods.
Bayesian persuasion studies how an informed sender should partially disclose information to influence the behavior of a self-interested receiver. Classical models make the stringent assumption that the sender knows the receiver’s utility. This can be relaxed by considering an online learning framework in which the sender repeatedly faces a receiver of an unknown, adversarially selected type. We study, for the first time, an online Bayesian persuasion setting with multiple receivers. We focus on the case with no externalities and binary actions, as customary in offline models. Our goal is to design no-regret algorithms for the sender with polynomial per-iteration running time. First, we prove a negative result: for any 0 < α ≤ 1, there is no polynomial-time no-α-regret algorithm when the sender’s utility function is supermodular or anonymous. Then, we focus on the setting of submodular sender’s utility functions and we show that, in this case, it is possible to design a polynomial-time no-(1-1/e)-regret algorithm. To do so, we introduce a general online gradient descent framework to handle online learning problems with a finite number of possible loss functions. This requires the existence of an approximate projection oracle. We show that, in our setting, there exists one such projection …
Stochastic differential equations (SDEs) are a staple of mathematical modelling of temporal dynamics. However, a fundamental limitation has been that such models have typically been relatively inflexible, which recent work introducing Neural SDEs has sought to solve. Here, we show that the current classical approach to fitting SDEs may be approached as a special case of (Wasserstein) GANs, and in doing so the neural and classical regimes may be brought together. The input noise is Brownian motion, the output samples are time-evolving paths produced by a numerical solver, and by parameterising a discriminator as a Neural Controlled Differential Equation (CDE), we obtain Neural SDEs as (in modern machine learning parlance) continuous-time generative time series models. Unlike previous work on this problem, this is a direct extension of the classical approach without reference to either prespecified statistics or density functions. Arbitrary drift and diffusions are admissible, so as the Wasserstein loss has a unique global minima, in the infinite data limit \textit{any} SDE may be learnt.
In the vanishing learning rate regime, stochastic gradient descent (SGD) is now relatively well understood. In this work, we propose to study the basic properties of SGD and its variants in the non-vanishing learning rate regime. The focus is on deriving exactly solvable results and discussing their implications. The main contributions of this work are to derive the stationary distribution for discrete-time SGD in a quadratic loss function with and without momentum; in particular, one implication of our result is that the fluctuation caused by discrete-time dynamics takes a distorted shape and is dramatically larger than a continuous-time theory could predict. Examples of applications of the proposed theory considered in this work include the approximation error of variants of SGD, the effect of minibatch noise, the optimal Bayesian inference, the escape rate from a sharp minimum, and the stationary covariance of a few second-order methods including damped Newton's method, natural gradient descent, and Adam.
Consider N players that each uses a mixture of K resources. Each of the players' reward functions includes a linear pricing term for each resource that is controlled by the game manager. We assume that the game is strongly monotone, so if each player runs gradient descent, the dynamics converge to a unique Nash equilibrium (NE). Unfortunately, this NE can be inefficient since the total load on a given resource can be very high. In principle, we can control the total loads by tuning the coefficients of the pricing terms. However, finding pricing coefficients that balance the loads requires knowing the players' reward functions and their action sets. Obtaining this game structure information is infeasible in a large-scale network and violates the users' privacy. To overcome this, we propose a simple algorithm that learns to shift the NE of the game to meet the total load constraints by adjusting the pricing coefficients in an online manner. Our algorithm only requires the total load per resource as feedback and does not need to know the reward functions or the action sets. We prove that our algorithm guarantees convergence in L2 to a NE that meets target total load constraints. Simulations show …
Motivated by applications in shared mobility, we address the problem of allocating a group of agents to a set of resources to maximize a cumulative welfare objective. We model the welfare obtainable from each resource as a monotone DR-submodular function which is a-priori unknown and can only be learned by observing the welfare of selected allocations. Moreover, these functions can depend on time-varying contextual information. We propose a distributed scheme to maximize the cumulative welfare by designing a repeated game among the agents, who learn to act via regret minimization. We propose two design choices for the game rewards based on upper confidence bounds built around the unknown welfare functions. We analyze them theoretically, bounding the gap between the cumulative welfare of the game and the highest cumulative welfare obtainable in hindsight. Finally, we evaluate our approach in a realistic case study of rebalancing a shared mobility system (i.e., positioning vehicles in strategic areas). From observed trip data, our algorithm gradually learns the users' demand pattern and improves the overall system operation.
Lossy compression algorithms are typically designed to achieve the lowest possible distortion at a given bit rate. However, recent studies show that pursuing high perceptual quality would lead to increase of the lowest achievable distortion (e.g., MSE). This paper provides nontrivial results theoretically revealing that, 1) the cost of achieving perfect perception quality is exactly a doubling of the lowest achievable MSE distortion, 2) an optimal encoder for the “classic” rate-distortion problem is also optimal for the perceptual compression problem, 3) distortion loss is unnecessary for training a perceptual decoder. Further, we propose a novel training framework to achieve the lowest MSE distortion under perfect perception constraint at a given bit rate. This framework uses a GAN with discriminator conditioned on an MSE-optimized encoder, which is superior over the traditional framework using distortion plus adversarial loss. Experiments are provided to verify the theoretical finding and demonstrate the superiority of the proposed training framework.
We study the problem of robust mean estimation and introduce a novel Hamming distance-based measure of distribution shift for coordinate-level corruptions. We show that this measure yields adversary models that capture more realistic corruptions than those used in prior works, and present an information-theoretic analysis of robust mean estimation in these settings. We show that for structured distributions, methods that leverage the structure yield information theoretically more accurate mean estimation. We also focus on practical algorithms for robust mean estimation and study when data cleaning-inspired approaches that first fix corruptions in the input data and then perform robust mean estimation can match the information theoretic bounds of our analysis. We finally demonstrate experimentally that this two-step approach outperforms structure-agnostic robust estimation and provides accurate mean estimation even for high-magnitude corruption.
Randomly perturbing networks during the training process is a commonly used approach to improving generalization performance. In this paper, we present a theoretical study of one particular way of random perturbation, which corresponds to injecting artificial noise to the training data. We provide a precise asymptotic characterization of the training and generalization errors of such randomly perturbed learning problems on a random feature model. Our analysis shows that Gaussian noise injection in the training process is equivalent to introducing a weighted ridge regularization, when the number of noise injections tends to infinity. The explicit form of the regularization is also given. Numerical results corroborate our asymptotic predictions, showing that they are accurate even in moderate problem dimensions. Our theoretical predictions are based on a new correlated Gaussian equivalence conjecture that generalizes recent results in the study of random feature models.
Biclustering structures exist ubiquitously in data matrices and the biclustering problem was first formalized by John Hartigan (1972) to cluster rows and columns simultaneously. In this paper, we develop a theory for the estimation of general biclustering models, where the data is assumed to follow certain statistical distribution with underlying biclustering structure. Due to the existence of latent variables, directly computing the maximal likelihood estimator is prohibitively difficult in practice and we instead consider the variational inference (VI) approach to solve the parameter estimation problem. Although variational inference method generally has good empirical performance, there are very few theoretical results around VI. In this paper, we obtain the precise estimation bound of variational estimator and show that it matches the minimax rate in terms of estimation error under mild assumptions in biclustering setting. Furthermore, we study the convergence property of the coordinate ascent variational inference algorithm, where both local and global convergence results have been provided. Numerical results validate our new theories.
This paper studies two variants of the best arm identification (BAI) problem under the streaming model, where we have a stream of n arms with reward distributions supported on [0,1] with unknown means. The arms in the stream are arriving one by one, and the algorithm cannot access an arm unless it is stored in a limited size memory.
We first study the streaming \epslion-topk-arms identification problem, which asks for k arms whose reward means are lower than that of the k-th best arm by at most \epsilon with probability at least 1-\delta. For general \epsilon \in (0,1), the existing solution for this problem assumes k = 1 and achieves the optimal sample complexity O(\frac{n}{\epsilon^2} \log \frac{1}{\delta}) using O(\log^*(n)) memory and a single pass of the stream. We propose an algorithm that works for any k and achieves the optimal sample complexity O(\frac{n}{\epsilon^2} \log\frac{k}{\delta}) using a single-arm memory and a single pass of the stream.
Second, we study the streaming BAI problem, where the objective is to identify the arm with the maximum reward mean with at least 1-\delta probability, using a single-arm memory and as few passes of the input stream as possible. We present a single-arm-memory algorithm that …
In performative prediction, predictions guide decision-making and hence can influence the distribution of future data. To date, work on performative prediction has focused on finding performatively stable models, which are the fixed points of repeated retraining. However, stable solutions can be far from optimal when evaluated in terms of the performative risk, the loss experienced by the decision maker when deploying a model. In this paper, we shift attention beyond performative stability and focus on optimizing the performative risk directly. We identify a natural set of properties of the loss function and model-induced distribution shift under which the performative risk is convex, a property which does not follow from convexity of the loss alone. Furthermore, we develop algorithms that leverage our structural assumptions to optimize the performative risk with better sample efficiency than generic methods for derivative-free convex optimization.
Counterfactual estimation using synthetic controls is one of the most successful recent methodological developments in causal inference. Despite its popularity, the current description only considers time series aligned across units and synthetic controls expressed as linear combinations of observed control units. We propose a continuous-time alternative that models the latent counterfactual path explicitly using the formalism of controlled differential equations. This model is directly applicable to the general setting of irregularly-aligned multivariate time series and may be optimized in rich function spaces -- thereby improving on some limitations of existing approaches.
Meta-learning, or learning-to-learn, seeks to design algorithms that can utilize previous experience to rapidly learn new skills or adapt to new environments. Representation learning---a key tool for performing meta-learning---learns a data representation that can transfer knowledge across multiple tasks, which is essential in regimes where data is scarce. Despite a recent surge of interest in the practice of meta-learning, the theoretical underpinnings of meta-learning algorithms are lacking, especially in the context of learning transferable representations. In this paper, we focus on the problem of multi-task linear regression---in which multiple linear regression models share a common, low-dimensional linear representation. Here, we provide provably fast, sample-efficient algorithms to address the dual challenges of (1) learning a common set of features from multiple, related tasks, and (2) transferring this knowledge to new, unseen tasks. Both are central to the general problem of meta-learning. Finally, we complement these results by providing information-theoretic lower bounds on the sample complexity of learning these linear features.
We study multi-objective reinforcement learning (RL) where an agent's reward is represented as a vector. In settings where an agent competes against opponents, its performance is measured by the distance of its average return vector to a target set. We develop statistically and computationally efficient algorithms to approach the associated target set. Our results extend Blackwell's approachability theorem~\citep{blackwell1956analog} to tabular RL, where strategic exploration becomes essential. The algorithms presented are adaptive; their guarantees hold even without Blackwell's approachability condition. If the opponents use fixed policies, we give an improved rate of approaching the target set while also tackling the more ambitious goal of simultaneously minimizing a scalar cost function. We discuss our analysis for this special case by relating our results to previous works on constrained RL. To our knowledge, this work provides the first provably efficient algorithms for vector-valued Markov games and our theoretical guarantees are near-optimal.
Finding an optimal matching in a weighted graph is a standard combinatorial problem. We consider its semi-bandit version where either a pair or a full matching is sampled sequentially. We prove that it is possible to leverage a rank-1 assumption on the adjacency matrix to reduce the sample complexity and the regret of off-the-shelf algorithms up to reaching a linear dependency in the number of vertices (up to to poly-log terms).
We study the problem of learning conditional average treatment effects (CATE) from high-dimensional, observational data with unobserved confounders. Unobserved confounders introduce ignorance---a level of unidentifiability---about an individual's response to treatment by inducing bias in CATE estimates. We present a new parametric interval estimator suited for high-dimensional data, that estimates a range of possible CATE values when given a predefined bound on the level of hidden confounding. Further, previous interval estimators do not account for ignorance about the CATE associated with samples that may be underrepresented in the original study, or samples that violate the overlap assumption. Our interval estimator also incorporates model uncertainty so that practitioners can be made aware of such out-of-distribution data. We prove that our estimator converges to tight bounds on CATE when there may be unobserved confounding and assess it using semi-synthetic, high-dimensional datasets.
Decentralized training of deep learning models is a key element for enabling data privacy and on-device learning over networks. In realistic learning scenarios, the presence of heterogeneity across different clients' local datasets poses an optimization challenge and may severely deteriorate the generalization performance. In this paper, we investigate and identify the limitation of several decentralized optimization algorithms for different degrees of data heterogeneity. We propose a novel momentum-based method to mitigate this decentralized training difficulty. We show in extensive empirical experiments on various CV/NLP datasets (CIFAR-10, ImageNet, and AG News) and several network topologies (Ring and Social Network) that our method is much more robust to the heterogeneity of clients' data than other existing methods, by a significant improvement in test performance (1%-20%).
To assess generalization, machine learning scientists typically either (i) bound the generalization gap and then (after training) plug in the empirical risk to obtain a bound on the true risk; or (ii) validate empirically on holdout data. However, (i) typically yields vacuous guarantees for overparameterized models; and (ii) shrinks the training set and its guarantee erodes with each re-use of the holdout set. In this paper, we leverage unlabeled data to produce generalization bounds. After augmenting our (labeled) training set with randomly labeled data, we train in the standard fashion. Whenever classifiers achieve low error on the clean data but high error on the random data, our bound ensures that the true risk is low. We prove that our bound is valid for 0-1 empirical risk minimization and with linear classifiers trained by gradient descent. Our approach is especially useful in conjunction with deep learning due to the early learning phenomenon whereby networks fit true labels before noisy labels but requires one intuitive assumption. Empirically, on canonical computer vision and NLP tasks, our bound provides non-vacuous generalization guarantees that track actual performance closely. This work enables practitioners to certify generalization even when (labeled) holdout data is unavailable and provides insights …
Collecting more diverse and representative training data is often touted as a remedy for the disparate performance of machine learning predictors across subpopulations. However, a precise framework for understanding how dataset properties like diversity affect learning outcomes is largely lacking. By casting data collection as part of the learning process, we demonstrate that diverse representation in training data is key not only to increasing subgroup performances, but also to achieving population-level objectives. Our analysis and experiments describe how dataset compositions influence performance and provide constructive results for using trends in existing data, alongside domain knowledge, to help guide intentional, objective-aware dataset design
We consider the pure exploration problem in the fixed-budget linear bandit setting. We provide a new algorithm that identifies the best arm with high probability while being robust to unknown levels of observation noise as well as to moderate levels of misspecification in the linear model. Our technique combines prior approaches to pure exploration in the multi-armed bandit problem with optimal experimental design algorithms to obtain both problem dependent and problem independent bounds. Our success probability is never worse than that of an algorithm that ignores the linear structure, but seamlessly takes advantage of such structure when possible. Furthermore, we only need the number of samples to scale with the dimension of the problem rather than the number of arms. We complement our theoretical results with empirical validation.
The scarcity of available samples and the high annotation cost of medical data cause a bottleneck in many digital diagnosis tasks based on deep learning. This problem is especially severe in pediatric tumor tasks, due to the small population base of children and high sample diversity caused by the high metastasis rate of related tumors. Targeted research on pediatric tumors is urgently needed but lacks sufficient attention. In this work, we propose a novel model to solve the diagnosis task of small round blue cell tumors (SRBCTs). To solve the problem of high noise and high diversity in the small sample scenario, the model is constrained to pay attention to the valid areas in the pathological image with a masking mechanism, and a length-aware loss is proposed to improve the tolerance to feature diversity. We evaluate this framework on a challenging small sample SRBCTs dataset, whose classification is difficult even for professional pathologists. The proposed model shows the best performance compared with state-of-the-art deep models and generalization on another pathological dataset, which illustrates the potentiality of deep learning applications in difficult small sample medical tasks.
We present a novel adaptive cruise control (ACC) system namely SAINT-ACC: {S}afety-{A}ware {Int}elligent {ACC} system (SAINT-ACC) that is designed to achieve simultaneous optimization of traffic efficiency, driving safety, and driving comfort through dynamic adaptation of the inter-vehicle gap based on deep reinforcement learning (RL). A novel dual RL agent-based approach is developed to seek and adapt the optimal balance between traffic efficiency and driving safety/comfort by effectively controlling the driving safety model parameters and inter-vehicle gap based on macroscopic and microscopic traffic information collected from dynamically changing and complex traffic environments. Results obtained through over 12,000 simulation runs with varying traffic scenarios and penetration rates demonstrate that SAINT-ACC significantly enhances traffic flow, driving safety and comfort compared with a state-of-the-art approach.
Reinforcement learning (RL) is empirically successful in complex nonlinear Markov decision processes (MDPs) with continuous state spaces. By contrast, the majority of theoretical RL literature requires the MDP to satisfy some form of linear structure, in order to guarantee sample efficient RL. Such efforts typically assume the transition dynamics or value function of the MDP are described by linear functions of the state features. To resolve this discrepancy between theory and practice, we introduce the Effective Planning Window (EPW) condition, a structural condition on MDPs that makes no linearity assumptions. We demonstrate that the EPW condition permits sample efficient RL, by providing an algorithm which provably solves MDPs satisfying this condition. Our algorithm requires minimal assumptions on the policy class, which can include multi-layer neural networks with nonlinear activation functions. Notably, the EPW condition is directly motivated by popular gaming benchmarks, and we show that many classic Atari games satisfy this condition. We additionally show the necessity of conditions like EPW, by demonstrating that simple MDPs with slight nonlinearities cannot be solved sample efficiently.
Residual networks (ResNets) have displayed impressive results in pattern recognition and, recently, have garnered considerable theoretical interest due to a perceived link with neural ordinary differential equations (neural ODEs). This link relies on the convergence of network weights to a smooth function as the number of layers increases. We investigate the properties of weights trained by stochastic gradient descent and their scaling with network depth through detailed numerical experiments. We observe the existence of scaling regimes markedly different from those assumed in neural ODE literature. Depending on certain features of the network architecture, such as the smoothness of the activation function, one may obtain an alternative ODE limit, a stochastic differential equation or neither of these. These findings cast doubts on the validity of the neural ODE model as an adequate asymptotic description of deep ResNets and point to an alternative class of differential equations as a better description of the deep network limit.
Sparse neural networks have been widely applied to reduce the computational demands of training and deploying over-parameterized deep neural networks. For inference acceleration, methods that discover a sparse network from a pre-trained dense network (dense-to-sparse training) work effectively. Recently, dynamic sparse training (DST) has been proposed to train sparse neural networks without pre-training a dense model (sparse-to-sparse training), so that the training process can also be accelerated. However, previous sparse-to-sparse methods mainly focus on Multilayer Perceptron Networks (MLPs) and Convolutional Neural Networks (CNNs), failing to match the performance of dense-to-sparse methods in the Recurrent Neural Networks (RNNs) setting. In this paper, we propose an approach to train intrinsically sparse RNNs with a fixed parameter count in one single run, without compromising performance. During training, we allow RNN layers to have a non-uniform redistribution across cell gates for better regularization. Further, we propose SNT-ASGD, a novel variant of the averaged stochastic gradient optimizer, which significantly improves the performance of all sparse training methods for RNNs. Using these strategies, we achieve state-of-the-art sparse training results, better than the dense-to-sparse methods, with various types of RNNs on Penn TreeBank and Wikitext-2 datasets. Our codes are available at https://github.com/Shiweiliuiiiiiii/Selfish-RNN.
We study image inverse problems with a normalizing flow prior. Our formulation views the solution as the maximum a posteriori estimate of the image conditioned on the measurements. This formulation allows us to use noise models with arbitrary dependencies as well as non-linear forward operators. We empirically validate the efficacy of our method on various inverse problems, including compressed sensing with quantized measurements and denoising with highly structured noise patterns. We also present initial theoretical recovery guarantees for solving inverse problems with a flow prior.
This paper provides a statistical analysis of high-dimensional batch reinforcement learning (RL) using sparse linear function approximation. When there is a large number of candidate features, our result sheds light on the fact that sparsity-aware methods can make batch RL more sample efficient. We first consider the off-policy policy evaluation problem. To evaluate a new target policy, we analyze a Lasso fitted Q-evaluation method and establish a finite-sample error bound that has no polynomial dependence on the ambient dimension. To reduce the Lasso bias, we further propose a post model-selection estimator that applies fitted Q-evaluation to the features selected via group Lasso. Under an additional signal strength assumption, we derive a sharper instance-dependent error bound that depends on a divergence function measuring the distribution mismatch between the data distribution and occupancy measure of the target policy. Further, we study the Lasso fitted Q-iteration for batch policy optimization and establish a finite-sample error bound depending on the ratio between the number of relevant features and restricted minimal eigenvalue of the data's covariance. In the end, we complement the results with minimax lower bounds for batch-data policy evaluation/optimization that nearly match our upper bounds. The results suggest that having well-conditioned data is …
Spreadsheet formula prediction has been an important program synthesis problem with many real-world applications. Previous works typically utilize input-output examples as the specification for spreadsheet formula synthesis, where each input-output pair simulates a separate row in the spreadsheet. However, this formulation does not fully capture the rich context in real-world spreadsheets. First, spreadsheet data entries are organized as tables, thus rows and columns are not necessarily independent from each other. In addition, many spreadsheet tables include headers, which provide high-level descriptions of the cell data. However, previous synthesis approaches do not consider headers as part of the specification. In this work, we present the first approach for synthesizing spreadsheet formulas from tabular context, which includes both headers and semi-structured tabular data. In particular, we propose SpreadsheetCoder, a BERT-based model architecture to represent the tabular context in both row-based and column-based formats. We train our model on a large dataset of spreadsheets, and demonstrate that SpreadsheetCoder achieves top-1 prediction accuracy of 42.51%, which is a considerable improvement over baselines that do not employ rich tabular context. Compared to the rule-based system, SpreadsheetCoder assists 82% more users in composing formulas on Google Sheets.
Many machine learning problems can be formulated as minimax problems such as Generative Adversarial Networks (GANs), AUC maximization and robust estimation, to mention but a few. A substantial amount of studies are devoted to studying the convergence behavior of their stochastic gradient-type algorithms. In contrast, there is relatively little work on understanding their generalization, i.e., how the learning models built from training examples would behave on test examples. In this paper, we provide a comprehensive generalization analysis of stochastic gradient methods for minimax problems under both convex-concave and nonconvex-nonconcave cases through the lens of algorithmic stability. We establish a quantitative connection between stability and several generalization measures both in expectation and with high probability. For the convex-concave setting, our stability analysis shows that stochastic gradient descent ascent attains optimal generalization bounds for both smooth and nonsmooth minimax problems. We also establish generalization bounds for both weakly-convex-weakly-concave and gradient-dominated problems. We report preliminary experimental results to verify our theory.
Exploration in unknown environments is a fundamental problem in reinforcement learning and control. In this work, we study task-guided exploration and determine what precisely an agent must learn about their environment in order to complete a particular task. Formally, we study a broad class of decision-making problems in the setting of linear dynamical systems, a class that includes the linear quadratic regulator problem. We provide instance- and task-dependent lower bounds which explicitly quantify the difficulty of completing a task of interest. Motivated by our lower bound, we propose a computationally efficient experiment-design based exploration algorithm. We show that it optimally explores the environment, collecting precisely the information needed to complete the task, and provide finite-time bounds guaranteeing that it achieves the instance- and task-optimal sample complexity, up to constant factors. Through several examples of the linear quadratic regulator problem, we show that performing task-guided exploration provably improves on exploration schemes which do not take into account the task of interest. Along the way, we establish that certainty equivalence decision making is instance- and task-optimal, and obtain the first algorithm for the linear quadratic regulator problem which is instance-optimal. We conclude with several experiments illustrating the effectiveness of our approach in …
Yang (2020) recently showed that the Neural Tangent Kernel (NTK) at initialization has an infinite-width limit for a large class of architectures including modern staples such as ResNet and Transformers. However, their analysis does not apply to training. Here, we show the same neural networks (in the so-called NTK parametrization) during training follow a kernel gradient descent dynamics in function space, where the kernel is the infinite-width NTK. This completes the proof of the architectural universality of NTK behavior. To achieve this result, we apply the Tensor Programs technique: Write the entire SGD dynamics inside a Tensor Program and analyze it via the Master Theorem. To facilitate this proof, we develop a graphical notation for Tensor Programs, which we believe is also an important contribution toward the pedagogy and exposition of the Tensor Programs technique.
As its width tends to infinity, a deep neural network's behavior under gradient descent can become simplified and predictable (e.g. given by the Neural Tangent Kernel (NTK)), if it is parametrized appropriately (e.g. the NTK parametrization). However, we show that the standard and NTK parametrizations of a neural network do not admit infinite-width limits that can learn features, which is crucial for pretraining and transfer learning such as with BERT. We propose simple modifications to the standard parametrization to allow for feature learning in the limit. Using the Tensor Programs technique, we derive explicit formulas for such limits. On Word2Vec and few-shot learning on Omniglot via MAML, two canonical tasks that rely crucially on feature learning, we compute these limits exactly. We find that they outperform both NTK baselines and finite-width networks, with the latter approaching the infinite-width feature learning performance as width increases.
Algorithmic stability is a key characteristic to ensure the generalization ability of a learning algorithm. Among different notions of stability, \emph{uniform stability} is arguably the most popular one, which yields exponential generalization bounds. However, uniform stability only considers the worst-case loss change (or so-called sensitivity) by removing a single data point, which is distribution-independent and therefore undesirable. There are many cases that the worst-case sensitivity of the loss is much larger than the average sensitivity taken over the single data point that is removed, especially in some advanced models such as random feature models or neural networks. Many previous works try to mitigate the distribution independent issue by proposing weaker notions of stability, however, they either only yield polynomial bounds or the bounds derived do not vanish as sample size goes to infinity. Given that, we propose \emph{locally elastic stability} as a weaker and distribution-dependent stability notion, which still yields exponential generalization bounds. We further demonstrate that locally elastic stability implies tighter generalization bounds than those derived based on uniform stability in many situations by revisiting the examples of bounded support vector machines, regularized least square regressions, and stochastic gradient descent.
In active visual tracking, it is notoriously difficult when distracting objects appear, as distractors often mislead the tracker by occluding the target or bringing a confusing appearance. To address this issue, we propose a mixed cooperative-competitive multi-agent game, where a target and multiple distractors form a collaborative team to play against a tracker and make it fail to follow. Through learning in our game, diverse distracting behaviors of the distractors naturally emerge, thereby exposing the tracker's weakness, which helps enhance the distraction-robustness of the tracker. For effective learning, we then present a bunch of practical methods, including a reward function for distractors, a cross-modal teacher-student learning strategy, and a recurrent attention mechanism for the tracker. The experimental results show that our tracker performs desired distraction-robust active visual tracking and can be well generalized to unseen environments. We also show that the multi-agent game can be used to adversarially test the robustness of trackers.
In many machine learning applications, each record represents a set of items. For example, when making predictions from medical records, the medications prescribed to a patient are a set whose size is not fixed and whose order is arbitrary. However, most machine learning algorithms are not designed to handle set structures and are limited to processing records of fixed size. Set-Tree, presented in this work, extends the support for sets to tree-based models, such as Random-Forest and Gradient-Boosting, by introducing an attention mechanism and set-compatible split criteria. We evaluate the new method empirically on a wide range of problems ranging from making predictions on sub-atomic particle jets to estimating the redshift of galaxies. The new method outperforms existing tree-based methods consistently and significantly. Moreover, it is competitive and often outperforms Deep Learning. We also discuss the theoretical properties of Set-Trees and explain how they enable item-level explainability.
Noise injection is an effective way of circumventing overfitting and enhancing generalization in machine learning, the rationale of which has been validated in deep learning as well. Recently, noise injection exhibits surprising effectiveness when generating high-fidelity images in Generative Adversarial Networks (GANs) (e.g. StyleGAN). Despite its successful applications in GANs, the mechanism of its validity is still unclear. In this paper, we propose a geometric framework to theoretically analyze the role of noise injection in GANs. First, we point out the existence of the adversarial dimension trap inherent in GANs, which leads to the difficulty of learning a proper generator. Second, we successfully model the noise injection framework with exponential maps based on Riemannian geometry. Guided by our theories, we propose a general geometric realization for noise injection. Under our novel framework, the simple noise injection used in StyleGAN reduces to the Euclidean case. The goal of our work is to make theoretical steps towards understanding the underlying mechanism of state-of-the-art GAN algorithms. Experiments on image generation and GAN inversion validate our theory in practice.
We provide a detailed analysis of the dynamics ofthe gradient flow in overparameterized two-layerlinear models. A particularly interesting featureof this model is that its nonlinear dynamics can beexactly solved as a consequence of a large num-ber of conservation laws that constrain the systemto follow particular trajectories. More precisely,the gradient flow preserves the difference of theGramian matrices of the input and output weights,and its convergence to equilibrium depends onboth the magnitude of that difference (which isfixed at initialization) and the spectrum of the data.In addition, and generalizing prior work, we proveour results without assuming small, balanced orspectral initialization for the weights. Moreover,we establish interesting mathematical connectionsbetween matrix factorization problems and differ-ential equations of the Riccati type.
Machine learned models often must abide by certain requirements (e.g., fairness or legal). This has spurred interested in developing approaches that can provably verify whether a model satisfies certain properties. This paper introduces a generic algorithm called Veritas that enables tackling multiple different verification tasks for tree ensemble models like random forests (RFs) and gradient boosted decision trees (GBDTs). This generality contrasts with previous work, which has focused exclusively on either adversarial example generation or robustness checking. Veritas formulates the verification task as a generic optimization problem and introduces a novel search space representation. Veritas offers two key advantages. First, it provides anytime lower and upper bounds when the optimization problem cannot be solved exactly. In contrast, many existing methods have focused on exact solutions and are thus limited by the verification problem being NP-complete. Second, Veritas produces full (bounded suboptimal) solutions that can be used to generate concrete examples. We experimentally show that our method produces state-of-the-art robustness estimates, especially when executed with strict time constraints. This is exceedingly important when checking the robustness of large datasets. Additionally, we show that Veritas enables tackling more real-world verification scenarios.
Generative adversarial networks (GAN) are a widely used class of deep generative models, but their minimax training dynamics are not understood very well. In this work, we show that GANs with a 2-layer infinite-width generator and a 2-layer finite-width discriminator trained with stochastic gradient ascent-descent have no spurious stationary points. We then show that when the width of the generator is finite but wide, there are no spurious stationary points within a ball whose radius becomes arbitrarily large (to cover the entire parameter space) as the width goes to infinity.
There recently has been a surge of interest in developing a new class of deep learning (DL) architectures that integrate an explicit time dimension as a fundamental building block of learning and representation mechanisms. In turn, many recent results show that topological descriptors of the observed data, encoding information on the shape of the dataset in a topological space at different scales, that is, persistent homology of the data, may contain important complementary information, improving both performance and robustness of DL. As convergence of these two emerging ideas, we propose to enhance DL architectures with the most salient time-conditioned topological information of the data and introduce the concept of zigzag persistence into time-aware graph convolutional networks (GCNs). Zigzag persistence provides a systematic and mathematically rigorous framework to track the most important topological features of the observed data that tend to manifest themselves over time. To integrate the extracted time-conditioned topological descriptors into DL, we develop a new topological summary, zigzag persistence image, and derive its theoretical stability guarantees. We validate the new GCNs with a time-aware zigzag topological layer (Z-GCNETs), in application to traffic forecasting and Ethereum blockchain price prediction. Our results indicate that Z-GCNET outperforms 13 state-of-the-art methods on …
Oral: Semisupervised Learning 1 Thu 22 Jul 02:00 p.m.

In learning with noisy labels, for every instance, its label can randomly walk to other classes following a transition distribution which is named a noise model. Well-studied noise models are all instance-independent, namely, the transition depends only on the original label but not the instance itself, and thus they are less practical in the wild. Fortunately, methods based on instance-dependent noise have been studied, but most of them have to rely on strong assumptions on the noise models. To alleviate this issue, we introduce confidence-scored instance-dependent noise (CSIDN), where each instance-label pair is equipped with a confidence score. We find that with the help of confidence scores, the transition distribution of each instance can be approximately estimated. Similarly to the powerful forward correction for instance-independent noise, we propose a novel instance-level forward correction for CSIDN. We demonstrate the utility and effectiveness of our method through multiple experiments on datasets with synthetic label noise and real-world unknown noise.

Density ratio estimation (DRE) is at the core of various machine learning tasks such as anomaly detection and domain adaptation. In the DRE literature, existing studies have extensively studied methods based on Bregman divergence (BD) minimization. However, when we apply the BD minimization with highly flexible models, such as deep neural networks, it tends to suffer from what we call train-loss hacking, which is a source of over-fitting caused by a typical characteristic of empirical BD estimators. In this paper, to mitigate train-loss hacking, we propose non-negative correction for empirical BD estimators. Theoretically, we confirm the soundness of the proposed method through a generalization error bound. In our experiments, the proposed methods show favorable performances in inlier-based outlier detection.
The recent breakthrough achieved by contrastive learning accelerates the pace for deploying unsupervised training on real-world data applications. However, unlabeled data in reality is commonly imbalanced and shows a long-tail distribution, and it is unclear how robustly the latest contrastive learning methods could perform in the practical scenario. This paper proposes to explicitly tackle this challenge, via a principled framework called Self-Damaging Contrastive Learning (SDCLR), to automatically balance the representation learning without knowing the classes. Our main inspiration is drawn from the recent finding that deep models have difficult-to-memorize samples, and those may be exposed through network pruning. It is further natural to hypothesize that long-tail samples are also tougher for the model to learn well due to insufficient examples. Hence, the key innovation in SDCLR is to create a dynamic self-competitor model to contrast with the target model, which is a pruned version of the latter. During training, contrasting the two models will lead to adaptive online mining of the most easily forgotten samples for the current target model, and implicitly emphasize them more in the contrastive loss. Extensive experiments across multiple datasets and imbalance settings show that SDCLR significantly improves not only overall accuracies but also balancedness, in …

Learning with noisy labels has attracted a lot of attention in recent years, where the mainstream approaches are in \emph{pointwise} manners. Meanwhile, \emph{pairwise} manners have shown great potential in supervised metric learning and unsupervised contrastive learning. Thus, a natural question is raised: does learning in a pairwise manner \emph{mitigate} label noise? To give an affirmative answer, in this paper, we propose a framework called \emph{Class2Simi}: it transforms data points with noisy \emph{class labels} to data pairs with noisy \emph{similarity labels}, where a similarity label denotes whether a pair shares the class label or not. Through this transformation, the \emph{reduction of the noise rate} is theoretically guaranteed, and hence it is in principle easier to handle noisy similarity labels. Amazingly, DNNs that predict the \emph{clean} class labels can be trained from noisy data pairs if they are first pretrained from noisy data points. Class2Simi is \emph{computationally efficient} because not only this transformation is on-the-fly in mini-batches, but also it just changes loss computation on top of model prediction into a pairwise manner. Its effectiveness is verified by extensive experiments.

We present GNNAutoScale (GAS), a framework for scaling arbitrary message-passing GNNs to large graphs. GAS prunes entire sub-trees of the computation graph by utilizing historical embeddings from prior training iterations, leading to constant GPU memory consumption in respect to input node size without dropping any data. While existing solutions weaken the expressive power of message passing due to sub-sampling of edges or non-trainable propagations, our approach is provably able to maintain the expressive power of the original GNN. We achieve this by providing approximation error bounds of historical embeddings and show how to tighten them in practice. Empirically, we show that the practical realization of our framework, PyGAS, an easy-to-use extension for PyTorch Geometric, is both fast and memory-efficient, learns expressive node representations, closely resembles the performance of their non-scaling counterparts, and reaches state-of-the-art performance on large-scale graphs.

Data transformations (e.g. rotations, reflections, and cropping) play an important role in self-supervised learning. Typically, images are transformed into different views, and neural networks trained on tasks involving these views produce useful feature representations for downstream tasks, including anomaly detection. However, for anomaly detection beyond image data, it is often unclear which transformations to use. Here we present a simple end-to-end procedure for anomaly detection with learnable transformations. The key idea is to embed the transformed data into a semantic space such that the transformed data still resemble their untransformed form, while different transformations are easily distinguishable. Extensive experiments on time series show that our proposed method outperforms existing approaches in the one-vs.-rest setting and is competitive in the more challenging n-vs.-rest anomaly-detection task. On medical and cyber-security tabular data, our method learns domain-specific transformations and detects anomalies more accurately than previous work.
We propose a novel Wasserstein distributional normalization method that can classify noisy labeled data accurately. Recently, noisy labels have been successfully handled based on small-loss criteria, but have not been clearly understood from the theoretical point of view. In this paper, we address this problem by adopting distributionally robust optimization (DRO). In particular, we present a theoretical investigation of the distributional relationship between uncertain and certain samples based on the small-loss criteria. Our method takes advantage of this relationship to exploit useful information from uncertain samples. To this end, we normalize uncertain samples into the robustly certified region by introducing the non-parametric Ornstein-Ulenbeck type of Wasserstein gradient flows called Wasserstein distributional normalization, which is cheap and fast to implement. We verify that network confidence and distributional certification are fundamentally correlated and show the concentration inequality when the network escapes from over-parameterization. Experimental results demonstrate that our non-parametric classification method outperforms other parametric baselines on the Clothing1M and CIFAR-10/100 datasets when the data have diverse noisy labels.
Oral: Systems and Hardware Thu 22 Jul 02:00 p.m.

Inspired by a new coded computation algorithm for invertible functions, we propose Coded-InvNet a new approach to design resilient prediction serving systems that can gracefully handle stragglers or node failures. Coded-InvNet leverages recent findings in the deep learning literature such as invertible neural networks, Manifold Mixup, and domain translation algorithms, identifying interesting research directions that span across machine learning and systems. Our experimental results show that Coded-InvNet can outperform existing approaches, especially when the compute resource overhead is as low as 10%. For instance, without knowing which of the ten workers is going to fail, our algorithm can design a backup task so that it can correctly recover the missing prediction result with an accuracy of 85.9%, significantly outperforming the previous SOTA by 32.5%.

Many state-of-the-art ML results have been obtained by scaling up the number of parameters in existing models. However, parameters and activations for such large models often do not fit in the memory of a single accelerator device; this means that it is necessary to distribute training of large models over multiple accelerators. In this work, we propose PipeDream-2BW, a system that supports memory-efficient pipeline parallelism. PipeDream-2BW uses a novel pipelining and weight gradient coalescing strategy, combined with the double buffering of weights, to ensure high throughput, low memory footprint, and weight update semantics similar to data parallelism. In addition, PipeDream-2BW automatically partitions the model over the available hardware resources, while respecting hardware constraints such as memory capacities of accelerators and interconnect topologies. PipeDream-2BW can accelerate the training of large GPT and BERT language models by up to 20x with similar final model accuracy.


We study robust testing and estimation of discrete distributions in the strong contamination model. Our results cover both centralized setting and distributed setting with general local information constraints including communication and LDP constraints. Our technique relates the strength of manipulation attacks to the earth-mover distance using Hamming distance as the metric between messages (samples) from the users. In the centralized setting, we provide optimal error bounds for both learning and testing. Our lower bounds under local information constraints build on the recent lower bound methods in distributed inference. In the communication constrained setting, we develop novel algorithms based on random hashing and an L1-L1 isometry.

It is not trivial to optimally learn a 3D Convolutional Neural Networks (3D ConvNets) due to high complexity and various options of the training scheme. The most common hand-tuning process starts from learning 3D ConvNets using short video clips and then is followed by learning long-term temporal dependency using lengthy clips, while gradually decaying the learning rate from high to low as training progresses. The fact that such process comes along with several heuristic settings motivates the study to seek an optimal "path" to automate the entire training. In this paper, we decompose the path into a series of training "states" and specify the hyper-parameters, e.g., learning rate and the length of input clips, in each state. The estimation of the knee point on the performance-epoch curve triggers the transition from one state to another. We perform dynamic programming over all the candidate states to plan the optimal permutation of states, i.e., optimization path. Furthermore, we devise a new 3D ConvNets with a unique design of dual-head classifier to improve spatial and temporal discrimination. Extensive experiments on seven public video recognition benchmarks demonstrate the advantages of our proposal. With the optimization planning, our 3D ConvNets achieves superior results when comparing …

Effective caching is crucial for performance of modern-day computing systems. A key optimization problem arising in caching -- which item to evict to make room for a new item -- cannot be optimally solved without knowing the future. There are many classical approximation algorithms for this problem, but more recently researchers started to successfully apply machine learning to decide what to evict by discovering implicit input patterns and predicting the future. While machine learning typically does not provide any worst-case guarantees, the new field of learning-augmented algorithms proposes solutions which leverage classical online caching algorithms to make the machine-learned predictors robust. We are the first to comprehensively evaluate these learning-augmented algorithms on real-world caching datasets and state-of-the-art machine-learned predictors. We show that a straightforward method -- blindly following either a predictor or a classical robust algorithm, and switching whenever one becomes worse than the other -- has only a low overhead over a well-performing predictor, while competing with classical methods when the coupled predictor fails, thus providing a cheap worst-case insurance.

Microfluidic biochips are being utilized for clinical diagnostics, including COVID-19 testing, because of they provide sample-to-result turnaround at low cost. Recently, microelectrode-dot-array (MEDA) biochips have been proposed to advance microfluidics technology. A MEDA biochip manipulates droplets of nano/picoliter volumes to automatically execute biochemical protocols. During bioassay execution, droplets are transported in parallel to achieve high-throughput outcomes. However, a major concern associated with the use of MEDA biochips is microelectrode degradation over time. Recent work has shown that formulating droplet transportation as a reinforcement-learning (RL) problem enables the training of policies to capture the underlying health conditions of microelectrodes and ensure reliable fluidic operations. However, the above RL-based approach suffers from two key limitations: 1) it cannot be used for concurrent transportation of multiple droplets; 2) it requires the availability of CCD cameras for monitoring droplet movement. To overcome these problems, we present a multi-agent reinforcement learning (MARL) droplet-routing solution that can be used for various sizes of MEDA biochips with integrated sensors, and we demonstrate the reliable execution of a serial-dilution bioassay with the MARL droplet router on a fabricated MEDA biochip. To facilitate further research, we also present a simulation environment based on the PettingZoo Gym Interface for MARL-guided …
Oral: Gaussian Processes 1 Thu 22 Jul 02:00 p.m.

We propose a lower bound on the log marginal likelihood of Gaussian process regression models that can be computed without matrix factorisation of the full kernel matrix. We show that approximate maximum likelihood learning of model parameters by maximising our lower bound retains many benefits of the sparse variational approach while reducing the bias introduced into hyperparameter learning. The basis of our bound is a more careful analysis of the log-determinant term appearing in the log marginal likelihood, as well as using the method of conjugate gradients to derive tight lower bounds on the term involving a quadratic form. Our approach is a step forward in unifying methods relying on lower bound maximisation (e.g. variational methods) and iterative approaches based on conjugate gradients for training Gaussian processes. In experiments, we show improved predictive performance with our model for a comparable amount of training time compared to other conjugate gradient based approaches.

We present a probabilistic model where the latent variable respects both the distances and the topology of the modeled data. The model leverages the Riemannian geometry of the generated manifold to endow the latent space with a well-defined stochastic distance measure, which is modeled locally as Nakagami distributions. These stochastic distances are sought to be as similar as possible to observed distances along a neighborhood graph through a censoring process. The model is inferred by variational inference based on observations of pairwise distances. We demonstrate how the new model can encode invariances in the learned manifolds.

Through sequential construction of posteriors on observing data online, Bayes’ theorem provides a natural framework for continual learning. We develop Variational Auto-Regressive Gaussian Processes (VAR-GPs), a principled posterior updating mechanism to solve sequential tasks in continual learning. By relying on sparse inducing point approximations for scalable posteriors, we propose a novel auto-regressive variational distribution which reveals two fruitful connections to existing results in Bayesian inference, expectation propagation and orthogonal inducing points. Mean predictive entropy estimates show VAR-GPs prevent catastrophic forgetting, which is empirically supported by strong performance on modern continual learning benchmarks against competitive baselines. A thorough ablation study demonstrates the efficacy of our modeling choices.
Approximations to Gaussian processes (GPs) based on inducing variables, combined with variational inference techniques, enable state-of-the-art sparse approaches to infer GPs at scale through mini-batch based learning. In this work, we further push the limits of scalability of sparse GPs by allowing large number of inducing variables without imposing a special structure on the inducing inputs. In particular, we introduce a novel hierarchical prior, which imposes sparsity on the set of inducing variables. We treat our model variationally, and we experimentally show considerable computational gains compared to standard sparse GPs when sparsity on the inducing variables is realized considering the nearest inducing inputs of a random mini-batch of the data. We perform an extensive experimental validation that demonstrates the effectiveness of our approach compared to the state-of-the-art. Our approach enables the possibility to use sparse GPs using a large number of inducing points without incurring a prohibitive computational cost.

Making predictions and quantifying their uncertainty when the input data is sequential is a fundamental learning challenge, recently attracting increasing attention. We develop SigGPDE, a new scalable sparse variational inference framework for Gaussian Processes (GPs) on sequential data. Our contribution is twofold. First, we construct inducing variables underpinning the sparse approximation so that the resulting evidence lower bound (ELBO) does not require any matrix inversion. Second, we show that the gradients of the GP signature kernel are solutions of a hyperbolic partial differential equation (PDE). This theoretical insight allows us to build an efficient back-propagation algorithm to optimize the ELBO. We showcase the significant computational gains of SigGPDE compared to existing methods, while achieving state-of-the-art performance for classification tasks on large datasets of up to 1 million multivariate time series.

We show that the gradient estimates used in training Deep Gaussian Processes (DGPs) with importance-weighted variational inference are susceptible to signal-to-noise ratio (SNR) issues. Specifically, we show both theoretically and via an extensive empirical evaluation that the SNR of the gradient estimates for the latent variable's variational parameters decreases as the number of importance samples increases. As a result, these gradient estimates degrade to pure noise if the number of importance samples is too large. To address this pathology, we show how doubly-reparameterized gradient estimators, originally proposed for training variational autoencoders, can be adapted to the DGP setting and that the resultant estimators completely remedy the SNR issue, thereby providing more reliable training. Finally, we demonstrate that our fix can lead to consistent improvements in the predictive performance of DGP models.

We introduce a new scalable variational Gaussian process approximation which provides a high fidelity approximation while retaining general applicability. We propose the harmonic kernel decomposition (HKD), which uses Fourier series to decompose a kernel as a sum of orthogonal kernels. Our variational approximation exploits this orthogonality to enable a large number of inducing points at a low computational cost. We demonstrate that, on a range of regression and classification problems, our approach can exploit input space symmetries such as translations and reflections, and it significantly outperforms standard variational methods in scalability and accuracy. Notably, our approach achieves state-of-the-art results on CIFAR-10 among pure GP models.
Oral: Representation Learning 1 Thu 22 Jul 02:00 p.m.

Pre-trained representations are becoming crucial for many NLP and perception tasks. While representation learning in NLP has transitioned to training on raw text without human annotations, visual and vision-language representations still rely heavily on curated training datasets that are expensive or require expert knowledge. For vision applications, representations are mostly learned using datasets with explicit class labels such as ImageNet or OpenImages. For vision-language, popular datasets like Conceptual Captions, MSCOCO, or CLIP all involve a non-trivial data collection (and cleaning) process. This costly curation process limits the size of datasets and hence hinders the scaling of trained models. In this paper, we leverage a noisy dataset of over one billion image alt-text pairs, obtained without expensive filtering or post-processing steps in the Conceptual Captions dataset. A simple dual-encoder architecture learns to align visual and language representations of the image and text pairs using a contrastive loss. We show that the scale of our corpus can make up for its noise and leads to state-of-the-art representations even with such a simple learning scheme. Our visual representation achieves strong performance when transferred to classification tasks such as ImageNet and VTAB. The aligned visual and language representations enables zero-shot image classification and also …

We present Graph Neural Diffusion (GRAND) that approaches deep learning on graphs as a continuous diffusion process and treats Graph Neural Networks (GNNs) as discretisations of an underlying PDE. In our model, the layer structure and topology correspond to the discretisation choices of temporal and spatial operators. Our approach allows a principled development of a broad new class of GNNs that are able to address the common plights of graph learning models such as depth, oversmoothing, and bottlenecks. Key to the success of our models are stability with respect to perturbations in the data and this is addressed for both implicit and explicit discretisation schemes. We develop linear and nonlinear versions of GRAND, which achieve competitive results on many standard graph benchmarks.

Identifiability is a desirable property of a statistical model: it implies that the true model parameters may be estimated to any desired precision, given sufficient computational resources and data. We study identifiability in the context of representation learning: discovering nonlinear data representations that are optimal with respect to some downstream task. When parameterized as deep neural networks, such representation functions lack identifiability in parameter space, because they are over-parameterized by design. In this paper, building on recent advances in nonlinear Independent Components Analysis, we aim to rehabilitate identifiability by showing that a large family of discriminative models are in fact identifiable in function space, up to a linear indeterminacy. Many models for representation learning in a wide variety of domains have been identifiable in this sense, including text, images and audio, state-of-the-art at time of publication. We derive sufficient conditions for linear identifiability and provide empirical support for the result on both simulated and real-world data.

We propose a novel approach to disentangle the generative factors of variation underlying a given set of observations. Our method builds upon the idea that the (unknown) low-dimensional manifold underlying the data space can be explicitly modeled as a product of submanifolds. This definition of disentanglement gives rise to a novel weakly-supervised algorithm for recovering the unknown explanatory factors behind the data. At training time, our algorithm only requires pairs of non i.i.d. data samples whose elements share at least one, possibly multidimensional, generative factor of variation. We require no knowledge on the nature of these transformations, and do not make any limiting assumption on the properties of each subspace. Our approach is easy to implement, and can be successfully applied to different kinds of data (from images to 3D surfaces) undergoing arbitrary transformations. In addition to standard synthetic benchmarks, we showcase our method in challenging real-world applications, where we compare favorably with the state of the art.

Collective Inference (CI) is a procedure designed to boost weak relational classifiers, specially for node classification tasks. Graph Neural Networks (GNNs) are strong classifiers that have been used with great success. Unfortunately, most existing practical GNNs are not most-expressive (universal). Thus, it is an open question whether one can improve strong relational node classifiers, such as GNNs, with CI. In this work, we investigate this question and propose {\em collective learning} for GNNs ---a general collective classification approach for node representation learning that increases their representation power. We show that previous attempts to incorporate CI into GNNs fail to boost their expressiveness because they do not adapt CI's Monte Carlo sampling to representation learning. We evaluate our proposed framework with a variety of state-of-the-art GNNs. Our experiments show a consistent, significant boost in node classification accuracy ---regardless of the choice of underlying GNN--- for inductive node classification in partially-labeled graphs, across five real-world network datasets.

The inductive biases of graph representation learning algorithms are often encoded in the background geometry of their embedding space. In this paper, we show that general directed graphs can be effectively represented by an embedding model that combines three components: a pseudo-Riemannian metric structure, a non-trivial global topology, and a unique likelihood function that explicitly incorporates a preferred direction in embedding space. We demonstrate the representational capabilities of this method by applying it to the task of link prediction on a series of synthetic and real directed graphs from natural language applications and biology. In particular, we show that low-dimensional cylindrical Minkowski and anti-de Sitter spacetimes can produce equal or better graph representations than curved Riemannian manifolds of higher dimensions.
Multi-source domain adaptation aims at leveraging the knowledge from multiple tasks for predicting a related target domain. Hence, a crucial aspect is to properly combine different sources based on their relations. In this paper, we analyzed the problem for aggregating source domains with different label distributions, where most recent source selection approaches fail. Our proposed algorithm differs from previous approaches in two key ways: the model aggregates multiple sources mainly through the similarity of semantic conditional distribution rather than marginal distribution; the model proposes a unified framework to select relevant sources for three popular scenarios, i.e., domain adaptation with limited label on target domain, unsupervised domain adaptation and label partial unsupervised domain adaption. We evaluate the proposed method through extensive experiments. The empirical results significantly outperform the baselines.
Oral: Reinforcement Learning 15 Thu 22 Jul 02:00 p.m.
Many transfer problems require re-using previously optimal decisions for solving new tasks, which suggests the need for learning algorithms that can modify the mechanisms for choosing certain actions independently of those for choosing others. However, there is currently no formalism nor theory for how to achieve this kind of modular credit assignment. To answer this question, we define modular credit assignment as a constraint on minimizing the algorithmic mutual information among feedback signals for different decisions. We introduce what we call the modularity criterion for testing whether a learning algorithm satisfies this constraint by performing causal analysis on the algorithm itself. We generalize the recently proposed societal decision-making framework as a more granular formalism than the Markov decision process to prove that for decision sequences that do not contain cycles, certain single-step temporal difference action-value methods meet this criterion while all policy-gradient methods do not. Empirical evidence suggests that such action-value methods are more sample efficient than policy-gradient methods on transfer problems that require only sparse changes to a sequence of previously optimal decisions.
In many machine learning problems, large-scale datasets have become the de-facto standard to train state-of-the-art deep networks at the price of heavy computation load. In this paper, we focus on condensing large training sets into significantly smaller synthetic sets which can be used to train deep neural networks from scratch with minimum drop in performance. Inspired from the recent training set synthesis methods, we propose Differentiable Siamese Augmentation that enables effective use of data augmentation to synthesize more informative synthetic images and thus achieves better performance when training networks with augmentations. Experiments on multiple image classification benchmarks demonstrate that the proposed method obtains substantial gains over the state-of-the-art, 7% improvements on CIFAR10 and CIFAR100 datasets. We show with only less than 1% data that our method achieves 99.6%, 94.9%, 88.5%, 71.5% relative performance on MNIST, FashionMNIST, SVHN, CIFAR10 respectively. We also explore the use of our method in continual learning and neural architecture search, and show promising results.

Meta-learning can successfully acquire useful inductive biases from data. Yet, its generalization properties to unseen learning tasks are poorly understood. Particularly if the number of meta-training tasks is small, this raises concerns about overfitting. We provide a theoretical analysis using the PAC-Bayesian framework and derive novel generalization bounds for meta-learning. Using these bounds, we develop a class of PAC-optimal meta-learning algorithms with performance guarantees and a principled meta-level regularization. Unlike previous PAC-Bayesian meta-learners, our method results in a standard stochastic optimization problem which can be solved efficiently and scales well.When instantiating our PAC-optimal hyper-posterior (PACOH) with Gaussian processes and Bayesian Neural Networks as base learners, the resulting methods yield state-of-the-art performance, both in terms of predictive accuracy and the quality of uncertainty estimates. Thanks to their principled treatment of uncertainty, our meta-learners can also be successfully employed for sequential decision problems.

Recent literature in few-shot learning (FSL) has shown that transductive methods often outperform their inductive counterparts. However, most transductive solutions, particularly the meta-learning based ones, require inserting trainable parameters on top of some inductive baselines to facilitate transduction. In this paper, we propose a parameterless transductive feature re-representation framework that differs from all existing solutions from the following perspectives. (1) It is widely compatible with existing FSL methods, including meta-learning and fine tuning based models. (2) The framework is simple and introduces no extra training parameters when applied to any architecture. We conduct experiments on three benchmark datasets by applying the framework to both representative meta-learning baselines and state-of-the-art FSL methods. Our framework consistently improves performances in all experiments and refreshes the state-of-the-art FSL results.

Effective lifelong learning across diverse tasks requires the transfer of diverse knowledge, yet transferring irrelevant knowledge may lead to interference and catastrophic forgetting. In deep networks, transferring the appropriate granularity of knowledge is as important as the transfer mechanism, and must be driven by the relationships among tasks. We first show that the lifelong learning performance of several current deep learning architectures can be significantly improved by transfer at the appropriate layers. We then develop an expectation-maximization (EM) method to automatically select the appropriate transfer configuration and optimize the task network weights. This EM-based selective transfer is highly effective, balancing transfer performance on all tasks with avoiding catastrophic forgetting, as demonstrated on three algorithms in several lifelong object classification scenarios.

We propose a novel algorithm for online meta learning where task instances are sequentially revealed with limited supervision and a learner is expected to meta learn them in each round, so as to allow the learner to customize a task-specific model rapidly with little task-level supervision. A fundamental concern arising in online meta-learning is the scalability of memory as more tasks are viewed over time. Heretofore, prior works have allowed for perfect recall leading to linear increase in memory with time. Different from prior works, in our method, prior task instances are allowed to be deleted. We propose to leverage prior task instances by means of a fixed-size state-vector, which is updated sequentially. Our theoretical analysis demonstrates that our proposed memory efficient online learning (MOML) method suffers sub-linear regret with convex loss functions and sub-linear local regret for nonconvex losses. On benchmark datasets we show that our method can outperform prior works even though they allow for perfect recall.
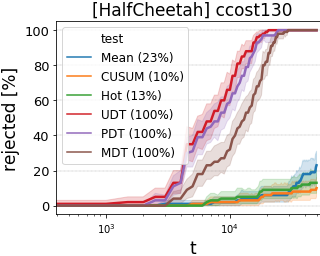
In many RL applications, once training ends, it is vital to detect any deterioration in the agent performance as soon as possible. Furthermore, it often has to be done without modifying the policy and under minimal assumptions regarding the environment. In this paper, we address this problem by focusing directly on the rewards and testing for degradation. We consider an episodic framework, where the rewards within each episode are not independent, nor identically-distributed, nor Markov. We present this problem as a multivariate mean-shift detection problem with possibly partial observations. We define the mean-shift in a way corresponding to deterioration of a temporal signal (such as the rewards), and derive a test for this problem with optimal statistical power. Empirically, on deteriorated rewards in control problems (generated using various environment modifications), the test is demonstrated to be more powerful than standard tests - often by orders of magnitude. We also suggest a novel Bootstrap mechanism for False Alarm Rate control (BFAR), applicable to episodic (non-i.i.d) signal and allowing our test to run sequentially in an online manner. Our method does not rely on a learned model of the environment, is entirely external to the agent, and in fact can be applied …
Oral: Fairness Thu 22 Jul 02:00 p.m.

Selective classification is a powerful tool for decision-making in scenarios where mistakes are costly but abstentions are allowed. In general, by allowing a classifier to abstain, one can improve the performance of a model at the cost of reducing coverage and classifying fewer samples. However, recent work has shown, in some cases, that selective classification can magnify disparities between groups, and has illustrated this phenomenon on multiple real-world datasets. We prove that the sufficiency criterion can be used to mitigate these disparities by ensuring that selective classification increases performance on all groups, and introduce a method for mitigating the disparity in precision across the entire coverage scale based on this criterion. We then provide an upper bound on the conditional mutual information between the class label and sensitive attribute, conditioned on the learned features, which can be used as a regularizer to achieve fairer selective classification. The effectiveness of the method is demonstrated on the Adult, CelebA, Civil Comments, and CheXpert datasets.

When machine predictors can achieve higher performance than the human decision-makers they support, improving the performance of human decision-makers is often conflated with improving machine accuracy. Here we propose a framework to directly support human decision-making, in which the role of machines is to reframe problems rather than to prescribe actions through prediction. Inspired by the success of representation learning in improving performance of machine predictors, our framework learns human-facing representations optimized for human performance. This “Mind Composed with Machine” framework incorporates a human decision-making model directly into the representation learning paradigm and is trained with a novel human-in-the-loop training procedure. We empirically demonstrate the successful application of the framework to various tasks and representational forms.
Strategic classification studies the interaction between a classification rule and the strategic agents it governs. Agents respond by manipulating their features, under the assumption that the classifier is known. However, in many real-life scenarios of high-stake classification (e.g., credit scoring), the classifier is not revealed to the agents, which leads agents to attempt to learn the classifier and game it too. In this paper we generalize the strategic classification model to such scenarios and analyze the effect of an unknown classifier. We define the ''price of opacity'' as the difference between the prediction error under the opaque and transparent policies, characterize it, and give a sufficient condition for it to be strictly positive, in which case transparency is the recommended policy. Our experiments show how Hardt et al.’s robust classifier is affected by keeping agents in the dark.

This work tackles the issue of fairness in the context of generative
procedures, such as image super-resolution, which entail different
definitions from the standard classification setting. Moreover,
while traditional group fairness definitions are typically defined
with respect to specified protected groups -- camouflaging the
fact that these groupings are artificial and carry historical and
political motivations -- we emphasize that there are no ground
truth identities. For instance, should South and East Asians be
viewed as a single group or separate groups? Should we consider one
race as a whole or further split by gender? Choosing which groups
are valid and who belongs in them is an impossible dilemma and being
fair'' with respect to Asians may require beingunfair'' with
respect to South Asians. This motivates the introduction of
definitions that allow algorithms to be \emph{oblivious} to the
relevant groupings.
We define several intuitive notions of group fairness and study their incompatibilities and trade-offs. We show that the natural extension of demographic parity is strongly dependent on the grouping, and \emph{impossible} to achieve obliviously. On the other hand, the conceptually new definition we introduce, Conditional Proportional Representation, can be achieved obliviously through Posterior Sampling. Our experiments validate our theoretical …

Algorithmic risk assessments are used to inform decisions in a wide variety of high-stakes settings. Often multiple predictive models deliver similar overall performance but differ markedly in their predictions for individual cases, an empirical phenomenon known as the Rashomon Effect.'' These models may have different properties over various groups, and therefore have different predictive fairness properties. We develop a framework for characterizing predictive fairness properties over the set of models that deliver similar overall performance, orthe set of good models.'' Our framework addresses the empirically relevant challenge of selectively labelled data in the setting where the selection decision and outcome are unconfounded given the observed data features. Our framework can be used to 1) audit for predictive bias; or 2) replace an existing model with one that has better fairness properties. We illustrate these use cases on a recidivism prediction task and a real-world credit-scoring task.
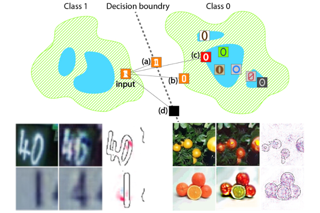
Attribution methods have been shown as promising approaches for identifying key features that led to learned model predictions. While most existing attribution methods rely on a baseline input for performing feature perturbations, limited research has been conducted to address the baseline selection issues. Poor choices of baselines limit the ability of one-vs-one explanations for multi-class classifiers, which means the attribution methods were not able to explain why an input belongs to its original class but not the other specified target class. Achieving one-vs-one explanation is crucial when certain classes are more similar than others, e.g. two bird types among multiple animals, by focusing on key differentiating features rather than shared features across classes. In this paper, we present GANMEX, a novel approach applying Generative Adversarial Networks (GAN) by incorporating the to-be-explained classifier as part of the adversarial networks. Our approach effectively selects the baseline as the closest realistic sample belong to the target class, which allows attribution methods to provide true one-vs-one explanations. We showed that GANMEX baselines improved the saliency maps and led to stronger performance on multiple evaluation metrics over the existing baselines. Existing attribution results are known for being insensitive to model randomization, and we demonstrated that …

Oral: Unsupervised Learning 1 Thu 22 Jul 02:00 p.m.

Local graph clustering is an important algorithmic technique for analysing massive graphs, and has been widely applied in many research fields of data science. While the objective of most (local) graph clustering algorithms is to find a vertex set of low conductance, there has been a sequence of recent studies that highlight the importance of the inter-connection between clusters when analysing real-world datasets. Following this line of research, in this work we study local algorithms for finding a pair of vertex sets defined with respect to their inter-connection and their relationship with the rest of the graph. The key to our analysis is a new reduction technique that relates the structure of multiple sets to a single vertex set in the reduced graph. Among many potential applications, we show that our algorithms successfully recover densely connected clusters in the Interstate Disputes Dataset and the US Migration Dataset.

Many cluster similarity indices are used to evaluate clustering algorithms, and choosing the best one for a particular task remains an open problem. We demonstrate that this problem is crucial: there are many disagreements among the indices, these disagreements do affect which algorithms are preferred in applications, and this can lead to degraded performance in real-world systems. We propose a theoretical framework to tackle this problem: we develop a list of desirable properties and conduct an extensive theoretical analysis to verify which indices satisfy them. This allows for making an informed choice: given a particular application, one can first select properties that are desirable for the task and then identify indices satisfying these. Our work unifies and considerably extends existing attempts at analyzing cluster similarity indices: we introduce new properties, formalize existing ones, and mathematically prove or disprove each property for an extensive list of validation indices. This broader and more rigorous approach leads to recommendations that considerably differ from how validation indices are currently being chosen by practitioners. Some of the most popular indices are even shown to be dominated by previously overlooked ones.



The Variational Autoencoder (VAE) performs effective nonlinear dimensionality reduction in a variety of problem settings. However, the black-box neural network decoder function typically employed limits the ability of the decoder function to be constrained and interpreted, making the use of VAEs problematic in settings where prior knowledge should be embedded within the decoder. We present DeVAE, a novel VAE-based model with a derivative-based forward mapping, allowing for greater control over decoder behaviour via specification of the decoder function in derivative space. Additionally, we show how DeVAE can be paired with a sparse clustering prior to create BasisDeVAE and perform interpretable simultaneous dimensionality reduction and feature-level clustering. We demonstrate the performance and scalability of the DeVAE and BasisDeVAE models on synthetic and real-world data and present how the derivative-based approach allows for expressive yet interpretable forward models which respect prior knowledge.

We investigate the problem of hierarchically clustering data streams containing metric data in R^d. We introduce a desirable invariance property for such algorithms, describe a general family of hyperplane-based methods enjoying this property, and analyze two scalable instances of this general family against recently popularized similarity/dissimilarity-based metrics for hierarchical clustering. We prove a number of new results related to the approximation ratios of these algorithms, improving in various ways over the literature on this subject. Finally, since our algorithms are principled but also very practical, we carry out an experimental comparison on both synthetic and real-world datasets showing competitive results against known baselines.

Oral: Deep Learning Theory 6 Thu 22 Jul 02:00 p.m.

We show that learning can be improved by using loss functions that evolve cyclically during training to emphasize one class at a time. In underparameterized networks, such dynamical loss functions can lead to successful training for networks that fail to find deep minima of the standard cross-entropy loss. In overparameterized networks, dynamical loss functions can lead to better generalization. Improvement arises from the interplay of the changing loss landscape with the dynamics of the system as it evolves to minimize the loss. In particular, as the loss function oscillates, instabilities develop in the form of bifurcation cascades, which we study using the Hessian and Neural Tangent Kernel. Valleys in the landscape widen and deepen, and then narrow and rise as the loss landscape changes during a cycle. As the landscape narrows, the learning rate becomes too large and the network becomes unstable and bounces around the valley. This process ultimately pushes the system into deeper and wider regions of the loss landscape and is characterized by decreasing eigenvalues of the Hessian. This results in better regularized models with improved generalization performance.

The reliability of deep learning algorithms is fundamentally challenged by the existence of adversarial examples, which are incorrectly classified inputs that are extremely close to a correctly classified input. We explore the properties of adversarial examples for deep neural networks with random weights and biases, and prove that for any p≥1, the ℓ^p distance of any given input from the classification boundary scales as one over the square root of the dimension of the input times the ℓ^p norm of the input. The results are based on the recently proved equivalence between Gaussian processes and deep neural networks in the limit of infinite width of the hidden layers, and are validated with experiments on both random deep neural networks and deep neural networks trained on the MNIST and CIFAR10 datasets. The results constitute a fundamental advance in the theoretical understanding of adversarial examples, and open the way to a thorough theoretical characterization of the relation between network architecture and robustness to adversarial perturbations.

Contemporary wisdom based on empirical studies suggests that standard recurrent neural networks (RNNs) do not perform well on tasks requiring long-term memory. However, RNNs' poor ability to capture long-term dependencies has not been fully understood. This paper provides a rigorous explanation of this property in the special case of linear RNNs. Although this work is limited to linear RNNs, even these systems have traditionally been difficult to analyze due to their non-linear parameterization. Using recently-developed kernel regime analysis, our main result shows that as the number of hidden units goes to infinity, linear RNNs learned from random initializations are functionally equivalent to a certain weighted 1D-convolutional network. Importantly, the weightings in the equivalent model cause an implicit bias to elements with smaller time lags in the convolution, and hence shorter memory. The degree of this bias depends on the variance of the transition matrix at initialization and is related to the classic exploding and vanishing gradients problem. The theory is validated with both synthetic and real data experiments.
Random forests on the one hand, and neural networks on the other hand, have met great success in the machine learning community for their predictive performance. Combinations of both have been proposed in the literature, notably leading to the so-called deep forests (DF) (Zhou & Feng,2019). In this paper, our aim is not to benchmark DF performances but to investigate instead their underlying mechanisms. Additionally, DF architecture can be generally simplified into more simple and computationally efficient shallow forest networks. Despite some instability, the latter may outperform standard predictive tree-based methods. We exhibit a theoretical framework in which a shallow tree network is shown to enhance the performance of classical decision trees. In such a setting, we provide tight theoretical lower and upper bounds on its excess risk. These theoretical results show the interest of tree-network architectures for well-structured data provided that the first layer, acting as a data encoder, is rich enough.

We study the relative power of learning with gradient descent on differentiable models, such as neural networks, versus using the corresponding tangent kernels. We show that under certain conditions, gradient descent achieves small error only if a related tangent kernel method achieves a non-trivial advantage over random guessing (a.k.a. weak learning), though this advantage might be very small even when gradient descent can achieve arbitrarily high accuracy. Complementing this, we show that without these conditions, gradient descent can in fact learn with small error even when no kernel method, in particular using the tangent kernel, can achieve a non-trivial advantage over random guessing.
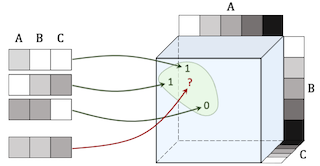
Recent efforts to unravel the mystery of implicit regularization in deep learning have led to a theoretical focus on matrix factorization --- matrix completion via linear neural network. As a step further towards practical deep learning, we provide the first theoretical analysis of implicit regularization in tensor factorization --- tensor completion via certain type of non-linear neural network. We circumvent the notorious difficulty of tensor problems by adopting a dynamical systems perspective, and characterizing the evolution induced by gradient descent. The characterization suggests a form of greedy low tensor rank search, which we rigorously prove under certain conditions, and empirically demonstrate under others. Motivated by tensor rank capturing the implicit regularization of a non-linear neural network, we empirically explore it as a measure of complexity, and find that it captures the essence of datasets on which neural networks generalize. This leads us to believe that tensor rank may pave way to explaining both implicit regularization in deep learning, and the properties of real-world data translating this implicit regularization to generalization.

Previous work has cast doubt on the general framework of uniform convergence and its ability to explain generalization in neural networks. By considering a specific dataset, it was observed that a neural network completely misclassifies a projection of the training data (adversarial set), rendering any existing generalization bound based on uniform convergence vacuous. We provide an extensive theoretical investigation of the previously studied data setting through the lens of infinitely-wide models. We prove that the Neural Tangent Kernel (NTK) also suffers from the same phenomenon and we uncover its origin. We highlight the important role of the output bias and show theoretically as well as empirically how a sensible choice completely mitigates the problem. We identify sharp phase transitions in the accuracy on the adversarial set and study its dependency on the training sample size. As a result, we are able to characterize critical sample sizes beyond which the effect disappears. Moreover, we study decompositions of a neural network into a clean and noisy part by considering its canonical decomposition into its different eigenfunctions and show empirically that for too small bias the adversarial phenomenon still persists.
Oral: Probabilistic Methods 2 Thu 22 Jul 02:00 p.m.

Particle Filtering (PF) methods are an established class of procedures for performing inference in non-linear state-space models. Resampling is a key ingredient of PF necessary to obtain low variance likelihood and states estimates. However, traditional resampling methods result in PF-based loss functions being non-differentiable with respect to model and PF parameters. In a variational inference context, resampling also yields high variance gradient estimates of the PF-based evidence lower bound. By leveraging optimal transport ideas, we introduce a principled differentiable particle filter and provide convergence results. We demonstrate this novel method on a variety of applications.


Efficient low-variance gradient estimation enabled by the reparameterization trick (RT) has been essential to the success of variational autoencoders. Doubly-reparameterized gradients (DReGs) improve on the RT for multi-sample variational bounds by applying reparameterization a second time for an additional reduction in variance. Here, we develop two generalizations of the DReGs estimator and show that they can be used to train conditional and hierarchical VAEs on image modelling tasks more effectively. We first extend the estimator to hierarchical models with several stochastic layers by showing how to treat additional score function terms due to the hierarchical variational posterior. We then generalize DReGs to score functions of arbitrary distributions instead of just those of the sampling distribution, which makes the estimator applicable to the parameters of the prior in addition to those of the posterior.

hile probabilistic circuits have been extensively explored for tabular data, less attention has been paid to time series. Here, the goal is to estimate joint densities among the entire time series and, in turn, determining, for instance, conditional independence relations between them. To this end, we propose the first probabilistic circuits (PCs) approach for modeling the joint distribution of multivariate time series, called Whittle sum-product networks (WSPNs). WSPNs leverage the Whittle approximation, casting the likelihood in the frequency domain, and place a complex-valued sum-product network, the most prominent PC, over the frequencies. The conditional independence relations among the time series can then be determined efficiently in the spectral domain. Moreover, WSPNs can naturally be placed into the deep neural learning stack for time series, resulting in Whittle Networks, opening the likelihood toolbox for training deep neural models and inspecting their behaviour. Our experiments show that Whittle Networks can indeed capture complex dependencies between time series and provide a useful measure of uncertainty for neural networks.


Neural networks are known to suffer from catastrophic forgetting when trained on sequential datasets. While there have been numerous attempts to solve this problem in large-scale supervised classification, little has been done to overcome catastrophic forgetting in few-shot classification problems. We demonstrate that the popular gradient-based model-agnostic meta-learning algorithm (MAML) indeed suffers from catastrophic forgetting and introduce a Bayesian online meta-learning framework that tackles this problem. Our framework utilises Bayesian online learning and meta-learning along with Laplace approximation and variational inference to overcome catastrophic forgetting in few-shot classification problems. The experimental evaluations demonstrate that our framework can effectively achieve this goal in comparison with various baselines. As an additional utility, we also demonstrate empirically that our framework is capable of meta-learning on sequentially arriving few-shot tasks from a stationary task distribution.

In many real world problems, we want to infer some property of an expensive black-box function f, given a budget of T function evaluations. One example is budget constrained global optimization of f, for which Bayesian optimization is a popular method. Other properties of interest include local optima, level sets, integrals, or graph-structured information induced by f. Often, we can find an algorithm A to compute the desired property, but it may require far more than T queries to execute. Given such an A, and a prior distribution over f, we refer to the problem of inferring the output of A using T evaluations as Bayesian Algorithm Execution (BAX). To tackle this problem, we present a procedure, InfoBAX, that sequentially chooses queries that maximize mutual information with respect to the algorithm's output. Applying this to Dijkstra’s algorithm, for instance, we infer shortest paths in synthetic and real-world graphs with black-box edge costs. Using evolution strategies, we yield variants of Bayesian optimization that target local, rather than global, optima. On these problems, InfoBAX uses up to 500 times fewer queries to f than required by the original algorithm. Our method is closely connected to other Bayesian optimal experimental design procedures such …
Oral: Adversarial Learning 1 Thu 22 Jul 03:00 p.m.

Randomized smoothing is a general technique for computing sample-dependent robustness guarantees against adversarial attacks for deep classifiers. Prior works on randomized smoothing against L1 adversarial attacks use additive smoothing noise and provide probabilistic robustness guarantees. In this work, we propose a non-additive and deterministic smoothing method, Deterministic Smoothing with Splitting Noise (DSSN). To develop DSSN, we first develop SSN, a randomized method which involves generating each noisy smoothing sample by first randomly splitting the input space and then returning a representation of the center of the subdivision occupied by the input sample. In contrast to uniform additive smoothing, the SSN certification does not require the random noise components used to be independent. Thus, smoothing can be done effectively in just one dimension and can therefore be efficiently derandomized for quantized data (e.g., images). To the best of our knowledge, this is the first work to provide deterministic "randomized smoothing" for a norm-based adversarial threat model while allowing for an arbitrary classifier (i.e., a deep model) to be used as a base classifier and without requiring an exponential number of smoothing samples. On CIFAR-10 and ImageNet datasets, we provide substantially larger L1 robustness certificates compared to prior works, establishing …

This paper tackles the problem of adversarial examples from a game theoretic point of view. We study the open question of the existence of mixed Nash equilibria in the zero-sum game formed by the attacker and the classifier. While previous works usually allow only one player to use randomized strategies, we show the necessity of considering randomization for both the classifier and the attacker. We demonstrate that this game has no duality gap, meaning that it always admits approximate Nash equilibria. We also provide the first optimization algorithms to learn a mixture of classifiers that approximately realizes the value of this game, \emph{i.e.} procedures to build an optimally robust randomized classifier.


There are two main attack models considered in the adversarial robustness literature: black-box and white-box. We consider these threat models as two ends of a fine-grained spectrum, indexed by the number of queries the adversary can ask. Using this point of view we investigate how many queries the adversary needs to make to design an attack that is comparable to the best possible attack in the white-box model. We give a lower bound on that number of queries in terms of entropy of decision boundaries of the classifier. Using this result we analyze two classical learning algorithms on two synthetic tasks for which we prove meaningful security guarantees. The obtained bounds suggest that some learning algorithms are inherently more robust against query-bounded adversaries than others.

Deep neural networks have been shown to be susceptible to adversarial attacks. This lack of adversarial robustness is even more pronounced when models are compressed in order to meet hardware limitations. Hence, if adversarial robustness is an issue, training of sparsely connected networks necessitates considering adversarially robust sparse learning. Motivated by the efficient and stable computational function of the brain in the presence of a highly dynamic synaptic connectivity structure, we propose an intrinsically sparse rewiring approach to train neural networks with state-of-the-art robust learning objectives under high sparsity. Importantly, in contrast to previously proposed pruning techniques, our approach satisfies global connectivity constraints throughout robust optimization, i.e., it does not require dense pre-training followed by pruning. Based on a Bayesian posterior sampling principle, a network rewiring process simultaneously learns the sparse connectivity structure and the robustness-accuracy trade-off based on the adversarial learning objective. Although our networks are sparsely connected throughout the whole training process, our experimental benchmark evaluations show that their performance is superior to recently proposed robustness-aware network pruning methods which start from densely connected networks.

Current state-of-the-art algorithms for training robust decision trees have high runtime costs and require hours to run. We present GROOT, an efficient algorithm for training robust decision trees and random forests that runs in a matter of seconds to minutes. Where before the worst-case Gini impurity was computed iteratively, we find that we can solve this function analytically to improve time complexity from O(n) to O(1) in terms of n samples. Our results on both single trees and ensembles on 14 structured datasets as well as on MNIST and Fashion-MNIST demonstrate that GROOT runs several orders of magnitude faster than the state-of-the-art works and also shows better performance in terms of adversarial accuracy on structured data.

We present a new certification method for image and point cloud segmentation based on randomized smoothing. The method leverages a novel scalable algorithm for prediction and certification that correctly accounts for multiple testing, necessary for ensuring statistical guarantees. The key to our approach is reliance on established multiple-testing correction mechanisms as well as the ability to abstain from classifying single pixels or points while still robustly segmenting the overall input. Our experimental evaluation on synthetic data and challenging datasets, such as Pascal Context, Cityscapes, and ShapeNet, shows that our algorithm can achieve, for the first time, competitive accuracy and certification guarantees on real-world segmentation tasks. We provide an implementation at https://github.com/eth-sri/segmentation-smoothing.
Oral: Representation Learning 2 Thu 22 Jul 03:00 p.m.

In representation learning, there has been recent interest in developing algorithms to disentangle the ground-truth generative factors behind a dataset, and metrics to quantify how fully this occurs. However, these algorithms and metrics often assume that both representations and ground-truth factors are flat, continuous, and factorized, whereas many real-world generative processes involve rich hierarchical structure, mixtures of discrete and continuous variables with dependence between them, and even varying intrinsic dimensionality. In this work, we develop benchmarks, algorithms, and metrics for learning such hierarchical representations.
Most of the current self-supervised representation learning (SSL) methods are based on the contrastive loss and the instance-discrimination task, where augmented versions of the same image instance ("positives") are contrasted with instances extracted from other images ("negatives"). For the learning to be effective, many negatives should be compared with a positive pair, which is computationally demanding. In this paper, we propose a different direction and a new loss function for SSL, which is based on the whitening of the latent-space features. The whitening operation has a "scattering" effect on the batch samples, avoiding degenerate solutions where all the sample representations collapse to a single point. Our solution does not require asymmetric networks and it is conceptually simple. Moreover, since negatives are not needed, we can extract multiple positive pairs from the same image instance. The source code of the method and of all the experiments is available at: https://github.com/htdt/self-supervised.

Understanding the complex structure of multivariate extremes is a major challenge in various fields from portfolio monitoring and environmental risk management to insurance. In the framework of multivariate Extreme Value Theory, a common characterization of extremes' dependence structure is the angular measure. It is a suitable measure to work in extreme regions as it provides meaningful insights concerning the subregions where extremes tend to concentrate their mass. The present paper develops a novel optimization-based approach to assess the dependence structure of extremes. This support identification scheme rewrites as estimating clusters of features which best capture the support of extremes. The dimension reduction technique we provide is applied to statistical learning tasks such as feature clustering and anomaly detection. Numerical experiments provide strong empirical evidence of the relevance of our approach.

Learning faithful graph representations as sets of vertex embeddings has become a fundamental intermediary step in a wide range of machine learning applications. We propose the systematic use of symmetric spaces in representation learning, a class encompassing many of the previously used embedding targets. This enables us to introduce a new method, the use of Finsler metrics integrated in a Riemannian optimization scheme, that better adapts to dissimilar structures in the graph. We develop a tool to analyze the embeddings and infer structural properties of the data sets. For implementation, we choose Siegel spaces, a versatile family of symmetric spaces. Our approach outperforms competitive baselines for graph reconstruction tasks on various synthetic and real-world datasets. We further demonstrate its applicability on two downstream tasks, recommender systems and node classification.

A fundamental challenge in artificial intelligence is learning useful representations of data that yield good performance on a downstream classification task, without overfitting to spurious input features. Extracting such task-relevant predictive information becomes particularly difficult for noisy and high-dimensional real-world data. In this work, we propose Contrastive Input Morphing (CIM), a representation learning framework that learns input-space transformations of the data to mitigate the effect of irrelevant input features on downstream performance. Our method leverages a perceptual similarity metric via a triplet loss to ensure that the transformation preserves task-relevant information. Empirically, we demonstrate the efficacy of our approach on various tasks which typically suffer from the presence of spurious correlations: classification with nuisance information, out-of-distribution generalization, and preservation of subgroup accuracies. We additionally show that CIM is complementary to other mutual information-based representation learning techniques, and demonstrate that it improves the performance of variational information bottleneck (VIB) when used in conjunction.
In an effort to overcome limitations of reward-driven feature learning in deep reinforcement learning (RL) from images, we propose decoupling representation learning from policy learning. To this end, we introduce a new unsupervised learning (UL) task, called Augmented Temporal Contrast (ATC), which trains a convolutional encoder to associate pairs of observations separated by a short time difference, under image augmentations and using a contrastive loss. In online RL experiments, we show that training the encoder exclusively using ATC matches or outperforms end-to-end RL in most environments. Additionally, we benchmark several leading UL algorithms by pre-training encoders on expert demonstrations and using them, with weights frozen, in RL agents; we find that agents using ATC-trained encoders outperform all others. We also train multi-task encoders on data from multiple environments and show generalization to different downstream RL tasks. Finally, we ablate components of ATC, and introduce a new data augmentation to enable replay of (compressed) latent images from pre-trained encoders when RL requires augmentation. Our experiments span visually diverse RL benchmarks in DeepMind Control, DeepMind Lab, and Atari, and our complete code is available at \url{https://github.com/astooke/rlpyt/tree/master/rlpyt/ul}.

We present a method for estimating neural scenes representations of objects given only a single image. The core of our method is the estimation of a geometric scaffold for the object and its use as a guide for the reconstruction of the underlying radiance field. Our formulation is based on a generative process that first maps a latent code to a voxelized shape, and then renders it to an image, with the object appearance being controlled by a second latent code. During inference, we optimize both the latent codes and the networks to fit a test image of a new object. The explicit disentanglement of shape and appearance allows our model to be fine-tuned given a single image. We can then render new views in a geometrically consistent manner and they represent faithfully the input object. Additionally, our method is able to generalize to images outside of the training domain (more realistic renderings and even real photographs). Finally, the inferred geometric scaffold is itself an accurate estimate of the object's 3D shape. We demonstrate in several experiments the effectiveness of our approach in both synthetic and real images.
Oral: Bayesian Learning 1 Thu 22 Jul 03:00 p.m.

We introduce Deep Adaptive Design (DAD), a method for amortizing the cost of adaptive Bayesian experimental design that allows experiments to be run in real-time. Traditional sequential Bayesian optimal experimental design approaches require substantial computation at each stage of the experiment. This makes them unsuitable for most real-world applications, where decisions must typically be made quickly. DAD addresses this restriction by learning an amortized design network upfront and then using this to rapidly run (multiple) adaptive experiments at deployment time. This network represents a design policy which takes as input the data from previous steps, and outputs the next design using a single forward pass; these design decisions can be made in milliseconds during the live experiment. To train the network, we introduce contrastive information bounds that are suitable objectives for the sequential setting, and propose a customized network architecture that exploits key symmetries. We demonstrate that DAD successfully amortizes the process of experimental design, outperforming alternative strategies on a number of problems.

Many problems in engineering design and simulation require balancing competing objectives under the presence of uncertainty. Sample-efficient multiobjective optimization methods focus on the objective function values in metric space and ignore the sampling behavior of the design configurations in parameter space. Consequently, they may provide little actionable insight on how to choose designs in the presence of metric uncertainty or limited precision when implementing a chosen design. We propose a new formulation that accounts for the importance of the parameter space and is thus more suitable for multiobjective design problems; instead of searching for the Pareto-efficient frontier, we solicit the desired minimum performance thresholds on all objectives to define regions of satisfaction. We introduce an active search algorithm called Expected Coverage Improvement (ECI) to efficiently discover the region of satisfaction and simultaneously sample diverse acceptable configurations. We demonstrate our algorithm on several design and simulation domains: mechanical design, additive manufacturing, medical monitoring, and plasma physics.

Scientists and engineers are often interested in learning the number of subpopulations (or components) present in a data set. A common suggestion is to use a finite mixture model (FMM) with a prior on the number of components. Past work has shown the resulting FMM component-count posterior is consistent; that is, the posterior concentrates on the true, generating number of components. But consistency requires the assumption that the component likelihoods are perfectly specified, which is unrealistic in practice. In this paper, we add rigor to data-analysis folk wisdom by proving that under even the slightest model misspecification, the FMM component-count posterior diverges: the posterior probability of any particular finite number of components converges to 0 in the limit of infinite data. Contrary to intuition, posterior-density consistency is not sufficient to establish this result. We develop novel sufficient conditions that are more realistic and easily checkable than those common in the asymptotics literature. We illustrate practical consequences of our theory on simulated and real data.

Riemannian manifold Hamiltonian Monte Carlo is traditionally carried out using the generalized leapfrog integrator. However, this integrator is not the only choice and other integrators yielding valid Markov chain transition operators may be considered. In this work, we examine the implicit midpoint integrator as an alternative to the generalized leapfrog integrator. We discuss advantages and disadvantages of the implicit midpoint integrator for Hamiltonian Monte Carlo, its theoretical properties, and an empirical assessment of the critical attributes of such an integrator for Hamiltonian Monte Carlo: energy conservation, volume preservation, and reversibility. Empirically, we find that while leapfrog iterations are faster, the implicit midpoint integrator has better energy conservation, leading to higher acceptance rates, as well as better conservation of volume and better reversibility, arguably yielding a more accurate sampling procedure.

Despite the success of existing tensor factorization methods, most of them conduct a multilinear decomposition, and rarely exploit powerful modeling frameworks, like deep neural networks, to capture a variety of complicated interactions in data. More important, for highly expressive, deep factorization, we lack an effective approach to handle streaming data, which are ubiquitous in real-world applications. To address these issues, we propose SBTD, a Streaming Bayesian Deep Tensor factorization method. We first use Bayesian neural networks (NNs) to build a deep tensor factorization model. We assign a spike-and-slab prior over each NN weight to encourage sparsity and to prevent overfitting. We then use multivariate Delta's method and moment matching to approximate the posterior of the NN output and calculate the running model evidence, based on which we develop an efficient streaming posterior inference algorithm in the assumed-density-filtering and expectation propagation framework. Our algorithm provides responsive incremental updates for the posterior of the latent factors and NN weights upon receiving newly observed tensor entries, and meanwhile identify and inhibit redundant/useless weights. We show the advantages of our approach in four real-world applications.

We consider the problem of learning structures and parameters of Continuous-time Bayesian Networks (CTBNs) from time-course data under minimal experimental resources. In practice, the cost of generating experimental data poses a bottleneck, especially in the natural and social sciences. A popular approach to overcome this is Bayesian optimal experimental design (BOED). However, BOED becomes infeasible in high-dimensional settings, as it involves integration over all possible experimental outcomes. We propose a novel criterion for experimental design based on a variational approximation of the expected information gain. We show that for CTBNs, a semi-analytical expression for this criterion can be calculated for structure and parameter learning. By doing so, we can replace sampling over experimental outcomes by solving the CTBNs master-equation, for which scalable approximations exist. This alleviates the computational burden of sampling possible experimental outcomes in high-dimensions. We employ this framework to recommend interventional sequences. In this context, we extend the CTBN model to conditional CTBNs to incorporate interventions. We demonstrate the performance of our criterion on synthetic and real-world data.

Attention-based neural networks have achieved state-of-the-art results on a wide range of tasks. Most such models use deterministic attention while stochastic attention is less explored due to the optimization difficulties or complicated model design. This paper introduces Bayesian attention belief networks, which construct a decoder network by modeling unnormalized attention weights with a hierarchy of gamma distributions, and an encoder network by stacking Weibull distributions with a deterministic-upward-stochastic-downward structure to approximate the posterior. The resulting auto-encoding networks can be optimized in a differentiable way with a variational lower bound. It is simple to convert any models with deterministic attention, including pretrained ones, to the proposed Bayesian attention belief networks. On a variety of language understanding tasks, we show that our method outperforms deterministic attention and state-of-the-art stochastic attention in accuracy, uncertainty estimation, generalization across domains, and robustness to adversarial attacks. We further demonstrate the general applicability of our method on neural machine translation and visual question answering, showing great potential of incorporating our method into various attention-related tasks.
Oral: Applications and Algorithms Thu 22 Jul 03:00 p.m.
Real-world data often exhibit imbalanced distributions, where certain target values have significantly fewer observations. Existing techniques for dealing with imbalanced data focus on targets with categorical indices, i.e., different classes. However, many tasks involve continuous targets, where hard boundaries between classes do not exist. We define Deep Imbalanced Regression (DIR) as learning from such imbalanced data with continuous targets, dealing with potential missing data for certain target values, and generalizing to the entire target range. Motivated by the intrinsic difference between categorical and continuous label space, we propose distribution smoothing for both labels and features, which explicitly acknowledges the effects of nearby targets, and calibrates both label and learned feature distributions. We curate and benchmark large-scale DIR datasets from common real-world tasks in computer vision, natural language processing, and healthcare domains. Extensive experiments verify the superior performance of our strategies. Our work fills the gap in benchmarks and techniques for practical imbalanced regression problems. Code and data are available at: https://github.com/YyzHarry/imbalanced-regression.

Current low-precision quantization algorithms often have the hidden cost of conversion back and forth from floating point to quantized integer values. This hidden cost limits the latency improvement realized by quantizing Neural Networks. To address this, we present HAWQ-V3, a novel mixed-precision integer-only quantization framework. The contributions of HAWQ-V3 are the following: (i) An integer-only inference where the entire computational graph is performed only with integer multiplication, addition, and bit shifting, without any floating point operations or even integer division; (ii) A novel hardware-aware mixed-precision quantization method where the bit-precision is calculated by solving an integer linear programming problem that balances the trade-off between model perturbation and other constraints, e.g., memory footprint and latency; (iii) Direct hardware deployment and open source contribution for 4-bit uniform/mixed-precision quantization in TVM, achieving an average speed up of 1.45x for uniform 4-bit, as compared to uniform 8-bit for ResNet50 on T4 GPUs; and (iv) extensive evaluation of the proposed methods on ResNet18/50 and InceptionV3, for various model compression levels with/without mixed precision. For ResNet50, our INT8 quantization achieves an accuracy of 77.58%, which is 2.68% higher than prior integer-only work, and our mixed-precision INT4/8 quantization can reduce INT8 latency by 23% and still achieve …

Nondeterminism in neural network optimization produces uncertainty in performance, making small improvements difficult to discern from run-to-run variability. While uncertainty can be reduced by training multiple model copies, doing so is time-consuming, costly, and harms reproducibility. In this work, we establish an experimental protocol for understanding the effect of optimization nondeterminism on model diversity, allowing us to isolate the effects of a variety of sources of nondeterminism. Surprisingly, we find that all sources of nondeterminism have similar effects on measures of model diversity. To explain this intriguing fact, we identify the instability of model training, taken as an end-to-end procedure, as the key determinant. We show that even one-bit changes in initial parameters result in models converging to vastly different values. Last, we propose two approaches for reducing the effects of instability on run-to-run variability.

Representing surfaces as zero level sets of neural networks recently emerged as a powerful modeling paradigm, named Implicit Neural Representations (INRs), serving numerous downstream applications in geometric deep learning and 3D vision. Training INRs previously required choosing between occupancy and distance function representation and different losses with unknown limit behavior and/or bias. In this paper we draw inspiration from the theory of phase transitions of fluids and suggest a loss for training INRs that learns a density function that converges to a proper occupancy function, while its log transform converges to a distance function. Furthermore, we analyze the limit minimizer of this loss showing it satisfies the reconstruction constraints and has minimal surface perimeter, a desirable inductive bias for surface reconstruction. Training INRs with this new loss leads to state-of-the-art reconstructions on a standard benchmark.

The size of Transformer models is growing at an unprecedented rate. It has taken less than one year to reach trillion-level parameters since the release of GPT-3 (175B). Training such models requires both substantial engineering efforts and enormous computing resources, which are luxuries most research teams cannot afford. In this paper, we propose PipeTransformer, which leverages automated elastic pipelining for efficient distributed training of Transformer models. In PipeTransformer, we design an adaptive on the fly freeze algorithm that can identify and freeze some layers gradually during training, and an elastic pipelining system that can dynamically allocate resources to train the remaining active layers. More specifically, PipeTransformer automatically excludes frozen layers from the pipeline, packs active layers into fewer GPUs, and forks more replicas to increase data-parallel width. We evaluate PipeTransformer using Vision Transformer (ViT) on ImageNet and BERT on SQuAD and GLUE datasets. Our results show that compared to the state-of-the-art baseline, PipeTransformer attains up to 2.83-fold speedup without losing accuracy. We also provide various performance analyses for a more comprehensive understanding of our algorithmic and system-wise design. Finally, we have modularized our training system with flexible APIs and made the source code publicly available at https://DistML.ai.

In this paper, we aim to solve data-driven model-based optimization (MBO) problems, where the goal is to find a design input that maximizes an unknown objective function provided access to only a static dataset of inputs and their corresponding objective values. Such data-driven optimization procedures are the only practical methods in many real-world domains where active data collection is expensive (e.g., when optimizing over proteins) or dangerous (e.g., when optimizing over aircraft designs, actively evaluating malformed aircraft designs is unsafe). Typical methods for MBO that optimize the input against a learned model of the unknown score function are affected by erroneous overestimation in the learned model caused due to distributional shift, that drives the optimizer to low-scoring or invalid inputs. To overcome this, we propose conservative objective models (COMs), a method that learns a model of the objective function which lower bounds the actual value of the ground-truth objective on out-of-distribution inputs and uses it for optimization. In practice, COMs outperform a number existing methods on a wide range of MBO problems, including optimizing controller parameters, robot morphologies, and superconducting materials.

The problem of fixing errors in programs has attracted substantial interest over the years. The key challenge for building an effective code fixing tool is to capture a wide range of errors and meanwhile maintain high accuracy. In this paper, we address this challenge and present a new learning-based system, called TFix. TFix works directly on program text and phrases the problem of code fixing as a text-to-text task. In turn, this enables it to leverage a powerful Transformer based model pre-trained on natural language and fine-tuned to generate code fixes (via a large, high-quality dataset obtained from GitHub commits). TFix is not specific to a particular programming language or class of defects and, in fact, improved its precision by simultaneously fine-tuning on 52 different error types reported by a popular static analyzer. Our evaluation on a massive dataset of JavaScript programs shows that TFix is practically effective: it is able to synthesize code that fixes the error in ~67 percent of cases and significantly outperforms existing learning-based approaches.
Oral: Applications (NLP) 1 Thu 22 Jul 03:00 p.m.
Transformer based models, like BERT and RoBERTa, have achieved state-of-the-art results in many Natural Language Processing tasks. However, their memory footprint, inference latency, and power consumption are prohibitive efficient inference at the edge, and even at the data center. While quantization can be a viable solution for this, previous work on quantizing Transformer based models use floating-point arithmetic during inference, which cannot efficiently utilize integer-only logical units such as the recent Turing Tensor Cores, or traditional integer-only ARM processors. In this work, we propose I-BERT, a novel quantization scheme for Transformer based models that quantizes the entire inference with integer-only arithmetic. Based on lightweight integer-only approximation methods for nonlinear operations, e.g., GELU, Softmax, and Layer Normalization, I-BERT performs an end-to-end integer-only BERT inference without any floating point calculation. We evaluate our approach on GLUE downstream tasks using RoBERTa-Base/Large. We show that for both cases, I-BERT achieves similar (and slightly higher) accuracy as compared to the full-precision baseline. Furthermore, our preliminary implementation of I-BERT shows a speedup of 2.4- 4.0x for INT8 inference on a T4 GPU system as compared to FP32 inference. The framework has been developed in PyTorch and has been open-sourced.

Transformer-based models are popularly used in natural language processing (NLP). Its core component, self-attention, has aroused widespread interest. To understand the self-attention mechanism, a direct method is to visualize the attention map of a pre-trained model. Based on the patterns observed, a series of efficient Transformers with different sparse attention masks have been proposed. From a theoretical perspective, universal approximability of Transformer-based models is also recently proved. However, the above understanding and analysis of self-attention is based on a pre-trained model. To rethink the importance analysis in self-attention, we study the significance of different positions in attention matrix during pre-training. A surprising result is that diagonal elements in the attention map are the least important compared with other attention positions. We provide a proof showing that these diagonal elements can indeed be removed without deteriorating model performance. Furthermore, we propose a Differentiable Attention Mask (DAM) algorithm, which further guides the design of the SparseBERT. Extensive experiments verify our interesting findings and illustrate the effect of the proposed algorithm.

Existing reasoning tasks often have an important assumption that the input contents can be always accessed while reasoning, requiring unlimited storage resources and suffering from severe time delay on long sequences. To achieve efficient reasoning on long sequences with limited storage resources, memory augmented neural networks introduce a human-like write-read memory to compress and memorize the long input sequence in one pass, trying to answer subsequent queries only based on the memory. But they have two serious drawbacks: 1) they continually update the memory from current information and inevitably forget the early contents; 2) they do not distinguish what information is important and treat all contents equally. In this paper, we propose the Rehearsal Memory (RM) to enhance long-sequence memorization by self-supervised rehearsal with a history sampler. To alleviate the gradual forgetting of early information, we design self-supervised rehearsal training with recollection and familiarity tasks. Further, we design a history sampler to select informative fragments for rehearsal training, making the memory focus on the crucial information. We evaluate the performance of our rehearsal memory by the synthetic bAbI task and several downstream tasks, including text/video question answering and recommendation on long sequences.
Recently, denoising diffusion probabilistic models and generative score matching have shown high potential in modelling complex data distributions while stochastic calculus has provided a unified point of view on these techniques allowing for flexible inference schemes. In this paper we introduce Grad-TTS, a novel text-to-speech model with score-based decoder producing mel-spectrograms by gradually transforming noise predicted by encoder and aligned with text input by means of Monotonic Alignment Search. The framework of stochastic differential equations helps us to generalize conventional diffusion probabilistic models to the case of reconstructing data from noise with different parameters and allows to make this reconstruction flexible by explicitly controlling trade-off between sound quality and inference speed. Subjective human evaluation shows that Grad-TTS is competitive with state-of-the-art text-to-speech approaches in terms of Mean Opinion Score.

We show the formal equivalence of linearised self-attention mechanisms and fast weight controllers from the early '90s, where a slow neural net learns by gradient descent to program the fast weights of another net through sequences of elementary programming instructions which are additive outer products of self-invented activation patterns (today called keys and values). Such Fast Weight Programmers (FWPs) learn to manipulate the contents of a finite memory and dynamically interact with it. We infer a memory capacity limitation of recent linearised softmax attention variants, and replace the purely additive outer products by a delta rule-like programming instruction, such that the FWP can more easily learn to correct the current mapping from keys to values. The FWP also learns to compute dynamically changing learning rates. We also propose a new kernel function to linearise attention which balances simplicity and effectiveness. We conduct experiments on synthetic retrieval problems as well as standard machine translation and language modelling tasks which demonstrate the benefits of our methods.

We propose Predict then Interpolate (PI), a simple algorithm for learning correlations that are stable across environments. The algorithm follows from the intuition that when using a classifier trained on one environment to make predictions on examples from another environment, its mistakes are informative as to which correlations are unstable. In this work, we prove that by interpolating the distributions of the correct predictions and the wrong predictions, we can uncover an oracle distribution where the unstable correlation vanishes. Since the oracle interpolation coefficients are not accessible, we use group distributionally robust optimization to minimize the worst-case risk across all such interpolations. We evaluate our method on both text classification and image classification. Empirical results demonstrate that our algorithm is able to learn robust classifiers (outperforms IRM by 23.85% on synthetic environments and 12.41% on natural environments). Our code and data are available at https://github.com/YujiaBao/ Predict-then-Interpolate.

Recent findings have shown multiple graph learning models, such as graph classification and graph matching, are highly vulnerable to adversarial attacks, i.e. small input perturbations in graph structures and node attributes can cause the model failures. Existing defense techniques often defend specific attacks on particular multiple graph learning tasks. This paper proposes an attack-agnostic graph-adaptive 1-Lipschitz neural network, ERNN, for improving the robustness of deep multiple graph learning while achieving remarkable expressive power. A Kl-Lipschitz Weibull activation function is designed to enforce the gradient norm as Kl at layer l. The nearest matrix orthogonalization and polar decomposition techniques are utilized to constraint the weight norm as 1/Kl and make the norm-constrained weight close to the original weight. The theoretical analysis is conducted to derive lower and upper bounds of feasible Kl under the 1-Lipschitz constraint. The combination of norm-constrained weight and activation function leads to the 1-Lipschitz neural network for expressive and robust multiple graph learning.
Oral: Privacy 1 Thu 22 Jul 03:00 p.m.

We propose, implement, and evaluate a new algo-rithm for releasing answers to very large numbersof statistical queries likek-way marginals, sub-ject to differential privacy. Our algorithm makesadaptive use of a continuous relaxation of thePro-jection Mechanism, which answers queries on theprivate dataset using simple perturbation, and thenattempts to find the synthetic dataset that mostclosely matches the noisy answers. We use a con-tinuous relaxation of the synthetic dataset domainwhich makes the projection loss differentiable,and allows us to use efficient ML optimizationtechniques and tooling. Rather than answering allqueries up front, we make judicious use of ourprivacy budget by iteratively finding queries forwhich our (relaxed) synthetic data has high error,and then repeating the projection. Randomizedrounding allows us to obtain synthetic data in theoriginal schema. We perform experimental evalu-ations across a range of parameters and datasets,and find that our method outperforms existingalgorithms on large query classes.


In hypothesis testing, a \emph{false discovery} occurs when a hypothesis is incorrectly rejected due to noise in the sample. When adaptively testing multiple hypotheses, the probability of a false discovery increases as more tests are performed. Thus the problem of \emph{False Discovery Rate (FDR) control} is to find a procedure for testing multiple hypotheses that accounts for this effect in determining the set of hypotheses to reject. The goal is to minimize the number (or fraction) of false discoveries, while maintaining a high true positive rate (i.e., correct discoveries). In this work, we study False Discovery Rate (FDR) control in multiple hypothesis testing under the constraint of differential privacy for the sample. Unlike previous work in this direction, we focus on the \emph{online setting}, meaning that a decision about each hypothesis must be made immediately after the test is performed, rather than waiting for the output of all tests as in the offline setting. We provide new private algorithms based on state-of-the-art results in non-private online FDR control. Our algorithms have strong provable guarantees for privacy and statistical performance as measured by FDR and power. We also provide experimental results to demonstrate the efficacy of our algorithms in a variety …

Many video classification applications require access to personal data, thereby posing an invasive security risk to the users' privacy. We propose a privacy-preserving implementation of single-frame method based video classification with convolutional neural networks that allows a party to infer a label from a video without necessitating the video owner to disclose their video to other entities in an unencrypted manner. Similarly, our approach removes the requirement of the classifier owner from revealing their model parameters to outside entities in plaintext. To this end, we combine existing Secure Multi-Party Computation (MPC) protocols for private image classification with our novel MPC protocols for oblivious single-frame selection and secure label aggregation across frames. The result is an end-to-end privacy-preserving video classification pipeline. We evaluate our proposed solution in an application for private human emotion recognition. Our results across a variety of security settings, spanning honest and dishonest majority configurations of the computing parties, and for both passive and active adversaries, demonstrate that videos can be classified with state-of-the-art accuracy, and without leaking sensitive user information.

This work addresses the problem of optimizing communications between server and clients in federated learning (FL). Current sampling approaches in FL are either biased, or non optimal in terms of server-clients communications and training stability. To overcome this issue, we introduce clustered sampling for clients selection. We prove that clustered sampling leads to better clients representatitivity and to reduced variance of the clients stochastic aggregation weights in FL. Compatibly with our theory, we provide two different clustering approaches enabling clients aggregation based on 1) sample size, and 2) models similarity. Through a series of experiments in non-iid and unbalanced scenarios, we demonstrate that model aggregation through clustered sampling consistently leads to better training convergence and variability when compared to standard sampling approaches. Our approach does not require any additional operation on the clients side, and can be seamlessly integrated in standard FL implementations. Finally, clustered sampling is compatible with existing methods and technologies for privacy enhancement, and for communication reduction through model compression.

Correlation clustering is a widely used technique in unsupervised machine learning. Motivated by applications where individual privacy is a concern, we initiate the study of differentially private correlation clustering. We propose an algorithm that achieves subquadratic additive error compared to the optimal cost. In contrast, straightforward adaptations of existing non-private algorithms all lead to a trivial quadratic error. Finally, we give a lower bound showing that any pure differentially private algorithm for correlation clustering requires additive error Ω(n).

We show that adding differential privacy to Explainable Boosting Machines (EBMs), a recent method for training interpretable ML models, yields state-of-the-art accuracy while protecting privacy. Our experiments on multiple classification and regression datasets show that DP-EBM models suffer surprisingly little accuracy loss even with strong differential privacy guarantees. In addition to high accuracy, two other benefits of applying DP to EBMs are: a) trained models provide exact global and local interpretability, which is often important in settings where differential privacy is needed; and b) the models can be edited after training without loss of privacy to correct errors which DP noise may have introduced.
Oral: Learning Theory 14 Thu 22 Jul 03:00 p.m.



We develop confidence bounds that hold uniformly over time for off-policy evaluation in the contextual bandit setting. These confidence sequences are based on recent ideas from martingale analysis and are non-asymptotic, non-parametric, and valid at arbitrary stopping times. We provide algorithms for computing these confidence sequences that strike a good balance between computational and statistical efficiency. We empirically demonstrate the tightness of our approach in terms of failure probability and width and apply it to the ``gated deployment'' problem of safely upgrading a production contextual bandit system.
We investigate the problem of best-policy identification in discounted Markov Decision Processes (MDPs) when the learner has access to a generative model. The objective is to devise a learning algorithm returning the best policy as early as possible. We first derive a problem-specific lower bound of the sample complexity satisfied by any learning algorithm. This lower bound corresponds to an optimal sample allocation that solves a non-convex program, and hence, is hard to exploit in the design of efficient algorithms. We then provide a simple and tight upper bound of the sample complexity lower bound, whose corresponding nearly-optimal sample allocation becomes explicit. The upper bound depends on specific functionals of the MDP such as the sub-optimality gaps and the variance of the next-state value function, and thus really captures the hardness of the MDP. Finally, we devise KLB-TS (KL Ball Track-and-Stop), an algorithm tracking this nearly-optimal allocation, and provide asymptotic guarantees for its sample complexity (both almost surely and in expectation). The advantages of KLB-TS against state-of-the-art algorithms are discussed and illustrated numerically.


Hindsight allows reinforcement learning agents to leverage new observations to make inferences about earlier states and transitions. In this paper, we exploit the idea of hindsight and introduce posterior value functions. Posterior value functions are computed by inferring the posterior distribution over hidden components of the state in previous timesteps and can be used to construct novel unbiased baselines for policy gradient methods. Importantly, we prove that these baselines reduce (and never increase) the variance of policy gradient estimators compared to traditional state value functions. While the posterior value function is motivated by partial observability, we extend these results to arbitrary stochastic MDPs by showing that hindsight-capable agents can model stochasticity in the environment as a special case of partial observability. Finally, we introduce a pair of methods for learning posterior value functions and prove their convergence.

Oral: Semisupervised Learning 3 Thu 22 Jul 03:00 p.m.
While semi-supervised learning (SSL) has received tremendous attentions in many machine learning tasks due to its successful use of unlabeled data, existing SSL algorithms use either all unlabeled examples or the unlabeled examples with a fixed high-confidence prediction during the training progress. However, it is possible that too many correct/wrong pseudo labeled examples are eliminated/selected. In this work we develop a simple yet powerful framework, whose key idea is to select a subset of training examples from the unlabeled data when performing existing SSL methods so that only the unlabeled examples with pseudo labels related to the labeled data will be used to train models. The selection is performed at each updating iteration by only keeping the examples whose losses are smaller than a given threshold that is dynamically adjusted through the iteration. Our proposed approach, Dash, enjoys its adaptivity in terms of unlabeled data selection and its theoretical guarantee. Specifically, we theoretically establish the convergence rate of Dash from the view of non-convex optimization. Finally, we empirically demonstrate the effectiveness of the proposed method in comparison with state-of-the-art over benchmarks.



Detecting semantic anomalies is challenging due to the countless ways in which they may appear in real-world data. While enhancing the robustness of networks may be sufficient for modeling simplistic anomalies, there is no good known way of preparing models for all potential and unseen anomalies that can potentially occur, such as the appearance of new object classes. In this paper, we show that a previously overlooked strategy for anomaly detection (AD) is to introduce an explicit inductive bias toward representations transferred over from some large and varied semantic task. We rigorously verify our hypothesis in controlled trials that utilize intervention, and show that it gives rise to surprisingly effective auxiliary objectives that outperform previous AD paradigms.


Self-training is a standard approach to semi-supervised learning where the learner's own predictions on unlabeled data are used as supervision during training. In this paper, we reinterpret this label assignment process as an optimal transportation problem between examples and classes, wherein the cost of assigning an example to a class is mediated by the current predictions of the classifier. This formulation facilitates a practical annealing strategy for label assignment and allows for the inclusion of prior knowledge on class proportions via flexible upper bound constraints. The solutions to these assignment problems can be efficiently approximated using Sinkhorn iteration, thus enabling their use in the inner loop of standard stochastic optimization algorithms. We demonstrate the effectiveness of our algorithm on the CIFAR-10, CIFAR-100, and SVHN datasets in comparison with FixMatch, a state-of-the-art self-training algorithm.
Oral: Semisupervised Learning 2 Thu 22 Jul 03:00 p.m.

Many weakly supervised classification methods employ a noise transition matrix to capture the class-conditional label corruption. To estimate the transition matrix from noisy data, existing methods often need to estimate the noisy class-posterior, which could be unreliable due to the overconfidence of neural networks. In this work, we propose a theoretically grounded method that can estimate the noise transition matrix and learn a classifier simultaneously, without relying on the error-prone noisy class-posterior estimation. Concretely, inspired by the characteristics of the stochastic label corruption process, we propose total variation regularization, which encourages the predicted probabilities to be more distinguishable from each other. Under mild assumptions, the proposed method yields a consistent estimator of the transition matrix. We show the effectiveness of the proposed method through experiments on benchmark and real-world datasets.


The healthcare industry generates troves of unlabelled physiological data. This data can be exploited via contrastive learning, a self-supervised pre-training method that encourages representations of instances to be similar to one another. We propose a family of contrastive learning methods, CLOCS, that encourages representations across space, time, \textit{and} patients to be similar to one another. We show that CLOCS consistently outperforms the state-of-the-art methods, BYOL and SimCLR, when performing a linear evaluation of, and fine-tuning on, downstream tasks. We also show that CLOCS achieves strong generalization performance with only 25\% of labelled training data. Furthermore, our training procedure naturally generates patient-specific representations that can be used to quantify patient-similarity.
Machine learning approached through supervised learning requires expensive annotation of data. This motivates weakly supervised learning, where data are annotated with incomplete yet discriminative information. In this paper, we focus on partial labelling, an instance of weak supervision where, from a given input, we are given a set of potential targets. We review a disambiguation principle to recover full supervision from weak supervision, and propose an empirical disambiguation algorithm. We prove exponential convergence rates of our algorithm under classical learnability assumptions, and we illustrate the usefulness of our method on practical examples.


We consider a linear autoencoder in which the latent variables are quantized, or corrupted by noise, and the constraint is Schur-concave in the set of latent variances. Although finding the optimal encoder/decoder pair for this setup is a nonconvex optimization problem, we show that decomposing the source into its principal components is optimal. If the constraint is strictly Schur-concave and the empirical covariance matrix has only simple eigenvalues, then any optimal encoder/decoder must decompose the source in this way. As one application, we consider a strictly Schur-concave constraint that estimates the number of bits needed to represent the latent variables under fixed-rate encoding, a setup that we call \emph{Principal Bit Analysis (PBA)}. This yields a practical, general-purpose, fixed-rate compressor that outperforms existing algorithms. As a second application, we show that a prototypical autoencoder-based variable-rate compressor is guaranteed to decompose the source into its principal components.
Oral: Privacy 3 Thu 22 Jul 04:00 p.m.

We study the problem of differentially private (DP) matrix completion under user-level privacy. We design a joint differentially private variant of the popular Alternating-Least-Squares (ALS) method that achieves: i) (nearly) optimal sample complexity for matrix completion (in terms of number of items, users), and ii) the best known privacy/utility trade-off both theoretically, as well as on benchmark data sets. In particular, we provide the first global convergence analysis of ALS with noise introduced to ensure DP, and show that, in comparison to the best known alternative (the Private Frank-Wolfe algorithm by Jain et al. (2018)), our error bounds scale significantly better with respect to the number of items and users, which is critical in practical problems. Extensive validation on standard benchmarks demonstrate that the algorithm, in combination with carefully designed sampling procedures, is significantly more accurate than existing techniques, thus promising to be the first practical DP embedding model.

Despite the considerable success of neural networks in security settings such as malware detection, such models have proved vulnerable to evasion attacks, in which attackers make slight changes to inputs (e.g., malware) to bypass detection. We propose a novel approach, Fourier stabilization, for designing evasion-robust neural networks with binary inputs. This approach, which is complementary to other forms of defense, replaces the weights of individual neurons with robust analogs derived using Fourier analytic tools. The choice of which neurons to stabilize in a neural network is then a combinatorial optimization problem, and we propose several methods for approximately solving it. We provide a formal bound on the per-neuron drop in accuracy due to Fourier stabilization, and experimentally demonstrate the effectiveness of the proposed approach in boosting robustness of neural networks in several detection settings. Moreover, we show that our approach effectively composes with adversarial training.

In this work, we consider how preference models in interactive recommendation systems determine the availability of content and users' opportunities for discovery. We propose an evaluation procedure based on stochastic reachability to quantify the maximum probability of recommending a target piece of content to an user for a set of allowable strategic modifications. This framework allows us to compute an upper bound on the likelihood of recommendation with minimal assumptions about user behavior. Stochastic reachability can be used to detect biases in the availability of content and diagnose limitations in the opportunities for discovery granted to users. We show that this metric can be computed efficiently as a convex program for a variety of practical settings, and further argue that reachability is not inherently at odds with accuracy. We demonstrate evaluations of recommendation algorithms trained on large datasets of explicit and implicit ratings. Our results illustrate how preference models, selection rules, and user interventions impact reachability and how these effects can be distributed unevenly.

We study stochastic gradient descent (SGD) with local iterations in the presence of Byzantine clients, motivated by the federated learning. The clients, instead of communicating with the server in every iteration, maintain their local models, which they update by taking several SGD iterations based on their own datasets and then communicate the net update with the server, thereby achieving communication-efficiency. Furthermore, only a subset of clients communicates with the server at synchronization times. The Byzantine clients may collude and send arbitrary vectors to the server to disrupt the learning process. To combat the adversary, we employ an efficient high-dimensional robust mean estimation algorithm at the server to filter-out corrupt vectors; and to analyze the outlier-filtering procedure, we develop a novel matrix concentration result that may be of independent interest. We provide convergence analyses for both strongly-convex and non-convex smooth objectives in the heterogeneous data setting. We believe that ours is the first Byzantine-resilient local SGD algorithm and analysis with non-trivial guarantees. We corroborate our theoretical results with preliminary experiments for neural network training.
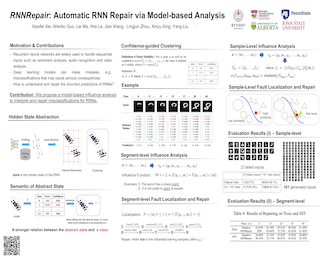
Deep neural networks are vulnerable to adversarial attacks. Due to their black-box nature, it is rather challenging to interpret and properly repair these incorrect behaviors. This paper focuses on interpreting and repairing the incorrect behaviors of Recurrent Neural Networks (RNNs). We propose a lightweight model-based approach (RNNRepair) to help understand and repair incorrect behaviors of an RNN. Specifically, we build an influence model to characterize the stateful and statistical behaviors of an RNN over all the training data and to perform the influence analysis for the errors. Compared with the existing techniques on influence function, our method can efficiently estimate the influence of existing or newly added training samples for a given prediction at both sample level and segmentation level. Our empirical evaluation shows that the proposed influence model is able to extract accurate and understandable features. Based on the influence model, our proposed technique could effectively infer the influential instances from not only an entire testing sequence but also a segment within that sequence. Moreover, with the sample-level and segment-level influence relations, RNNRepair could further remediate two types of incorrect predictions at the sample level and segment level.

In a two-player deep reinforcement learning task, recent work shows an attacker could learn an adversarial policy that triggers a target agent to perform poorly and even react in an undesired way. However, its efficacy heavily relies upon the zero-sum assumption made in the two-player game. In this work, we propose a new adversarial learning algorithm. It addresses the problem by resetting the optimization goal in the learning process and designing a new surrogate optimization function. Our experiments show that our method significantly improves adversarial agents' exploitability compared with the state-of-art attack. Besides, we also discover that our method could augment an agent with the ability to abuse the target game's unfairness. Finally, we show that agents adversarially re-trained against our adversarial agents could obtain stronger adversary-resistance.

Contextual bandit algorithms have become widely used for recommendation in online systems (e.g. marketplaces, music streaming, news), where they now wield substantial influence on which items get shown to users. This raises questions of fairness to the items --- and to the sellers, artists, and writers that benefit from this exposure. We argue that the conventional bandit formulation can lead to an undesirable and unfair winner-takes-all allocation of exposure. To remedy this problem, we propose a new bandit objective that guarantees merit-based fairness of exposure to the items while optimizing utility to the users. We formulate fairness regret and reward regret in this setting and present algorithms for both stochastic multi-armed bandits and stochastic linear bandits. We prove that the algorithms achieve sublinear fairness regret and reward regret. Beyond the theoretical analysis, we also provide empirical evidence that these algorithms can allocate exposure to different arms effectively.
Oral: Representation Learning 3 Thu 22 Jul 04:00 p.m.

The focus of disentanglement approaches has been on identifying independent factors of variation in data. However, the causal variables underlying real-world observations are often not statistically independent. In this work, we bridge the gap to real-world scenarios by analyzing the behavior of the most prominent disentanglement approaches on correlated data in a large-scale empirical study (including 4260 models). We show and quantify that systematically induced correlations in the dataset are being learned and reflected in the latent representations, which has implications for downstream applications of disentanglement such as fairness. We also demonstrate how to resolve these latent correlations, either using weak supervision during training or by post-hoc correcting a pre-trained model with a small number of labels.
Recently, neural networks purely based on attention were shown to address image understanding tasks such as image classification. These high-performing vision transformers are pre-trained with hundreds of millions of images using a large infrastructure, thereby limiting their adoption.
In this work, we produce competitive convolution-free transformers trained on ImageNet only using a single computer in less than 3 days. Our reference vision transformer (86M parameters) achieves top-1 accuracy of 83.1% (single-crop) on ImageNet with no external data.
We also introduce a teacher-student strategy specific to transformers. It relies on a distillation token ensuring that the student learns from the teacher through attention, typically from a convnet teacher. The learned transformers are competitive (85.2% top-1 acc.) with the state of the art on ImageNet, and similarly when transferred to other tasks. We will share our code and models.

Sketch drawings capture the salient information of visual concepts. Previous work has shown that neural networks are capable of producing sketches of natural objects drawn from a small number of classes. While earlier approaches focus on generation quality or retrieval, we explore properties of image representations learned by training a model to produce sketches of images. We show that this generative, class-agnostic model produces informative embeddings of images from novel examples, classes, and even novel datasets in a few-shot setting. Additionally, we find that these learned representations exhibit interesting structure and compositionality.

Evaluating the quality of learned representations without relying on a downstream task remains one of the challenges in representation learning. In this work, we present Geometric Component Analysis (GeomCA) algorithm that evaluates representation spaces based on their geometric and topological properties. GeomCA can be applied to representations of any dimension, independently of the model that generated them. We demonstrate its applicability by analyzing representations obtained from a variety of scenarios, such as contrastive learning models, generative models and supervised learning models.

We study neural-linear bandits for solving problems where {\em both} exploration and representation learning play an important role. Neural-linear bandits harnesses the representation power of Deep Neural Networks (DNNs) and combines it with efficient exploration mechanisms by leveraging uncertainty estimation of the model, designed for linear contextual bandits on top of the last hidden layer. In order to mitigate the problem of representation change during the process, new uncertainty estimations are computed using stored data from an unlimited buffer. Nevertheless, when the amount of stored data is limited, a phenomenon called catastrophic forgetting emerges. To alleviate this, we propose a likelihood matching algorithm that is resilient to catastrophic forgetting and is completely online. We applied our algorithm, Limited Memory Neural-Linear with Likelihood Matching (NeuralLinear-LiM2) on a variety of datasets and observed that our algorithm achieves comparable performance to the unlimited memory approach while exhibits resilience to catastrophic forgetting.

Learning models that gracefully handle distribution shifts is central to research on domain generalization, robust optimization, and fairness. A promising formulation is domain-invariant learning, which identifies the key issue of learning which features are domain-specific versus domain-invariant. An important assumption in this area is that the training examples are partitioned into domains'' orenvironments''. Our focus is on the more common setting where such partitions are not provided. We propose EIIL, a general framework for domain-invariant learning that incorporates Environment Inference to directly infer partitions that are maximally informative for downstream Invariant Learning. We show that EIIL outperforms invariant learning methods on the CMNIST benchmark without using environment labels, and significantly outperforms ERM on worst-group performance in the Waterbirds dataset. Finally, we establish connections between EIIL and algorithmic fairness, which enables EIIL to improve accuracy and calibration in a fair prediction problem.

Recently, neural implicit functions have achieved impressive results for encoding 3D shapes. Conditioning on low-dimensional latent codes generalises a single implicit function to learn shared representation space for a variety of shapes, with the advantage of smooth interpolation. While the benefits from the global latent space do not correspond to explicit points at local level, we propose to track the continuous point trajectory by matching implicit features with the latent code interpolating between shapes, from which we corroborate the hierarchical functionality of the deep implicit functions, where early layers map the latent code to fitting the coarse shape structure, and deeper layers further refine the shape details. Furthermore, the structured representation space of implicit functions enables to apply feature matching for shape deformation, with the benefits to handle topology and semantics inconsistency, such as from an armchair to a chair with no arms, without explicit flow functions or manual annotations.
Oral: Applications (CV and NLP) Thu 22 Jul 04:00 p.m.

Recursive Neural Networks (RvNNs), which compose sequences according to their underlying hierarchical syntactic structure, have performed well in several natural language processing tasks compared to similar models without structural biases. However, traditional RvNNs are incapable of inducing the latent structure in a plain text sequence on their own. Several extensions have been proposed to overcome this limitation. Nevertheless, these extensions tend to rely on surrogate gradients or reinforcement learning at the cost of higher bias or variance. In this work, we propose Continuous Recursive Neural Network (CRvNN) as a backpropagation-friendly alternative to address the aforementioned limitations. This is done by incorporating a continuous relaxation to the induced structure. We demonstrate that CRvNN achieves strong performance in challenging synthetic tasks such as logical inference (Bowman et al., 2015b) and ListOps (Nangia & Bowman, 2018). We also show that CRvNN performs comparably or better than prior latent structure models on real-world tasks such as sentiment analysis and natural language inference.

Processing point cloud data is an important component of many real-world systems. As such, a wide variety of point-based approaches have been proposed, reporting steady benchmark improvements over time. We study the key ingredients of this progress and uncover two critical results. First, we find that auxiliary factors like different evaluation schemes, data augmentation strategies, and loss functions, which are independent of the model architecture, make a large difference in performance. The differences are large enough that they obscure the effect of architecture. When these factors are controlled for, PointNet++, a relatively older network, performs competitively with recent methods. Second, a very simple projection-based method, which we refer to as SimpleView, performs surprisingly well. It achieves on par or better results than sophisticated state-of-the-art methods on ModelNet40 while being half the size of PointNet++. It also outperforms state-of-the-art methods on ScanObjectNN, a real-world point cloud benchmark, and demonstrates better cross-dataset generalization. Code is available at https://github.com/princeton-vl/SimpleView.

Model quantization is challenging due to many tedious hyper-parameters such as precision (bitwidth), dynamic range (minimum and maximum discrete values) and stepsize (interval between discrete values). Unlike prior arts that carefully tune these values, we present a fully differentiable approach to learn all of them, named Differentiable Dynamic Quantization (DDQ), which has several benefits. (1) DDQ is able to quantize challenging lightweight architectures like MobileNets, where different layers prefer different quantization parameters. (2) DDQ is hardware-friendly and can be easily implemented using low-precision matrix-vector multiplication, making it capable in many hardware such as ARM. (3) Extensive experiments show that DDQ outperforms prior arts on many networks and benchmarks, especially when models are already efficient and compact. e.g., DDQ is the first approach that achieves lossless 4-bit quantization for MobileNetV2 on ImageNet.

We introduce a method to determine if a certain capability helps to achieve an accurate model of given data. We view labels as being generated from the inputs by a program composed of subroutines with different capabilities, and we posit that a subroutine is useful if and only if the minimal program that invokes it is shorter than the one that does not. Since minimum program length is uncomputable, we instead estimate the labels' minimum description length (MDL) as a proxy, giving us a theoretically-grounded method for analyzing dataset characteristics. We call the method Rissanen Data Analysis (RDA) after the father of MDL, and we showcase its applicability on a wide variety of settings in NLP, ranging from evaluating the utility of generating subquestions before answering a question, to analyzing the value of rationales and explanations, to investigating the importance of different parts of speech, and uncovering dataset gender bias.

In this paper, we propose a novel method for matrix completion under general non-uniform missing structures. By controlling an upper bound of a novel balancing error, we construct weights that can actively adjust for the non-uniformity in the empirical risk without explicitly modeling the observation probabilities, and can be computed efficiently via convex optimization. The recovered matrix based on the proposed weighted empirical risk enjoys appealing theoretical guarantees. In particular, the proposed method achieves stronger guarantee than existing work in terms of the scaling with respect to the observation probabilities, under asymptotically heterogeneous missing settings (where entry-wise observation probabilities can be of different orders). These settings can be regarded as a better theoretical model of missing patterns with highly varying probabilities. We also provide a new minimax lower bound under a class of heterogeneous settings. Numerical experiments are also provided to demonstrate the effectiveness of the proposed method.

Methods that sparsify a network at initialization are important in practice because they greatly improve the efficiency of both learning and inference. Our work is based on a recently proposed decomposition of the Neural Tangent Kernel (NTK) that has decoupled the dynamics of the training process into a data-dependent component and an architecture-dependent kernel – the latter referred to as Path Kernel. That work has shown how to design sparse neural networks for faster convergence, without any training data, using the Synflow-L2 algorithm. We first show that even though Synflow-L2 is optimal in terms of convergence, for a given network density, it results in sub-networks with ``bottleneck'' (narrow) layers – leading to poor performance as compared to other data-agnostic methods that use the same number of parameters. Then we propose a new method to construct sparse networks, without any training data, referred to as Paths with Higher-Edge Weights (PHEW). PHEW is a probabilistic network formation method based on biased random walks that only depends on the initial weights. It has similar path kernel properties as Synflow-L2 but it generates much wider layers, resulting in better generalization and performance. PHEW achieves significant improvements over the data-independent SynFlow and SynFlow-L2 methods at …

Transformer model with multi-head attention requires caching intermediate results for efficient inference in generation tasks. However, cache brings new memory-related costs and prevents leveraging larger batch size for faster speed. We propose memory-efficient lossless attention (called EL-attention) to address this issue. It avoids heavy operations for building multi-head keys and values, cache for them is not needed. EL-attention constructs an ensemble of attention results by expanding query while keeping key and value shared. It produces the same result as multi-head attention with less GPU memory and faster inference speed. We conduct extensive experiments on Transformer, BART, and GPT-2 for summarization and question generation tasks. The results show EL-attention speeds up existing models by 1.6x to 5.3x without accuracy loss.
Oral: Probabilistic Methods 3 Thu 22 Jul 04:00 p.m.

Performing reliable Bayesian inference on a big data scale is becoming a keystone in the modern era of machine learning. A workhorse class of methods to achieve this task are Markov chain Monte Carlo (MCMC) algorithms and their design to handle distributed datasets has been the subject of many works. However, existing methods are not completely either reliable or computationally efficient. In this paper, we propose to fill this gap in the case where the dataset is partitioned and stored on computing nodes within a cluster under a master/slaves architecture. We derive a user-friendly centralised distributed MCMC algorithm with provable scaling in high-dimensional settings. We illustrate the relevance of the proposed methodology on both synthetic and real data experiments.

Active search is a learning paradigm where we seek to identify as many members of a rare, valuable class as possible given a labeling budget. Previous work on active search has assumed access to a faithful (and expensive) oracle reporting experimental results. However, some settings offer access to cheaper surrogates such as computational simulation that may aid in the search. We propose a model of multifidelity active search, as well as a novel, computationally efficient policy for this setting that is motivated by state-of-the-art classical policies. Our policy is nonmyopic and budget aware, allowing for a dynamic tradeoff between exploration and exploitation. We evaluate the performance of our solution on real-world datasets and demonstrate significantly better performance than natural benchmarks.

We introduce a new framework for sample-efficient model evaluation that we call active testing. While approaches like active learning reduce the number of labels needed for model training, existing literature largely ignores the cost of labeling test data, typically unrealistically assuming large test sets for model evaluation. This creates a disconnect to real applications, where test labels are important and just as expensive, e.g. for optimizing hyperparameters. Active testing addresses this by carefully selecting the test points to label, ensuring model evaluation is sample-efficient. To this end, we derive theoretically-grounded and intuitive acquisition strategies that are specifically tailored to the goals of active testing, noting these are distinct to those of active learning. As actively selecting labels introduces a bias; we further show how to remove this bias while reducing the variance of the estimator at the same time. Active testing is easy to implement and can be applied to any supervised machine learning method. We demonstrate its effectiveness on models including WideResNets and Gaussian processes on datasets including Fashion-MNIST and CIFAR-100.


This paper introduces Stochastic Gradient Langevin Boosting (SGLB) - a powerful and efficient machine learning framework that may deal with a wide range of loss functions and has provable generalization guarantees. The method is based on a special form of the Langevin diffusion equation specifically designed for gradient boosting. This allows us to theoretically guarantee the global convergence even for multimodal loss functions, while standard gradient boosting algorithms can guarantee only local optimum. We also empirically show that SGLB outperforms classic gradient boosting when applied to classification tasks with 0-1 loss function, which is known to be multimodal.
We study the attribution problem in a graphical model, wherein the objective is to quantify how the effect of changes at the source nodes propagates through the graph. We develop a model-agnostic flow-based attribution method, called recursive Shapley value (RSV). RSV generalizes a number of existing node-based methods and uniquely satisfies a set of flow-based axioms. In addition to admitting a natural characterization for linear models and facilitating mediation analysis for non-linear models, RSV satisfies a mix of desirable properties discussed in the recent literature, including implementation invariance, sensitivity, monotonicity, and affine scale invariance.

Several approximate inference algorithms have been proposed to minimize an alpha-divergence between an approximating distribution and a target distribution. Many of these algorithms introduce bias, the magnitude of which becomes problematic in high dimensions. Other algorithms are unbiased. These often seem to suffer from high variance, but little is rigorously known. In this work we study unbiased methods for alpha-divergence minimization through the Signal-to-Noise Ratio (SNR) of the gradient estimator. We study several representative scenarios where strong analytical results are possible, such as fully-factorized or Gaussian distributions. We find that when alpha is not zero, the SNR worsens exponentially in the dimensionality of the problem. This casts doubt on the practicality of these methods. We empirically confirm these theoretical results.
Oral: Privacy 2 Thu 22 Jul 04:00 p.m.
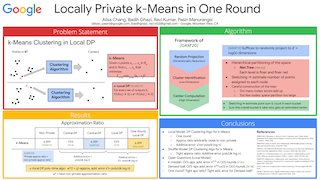
We provide an approximation algorithm for k-means clustering in the \emph{one-round} (aka \emph{non-interactive}) local model of differential privacy (DP). Our algorithm achieves an approximation ratio arbitrarily close to the best \emph{non private} approximation algorithm, improving upon previously known algorithms that only guarantee large (constant) approximation ratios. Furthermore, ours is the first constant-factor approximation algorithm for k-means that requires only \emph{one} round of communication in the local DP model, positively resolving an open question of Stemmer (SODA 2020). Our algorithmic framework is quite flexible; we demonstrate this by showing that it also yields a similar near-optimal approximation algorithm in the (one-round) shuffle DP model.

Collaborative learning allows participants to jointly train a model without data sharing. To update the model parameters, the central server broadcasts model parameters to the clients, and the clients send updating directions such as gradients to the server. While data do not leave a client device, the communicated gradients and parameters will leak a client's privacy. Attacks that infer clients' privacy from gradients and parameters have been developed by prior work. Simple defenses such as dropout and differential privacy either fail to defend the attacks or seriously hurt test accuracy. We propose a practical defense which we call Double-Blind Collaborative Learning (DBCL). The high-level idea is to apply random matrix sketching to the parameters (aka weights) and re-generate random sketching after each iteration. DBCL prevents clients from conducting gradient-based privacy inferences which are the most effective attacks. DBCL works because from the attacker's perspective, sketching is effectively random noise that outweighs the signal. Notably, DBCL does not much increase computation and communication costs and does not hurt test accuracy at all.

Inpainting is a learned interpolation technique that is based on generative modeling and used to populate masked or missing pieces in an image; it has wide applications in picture editing and retouching. Recently, inpainting started being used for watermark removal, raising concerns. In this paper we study how to manipulate it using our markpainting technique. First, we show how an image owner with access to an inpainting model can augment their image in such a way that any attempt to edit it using that model will add arbitrary visible information. We find that we can target multiple different models simultaneously with our technique. This can be designed to reconstitute a watermark if the editor had been trying to remove it. Second, we show that our markpainting technique is transferable to models that have different architectures or were trained on different datasets, so watermarks created using it are difficult for adversaries to remove. Markpainting is novel and can be used as a manipulation alarm that becomes visible in the event of inpainting. Source code is available at: https://github.com/iliaishacked/markpainting.

Clustering is a fundamental problem in data analysis. In differentially private clustering, the goal is to identify k cluster centers without disclosing information on individual data points. Despite significant research progress, the problem had so far resisted practical solutions. In this work we aim at providing simple implementable differentrially private clustering algorithms when the the data is "easy," e.g., when there exists a significant separation between the clusters.
For the easy instances we consider, we have a simple implementation based on utilizing non-private clustering algorithms, and combining them privately. We are able to get improved sample complexity bounds in some cases of Gaussian mixtures and k-means. We complement our theoretical algorithms with experiments of simulated data.

Network regression models, where the outcome comprises the valued edge in a network and the predictors are actor or dyad-level covariates, are used extensively in the social and biological sciences. Valid inference relies on accurately modeling the residual dependencies among the relations. Frequently homogeneity assumptions are placed on the errors which are commonly incorrect and ignore critical natural clustering of the actors. In this work, we present a novel regression modeling framework that models the errors as resulting from a community-based dependence structure and exploits the subsequent exchangeability properties of the error distribution to obtain parsimonious standard errors for regression parameters.

The recent rise of privacy concerns has led researchers to devise methods for private neural inference---where inferences are made directly on encrypted data, never seeing inputs. The primary challenge facing private inference is that computing on encrypted data levies an impractically-high latency penalty, stemming mostly from non-linear operators like ReLU. Enabling practical and private inference requires new optimization methods that minimize network ReLU counts while preserving accuracy. This paper proposes DeepReDuce: a set of optimizations for the judicious removal of ReLUs to reduce private inference latency. The key insight is that not all ReLUs contribute equally to accuracy. We leverage this insight to drop, or remove, ReLUs from classic networks to significantly reduce inference latency and maintain high accuracy. Given a network architecture, DeepReDuce outputs a Pareto frontier of networks that tradeoff the number of ReLUs and accuracy. Compared to the state-of-the-art for private inference DeepReDuce improves accuracy and reduces ReLU count by up to 3.5% (iso-ReLU count) and 3.5x (iso-accuracy), respectively.
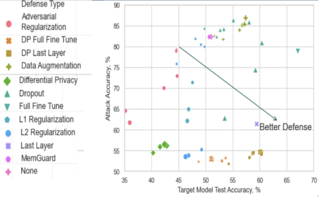
Membership inference is one of the simplest privacy threats faced by machine learning models that are trained on private sensitive data. In this attack, an adversary infers whether a particular point was used to train the model, or not, by observing the model's predictions. Whereas current attack methods all require access to the model's predicted confidence score, we introduce a label-only attack that instead evaluates the robustness of the model's predicted (hard) labels under perturbations of the input, to infer membership. Our label-only attack is not only as-effective as attacks requiring access to confidence scores, it also demonstrates that a class of defenses against membership inference, which we call ``confidence masking'' because they obfuscate the confidence scores to thwart attacks, are insufficient to prevent the leakage of private information. Our experiments show that training with differential privacy or strong L2 regularization are the only current defenses that meaningfully decrease leakage of private information, even for points that are outliers of the training distribution.
Oral: Adversarial Learning 2 Thu 22 Jul 04:00 p.m.

Transfer learning eases the burden of training a well-performed model from scratch, especially when training data is scarce and computation power is limited. In deep learning, a typical strategy for transfer learning is to freeze the early layers of a pre-trained model and fine-tune the rest of its layers on the target domain. Previous work focuses on the accuracy of the transferred model but neglects the transfer of adversarial robustness. In this work, we first show that transfer learning improves the accuracy on the target domain but degrades the inherited robustness of the target model. To address such a problem, we propose a novel cooperative adversarially-robust transfer learning (CARTL) by pre-training the model via feature distance minimization and fine-tuning the pre-trained model with non-expansive fine-tuning for target domain tasks. Empirical results show that CARTL improves the inherited robustness by about 28% at most compared with the baseline with the same degree of accuracy. Furthermore, we study the relationship between the batch normalization (BN) layers and the robustness in the context of transfer learning, and we reveal that freezing BN layers can further boost the robustness transfer.


Understanding the fundamental limits of robust supervised learning has emerged as a problem of immense interest, from both practical and theoretical standpoints. In particular, it is critical to determine classifier-agnostic bounds on the training loss to establish when learning is possible. In this paper, we determine optimal lower bounds on the cross-entropy loss in the presence of test-time adversaries, along with the corresponding optimal classification outputs. Our formulation of the bound as a solution to an optimization problem is general enough to encompass any loss function depending on soft classifier outputs. We also propose and provide a proof of correctness for a bespoke algorithm to compute this lower bound efficiently, allowing us to determine lower bounds for multiple practical datasets of interest. We use our lower bounds as a diagnostic tool to determine the effectiveness of current robust training methods and find a gap from optimality at larger budgets. Finally, we investigate the possibility of using of optimal classification outputs as soft labels to empirically improve robust training.

Modern machine learning increasingly requires training on a large collection of data from multiple sources, not all of which can be trusted. A particularly frightening scenario is when a small fraction of corrupted data changes the behavior of the trained model when triggered by an attacker-specified watermark. Such a compromised model will be deployed unnoticed as the model is accurate otherwise. There has been promising attempts to use the intermediate representations of such a model to separate corrupted examples from clean ones. However, these methods require a significant fraction of the data to be corrupted, in order to have strong enough signal for detection. We propose a novel defense algorithm using robust covariance estimation to amplify the spectral signature of corrupted data. This defense is able to completely remove backdoors whenever the benchmark backdoor attacks are successful, even in regimes where previous methods have no hope for detecting poisoned examples.

While adversarial training is considered as a standard defense method against adversarial attacks for image classifiers, adversarial purification, which purifies attacked images into clean images with a standalone purification, model has shown promises as an alternative defense method. Recently, an EBM trained with MCMC has been highlighted as a purification model, where an attacked image is purified by running a long Markov-chain using the gradients of the EBM. Yet, the practicality of the adversarial purification using an EBM remains questionable because the number of MCMC steps required for such purification is too large. In this paper, we propose a novel adversarial purification method based on an EBM trained with DSM. We show that an EBM trained with DSM can quickly purify attacked images within a few steps. We further introduce a simple yet effective randomized purification scheme that injects random noises into images before purification. This process screens the adversarial perturbations imposed on images by the random noises and brings the images to the regime where the EBM can denoise well. We show that our purification method is robust against various attacks and demonstrate its state-of-the-art performances.


Adversarial training algorithms have been proved to be reliable to improve machine learning models' robustness against adversarial examples. However, we find that adversarial training algorithms tend to introduce severe disparity of accuracy and robustness between different groups of data. For instance, PGD adversarially trained ResNet18 model on CIFAR-10 has 93% clean accuracy and 67% PGD l_infty-8 adversarial accuracy on the class ''automobile'' but only 65% and 17% on class ''cat''. This phenomenon happens in balanced datasets and does not exist in naturally trained models when only using clean samples. In this work, we empirically and theoretically show that this phenomenon can generally happen under adversarial training algorithms which minimize DNN models' robust errors. Motivated by these findings, we propose a Fair-Robust-Learning (FRL) framework to mitigate this unfairness problem when doing adversarial defenses and experimental results validate the effectiveness of FRL.
Oral: Bayesian Methods Thu 22 Jul 04:00 p.m.

Annealed Importance Sampling (AIS) and its Sequential Monte Carlo (SMC) extensions are state-of-the-art methods for estimating normalizing constants of probability distributions. We propose here a novel Monte Carlo algorithm, Annealed Flow Transport (AFT), that builds upon AIS and SMC and combines them with normalizing flows (NFs) for improved performance. This method transports a set of particles using not only importance sampling (IS), Markov chain Monte Carlo (MCMC) and resampling steps - as in SMC, but also relies on NFs which are learned sequentially to push particles towards the successive annealed targets. We provide limit theorems for the resulting Monte Carlo estimates of the normalizing constant and expectations with respect to the target distribution. Additionally, we show that a continuous-time scaling limit of the population version of AFT is given by a Feynman--Kac measure which simplifies to the law of a controlled diffusion for expressive NFs. We demonstrate experimentally the benefits and limitations of our methodology on a variety of applications.

Tensor decomposition is a powerful framework for multiway data analysis. Despite the success of existing approaches, they ignore the sparse nature of the tensor data in many real-world applications, explicitly or implicitly assuming dense tensors. To address this model misspecification and to exploit the sparse tensor structures, we propose Nonparametric dEcomposition of Sparse Tensors (\ours), which can capture both the sparse structure properties and complex relationships between the tensor nodes to enhance the embedding estimation. Specifically, we first use completely random measures to construct tensor-valued random processes. We prove that the entry growth is much slower than that of the corresponding tensor size, which implies sparsity. Given finite observations (\ie projections), we then propose two nonparametric decomposition models that couple Dirichlet processes and Gaussian processes to jointly sample the sparse entry indices and the entry values (the latter as a nonlinear mapping of the embeddings), so as to encode both the structure properties and nonlinear relationships of the tensor nodes into the embeddings. Finally, we use the stick-breaking construction and random Fourier features to develop a scalable, stochastic variational learning algorithm. We show the advantage of our approach in sparse tensor generation, and entry index and value prediction in several …

Parallel tempering (PT) is a class of Markov chain Monte Carlo algorithms that constructs a path of distributions annealing between a tractable reference and an intractable target, and then interchanges states along the path to improve mixing in the target. The performance of PT depends on how quickly a sample from the reference distribution makes its way to the target, which in turn depends on the particular path of annealing distributions. However, past work on PT has used only simple paths constructed from convex combinations of the reference and target log-densities. This paper begins by demonstrating that this path performs poorly in the setting where the reference and target are nearly mutually singular. To address this issue, we expand the framework of PT to general families of paths, formulate the choice of path as an optimization problem that admits tractable gradient estimates, and propose a flexible new family of spline interpolation paths for use in practice. Theoretical and empirical results both demonstrate that our proposed methodology breaks previously-established upper performance limits for traditional paths.

Sparse Bayesian Learning (SBL) is a powerful framework for attaining sparsity in probabilistic models. Herein, we propose a coordinate ascent algorithm for SBL termed Relevance Matching Pursuit (RMP) and show that, as its noise variance parameter goes to zero, RMP exhibits a surprising connection to Stepwise Regression. Further, we derive novel guarantees for Stepwise Regression algorithms, which also shed light on RMP. Our guarantees for Forward Regression improve on deterministic and probabilistic results for Orthogonal Matching Pursuit with noise. Our analysis of Backward Regression culminates in a bound on the residual of the optimal solution to the subset selection problem that, if satisfied, guarantees the optimality of the result. To our knowledge, this bound is the first that can be computed in polynomial time and depends chiefly on the smallest singular value of the matrix. We report numerical experiments using a variety of feature selection algorithms. Notably, RMP and its limiting variant are both efficient and maintain strong performance with correlated features.

For Bayesian learning, given likelihood function and Gaussian prior, the elliptical slice sampler, introduced by Murray, Adams and MacKay 2010, provides a tool for the construction of a Markov chain for approximate sampling of the underlying posterior distribution. Besides of its wide applicability and simplicity its main feature is that no tuning is necessary. Under weak regularity assumptions on the posterior density we show that the corresponding Markov chain is geometrically ergodic and therefore yield qualitative convergence guarantees. We illustrate our result for Gaussian posteriors as they appear in Gaussian process regression in a fully Gaussian scenario, which for example is exhibited in Gaussian process regression, as well as in a setting of a multi-modal distribution. Remarkably, our numerical experiments indicate a dimension-independent performance of elliptical slice sampling even in situations where our ergodicity result does not apply.
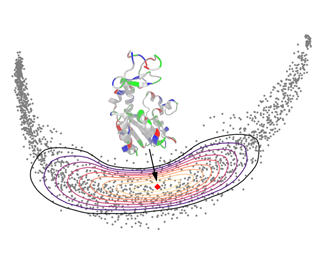
Riemannian manifolds provide a principled way to model nonlinear geometric structure inherent in data. A Riemannian metric on said manifolds determines geometry-aware shortest paths and provides the means to define statistical models accordingly. However, these operations are typically computationally demanding. To ease this computational burden, we advocate probabilistic numerical methods for Riemannian statistics. In particular, we focus on Bayesian quadrature (BQ) to numerically compute integrals over normal laws on Riemannian manifolds learned from data. In this task, each function evaluation relies on the solution of an expensive initial value problem. We show that by leveraging both prior knowledge and an active exploration scheme, BQ significantly reduces the number of required evaluations and thus outperforms Monte Carlo methods on a wide range of integration problems. As a concrete application, we highlight the merits of adopting Riemannian geometry with our proposed framework on a nonlinear dataset from molecular dynamics.

Hamiltonian Monte Carlo (HMC) is one of the most successful sampling methods in machine learning. However, its performance is significantly affected by the choice of hyperparameter values. Existing approaches for optimizing the HMC hyperparameters either optimize a proxy for mixing speed or consider the HMC chain as an implicit variational distribution and optimize a tractable lower bound that can be very loose in practice. Instead, we propose to optimize an objective that quantifies directly the speed of convergence to the target distribution. Our objective can be easily optimized using stochastic gradient descent. We evaluate our proposed method and compare to baselines on a variety of problems including sampling from synthetic 2D distributions, reconstructing sparse signals, learning deep latent variable models and sampling molecular configurations from the Boltzmann distribution of a 22 atom molecule. We find that our method is competitive with or improves upon alternative baselines in all these experiments.
Oral: Domain Generalization and Multi-task Learning Thu 22 Jul 04:00 p.m.

In the domain generalization literature, a common objective is to learn representations independent of the domain after conditioning on the class label. We show that this objective is not sufficient: there exist counter-examples where a model fails to generalize to unseen domains even after satisfying class-conditional domain invariance. We formalize this observation through a structural causal model and show the importance of modeling within-class variations for generalization. Specifically, classes contain objects that characterize specific causal features, and domains can be interpreted as interventions on these objects that change non-causal features. We highlight an alternative condition: inputs across domains should have the same representation if they are derived from the same object. Based on this objective, we propose matching-based algorithms when base objects are observed (e.g., through data augmentation) and approximate the objective when objects are not observed (MatchDG). Our simple matching-based algorithms are competitive to prior work on out-of-domain accuracy for rotated MNIST, Fashion-MNIST, PACS, and Chest-Xray datasets. Our method MatchDG also recovers ground-truth object matches: on MNIST and Fashion-MNIST, top-10 matches from MatchDG have over 50% overlap with ground-truth matches.

In this paper, we propose a novel noise-robust semi-supervised deep generative model by jointly tackling noisy labels and outliers simultaneously in a unified robust semi-supervised variational autoencoder (URSVAE). Typically, the uncertainty of of input data is characterized by placing uncertainty prior on the parameters of the probability density distributions in order to ensure the robustness of the variational encoder towards outliers. Subsequently, a noise transition model is integrated naturally into our model to alleviate the detrimental effects of noisy labels. Moreover, a robust divergence measure is employed to further enhance the robustness, where a novel variational lower bound is derived and optimized to infer the network parameters. By proving the influence function on the proposed evidence lower bound is bounded, the enormous potential of the proposed model in the classification in the presence of the compound noise is demonstrated. The experimental results highlight the superiority of the proposed framework by the evaluating on image classification tasks and comparing with the state-of-the-art approaches.

Regression, as a counterpart to classification, is a major paradigm with a wide range of applications. Domain adaptation regression extends it by generalizing a regressor from a labeled source domain to an unlabeled target domain. Existing domain adaptation regression methods have achieved positive results limited only to the shallow regime. A question arises: Why learning invariant representations in the deep regime less pronounced? A key finding of this paper is that classification is robust to feature scaling but regression is not, and aligning the distributions of deep representations will alter feature scale and impede domain adaptation regression. Based on this finding, we propose to close the domain gap through orthogonal bases of the representation spaces, which are free from feature scaling. Inspired by Riemannian geometry of Grassmann manifold, we define a geometrical distance over representation subspaces and learn deep transferable representations by minimizing it. To avoid breaking the geometrical properties of deep representations, we further introduce the bases mismatch penalization to match the ordering of orthogonal bases across representation subspaces. Our method is evaluated on three domain adaptation regression benchmarks, two of which are introduced in this paper. Our method outperforms the state-of-the-art methods significantly, forming early positive results in …

Personalized federated learning is tasked with training machine learning models for multiple clients, each with its own data distribution. The goal is to train personalized models collaboratively while accounting for data disparities across clients and reducing communication costs.
We propose a novel approach to this problem using hypernetworks, termed pFedHN for personalized Federated HyperNetworks. In this approach, a central hypernetwork model is trained to generate a set of models, one model for each client. This architecture provides effective parameter sharing across clients while maintaining the capacity to generate unique and diverse personal models. Furthermore, since hypernetwork parameters are never transmitted, this approach decouples the communication cost from the trainable model size. We test pFedHN empirically in several personalized federated learning challenges and find that it outperforms previous methods. Finally, since hypernetworks share information across clients, we show that pFedHN can generalize better to new clients whose distributions differ from any client observed during training.

Unsupervised domain adaptation is used in many machine learning applications where, during training, a model has access to unlabeled data in the target domain, and a related labeled dataset. In this paper, we introduce a novel and general domain-adversarial framework. Specifically, we derive a novel generalization bound for domain adaptation that exploits a new measure of discrepancy between distributions based on a variational characterization of f-divergences. It recovers the theoretical results from Ben-David et al. (2010a) as a special case and supports divergences used in practice. Based on this bound, we derive a new algorithmic framework that introduces a key correction in the original adversarial training method of Ganin et al. (2016). We show that many regularizers and ad-hoc objectives introduced over the last years in this framework are then not required to achieve performance comparable to (if not better than) state-of-the-art domain-adversarial methods. Experimental analysis conducted on real-world natural language and computer vision datasets show that our framework outperforms existing baselines, and obtains the best results for f-divergences that were not considered previously in domain-adversarial learning.

We develop a novel approach to conformal prediction when the target task has limited data available for training. Conformal prediction identifies a small set of promising output candidates in place of a single prediction, with guarantees that the set contains the correct answer with high probability. When training data is limited, however, the predicted set can easily become unusably large. In this work, we obtain substantially tighter prediction sets while maintaining desirable marginal guarantees by casting conformal prediction as a meta-learning paradigm over exchangeable collections of auxiliary tasks. Our conformalization algorithm is simple, fast, and agnostic to the choice of underlying model, learning algorithm, or dataset. We demonstrate the effectiveness of this approach across a number of few-shot classification and regression tasks in natural language processing, computer vision, and computational chemistry for drug discovery.

Few-shot dataset generalization is a challenging variant of the well-studied few-shot classification problem where a diverse training set of several datasets is given, for the purpose of training an adaptable model that can then learn classes from \emph{new datasets} using only a few examples. To this end, we propose to utilize the diverse training set to construct a \emph{universal template}: a partial model that can define a wide array of dataset-specialized models, by plugging in appropriate components. For each new few-shot classification problem, our approach therefore only requires inferring a small number of parameters to insert into the universal template. We design a separate network that produces an initialization of those parameters for each given task, and we then fine-tune its proposed initialization via a few steps of gradient descent. Our approach is more parameter-efficient, scalable and adaptable compared to previous methods, and achieves the state-of-the-art on the challenging Meta-Dataset benchmark.
Oral: Semisupervised and Unsupervised Learning 1 Thu 22 Jul 04:00 p.m.

Self-supervised learning on graph-structured data has drawn recent interest for learning generalizable, transferable and robust representations from unlabeled graphs. Among many, graph contrastive learning (GraphCL) has emerged with promising representation learning performance. Unfortunately, unlike its counterpart on image data, the effectiveness of GraphCL hinges on ad-hoc data augmentations, which have to be manually picked per dataset, by either rules of thumb or trial-and-errors, owing to the diverse nature of graph data. That significantly limits the more general applicability of GraphCL. Aiming to fill in this crucial gap, this paper proposes a unified bi-level optimization framework to automatically, adaptively and dynamically select data augmentations when performing GraphCL on specific graph data. The general framework, dubbed JOint Augmentation Optimization (JOAO), is instantiated as min-max optimization. The selections of augmentations made by JOAO are shown to be in general aligned with previous "best practices" observed from handcrafted tuning: yet now being automated, more flexible and versatile. Moreover, we propose a new augmentation-aware projection head mechanism, which will route output features through different projection heads corresponding to different augmentations chosen at each training step. Extensive experiments demonstrate that JOAO performs on par with or sometimes better than the state-of-the-art competitors including GraphCL, on multiple …

Self-supervised learning (SSL) is rapidly closing the gap with supervised methods on large computer vision benchmarks. A successful approach to SSL is to learn embeddings which are invariant to distortions of the input sample. However, a recurring issue with this approach is the existence of trivial constant solutions. Most current methods avoid such solutions by careful implementation details. We propose an objective function that naturally avoids collapse by measuring the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of a sample, and making it as close to the identity matrix as possible. This causes the embedding vectors of distorted versions of a sample to be similar, while minimizing the redundancy between the components of these vectors. The method is called Barlow Twins, owing to neuroscientist H. Barlow's redundancy-reduction principle applied to a pair of identical networks. Barlow Twins does not require large batches nor asymmetry between the network twins such as a predictor network, gradient stopping, or a moving average on the weight updates. Intriguingly it benefits from very high-dimensional output vectors. Barlow Twins outperforms previous methods on ImageNet for semi-supervised classification in the low-data regime, and is on par with current state of the …

To alleviate the data requirement for training effective binary classifiers in binary classification, many weakly supervised learning settings have been proposed. Among them, some consider using pairwise but not pointwise labels, when pointwise labels are not accessible due to privacy, confidentiality, or security reasons. However, as a pairwise label denotes whether or not two data points share a pointwise label, it cannot be easily collected if either point is equally likely to be positive or negative. Thus, in this paper, we propose a novel setting called pairwise comparison (Pcomp) classification, where we have only pairs of unlabeled data that we know one is more likely to be positive than the other. Firstly, we give a Pcomp data generation process, derive an unbiased risk estimator (URE) with theoretical guarantee, and further improve URE using correction functions. Secondly, we link Pcomp classification to noisy-label learning to develop a progressive URE and improve it by imposing consistency regularization. Finally, we demonstrate by experiments the effectiveness of our methods, which suggests Pcomp is a valuable and practically useful type of pairwise supervision besides the pairwise label.

Weakly supervised learning has drawn considerable attention recently to reduce the expensive time and labor consumption of labeling massive data. In this paper, we investigate a novel weakly supervised learning problem of learning from similarity-confidence (Sconf) data, where only unlabeled data pairs equipped with confidence that illustrates their degree of similarity (two examples are similar if they belong to the same class) are needed for training a discriminative binary classifier. We propose an unbiased estimator of the classification risk that can be calculated from only Sconf data and show that the estimation error bound achieves the optimal convergence rate. To alleviate potential overfitting when flexible models are used, we further employ a risk correction scheme on the proposed risk estimator. Experimental results demonstrate the effectiveness of the proposed methods.

Co-part segmentation is an important problem in computer vision for its rich applications. We propose an unsupervised learning approach for co-part segmentation from images. For the training stage, we leverage motion information embedded in videos and explicitly extract latent representations to segment meaningful object parts. More importantly, we introduce a dual procedure of part-assembly to form a closed loop with part-segmentation, enabling an effective self-supervision. We demonstrate the effectiveness of our approach with a host of extensive experiments, ranging from human bodies, hands, quadruped, and robot arms. We show that our approach can achieve meaningful and compact part segmentation, outperforming state-of-the-art approaches on diverse benchmarks.


We address the problem of learning binary decision trees that partition data for some downstream task. We propose to learn discrete parameters (i.e., for tree traversals and node pruning) and continuous parameters (i.e., for tree split functions and prediction functions) simultaneously using argmin differentiation. We do so by sparsely relaxing a mixed-integer program for the discrete parameters, to allow gradients to pass through the program to continuous parameters. We derive customized algorithms to efficiently compute the forward and backward passes. This means that our tree learning procedure can be used as an (implicit) layer in arbitrary deep networks, and can be optimized with arbitrary loss functions. We demonstrate that our approach produces binary trees that are competitive with existing single tree and ensemble approaches, in both supervised and unsupervised settings. Further, apart from greedy approaches (which do not have competitive accuracies), our method is faster to train than all other tree-learning baselines we compare with.
Social: Open Collaboration in ML Research Thu 22 Jul 05:00 p.m.
Making AI research more inviting, inclusive, and accessible is a difficult task, but the movement to do so is close to many researchers' hearts. Progress toward democratizing AI research has been centered around making knowledge (e.g. class materials), established ideas (e.g. papers), and technologies (e.g. code) more accessible. However, open, online resources are only part of the equation. Growth as a researcher requires not only learning by consuming information individually, but hands-on practicewhiteboarding, coding, plotting, debugging, and writing collaboratively, with either mentors or peers. Of course, making ""collaborators"" more universally accessible is fundamentally more difficult than, say, ensuring all can access arXiv papers, because scaling people and research groups is much harder than scaling websites. Can we nevertheless make access to collaboration itself more open? Can we flatten access to peers and mentors so the opportunities available to those at the best industrial and academic labs are more broadly available to all entrants to our burgeoning field? How can we kick-start remote, non-employment based research collaborations more effectively? This social is designed to discuss these topics and help you meet potential collaborators, find interesting ideas, and kick-start your next project.
Invited Talk: Cecilia Clementi
Machine Learning for Molecular Science
I present an overview of the different ways machine learning is making an impact in molecular science. In particular I focus on theoretical and computational biophysics at the molecular scale, and how machine learning is revolutionizing molecular simulation techniques. I present some of the methods developed in the last few years, the results that have been obtained and the challenges ahead. I describe in some detail the application of machine learning to the development of molecular models for biological macromolecules at resolutions coarser than atomistic, that can accurately reproduce the behavior of the system as described by atomistic models or experimental measurements.
Bio :
Poster Session 5 Thu 22 Jul 06:00 p.m.
[ Virtual ]
We consider the problem of learning structures and parameters of Continuous-time Bayesian Networks (CTBNs) from time-course data under minimal experimental resources. In practice, the cost of generating experimental data poses a bottleneck, especially in the natural and social sciences. A popular approach to overcome this is Bayesian optimal experimental design (BOED). However, BOED becomes infeasible in high-dimensional settings, as it involves integration over all possible experimental outcomes. We propose a novel criterion for experimental design based on a variational approximation of the expected information gain. We show that for CTBNs, a semi-analytical expression for this criterion can be calculated for structure and parameter learning. By doing so, we can replace sampling over experimental outcomes by solving the CTBNs master-equation, for which scalable approximations exist. This alleviates the computational burden of sampling possible experimental outcomes in high-dimensions. We employ this framework to recommend interventional sequences. In this context, we extend the CTBN model to conditional CTBNs to incorporate interventions. We demonstrate the performance of our criterion on synthetic and real-world data.
[ Virtual ]
We introduce a new framework for sample-efficient model evaluation that we call active testing. While approaches like active learning reduce the number of labels needed for model training, existing literature largely ignores the cost of labeling test data, typically unrealistically assuming large test sets for model evaluation. This creates a disconnect to real applications, where test labels are important and just as expensive, e.g. for optimizing hyperparameters. Active testing addresses this by carefully selecting the test points to label, ensuring model evaluation is sample-efficient. To this end, we derive theoretically-grounded and intuitive acquisition strategies that are specifically tailored to the goals of active testing, noting these are distinct to those of active learning. As actively selecting labels introduces a bias; we further show how to remove this bias while reducing the variance of the estimator at the same time. Active testing is easy to implement and can be applied to any supervised machine learning method. We demonstrate its effectiveness on models including WideResNets and Gaussian processes on datasets including Fashion-MNIST and CIFAR-100.
[ Virtual ]

[ Virtual ]
We investigate the problem of best-policy identification in discounted Markov Decision Processes (MDPs) when the learner has access to a generative model. The objective is to devise a learning algorithm returning the best policy as early as possible. We first derive a problem-specific lower bound of the sample complexity satisfied by any learning algorithm. This lower bound corresponds to an optimal sample allocation that solves a non-convex program, and hence, is hard to exploit in the design of efficient algorithms. We then provide a simple and tight upper bound of the sample complexity lower bound, whose corresponding nearly-optimal sample allocation becomes explicit. The upper bound depends on specific functionals of the MDP such as the sub-optimality gaps and the variance of the next-state value function, and thus really captures the hardness of the MDP. Finally, we devise KLB-TS (KL Ball Track-and-Stop), an algorithm tracking this nearly-optimal allocation, and provide asymptotic guarantees for its sample complexity (both almost surely and in expectation). The advantages of KLB-TS against state-of-the-art algorithms are discussed and illustrated numerically.
[ Virtual ]
Neural networks are known to suffer from catastrophic forgetting when trained on sequential datasets. While there have been numerous attempts to solve this problem in large-scale supervised classification, little has been done to overcome catastrophic forgetting in few-shot classification problems. We demonstrate that the popular gradient-based model-agnostic meta-learning algorithm (MAML) indeed suffers from catastrophic forgetting and introduce a Bayesian online meta-learning framework that tackles this problem. Our framework utilises Bayesian online learning and meta-learning along with Laplace approximation and variational inference to overcome catastrophic forgetting in few-shot classification problems. The experimental evaluations demonstrate that our framework can effectively achieve this goal in comparison with various baselines. As an additional utility, we also demonstrate empirically that our framework is capable of meta-learning on sequentially arriving few-shot tasks from a stationary task distribution.
[ Virtual ]
While adversarial training is considered as a standard defense method against adversarial attacks for image classifiers, adversarial purification, which purifies attacked images into clean images with a standalone purification, model has shown promises as an alternative defense method. Recently, an EBM trained with MCMC has been highlighted as a purification model, where an attacked image is purified by running a long Markov-chain using the gradients of the EBM. Yet, the practicality of the adversarial purification using an EBM remains questionable because the number of MCMC steps required for such purification is too large. In this paper, we propose a novel adversarial purification method based on an EBM trained with DSM. We show that an EBM trained with DSM can quickly purify attacked images within a few steps. We further introduce a simple yet effective randomized purification scheme that injects random noises into images before purification. This process screens the adversarial perturbations imposed on images by the random noises and brings the images to the regime where the EBM can denoise well. We show that our purification method is robust against various attacks and demonstrate its state-of-the-art performances.
[ Virtual ]
The reliability of deep learning algorithms is fundamentally challenged by the existence of adversarial examples, which are incorrectly classified inputs that are extremely close to a correctly classified input. We explore the properties of adversarial examples for deep neural networks with random weights and biases, and prove that for any p≥1, the ℓ^p distance of any given input from the classification boundary scales as one over the square root of the dimension of the input times the ℓ^p norm of the input. The results are based on the recently proved equivalence between Gaussian processes and deep neural networks in the limit of infinite width of the hidden layers, and are validated with experiments on both random deep neural networks and deep neural networks trained on the MNIST and CIFAR10 datasets. The results constitute a fundamental advance in the theoretical understanding of adversarial examples, and open the way to a thorough theoretical characterization of the relation between network architecture and robustness to adversarial perturbations.
[ Virtual ]
Multi-source domain adaptation aims at leveraging the knowledge from multiple tasks for predicting a related target domain. Hence, a crucial aspect is to properly combine different sources based on their relations. In this paper, we analyzed the problem for aggregating source domains with different label distributions, where most recent source selection approaches fail. Our proposed algorithm differs from previous approaches in two key ways: the model aggregates multiple sources mainly through the similarity of semantic conditional distribution rather than marginal distribution; the model proposes a unified framework to select relevant sources for three popular scenarios, i.e., domain adaptation with limited label on target domain, unsupervised domain adaptation and label partial unsupervised domain adaption. We evaluate the proposed method through extensive experiments. The empirical results significantly outperform the baselines.
[ Virtual ]
[ Virtual ]
Self-supervised learning (SSL) is rapidly closing the gap with supervised methods on large computer vision benchmarks. A successful approach to SSL is to learn embeddings which are invariant to distortions of the input sample. However, a recurring issue with this approach is the existence of trivial constant solutions. Most current methods avoid such solutions by careful implementation details. We propose an objective function that naturally avoids collapse by measuring the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of a sample, and making it as close to the identity matrix as possible. This causes the embedding vectors of distorted versions of a sample to be similar, while minimizing the redundancy between the components of these vectors. The method is called Barlow Twins, owing to neuroscientist H. Barlow's redundancy-reduction principle applied to a pair of identical networks. Barlow Twins does not require large batches nor asymmetry between the network twins such as a predictor network, gradient stopping, or a moving average on the weight updates. Intriguingly it benefits from very high-dimensional output vectors. Barlow Twins outperforms previous methods on ImageNet for semi-supervised classification in the low-data regime, and is on par with current state of the …
[ Virtual ]
The Variational Autoencoder (VAE) performs effective nonlinear dimensionality reduction in a variety of problem settings. However, the black-box neural network decoder function typically employed limits the ability of the decoder function to be constrained and interpreted, making the use of VAEs problematic in settings where prior knowledge should be embedded within the decoder. We present DeVAE, a novel VAE-based model with a derivative-based forward mapping, allowing for greater control over decoder behaviour via specification of the decoder function in derivative space. Additionally, we show how DeVAE can be paired with a sparse clustering prior to create BasisDeVAE and perform interpretable simultaneous dimensionality reduction and feature-level clustering. We demonstrate the performance and scalability of the DeVAE and BasisDeVAE models on synthetic and real-world data and present how the derivative-based approach allows for expressive yet interpretable forward models which respect prior knowledge.
[ Virtual ]
In many real world problems, we want to infer some property of an expensive black-box function f, given a budget of T function evaluations. One example is budget constrained global optimization of f, for which Bayesian optimization is a popular method. Other properties of interest include local optima, level sets, integrals, or graph-structured information induced by f. Often, we can find an algorithm A to compute the desired property, but it may require far more than T queries to execute. Given such an A, and a prior distribution over f, we refer to the problem of inferring the output of A using T evaluations as Bayesian Algorithm Execution (BAX). To tackle this problem, we present a procedure, InfoBAX, that sequentially chooses queries that maximize mutual information with respect to the algorithm's output. Applying this to Dijkstra’s algorithm, for instance, we infer shortest paths in synthetic and real-world graphs with black-box edge costs. Using evolution strategies, we yield variants of Bayesian optimization that target local, rather than global, optima. On these problems, InfoBAX uses up to 500 times fewer queries to f than required by the original algorithm. Our method is closely connected to other Bayesian optimal experimental design procedures such …
[ Virtual ]
Many problems in engineering design and simulation require balancing competing objectives under the presence of uncertainty. Sample-efficient multiobjective optimization methods focus on the objective function values in metric space and ignore the sampling behavior of the design configurations in parameter space. Consequently, they may provide little actionable insight on how to choose designs in the presence of metric uncertainty or limited precision when implementing a chosen design. We propose a new formulation that accounts for the importance of the parameter space and is thus more suitable for multiobjective design problems; instead of searching for the Pareto-efficient frontier, we solicit the desired minimum performance thresholds on all objectives to define regions of satisfaction. We introduce an active search algorithm called Expected Coverage Improvement (ECI) to efficiently discover the region of satisfaction and simultaneously sample diverse acceptable configurations. We demonstrate our algorithm on several design and simulation domains: mechanical design, additive manufacturing, medical monitoring, and plasma physics.
[ Virtual ]
We study stochastic gradient descent (SGD) with local iterations in the presence of Byzantine clients, motivated by the federated learning. The clients, instead of communicating with the server in every iteration, maintain their local models, which they update by taking several SGD iterations based on their own datasets and then communicate the net update with the server, thereby achieving communication-efficiency. Furthermore, only a subset of clients communicates with the server at synchronization times. The Byzantine clients may collude and send arbitrary vectors to the server to disrupt the learning process. To combat the adversary, we employ an efficient high-dimensional robust mean estimation algorithm at the server to filter-out corrupt vectors; and to analyze the outlier-filtering procedure, we develop a novel matrix concentration result that may be of independent interest. We provide convergence analyses for both strongly-convex and non-convex smooth objectives in the heterogeneous data setting. We believe that ours is the first Byzantine-resilient local SGD algorithm and analysis with non-trivial guarantees. We corroborate our theoretical results with preliminary experiments for neural network training.
[ Virtual ]
Transfer learning eases the burden of training a well-performed model from scratch, especially when training data is scarce and computation power is limited. In deep learning, a typical strategy for transfer learning is to freeze the early layers of a pre-trained model and fine-tune the rest of its layers on the target domain. Previous work focuses on the accuracy of the transferred model but neglects the transfer of adversarial robustness. In this work, we first show that transfer learning improves the accuracy on the target domain but degrades the inherited robustness of the target model. To address such a problem, we propose a novel cooperative adversarially-robust transfer learning (CARTL) by pre-training the model via feature distance minimization and fine-tuning the pre-trained model with non-expansive fine-tuning for target domain tasks. Empirical results show that CARTL improves the inherited robustness by about 28% at most compared with the baseline with the same degree of accuracy. Furthermore, we study the relationship between the batch normalization (BN) layers and the robustness in the context of transfer learning, and we reveal that freezing BN layers can further boost the robustness transfer.
[ Virtual ]
Algorithmic risk assessments are used to inform decisions in a wide variety of high-stakes settings. Often multiple predictive models deliver similar overall performance but differ markedly in their predictions for individual cases, an empirical phenomenon known as the Rashomon Effect.'' These models may have different properties over various groups, and therefore have different predictive fairness properties. We develop a framework for characterizing predictive fairness properties over the set of models that deliver similar overall performance, orthe set of good models.'' Our framework addresses the empirically relevant challenge of selectively labelled data in the setting where the selection decision and outcome are unconfounded given the observed data features. Our framework can be used to 1) audit for predictive bias; or 2) replace an existing model with one that has better fairness properties. We illustrate these use cases on a recidivism prediction task and a real-world credit-scoring task.
[ Virtual ]
In this paper, we aim to solve data-driven model-based optimization (MBO) problems, where the goal is to find a design input that maximizes an unknown objective function provided access to only a static dataset of inputs and their corresponding objective values. Such data-driven optimization procedures are the only practical methods in many real-world domains where active data collection is expensive (e.g., when optimizing over proteins) or dangerous (e.g., when optimizing over aircraft designs, actively evaluating malformed aircraft designs is unsafe). Typical methods for MBO that optimize the input against a learned model of the unknown score function are affected by erroneous overestimation in the learned model caused due to distributional shift, that drives the optimizer to low-scoring or invalid inputs. To overcome this, we propose conservative objective models (COMs), a method that learns a model of the objective function which lower bounds the actual value of the ground-truth objective on out-of-distribution inputs and uses it for optimization. In practice, COMs outperform a number existing methods on a wide range of MBO problems, including optimizing controller parameters, robot morphologies, and superconducting materials.
[ Virtual ]
[ Virtual ]
In many machine learning problems, large-scale datasets have become the de-facto standard to train state-of-the-art deep networks at the price of heavy computation load. In this paper, we focus on condensing large training sets into significantly smaller synthetic sets which can be used to train deep neural networks from scratch with minimum drop in performance. Inspired from the recent training set synthesis methods, we propose Differentiable Siamese Augmentation that enables effective use of data augmentation to synthesize more informative synthetic images and thus achieves better performance when training networks with augmentations. Experiments on multiple image classification benchmarks demonstrate that the proposed method obtains substantial gains over the state-of-the-art, 7% improvements on CIFAR10 and CIFAR100 datasets. We show with only less than 1% data that our method achieves 99.6%, 94.9%, 88.5%, 71.5% relative performance on MNIST, FashionMNIST, SVHN, CIFAR10 respectively. We also explore the use of our method in continual learning and neural architecture search, and show promising results.
[ Virtual ]
We introduce Deep Adaptive Design (DAD), a method for amortizing the cost of adaptive Bayesian experimental design that allows experiments to be run in real-time. Traditional sequential Bayesian optimal experimental design approaches require substantial computation at each stage of the experiment. This makes them unsuitable for most real-world applications, where decisions must typically be made quickly. DAD addresses this restriction by learning an amortized design network upfront and then using this to rapidly run (multiple) adaptive experiments at deployment time. This network represents a design policy which takes as input the data from previous steps, and outputs the next design using a single forward pass; these design decisions can be made in milliseconds during the live experiment. To train the network, we introduce contrastive information bounds that are suitable objectives for the sequential setting, and propose a customized network architecture that exploits key symmetries. We demonstrate that DAD successfully amortizes the process of experimental design, outperforming alternative strategies on a number of problems.
[ Virtual ]
The recent rise of privacy concerns has led researchers to devise methods for private neural inference---where inferences are made directly on encrypted data, never seeing inputs. The primary challenge facing private inference is that computing on encrypted data levies an impractically-high latency penalty, stemming mostly from non-linear operators like ReLU. Enabling practical and private inference requires new optimization methods that minimize network ReLU counts while preserving accuracy. This paper proposes DeepReDuce: a set of optimizations for the judicious removal of ReLUs to reduce private inference latency. The key insight is that not all ReLUs contribute equally to accuracy. We leverage this insight to drop, or remove, ReLUs from classic networks to significantly reduce inference latency and maintain high accuracy. Given a network architecture, DeepReDuce outputs a Pareto frontier of networks that tradeoff the number of ReLUs and accuracy. Compared to the state-of-the-art for private inference DeepReDuce improves accuracy and reduces ReLU count by up to 3.5% (iso-ReLU count) and 3.5x (iso-accuracy), respectively.
[ Virtual ]
Real-world data often exhibit imbalanced distributions, where certain target values have significantly fewer observations. Existing techniques for dealing with imbalanced data focus on targets with categorical indices, i.e., different classes. However, many tasks involve continuous targets, where hard boundaries between classes do not exist. We define Deep Imbalanced Regression (DIR) as learning from such imbalanced data with continuous targets, dealing with potential missing data for certain target values, and generalizing to the entire target range. Motivated by the intrinsic difference between categorical and continuous label space, we propose distribution smoothing for both labels and features, which explicitly acknowledges the effects of nearby targets, and calibrates both label and learned feature distributions. We curate and benchmark large-scale DIR datasets from common real-world tasks in computer vision, natural language processing, and healthcare domains. Extensive experiments verify the superior performance of our strategies. Our work fills the gap in benchmarks and techniques for practical imbalanced regression problems. Code and data are available at: https://github.com/YyzHarry/imbalanced-regression.
[ Virtual ]
In many RL applications, once training ends, it is vital to detect any deterioration in the agent performance as soon as possible. Furthermore, it often has to be done without modifying the policy and under minimal assumptions regarding the environment. In this paper, we address this problem by focusing directly on the rewards and testing for degradation. We consider an episodic framework, where the rewards within each episode are not independent, nor identically-distributed, nor Markov. We present this problem as a multivariate mean-shift detection problem with possibly partial observations. We define the mean-shift in a way corresponding to deterioration of a temporal signal (such as the rewards), and derive a test for this problem with optimal statistical power. Empirically, on deteriorated rewards in control problems (generated using various environment modifications), the test is demonstrated to be more powerful than standard tests - often by orders of magnitude. We also suggest a novel Bootstrap mechanism for False Alarm Rate control (BFAR), applicable to episodic (non-i.i.d) signal and allowing our test to run sequentially in an online manner. Our method does not rely on a learned model of the environment, is entirely external to the agent, and in fact can be applied …
[ Virtual ]
Particle Filtering (PF) methods are an established class of procedures for performing inference in non-linear state-space models. Resampling is a key ingredient of PF necessary to obtain low variance likelihood and states estimates. However, traditional resampling methods result in PF-based loss functions being non-differentiable with respect to model and PF parameters. In a variational inference context, resampling also yields high variance gradient estimates of the PF-based evidence lower bound. By leveraging optimal transport ideas, we introduce a principled differentiable particle filter and provide convergence results. We demonstrate this novel method on a variety of applications.
[ Virtual ]
Clustering is a fundamental problem in data analysis. In differentially private clustering, the goal is to identify k cluster centers without disclosing information on individual data points. Despite significant research progress, the problem had so far resisted practical solutions. In this work we aim at providing simple implementable differentrially private clustering algorithms when the the data is "easy," e.g., when there exists a significant separation between the clusters.
For the easy instances we consider, we have a simple implementation based on utilizing non-private clustering algorithms, and combining them privately. We are able to get improved sample complexity bounds in some cases of Gaussian mixtures and k-means. We complement our theoretical algorithms with experiments of simulated data.
[ Virtual ]
Correlation clustering is a widely used technique in unsupervised machine learning. Motivated by applications where individual privacy is a concern, we initiate the study of differentially private correlation clustering. We propose an algorithm that achieves subquadratic additive error compared to the optimal cost. In contrast, straightforward adaptations of existing non-private algorithms all lead to a trivial quadratic error. Finally, we give a lower bound showing that any pure differentially private algorithm for correlation clustering requires additive error Ω(n).
[ Virtual ]
The inductive biases of graph representation learning algorithms are often encoded in the background geometry of their embedding space. In this paper, we show that general directed graphs can be effectively represented by an embedding model that combines three components: a pseudo-Riemannian metric structure, a non-trivial global topology, and a unique likelihood function that explicitly incorporates a preferred direction in embedding space. We demonstrate the representational capabilities of this method by applying it to the task of link prediction on a series of synthetic and real directed graphs from natural language applications and biology. In particular, we show that low-dimensional cylindrical Minkowski and anti-de Sitter spacetimes can produce equal or better graph representations than curved Riemannian manifolds of higher dimensions.
[ Virtual ]
In the domain generalization literature, a common objective is to learn representations independent of the domain after conditioning on the class label. We show that this objective is not sufficient: there exist counter-examples where a model fails to generalize to unseen domains even after satisfying class-conditional domain invariance. We formalize this observation through a structural causal model and show the importance of modeling within-class variations for generalization. Specifically, classes contain objects that characterize specific causal features, and domains can be interpreted as interventions on these objects that change non-causal features. We highlight an alternative condition: inputs across domains should have the same representation if they are derived from the same object. Based on this objective, we propose matching-based algorithms when base objects are observed (e.g., through data augmentation) and approximate the objective when objects are not observed (MatchDG). Our simple matching-based algorithms are competitive to prior work on out-of-domain accuracy for rotated MNIST, Fashion-MNIST, PACS, and Chest-Xray datasets. Our method MatchDG also recovers ground-truth object matches: on MNIST and Fashion-MNIST, top-10 matches from MatchDG have over 50% overlap with ground-truth matches.
[ Virtual ]
Current state-of-the-art algorithms for training robust decision trees have high runtime costs and require hours to run. We present GROOT, an efficient algorithm for training robust decision trees and random forests that runs in a matter of seconds to minutes. Where before the worst-case Gini impurity was computed iteratively, we find that we can solve this function analytically to improve time complexity from O(n) to O(1) in terms of n samples. Our results on both single trees and ensembles on 14 structured datasets as well as on MNIST and Fashion-MNIST demonstrate that GROOT runs several orders of magnitude faster than the state-of-the-art works and also shows better performance in terms of adversarial accuracy on structured data.
[ Virtual ]
Unsupervised domain adaptation is used in many machine learning applications where, during training, a model has access to unlabeled data in the target domain, and a related labeled dataset. In this paper, we introduce a novel and general domain-adversarial framework. Specifically, we derive a novel generalization bound for domain adaptation that exploits a new measure of discrepancy between distributions based on a variational characterization of f-divergences. It recovers the theoretical results from Ben-David et al. (2010a) as a special case and supports divergences used in practice. Based on this bound, we derive a new algorithmic framework that introduces a key correction in the original adversarial training method of Ganin et al. (2016). We show that many regularizers and ad-hoc objectives introduced over the last years in this framework are then not required to achieve performance comparable to (if not better than) state-of-the-art domain-adversarial methods. Experimental analysis conducted on real-world natural language and computer vision datasets show that our framework outperforms existing baselines, and obtains the best results for f-divergences that were not considered previously in domain-adversarial learning.
[ Virtual ]
We develop a novel approach to conformal prediction when the target task has limited data available for training. Conformal prediction identifies a small set of promising output candidates in place of a single prediction, with guarantees that the set contains the correct answer with high probability. When training data is limited, however, the predicted set can easily become unusably large. In this work, we obtain substantially tighter prediction sets while maintaining desirable marginal guarantees by casting conformal prediction as a meta-learning paradigm over exchangeable collections of auxiliary tasks. Our conformalization algorithm is simple, fast, and agnostic to the choice of underlying model, learning algorithm, or dataset. We demonstrate the effectiveness of this approach across a number of few-shot classification and regression tasks in natural language processing, computer vision, and computational chemistry for drug discovery.
[ Virtual ]
[ Virtual ]
We study the attribution problem in a graphical model, wherein the objective is to quantify how the effect of changes at the source nodes propagates through the graph. We develop a model-agnostic flow-based attribution method, called recursive Shapley value (RSV). RSV generalizes a number of existing node-based methods and uniquely satisfies a set of flow-based axioms. In addition to admitting a natural characterization for linear models and facilitating mediation analysis for non-linear models, RSV satisfies a mix of desirable properties discussed in the recent literature, including implementation invariance, sensitivity, monotonicity, and affine scale invariance.
[ Virtual ]
Attribution methods have been shown as promising approaches for identifying key features that led to learned model predictions. While most existing attribution methods rely on a baseline input for performing feature perturbations, limited research has been conducted to address the baseline selection issues. Poor choices of baselines limit the ability of one-vs-one explanations for multi-class classifiers, which means the attribution methods were not able to explain why an input belongs to its original class but not the other specified target class. Achieving one-vs-one explanation is crucial when certain classes are more similar than others, e.g. two bird types among multiple animals, by focusing on key differentiating features rather than shared features across classes. In this paper, we present GANMEX, a novel approach applying Generative Adversarial Networks (GAN) by incorporating the to-be-explained classifier as part of the adversarial networks. Our approach effectively selects the baseline as the closest realistic sample belong to the target class, which allows attribution methods to provide true one-vs-one explanations. We showed that GANMEX baselines improved the saliency maps and led to stronger performance on multiple evaluation metrics over the existing baselines. Existing attribution results are known for being insensitive to model randomization, and we demonstrated that …
[ Virtual ]
For Bayesian learning, given likelihood function and Gaussian prior, the elliptical slice sampler, introduced by Murray, Adams and MacKay 2010, provides a tool for the construction of a Markov chain for approximate sampling of the underlying posterior distribution. Besides of its wide applicability and simplicity its main feature is that no tuning is necessary. Under weak regularity assumptions on the posterior density we show that the corresponding Markov chain is geometrically ergodic and therefore yield qualitative convergence guarantees. We illustrate our result for Gaussian posteriors as they appear in Gaussian process regression in a fully Gaussian scenario, which for example is exhibited in Gaussian process regression, as well as in a setting of a multi-modal distribution. Remarkably, our numerical experiments indicate a dimension-independent performance of elliptical slice sampling even in situations where our ergodicity result does not apply.
[ Virtual ]
We present GNNAutoScale (GAS), a framework for scaling arbitrary message-passing GNNs to large graphs. GAS prunes entire sub-trees of the computation graph by utilizing historical embeddings from prior training iterations, leading to constant GPU memory consumption in respect to input node size without dropping any data. While existing solutions weaken the expressive power of message passing due to sub-sampling of edges or non-trainable propagations, our approach is provably able to maintain the expressive power of the original GNN. We achieve this by providing approximation error bounds of historical embeddings and show how to tighten them in practice. Empirically, we show that the practical realization of our framework, PyGAS, an easy-to-use extension for PyTorch Geometric, is both fast and memory-efficient, learns expressive node representations, closely resembles the performance of their non-scaling counterparts, and reaches state-of-the-art performance on large-scale graphs.
[ Virtual ]
We present Graph Neural Diffusion (GRAND) that approaches deep learning on graphs as a continuous diffusion process and treats Graph Neural Networks (GNNs) as discretisations of an underlying PDE. In our model, the layer structure and topology correspond to the discretisation choices of temporal and spatial operators. Our approach allows a principled development of a broad new class of GNNs that are able to address the common plights of graph learning models such as depth, oversmoothing, and bottlenecks. Key to the success of our models are stability with respect to perturbations in the data and this is addressed for both implicit and explicit discretisation schemes. We develop linear and nonlinear versions of GRAND, which achieve competitive results on many standard graph benchmarks.
[ Virtual ]
Self-supervised learning on graph-structured data has drawn recent interest for learning generalizable, transferable and robust representations from unlabeled graphs. Among many, graph contrastive learning (GraphCL) has emerged with promising representation learning performance. Unfortunately, unlike its counterpart on image data, the effectiveness of GraphCL hinges on ad-hoc data augmentations, which have to be manually picked per dataset, by either rules of thumb or trial-and-errors, owing to the diverse nature of graph data. That significantly limits the more general applicability of GraphCL. Aiming to fill in this crucial gap, this paper proposes a unified bi-level optimization framework to automatically, adaptively and dynamically select data augmentations when performing GraphCL on specific graph data. The general framework, dubbed JOint Augmentation Optimization (JOAO), is instantiated as min-max optimization. The selections of augmentations made by JOAO are shown to be in general aligned with previous "best practices" observed from handcrafted tuning: yet now being automated, more flexible and versatile. Moreover, we propose a new augmentation-aware projection head mechanism, which will route output features through different projection heads corresponding to different augmentations chosen at each training step. Extensive experiments demonstrate that JOAO performs on par with or sometimes better than the state-of-the-art competitors including GraphCL, on multiple …
[ Virtual ]
[ Virtual ]
Contemporary wisdom based on empirical studies suggests that standard recurrent neural networks (RNNs) do not perform well on tasks requiring long-term memory. However, RNNs' poor ability to capture long-term dependencies has not been fully understood. This paper provides a rigorous explanation of this property in the special case of linear RNNs. Although this work is limited to linear RNNs, even these systems have traditionally been difficult to analyze due to their non-linear parameterization. Using recently-developed kernel regime analysis, our main result shows that as the number of hidden units goes to infinity, linear RNNs learned from random initializations are functionally equivalent to a certain weighted 1D-convolutional network. Importantly, the weightings in the equivalent model cause an implicit bias to elements with smaller time lags in the convolution, and hence shorter memory. The degree of this bias depends on the variance of the transition matrix at initialization and is related to the classic exploding and vanishing gradients problem. The theory is validated with both synthetic and real data experiments.
[ Virtual ]
Recent efforts to unravel the mystery of implicit regularization in deep learning have led to a theoretical focus on matrix factorization --- matrix completion via linear neural network. As a step further towards practical deep learning, we provide the first theoretical analysis of implicit regularization in tensor factorization --- tensor completion via certain type of non-linear neural network. We circumvent the notorious difficulty of tensor problems by adopting a dynamical systems perspective, and characterizing the evolution induced by gradient descent. The characterization suggests a form of greedy low tensor rank search, which we rigorously prove under certain conditions, and empirically demonstrate under others. Motivated by tensor rank capturing the implicit regularization of a non-linear neural network, we empirically explore it as a measure of complexity, and find that it captures the essence of datasets on which neural networks generalize. This leads us to believe that tensor rank may pave way to explaining both implicit regularization in deep learning, and the properties of real-world data translating this implicit regularization to generalization.
[ Virtual ]
[ Virtual ]
[ Virtual ]
Few-shot dataset generalization is a challenging variant of the well-studied few-shot classification problem where a diverse training set of several datasets is given, for the purpose of training an adaptable model that can then learn classes from \emph{new datasets} using only a few examples. To this end, we propose to utilize the diverse training set to construct a \emph{universal template}: a partial model that can define a wide array of dataset-specialized models, by plugging in appropriate components. For each new few-shot classification problem, our approach therefore only requires inferring a small number of parameters to insert into the universal template. We design a separate network that produces an initialization of those parameters for each given task, and we then fine-tune its proposed initialization via a few steps of gradient descent. Our approach is more parameter-efficient, scalable and adaptable compared to previous methods, and achieves the state-of-the-art on the challenging Meta-Dataset benchmark.
[ Virtual ]
Many weakly supervised classification methods employ a noise transition matrix to capture the class-conditional label corruption. To estimate the transition matrix from noisy data, existing methods often need to estimate the noisy class-posterior, which could be unreliable due to the overconfidence of neural networks. In this work, we propose a theoretically grounded method that can estimate the noise transition matrix and learn a classifier simultaneously, without relying on the error-prone noisy class-posterior estimation. Concretely, inspired by the characteristics of the stochastic label corruption process, we propose total variation regularization, which encourages the predicted probabilities to be more distinguishable from each other. Under mild assumptions, the proposed method yields a consistent estimator of the transition matrix. We show the effectiveness of the proposed method through experiments on benchmark and real-world datasets.
[ Virtual ]
[ Virtual ]
Local graph clustering is an important algorithmic technique for analysing massive graphs, and has been widely applied in many research fields of data science. While the objective of most (local) graph clustering algorithms is to find a vertex set of low conductance, there has been a sequence of recent studies that highlight the importance of the inter-connection between clusters when analysing real-world datasets. Following this line of research, in this work we study local algorithms for finding a pair of vertex sets defined with respect to their inter-connection and their relationship with the rest of the graph. The key to our analysis is a new reduction technique that relates the structure of multiple sets to a single vertex set in the reduced graph. Among many potential applications, we show that our algorithms successfully recover densely connected clusters in the Interstate Disputes Dataset and the US Migration Dataset.
[ Virtual ]
[ Virtual ]
We provide an approximation algorithm for k-means clustering in the \emph{one-round} (aka \emph{non-interactive}) local model of differential privacy (DP). Our algorithm achieves an approximation ratio arbitrarily close to the best \emph{non private} approximation algorithm, improving upon previously known algorithms that only guarantee large (constant) approximation ratios. Furthermore, ours is the first constant-factor approximation algorithm for k-means that requires only \emph{one} round of communication in the local DP model, positively resolving an open question of Stemmer (SODA 2020). Our algorithmic framework is quite flexible; we demonstrate this by showing that it also yields a similar near-optimal approximation algorithm in the (one-round) shuffle DP model.
[ Virtual ]
Understanding the fundamental limits of robust supervised learning has emerged as a problem of immense interest, from both practical and theoretical standpoints. In particular, it is critical to determine classifier-agnostic bounds on the training loss to establish when learning is possible. In this paper, we determine optimal lower bounds on the cross-entropy loss in the presence of test-time adversaries, along with the corresponding optimal classification outputs. Our formulation of the bound as a solution to an optimization problem is general enough to encompass any loss function depending on soft classifier outputs. We also propose and provide a proof of correctness for a bespoke algorithm to compute this lower bound efficiently, allowing us to determine lower bounds for multiple practical datasets of interest. We use our lower bounds as a diagnostic tool to determine the effectiveness of current robust training methods and find a gap from optimality at larger budgets. Finally, we investigate the possibility of using of optimal classification outputs as soft labels to empirically improve robust training.
[ Virtual ]
In this paper, we propose a novel method for matrix completion under general non-uniform missing structures. By controlling an upper bound of a novel balancing error, we construct weights that can actively adjust for the non-uniformity in the empirical risk without explicitly modeling the observation probabilities, and can be computed efficiently via convex optimization. The recovered matrix based on the proposed weighted empirical risk enjoys appealing theoretical guarantees. In particular, the proposed method achieves stronger guarantee than existing work in terms of the scaling with respect to the observation probabilities, under asymptotically heterogeneous missing settings (where entry-wise observation probabilities can be of different orders). These settings can be regarded as a better theoretical model of missing patterns with highly varying probabilities. We also provide a new minimax lower bound under a class of heterogeneous settings. Numerical experiments are also provided to demonstrate the effectiveness of the proposed method.
[ Virtual ]
[ Virtual ]
Many state-of-the-art ML results have been obtained by scaling up the number of parameters in existing models. However, parameters and activations for such large models often do not fit in the memory of a single accelerator device; this means that it is necessary to distribute training of large models over multiple accelerators. In this work, we propose PipeDream-2BW, a system that supports memory-efficient pipeline parallelism. PipeDream-2BW uses a novel pipelining and weight gradient coalescing strategy, combined with the double buffering of weights, to ensure high throughput, low memory footprint, and weight update semantics similar to data parallelism. In addition, PipeDream-2BW automatically partitions the model over the available hardware resources, while respecting hardware constraints such as memory capacities of accelerators and interconnect topologies. PipeDream-2BW can accelerate the training of large GPT and BERT language models by up to 20x with similar final model accuracy.
[ Virtual ]
Recursive Neural Networks (RvNNs), which compose sequences according to their underlying hierarchical syntactic structure, have performed well in several natural language processing tasks compared to similar models without structural biases. However, traditional RvNNs are incapable of inducing the latent structure in a plain text sequence on their own. Several extensions have been proposed to overcome this limitation. Nevertheless, these extensions tend to rely on surrogate gradients or reinforcement learning at the cost of higher bias or variance. In this work, we propose Continuous Recursive Neural Network (CRvNN) as a backpropagation-friendly alternative to address the aforementioned limitations. This is done by incorporating a continuous relaxation to the induced structure. We demonstrate that CRvNN achieves strong performance in challenging synthetic tasks such as logical inference (Bowman et al., 2015b) and ListOps (Nangia & Bowman, 2018). We also show that CRvNN performs comparably or better than prior latent structure models on real-world tasks such as sentiment analysis and natural language inference.
[ Virtual ]
Many transfer problems require re-using previously optimal decisions for solving new tasks, which suggests the need for learning algorithms that can modify the mechanisms for choosing certain actions independently of those for choosing others. However, there is currently no formalism nor theory for how to achieve this kind of modular credit assignment. To answer this question, we define modular credit assignment as a constraint on minimizing the algorithmic mutual information among feedback signals for different decisions. We introduce what we call the modularity criterion for testing whether a learning algorithm satisfies this constraint by performing causal analysis on the algorithm itself. We generalize the recently proposed societal decision-making framework as a more granular formalism than the Markov decision process to prove that for decision sequences that do not contain cycles, certain single-step temporal difference action-value methods meet this criterion while all policy-gradient methods do not. Empirical evidence suggests that such action-value methods are more sample efficient than policy-gradient methods on transfer problems that require only sparse changes to a sequence of previously optimal decisions.
[ Virtual ]
[ Virtual ]
Recently, neural implicit functions have achieved impressive results for encoding 3D shapes. Conditioning on low-dimensional latent codes generalises a single implicit function to learn shared representation space for a variety of shapes, with the advantage of smooth interpolation. While the benefits from the global latent space do not correspond to explicit points at local level, we propose to track the continuous point trajectory by matching implicit features with the latent code interpolating between shapes, from which we corroborate the hierarchical functionality of the deep implicit functions, where early layers map the latent code to fitting the coarse shape structure, and deeper layers further refine the shape details. Furthermore, the structured representation space of implicit functions enables to apply feature matching for shape deformation, with the benefits to handle topology and semantics inconsistency, such as from an armchair to a chair with no arms, without explicit flow functions or manual annotations.
[ Virtual ]
Data transformations (e.g. rotations, reflections, and cropping) play an important role in self-supervised learning. Typically, images are transformed into different views, and neural networks trained on tasks involving these views produce useful feature representations for downstream tasks, including anomaly detection. However, for anomaly detection beyond image data, it is often unclear which transformations to use. Here we present a simple end-to-end procedure for anomaly detection with learnable transformations. The key idea is to embed the transformed data into a semantic space such that the transformed data still resemble their untransformed form, while different transformations are easily distinguishable. Extensive experiments on time series show that our proposed method outperforms existing approaches in the one-vs.-rest setting and is competitive in the more challenging n-vs.-rest anomaly-detection task. On medical and cyber-security tabular data, our method learns domain-specific transformations and detects anomalies more accurately than previous work.
[ Virtual ]
Density ratio estimation (DRE) is at the core of various machine learning tasks such as anomaly detection and domain adaptation. In the DRE literature, existing studies have extensively studied methods based on Bregman divergence (BD) minimization. However, when we apply the BD minimization with highly flexible models, such as deep neural networks, it tends to suffer from what we call train-loss hacking, which is a source of over-fitting caused by a typical characteristic of empirical BD estimators. In this paper, to mitigate train-loss hacking, we propose non-negative correction for empirical BD estimators. Theoretically, we confirm the soundness of the proposed method through a generalization error bound. In our experiments, the proposed methods show favorable performances in inlier-based outlier detection.
[ Virtual ]
We develop confidence bounds that hold uniformly over time for off-policy evaluation in the contextual bandit setting. These confidence sequences are based on recent ideas from martingale analysis and are non-asymptotic, non-parametric, and valid at arbitrary stopping times. We provide algorithms for computing these confidence sequences that strike a good balance between computational and statistical efficiency. We empirically demonstrate the tightness of our approach in terms of failure probability and width and apply it to the ``gated deployment'' problem of safely upgrading a production contextual bandit system.
[ Virtual ]
We study neural-linear bandits for solving problems where {\em both} exploration and representation learning play an important role. Neural-linear bandits harnesses the representation power of Deep Neural Networks (DNNs) and combines it with efficient exploration mechanisms by leveraging uncertainty estimation of the model, designed for linear contextual bandits on top of the last hidden layer. In order to mitigate the problem of representation change during the process, new uncertainty estimations are computed using stored data from an unlimited buffer. Nevertheless, when the amount of stored data is limited, a phenomenon called catastrophic forgetting emerges. To alleviate this, we propose a likelihood matching algorithm that is resilient to catastrophic forgetting and is completely online. We applied our algorithm, Limited Memory Neural-Linear with Likelihood Matching (NeuralLinear-LiM2) on a variety of datasets and observed that our algorithm achieves comparable performance to the unlimited memory approach while exhibits resilience to catastrophic forgetting.
[ Virtual ]
We show that the gradient estimates used in training Deep Gaussian Processes (DGPs) with importance-weighted variational inference are susceptible to signal-to-noise ratio (SNR) issues. Specifically, we show both theoretically and via an extensive empirical evaluation that the SNR of the gradient estimates for the latent variable's variational parameters decreases as the number of importance samples increases. As a result, these gradient estimates degrade to pure noise if the number of importance samples is too large. To address this pathology, we show how doubly-reparameterized gradient estimators, originally proposed for training variational autoencoders, can be adapted to the DGP setting and that the resultant estimators completely remedy the SNR issue, thereby providing more reliable training. Finally, we demonstrate that our fix can lead to consistent improvements in the predictive performance of DGP models.
[ Virtual ]
Meta-learning can successfully acquire useful inductive biases from data. Yet, its generalization properties to unseen learning tasks are poorly understood. Particularly if the number of meta-training tasks is small, this raises concerns about overfitting. We provide a theoretical analysis using the PAC-Bayesian framework and derive novel generalization bounds for meta-learning. Using these bounds, we develop a class of PAC-optimal meta-learning algorithms with performance guarantees and a principled meta-level regularization. Unlike previous PAC-Bayesian meta-learners, our method results in a standard stochastic optimization problem which can be solved efficiently and scales well.When instantiating our PAC-optimal hyper-posterior (PACOH) with Gaussian processes and Bayesian Neural Networks as base learners, the resulting methods yield state-of-the-art performance, both in terms of predictive accuracy and the quality of uncertainty estimates. Thanks to their principled treatment of uncertainty, our meta-learners can also be successfully employed for sequential decision problems.
[ Virtual ]
In hypothesis testing, a \emph{false discovery} occurs when a hypothesis is incorrectly rejected due to noise in the sample. When adaptively testing multiple hypotheses, the probability of a false discovery increases as more tests are performed. Thus the problem of \emph{False Discovery Rate (FDR) control} is to find a procedure for testing multiple hypotheses that accounts for this effect in determining the set of hypotheses to reject. The goal is to minimize the number (or fraction) of false discoveries, while maintaining a high true positive rate (i.e., correct discoveries). In this work, we study False Discovery Rate (FDR) control in multiple hypothesis testing under the constraint of differential privacy for the sample. Unlike previous work in this direction, we focus on the \emph{online setting}, meaning that a decision about each hypothesis must be made immediately after the test is performed, rather than waiting for the output of all tests as in the offline setting. We provide new private algorithms based on state-of-the-art results in non-private online FDR control. Our algorithms have strong provable guarantees for privacy and statistical performance as measured by FDR and power. We also provide experimental results to demonstrate the efficacy of our algorithms in a variety …
[ Virtual ]
Methods that sparsify a network at initialization are important in practice because they greatly improve the efficiency of both learning and inference. Our work is based on a recently proposed decomposition of the Neural Tangent Kernel (NTK) that has decoupled the dynamics of the training process into a data-dependent component and an architecture-dependent kernel – the latter referred to as Path Kernel. That work has shown how to design sparse neural networks for faster convergence, without any training data, using the Synflow-L2 algorithm. We first show that even though Synflow-L2 is optimal in terms of convergence, for a given network density, it results in sub-networks with ``bottleneck'' (narrow) layers – leading to poor performance as compared to other data-agnostic methods that use the same number of parameters. Then we propose a new method to construct sparse networks, without any training data, referred to as Paths with Higher-Edge Weights (PHEW). PHEW is a probabilistic network formation method based on biased random walks that only depends on the initial weights. It has similar path kernel properties as Synflow-L2 but it generates much wider layers, resulting in better generalization and performance. PHEW achieves significant improvements over the data-independent SynFlow and SynFlow-L2 methods at …
[ Virtual ]
Many video classification applications require access to personal data, thereby posing an invasive security risk to the users' privacy. We propose a privacy-preserving implementation of single-frame method based video classification with convolutional neural networks that allows a party to infer a label from a video without necessitating the video owner to disclose their video to other entities in an unencrypted manner. Similarly, our approach removes the requirement of the classifier owner from revealing their model parameters to outside entities in plaintext. To this end, we combine existing Secure Multi-Party Computation (MPC) protocols for private image classification with our novel MPC protocols for oblivious single-frame selection and secure label aggregation across frames. The result is an end-to-end privacy-preserving video classification pipeline. We evaluate our proposed solution in an application for private human emotion recognition. Our results across a variety of security settings, spanning honest and dishonest majority configurations of the computing parties, and for both passive and active adversaries, demonstrate that videos can be classified with state-of-the-art accuracy, and without leaking sensitive user information.
[ Virtual ]
[ Virtual ]
[ Virtual ]
We introduce a method to determine if a certain capability helps to achieve an accurate model of given data. We view labels as being generated from the inputs by a program composed of subroutines with different capabilities, and we posit that a subroutine is useful if and only if the minimal program that invokes it is shorter than the one that does not. Since minimum program length is uncomputable, we instead estimate the labels' minimum description length (MDL) as a proxy, giving us a theoretically-grounded method for analyzing dataset characteristics. We call the method Rissanen Data Analysis (RDA) after the father of MDL, and we showcase its applicability on a wide variety of settings in NLP, ranging from evaluating the utility of generating subquestions before answering a question, to analyzing the value of rationales and explanations, to investigating the importance of different parts of speech, and uncovering dataset gender bias.
[ Virtual ]
A fundamental challenge in artificial intelligence is learning useful representations of data that yield good performance on a downstream classification task, without overfitting to spurious input features. Extracting such task-relevant predictive information becomes particularly difficult for noisy and high-dimensional real-world data. In this work, we propose Contrastive Input Morphing (CIM), a representation learning framework that learns input-space transformations of the data to mitigate the effect of irrelevant input features on downstream performance. Our method leverages a perceptual similarity metric via a triplet loss to ensure that the transformation preserves task-relevant information. Empirically, we demonstrate the efficacy of our approach on various tasks which typically suffer from the presence of spurious correlations: classification with nuisance information, out-of-distribution generalization, and preservation of subgroup accuracies. We additionally show that CIM is complementary to other mutual information-based representation learning techniques, and demonstrate that it improves the performance of variational information bottleneck (VIB) when used in conjunction.
[ Virtual ]
We present a new certification method for image and point cloud segmentation based on randomized smoothing. The method leverages a novel scalable algorithm for prediction and certification that correctly accounts for multiple testing, necessary for ensuring statistical guarantees. The key to our approach is reliance on established multiple-testing correction mechanisms as well as the ability to abstain from classifying single pixels or points while still robustly segmenting the overall input. Our experimental evaluation on synthetic data and challenging datasets, such as Pascal Context, Cityscapes, and ShapeNet, shows that our algorithm can achieve, for the first time, competitive accuracy and certification guarantees on real-world segmentation tasks. We provide an implementation at https://github.com/eth-sri/segmentation-smoothing.
[ Virtual ]
The recent breakthrough achieved by contrastive learning accelerates the pace for deploying unsupervised training on real-world data applications. However, unlabeled data in reality is commonly imbalanced and shows a long-tail distribution, and it is unclear how robustly the latest contrastive learning methods could perform in the practical scenario. This paper proposes to explicitly tackle this challenge, via a principled framework called Self-Damaging Contrastive Learning (SDCLR), to automatically balance the representation learning without knowing the classes. Our main inspiration is drawn from the recent finding that deep models have difficult-to-memorize samples, and those may be exposed through network pruning. It is further natural to hypothesize that long-tail samples are also tougher for the model to learn well due to insufficient examples. Hence, the key innovation in SDCLR is to create a dynamic self-competitor model to contrast with the target model, which is a pruned version of the latter. During training, contrasting the two models will lead to adaptive online mining of the most easily forgotten samples for the current target model, and implicitly emphasize them more in the contrastive loss. Extensive experiments across multiple datasets and imbalance settings show that SDCLR significantly improves not only overall accuracies but also balancedness, in …
[ Virtual ]
Effective lifelong learning across diverse tasks requires the transfer of diverse knowledge, yet transferring irrelevant knowledge may lead to interference and catastrophic forgetting. In deep networks, transferring the appropriate granularity of knowledge is as important as the transfer mechanism, and must be driven by the relationships among tasks. We first show that the lifelong learning performance of several current deep learning architectures can be significantly improved by transfer at the appropriate layers. We then develop an expectation-maximization (EM) method to automatically select the appropriate transfer configuration and optimize the task network weights. This EM-based selective transfer is highly effective, balancing transfer performance on all tasks with avoiding catastrophic forgetting, as demonstrated on three algorithms in several lifelong object classification scenarios.
[ Virtual ]
Transformer-based models are popularly used in natural language processing (NLP). Its core component, self-attention, has aroused widespread interest. To understand the self-attention mechanism, a direct method is to visualize the attention map of a pre-trained model. Based on the patterns observed, a series of efficient Transformers with different sparse attention masks have been proposed. From a theoretical perspective, universal approximability of Transformer-based models is also recently proved. However, the above understanding and analysis of self-attention is based on a pre-trained model. To rethink the importance analysis in self-attention, we study the significance of different positions in attention matrix during pre-training. A surprising result is that diagonal elements in the attention map are the least important compared with other attention positions. We provide a proof showing that these diagonal elements can indeed be removed without deteriorating model performance. Furthermore, we propose a Differentiable Attention Mask (DAM) algorithm, which further guides the design of the SparseBERT. Extensive experiments verify our interesting findings and illustrate the effect of the proposed algorithm.
[ Virtual ]
Strategic classification studies the interaction between a classification rule and the strategic agents it governs. Agents respond by manipulating their features, under the assumption that the classifier is known. However, in many real-life scenarios of high-stake classification (e.g., credit scoring), the classifier is not revealed to the agents, which leads agents to attempt to learn the classifier and game it too. In this paper we generalize the strategic classification model to such scenarios and analyze the effect of an unknown classifier. We define the ''price of opacity'' as the difference between the prediction error under the opaque and transparent policies, characterize it, and give a sufficient condition for it to be strictly positive, in which case transparency is the recommended policy. Our experiments show how Hardt et al.’s robust classifier is affected by keeping agents in the dark.
[ Virtual ]
Learning faithful graph representations as sets of vertex embeddings has become a fundamental intermediary step in a wide range of machine learning applications. We propose the systematic use of symmetric spaces in representation learning, a class encompassing many of the previously used embedding targets. This enables us to introduce a new method, the use of Finsler metrics integrated in a Riemannian optimization scheme, that better adapts to dissimilar structures in the graph. We develop a tool to analyze the embeddings and infer structural properties of the data sets. For implementation, we choose Siegel spaces, a versatile family of symmetric spaces. Our approach outperforms competitive baselines for graph reconstruction tasks on various synthetic and real-world datasets. We further demonstrate its applicability on two downstream tasks, recommender systems and node classification.
[ Virtual ]
[ Virtual ]
The problem of fixing errors in programs has attracted substantial interest over the years. The key challenge for building an effective code fixing tool is to capture a wide range of errors and meanwhile maintain high accuracy. In this paper, we address this challenge and present a new learning-based system, called TFix. TFix works directly on program text and phrases the problem of code fixing as a text-to-text task. In turn, this enables it to leverage a powerful Transformer based model pre-trained on natural language and fine-tuned to generate code fixes (via a large, high-quality dataset obtained from GitHub commits). TFix is not specific to a particular programming language or class of defects and, in fact, improved its precision by simultaneously fine-tuning on 52 different error types reported by a popular static analyzer. Our evaluation on a massive dataset of JavaScript programs shows that TFix is practically effective: it is able to synthesize code that fixes the error in ~67 percent of cases and significantly outperforms existing learning-based approaches.
[ Virtual ]
We propose a lower bound on the log marginal likelihood of Gaussian process regression models that can be computed without matrix factorisation of the full kernel matrix. We show that approximate maximum likelihood learning of model parameters by maximising our lower bound retains many benefits of the sparse variational approach while reducing the bias introduced into hyperparameter learning. The basis of our bound is a more careful analysis of the log-determinant term appearing in the log marginal likelihood, as well as using the method of conjugate gradients to derive tight lower bounds on the term involving a quadratic form. Our approach is a step forward in unifying methods relying on lower bound maximisation (e.g. variational methods) and iterative approaches based on conjugate gradients for training Gaussian processes. In experiments, we show improved predictive performance with our model for a comparable amount of training time compared to other conjugate gradient based approaches.
[ Virtual ]
We show that learning can be improved by using loss functions that evolve cyclically during training to emphasize one class at a time. In underparameterized networks, such dynamical loss functions can lead to successful training for networks that fail to find deep minima of the standard cross-entropy loss. In overparameterized networks, dynamical loss functions can lead to better generalization. Improvement arises from the interplay of the changing loss landscape with the dynamics of the system as it evolves to minimize the loss. In particular, as the loss function oscillates, instabilities develop in the form of bifurcation cascades, which we study using the Hessian and Neural Tangent Kernel. Valleys in the landscape widen and deepen, and then narrow and rise as the loss landscape changes during a cycle. As the landscape narrows, the learning rate becomes too large and the network becomes unstable and bounces around the valley. This process ultimately pushes the system into deeper and wider regions of the loss landscape and is characterized by decreasing eigenvalues of the Hessian. This results in better regularized models with improved generalization performance.
[ Virtual ]
Adversarial training algorithms have been proved to be reliable to improve machine learning models' robustness against adversarial examples. However, we find that adversarial training algorithms tend to introduce severe disparity of accuracy and robustness between different groups of data. For instance, PGD adversarially trained ResNet18 model on CIFAR-10 has 93% clean accuracy and 67% PGD l_infty-8 adversarial accuracy on the class ''automobile'' but only 65% and 17% on class ''cat''. This phenomenon happens in balanced datasets and does not exist in naturally trained models when only using clean samples. In this work, we empirically and theoretically show that this phenomenon can generally happen under adversarial training algorithms which minimize DNN models' robust errors. Motivated by these findings, we propose a Fair-Robust-Learning (FRL) framework to mitigate this unfairness problem when doing adversarial defenses and experimental results validate the effectiveness of FRL.
[ Virtual ]

[ Virtual ]
Through sequential construction of posteriors on observing data online, Bayes’ theorem provides a natural framework for continual learning. We develop Variational Auto-Regressive Gaussian Processes (VAR-GPs), a principled posterior updating mechanism to solve sequential tasks in continual learning. By relying on sparse inducing point approximations for scalable posteriors, we propose a novel auto-regressive variational distribution which reveals two fruitful connections to existing results in Bayesian inference, expectation propagation and orthogonal inducing points. Mean predictive entropy estimates show VAR-GPs prevent catastrophic forgetting, which is empirically supported by strong performance on modern continual learning benchmarks against competitive baselines. A thorough ablation study demonstrates the efficacy of our modeling choices.
[ Virtual ]
hile probabilistic circuits have been extensively explored for tabular data, less attention has been paid to time series. Here, the goal is to estimate joint densities among the entire time series and, in turn, determining, for instance, conditional independence relations between them. To this end, we propose the first probabilistic circuits (PCs) approach for modeling the joint distribution of multivariate time series, called Whittle sum-product networks (WSPNs). WSPNs leverage the Whittle approximation, casting the likelihood in the frequency domain, and place a complex-valued sum-product network, the most prominent PC, over the frequencies. The conditional independence relations among the time series can then be determined efficiently in the spectral domain. Moreover, WSPNs can naturally be placed into the deep neural learning stack for time series, resulting in Whittle Networks, opening the likelihood toolbox for training deep neural models and inspecting their behaviour. Our experiments show that Whittle Networks can indeed capture complex dependencies between time series and provide a useful measure of uncertainty for neural networks.
We show that adding differential privacy to Explainable Boosting Machines (EBMs), a recent method for training interpretable ML models, yields state-of-the-art accuracy while protecting privacy. Our experiments on multiple classification and regression datasets show that DP-EBM models suffer surprisingly little accuracy loss even with strong differential privacy guarantees. In addition to high accuracy, two other benefits of applying DP to EBMs are: a) trained models provide exact global and local interpretability, which is often important in settings where differential privacy is needed; and b) the models can be edited after training without loss of privacy to correct errors which DP noise may have introduced.
Collective Inference (CI) is a procedure designed to boost weak relational classifiers, specially for node classification tasks. Graph Neural Networks (GNNs) are strong classifiers that have been used with great success. Unfortunately, most existing practical GNNs are not most-expressive (universal). Thus, it is an open question whether one can improve strong relational node classifiers, such as GNNs, with CI. In this work, we investigate this question and propose {\em collective learning} for GNNs ---a general collective classification approach for node representation learning that increases their representation power. We show that previous attempts to incorporate CI into GNNs fail to boost their expressiveness because they do not adapt CI's Monte Carlo sampling to representation learning. We evaluate our proposed framework with a variety of state-of-the-art GNNs. Our experiments show a consistent, significant boost in node classification accuracy ---regardless of the choice of underlying GNN--- for inductive node classification in partially-labeled graphs, across five real-world network datasets.

We present a new discriminative technique for the multiple-source adaptation (MSA) problem. Unlike previous work, which relies on density estimation for each source domain, our solution only requires conditional probabilities that can be straightforwardly accurately estimated from unlabeled data from the source domains. We give a detailed analysis of our new technique, including general guarantees based on R\'enyi divergences, and learning bounds when conditional Maxent is used for estimating conditional probabilities for a point to belong to a source domain. We show that these guarantees compare favorably to those that can be derived for the generative solution, using kernel density estimation. Our experiments with real-world applications further demonstrate that our new discriminative MSA algorithm outperforms the previous generative solution as well as other domain adaptation baselines.
In a two-player deep reinforcement learning task, recent work shows an attacker could learn an adversarial policy that triggers a target agent to perform poorly and even react in an undesired way. However, its efficacy heavily relies upon the zero-sum assumption made in the two-player game. In this work, we propose a new adversarial learning algorithm. It addresses the problem by resetting the optimization goal in the learning process and designing a new surrogate optimization function. Our experiments show that our method significantly improves adversarial agents' exploitability compared with the state-of-art attack. Besides, we also discover that our method could augment an agent with the ability to abuse the target game's unfairness. Finally, we show that agents adversarially re-trained against our adversarial agents could obtain stronger adversary-resistance.
Hamiltonian Monte Carlo (HMC) is one of the most successful sampling methods in machine learning. However, its performance is significantly affected by the choice of hyperparameter values. Existing approaches for optimizing the HMC hyperparameters either optimize a proxy for mixing speed or consider the HMC chain as an implicit variational distribution and optimize a tractable lower bound that can be very loose in practice. Instead, we propose to optimize an objective that quantifies directly the speed of convergence to the target distribution. Our objective can be easily optimized using stochastic gradient descent. We evaluate our proposed method and compare to baselines on a variety of problems including sampling from synthetic 2D distributions, reconstructing sparse signals, learning deep latent variable models and sampling molecular configurations from the Boltzmann distribution of a 22 atom molecule. We find that our method is competitive with or improves upon alternative baselines in all these experiments.
Random forests on the one hand, and neural networks on the other hand, have met great success in the machine learning community for their predictive performance. Combinations of both have been proposed in the literature, notably leading to the so-called deep forests (DF) (Zhou & Feng,2019). In this paper, our aim is not to benchmark DF performances but to investigate instead their underlying mechanisms. Additionally, DF architecture can be generally simplified into more simple and computationally efficient shallow forest networks. Despite some instability, the latter may outperform standard predictive tree-based methods. We exhibit a theoretical framework in which a shallow tree network is shown to enhance the performance of classical decision trees. In such a setting, we provide tight theoretical lower and upper bounds on its excess risk. These theoretical results show the interest of tree-network architectures for well-structured data provided that the first layer, acting as a data encoder, is rich enough.
Annealed Importance Sampling (AIS) and its Sequential Monte Carlo (SMC) extensions are state-of-the-art methods for estimating normalizing constants of probability distributions. We propose here a novel Monte Carlo algorithm, Annealed Flow Transport (AFT), that builds upon AIS and SMC and combines them with normalizing flows (NFs) for improved performance. This method transports a set of particles using not only importance sampling (IS), Markov chain Monte Carlo (MCMC) and resampling steps - as in SMC, but also relies on NFs which are learned sequentially to push particles towards the successive annealed targets. We provide limit theorems for the resulting Monte Carlo estimates of the normalizing constant and expectations with respect to the target distribution. Additionally, we show that a continuous-time scaling limit of the population version of AFT is given by a Feynman--Kac measure which simplifies to the law of a controlled diffusion for expressive NFs. We demonstrate experimentally the benefits and limitations of our methodology on a variety of applications.
Attention-based neural networks have achieved state-of-the-art results on a wide range of tasks. Most such models use deterministic attention while stochastic attention is less explored due to the optimization difficulties or complicated model design. This paper introduces Bayesian attention belief networks, which construct a decoder network by modeling unnormalized attention weights with a hierarchy of gamma distributions, and an encoder network by stacking Weibull distributions with a deterministic-upward-stochastic-downward structure to approximate the posterior. The resulting auto-encoding networks can be optimized in a differentiable way with a variational lower bound. It is simple to convert any models with deterministic attention, including pretrained ones, to the proposed Bayesian attention belief networks. On a variety of language understanding tasks, we show that our method outperforms deterministic attention and state-of-the-art stochastic attention in accuracy, uncertainty estimation, generalization across domains, and robustness to adversarial attacks. We further demonstrate the general applicability of our method on neural machine translation and visual question answering, showing great potential of incorporating our method into various attention-related tasks.
Riemannian manifolds provide a principled way to model nonlinear geometric structure inherent in data. A Riemannian metric on said manifolds determines geometry-aware shortest paths and provides the means to define statistical models accordingly. However, these operations are typically computationally demanding. To ease this computational burden, we advocate probabilistic numerical methods for Riemannian statistics. In particular, we focus on Bayesian quadrature (BQ) to numerically compute integrals over normal laws on Riemannian manifolds learned from data. In this task, each function evaluation relies on the solution of an expensive initial value problem. We show that by leveraging both prior knowledge and an active exploration scheme, BQ significantly reduces the number of required evaluations and thus outperforms Monte Carlo methods on a wide range of integration problems. As a concrete application, we highlight the merits of adopting Riemannian geometry with our proposed framework on a nonlinear dataset from molecular dynamics.
In representation learning, there has been recent interest in developing algorithms to disentangle the ground-truth generative factors behind a dataset, and metrics to quantify how fully this occurs. However, these algorithms and metrics often assume that both representations and ground-truth factors are flat, continuous, and factorized, whereas many real-world generative processes involve rich hierarchical structure, mixtures of discrete and continuous variables with dependence between them, and even varying intrinsic dimensionality. In this work, we develop benchmarks, algorithms, and metrics for learning such hierarchical representations.
Learning with noisy labels has attracted a lot of attention in recent years, where the mainstream approaches are in \emph{pointwise} manners. Meanwhile, \emph{pairwise} manners have shown great potential in supervised metric learning and unsupervised contrastive learning. Thus, a natural question is raised: does learning in a pairwise manner \emph{mitigate} label noise? To give an affirmative answer, in this paper, we propose a framework called \emph{Class2Simi}: it transforms data points with noisy \emph{class labels} to data pairs with noisy \emph{similarity labels}, where a similarity label denotes whether a pair shares the class label or not. Through this transformation, the \emph{reduction of the noise rate} is theoretically guaranteed, and hence it is in principle easier to handle noisy similarity labels. Amazingly, DNNs that predict the \emph{clean} class labels can be trained from noisy data pairs if they are first pretrained from noisy data points. Class2Simi is \emph{computationally efficient} because not only this transformation is on-the-fly in mini-batches, but also it just changes loss computation on top of model prediction into a pairwise manner. Its effectiveness is verified by extensive experiments.
The healthcare industry generates troves of unlabelled physiological data. This data can be exploited via contrastive learning, a self-supervised pre-training method that encourages representations of instances to be similar to one another. We propose a family of contrastive learning methods, CLOCS, that encourages representations across space, time, \textit{and} patients to be similar to one another. We show that CLOCS consistently outperforms the state-of-the-art methods, BYOL and SimCLR, when performing a linear evaluation of, and fine-tuning on, downstream tasks. We also show that CLOCS achieves strong generalization performance with only 25\% of labelled training data. Furthermore, our training procedure naturally generates patient-specific representations that can be used to quantify patient-similarity.
This work addresses the problem of optimizing communications between server and clients in federated learning (FL). Current sampling approaches in FL are either biased, or non optimal in terms of server-clients communications and training stability. To overcome this issue, we introduce clustered sampling for clients selection. We prove that clustered sampling leads to better clients representatitivity and to reduced variance of the clients stochastic aggregation weights in FL. Compatibly with our theory, we provide two different clustering approaches enabling clients aggregation based on 1) sample size, and 2) models similarity. Through a series of experiments in non-iid and unbalanced scenarios, we demonstrate that model aggregation through clustered sampling consistently leads to better training convergence and variability when compared to standard sampling approaches. Our approach does not require any additional operation on the clients side, and can be seamlessly integrated in standard FL implementations. Finally, clustered sampling is compatible with existing methods and technologies for privacy enhancement, and for communication reduction through model compression.
Inspired by a new coded computation algorithm for invertible functions, we propose Coded-InvNet a new approach to design resilient prediction serving systems that can gracefully handle stragglers or node failures. Coded-InvNet leverages recent findings in the deep learning literature such as invertible neural networks, Manifold Mixup, and domain translation algorithms, identifying interesting research directions that span across machine learning and systems. Our experimental results show that Coded-InvNet can outperform existing approaches, especially when the compute resource overhead is as low as 10%. For instance, without knowing which of the ten workers is going to fail, our algorithm can design a backup task so that it can correctly recover the missing prediction result with an accuracy of 85.9%, significantly outperforming the previous SOTA by 32.5%.
In learning with noisy labels, for every instance, its label can randomly walk to other classes following a transition distribution which is named a noise model. Well-studied noise models are all instance-independent, namely, the transition depends only on the original label but not the instance itself, and thus they are less practical in the wild. Fortunately, methods based on instance-dependent noise have been studied, but most of them have to rely on strong assumptions on the noise models. To alleviate this issue, we introduce confidence-scored instance-dependent noise (CSIDN), where each instance-label pair is equipped with a confidence score. We find that with the help of confidence scores, the transition distribution of each instance can be approximately estimated. Similarly to the powerful forward correction for instance-independent noise, we propose a novel instance-level forward correction for CSIDN. We demonstrate the utility and effectiveness of our method through multiple experiments on datasets with synthetic label noise and real-world unknown noise.
While semi-supervised learning (SSL) has received tremendous attentions in many machine learning tasks due to its successful use of unlabeled data, existing SSL algorithms use either all unlabeled examples or the unlabeled examples with a fixed high-confidence prediction during the training progress. However, it is possible that too many correct/wrong pseudo labeled examples are eliminated/selected. In this work we develop a simple yet powerful framework, whose key idea is to select a subset of training examples from the unlabeled data when performing existing SSL methods so that only the unlabeled examples with pseudo labels related to the labeled data will be used to train models. The selection is performed at each updating iteration by only keeping the examples whose losses are smaller than a given threshold that is dynamically adjusted through the iteration. Our proposed approach, Dash, enjoys its adaptivity in terms of unlabeled data selection and its theoretical guarantee. Specifically, we theoretically establish the convergence rate of Dash from the view of non-convex optimization. Finally, we empirically demonstrate the effectiveness of the proposed method in comparison with state-of-the-art over benchmarks.
In an effort to overcome limitations of reward-driven feature learning in deep reinforcement learning (RL) from images, we propose decoupling representation learning from policy learning. To this end, we introduce a new unsupervised learning (UL) task, called Augmented Temporal Contrast (ATC), which trains a convolutional encoder to associate pairs of observations separated by a short time difference, under image augmentations and using a contrastive loss. In online RL experiments, we show that training the encoder exclusively using ATC matches or outperforms end-to-end RL in most environments. Additionally, we benchmark several leading UL algorithms by pre-training encoders on expert demonstrations and using them, with weights frozen, in RL agents; we find that agents using ATC-trained encoders outperform all others. We also train multi-task encoders on data from multiple environments and show generalization to different downstream RL tasks. Finally, we ablate components of ATC, and introduce a new data augmentation to enable replay of (compressed) latent images from pre-trained encoders when RL requires augmentation. Our experiments span visually diverse RL benchmarks in DeepMind Control, DeepMind Lab, and Atari, and our complete code is available at \url{https://github.com/astooke/rlpyt/tree/master/rlpyt/ul}.
Modern machine learning increasingly requires training on a large collection of data from multiple sources, not all of which can be trusted. A particularly frightening scenario is when a small fraction of corrupted data changes the behavior of the trained model when triggered by an attacker-specified watermark. Such a compromised model will be deployed unnoticed as the model is accurate otherwise. There has been promising attempts to use the intermediate representations of such a model to separate corrupted examples from clean ones. However, these methods require a significant fraction of the data to be corrupted, in order to have strong enough signal for detection. We propose a novel defense algorithm using robust covariance estimation to amplify the spectral signature of corrupted data. This defense is able to completely remove backdoors whenever the benchmark backdoor attacks are successful, even in regimes where previous methods have no hope for detecting poisoned examples.
Performing reliable Bayesian inference on a big data scale is becoming a keystone in the modern era of machine learning. A workhorse class of methods to achieve this task are Markov chain Monte Carlo (MCMC) algorithms and their design to handle distributed datasets has been the subject of many works. However, existing methods are not completely either reliable or computationally efficient. In this paper, we propose to fill this gap in the case where the dataset is partitioned and stored on computing nodes within a cluster under a master/slaves architecture. We derive a user-friendly centralised distributed MCMC algorithm with provable scaling in high-dimensional settings. We illustrate the relevance of the proposed methodology on both synthetic and real data experiments.
Model quantization is challenging due to many tedious hyper-parameters such as precision (bitwidth), dynamic range (minimum and maximum discrete values) and stepsize (interval between discrete values). Unlike prior arts that carefully tune these values, we present a fully differentiable approach to learn all of them, named Differentiable Dynamic Quantization (DDQ), which has several benefits. (1) DDQ is able to quantize challenging lightweight architectures like MobileNets, where different layers prefer different quantization parameters. (2) DDQ is hardware-friendly and can be easily implemented using low-precision matrix-vector multiplication, making it capable in many hardware such as ARM. (3) Extensive experiments show that DDQ outperforms prior arts on many networks and benchmarks, especially when models are already efficient and compact. e.g., DDQ is the first approach that achieves lossless 4-bit quantization for MobileNetV2 on ImageNet.
We propose, implement, and evaluate a new algo-rithm for releasing answers to very large numbersof statistical queries likek-way marginals, sub-ject to differential privacy. Our algorithm makesadaptive use of a continuous relaxation of thePro-jection Mechanism, which answers queries on theprivate dataset using simple perturbation, and thenattempts to find the synthetic dataset that mostclosely matches the noisy answers. We use a con-tinuous relaxation of the synthetic dataset domainwhich makes the projection loss differentiable,and allows us to use efficient ML optimizationtechniques and tooling. Rather than answering allqueries up front, we make judicious use of ourprivacy budget by iteratively finding queries forwhich our (relaxed) synthetic data has high error,and then repeating the projection. Randomizedrounding allows us to obtain synthetic data in theoriginal schema. We perform experimental evalu-ations across a range of parameters and datasets,and find that our method outperforms existingalgorithms on large query classes.
Machine learning approached through supervised learning requires expensive annotation of data. This motivates weakly supervised learning, where data are annotated with incomplete yet discriminative information. In this paper, we focus on partial labelling, an instance of weak supervision where, from a given input, we are given a set of potential targets. We review a disambiguation principle to recover full supervision from weak supervision, and propose an empirical disambiguation algorithm. We prove exponential convergence rates of our algorithm under classical learnability assumptions, and we illustrate the usefulness of our method on practical examples.
Transformer model with multi-head attention requires caching intermediate results for efficient inference in generation tasks. However, cache brings new memory-related costs and prevents leveraging larger batch size for faster speed. We propose memory-efficient lossless attention (called EL-attention) to address this issue. It avoids heavy operations for building multi-head keys and values, cache for them is not needed. EL-attention constructs an ensemble of attention results by expanding query while keeping key and value shared. It produces the same result as multi-head attention with less GPU memory and faster inference speed. We conduct extensive experiments on Transformer, BART, and GPT-2 for summarization and question generation tasks. The results show EL-attention speeds up existing models by 1.6x to 5.3x without accuracy loss.
Despite the considerable success of neural networks in security settings such as malware detection, such models have proved vulnerable to evasion attacks, in which attackers make slight changes to inputs (e.g., malware) to bypass detection. We propose a novel approach, Fourier stabilization, for designing evasion-robust neural networks with binary inputs. This approach, which is complementary to other forms of defense, replaces the weights of individual neurons with robust analogs derived using Fourier analytic tools. The choice of which neurons to stabilize in a neural network is then a combinatorial optimization problem, and we propose several methods for approximately solving it. We provide a formal bound on the per-neuron drop in accuracy due to Fourier stabilization, and experimentally demonstrate the effectiveness of the proposed approach in boosting robustness of neural networks in several detection settings. Moreover, we show that our approach effectively composes with adversarial training.
Learning models that gracefully handle distribution shifts is central to research on domain generalization, robust optimization, and fairness. A promising formulation is domain-invariant learning, which identifies the key issue of learning which features are domain-specific versus domain-invariant. An important assumption in this area is that the training examples are partitioned into domains'' orenvironments''. Our focus is on the more common setting where such partitions are not provided. We propose EIIL, a general framework for domain-invariant learning that incorporates Environment Inference to directly infer partitions that are maximally informative for downstream Invariant Learning. We show that EIIL outperforms invariant learning methods on the CMNIST benchmark without using environment labels, and significantly outperforms ERM on worst-group performance in the Waterbirds dataset. Finally, we establish connections between EIIL and algorithmic fairness, which enables EIIL to improve accuracy and calibration in a fair prediction problem.
Riemannian manifold Hamiltonian Monte Carlo is traditionally carried out using the generalized leapfrog integrator. However, this integrator is not the only choice and other integrators yielding valid Markov chain transition operators may be considered. In this work, we examine the implicit midpoint integrator as an alternative to the generalized leapfrog integrator. We discuss advantages and disadvantages of the implicit midpoint integrator for Hamiltonian Monte Carlo, its theoretical properties, and an empirical assessment of the critical attributes of such an integrator for Hamiltonian Monte Carlo: energy conservation, volume preservation, and reversibility. Empirically, we find that while leapfrog iterations are faster, the implicit midpoint integrator has better energy conservation, leading to higher acceptance rates, as well as better conservation of volume and better reversibility, arguably yielding a more accurate sampling procedure.
Conformal Predictors (CP) are wrappers around ML models, providing error guarantees under weak assumptions on the data distribution. They are suitable for a wide range of problems, from classification and regression to anomaly detection. Unfortunately, their very high computational complexity limits their applicability to large datasets. In this work, we show that it is possible to speed up a CP classifier considerably, by studying it in conjunction with the underlying ML method, and by exploiting incremental\&decremental learning. For methods such as k-NN, KDE, and kernel LS-SVM, our approach reduces the running time by one order of magnitude, whilst producing exact solutions. With similar ideas, we also achieve a linear speed up for the harder case of bootstrapping. Finally, we extend these techniques to improve upon an optimization of k-NN CP for regression. We evaluate our findings empirically, and discuss when methods are suitable for CP optimization.
Recent findings have shown multiple graph learning models, such as graph classification and graph matching, are highly vulnerable to adversarial attacks, i.e. small input perturbations in graph structures and node attributes can cause the model failures. Existing defense techniques often defend specific attacks on particular multiple graph learning tasks. This paper proposes an attack-agnostic graph-adaptive 1-Lipschitz neural network, ERNN, for improving the robustness of deep multiple graph learning while achieving remarkable expressive power. A Kl-Lipschitz Weibull activation function is designed to enforce the gradient norm as Kl at layer l. The nearest matrix orthogonalization and polar decomposition techniques are utilized to constraint the weight norm as 1/Kl and make the norm-constrained weight close to the original weight. The theoretical analysis is conducted to derive lower and upper bounds of feasible Kl under the 1-Lipschitz constraint. The combination of norm-constrained weight and activation function leads to the 1-Lipschitz neural network for expressive and robust multiple graph learning.
This work tackles the issue of fairness in the context of generative
procedures, such as image super-resolution, which entail different
definitions from the standard classification setting. Moreover,
while traditional group fairness definitions are typically defined
with respect to specified protected groups -- camouflaging the
fact that these groupings are artificial and carry historical and
political motivations -- we emphasize that there are no ground
truth identities. For instance, should South and East Asians be
viewed as a single group or separate groups? Should we consider one
race as a whole or further split by gender? Choosing which groups
are valid and who belongs in them is an impossible dilemma and being
fair'' with respect to Asians may require beingunfair'' with
respect to South Asians. This motivates the introduction of
definitions that allow algorithms to be \emph{oblivious} to the
relevant groupings.
We define several intuitive notions of group fairness and study their incompatibilities and trade-offs. We show that the natural extension of demographic parity is strongly dependent on the grouping, and \emph{impossible} to achieve obliviously. On the other hand, the conceptually new definition we introduce, Conditional Proportional Representation, can be achieved obliviously through Posterior Sampling. Our experiments validate our theoretical …
Contextual bandit algorithms have become widely used for recommendation in online systems (e.g. marketplaces, music streaming, news), where they now wield substantial influence on which items get shown to users. This raises questions of fairness to the items --- and to the sellers, artists, and writers that benefit from this exposure. We argue that the conventional bandit formulation can lead to an undesirable and unfair winner-takes-all allocation of exposure. To remedy this problem, we propose a new bandit objective that guarantees merit-based fairness of exposure to the items while optimizing utility to the users. We formulate fairness regret and reward regret in this setting and present algorithms for both stochastic multi-armed bandits and stochastic linear bandits. We prove that the algorithms achieve sublinear fairness regret and reward regret. Beyond the theoretical analysis, we also provide empirical evidence that these algorithms can allocate exposure to different arms effectively.
Selective classification is a powerful tool for decision-making in scenarios where mistakes are costly but abstentions are allowed. In general, by allowing a classifier to abstain, one can improve the performance of a model at the cost of reducing coverage and classifying fewer samples. However, recent work has shown, in some cases, that selective classification can magnify disparities between groups, and has illustrated this phenomenon on multiple real-world datasets. We prove that the sufficiency criterion can be used to mitigate these disparities by ensuring that selective classification increases performance on all groups, and introduce a method for mitigating the disparity in precision across the entire coverage scale based on this criterion. We then provide an upper bound on the conditional mutual information between the class label and sensitive attribute, conditioned on the learned features, which can be used as a regularizer to achieve fairer selective classification. The effectiveness of the method is demonstrated on the Adult, CelebA, Civil Comments, and CheXpert datasets.
Understanding the complex structure of multivariate extremes is a major challenge in various fields from portfolio monitoring and environmental risk management to insurance. In the framework of multivariate Extreme Value Theory, a common characterization of extremes' dependence structure is the angular measure. It is a suitable measure to work in extreme regions as it provides meaningful insights concerning the subregions where extremes tend to concentrate their mass. The present paper develops a novel optimization-based approach to assess the dependence structure of extremes. This support identification scheme rewrites as estimating clusters of features which best capture the support of extremes. The dimension reduction technique we provide is applied to statistical learning tasks such as feature clustering and anomaly detection. Numerical experiments provide strong empirical evidence of the relevance of our approach.
Scientists and engineers are often interested in learning the number of subpopulations (or components) present in a data set. A common suggestion is to use a finite mixture model (FMM) with a prior on the number of components. Past work has shown the resulting FMM component-count posterior is consistent; that is, the posterior concentrates on the true, generating number of components. But consistency requires the assumption that the component likelihoods are perfectly specified, which is unrealistic in practice. In this paper, we add rigor to data-analysis folk wisdom by proving that under even the slightest model misspecification, the FMM component-count posterior diverges: the posterior probability of any particular finite number of components converges to 0 in the limit of infinite data. Contrary to intuition, posterior-density consistency is not sufficient to establish this result. We develop novel sufficient conditions that are more realistic and easily checkable than those common in the asymptotics literature. We illustrate practical consequences of our theory on simulated and real data.
Efficient low-variance gradient estimation enabled by the reparameterization trick (RT) has been essential to the success of variational autoencoders. Doubly-reparameterized gradients (DReGs) improve on the RT for multi-sample variational bounds by applying reparameterization a second time for an additional reduction in variance. Here, we develop two generalizations of the DReGs estimator and show that they can be used to train conditional and hierarchical VAEs on image modelling tasks more effectively. We first extend the estimator to hierarchical models with several stochastic layers by showing how to treat additional score function terms due to the hierarchical variational posterior. We then generalize DReGs to score functions of arbitrary distributions instead of just those of the sampling distribution, which makes the estimator applicable to the parameters of the prior in addition to those of the posterior.
Evaluating the quality of learned representations without relying on a downstream task remains one of the challenges in representation learning. In this work, we present Geometric Component Analysis (GeomCA) algorithm that evaluates representation spaces based on their geometric and topological properties. GeomCA can be applied to representations of any dimension, independently of the model that generated them. We demonstrate its applicability by analyzing representations obtained from a variety of scenarios, such as contrastive learning models, generative models and supervised learning models.
Recently, denoising diffusion probabilistic models and generative score matching have shown high potential in modelling complex data distributions while stochastic calculus has provided a unified point of view on these techniques allowing for flexible inference schemes. In this paper we introduce Grad-TTS, a novel text-to-speech model with score-based decoder producing mel-spectrograms by gradually transforming noise predicted by encoder and aligned with text input by means of Monotonic Alignment Search. The framework of stochastic differential equations helps us to generalize conventional diffusion probabilistic models to the case of reconstructing data from noise with different parameters and allows to make this reconstruction flexible by explicitly controlling trade-off between sound quality and inference speed. Subjective human evaluation shows that Grad-TTS is competitive with state-of-the-art text-to-speech approaches in terms of Mean Opinion Score.
Current low-precision quantization algorithms often have the hidden cost of conversion back and forth from floating point to quantized integer values. This hidden cost limits the latency improvement realized by quantizing Neural Networks. To address this, we present HAWQ-V3, a novel mixed-precision integer-only quantization framework. The contributions of HAWQ-V3 are the following: (i) An integer-only inference where the entire computational graph is performed only with integer multiplication, addition, and bit shifting, without any floating point operations or even integer division; (ii) A novel hardware-aware mixed-precision quantization method where the bit-precision is calculated by solving an integer linear programming problem that balances the trade-off between model perturbation and other constraints, e.g., memory footprint and latency; (iii) Direct hardware deployment and open source contribution for 4-bit uniform/mixed-precision quantization in TVM, achieving an average speed up of 1.45x for uniform 4-bit, as compared to uniform 8-bit for ResNet50 on T4 GPUs; and (iv) extensive evaluation of the proposed methods on ResNet18/50 and InceptionV3, for various model compression levels with/without mixed precision. For ResNet50, our INT8 quantization achieves an accuracy of 77.58%, which is 2.68% higher than prior integer-only work, and our mixed-precision INT4/8 quantization can reduce INT8 latency by 23% and still achieve …
We investigate the problem of hierarchically clustering data streams containing metric data in R^d. We introduce a desirable invariance property for such algorithms, describe a general family of hyperplane-based methods enjoying this property, and analyze two scalable instances of this general family against recently popularized similarity/dissimilarity-based metrics for hierarchical clustering. We prove a number of new results related to the approximation ratios of these algorithms, improving in various ways over the literature on this subject. Finally, since our algorithms are principled but also very practical, we carry out an experimental comparison on both synthetic and real-world datasets showing competitive results against known baselines.
Transformer based models, like BERT and RoBERTa, have achieved state-of-the-art results in many Natural Language Processing tasks. However, their memory footprint, inference latency, and power consumption are prohibitive efficient inference at the edge, and even at the data center. While quantization can be a viable solution for this, previous work on quantizing Transformer based models use floating-point arithmetic during inference, which cannot efficiently utilize integer-only logical units such as the recent Turing Tensor Cores, or traditional integer-only ARM processors. In this work, we propose I-BERT, a novel quantization scheme for Transformer based models that quantizes the entire inference with integer-only arithmetic. Based on lightweight integer-only approximation methods for nonlinear operations, e.g., GELU, Softmax, and Layer Normalization, I-BERT performs an end-to-end integer-only BERT inference without any floating point calculation. We evaluate our approach on GLUE downstream tasks using RoBERTa-Base/Large. We show that for both cases, I-BERT achieves similar (and slightly higher) accuracy as compared to the full-precision baseline. Furthermore, our preliminary implementation of I-BERT shows a speedup of 2.4- 4.0x for INT8 inference on a T4 GPU system as compared to FP32 inference. The framework has been developed in PyTorch and has been open-sourced.
Randomized smoothing is a general technique for computing sample-dependent robustness guarantees against adversarial attacks for deep classifiers. Prior works on randomized smoothing against L1 adversarial attacks use additive smoothing noise and provide probabilistic robustness guarantees. In this work, we propose a non-additive and deterministic smoothing method, Deterministic Smoothing with Splitting Noise (DSSN). To develop DSSN, we first develop SSN, a randomized method which involves generating each noisy smoothing sample by first randomly splitting the input space and then returning a representation of the center of the subdivision occupied by the input sample. In contrast to uniform additive smoothing, the SSN certification does not require the random noise components used to be independent. Thus, smoothing can be done effectively in just one dimension and can therefore be efficiently derandomized for quantized data (e.g., images). To the best of our knowledge, this is the first work to provide deterministic "randomized smoothing" for a norm-based adversarial threat model while allowing for an arbitrary classifier (i.e., a deep model) to be used as a base classifier and without requiring an exponential number of smoothing samples. On CIFAR-10 and ImageNet datasets, we provide substantially larger L1 robustness certificates compared to prior works, establishing …
Network regression models, where the outcome comprises the valued edge in a network and the predictors are actor or dyad-level covariates, are used extensively in the social and biological sciences. Valid inference relies on accurately modeling the residual dependencies among the relations. Frequently homogeneity assumptions are placed on the errors which are commonly incorrect and ignore critical natural clustering of the actors. In this work, we present a novel regression modeling framework that models the errors as resulting from a community-based dependence structure and exploits the subsequent exchangeability properties of the error distribution to obtain parsimonious standard errors for regression parameters.
We present a probabilistic model where the latent variable respects both the distances and the topology of the modeled data. The model leverages the Riemannian geometry of the generated manifold to endow the latent space with a well-defined stochastic distance measure, which is modeled locally as Nakagami distributions. These stochastic distances are sought to be as similar as possible to observed distances along a neighborhood graph through a censoring process. The model is inferred by variational inference based on observations of pairwise distances. We demonstrate how the new model can encode invariances in the learned manifolds.
Membership inference is one of the simplest privacy threats faced by machine learning models that are trained on private sensitive data. In this attack, an adversary infers whether a particular point was used to train the model, or not, by observing the model's predictions. Whereas current attack methods all require access to the model's predicted confidence score, we introduce a label-only attack that instead evaluates the robustness of the model's predicted (hard) labels under perturbations of the input, to infer membership. Our label-only attack is not only as-effective as attacks requiring access to confidence scores, it also demonstrates that a class of defenses against membership inference, which we call ``confidence masking'' because they obfuscate the confidence scores to thwart attacks, are insufficient to prevent the leakage of private information. Our experiments show that training with differential privacy or strong L2 regularization are the only current defenses that meaningfully decrease leakage of private information, even for points that are outliers of the training distribution.
We address the problem of learning binary decision trees that partition data for some downstream task. We propose to learn discrete parameters (i.e., for tree traversals and node pruning) and continuous parameters (i.e., for tree split functions and prediction functions) simultaneously using argmin differentiation. We do so by sparsely relaxing a mixed-integer program for the discrete parameters, to allow gradients to pass through the program to continuous parameters. We derive customized algorithms to efficiently compute the forward and backward passes. This means that our tree learning procedure can be used as an (implicit) layer in arbitrary deep networks, and can be optimized with arbitrary loss functions. We demonstrate that our approach produces binary trees that are competitive with existing single tree and ensemble approaches, in both supervised and unsupervised settings. Further, apart from greedy approaches (which do not have competitive accuracies), our method is faster to train than all other tree-learning baselines we compare with.
We propose a novel approach to disentangle the generative factors of variation underlying a given set of observations. Our method builds upon the idea that the (unknown) low-dimensional manifold underlying the data space can be explicitly modeled as a product of submanifolds. This definition of disentanglement gives rise to a novel weakly-supervised algorithm for recovering the unknown explanatory factors behind the data. At training time, our algorithm only requires pairs of non i.i.d. data samples whose elements share at least one, possibly multidimensional, generative factor of variation. We require no knowledge on the nature of these transformations, and do not make any limiting assumption on the properties of each subspace. Our approach is easy to implement, and can be successfully applied to different kinds of data (from images to 3D surfaces) undergoing arbitrary transformations. In addition to standard synthetic benchmarks, we showcase our method in challenging real-world applications, where we compare favorably with the state of the art.
Weakly supervised learning has drawn considerable attention recently to reduce the expensive time and labor consumption of labeling massive data. In this paper, we investigate a novel weakly supervised learning problem of learning from similarity-confidence (Sconf) data, where only unlabeled data pairs equipped with confidence that illustrates their degree of similarity (two examples are similar if they belong to the same class) are needed for training a discriminative binary classifier. We propose an unbiased estimator of the classification risk that can be calculated from only Sconf data and show that the estimation error bound achieves the optimal convergence rate. To alleviate potential overfitting when flexible models are used, we further employ a risk correction scheme on the proposed risk estimator. Experimental results demonstrate the effectiveness of the proposed methods.
When machine predictors can achieve higher performance than the human decision-makers they support, improving the performance of human decision-makers is often conflated with improving machine accuracy. Here we propose a framework to directly support human decision-making, in which the role of machines is to reframe problems rather than to prescribe actions through prediction. Inspired by the success of representation learning in improving performance of machine predictors, our framework learns human-facing representations optimized for human performance. This “Mind Composed with Machine” framework incorporates a human decision-making model directly into the representation learning paradigm and is trained with a novel human-in-the-loop training procedure. We empirically demonstrate the successful application of the framework to various tasks and representational forms.
Existing reasoning tasks often have an important assumption that the input contents can be always accessed while reasoning, requiring unlimited storage resources and suffering from severe time delay on long sequences. To achieve efficient reasoning on long sequences with limited storage resources, memory augmented neural networks introduce a human-like write-read memory to compress and memorize the long input sequence in one pass, trying to answer subsequent queries only based on the memory. But they have two serious drawbacks: 1) they continually update the memory from current information and inevitably forget the early contents; 2) they do not distinguish what information is important and treat all contents equally. In this paper, we propose the Rehearsal Memory (RM) to enhance long-sequence memorization by self-supervised rehearsal with a history sampler. To alleviate the gradual forgetting of early information, we design self-supervised rehearsal training with recollection and familiarity tasks. Further, we design a history sampler to select informative fragments for rehearsal training, making the memory focus on the crucial information. We evaluate the performance of our rehearsal memory by the synthetic bAbI task and several downstream tasks, including text/video question answering and recommendation on long sequences.
We show the formal equivalence of linearised self-attention mechanisms and fast weight controllers from the early '90s, where a slow neural net learns by gradient descent to program the fast weights of another net through sequences of elementary programming instructions which are additive outer products of self-invented activation patterns (today called keys and values). Such Fast Weight Programmers (FWPs) learn to manipulate the contents of a finite memory and dynamically interact with it. We infer a memory capacity limitation of recent linearised softmax attention variants, and replace the purely additive outer products by a delta rule-like programming instruction, such that the FWP can more easily learn to correct the current mapping from keys to values. The FWP also learns to compute dynamically changing learning rates. We also propose a new kernel function to linearise attention which balances simplicity and effectiveness. We conduct experiments on synthetic retrieval problems as well as standard machine translation and language modelling tasks which demonstrate the benefits of our methods.
Inpainting is a learned interpolation technique that is based on generative modeling and used to populate masked or missing pieces in an image; it has wide applications in picture editing and retouching. Recently, inpainting started being used for watermark removal, raising concerns. In this paper we study how to manipulate it using our markpainting technique. First, we show how an image owner with access to an inpainting model can augment their image in such a way that any attempt to edit it using that model will add arbitrary visible information. We find that we can target multiple different models simultaneously with our technique. This can be designed to reconstitute a watermark if the editor had been trying to remove it. Second, we show that our markpainting technique is transferable to models that have different architectures or were trained on different datasets, so watermarks created using it are difficult for adversaries to remove. Markpainting is novel and can be used as a manipulation alarm that becomes visible in the event of inpainting. Source code is available at: https://github.com/iliaishacked/markpainting.
Collaborative learning allows participants to jointly train a model without data sharing. To update the model parameters, the central server broadcasts model parameters to the clients, and the clients send updating directions such as gradients to the server. While data do not leave a client device, the communicated gradients and parameters will leak a client's privacy. Attacks that infer clients' privacy from gradients and parameters have been developed by prior work. Simple defenses such as dropout and differential privacy either fail to defend the attacks or seriously hurt test accuracy. We propose a practical defense which we call Double-Blind Collaborative Learning (DBCL). The high-level idea is to apply random matrix sketching to the parameters (aka weights) and re-generate random sketching after each iteration. DBCL prevents clients from conducting gradient-based privacy inferences which are the most effective attacks. DBCL works because from the attacker's perspective, sketching is effectively random noise that outweighs the signal. Notably, DBCL does not much increase computation and communication costs and does not hurt test accuracy at all.
We propose a novel algorithm for online meta learning where task instances are sequentially revealed with limited supervision and a learner is expected to meta learn them in each round, so as to allow the learner to customize a task-specific model rapidly with little task-level supervision. A fundamental concern arising in online meta-learning is the scalability of memory as more tasks are viewed over time. Heretofore, prior works have allowed for perfect recall leading to linear increase in memory with time. Different from prior works, in our method, prior task instances are allowed to be deleted. We propose to leverage prior task instances by means of a fixed-size state-vector, which is updated sequentially. Our theoretical analysis demonstrates that our proposed memory efficient online learning (MOML) method suffers sub-linear regret with convex loss functions and sub-linear local regret for nonconvex losses. On benchmark datasets we show that our method can outperform prior works even though they allow for perfect recall.
This paper tackles the problem of adversarial examples from a game theoretic point of view. We study the open question of the existence of mixed Nash equilibria in the zero-sum game formed by the attacker and the classifier. While previous works usually allow only one player to use randomized strategies, we show the necessity of considering randomization for both the classifier and the attacker. We demonstrate that this game has no duality gap, meaning that it always admits approximate Nash equilibria. We also provide the first optimization algorithms to learn a mixture of classifiers that approximately realizes the value of this game, \emph{i.e.} procedures to build an optimally robust randomized classifier.
Nondeterminism in neural network optimization produces uncertainty in performance, making small improvements difficult to discern from run-to-run variability. While uncertainty can be reduced by training multiple model copies, doing so is time-consuming, costly, and harms reproducibility. In this work, we establish an experimental protocol for understanding the effect of optimization nondeterminism on model diversity, allowing us to isolate the effects of a variety of sources of nondeterminism. Surprisingly, we find that all sources of nondeterminism have similar effects on measures of model diversity. To explain this intriguing fact, we identify the instability of model training, taken as an end-to-end procedure, as the key determinant. We show that even one-bit changes in initial parameters result in models converging to vastly different values. Last, we propose two approaches for reducing the effects of instability on run-to-run variability.
Active search is a learning paradigm where we seek to identify as many members of a rare, valuable class as possible given a labeling budget. Previous work on active search has assumed access to a faithful (and expensive) oracle reporting experimental results. However, some settings offer access to cheaper surrogates such as computational simulation that may aid in the search. We propose a model of multifidelity active search, as well as a novel, computationally efficient policy for this setting that is motivated by state-of-the-art classical policies. Our policy is nonmyopic and budget aware, allowing for a dynamic tradeoff between exploration and exploitation. We evaluate the performance of our solution on real-world datasets and demonstrate significantly better performance than natural benchmarks.
Tensor decomposition is a powerful framework for multiway data analysis. Despite the success of existing approaches, they ignore the sparse nature of the tensor data in many real-world applications, explicitly or implicitly assuming dense tensors. To address this model misspecification and to exploit the sparse tensor structures, we propose Nonparametric dEcomposition of Sparse Tensors (\ours), which can capture both the sparse structure properties and complex relationships between the tensor nodes to enhance the embedding estimation. Specifically, we first use completely random measures to construct tensor-valued random processes. We prove that the entry growth is much slower than that of the corresponding tensor size, which implies sparsity. Given finite observations (\ie projections), we then propose two nonparametric decomposition models that couple Dirichlet processes and Gaussian processes to jointly sample the sparse entry indices and the entry values (the latter as a nonlinear mapping of the embeddings), so as to encode both the structure properties and nonlinear relationships of the tensor nodes into the embeddings. Finally, we use the stick-breaking construction and random Fourier features to develop a scalable, stochastic variational learning algorithm. We show the advantage of our approach in sparse tensor generation, and entry index and value prediction in several …
The focus of disentanglement approaches has been on identifying independent factors of variation in data. However, the causal variables underlying real-world observations are often not statistically independent. In this work, we bridge the gap to real-world scenarios by analyzing the behavior of the most prominent disentanglement approaches on correlated data in a large-scale empirical study (including 4260 models). We show and quantify that systematically induced correlations in the dataset are being learned and reflected in the latent representations, which has implications for downstream applications of disentanglement such as fairness. We also demonstrate how to resolve these latent correlations, either using weak supervision during training or by post-hoc correcting a pre-trained model with a small number of labels.
Identifiability is a desirable property of a statistical model: it implies that the true model parameters may be estimated to any desired precision, given sufficient computational resources and data. We study identifiability in the context of representation learning: discovering nonlinear data representations that are optimal with respect to some downstream task. When parameterized as deep neural networks, such representation functions lack identifiability in parameter space, because they are over-parameterized by design. In this paper, building on recent advances in nonlinear Independent Components Analysis, we aim to rehabilitate identifiability by showing that a large family of discriminative models are in fact identifiable in function space, up to a linear indeterminacy. Many models for representation learning in a wide variety of domains have been identifiable in this sense, including text, images and audio, state-of-the-art at time of publication. We derive sufficient conditions for linear identifiability and provide empirical support for the result on both simulated and real-world data.
Several approximate inference algorithms have been proposed to minimize an alpha-divergence between an approximating distribution and a target distribution. Many of these algorithms introduce bias, the magnitude of which becomes problematic in high dimensions. Other algorithms are unbiased. These often seem to suffer from high variance, but little is rigorously known. In this work we study unbiased methods for alpha-divergence minimization through the Signal-to-Noise Ratio (SNR) of the gradient estimator. We study several representative scenarios where strong analytical results are possible, such as fully-factorized or Gaussian distributions. We find that when alpha is not zero, the SNR worsens exponentially in the dimensionality of the problem. This casts doubt on the practicality of these methods. We empirically confirm these theoretical results.
It is not trivial to optimally learn a 3D Convolutional Neural Networks (3D ConvNets) due to high complexity and various options of the training scheme. The most common hand-tuning process starts from learning 3D ConvNets using short video clips and then is followed by learning long-term temporal dependency using lengthy clips, while gradually decaying the learning rate from high to low as training progresses. The fact that such process comes along with several heuristic settings motivates the study to seek an optimal "path" to automate the entire training. In this paper, we decompose the path into a series of training "states" and specify the hyper-parameters, e.g., learning rate and the length of input clips, in each state. The estimation of the knee point on the performance-epoch curve triggers the transition from one state to another. We perform dynamic programming over all the candidate states to plan the optimal permutation of states, i.e., optimization path. Furthermore, we devise a new 3D ConvNets with a unique design of dual-head classifier to improve spatial and temporal discrimination. Extensive experiments on seven public video recognition benchmarks demonstrate the advantages of our proposal. With the optimization planning, our 3D ConvNets achieves superior results when comparing …
Microfluidic biochips are being utilized for clinical diagnostics, including COVID-19 testing, because of they provide sample-to-result turnaround at low cost. Recently, microelectrode-dot-array (MEDA) biochips have been proposed to advance microfluidics technology. A MEDA biochip manipulates droplets of nano/picoliter volumes to automatically execute biochemical protocols. During bioassay execution, droplets are transported in parallel to achieve high-throughput outcomes. However, a major concern associated with the use of MEDA biochips is microelectrode degradation over time. Recent work has shown that formulating droplet transportation as a reinforcement-learning (RL) problem enables the training of policies to capture the underlying health conditions of microelectrodes and ensure reliable fluidic operations. However, the above RL-based approach suffers from two key limitations: 1) it cannot be used for concurrent transportation of multiple droplets; 2) it requires the availability of CCD cameras for monitoring droplet movement. To overcome these problems, we present a multi-agent reinforcement learning (MARL) droplet-routing solution that can be used for various sizes of MEDA biochips with integrated sensors, and we demonstrate the reliable execution of a serial-dilution bioassay with the MARL droplet router on a fabricated MEDA biochip. To facilitate further research, we also present a simulation environment based on the PettingZoo Gym Interface for MARL-guided …
Parallel tempering (PT) is a class of Markov chain Monte Carlo algorithms that constructs a path of distributions annealing between a tractable reference and an intractable target, and then interchanges states along the path to improve mixing in the target. The performance of PT depends on how quickly a sample from the reference distribution makes its way to the target, which in turn depends on the particular path of annealing distributions. However, past work on PT has used only simple paths constructed from convex combinations of the reference and target log-densities. This paper begins by demonstrating that this path performs poorly in the setting where the reference and target are nearly mutually singular. To address this issue, we expand the framework of PT to general families of paths, formulate the choice of path as an optimization problem that admits tractable gradient estimates, and propose a flexible new family of spline interpolation paths for use in practice. Theoretical and empirical results both demonstrate that our proposed methodology breaks previously-established upper performance limits for traditional paths.
Recent literature in few-shot learning (FSL) has shown that transductive methods often outperform their inductive counterparts. However, most transductive solutions, particularly the meta-learning based ones, require inserting trainable parameters on top of some inductive baselines to facilitate transduction. In this paper, we propose a parameterless transductive feature re-representation framework that differs from all existing solutions from the following perspectives. (1) It is widely compatible with existing FSL methods, including meta-learning and fine tuning based models. (2) The framework is simple and introduces no extra training parameters when applied to any architecture. We conduct experiments on three benchmark datasets by applying the framework to both representative meta-learning baselines and state-of-the-art FSL methods. Our framework consistently improves performances in all experiments and refreshes the state-of-the-art FSL results.
Personalized federated learning is tasked with training machine learning models for multiple clients, each with its own data distribution. The goal is to train personalized models collaboratively while accounting for data disparities across clients and reducing communication costs.
We propose a novel approach to this problem using hypernetworks, termed pFedHN for personalized Federated HyperNetworks. In this approach, a central hypernetwork model is trained to generate a set of models, one model for each client. This architecture provides effective parameter sharing across clients while maintaining the capacity to generate unique and diverse personal models. Furthermore, since hypernetwork parameters are never transmitted, this approach decouples the communication cost from the trainable model size. We test pFedHN empirically in several personalized federated learning challenges and find that it outperforms previous methods. Finally, since hypernetworks share information across clients, we show that pFedHN can generalize better to new clients whose distributions differ from any client observed during training.
Representing surfaces as zero level sets of neural networks recently emerged as a powerful modeling paradigm, named Implicit Neural Representations (INRs), serving numerous downstream applications in geometric deep learning and 3D vision. Training INRs previously required choosing between occupancy and distance function representation and different losses with unknown limit behavior and/or bias. In this paper we draw inspiration from the theory of phase transitions of fluids and suggest a loss for training INRs that learns a density function that converges to a proper occupancy function, while its log transform converges to a distance function. Furthermore, we analyze the limit minimizer of this loss showing it satisfies the reconstruction constraints and has minimal surface perimeter, a desirable inductive bias for surface reconstruction. Training INRs with this new loss leads to state-of-the-art reconstructions on a standard benchmark.
The size of Transformer models is growing at an unprecedented rate. It has taken less than one year to reach trillion-level parameters since the release of GPT-3 (175B). Training such models requires both substantial engineering efforts and enormous computing resources, which are luxuries most research teams cannot afford. In this paper, we propose PipeTransformer, which leverages automated elastic pipelining for efficient distributed training of Transformer models. In PipeTransformer, we design an adaptive on the fly freeze algorithm that can identify and freeze some layers gradually during training, and an elastic pipelining system that can dynamically allocate resources to train the remaining active layers. More specifically, PipeTransformer automatically excludes frozen layers from the pipeline, packs active layers into fewer GPUs, and forks more replicas to increase data-parallel width. We evaluate PipeTransformer using Vision Transformer (ViT) on ImageNet and BERT on SQuAD and GLUE datasets. Our results show that compared to the state-of-the-art baseline, PipeTransformer attains up to 2.83-fold speedup without losing accuracy. We also provide various performance analyses for a more comprehensive understanding of our algorithmic and system-wise design. Finally, we have modularized our training system with flexible APIs and made the source code publicly available at https://DistML.ai.
To alleviate the data requirement for training effective binary classifiers in binary classification, many weakly supervised learning settings have been proposed. Among them, some consider using pairwise but not pointwise labels, when pointwise labels are not accessible due to privacy, confidentiality, or security reasons. However, as a pairwise label denotes whether or not two data points share a pointwise label, it cannot be easily collected if either point is equally likely to be positive or negative. Thus, in this paper, we propose a novel setting called pairwise comparison (Pcomp) classification, where we have only pairs of unlabeled data that we know one is more likely to be positive than the other. Firstly, we give a Pcomp data generation process, derive an unbiased risk estimator (URE) with theoretical guarantee, and further improve URE using correction functions. Secondly, we link Pcomp classification to noisy-label learning to develop a progressive URE and improve it by imposing consistency regularization. Finally, we demonstrate by experiments the effectiveness of our methods, which suggests Pcomp is a valuable and practically useful type of pairwise supervision besides the pairwise label.
Hindsight allows reinforcement learning agents to leverage new observations to make inferences about earlier states and transitions. In this paper, we exploit the idea of hindsight and introduce posterior value functions. Posterior value functions are computed by inferring the posterior distribution over hidden components of the state in previous timesteps and can be used to construct novel unbiased baselines for policy gradient methods. Importantly, we prove that these baselines reduce (and never increase) the variance of policy gradient estimators compared to traditional state value functions. While the posterior value function is motivated by partial observability, we extend these results to arbitrary stochastic MDPs by showing that hindsight-capable agents can model stochasticity in the environment as a special case of partial observability. Finally, we introduce a pair of methods for learning posterior value functions and prove their convergence.
We propose Predict then Interpolate (PI), a simple algorithm for learning correlations that are stable across environments. The algorithm follows from the intuition that when using a classifier trained on one environment to make predictions on examples from another environment, its mistakes are informative as to which correlations are unstable. In this work, we prove that by interpolating the distributions of the correct predictions and the wrong predictions, we can uncover an oracle distribution where the unstable correlation vanishes. Since the oracle interpolation coefficients are not accessible, we use group distributionally robust optimization to minimize the worst-case risk across all such interpolations. We evaluate our method on both text classification and image classification. Empirical results demonstrate that our algorithm is able to learn robust classifiers (outperforms IRM by 23.85% on synthetic environments and 12.41% on natural environments). Our code and data are available at https://github.com/YujiaBao/ Predict-then-Interpolate.
We consider a linear autoencoder in which the latent variables are quantized, or corrupted by noise, and the constraint is Schur-concave in the set of latent variances. Although finding the optimal encoder/decoder pair for this setup is a nonconvex optimization problem, we show that decomposing the source into its principal components is optimal. If the constraint is strictly Schur-concave and the empirical covariance matrix has only simple eigenvalues, then any optimal encoder/decoder must decompose the source in this way. As one application, we consider a strictly Schur-concave constraint that estimates the number of bits needed to represent the latent variables under fixed-rate encoding, a setup that we call \emph{Principal Bit Analysis (PBA)}. This yields a practical, general-purpose, fixed-rate compressor that outperforms existing algorithms. As a second application, we show that a prototypical autoencoder-based variable-rate compressor is guaranteed to decompose the source into its principal components.
We study the problem of differentially private (DP) matrix completion under user-level privacy. We design a joint differentially private variant of the popular Alternating-Least-Squares (ALS) method that achieves: i) (nearly) optimal sample complexity for matrix completion (in terms of number of items, users), and ii) the best known privacy/utility trade-off both theoretically, as well as on benchmark data sets. In particular, we provide the first global convergence analysis of ALS with noise introduced to ensure DP, and show that, in comparison to the best known alternative (the Private Frank-Wolfe algorithm by Jain et al. (2018)), our error bounds scale significantly better with respect to the number of items and users, which is critical in practical problems. Extensive validation on standard benchmarks demonstrate that the algorithm, in combination with carefully designed sampling procedures, is significantly more accurate than existing techniques, thus promising to be the first practical DP embedding model.
In this work, we consider how preference models in interactive recommendation systems determine the availability of content and users' opportunities for discovery. We propose an evaluation procedure based on stochastic reachability to quantify the maximum probability of recommending a target piece of content to an user for a set of allowable strategic modifications. This framework allows us to compute an upper bound on the likelihood of recommendation with minimal assumptions about user behavior. Stochastic reachability can be used to detect biases in the availability of content and diagnose limitations in the opportunities for discovery granted to users. We show that this metric can be computed efficiently as a convex program for a variety of practical settings, and further argue that reachability is not inherently at odds with accuracy. We demonstrate evaluations of recommendation algorithms trained on large datasets of explicit and implicit ratings. Our results illustrate how preference models, selection rules, and user interventions impact reachability and how these effects can be distributed unevenly.
We study the relative power of learning with gradient descent on differentiable models, such as neural networks, versus using the corresponding tangent kernels. We show that under certain conditions, gradient descent achieves small error only if a related tangent kernel method achieves a non-trivial advantage over random guessing (a.k.a. weak learning), though this advantage might be very small even when gradient descent can achieve arbitrarily high accuracy. Complementing this, we show that without these conditions, gradient descent can in fact learn with small error even when no kernel method, in particular using the tangent kernel, can achieve a non-trivial advantage over random guessing.
There are two main attack models considered in the adversarial robustness literature: black-box and white-box. We consider these threat models as two ends of a fine-grained spectrum, indexed by the number of queries the adversary can ask. Using this point of view we investigate how many queries the adversary needs to make to design an attack that is comparable to the best possible attack in the white-box model. We give a lower bound on that number of queries in terms of entropy of decision boundaries of the classifier. Using this result we analyze two classical learning algorithms on two synthetic tasks for which we prove meaningful security guarantees. The obtained bounds suggest that some learning algorithms are inherently more robust against query-bounded adversaries than others.
Regression, as a counterpart to classification, is a major paradigm with a wide range of applications. Domain adaptation regression extends it by generalizing a regressor from a labeled source domain to an unlabeled target domain. Existing domain adaptation regression methods have achieved positive results limited only to the shallow regime. A question arises: Why learning invariant representations in the deep regime less pronounced? A key finding of this paper is that classification is robust to feature scaling but regression is not, and aligning the distributions of deep representations will alter feature scale and impede domain adaptation regression. Based on this finding, we propose to close the domain gap through orthogonal bases of the representation spaces, which are free from feature scaling. Inspired by Riemannian geometry of Grassmann manifold, we define a geometrical distance over representation subspaces and learn deep transferable representations by minimizing it. To avoid breaking the geometrical properties of deep representations, we further introduce the bases mismatch penalization to match the ordering of orthogonal bases across representation subspaces. Our method is evaluated on three domain adaptation regression benchmarks, two of which are introduced in this paper. Our method outperforms the state-of-the-art methods significantly, forming early positive results in …
Processing point cloud data is an important component of many real-world systems. As such, a wide variety of point-based approaches have been proposed, reporting steady benchmark improvements over time. We study the key ingredients of this progress and uncover two critical results. First, we find that auxiliary factors like different evaluation schemes, data augmentation strategies, and loss functions, which are independent of the model architecture, make a large difference in performance. The differences are large enough that they obscure the effect of architecture. When these factors are controlled for, PointNet++, a relatively older network, performs competitively with recent methods. Second, a very simple projection-based method, which we refer to as SimpleView, performs surprisingly well. It achieves on par or better results than sophisticated state-of-the-art methods on ModelNet40 while being half the size of PointNet++. It also outperforms state-of-the-art methods on ScanObjectNN, a real-world point cloud benchmark, and demonstrates better cross-dataset generalization. Code is available at https://github.com/princeton-vl/SimpleView.
Deep neural networks are vulnerable to adversarial attacks. Due to their black-box nature, it is rather challenging to interpret and properly repair these incorrect behaviors. This paper focuses on interpreting and repairing the incorrect behaviors of Recurrent Neural Networks (RNNs). We propose a lightweight model-based approach (RNNRepair) to help understand and repair incorrect behaviors of an RNN. Specifically, we build an influence model to characterize the stateful and statistical behaviors of an RNN over all the training data and to perform the influence analysis for the errors. Compared with the existing techniques on influence function, our method can efficiently estimate the influence of existing or newly added training samples for a given prediction at both sample level and segmentation level. Our empirical evaluation shows that the proposed influence model is able to extract accurate and understandable features. Based on the influence model, our proposed technique could effectively infer the influential instances from not only an entire testing sequence but also a segment within that sequence. Moreover, with the sample-level and segment-level influence relations, RNNRepair could further remediate two types of incorrect predictions at the sample level and segment level.
Effective caching is crucial for performance of modern-day computing systems. A key optimization problem arising in caching -- which item to evict to make room for a new item -- cannot be optimally solved without knowing the future. There are many classical approximation algorithms for this problem, but more recently researchers started to successfully apply machine learning to decide what to evict by discovering implicit input patterns and predicting the future. While machine learning typically does not provide any worst-case guarantees, the new field of learning-augmented algorithms proposes solutions which leverage classical online caching algorithms to make the machine-learned predictors robust. We are the first to comprehensively evaluate these learning-augmented algorithms on real-world caching datasets and state-of-the-art machine-learned predictors. We show that a straightforward method -- blindly following either a predictor or a classical robust algorithm, and switching whenever one becomes worse than the other -- has only a low overhead over a well-performing predictor, while competing with classical methods when the coupled predictor fails, thus providing a cheap worst-case insurance.
We study robust testing and estimation of discrete distributions in the strong contamination model. Our results cover both centralized setting and distributed setting with general local information constraints including communication and LDP constraints. Our technique relates the strength of manipulation attacks to the earth-mover distance using Hamming distance as the metric between messages (samples) from the users. In the centralized setting, we provide optimal error bounds for both learning and testing. Our lower bounds under local information constraints build on the recent lower bound methods in distributed inference. In the communication constrained setting, we develop novel algorithms based on random hashing and an L1-L1 isometry.
We introduce a new scalable variational Gaussian process approximation which provides a high fidelity approximation while retaining general applicability. We propose the harmonic kernel decomposition (HKD), which uses Fourier series to decompose a kernel as a sum of orthogonal kernels. Our variational approximation exploits this orthogonality to enable a large number of inducing points at a low computational cost. We demonstrate that, on a range of regression and classification problems, our approach can exploit input space symmetries such as translations and reflections, and it significantly outperforms standard variational methods in scalability and accuracy. Notably, our approach achieves state-of-the-art results on CIFAR-10 among pure GP models.
Pre-trained representations are becoming crucial for many NLP and perception tasks. While representation learning in NLP has transitioned to training on raw text without human annotations, visual and vision-language representations still rely heavily on curated training datasets that are expensive or require expert knowledge. For vision applications, representations are mostly learned using datasets with explicit class labels such as ImageNet or OpenImages. For vision-language, popular datasets like Conceptual Captions, MSCOCO, or CLIP all involve a non-trivial data collection (and cleaning) process. This costly curation process limits the size of datasets and hence hinders the scaling of trained models. In this paper, we leverage a noisy dataset of over one billion image alt-text pairs, obtained without expensive filtering or post-processing steps in the Conceptual Captions dataset. A simple dual-encoder architecture learns to align visual and language representations of the image and text pairs using a contrastive loss. We show that the scale of our corpus can make up for its noise and leads to state-of-the-art representations even with such a simple learning scheme. Our visual representation achieves strong performance when transferred to classification tasks such as ImageNet and VTAB. The aligned visual and language representations enables zero-shot image classification and also …
This paper introduces Stochastic Gradient Langevin Boosting (SGLB) - a powerful and efficient machine learning framework that may deal with a wide range of loss functions and has provable generalization guarantees. The method is based on a special form of the Langevin diffusion equation specifically designed for gradient boosting. This allows us to theoretically guarantee the global convergence even for multimodal loss functions, while standard gradient boosting algorithms can guarantee only local optimum. We also empirically show that SGLB outperforms classic gradient boosting when applied to classification tasks with 0-1 loss function, which is known to be multimodal.
We present a method for estimating neural scenes representations of objects given only a single image. The core of our method is the estimation of a geometric scaffold for the object and its use as a guide for the reconstruction of the underlying radiance field. Our formulation is based on a generative process that first maps a latent code to a voxelized shape, and then renders it to an image, with the object appearance being controlled by a second latent code. During inference, we optimize both the latent codes and the networks to fit a test image of a new object. The explicit disentanglement of shape and appearance allows our model to be fine-tuned given a single image. We can then render new views in a geometrically consistent manner and they represent faithfully the input object. Additionally, our method is able to generalize to images outside of the training domain (more realistic renderings and even real photographs). Finally, the inferred geometric scaffold is itself an accurate estimate of the object's 3D shape. We demonstrate in several experiments the effectiveness of our approach in both synthetic and real images.
Making predictions and quantifying their uncertainty when the input data is sequential is a fundamental learning challenge, recently attracting increasing attention. We develop SigGPDE, a new scalable sparse variational inference framework for Gaussian Processes (GPs) on sequential data. Our contribution is twofold. First, we construct inducing variables underpinning the sparse approximation so that the resulting evidence lower bound (ELBO) does not require any matrix inversion. Second, we show that the gradients of the GP signature kernel are solutions of a hyperbolic partial differential equation (PDE). This theoretical insight allows us to build an efficient back-propagation algorithm to optimize the ELBO. We showcase the significant computational gains of SigGPDE compared to existing methods, while achieving state-of-the-art performance for classification tasks on large datasets of up to 1 million multivariate time series.
Self-training is a standard approach to semi-supervised learning where the learner's own predictions on unlabeled data are used as supervision during training. In this paper, we reinterpret this label assignment process as an optimal transportation problem between examples and classes, wherein the cost of assigning an example to a class is mediated by the current predictions of the classifier. This formulation facilitates a practical annealing strategy for label assignment and allows for the inclusion of prior knowledge on class proportions via flexible upper bound constraints. The solutions to these assignment problems can be efficiently approximated using Sinkhorn iteration, thus enabling their use in the inner loop of standard stochastic optimization algorithms. We demonstrate the effectiveness of our algorithm on the CIFAR-10, CIFAR-100, and SVHN datasets in comparison with FixMatch, a state-of-the-art self-training algorithm.
Sketch drawings capture the salient information of visual concepts. Previous work has shown that neural networks are capable of producing sketches of natural objects drawn from a small number of classes. While earlier approaches focus on generation quality or retrieval, we explore properties of image representations learned by training a model to produce sketches of images. We show that this generative, class-agnostic model produces informative embeddings of images from novel examples, classes, and even novel datasets in a few-shot setting. Additionally, we find that these learned representations exhibit interesting structure and compositionality.
Sparse Bayesian Learning (SBL) is a powerful framework for attaining sparsity in probabilistic models. Herein, we propose a coordinate ascent algorithm for SBL termed Relevance Matching Pursuit (RMP) and show that, as its noise variance parameter goes to zero, RMP exhibits a surprising connection to Stepwise Regression. Further, we derive novel guarantees for Stepwise Regression algorithms, which also shed light on RMP. Our guarantees for Forward Regression improve on deterministic and probabilistic results for Orthogonal Matching Pursuit with noise. Our analysis of Backward Regression culminates in a bound on the residual of the optimal solution to the subset selection problem that, if satisfied, guarantees the optimality of the result. To our knowledge, this bound is the first that can be computed in polynomial time and depends chiefly on the smallest singular value of the matrix. We report numerical experiments using a variety of feature selection algorithms. Notably, RMP and its limiting variant are both efficient and maintain strong performance with correlated features.
Approximations to Gaussian processes (GPs) based on inducing variables, combined with variational inference techniques, enable state-of-the-art sparse approaches to infer GPs at scale through mini-batch based learning. In this work, we further push the limits of scalability of sparse GPs by allowing large number of inducing variables without imposing a special structure on the inducing inputs. In particular, we introduce a novel hierarchical prior, which imposes sparsity on the set of inducing variables. We treat our model variationally, and we experimentally show considerable computational gains compared to standard sparse GPs when sparsity on the inducing variables is realized considering the nearest inducing inputs of a random mini-batch of the data. We perform an extensive experimental validation that demonstrates the effectiveness of our approach compared to the state-of-the-art. Our approach enables the possibility to use sparse GPs using a large number of inducing points without incurring a prohibitive computational cost.
Despite the success of existing tensor factorization methods, most of them conduct a multilinear decomposition, and rarely exploit powerful modeling frameworks, like deep neural networks, to capture a variety of complicated interactions in data. More important, for highly expressive, deep factorization, we lack an effective approach to handle streaming data, which are ubiquitous in real-world applications. To address these issues, we propose SBTD, a Streaming Bayesian Deep Tensor factorization method. We first use Bayesian neural networks (NNs) to build a deep tensor factorization model. We assign a spike-and-slab prior over each NN weight to encourage sparsity and to prevent overfitting. We then use multivariate Delta's method and moment matching to approximate the posterior of the NN output and calculate the running model evidence, based on which we develop an efficient streaming posterior inference algorithm in the assumed-density-filtering and expectation propagation framework. Our algorithm provides responsive incremental updates for the posterior of the latent factors and NN weights upon receiving newly observed tensor entries, and meanwhile identify and inhibit redundant/useless weights. We show the advantages of our approach in four real-world applications.
Many cluster similarity indices are used to evaluate clustering algorithms, and choosing the best one for a particular task remains an open problem. We demonstrate that this problem is crucial: there are many disagreements among the indices, these disagreements do affect which algorithms are preferred in applications, and this can lead to degraded performance in real-world systems. We propose a theoretical framework to tackle this problem: we develop a list of desirable properties and conduct an extensive theoretical analysis to verify which indices satisfy them. This allows for making an informed choice: given a particular application, one can first select properties that are desirable for the task and then identify indices satisfying these. Our work unifies and considerably extends existing attempts at analyzing cluster similarity indices: we introduce new properties, formalize existing ones, and mathematically prove or disprove each property for an extensive list of validation indices. This broader and more rigorous approach leads to recommendations that considerably differ from how validation indices are currently being chosen by practitioners. Some of the most popular indices are even shown to be dominated by previously overlooked ones.
Deep neural networks have been shown to be susceptible to adversarial attacks. This lack of adversarial robustness is even more pronounced when models are compressed in order to meet hardware limitations. Hence, if adversarial robustness is an issue, training of sparsely connected networks necessitates considering adversarially robust sparse learning. Motivated by the efficient and stable computational function of the brain in the presence of a highly dynamic synaptic connectivity structure, we propose an intrinsically sparse rewiring approach to train neural networks with state-of-the-art robust learning objectives under high sparsity. Importantly, in contrast to previously proposed pruning techniques, our approach satisfies global connectivity constraints throughout robust optimization, i.e., it does not require dense pre-training followed by pruning. Based on a Bayesian posterior sampling principle, a network rewiring process simultaneously learns the sparse connectivity structure and the robustness-accuracy trade-off based on the adversarial learning objective. Although our networks are sparsely connected throughout the whole training process, our experimental benchmark evaluations show that their performance is superior to recently proposed robustness-aware network pruning methods which start from densely connected networks.
Recently, neural networks purely based on attention were shown to address image understanding tasks such as image classification. These high-performing vision transformers are pre-trained with hundreds of millions of images using a large infrastructure, thereby limiting their adoption.
In this work, we produce competitive convolution-free transformers trained on ImageNet only using a single computer in less than 3 days. Our reference vision transformer (86M parameters) achieves top-1 accuracy of 83.1% (single-crop) on ImageNet with no external data.
We also introduce a teacher-student strategy specific to transformers. It relies on a distillation token ensuring that the student learns from the teacher through attention, typically from a convnet teacher. The learned transformers are competitive (85.2% top-1 acc.) with the state of the art on ImageNet, and similarly when transferred to other tasks. We will share our code and models.
Detecting semantic anomalies is challenging due to the countless ways in which they may appear in real-world data. While enhancing the robustness of networks may be sufficient for modeling simplistic anomalies, there is no good known way of preparing models for all potential and unseen anomalies that can potentially occur, such as the appearance of new object classes. In this paper, we show that a previously overlooked strategy for anomaly detection (AD) is to introduce an explicit inductive bias toward representations transferred over from some large and varied semantic task. We rigorously verify our hypothesis in controlled trials that utilize intervention, and show that it gives rise to surprisingly effective auxiliary objectives that outperform previous AD paradigms.
In this paper, we propose a novel noise-robust semi-supervised deep generative model by jointly tackling noisy labels and outliers simultaneously in a unified robust semi-supervised variational autoencoder (URSVAE). Typically, the uncertainty of of input data is characterized by placing uncertainty prior on the parameters of the probability density distributions in order to ensure the robustness of the variational encoder towards outliers. Subsequently, a noise transition model is integrated naturally into our model to alleviate the detrimental effects of noisy labels. Moreover, a robust divergence measure is employed to further enhance the robustness, where a novel variational lower bound is derived and optimized to infer the network parameters. By proving the influence function on the proposed evidence lower bound is bounded, the enormous potential of the proposed model in the classification in the presence of the compound noise is demonstrated. The experimental results highlight the superiority of the proposed framework by the evaluating on image classification tasks and comparing with the state-of-the-art approaches.
Previous work has cast doubt on the general framework of uniform convergence and its ability to explain generalization in neural networks. By considering a specific dataset, it was observed that a neural network completely misclassifies a projection of the training data (adversarial set), rendering any existing generalization bound based on uniform convergence vacuous. We provide an extensive theoretical investigation of the previously studied data setting through the lens of infinitely-wide models. We prove that the Neural Tangent Kernel (NTK) also suffers from the same phenomenon and we uncover its origin. We highlight the important role of the output bias and show theoretically as well as empirically how a sensible choice completely mitigates the problem. We identify sharp phase transitions in the accuracy on the adversarial set and study its dependency on the training sample size. As a result, we are able to characterize critical sample sizes beyond which the effect disappears. Moreover, we study decompositions of a neural network into a clean and noisy part by considering its canonical decomposition into its different eigenfunctions and show empirically that for too small bias the adversarial phenomenon still persists.
Co-part segmentation is an important problem in computer vision for its rich applications. We propose an unsupervised learning approach for co-part segmentation from images. For the training stage, we leverage motion information embedded in videos and explicitly extract latent representations to segment meaningful object parts. More importantly, we introduce a dual procedure of part-assembly to form a closed loop with part-segmentation, enabling an effective self-supervision. We demonstrate the effectiveness of our approach with a host of extensive experiments, ranging from human bodies, hands, quadruped, and robot arms. We show that our approach can achieve meaningful and compact part segmentation, outperforming state-of-the-art approaches on diverse benchmarks.
We propose a novel Wasserstein distributional normalization method that can classify noisy labeled data accurately. Recently, noisy labels have been successfully handled based on small-loss criteria, but have not been clearly understood from the theoretical point of view. In this paper, we address this problem by adopting distributionally robust optimization (DRO). In particular, we present a theoretical investigation of the distributional relationship between uncertain and certain samples based on the small-loss criteria. Our method takes advantage of this relationship to exploit useful information from uncertain samples. To this end, we normalize uncertain samples into the robustly certified region by introducing the non-parametric Ornstein-Ulenbeck type of Wasserstein gradient flows called Wasserstein distributional normalization, which is cheap and fast to implement. We verify that network confidence and distributional certification are fundamentally correlated and show the concentration inequality when the network escapes from over-parameterization. Experimental results demonstrate that our non-parametric classification method outperforms other parametric baselines on the Clothing1M and CIFAR-10/100 datasets when the data have diverse noisy labels.
Most of the current self-supervised representation learning (SSL) methods are based on the contrastive loss and the instance-discrimination task, where augmented versions of the same image instance ("positives") are contrasted with instances extracted from other images ("negatives"). For the learning to be effective, many negatives should be compared with a positive pair, which is computationally demanding. In this paper, we propose a different direction and a new loss function for SSL, which is based on the whitening of the latent-space features. The whitening operation has a "scattering" effect on the batch samples, avoiding degenerate solutions where all the sample representations collapse to a single point. Our solution does not require asymmetric networks and it is conceptually simple. Moreover, since negatives are not needed, we can extract multiple positive pairs from the same image instance. The source code of the method and of all the experiments is available at: https://github.com/htdt/self-supervised.
Social: Games Among Us Thu 22 Jul 06:00 p.m.
Show up to play some (online, possibly board) games with people! We’ll have some suggestions but feel free to bring your own game!