Oral: Deep Learning Algorithms 5 Wed 21 Jul 02:00 a.m.


Most neural network pruning methods, such as filter-level and layer-level prunings, prune the network model along one dimension (depth, width, or resolution) solely to meet a computational budget. However, such a pruning policy often leads to excessive reduction of that dimension, thus inducing a huge accuracy loss. To alleviate this issue, we argue that pruning should be conducted along three dimensions comprehensively. For this purpose, our pruning framework formulates pruning as an optimization problem. Specifically, it first casts the relationships between a certain model's accuracy and depth/width/resolution into a polynomial regression and then maximizes the polynomial to acquire the optimal values for the three dimensions. Finally, the model is pruned along the three optimal dimensions accordingly. In this framework, since collecting too much data for training the regression is very time-costly, we propose two approaches to lower the cost: 1) specializing the polynomial to ensure an accurate regression even with less training data; 2) employing iterative pruning and fine-tuning to collect the data faster. Extensive experiments show that our proposed algorithm surpasses state-of-the-art pruning algorithms and even neural architecture search-based algorithms.

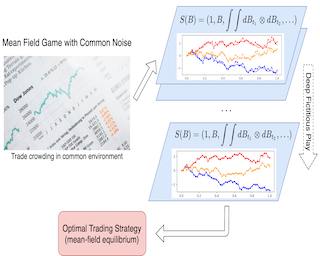
Existing deep learning methods for solving mean-field games (MFGs) with common noise fix the sampling common noise paths and then solve the corresponding MFGs. This leads to a nested loop structure with millions of simulations of common noise paths in order to produce accurate solutions, which results in prohibitive computational cost and limits the applications to a large extent. In this paper, based on the rough path theory, we propose a novel single-loop algorithm, named signatured deep fictitious play (Sig-DFP), by which we can work with the unfixed common noise setup to avoid the nested loop structure and reduce the computational complexity significantly. The proposed algorithm can accurately capture the effect of common uncertainty changes on mean-field equilibria without further training of neural networks, as previously needed in the existing machine learning algorithms. The efficiency is supported by three applications, including linear-quadratic MFGs, mean-field portfolio game, and mean-field game of optimal consumption and investment. Overall, we provide a new point of view from the rough path theory to solve MFGs with common noise with significantly improved efficiency and an extensive range of applications. In addition, we report the first deep learning work to deal with extended MFGs (a mean-field interaction …

Message passing neural networks have become a method of choice for learning on graphs, in particular the prediction of chemical properties and the acceleration of molecular dynamics studies. While they readily scale to large training data sets, previous approaches have proven to be less data efficient than kernel methods. We identify limitations of invariant representations as a major reason and extend the message passing formulation to rotationally equivariant representations. On this basis, we propose the polarizable atom interaction neural network (PaiNN) and improve on common molecule benchmarks over previous networks, while reducing model size and inference time. We leverage the equivariant atomwise representations obtained by PaiNN for the prediction of tensorial properties. Finally, we apply this to the simulation of molecular spectra, achieving speedups of 4-5 orders of magnitude compared to the electronic structure reference.

In this work, we focus on the ability of graph neural networks (GNNs) to learn long-range patterns in graphs with edge features. Learning patterns that involve longer paths in the graph, requires using deeper GNNs. However, GNNs suffer from a drop in performance with increasing network depth. To improve the performance of deeper GNNs, previous works have investigated normalization techniques and various types of skip connections. While they are designed to improve depth-wise backpropagation between the representations of the same node in successive layers, they do not improve breadth-wise backpropagation between representations of neighbouring nodes. To analyse the consequences, we design synthetic datasets serving as a testbed for the ability of GNNs to learn long-range patterns. Our analysis shows that several commonly used GNN variants with only depth-wise skip connections indeed have problems learning long-range patterns. They are clearly outperformed by an attention-based GNN architecture that we propose for improving both depth- and breadth-wise backpropagation. We also verify that the presented architecture is competitive on real-world data.

Face recognition is an important yet challenging problem in computer vision. A major challenge in practical face recognition applications lies in significant variations between profile and frontal faces. Traditional techniques address this challenge either by synthesizing frontal faces or by pose invariant learning. In this paper, we propose a novel method with Lie algebra theory to explore how face rotation in the 3D space affects the deep feature generation process of convolutional neural networks (CNNs). We prove that face rotation in the image space is equivalent to an additive residual component in the feature space of CNNs, which is determined solely by the rotation. Based on this theoretical finding, we further design a Lie Algebraic Residual Network (LARNet) for tackling pose robust face recognition. Our LARNet consists of a residual subnet for decoding rotation information from input face images, and a gating subnet to learn rotation magnitude for controlling the strength of the residual component contributing to the feature learning process. Comprehensive experimental evaluations on both frontal-profile face datasets and general face recognition datasets convincingly demonstrate that our method consistently outperforms the state-of-the-art ones.
Oral: Reinforcement Learning 4 Wed 21 Jul 02:00 a.m.

Policies for partially observed Markov decision processes can be efficiently learned by imitating expert policies generated using asymmetric information. Unfortunately, existing approaches for this kind of imitation learning have a serious flaw: the expert does not know what the trainee cannot see, and as a result may encourage actions that are sub-optimal or unsafe under partial information. To address this issue, we derive an update which, when applied iteratively to an expert, maximizes the expected reward of the trainee's policy. Using this update, we construct a computationally efficient algorithm, adaptive asymmetric DAgger (A2D), that jointly trains the expert and trainee policies. We then show that A2D allows the trainee to safely imitate the modified expert, and outperforms policies learned either by imitating a fixed expert or through direct reinforcement learning.

We consider the problem of spatial path planning. In contrast to the classical solutions which optimize a new plan from scratch and assume access to the full map with ground truth obstacle locations, we learn a planner from the data in a differentiable manner that allows us to leverage statistical regularities from past data. We propose Spatial Planning Transformers (SPT), which given an obstacle map learns to generate actions by planning over long-range spatial dependencies, unlike prior data-driven planners that propagate information locally via convolutional structure in an iterative manner. In the setting where the ground truth map is not known to the agent, we leverage pre-trained SPTs in an end-to-end framework that has the structure of mapper and planner built into it which allows seamless generalization to out-of-distribution maps and goals. SPTs outperform prior state-of-the-art differentiable planners across all the setups for both manipulation and navigation tasks, leading to an absolute improvement of 7-19\%.
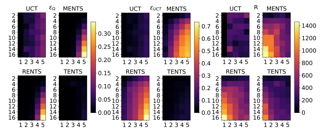
Monte-Carlo planning and Reinforcement Learning (RL) are essential to sequential decision making. The recent AlphaGo and AlphaZero algorithms have shown how to successfully combine these two paradigms to solve large-scale sequential decision problems. These methodologies exploit a variant of the well-known UCT algorithm to trade off the exploitation of good actions and the exploration of unvisited states, but their empirical success comes at the cost of poor sample-efficiency and high computation time. In this paper, we overcome these limitations by introducing the use of convex regularization in Monte-Carlo Tree Search (MCTS) to drive exploration efficiently and to improve policy updates. First, we introduce a unifying theory on the use of generic convex regularizers in MCTS, deriving the first regret analysis of regularized MCTS and showing that it guarantees an exponential convergence rate. Second, we exploit our theoretical framework to introduce novel regularized backup operators for MCTS, based on the relative entropy of the policy update and, more importantly, on the Tsallis entropy of the policy, for which we prove superior theoretical guarantees. We empirically verify the consequence of our theoretical results on a toy problem. Finally, we show how our framework can easily be incorporated in AlphaGo and we empirically …

We develop theory and algorithms for average-reward on-policy Reinforcement Learning (RL). We first consider bounding the difference of the long-term average reward for two policies. We show that previous work based on the discounted return (Schulman et al. 2015, Achiam et al. 2017) results in a non-meaningful lower bound in the average reward setting. By addressing the average-reward criterion directly, we then derive a novel bound which depends on the average divergence between the policies and on Kemeny's constant. Based on this bound, we develop an iterative procedure which produces a sequence of monotonically improved policies for the average reward criterion. This iterative procedure can then be combined with classic Deep Reinforcement Learning (DRL) methods, resulting in practical DRL algorithms that target the long-run average reward criterion. In particular, we demonstrate that Average-Reward TRPO (ATRPO), which adapts the on-policy TRPO algorithm to the average-reward criterion, significantly outperforms TRPO in the most challenging MuJuCo environments.
https://drive.google.com/file/d/1lRV72XaKoxZjgQrLXBJhsM82x54_1Vc4/view?usp=sharing

We present several classes of reinforcement learning algorithms that safely generalize to Markov decision processes (MDPs) not seen during training. Specifically, we study the setting in which some set of MDPs is accessible for training. The goal is to generalize safely to MDPs that are sampled from the same distribution, but which may not be in the set accessible for training. For various definitions of safety, our algorithms give probabilistic guarantees that agents can safely generalize to MDPs that are sampled from the same distribution but are not necessarily in the training set. These algorithms are a type of Seldonian algorithm (Thomas et al., 2019), which is a class of machine learning algorithms that return models with probabilistic safety guarantees for user-specified definitions of safety.

A major challenge in reinforcement learning is the design of exploration strategies, especially for environments with sparse reward structures and continuous state and action spaces. Intuitively, if the reinforcement signal is very scarce, the agent should rely on some form of short-term memory in order to cover its environment efficiently. We propose a new exploration method, based on two intuitions: (1) the choice of the next exploratory action should depend not only on the (Markovian) state of the environment, but also on the agent's trajectory so far, and (2) the agent should utilize a measure of spread in the state space to avoid getting stuck in a small region. Our method leverages concepts often used in statistical physics to provide explanations for the behavior of simplified (polymer) chains in order to generate persistent (locally self-avoiding) trajectories in state space. We discuss the theoretical properties of locally self-avoiding walks and their ability to provide a kind of short-term memory through a decaying temporal correlation within the trajectory. We provide empirical evaluations of our approach in a simulated 2D navigation task, as well as higher-dimensional MuJoCo continuous control locomotion tasks with sparse rewards.
Oral: Optimization and Algorithms 1 Wed 21 Jul 02:00 a.m.

Softmax classifiers with a very large number of classes naturally occur in many applications such as natural language processing and information retrieval. The calculation of full softmax is costly from the computational and energy perspective. There have been various sampling approaches to overcome this challenge, popularly known as negative sampling (NS). Ideally, NS should sample negative classes from a distribution that is dependent on the input data, the current parameters, and the correct positive class. Unfortunately, due to the dynamically updated parameters and data samples, there is no sampling scheme that is provably adaptive and samples the negative classes efficiently. Therefore, alternative heuristics like random sampling, static frequency-based sampling, or learning-based biased sampling, which primarily trade either the sampling cost or the adaptivity of samples per iteration are adopted. In this paper, we show two classes of distributions where the sampling scheme is truly adaptive and provably generates negative samples in near-constant time. Our implementation in C++ on CPU is significantly superior, both in terms of wall-clock time and accuracy, compared to the most optimized TensorFlow implementations of other popular negative sampling approaches on powerful NVIDIA V100 GPU.

Model parallelism has become a necessity for training modern large-scale deep language models. In this work, we identify a new and orthogonal dimension from existing model parallel approaches: it is possible to perform pipeline parallelism within a single training sequence for Transformer-based language models thanks to its autoregressive property. This enables a more fine-grained pipeline compared with previous work. With this key idea, we design TeraPipe, a high-performance token-level pipeline parallel algorithm for synchronous model-parallel training of Transformer-based language models. We develop a novel dynamic programming-based algorithm to calculate the optimal pipelining execution scheme given a specific model and cluster configuration. We show that TeraPipe can speed up the training by 5.0x for the largest GPT-3 model with 175 billion parameters on an AWS cluster with 48 p3.16xlarge instances compared with state-of-the-art model-parallel methods. The code for reproduction can be found at https://github.com/zhuohan123/terapipe


The recent work by Rendle et al. (2020), based on empirical observations, argues that matrix-factorization collaborative filtering (MCF) compares favorably to neural collaborative filtering (NCF), and conjectures the dot product's superiority over the feed-forward neural network as similarity function. In this paper, we address the comparison rigorously by answering the following questions: 1. what is the limiting expressivity of each model; 2. under the practical gradient descent, to which solution does each optimization path converge; 3. how would the models generalize under the inductive and transductive learning setting. Our results highlight the similar expressivity for the overparameterized NCF and MCF as kernelized predictors, and reveal the relation between their optimization paths. We further show their different generalization behaviors, where MCF and NCF experience specific tradeoff and comparison in the transductive and inductive collaborative filtering setting. Lastly, by showing a novel generalization result, we reveal the critical role of correcting exposure bias for model evaluation in the inductive setting. Our results explain some of the previously observed conflicts, and we provide synthetic and real-data experiments to shed further insights to this topic.



Decentralized learning enables a group of collaborative agents to learn models using a distributed dataset without the need for a central parameter server. Recently, decentralized learning algorithms have demonstrated state-of-the-art results on benchmark data sets, comparable with centralized algorithms. However, the key assumption to achieve competitive performance is that the data is independently and identically distributed (IID) among the agents which, in real-life applications, is often not applicable. Inspired by ideas from continual learning, we propose Cross-Gradient Aggregation (CGA), a novel decentralized learning algorithm where (i) each agent aggregates cross-gradient information, i.e., derivatives of its model with respect to its neighbors' datasets, and (ii) updates its model using a projected gradient based on quadratic programming (QP). We theoretically analyze the convergence characteristics of CGA and demonstrate its efficiency on non-IID data distributions sampled from the MNIST and CIFAR-10 datasets. Our empirical comparisons show superior learning performance of CGA over existing state-of-the-art decentralized learning algorithms, as well as maintaining the improved performance under information compression to reduce peer-to-peer communication overhead. The code is available here on GitHub.
Oral: Reinforcement Learning and Planning 3 Wed 21 Jul 02:00 a.m.



We propose the k-Shortest-Path (k-SP) constraint: a novel constraint on the agent’s trajectory that improves the sample efficiency in sparse-reward MDPs. We show that any optimal policy necessarily satisfies the k-SP constraint. Notably, the k-SP constraint prevents the policy from exploring state-action pairs along the non-k-SP trajectories (e.g., going back and forth). However, in practice, excluding state-action pairs may hinder the convergence of RL algorithms. To overcome this, we propose a novel cost function that penalizes the policy violating SP constraint, instead of completely excluding it. Our numerical experiment in a tabular RL setting demonstrates that the SP-constraint can significantly reduce the trajectory space of policy. As a result, our constraint enables more sample efficient learning by suppressing redundant exploration and exploitation. Our experiments on MiniGrid, DeepMind Lab, Atari, and Fetch show that the proposed method significantly improves proximal policy optimization (PPO) and outperforms existing novelty-seeking exploration methods including count-based exploration even in continuous control tasks, indicating that it improves the sample efficiency by preventing the agent from taking redundant actions.

Many modern approaches to offline Reinforcement Learning (RL) utilize behavior regularization, typically augmenting a model-free actor critic algorithm with a penalty measuring divergence of the policy from the offline data. In this work, we propose an alternative approach to encouraging the learned policy to stay close to the data, namely parameterizing the critic as the log-behavior-policy, which generated the offline data, plus a state-action value offset term, which can be learned using a neural network. Behavior regularization then corresponds to an appropriate regularizer on the offset term. We propose using a gradient penalty regularizer for the offset term and demonstrate its equivalence to Fisher divergence regularization, suggesting connections to the score matching and generative energy-based model literature. We thus term our resulting algorithm Fisher-BRC (Behavior Regularized Critic). On standard offline RL benchmarks, Fisher-BRC achieves both improved performance and faster convergence over existing state-of-the-art methods.


We consider the offline reinforcement learning (RL) setting where the agent aims to optimize the policy solely from the data without further environment interactions. In offline RL, the distributional shift becomes the primary source of difficulty, which arises from the deviation of the target policy being optimized from the behavior policy used for data collection. This typically causes overestimation of action values, which poses severe problems for model-free algorithms that use bootstrapping. To mitigate the problem, prior offline RL algorithms often used sophisticated techniques that encourage underestimation of action values, which introduces an additional set of hyperparameters that need to be tuned properly. In this paper, we present an offline RL algorithm that prevents overestimation in a more principled way. Our algorithm, OptiDICE, directly estimates the stationary distribution corrections of the optimal policy and does not rely on policy-gradients, unlike previous offline RL algorithms. Using an extensive set of benchmark datasets for offline RL, we show that OptiDICE performs competitively with the state-of-the-art methods.

Deep reinforcement learning (DRL) has proven successful for many difficult control problems by learning policies represented by neural networks. However, the complexity of neural network-based policies—involving thousands of composed non-linear operators—can render them problematic to understand, trust, and deploy. In contrast, simple policies comprising short symbolic expressions can facilitate human understanding, while also being transparent and exhibiting predictable behavior. To this end, we propose deep symbolic policy, a novel approach to directly search the space of symbolic policies. We use an autoregressive recurrent neural network to generate control policies represented by tractable mathematical expressions, employing a risk-seeking policy gradient to maximize performance of the generated policies. To scale to environments with multi-dimensional action spaces, we propose an "anchoring" algorithm that distills pre-trained neural network-based policies into fully symbolic policies, one action dimension at a time. We also introduce two novel methods to improve exploration in DRL-based combinatorial optimization, building on ideas of entropy regularization and distribution initialization. Despite their dramatically reduced complexity, we demonstrate that discovered symbolic policies outperform seven state-of-the-art DRL algorithms in terms of average rank and average normalized episodic reward across eight benchmark environments.
Oral: Reinforcement Learning 3 Wed 21 Jul 02:00 a.m.

Multi-agent settings in the real world often involve tasks with varying types and quantities of agents and non-agent entities; however, common patterns of behavior often emerge among these agents/entities. Our method aims to leverage these commonalities by asking the question: What is the expected utility of each agent when only considering a randomly selected sub-group of its observed entities?'' By posing this counterfactual question, we can recognize state-action trajectories within sub-groups of entities that we may have encountered in another task and use what we learned in that task to inform our prediction in the current one. We then reconstruct a prediction of the full returns as a combination of factors considering these disjoint groups of entities and train thisrandomly factorized" value function as an auxiliary objective for value-based multi-agent reinforcement learning. By doing so, our model can recognize and leverage similarities across tasks to improve learning efficiency in a multi-task setting. Our approach, Randomized Entity-wise Factorization for Imagined Learning (REFIL), outperforms all strong baselines by a significant margin in challenging multi-task StarCraft micromanagement settings.

We introduce an approach for understanding control policies represented as recurrent neural networks. Recent work has approached this problem by transforming such recurrent policy networks into finite-state machines (FSM) and then analyzing the equivalent minimized FSM. While this led to interesting insights, the minimization process can obscure a deeper understanding of a machine's operation by merging states that are semantically distinct. To address this issue, we introduce an analysis approach that starts with an unminimized FSM and applies more-interpretable reductions that preserve the key decision points of the policy. We also contribute an attention tool to attain a deeper understanding of the role of observations in the decisions. Our case studies on 7 Atari games and 3 control benchmarks demonstrate that the approach can reveal insights that have not been previously noticed.

Social learning is a key component of human and animal intelligence. By taking cues from the behavior of experts in their environment, social learners can acquire sophisticated behavior and rapidly adapt to new circumstances. This paper investigates whether independent reinforcement learning (RL) agents in a multi-agent environment can learn to use social learning to improve their performance. We find that in most circumstances, vanilla model-free RL agents do not use social learning. We analyze the reasons for this deficiency, and show that by imposing constraints on the training environment and introducing a model-based auxiliary loss we are able to obtain generalized social learning policies which enable agents to: i) discover complex skills that are not learned from single-agent training, and ii) adapt online to novel environments by taking cues from experts present in the new environment. In contrast, agents trained with model-free RL or imitation learning generalize poorly and do not succeed in the transfer tasks. By mixing multi-agent and solo training, we can obtain agents that use social learning to gain skills that they can deploy when alone, even out-performing agents trained alone from the start.
In this paper we investigate the Follow the Regularized Leader dynamics in sequential imperfect information games (IIG). We generalize existing results of Poincaré recurrence from normal-form games to zero-sum two-player imperfect information games and other sequential game settings. We then investigate how adapting the reward (by adding a regularization term) of the game can give strong convergence guarantees in monotone games. We continue by showing how this reward adaptation technique can be leveraged to build algorithms that converge exactly to the Nash equilibrium. Finally, we show how these insights can be directly used to build state-of-the-art model-free algorithms for zero-sum two-player Imperfect Information Games (IIG).

We consider the problem of learning useful robotic skills from previously collected offline data without access to manually specified rewards or additional online exploration, a setting that is becoming increasingly important for scaling robot learning by reusing past robotic data. In particular, we propose the objective of learning a functional understanding of the environment by learning to reach any goal state in a given dataset. We employ goal-conditioned Q-learning with hindsight relabeling and develop several techniques that enable training in a particularly challenging offline setting. We find that our method can operate on high-dimensional camera images and learn a variety of skills on real robots that generalize to previously unseen scenes and objects. We also show that our method can learn to reach long-horizon goals across multiple episodes through goal chaining, and learn rich representations that can help with downstream tasks through pre-training or auxiliary objectives.

We study the problem of zero-shot coordination (ZSC), where agents must independently produce strategies for a collaborative game that are compatible with novel partners not seen during training. Our first contribution is to consider the need for diversity in generating such agents. Because self-play (SP) agents control their own trajectory distribution during training, each policy typically only performs well on this exact distribution. As a result, they achieve low scores in ZSC, since playing with another agent is likely to put them in situations they have not encountered during training. To address this issue, we train a common best response (BR) to a population of agents, which we regulate to be diverse. To this end, we introduce \textit{Trajectory Diversity} (TrajeDi) -- a differentiable objective for generating diverse reinforcement learning policies. We derive TrajeDi as a generalization of the Jensen-Shannon divergence between policies and motivate it experimentally in two simple settings. We then focus on the collaborative card game Hanabi, demonstrating the scalability of our method and improving upon the cross-play scores of both independently trained SP agents and BRs to unregularized populations.

Value decomposition recently injects vigorous vitality into multi-agent actor-critic methods. However, existing decomposed actor-critic methods cannot guarantee the convergence of global optimum. In this paper, we present a novel multi-agent actor-critic method, FOP, which can factorize the optimal joint policy induced by maximum-entropy multi-agent reinforcement learning (MARL) into individual policies. Theoretically, we prove that factorized individual policies of FOP converge to the global optimum. Empirically, in the well-known matrix game and differential game, we verify that FOP can converge to the global optimum for both discrete and continuous action spaces. We also evaluate FOP on a set of StarCraft II micromanagement tasks, and demonstrate that FOP substantially outperforms state-of-the-art decomposed value-based and actor-critic methods.
Oral: Optimization 3 Wed 21 Jul 02:00 a.m.


The predominant measure for the performance of an algorithm is its worst-case approximation guarantee. While worst-case approximations give desirable robustness guarantees, they can differ significantly from the performance of an algorithm in practice. For the problem of monotone submodular maximization under a cardinality constraint, the greedy algorithm is known to obtain a 1-1/e approximation guarantee, which is optimal for a polynomial-time algorithm. However, very little is known about the approximation achieved by greedy and other submodular maximization algorithms on real instances.
We develop an algorithm that gives an instance-specific approximation for any solution of an instance of monotone submodular maximization under a cardinality constraint. This algorithm uses a novel dual approach to submodular maximization. In particular, it relies on the construction of a lower bound to the dual objective that can also be exactly minimized. We use this algorithm to show that on a wide variety of real-world datasets and objectives, greedy and other algorithms find solutions that approximate the optimal solution significantly better than the 1-1/e ~ 0.63 worst-case approximation guarantee, often exceeding 0.9.


Motivated by the needs from an airline crew scheduling application, we introduce structured convolutional kernel networks (Struct-CKN), which combine CKNs from Mairal et al. (2014) in a structured prediction framework that supports constraints on the outputs. CKNs are a particular kind of convolutional neural networks that approximate a kernel feature map on training data, thus combining properties of deep learning with the non-parametric flexibility of kernel methods. Extending CKNs to structured outputs allows us to obtain useful initial solutions on a flight-connection dataset that can be further refined by an airline crew scheduling solver. More specifically, we use a flight-based network modeled as a general conditional random field capable of incorporating local constraints in the learning process. Our experiments demonstrate that this approach yields significant improvements for the large-scale crew pairing problem (50,000 flights per month) over standard approaches, reducing the solution cost by 17% (a gain of millions of dollars) and the cost of global constraints by 97%.

Dictionary learning is a key tool for representation learning, that explains the data as linear combination of few basic elements. Yet, this analysis is not amenable in the context of graph learning, as graphs usually belong to different metric spaces. We fill this gap by proposing a new online Graph Dictionary Learning approach, which uses the Gromov Wasserstein divergence for the data fitting term. In our work, graphs are encoded through their nodes' pairwise relations and modeled as convex combination of graph atoms, i.e. dictionary elements, estimated thanks to an online stochastic algorithm, which operates on a dataset of unregistered graphs with potentially different number of nodes. Our approach naturally extends to labeled graphs, and is completed by a novel upper bound that can be used as a fast approximation of Gromov Wasserstein in the embedding space. We provide numerical evidences showing the interest of our approach for unsupervised embedding of graph datasets and for online graph subspace estimation and tracking.

Recent works apply Graph Neural Networks (GNNs) to graph matching tasks and show promising results. Considering that model outputs are complex matchings, we devise several techniques to improve the learning of GNNs and obtain a new model, Stochastic Iterative Graph MAtching (SIGMA). Our model predicts a distribution of matchings, instead of a single matching, for a graph pair so the model can explore several probable matchings. We further introduce a novel multi-step matching procedure, which learns how to refine a graph pair's matching results incrementally. The model also includes dummy nodes so that the model does not have to find matchings for nodes without correspondence. We fit this model to data via scalable stochastic optimization. We conduct extensive experiments across synthetic graph datasets as well as biochemistry and computer vision applications. Across all tasks, our results show that SIGMA can produce significantly improved graph matching results compared to state-of-the-art models. Ablation studies verify that each of our components (stochastic training, iterative matching, and dummy nodes) offers noticeable improvement.

Neural networks (NNs) have been extremely successful across many tasks in machine learning. Quantization of NN weights has become an important topic due to its impact on their energy efficiency, inference time and deployment on hardware. Although post-training quantization is well-studied, training optimal quantized NNs involves combinatorial non-convex optimization problems which appear intractable. In this work, we introduce a convex optimization strategy to train quantized NNs with polynomial activations. Our method leverages hidden convexity in two-layer neural networks from the recent literature, semidefinite lifting, and Grothendieck's identity. Surprisingly, we show that certain quantized NN problems can be solved to global optimality provably in polynomial time in all relevant parameters via tight semidefinite relaxations. We present numerical examples to illustrate the effectiveness of our method.
Oral: Deep Generative Model 3 Wed 21 Jul 02:00 a.m.

We propose NeRF-VAE, a 3D scene generative model that incorporates geometric structure via Neural Radiance Fields (NeRF) and differentiable volume rendering. In contrast to NeRF, our model takes into account shared structure across scenes, and is able to infer the structure of a novel scene---without the need to re-train---using amortized inference. NeRF-VAE's explicit 3D rendering process further contrasts previous generative models with convolution-based rendering which lacks geometric structure. Our model is a VAE that learns a distribution over radiance fields by conditioning them on a latent scene representation. We show that, once trained, NeRF-VAE is able to infer and render geometrically-consistent scenes from previously unseen 3D environments of synthetic scenes using very few input images. We further demonstrate that NeRF-VAE generalizes well to out-of-distribution cameras, while convolutional models do not. Finally, we introduce and study an attention-based conditioning mechanism of NeRF-VAE's decoder, which improves model performance.

Variational autoencoder (VAE) estimates the posterior parameters (mean and variance) of latent variables corresponding to each input data. While it is used for many tasks, the transparency of the model is still an underlying issue. This paper provides a quantitative understanding of VAE property through the differential geometric and information-theoretic interpretations of VAE. According to the Rate-distortion theory, the optimal transform coding is achieved by using an orthonormal transform with PCA basis where the transform space is isometric to the input. Considering the analogy of transform coding to VAE, we clarify theoretically and experimentally that VAE can be mapped to an implicit isometric embedding with a scale factor derived from the posterior parameter. As a result, we can estimate the data probabilities in the input space from the prior, loss metrics, and corresponding posterior parameters, and further, the quantitative importance of each latent variable can be evaluated like the eigenvalue of PCA.

Quantization is one of the core components in lossy image compression. For neural image compression, end-to-end optimization requires differentiable approximations of quantization, which can generally be grouped into three categories: additive uniform noise, straight-through estimator and soft-to-hard annealing. Training with additive uniform noise approximates the quantization error variationally but suffers from the train-test mismatch. The other two methods do not encounter this mismatch but, as shown in this paper, hurt the rate-distortion performance since the latent representation ability is weakened. We thus propose a novel soft-then-hard quantization strategy for neural image compression that first learns an expressive latent space softly, then closes the train-test mismatch with hard quantization. In addition, beyond the fixed integer-quantization, we apply scaled additive uniform noise to adaptively control the quantization granularity by deriving a new variational upper bound on actual rate. Experiments demonstrate that our proposed methods are easy to adopt, stable to train, and highly effective especially on complex compression models.

Contrastive divergence is a popular method of training energy-based models, but is known to have difficulties with training stability. We propose an adaptation to improve contrastive divergence training by scrutinizing a gradient term that is difficult to calculate and is often left out for convenience. We show that this gradient term is numerically significant and in practice is important to avoid training instabilities, while being tractable to estimate. We further highlight how data augmentation and multi-scale processing can be used to improve model robustness and generation quality. Finally, we empirically evaluate stability of model architectures and show improved performance on a host of benchmarks and use cases, such as image generation, OOD detection, and compositional generation.

We propose to learn a generative model via entropy interpolation with a Schrödinger Bridge. The generative learning task can be formulated as interpolating between a reference distribution and a target distribution based on the Kullback-Leibler divergence. At the population level, this entropy interpolation is characterized via an SDE on [0,1] with a time-varying drift term. At the sample level, we derive our Schrödinger Bridge algorithm by plugging the drift term estimated by a deep score estimator and a deep density ratio estimator into the Euler-Maruyama method. Under some mild smoothness assumptions of the target distribution, we prove the consistency of both the score estimator and the density ratio estimator, and then establish the consistency of the proposed Schrödinger Bridge approach. Our theoretical results guarantee that the distribution learned by our approach converges to the target distribution. Experimental results on multimodal synthetic data and benchmark data support our theoretical findings and indicate that the generative model via Schrödinger Bridge is comparable with state-of-the-art GANs, suggesting a new formulation of generative learning. We demonstrate its usefulness in image interpolation and image inpainting.

Modeling dependencies among features is fundamental for many machine learning tasks. Although there are often multiple related instances that may be leveraged to inform conditional dependencies, typical approaches only model conditional dependencies over individual instances. In this work, we propose a novel framework, partially observed exchangeable modeling (POEx) that takes in a set of related partially observed instances and infers the conditional distribution for the unobserved dimensions over multiple elements. Our approach jointly models the intra-instance (among features in a point) and inter-instance (among multiple points in a set) dependencies in data. POEx is a general framework that encompasses many existing tasks such as point cloud expansion and few-shot generation, as well as new tasks like few-shot imputation. Despite its generality, extensive empirical evaluations show that our model achieves state-of-the-art performance across a range of applications.

Deep generative models (DGMs) seem a natural fit for detecting out-of-distribution (OOD) inputs, but such models have been shown to assign higher probabilities or densities to OOD images than images from the training distribution. In this work, we explain why this behavior should be attributed to model misestimation. We first prove that no method can guarantee performance beyond random chance without assumptions on which out-distributions are relevant. We then interrogate the typical set hypothesis, the claim that relevant out-distributions can lie in high likelihood regions of the data distribution, and that OOD detection should be defined based on the data distribution's typical set. We highlight the consequences implied by assuming support overlap between in- and out-distributions, as well as the arbitrariness of the typical set for OOD detection. Our results suggest that estimation error is a more plausible explanation than the misalignment between likelihood-based OOD detection and out-distributions of interest, and we illustrate how even minimal estimation error can lead to OOD detection failures, yielding implications for future work in deep generative modeling and OOD detection.
Oral: Deep Learning 2 Wed 21 Jul 02:00 a.m.

Humans are accustomed to environments that contain both regularities and exceptions. For example, at most gas stations, one pays prior to pumping, but the occasional rural station does not accept payment in advance. Likewise, deep neural networks can generalize across instances that share common patterns or structures, yet have the capacity to memorize rare or irregular forms. We analyze how individual instances are treated by a model via a consistency score. The score characterizes the expected accuracy for a held-out instance given training sets of varying size sampled from the data distribution. We obtain empirical estimates of this score for individual instances in multiple data sets, and we show that the score identifies out-of-distribution and mislabeled examples at one end of the continuum and strongly regular examples at the other end. We identify computationally inexpensive proxies to the consistency score using statistics collected during training. We apply the score toward understanding the dynamics of representation learning and to filter outliers during training.

Deep equilibrium networks (DEQs) are a new class of models that eschews traditional depth in favor of finding the fixed point of a single non-linear layer. These models have been shown to achieve performance competitive with the state-of-the-art deep networks while using significantly less memory. Yet they are also slower, brittle to architectural choices, and introduce potential instability to the model. In this paper, we propose a regularization scheme for DEQ models that explicitly regularizes the Jacobian of the fixed-point update equations to stabilize the learning of equilibrium models. We show that this regularization adds only minimal computational cost, significantly stabilizes the fixed-point convergence in both forward and backward passes, and scales well to high-dimensional, realistic domains (e.g., WikiText-103 language modeling and ImageNet classification). Using this method, we demonstrate, for the first time, an implicit-depth model that runs with approximately the same speed and level of performance as popular conventional deep networks such as ResNet-101, while still maintaining the constant memory footprint and architectural simplicity of DEQs. Code is available https://github.com/locuslab/deq.
We show that the error of iteratively magnitude-pruned networks empirically follows a scaling law with interpretable coefficients that depend on the architecture and task. We functionally approximate the error of the pruned networks, showing it is predictable in terms of an invariant tying width, depth, and pruning level, such that networks of vastly different pruned densities are interchangeable. We demonstrate the accuracy of this approximation over orders of magnitude in depth, width, dataset size, and density. We show that the functional form holds (generalizes) for large scale data (e.g., ImageNet) and architectures (e.g., ResNets). As neural networks become ever larger and costlier to train, our findings suggest a framework for reasoning conceptually and analytically about a standard method for unstructured pruning.

In deep model compression, the recent finding "Lottery Ticket Hypothesis" (LTH) pointed out that there could exist a winning ticket (i.e., a properly pruned sub-network together with original weight initialization) that can achieve competitive performance than the original dense network. However, it is not easy to observe such winning property in many scenarios, where for example, a relatively large learning rate is used even if it benefits training the original dense model. In this work, we investigate the underlying condition and rationale behind the winning property, and find that the underlying reason is largely attributed to the correlation between initialized weights and final-trained weights when the learning rate is not sufficiently large. Thus, the existence of winning property is correlated with an insufficient DNN pretraining, and is unlikely to occur for a well-trained DNN. To overcome this limitation, we propose the "pruning & fine-tuning" method that consistently outperforms lottery ticket sparse training under the same pruning algorithm and the same total training epochs. Extensive experiments over multiple deep models (VGG, ResNet, MobileNet-v2) on different datasets have been conducted to justify our proposals.

While designing inductive bias in neural architectures has been widely studied, we hypothesize that transformer networks are flexible enough to learn inductive bias from suitable generic tasks. Here, we replace architecture engineering by encoding inductive bias in the form of datasets. Inspired by Peirce's view that deduction, induction, and abduction are the primitives of reasoning, we design three synthetic tasks that are intended to require the model to have these three abilities. We specifically design these tasks to be synthetic and devoid of mathematical knowledge to ensure that only the fundamental reasoning biases can be learned from these tasks. This defines a new pre-training methodology called "LIME" (Learning Inductive bias for Mathematical rEasoning). Models trained with LIME significantly outperform vanilla transformers on four very different large mathematical reasoning benchmarks. Unlike dominating the computation cost as traditional pre-training approaches, LIME requires only a small fraction of the computation cost of the typical downstream task. The code for generating LIME tasks is available at https://github.com/tonywu95/LIME.

That neural networks may be pruned to high sparsities and retain high accuracy is well established. Recent research efforts focus on pruning immediately after initialization so as to allow the computational savings afforded by sparsity to extend to the training process. In this work, we introduce a new `DCT plus Sparse' layer architecture, which maintains information propagation and trainability even with as little as 0.01% trainable parameters remaining. We show that standard training of networks built with these layers, and pruned at initialization, achieves state-of-the-art accuracy for extreme sparsities on a variety of benchmark network architectures and datasets. Moreover, these results are achieved using only simple heuristics to determine the locations of the trainable parameters in the network, and thus without having to initially store or compute with the full, unpruned network, as is required by competing prune-at-initialization algorithms. Switching from standard sparse layers to DCT plus Sparse layers does not increase the storage footprint of a network and incurs only a small additional computational overhead.

Recent observations have advanced our understanding of the neural network optimization landscape, revealing the existence of (1) paths of high accuracy containing diverse solutions and (2) wider minima offering improved performance. Previous methods observing diverse paths require multiple training runs. In contrast we aim to leverage both property (1) and (2) with a single method and in a single training run. With a similar computational cost as training one model, we learn lines, curves, and simplexes of high-accuracy neural networks. These neural network subspaces contain diverse solutions that can be ensembled, approaching the ensemble performance of independently trained networks without the training cost. Moreover, using the subspace midpoint boosts accuracy, calibration, and robustness to label noise, outperforming Stochastic Weight Averaging.
Oral: Deep Learning Algorithms 6 Wed 21 Jul 02:00 a.m.

Recent works (White et al., 2020a; Yan et al., 2020) demonstrate the importance of architecture encodings in Neural Architecture Search (NAS). These encodings encode either structure or computation information of the neural architectures. Compared to structure-aware encodings, computation-aware encodings map architectures with similar accuracies to the same region, which improves the downstream architecture search performance (Zhang et al., 2019; White et al., 2020a). In this work, we introduce a Computation-Aware Transformer-based Encoding method called CATE. Different from existing computation-aware encodings based on fixed transformation (e.g. path encoding), CATE employs a pairwise pre-training scheme to learn computation-aware encodings using Transformers with cross-attention. Such learned encodings contain dense and contextualized computation information of neural architectures. We compare CATE with eleven encodings under three major encoding-dependent NAS subroutines in both small and large search spaces. Our experiments show that CATE is beneficial to the downstream search, especially in the large search space. Moreover, the outside search space experiment demonstrates its superior generalization ability beyond the search space on which it was trained. Our code is available at: https://github.com/MSU-MLSys-Lab/CATE.

Understanding classifier decision under novel environments is central to the community, and a common practice is evaluating it on labeled test sets. However, in real-world testing, image annotations are difficult and expensive to obtain, especially when the test environment is changing. A natural question then arises: given a trained classifier, can we evaluate its accuracy on varying unlabeled test sets? In this work, we train semantic classification and rotation prediction in a multi-task way. On a series of datasets, we report an interesting finding, i.e., the semantic classification accuracy exhibits a strong linear relationship with the accuracy of the rotation prediction task (Pearson's Correlation r > 0.88). This finding allows us to utilize linear regression to estimate classifier performance from the accuracy of rotation prediction which can be obtained on the test set through the freely generated rotation labels.

Despite recent successes, most contrastive self-supervised learning methods are domain-specific, relying heavily on data augmentation techniques that require knowledge about a particular domain, such as image cropping and rotation. To overcome such limitation, we propose a domain-agnostic approach to contrastive learning, named DACL, that is applicable to problems where domain-specific data augmentations are not readily available. Key to our approach is the use of Mixup noise to create similar and dissimilar examples by mixing data samples differently either at the input or hidden-state levels. We theoretically analyze our method and show advantages over the Gaussian-noise based contrastive learning approach. To demonstrate the effectiveness of DACL, we conduct experiments across various domains such as tabular data, images, and graphs. Our results show that DACL not only outperforms other domain-agnostic noising methods, such as Gaussian-noise, but also combines well with domain-specific methods, such as SimCLR, to improve self-supervised visual representation learning.

Most, if not all, modern deep learning systems restrict themselves to a single dataset for neural network training and inference. In this article, we are interested in systematic ways to join datasets that are made of similar purposes. Unlike previous published works that ubiquitously conduct the dataset joining in the uninterpretable latent vectorial space, the core to our method is an augmentation procedure in the label space. The primary challenge to address the label space for dataset joining is the discrepancy between labels: non-overlapping label annotation sets, different labeling granularity or hierarchy and etc. Notably we propose a new technique leveraging artificially created knowledge graph, recurrent neural networks and policy gradient that successfully achieve the dataset joining in the label space. Empirical results on both image and text classification justify the validity of our approach.

Sorting and ranking supervision is a method for training neural networks end-to-end based on ordering constraints. That is, the ground truth order of sets of samples is known, while their absolute values remain unsupervised. For that, we propose differentiable sorting networks by relaxing their pairwise conditional swap operations. To address the problems of vanishing gradients and extensive blurring that arise with larger numbers of layers, we propose mapping activations to regions with moderate gradients. We consider odd-even as well as bitonic sorting networks, which outperform existing relaxations of the sorting operation. We show that bitonic sorting networks can achieve stable training on large input sets of up to 1024 elements.

With rapid progress in neural text-to-speech (TTS) models, personalized speech generation is now in high demand for many applications. For practical applicability, a TTS model should generate high-quality speech with only a few audio samples from the given speaker, that are also short in length. However, existing methods either require to fine-tune the model or achieve low adaptation quality without fine-tuning. In this work, we propose StyleSpeech, a new TTS model which not only synthesizes high-quality speech but also effectively adapts to new speakers. Specifically, we propose Style-Adaptive Layer Normalization (SALN) which aligns gain and bias of the text input according to the style extracted from a reference speech audio. With SALN, our model effectively synthesizes speech in the style of the target speaker even from a single speech audio. Furthermore, to enhance StyleSpeech's adaptation to speech from new speakers, we extend it to Meta-StyleSpeech by introducing two discriminators trained with style prototypes, and performing episodic training. The experimental results show that our models generate high-quality speech which accurately follows the speaker's voice with single short-duration (1-3 sec) speech audio, significantly outperforming baselines.

In this paper, we introduce a two-level attention schema, Poolingformer, for long document modeling. Its first level uses a smaller sliding window pattern to aggregate information from neighbors. Its second level employs a larger window to increase receptive fields with pooling attention to reduce both computational cost and memory consumption. We first evaluate Poolingformer on two long sequence QA tasks: the monolingual NQ and the multilingual TyDi QA. Experimental results show that Poolingformer sits atop three official leaderboards measured by F1, outperforming previous state-of-the-art models by 1.9 points (79.8 vs. 77.9) on NQ long answer, 1.9 points (79.5 vs. 77.6) on TyDi QA passage answer, and 1.6 points (67.6 vs. 66.0) on TyDi QA minimal answer. We further evaluate Poolingformer on a long sequence summarization task. Experimental results on the arXiv benchmark continue to demonstrate its superior performance.
Social: Continuing (Non-episodic) RL Problems Wed 21 Jul 02:00 a.m.
Please join us if you are interested in continuing reinforcement learning problems where the agent has a single non-episodic stream of experience. In many cases, and most importantly for natural intelligence, the agent is never reset to a state that it has visited before. What is the right objective for these problems? How is the problem different from the episodic ones? Plz join this social if you are also curious about these questions!
Oral: Reinforcement Learning 5 Wed 21 Jul 03:00 a.m.

Individuality is essential in human society. It induces the division of labor and thus improves the efficiency and productivity. Similarly, it should also be a key to multi-agent cooperation. Inspired by that individuality is of being an individual separate from others, we propose a simple yet efficient method for the emergence of individuality (EOI) in multi-agent reinforcement learning (MARL). EOI learns a probabilistic classifier that predicts a probability distribution over agents given their observation and gives each agent an intrinsic reward of being correctly predicted by the classifier. The intrinsic reward encourages the agents to visit their own familiar observations, and learning the classifier by such observations makes the intrinsic reward signals stronger and in turn makes the agents more identifiable. To further enhance the intrinsic reward and promote the emergence of individuality, two regularizers are proposed to increase the discriminability of the classifier. We implement EOI on top of popular MARL algorithms. Empirically, we show that EOI outperforms existing methods in a variety of multi-agent cooperative scenarios.

In fully cooperative multi-agent reinforcement learning (MARL) settings, the environments are highly stochastic due to the partial observability of each agent and the continuously changing policies of the other agents. To address the above issues, we integrate distributional RL and value function factorization methods by proposing a Distributional Value Function Factorization (DFAC) framework to generalize expected value function factorization methods to their distributional variants. DFAC extends the individual utility functions from deterministic variables to random variables, and models the quantile function of the total return as a quantile mixture. To validate DFAC, we demonstrate DFAC's ability to factorize a simple two-step matrix game with stochastic rewards and perform experiments on all Super Hard tasks of StarCraft Multi-Agent Challenge, showing that DFAC is able to outperform expected value function factorization baselines.
Norm emergence is a process where agents in a multi-agent system establish self-enforcing conformity through repeated interactions. When such interactions are confined to a social topology, several self-reinforcing substructures (SRS) may emerge within the population. This prevents a formation of a global norm. We propose incremental social instruments (ISI) to dissolve these SRSs by creating ties between agents. Establishing ties requires some effort and cost. Hence, it is worth to design methods that build a small number of ties yet dissolve the SRSs. By using the notion of information entropy, we propose an indicator called the BA-ratio that measures the current SRSs. We find that by building ties with minimal BA-ratio, our ISI is effective in facilitating the global norm emergence. We explain this through our experiments and theoretical results. Furthermore, we propose the small-degree principle in minimising the BA-ratio that helps us to design efficient ISI algorithms for finding the optimal ties. Experiments on both synthetic and real-world network topologies demonstrate that our adaptive ISI is efficient at dissolving SRS.

We study reinforcement learning in mean-field games. To achieve the Nash equilibrium, which consists of a policy and a mean-field state, existing algorithms require obtaining the optimal policy while fixing any mean-field state. In practice, however, the policy and the mean-field state evolve simultaneously, as each agent is learning while playing. To bridge such a gap, we propose a fictitious play algorithm, which alternatively updates the policy (learning) and the mean-field state (playing) by one step of policy optimization and gradient descent, respectively. Despite the nonstationarity induced by such an alternating scheme, we prove that the proposed algorithm converges to the Nash equilibrium with an explicit convergence rate. To the best of our knowledge, it is the first provably efficient algorithm that achieves learning while playing via alternating updates.

We consider the problem of learning fair policies in (deep) cooperative multi-agent reinforcement learning (MARL). We formalize it in a principled way as the problem of optimizing a welfare function that explicitly encodes two important aspects of fairness: efficiency and equity. We provide a theoretical analysis of the convergence of policy gradient for this problem. As a solution method, we propose a novel neural network architecture, which is composed of two sub-networks specifically designed for taking into account these two aspects of fairness. In experiments, we demonstrate the importance of the two sub-networks for fair optimization. Our overall approach is general as it can accommodate any (sub)differentiable welfare function. Therefore, it is compatible with various notions of fairness that have been proposed in the literature (e.g., lexicographic maximin, generalized Gini social welfare function, proportional fairness). Our method is generic and can be implemented in various MARL settings: centralized training and decentralized execution, or fully decentralized. Finally, we experimentally validate our approach in various domains and show that it can perform much better than previous methods, both in terms of efficiency and equity.

Reinforcement learning from large-scale offline datasets provides us with the ability to learn policies without potentially unsafe or impractical exploration. Significant progress has been made in the past few years in dealing with the challenge of correcting for differing behavior between the data collection and learned policies. However, little attention has been paid to potentially changing dynamics when transferring a policy to the online setting, where performance can be up to 90% reduced for existing methods. In this paper we address this problem with Augmented World Models (AugWM). We augment a learned dynamics model with simple transformations that seek to capture potential changes in physical properties of the robot, leading to more robust policies. We not only train our policy in this new setting, but also provide it with the sampled augmentation as a context, allowing it to adapt to changes in the environment. At test time we learn the context in a self-supervised fashion by approximating the augmentation which corresponds to the new environment. We rigorously evaluate our approach on over 100 different changed dynamics settings, and show that this simple approach can significantly improve the zero-shot generalization of a recent state-of-the-art baseline, often achieving successful policies where the …
Spotlight: AutoML Wed 21 Jul 03:00 a.m.

Differentiable ARchiTecture Search(DARTS) has recently become the mainstream in the neural architecture search (NAS) due to its efficiency and simplicity. With a gradient-based bi-level optimization, DARTS alternately optimizes the inner model weights and the outer architecture parameter in a weight-sharing supernet. A key challenge to the scalability and quality of the learned architectures is the need for differentiating through the inner-loop optimisation. While much has been discussed about several potentially fatal factors in DARTS, the architecture gradient, a.k.a. hypergradient, has received less attention. In this paper, we tackle the hypergradient computation in DARTS based on the implicit function theorem, making it only depends on the obtained solution to the inner-loop optimization and agnostic to the optimization path. To further reduce the computational requirements, we formulate a stochastic hypergradient approximation for differentiable NAS, and theoretically show that the architecture optimization with the proposed method is expected to converge to a stationary point. Comprehensive experiments on two NAS benchmark search spaces and the common NAS search space verify the effectiveness of our proposed method. It leads to architectures outperforming, with large margins, those learned by the baseline methods.

Lately, post-training quantization methods have gained considerable attention, as they are simple to use, and require only a small unlabeled calibration set. This small dataset cannot be used to fine-tune the model without significant over-fitting. Instead, these methods only use the calibration set to set the activations' dynamic ranges. However, such methods always resulted in significant accuracy degradation, when used below 8-bits (except on small datasets). Here we aim to break the 8-bit barrier. To this end, we minimize the quantization errors of each layer or block separately by optimizing its parameters over the calibration set. We empirically demonstrate that this approach is: (1) much less susceptible to over-fitting than the standard fine-tuning approaches, and can be used even on a very small calibration set; and (2) more powerful than previous methods, which only set the activations' dynamic ranges. We suggest two flavors for our method, parallel and sequential aim for a fixed and flexible bit-width allocation. For the latter, we demonstrate how to optimally allocate the bit-widths for each layer, while constraining accuracy degradation or model compression by proposing a novel integer programming formulation. Finally, we suggest model global statistics tuning, to correct biases introduced during quantization. Together, these …

Neural architecture search (NAS) automates the design of deep neural networks. One of the main challenges in searching complex and non-continuous architectures is to compare the similarity of networks that the conventional Euclidean metric may fail to capture. Optimal transport (OT) is resilient to such complex structure by considering the minimal cost for transporting a network into another. However, the OT is generally not negative definite which may limit its ability to build the positive-definite kernels required in many kernel-dependent frameworks. Building upon tree-Wasserstein (TW), which is a negative definite variant of OT, we develop a novel discrepancy for neural architectures, and demonstrate it within a Gaussian process surrogate model for the sequential NAS settings. Furthermore, we derive a novel parallel NAS, using quality k-determinantal point process on the GP posterior, to select diverse and high-performing architectures from a discrete set of candidates. Empirically, we demonstrate that our TW-based approaches outperform other baselines in both sequential and parallel NAS.

Efficient evaluation of a network architecture drawn from a large search space remains a key challenge in Neural Architecture Search (NAS). Vanilla NAS evaluates each architecture by training from scratch, which gives the true performance but is extremely time-consuming. Recently, one-shot NAS substantially reduces the computation cost by training only one supernetwork, a.k.a. supernet, to approximate the performance of every architecture in the search space via weight-sharing. However, the performance estimation can be very inaccurate due to the co-adaption among operations. In this paper, we propose few-shot NAS that uses multiple supernetworks, called sub-supernet, each covering different regions of the search space to alleviate the undesired co-adaption. Compared to one-shot NAS, few-shot NAS improves the accuracy of architecture evaluation with a small increase of evaluation cost. With only up to 7 sub-supernets, few-shot NAS establishes new SoTAs: on ImageNet, it finds models that reach 80.5% top-1 accuracy at 600 MB FLOPS and 77.5% top-1 accuracy at 238 MFLOPS; on CIFAR10, it reaches 98.72% top-1 accuracy without using extra data or transfer learning. In Auto-GAN, few-shot NAS outperforms the previously published results by up to 20%. Extensive experiments show that few-shot NAS significantly improves various one-shot methods, including 4 gradient-based and …

Self-attention mechanisms have been widely adopted in many machine learning areas, including Natural Language Processing (NLP) and Graph Representation Learning (GRL), etc. However, existing works heavily rely on hand-crafted design to obtain customized attention mechanisms. In this paper, we automate Key, Query and Value representation design, which is one of the most important steps to obtain effective self-attentions. We propose an automated self-attention representation model, AutoAttend, which can automatically search powerful attention representations for downstream tasks leveraging Neural Architecture Search (NAS). In particular, we design a tailored search space for attention representation automation, which is flexible to produce effective attention representation designs. Based on the design prior obtained from attention representations in previous works, we further regularize our search space to reduce the space complexity without the loss of expressivity. Moreover, we propose a novel context-aware parameter sharing mechanism considering special characteristics of each sub-architecture to provide more accurate architecture estimations when conducting parameter sharing in our tailored search space. Experiments show the superiority of our proposed AutoAttend model over previous state-of-the-arts on eight text classification tasks in NLP and four node classification tasks in GRL.

High-dimensional black-box optimisation remains an important yet notoriously challenging problem. Despite the success of Bayesian optimisation methods on continuous domains, domains that are categorical, or that mix continuous and categorical variables, remain challenging. We propose a novel solution---we combine local optimisation with a tailored kernel design, effectively handling high-dimensional categorical and mixed search spaces, whilst retaining sample efficiency. We further derive convergence guarantee for the proposed approach. Finally, we demonstrate empirically that our method outperforms the current baselines on a variety of synthetic and real-world tasks in terms of performance, computational costs, or both.

While maximizing deep neural networks' (DNNs') acceleration efficiency requires a joint search/design of three different yet highly coupled aspects, including the networks, bitwidths, and accelerators, the challenges associated with such a joint search have not yet been fully understood and addressed. The key challenges include (1) the dilemma of whether to explode the memory consumption due to the huge joint space or achieve sub-optimal designs, (2) the discrete nature of the accelerator design space that is coupled yet different from that of the networks and bitwidths, and (3) the chicken and egg problem associated with network-accelerator co-search, i.e., co-search requires operation-wise hardware cost, which is lacking during search as the optimal accelerator depending on the whole network is still unknown during search. To tackle these daunting challenges towards optimal and fast development of DNN accelerators, we propose a framework dubbed Auto-NBA to enable jointly searching for the Networks, Bitwidths, and Accelerators, by efficiently localizing the optimal design within the huge joint design space for each target dataset and acceleration specification. Our Auto-NBA integrates a heterogeneous sampling strategy to achieve unbiased search with constant memory consumption, and a novel joint-search pipeline equipped with a generic differentiable accelerator search engine. Extensive experiments …
Oral: Algorithms 1 Wed 21 Jul 03:00 a.m.

Multi-modal distributions are commonly used to model clustered data in statistical learning tasks. In this paper, we consider the Mixed Linear Regression (MLR) problem. We propose an optimal transport-based framework for MLR problems, Wasserstein Mixed Linear Regression (WMLR), which minimizes the Wasserstein distance between the learned and target mixture regression models. Through a model-based duality analysis, WMLR reduces the underlying MLR task to a nonconvex-concave minimax optimization problem, which can be provably solved to find a minimax stationary point by the Gradient Descent Ascent (GDA) algorithm. In the special case of mixtures of two linear regression models, we show that WMLR enjoys global convergence and generalization guarantees. We prove that WMLR’s sample complexity grows linearly with the dimension of data. Finally, we discuss the application of WMLR to the federated learning task where the training samples are collected by multiple agents in a network. Unlike the Expectation-Maximization algorithm, WMLR directly extends to the distributed, federated learning setting. We support our theoretical results through several numerical experiments, which highlight our framework’s ability to handle the federated learning setting with mixture models.

Stochastic Neural Networks (SNNs) that inject noise into their hidden layers have recently been shown to achieve strong robustness against adversarial attacks. However, existing SNNs are usually heuristically motivated, and often rely on adversarial training, which is computationally costly. We propose a new SNN that achieves state-of-the-art performance without relying on adversarial training, and enjoys solid theoretical justification. Specifically, while existing SNNs inject learned or hand-tuned isotropic noise, our SNN learns an anisotropic noise distribution to optimize a learning-theoretic bound on adversarial robustness. We evaluate our method on a number of popular benchmarks, show that it can be applied to different architectures, and that it provides robustness to a variety of white-box and black-box attacks, while being simple and fast to train compared to existing alternatives.

Boundary discontinuity and its inconsistency to the final detection metric have been the bottleneck for rotating detection regression loss design. In this paper, we propose a novel regression loss based on Gaussian Wasserstein distance as a fundamental approach to solve the problem. Specifically, the rotated bounding box is converted to a 2-D Gaussian distribution, which enables to approximate the indifferentiable rotational IoU induced loss by the Gaussian Wasserstein distance (GWD) which can be learned efficiently by gradient back-propagation. GWD can still be informative for learning even there is no overlapping between two rotating bounding boxes which is often the case for small object detection. Thanks to its three unique properties, GWD can also elegantly solve the boundary discontinuity and square-like problem regardless how the bounding box is defined. Experiments on five datasets using different detectors show the effectiveness of our approach, and codes are available at https://github.com/yangxue0827/RotationDetection.


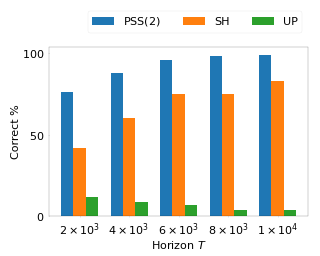
We consider a best arm identification (BAI) problem for stochastic bandits with adversarial corruptions in the fixed-budget setting of T steps. We design a novel randomized algorithm, Probabilistic Sequential Shrinking(u) (PSS(u)), which is agnostic to the amount of corruptions. When the amount of corruptions per step (CPS) is below a threshold, PSS(u) identifies the best arm or item with probability tending to 1 as T→∞. Otherwise, the optimality gap of the identified item degrades gracefully with the CPS.We argue that such a bifurcation is necessary. In PSS(u), the parameter u serves to balance between the optimality gap and success probability. The injection of randomization is shown to be essential to mitigate the impact of corruptions. To demonstrate this, we design two attack strategies that are applicable to any algorithm. We apply one of them to a deterministic analogue of PSS(u) known as Successive Halving (SH) by Karnin et al. (2013). The attack strategy results in a high failure probability for SH, but PSS(u) remains robust. In the absence of corruptions, PSS(2)'s performance guarantee matches SH's. We show that when the CPS is sufficiently large, no algorithm can achieve a BAI probability tending to 1 as T→∞. Numerical experiments corroborate our …

Inductive program synthesis, or inferring programs from examples of desired behavior, offers a general paradigm for building interpretable, robust, andgeneralizable machine learning systems. Effective program synthesis depends on two key ingredients: a strong library of functions from which to build programs, and an efficient search strategy for finding programs that solve a given task. We introduce LAPS (Language for Abstraction and Program Search), a technique for using natural language annotations to guide joint learning of libraries and neurally-guided search models for synthesis. When integrated into a state-of-the-art library learning system (DreamCoder), LAPS produces higher-quality libraries and improves search efficiency and generalization on three domains – string editing, image composition, and abstract reasoning about scenes – even when no natural language hints are available at test time.
Oral: Optimization (Stochastic) Wed 21 Jul 03:00 a.m.

In the stochastic submodular cover problem, the goal is to select a subset of stochastic items of minimum expected cost to cover a submodular function. Solutions in this setting correspond to a sequential decision process that selects items one by one ``adaptively'' (depending on prior observations). While such adaptive solutions achieve the best objective, the inherently sequential nature makes them undesirable in many applications. We ask: \emph{how well can solutions with only a few adaptive rounds approximate fully-adaptive solutions?} We consider both cases where the stochastic items are independent, and where they are correlated. For both situations, we obtain nearly tight answers, establishing smooth tradeoffs between the number of adaptive rounds and the solution quality, relative to fully adaptive solutions. Experiments on synthetic and real datasets validate the practical performance of our algorithms, showing qualitative improvements in the solutions as we allow more rounds of adaptivity; in practice, solutions using just a few rounds of adaptivity are nearly as good as fully adaptive solutions.

Federated Learning (FL) is a distributed learning paradigm that scales on-device learning collaboratively and privately. Standard FL algorithms such as FᴇᴅAᴠɢ are primarily geared towards smooth unconstrained settings. In this paper, we study the Federated Composite Optimization (FCO) problem, in which the loss function contains a non-smooth regularizer. Such problems arise naturally in FL applications that involve sparsity, low-rank, monotonicity, or more general constraints. We first show that straightforward extensions of primal algorithms such as FedAvg are not well-suited for FCO since they suffer from the "curse of primal averaging," resulting in poor convergence. As a solution, we propose a new primal-dual algorithm, Federated Dual Averaging (FedDualAvg), which by employing a novel server dual averaging procedure circumvents the curse of primal averaging. Our theoretical analysis and empirical experiments demonstrate that FedDualAvg outperforms the other baselines.

Latent variable models have been playing a central role in statistics, econometrics, machine learning with applications to repeated observation study, panel data inference, user behavior analysis, etc. In many modern applications, the inference based on latent variable models involves one or several of the following features: the presence of complex latent structure, the observed and latent variables being continuous or discrete, constraints on parameters, and data size being large. Therefore, solving an estimation problem for general latent variable models is highly non-trivial. In this paper, we consider a gradient based method via using variance reduction technique to accelerate estimation procedure. Theoretically, we show the convergence results for the proposed method under general and mild model assumptions. The algorithm has better computational complexity compared with the classical gradient methods and maintains nice statistical properties. Various numerical results corroborate our theory.

We consider stochastic convex optimization problems, where several machines act asynchronously in parallel while sharing a common memory. We propose a robust training method for the constrained setting and derive non asymptotic convergence guarantees that do not depend on prior knowledge of update delays, objective smoothness, and gradient variance. Conversely, existing methods for this setting crucially rely on this prior knowledge, which render them unsuitable for essentially all shared-resources computational environments, such as clouds and data centers. Concretely, existing approaches are unable to accommodate changes in the delays which result from dynamic allocation of the machines, while our method implicitly adapts to such changes.

Distributed learning has become a hot research topic due to its wide application in cluster-based large-scale learning, federated learning, edge computing and so on. Most traditional distributed learning methods typically assume no failure or attack. However, many unexpected cases, such as communication failure and even malicious attack, may happen in real applications. Hence, Byzantine learning (BL), which refers to distributed learning with failure or attack, has recently attracted much attention. Most existing BL methods are synchronous, which are impractical in some applications due to heterogeneous or offline workers. In these cases, asynchronous BL (ABL) is usually preferred. In this paper, we propose a novel method, called buffered asynchronous stochastic gradient descent (BASGD), for ABL. To the best of our knowledge, BASGD is the first ABL method that can resist malicious attack without storing any instances on server. Compared with those methods which need to store instances on server, BASGD has a wider scope of application. BASGD is proved to be convergent, and be able to resist failure or attack. Empirical results show that BASGD significantly outperforms vanilla asynchronous stochastic gradient descent (ASGD) and other ABL baselines when there exists failure or attack on workers.
Oral: Optimization and Algorithms 2 Wed 21 Jul 03:00 a.m.

Influence maximization is the task of selecting a small number of seed nodes in a social network to maximize the spread of the influence from these seeds, and it has been widely investigated in the past two decades. In the canonical setting, the whole social network as well as its diffusion parameters is given as input. In this paper, we consider the more realistic sampling setting where the network is unknown and we only have a set of passively observed cascades that record the set of activated nodes at each diffusion step. We study the task of influence maximization from these cascade samples (IMS), and present constant approximation algorithms for this task under mild conditions on the seed set distribution. To achieve the optimization goal, we also provide a novel solution to the network inference problem, that is, learning diffusion parameters and the network structure from the cascade data. Comparing with prior solutions, our network inference algorithm requires weaker assumptions and does not rely on maximum-likelihood estimation and convex programming. Our IMS algorithms enhance the learning-and-then-optimization approach by allowing a constant approximation ratio even when the diffusion parameters are hard to learn, and we do not need any assumption related …


In recent years, methods were proposed for assigning feature importance scores to measure the contribution of individual features. While in some cases the goal is to understand a specific model, in many cases the goal is to understand the contribution of certain properties (features) to a real-world phenomenon. Thus, a distinction has been made between feature importance scores that explain a model and scores that explain the data. When explaining the data, machine learning models are used as proxies in settings where conducting many real-world experiments is expensive or prohibited. While existing feature importance scores show great success in explaining models, we demonstrate their limitations when explaining the data, especially in the presence of correlations between features. Therefore, we develop a set of axioms to capture properties expected from a feature importance score when explaining data and prove that there exists only one score that satisfies all of them, the Marginal Contribution Feature Importance (MCI). We analyze the theoretical properties of this score function and demonstrate its merits empirically.

Recent research has recognized interpretability and robustness as essential properties of trustworthy classification. Curiously, a connection between robustness and interpretability was empirically observed, but the theoretical reasoning behind it remained elusive. In this paper, we rigorously investigate this connection. Specifically, we focus on interpretation using decision trees and robustness to l_{\infty}-perturbation. Previous works defined the notion of r-separation as a sufficient condition for robustness. We prove upper and lower bounds on the tree size in case the data is r-separated. We then show that a tighter bound on the size is possible when the data is linearly separated. We provide the first algorithm with provable guarantees both on robustness, interpretability, and accuracy in the context of decision trees. Experiments confirm that our algorithm yields classifiers that are both interpretable and robust and have high accuracy.


Bridging logical and algorithmic reasoning with modern machine learning techniques is a fundamental challenge with potentially transformative impact. On the algorithmic side, many NP-hard problems can be expressed as integer programs, in which the constraints play the role of their 'combinatorial specification'. In this work, we aim to integrate integer programming solvers into neural network architectures as layers capable of learning both the cost terms and the constraints. The resulting end-to-end trainable architectures jointly extract features from raw data and solve a suitable (learned) combinatorial problem with state-of-the-art integer programming solvers. We demonstrate the potential of such layers with an extensive performance analysis on synthetic data and with a demonstration on a competitive computer vision keypoint matching benchmark.
Oral: Deep Generative Model 4 Wed 21 Jul 03:00 a.m.

The high dimensionality of images presents architecture and sampling-efficiency challenges for likelihood-based generative models. Previous approaches such as VQ-VAE use deep autoencoders to obtain compact representations, which are more practical as inputs for likelihood-based models. We present an alternative approach, inspired by common image compression methods like JPEG, and convert images to quantized discrete cosine transform (DCT) blocks, which are represented sparsely as a sequence of DCT channel, spatial location, and DCT coefficient triples. We propose a Transformer-based autoregressive architecture, which is trained to sequentially predict the conditional distribution of the next element in such sequences, and which scales effectively to high resolution images. On a range of image datasets, we demonstrate that our approach can generate high quality, diverse images, with sample metric scores competitive with state of the art methods. We additionally show that simple modifications to our method yield effective image colorization and super-resolution models.

A large part of the literature on learning disentangled representations focuses on variational autoencoders (VAEs). Recent developments demonstrate that disentanglement cannot be obtained in a fully unsupervised setting without inductive biases on models and data. However, Khemakhem et al., AISTATS, 2020 suggest that employing a particular form of factorized prior, conditionally dependent on auxiliary variables complementing input observations, can be one such bias, resulting in an identifiable model with guarantees on disentanglement. Working along this line, we propose a novel VAE-based generative model with theoretical guarantees on identifiability. We obtain our conditional prior over the latents by learning an optimal representation, which imposes an additional strength on their regularization. We also extend our method to semi-supervised settings. Experimental results indicate superior performance with respect to state-of-the-art approaches, according to several established metrics proposed in the literature on disentanglement.

We propose a novel GAN training scheme that can handle any level of labeling in a unified manner. Our scheme introduces a form of artificial labeling that can incorporate manually defined labels, when available, and induce an alignment between them. To define the artificial labels, we exploit the assumption that neural network generators can be trained more easily to map nearby latent vectors to data with semantic similarities, than across separate categories. We use generated data samples and their corresponding artificial conditioning labels to train a classifier. The classifier is then used to self-label real data. To boost the accuracy of the self-labeling, we also use the exponential moving average of the classifier. However, because the classifier might still make mistakes, especially at the beginning of the training, we also refine the labels through self-attention, by using the labeling of real data samples only when the classifier outputs a high classification probability score. We evaluate our approach on CIFAR-10, STL-10 and SVHN, and show that both self-labeling and self-attention consistently improve the quality of generated data. More surprisingly, we find that the proposed scheme can even outperform class-conditional GANs.

Despite the accomplishments of Generative Adversarial Networks (GANs) in modeling data distributions, training them remains a challenging task. A contributing factor to this difficulty is the non-intuitive nature of the GAN loss curves, which necessitates a subjective evaluation of the generated output to infer training progress. Recently, motivated by game theory, Duality Gap has been proposed as a domain agnostic measure to monitor GAN training. However, it is restricted to the setting when the GAN converges to a Nash equilibrium. But GANs need not always converge to a Nash equilibrium to model the data distribution. In this work, we extend the notion of duality gap to proximal duality gap that is applicable to the general context of training GANs where Nash equilibria may not exist. We show theoretically that the proximal duality gap can monitor the convergence of GANs to a broader spectrum of equilibria that subsumes Nash equilibria. We also theoretically establish the relationship between the proximal duality gap and the divergence between the real and generated data distributions for different GAN formulations. Our results provide new insights into the nature of GAN convergence. Finally, we validate experimentally the usefulness of proximal duality gap for monitoring and influencing GAN …

Modeling sets is an important problem in machine learning since this type of data can be found in many domains. A promising approach defines a family of permutation invariant densities with continuous normalizing flows. This allows us to maximize the likelihood directly and sample new realizations with ease. In this work, we demonstrate how calculating the trace, a crucial step in this method, raises issues that occur both during training and inference, limiting its practicality. We propose an alternative way of defining permutation equivariant transformations that give closed form trace. This leads not only to improvements while training, but also to better final performance. We demonstrate the benefits of our approach on point processes and general set modeling.

This paper introduces an alternative approach to sampling from autoregressive models. Autoregressive models are typically sampled sequentially, according to the transition dynamics defined by the model. Instead, we propose a sampling procedure that initializes a sequence with white noise and follows a Markov chain defined by Langevin dynamics on the global log-likelihood of the sequence. This approach parallelizes the sampling process and generalizes to conditional sampling. Using an autoregressive model as a Bayesian prior, we can steer the output of a generative model using a conditional likelihood or constraints. We apply these techniques to autoregressive models in the visual and audio domains, with competitive results for audio source separation, super-resolution, and inpainting.
Text-to-image generation has traditionally focused on finding better modeling assumptions for training on a fixed dataset. These assumptions might involve complex architectures, auxiliary losses, or side information such as object part labels or segmentation masks supplied during training. We describe a simple approach for this task based on a transformer that autoregressively models the text and image tokens as a single stream of data. With sufficient data and scale, our approach is competitive with previous domain-specific models when evaluated in a zero-shot fashion.
Oral: Reinforcement Learning 7 Wed 21 Jul 03:00 a.m.

Conveying complex objectives to reinforcement learning (RL) agents can often be difficult, involving meticulous design of reward functions that are sufficiently informative yet easy enough to provide. Human-in-the-loop RL methods allow practitioners to instead interactively teach agents through tailored feedback; however, such approaches have been challenging to scale since human feedback is very expensive. In this work, we aim to make this process more sample- and feedback-efficient. We present an off-policy, interactive RL algorithm that capitalizes on the strengths of both feedback and off-policy learning. Specifically, we learn a reward model by actively querying a teacher's preferences between two clips of behavior and use it to train an agent. To enable off-policy learning, we relabel all the agent's past experience when its reward model changes. We additionally show that pre-training our agents with unsupervised exploration substantially increases the mileage of its queries. We demonstrate that our approach is capable of learning tasks of higher complexity than previously considered by human-in-the-loop methods, including a variety of locomotion and robotic manipulation skills. We also show that our method is able to utilize real-time human feedback to effectively prevent reward exploitation and learn new behaviors that are difficult to specify with standard reward …

Offline Reinforcement Learning promises to learn effective policies from previously-collected, static datasets without the need for exploration. However, existing Q-learning and actor-critic based off-policy RL algorithms fail when bootstrapping from out-of-distribution (OOD) actions or states. We hypothesize that a key missing ingredient from the existing methods is a proper treatment of uncertainty in the offline setting. We propose Uncertainty Weighted Actor-Critic (UWAC), an algorithm that detects OOD state-action pairs and down-weights their contribution in the training objectives accordingly. Implementation-wise, we adopt a practical and effective dropout-based uncertainty estimation method that introduces very little overhead over existing RL algorithms. Empirically, we observe that UWAC substantially improves model stability during training. In addition, UWAC out-performs existing offline RL methods on a variety of competitive tasks, and achieves significant performance gains over the state-of-the-art baseline on datasets with sparse demonstrations collected from human experts.

Imitation learning trains control policies by mimicking pre-recorded expert demonstrations. In partially observable settings, imitation policies must rely on observation histories, but many seemingly paradoxical results show better performance for policies that only access the most recent observation. Recent solutions ranging from causal graph learning to deep information bottlenecks have shown promising results, but failed to scale to realistic settings such as visual imitation. We propose a solution that outperforms these prior approaches by upweighting demonstration keyframes corresponding to expert action changepoints. This simple approach easily scales to complex visual imitation settings. Our experimental results demonstrate consistent performance improvements over all baselines on image-based Gym MuJoCo continuous control tasks. Finally, on the CARLA photorealistic vision-based urban driving simulator, we resolve a long-standing issue in behavioral cloning for driving by demonstrating effective imitation from observation histories. Supplementary materials and code at: \url{https://tinyurl.com/imitation-keyframes}.
We introduce learning and planning algorithms for average-reward MDPs, including 1) the first general proven-convergent off-policy model-free control algorithm without reference states, 2) the first proven-convergent off-policy model-free prediction algorithm, and 3) the first off-policy learning algorithm that converges to the actual value function rather than to the value function plus an offset. All of our algorithms are based on using the temporal-difference error rather than the conventional error when updating the estimate of the average reward. Our proof techniques are a slight generalization of those by Abounadi, Bertsekas, and Borkar (2001). In experiments with an Access-Control Queuing Task, we show some of the difficulties that can arise when using methods that rely on reference states and argue that our new algorithms are significantly easier to use.
The Laplacian representation recently gains increasing attention for reinforcement learning as it provides succinct and informative representation for states, by taking the eigenvectors of the Laplacian matrix of the state-transition graph as state embeddings. Such representation captures the geometry of the underlying state space and is beneficial to RL tasks such as option discovery and reward shaping. To approximate the Laplacian representation in large (or even continuous) state spaces, recent works propose to minimize a spectral graph drawing objective, which however has infinitely many global minimizers other than the eigenvectors. As a result, their learned Laplacian representation may differ from the ground truth. To solve this problem, we reformulate the graph drawing objective into a generalized form and derive a new learning objective, which is proved to have eigenvectors as its unique global minimizer. It enables learning high-quality Laplacian representations that faithfully approximate the ground truth. We validate this via comprehensive experiments on a set of gridworld and continuous control environments. Moreover, we show that our learned Laplacian representations lead to more exploratory options and better reward shaping.

Low-precision training has become a popular approach to reduce compute requirements, memory footprint, and energy consumption in supervised learning. In contrast, this promising approach has not yet enjoyed similarly widespread adoption within the reinforcement learning (RL) community, partly because RL agents can be notoriously hard to train even in full precision. In this paper we consider continuous control with the state-of-the-art SAC agent and demonstrate that a na\"ive adaptation of low-precision methods from supervised learning fails. We propose a set of six modifications, all straightforward to implement, that leaves the underlying agent and its hyperparameters unchanged but improves the numerical stability dramatically. The resulting modified SAC agent has lower memory and compute requirements while matching full-precision rewards, demonstrating that low-precision training can substantially accelerate state-of-the-art RL without parameter tuning.

Off-policy learning allows us to learn about possible policies of behavior from experience generated by a different behavior policy. Temporal difference (TD) learning algorithms can become unstable when combined with function approximation and off-policy sampling---this is known as the ``deadly triad''. Emphatic temporal difference (ETD(λ)) algorithm ensures convergence in the linear case by appropriately weighting the TD(λ) updates. In this paper, we extend the use of emphatic methods to deep reinforcement learning agents. We show that naively adapting ETD(λ) to popular deep reinforcement learning algorithms, which use forward view multi-step returns, results in poor performance. We then derive new emphatic algorithms for use in the context of such algorithms, and we demonstrate that they provide noticeable benefits in small problems designed to highlight the instability of TD methods. Finally, we observed improved performance when applying these algorithms at scale on classic Atari games from the Arcade Learning Environment.
Oral: Reinforcement Learning 6 Wed 21 Jul 03:00 a.m.

Standard deep reinforcement learning algorithms use a shared representation for the policy and value function, especially when training directly from images. However, we argue that more information is needed to accurately estimate the value function than to learn the optimal policy. Consequently, the use of a shared representation for the policy and value function can lead to overfitting. To alleviate this problem, we propose two approaches which are combined to create IDAAC: Invariant Decoupled Advantage Actor-Critic. First, IDAAC decouples the optimization of the policy and value function, using separate networks to model them. Second, it introduces an auxiliary loss which encourages the representation to be invariant to task-irrelevant properties of the environment. IDAAC shows good generalization to unseen environments, achieving a new state-of-the-art on the Procgen benchmark and outperforming popular methods on DeepMind Control tasks with distractors. Our implementation is available at https://github.com/rraileanu/idaac.

Environments with procedurally generated content serve as important benchmarks for testing systematic generalization in deep reinforcement learning. In this setting, each level is an algorithmically created environment instance with a unique configuration of its factors of variation. Training on a prespecified subset of levels allows for testing generalization to unseen levels. What can be learned from a level depends on the current policy, yet prior work defaults to uniform sampling of training levels independently of the policy. We introduce Prioritized Level Replay (PLR), a general framework for selectively sampling the next training level by prioritizing those with higher estimated learning potential when revisited in the future. We show TD-errors effectively estimate a level's future learning potential and, when used to guide the sampling procedure, induce an emergent curriculum of increasingly difficult levels. By adapting the sampling of training levels, PLR significantly improves sample-efficiency and generalization on Procgen Benchmark—matching the previous state-of-the-art in test return—and readily combines with other methods. Combined with the previous leading method, PLR raises the state-of-the-art to over 76% improvement in test return relative to standard RL baselines.

Generalization has been a long-standing challenge for reinforcement learning (RL). Visual RL, in particular, can be easily distracted by irrelevant factors in high-dimensional observation space. In this work, we consider robust policy learning which targets zero-shot generalization to unseen visual environments with large distributional shift. We propose SECANT, a novel self-expert cloning technique that leverages image augmentation in two stages to decouple robust representation learning from policy optimization. Specifically, an expert policy is first trained by RL from scratch with weak augmentations. A student network then learns to mimic the expert policy by supervised learning with strong augmentations, making its representation more robust against visual variations compared to the expert. Extensive experiments demonstrate that SECANT significantly advances the state of the art in zero-shot generalization across 4 challenging domains. Our average reward improvements over prior SOTAs are: DeepMind Control (+26.5%), robotic manipulation (+337.8%), vision-based autonomous driving (+47.7%), and indoor object navigation (+15.8%). Code release and video are available at https://linxifan.github.io/secant-site/.

In this paper, we devise a distributional framework on actor-critic as a solution to distributional instability, action type restriction, and conflation between samples and statistics. We propose a new method that minimizes the Cramér distance with the multi-step Bellman target distribution generated from a novel Sample-Replacement algorithm denoted SR(\lambda), which learns the correct value distribution under multiple Bellman operations. Parameterizing a value distribution with Gaussian Mixture Model further improves the efficiency and the performance of the method, which we name GMAC. We empirically show that GMAC captures the correct representation of value distributions and improves the performance of a conventional actor-critic method with low computational cost, in both discrete and continuous action spaces using Arcade Learning Environment (ALE) and PyBullet environment.

Goal-conditioned reinforcement learning endows an agent with a large variety of skills, but it often struggles to solve tasks that require more temporally extended reasoning. In this work, we propose to incorporate imagined subgoals into policy learning to facilitate learning of complex tasks. Imagined subgoals are predicted by a separate high-level policy, which is trained simultaneously with the policy and its critic. This high-level policy predicts intermediate states halfway to the goal using the value function as a reachability metric. We don’t require the policy to reach these subgoals explicitly. Instead, we use them to define a prior policy, and incorporate this prior into a KL-constrained policy iteration scheme to speed up and regularize learning. Imagined subgoals are used during policy learning, but not during test time, where we only apply the learned policy. We evaluate our approach on complex robotic navigation and manipulation tasks and show that it outperforms existing methods by a large margin.
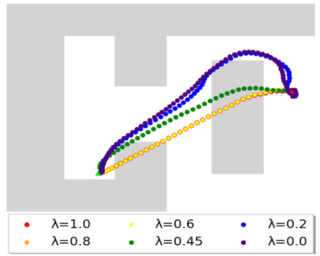
The difficulty in specifying rewards for many real-world problems has led to an increased focus on learning rewards from human feedback, such as demonstrations. However, there are often many different reward functions that explain the human feedback, leaving agents with uncertainty over what the true reward function is. While most policy optimization approaches handle this uncertainty by optimizing for expected performance, many applications demand risk-averse behavior. We derive a novel policy gradient-style robust optimization approach, PG-BROIL, that optimizes a soft-robust objective that balances expected performance and risk. To the best of our knowledge, PG-BROIL is the first policy optimization algorithm robust to a distribution of reward hypotheses which can scale to continuous MDPs. Results suggest that PG-BROIL can produce a family of behaviors ranging from risk-neutral to risk-averse and outperforms state-of-the-art imitation learning algorithms when learning from ambiguous demonstrations by hedging against uncertainty, rather than seeking to uniquely identify the demonstrator's reward function.

Learning to flexibly follow task instructions in dynamic environments poses interesting challenges for reinforcement learning agents. We focus here on the problem of learning control flow that deviates from a strict step-by-step execution of instructions—that is, control flow that may skip forward over parts of the instructions or return backward to previously completed or skipped steps. Demand for such flexible control arises in two fundamental ways: explicitly when control is specified in the instructions themselves (such as conditional branching and looping) and implicitly when stochastic environment dynamics require re-completion of instructions whose effects have been perturbed, or opportunistic skipping of instructions whose effects are already present. We formulate an attention-based architecture that meets these challenges by learning, from task reward only, to flexibly attend to and condition behavior on an internal encoding of the instructions. We test the architecture's ability to learn both explicit and implicit control in two illustrative domains---one inspired by Minecraft and the other by StarCraft---and show that the architecture exhibits zero-shot generalization to novel instructions of length greater than those in a training set, at a performance level unmatched by three baseline recurrent architectures and one ablation architecture.
Oral: Deep Learning Algorithms and Applications Wed 21 Jul 03:00 a.m.

Unrolled computation graphs arise in many scenarios, including training RNNs, tuning hyperparameters through unrolled optimization, and training learned optimizers. Current approaches to optimizing parameters in such computation graphs suffer from high variance gradients, bias, slow updates, or large memory usage. We introduce a method called Persistent Evolution Strategies (PES), which divides the computation graph into a series of truncated unrolls, and performs an evolution strategies-based update step after each unroll. PES eliminates bias from these truncations by accumulating correction terms over the entire sequence of unrolls. PES allows for rapid parameter updates, has low memory usage, is unbiased, and has reasonable variance characteristics. We experimentally demonstrate the advantages of PES compared to several other methods for gradient estimation on synthetic tasks, and show its applicability to training learned optimizers and tuning hyperparameters.

This paper introduces EfficientNetV2, a new family of convolutional networks that have faster training speed and better parameter efficiency than previous models. To develop these models, we use a combination of training-aware neural architecture search and scaling, to jointly optimize training speed and parameter efficiency. The models were searched from the search space enriched with new ops such as Fused-MBConv. Our experiments show that EfficientNetV2 models train much faster than state-of-the-art models while being up to 6.8x smaller. Our training can be further sped up by progressively increasing the image size during training, but it often causes a drop in accuracy. To compensate for this accuracy drop, we propose an improved method of progressive learning, which adaptively adjusts regularization (e.g. data augmentation) along with image size. With progressive learning, our EfficientNetV2 significantly outperforms previous models on ImageNet and CIFAR/Cars/Flowers datasets. By pretraining on the same ImageNet21k, our EfficientNetV2 achieves 87.3% top-1 accuracy on ImageNet ILSVRC2012, outperforming the recent ViT by 2.0% accuracy while training 5x-11x faster using the same computing resources.

Humans show an innate ability to learn the regularities of the world through interaction. By performing experiments in our environment, we are able to discern the causal factors of variation and infer how they affect the dynamics of our world. Analogously, here we attempt to equip reinforcement learning agents with the ability to perform experiments that facilitate a categorization of the rolled-out trajectories, and to subsequently infer the causal factors of the environment in a hierarchical manner. We introduce a novel intrinsic reward, called causal curiosity, and show that it allows our agents to learn optimal sequences of actions, and to discover causal factors in the dynamics. The learned behavior allows the agent to infer a binary quantized representation for the ground-truth causal factors in every environment. Additionally, we find that these experimental behaviors are semantically meaningful (e.g., to differentiate between heavy and light blocks, our agents learn to lift them), and are learnt in a self-supervised manner with approximately 2.5 times less data than conventional supervised planners. We show that these behaviors can be re-purposed and fine-tuned (e.g., from lifting to pushing or other downstream tasks). Finally, we show that the knowledge of causal factor representations aids zero-shot learning …

Deep domain adaptation (DDA) approaches have recently been shown to perform better than their shallow rivals with better modeling capacity on complex domains (e.g., image, structural data, and sequential data). The underlying idea is to learn domain invariant representations on a latent space that can bridge the gap between source and target domains. Several theoretical studies have established insightful understanding and the benefit of learning domain invariant features; however, they are usually limited to the case where there is no label shift, hence hindering its applicability. In this paper, we propose and study a new challenging setting that allows us to use a Wasserstein distance (WS) to not only quantify the data shift but also to define the label shift directly. We further develop a theory to demonstrate that minimizing the WS of the data shift leads to closing the gap between the source and target data distributions on the latent space (e.g., an intermediate layer of a deep net), while still being able to quantify the label shift with respect to this latent space. Interestingly, our theory can consequently explain certain drawbacks of learning domain invariant features on the latent space. Finally, grounded on the results and guidance of …
Sequence learning has attracted much research attention from the machine learning community in recent years. In many applications, a sequence learning task is usually associated with multiple temporally correlated auxiliary tasks, which are different in terms of how much input information to use or which future step to predict. For example, (i) in simultaneous machine translation, one can conduct translation under different latency (i.e., how many input words to read/wait before translation); (ii) in stock trend forecasting, one can predict the price of a stock in different future days (e.g., tomorrow, the day after tomorrow). While it is clear that those temporally correlated tasks can help each other, there is a very limited exploration on how to better leverage multiple auxiliary tasks to boost the performance of the main task. In this work, we introduce a learnable scheduler to sequence learning, which can adaptively select auxiliary tasks for training depending on the model status and the current training data. The scheduler and the model for the main task are jointly trained through bi-level optimization. Experiments show that our method significantly improves the performance of simultaneous machine translation and stock trend forecasting.
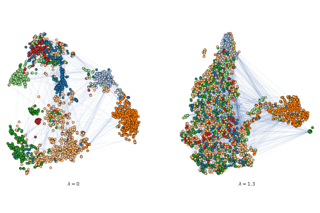
While the advent of Graph Neural Networks (GNNs) has greatly improved node and graph representation learning in many applications, the neighborhood aggregation scheme exposes additional vulnerabilities to adversaries seeking to extract node-level information about sensitive attributes. In this paper, we study the problem of protecting sensitive attributes by information obfuscation when learning with graph structured data. We propose a framework to locally filter out pre-determined sensitive attributes via adversarial training with the total variation and the Wasserstein distance. Our method creates a strong defense against inference attacks, while only suffering small loss in task performance. Theoretically, we analyze the effectiveness of our framework against a worst-case adversary, and characterize an inherent trade-off between maximizing predictive accuracy and minimizing information leakage. Experiments across multiple datasets from recommender systems, knowledge graphs and quantum chemistry demonstrate that the proposed approach provides a robust defense across various graph structures and tasks, while producing competitive GNN encoders for downstream tasks.
Oral: Reinforcement Learning 8 Wed 21 Jul 04:00 a.m.

Decision analysis deals with modeling and enhancing decision processes. A principal challenge in improving behavior is in obtaining a transparent description of existing behavior in the first place. In this paper, we develop an expressive, unifying perspective on inverse decision modeling: a framework for learning parameterized representations of sequential decision behavior. First, we formalize the forward problem (as a normative standard), subsuming common classes of control behavior. Second, we use this to formalize the inverse problem (as a descriptive model), generalizing existing work on imitation/reward learning---while opening up a much broader class of research problems in behavior representation. Finally, we instantiate this approach with an example (inverse bounded rational control), illustrating how this structure enables learning (interpretable) representations of (bounded) rationality---while naturally capturing intuitive notions of suboptimal actions, biased beliefs, and imperfect knowledge of environments.

Modern policy gradient algorithms such as Proximal Policy Optimization (PPO) rely on an arsenal of heuristics, including loss clipping and gradient clipping, to ensure successful learning. These heuristics are reminiscent of techniques from robust statistics, commonly used for estimation in outlier-rich ("heavy-tailed") regimes. In this paper, we present a detailed empirical study to characterize the heavy-tailed nature of the gradients of the PPO surrogate reward function. We demonstrate that the gradients, especially for the actor network, exhibit pronounced heavy-tailedness and that it increases as the agent's policy diverges from the behavioral policy (i.e., as the agent goes further off policy). Further examination implicates the likelihood ratios and advantages in the surrogate reward as the main sources of the observed heavy-tailedness. We then highlight issues arising due to the heavy-tailed nature of the gradients. In this light, we study the effects of the standard PPO clipping heuristics, demonstrating that these tricks primarily serve to offset heavy-tailedness in gradients. Thus motivated, we propose incorporating GMOM, a high-dimensional robust estimator, into PPO as a substitute for three clipping tricks. Despite requiring less hyperparameter tuning, our method matches the performance of PPO (with all heuristics enabled) on a battery of MuJoCo continuous control tasks.

Progress in deep reinforcement learning (RL) research is largely enabled by benchmark task environments. However, analyzing the nature of those environments is often overlooked. In particular, we still do not have agreeable ways to measure the difficulty or solvability of a task, given that each has fundamentally different actions, observations, dynamics, rewards, and can be tackled with diverse RL algorithms. In this work, we propose policy information capacity (PIC) -- the mutual information between policy parameters and episodic return -- and policy-optimal information capacity (POIC) -- between policy parameters and episodic optimality -- as two environment-agnostic, algorithm-agnostic quantitative metrics for task difficulty. Evaluating our metrics across toy environments as well as continuous control benchmark tasks from OpenAI Gym and DeepMind Control Suite, we empirically demonstrate that these information-theoretic metrics have higher correlations with normalized task solvability scores than a variety of alternatives. Lastly, we show that these metrics can also be used for fast and compute-efficient optimizations of key design parameters such as reward shaping, policy architectures, and MDP properties for better solvability by RL algorithms without ever running full RL experiments.
Learning to reach goal states and learning diverse skills through mutual information maximization have been proposed as principled frameworks for unsupervised reinforcement learning, allowing agents to acquire broadly applicable multi-task policies with minimal reward engineering. In this paper, we discuss how these two approaches — goal-conditioned RL (GCRL) and MI-based RL — can be generalized into a single family of methods, interpreting mutual information maximization and variational empowerment as representation learning methods that acquire function-ally aware state representations for goal reaching.Starting from a simple observation that the standard GCRL is encapsulated by the optimization objective of variational empowerment, we can derive novel variants of GCRL and variational empowerment under a single, unified optimization objective, such as adaptive-variance GCRL and linear-mapping GCRL, and study the characteristics of representation learning each variant provides. Furthermore, through the lens of GCRL, we show that adapting powerful techniques fromGCRL such as goal relabeling into the variationalMI context as well as proper regularization on the variational posterior provides substantial gains in algorithm performance, and propose a novel evaluation metric named latent goal reaching (LGR)as an objective measure for evaluating empowerment algorithms akin to goal-based RL. Through principled mathematical derivations and careful experimental validations, our work lays …

We study offline reinforcement learning (RL), which aims to learn an optimal policy based on a dataset collected a priori. Due to the lack of further interactions with the environment, offline RL suffers from the insufficient coverage of the dataset, which eludes most existing theoretical analysis. In this paper, we propose a pessimistic variant of the value iteration algorithm (PEVI), which incorporates an uncertainty quantifier as the penalty function. Such a penalty function simply flips the sign of the bonus function for promoting exploration in online RL, which makes it easily implementable and compatible with general function approximators.
Without assuming the sufficient coverage of the dataset, we establish a data-dependent upper bound on the suboptimality of PEVI for general Markov decision processes (MDPs). When specialized to linear MDPs, it matches the information-theoretic lower bound up to multiplicative factors of the dimension and horizon. In other words, pessimism is not only provably efficient but also minimax optimal. In particular, given the dataset, the learned policy serves as the best effort'' among all policies, as no other policies can do better. Our theoretical analysis identifies the critical role of pessimism in eliminating a notion of spurious correlation, which emerges from theirrelevant'' …

Bandit and reinforcement learning (RL) problems can often be framed as optimization problems where the goal is to maximize average performance while having access only to stochastic estimates of the true gradient. Traditionally, stochastic optimization theory predicts that learning dynamics are governed by the curvature of the loss function and the noise of the gradient estimates. In this paper we demonstrate that the standard view is too limited for bandit and RL problems. To allow our analysis to be interpreted in light of multi-step MDPs, we focus on techniques derived from stochastic optimization principles~(e.g., natural policy gradient and EXP3) and we show that some standard assumptions from optimization theory are violated in these problems. We present theoretical results showing that, at least for bandit problems, curvature and noise are not sufficient to explain the learning dynamics and that seemingly innocuous choices like the baseline can determine whether an algorithm converges. These theoretical findings match our empirical evaluation, which we extend to multi-state MDPs.

We study constrained reinforcement learning (CRL) from a novel perspective by setting constraints directly on state density functions, rather than the value functions considered by previous works. State density has a clear physical and mathematical interpretation, and is able to express a wide variety of constraints such as resource limits and safety requirements. Density constraints can also avoid the time-consuming process of designing and tuning cost functions required by value function-based constraints to encode system specifications. We leverage the duality between density functions and Q functions to develop an effective algorithm to solve the density constrained RL problem optimally and the constrains are guaranteed to be satisfied. We prove that the proposed algorithm converges to a near-optimal solution with a bounded error even when the policy update is imperfect. We use a set of comprehensive experiments to demonstrate the advantages of our approach over state-of-the-art CRL methods, with a wide range of density constrained tasks as well as standard CRL benchmarks such as Safety-Gym.
Oral: Deep Learning Algorithms 7 Wed 21 Jul 04:00 a.m.

Distributional shift is one of the major obstacles when transferring machine learning prediction systems from the lab to the real world. To tackle this problem, we assume that variation across training domains is representative of the variation we might encounter at test time, but also that shifts at test time may be more extreme in magnitude. In particular, we show that reducing differences in risk across training domains can reduce a model’s sensitivity to a wide range of extreme distributional shifts, including the challenging setting where the input contains both causal and anti-causal elements. We motivate this approach, Risk Extrapolation (REx), as a form of robust optimization over a perturbation set of extrapolated domains (MM-REx), and propose a penalty on the variance of training risks (V-REx) as a simpler variant. We prove that variants of REx can recover the causal mechanisms of the targets, while also providing robustness to changes in the input distribution (``covariate shift''). By appropriately trading-off robustness to causally induced distributional shifts and covariate shift, REx is able to outperform alternative methods such as Invariant Risk Minimization in situations where these types of shift co-occur.

Object detection has recently achieved a breakthrough for removing the last one non-differentiable component in the pipeline, Non-Maximum Suppression (NMS), and building up an end-to-end system. However, what makes for its one-to-one prediction has not been well understood. In this paper, we first point out that one-to-one positive sample assignment is the key factor, while, one-to-many assignment in previous detectors causes redundant predictions in inference. Second, we surprisingly find that even training with one-to-one assignment, previous detectors still produce redundant predictions. We identify that classification cost in matching cost is the main ingredient: (1) previous detectors only consider location cost, (2) by additionally introducing classification cost, previous detectors immediately produce one-to-one prediction during inference. We introduce the concept of score gap to explore the effect of matching cost. Classification cost enlarges the score gap by choosing positive samples as those of highest score in the training iteration and reducing noisy positive samples brought by only location cost. Finally, we demonstrate the advantages of end-to-end object detection on crowded scenes.

We consider the problem of explaining the predictions of graph neural networks (GNNs), which otherwise are considered as black boxes. Existing methods invariably focus on explaining the importance of graph nodes or edges but ignore the substructures of graphs, which are more intuitive and human-intelligible. In this work, we propose a novel method, known as SubgraphX, to explain GNNs by identifying important subgraphs. Given a trained GNN model and an input graph, our SubgraphX explains its predictions by efficiently exploring different subgraphs with Monte Carlo tree search. To make the tree search more effective, we propose to use Shapley values as a measure of subgraph importance, which can also capture the interactions among different subgraphs. To expedite computations, we propose efficient approximation schemes to compute Shapley values for graph data. Our work represents the first attempt to explain GNNs via identifying subgraphs explicitly and directly. Experimental results show that our SubgraphX achieves significantly improved explanations, while keeping computations at a reasonable level.

Data poisoning and backdoor attacks manipulate training data in order to cause models to fail during inference. A recent survey of industry practitioners found that data poisoning is the number one concern among threats ranging from model stealing to adversarial attacks. However, it remains unclear exactly how dangerous poisoning methods are and which ones are more effective considering that these methods, even ones with identical objectives, have not been tested in consistent or realistic settings. We observe that data poisoning and backdoor attacks are highly sensitive to variations in the testing setup. Moreover, we find that existing methods may not generalize to realistic settings. While these existing works serve as valuable prototypes for data poisoning, we apply rigorous tests to determine the extent to which we should fear them. In order to promote fair comparison in future work, we develop standardized benchmarks for data poisoning and backdoor attacks.

Conventional image classifiers are trained by randomly sampling mini-batches of images. To achieve state-of-the-art performance, practitioners use sophisticated data augmentation schemes to expand the amount of training data available for sampling. In contrast, meta-learning algorithms sample support data, query data, and tasks on each training step. In this complex sampling scenario, data augmentation can be used not only to expand the number of images available per class, but also to generate entirely new classes/tasks. We systematically dissect the meta-learning pipeline and investigate the distinct ways in which data augmentation can be integrated at both the image and class levels. Our proposed meta-specific data augmentation significantly improves the performance of meta-learners on few-shot classification benchmarks.

A discriminatively trained neural net classifier can fit the training data perfectly if all information about its input other than class membership has been discarded prior to the output layer. Surprisingly, past research has discovered that some extraneous visual detail remains in the unnormalized logits. This finding is based on inversion techniques that map deep embeddings back to images. We explore this phenomenon further using a novel synthesis of methods, yielding a feedforward inversion model that produces remarkably high fidelity reconstructions, qualitatively superior to those of past efforts. When applied to an adversarially robust classifier model, the reconstructions contain sufficient local detail and global structure that they might be confused with the original image in a quick glance, and the object category can clearly be gleaned from the reconstruction. Our approach is based on BigGAN (Brock, 2019), with conditioning on logits instead of one-hot class labels. We use our reconstruction model as a tool for exploring the nature of representations, including: the influence of model architecture and training objectives (specifically robust losses), the forms of invariance that networks achieve, representational differences between correctly and incorrectly classified images, and the effects of manipulating logits and images. We believe that our method …

Symbolic equations are at the core of scientific discovery. The task of discovering the underlying equation from a set of input-output pairs is called symbolic regression. Traditionally, symbolic regression methods use hand-designed strategies that do not improve with experience. In this paper, we introduce the first symbolic regression method that leverages large scale pre-training. We procedurally generate an unbounded set of equations, and simultaneously pre-train a Transformer to predict the symbolic equation from a corresponding set of input-output-pairs. At test time, we query the model on a new set of points and use its output to guide the search for the equation. We show empirically that this approach can re-discover a set of well-known physical equations, and that it improves over time with more data and compute.
Oral: Deep Reinforcement Learning 3 Wed 21 Jul 04:00 a.m.

Exploration is critical for good results in deep reinforcement learning and has attracted much attention. However, existing multi-agent deep reinforcement learning algorithms still use mostly noise-based techniques. Very recently, exploration methods that consider cooperation among multiple agents have been developed. However, existing methods suffer from a common challenge: agents struggle to identify states that are worth exploring, and hardly coordinate exploration efforts toward those states. To address this shortcoming, in this paper, we propose cooperative multi-agent exploration (CMAE): agents share a common goal while exploring. The goal is selected from multiple projected state spaces by a normalized entropy-based technique. Then, agents are trained to reach the goal in a coordinated manner. We demonstrate that CMAE consistently outperforms baselines on various tasks, including a sparse-reward version of multiple-particle environment (MPE) and the Starcraft multi-agent challenge (SMAC).

Marginalized importance sampling (MIS), which measures the density ratio between the state-action occupancy of a target policy and that of a sampling distribution, is a promising approach for off-policy evaluation. However, current state-of-the-art MIS methods rely on complex optimization tricks and succeed mostly on simple toy problems. We bridge the gap between MIS and deep reinforcement learning by observing that the density ratio can be computed from the successor representation of the target policy. The successor representation can be trained through deep reinforcement learning methodology and decouples the reward optimization from the dynamics of the environment, making the resulting algorithm stable and applicable to high-dimensional domains. We evaluate the empirical performance of our approach on a variety of challenging Atari and MuJoCo environments.

This paper investigates how to weight imperfect expert demonstrations for generative adversarial imitation learning (GAIL). The agent is expected to perform behaviors demonstrated by experts. But in many applications, experts could also make mistakes and their demonstrations would mislead or slow the learning process of the agent. Recently, existing methods for imitation learning from imperfect demonstrations mostly focus on using the preference or confidence scores to distinguish imperfect demonstrations. However, these auxiliary information needs to be collected with the help of an oracle, which is usually hard and expensive to afford in practice. In contrast, this paper proposes a method of learning to weight imperfect demonstrations in GAIL without imposing extensive prior information. We provide a rigorous mathematical analysis, presenting that the weights of demonstrations can be exactly determined by combining the discriminator and agent policy in GAIL. Theoretical analysis suggests that with the estimated weights the agent can learn a better policy beyond those plain expert demonstrations. Experiments in the Mujoco and Atari environments demonstrate that the proposed algorithm outperforms baseline methods in handling imperfect expert demonstrations.
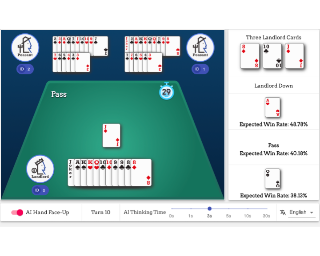
Games are abstractions of the real world, where artificial agents learn to compete and cooperate with other agents. While significant achievements have been made in various perfect- and imperfect-information games, DouDizhu (a.k.a. Fighting the Landlord), a three-player card game, is still unsolved. DouDizhu is a very challenging domain with competition, collaboration, imperfect information, large state space, and particularly a massive set of possible actions where the legal actions vary significantly from turn to turn. Unfortunately, modern reinforcement learning algorithms mainly focus on simple and small action spaces, and not surprisingly, are shown not to make satisfactory progress in DouDizhu. In this work, we propose a conceptually simple yet effective DouDizhu AI system, namely DouZero, which enhances traditional Monte-Carlo methods with deep neural networks, action encoding, and parallel actors. Starting from scratch in a single server with four GPUs, DouZero outperformed all the existing DouDizhu AI programs in days of training and was ranked the first in the Botzone leaderboard among 344 AI agents. Through building DouZero, we show that classic Monte-Carlo methods can be made to deliver strong results in a hard domain with a complex action space. The code and an online demo are released at https://github.com/kwai/DouZero with the …

Exploration in reinforcement learning is, in general, a challenging problem. A common technique to make learning easier is providing demonstrations from a human supervisor, but such demonstrations can be expensive and time-consuming to acquire. In this work, we study a more tractable class of reinforcement learning problems defined simply by examples of successful outcome states, which can be much easier to provide while still making the exploration problem more tractable. In this problem setting, the reward function can be obtained automatically by training a classifier to categorize states as successful or not. However, as we will show, this requires the classifier to make uncertainty-aware predictions that are very difficult using standard techniques for training deep networks. To address this, we propose a novel mechanism for obtaining calibrated uncertainty based on an amortized technique for computing the normalized maximum likelihood (NML) distribution, leveraging tools from meta-learning to make this distribution tractable. We show that the resulting algorithm has a number of intriguing connections to both count-based exploration methods and prior algorithms for learning reward functions, while also providing more effective guidance towards the goal. We demonstrate that our algorithm solves a number of challenging navigation and robotic manipulation tasks which prove …

The ability to autonomously learn behaviors via direct interactions in uninstrumented environments can lead to generalist robots capable of enhancing productivity or providing care in unstructured settings like homes. Such uninstrumented settings warrant operations only using the robot’s proprioceptive sensor such as onboard cameras, joint encoders, etc which can be challenging for policy learning owing to the high dimensionality and partial observability issues. We propose RRL: Resnet as representation for Reinforcement Learning – a straightforward yet effective approach that can learn complex behaviors directly from proprioceptive inputs. RRL fuses features extracted from pre-trained Resnet into the standard reinforcement learning pipeline and delivers results comparable to learning directly from the state. In a simulated dexterous manipulation benchmark, where the state of the art methods fails to make significant progress, RRL delivers contact rich behaviors. The appeal of RRL lies in its simplicity in bringing together progress from the fields of Representation Learning, Imitation Learning, and Reinforcement Learning. Its effectiveness in learning behaviors directly from visual inputs with performance and sample efficiency matching learning directly from the state, even in complex high dimensional domains, is far from obvious.

AlphaStar, the AI that reaches GrandMaster level in StarCraft II, is a remarkable milestone demonstrating what deep reinforcement learning can achieve in complex Real-Time Strategy (RTS) games. However, the complexities of the game, algorithms and systems, and especially the tremendous amount of computation needed are big obstacles for the community to conduct further research in this direction. We propose a deep reinforcement learning agent, StarCraft Commander (SCC). With order of magnitude less computation, it demonstrates top human performance defeating GrandMaster players in test matches and top professional players in a live event. Moreover, it shows strong robustness to various human strategies and discovers novel strategies unseen from human plays. In this paper, we’ll share the key insights and optimizations on efficient imitation learning and reinforcement learning for StarCraft II full game.
Oral: Reinforcement Learning 9 Wed 21 Jul 04:00 a.m.

We address the issue of tuning hyperparameters (HPs) for imitation learning algorithms in the context of continuous-control, when the underlying reward function of the demonstrating expert cannot be observed at any time. The vast literature in imitation learning mostly considers this reward function to be available for HP selection, but this is not a realistic setting. Indeed, would this reward function be available, it could then directly be used for policy training and imitation would not be necessary. To tackle this mostly ignored problem, we propose a number of possible proxies to the external reward. We evaluate them in an extensive empirical study (more than 10'000 agents across 9 environments) and make practical recommendations for selecting HPs. Our results show that while imitation learning algorithms are sensitive to HP choices, it is often possible to select good enough HPs through a proxy to the reward function.


State-of-the-art deep reinforcement learning (DRL) algorithms tend to overfit due to the model discrepancy between source and target environments. Though applying domain randomization during training can improve the average performance by randomly generating a sufficient diversity of environments in simulator, the worst-case environment is still neglected without any performance guarantee. Since the average and worst-case performance are both important for generalization in RL, in this paper, we propose a policy optimization approach for concurrently improving the policy's performance in the average and worst-case environment. We theoretically derive a lower bound for the worst-case performance of a given policy by relating it to the expected performance. Guided by this lower bound, we formulate an optimization problem to jointly optimize the policy and sampling distribution, and prove that by iteratively solving it the worst-case performance is monotonically improved. We then develop a practical algorithm, named monotonic robust policy optimization (MRPO). Experimental evaluations in several robot control tasks demonstrate that MRPO can generally improve both the average and worst-case performance in the source environments for training, and facilitate in all cases the learned policy with a better generalization capability in some unseen testing environments.

In practical reinforcement learning (RL), the discount factor used for estimating value functions often differs from that used for defining the evaluation objective. In this work, we study the effect that this discrepancy of discount factors has during learning, and discover a family of objectives that interpolate value functions of two distinct discount factors. Our analysis suggests new ways for estimating value functions and performing policy optimization updates, which demonstrate empirical performance gains. This framework also leads to new insights on commonly-used deep RL heuristic modifications to policy optimization algorithms.

Episodic memory-based methods can rapidly latch onto past successful strategies by a non-parametric memory and improve sample efficiency of traditional reinforcement learning. However, little effort is put into the continuous domain, where a state is never visited twice, and previous episodic methods fail to efficiently aggregate experience across trajectories. To address this problem, we propose Generalizable Episodic Memory (GEM), which effectively organizes the state-action values of episodic memory in a generalizable manner and supports implicit planning on memorized trajectories. GEM utilizes a double estimator to reduce the overestimation bias induced by value propagation in the planning process. Empirical evaluation shows that our method significantly outperforms existing trajectory-based methods on various MuJoCo continuous control tasks. To further show the general applicability, we evaluate our method on Atari games with discrete action space, which also shows a significant improvement over baseline algorithms.

The recent success of supervised learning methods on ever larger offline datasets has spurred interest in the reinforcement learning (RL) field to investigate whether the same paradigms can be translated to RL algorithms. This research area, known as offline RL, has largely focused on offline policy optimization, aiming to find a return-maximizing policy exclusively from offline data. In this paper, we consider a slightly different approach to incorporating offline data into sequential decision-making. We aim to answer the question, what unsupervised objectives applied to offline datasets are able to learn state representations which elevate performance on downstream tasks, whether those downstream tasks be online RL, imitation learning from expert demonstrations, or even offline policy optimization based on the same offline dataset? Through a variety of experiments utilizing standard offline RL datasets, we find that the use of pretraining with unsupervised learning objectives can dramatically improve the performance of policy learning algorithms that otherwise yield mediocre performance on their own. Extensive ablations further provide insights into what components of these unsupervised objectives – e.g., reward prediction, continuous or discrete representations, pretraining or finetuning – are most important and in which settings.

An ambitious goal for machine learning is to create agents that behave ethically: The capacity to abide by human moral norms would greatly expand the context in which autonomous agents could be practically and safely deployed, e.g. fully autonomous vehicles will encounter charged moral decisions that complicate their deployment. While ethical agents could be trained by rewarding correct behavior under a specific moral theory (e.g. utilitarianism), there remains widespread disagreement about the nature of morality. Acknowledging such disagreement, recent work in moral philosophy proposes that ethical behavior requires acting under moral uncertainty, i.e. to take into account when acting that one's credence is split across several plausible ethical theories. This paper translates such insights to the field of reinforcement learning, proposes two training methods that realize different points among competing desiderata, and trains agents in simple environments to act under moral uncertainty. The results illustrate (1) how such uncertainty can help curb extreme behavior from commitment to single theories and (2) several technical complications arising from attempting to ground moral philosophy in RL (e.g. how can a principled trade-off between two competing but incomparable reward functions be reached). The aim is to catalyze progress towards morally-competent agents and highlight the …
Oral: Large Scale Optimization Wed 21 Jul 04:00 a.m.

The increasing size of neural network models has been critical for improvements in their accuracy, but device memory is not growing at the same rate. This creates fundamental challenges for training neural networks within limited memory environments. In this work, we propose ActNN, a memory-efficient training framework that stores randomly quantized activations for back propagation. We prove the convergence of ActNN for general network architectures, and we characterize the impact of quantization on the convergence via an exact expression for the gradient variance. Using our theory, we propose novel mixed-precision quantization strategies that exploit the activation's heterogeneity across feature dimensions, samples, and layers. These techniques can be readily applied to existing dynamic graph frameworks, such as PyTorch, simply by substituting the layers. We evaluate ActNN on mainstream computer vision models for classification, detection, and segmentation tasks. On all these tasks, ActNN compresses the activation to 2 bits on average, with negligible accuracy loss. ActNN reduces the memory footprint of the activation by 12x, and it enables training with a 6.6x to 14x larger batch size.


Gradient staleness is a major side effect in decoupled learning when training convolutional neural networks asynchronously. Existing methods that ignore this effect might result in reduced generalization and even divergence. In this paper, we propose an accumulated decoupled learning (ADL), which includes a module-wise gradient accumulation in order to mitigate the gradient staleness. Unlike prior arts ignoring the gradient staleness, we quantify the staleness in such a way that its mitigation can be quantitatively visualized. As a new learning scheme, the proposed ADL is theoretically shown to converge to critical points in spite of its asynchronism. Extensive experiments on CIFAR-10 and ImageNet datasets are conducted, demonstrating that ADL gives promising generalization results while the state-of-the-art methods experience reduced generalization and divergence. In addition, our ADL is shown to have the fastest training speed among the compared methods.

Deep graph neural networks (GNNs) have achieved excellent results on various tasks on increasingly large graph datasets with millions of nodes and edges. However, memory complexity has become a major obstacle when training deep GNNs for practical applications due to the immense number of nodes, edges, and intermediate activations. To improve the scalability of GNNs, prior works propose smart graph sampling or partitioning strategies to train GNNs with a smaller set of nodes or sub-graphs. In this work, we study reversible connections, group convolutions, weight tying, and equilibrium models to advance the memory and parameter efficiency of GNNs. We find that reversible connections in combination with deep network architectures enable the training of overparameterized GNNs that significantly outperform existing methods on multiple datasets. Our models RevGNN-Deep (1001 layers with 80 channels each) and RevGNN-Wide (448 layers with 224 channels each) were both trained on a single commodity GPU and achieve an ROC-AUC of 87.74 ± 0.13 and 88.14 ± 0.15 on the ogbn-proteins dataset. To the best of our knowledge, RevGNN-Deep is the deepest GNN in the literature by one order of magnitude.

Scalable training of large models (like BERT and GPT-3) requires careful optimization rooted in model design, architecture, and system capabilities. From a system standpoint, communication has become a major bottleneck, especially on commodity systems with standard TCP interconnects that offer limited network bandwidth. Communication compression is an important technique to reduce training time on such systems. One of the most effective ways to compress communication is via error compensation compression, which offers robust convergence speed, even under 1-bit compression. However, state-of-the-art error compensation techniques only work with basic optimizers like SGD and momentum SGD, which are linearly dependent on the gradients. They do not work with non-linear gradient-based optimizers like Adam, which offer state-of-the-art convergence efficiency and accuracy for models like BERT. In this paper, we propose 1-bit Adam that reduces the communication volume by up to 5x, offers much better scalability, and provides the same convergence speed as uncompressed Adam. Our key finding is that Adam's variance becomes stable (after a warmup phase) and can be used as a fixed precondition for the rest of the training (compression phase). We performed experiments on up to 256 GPUs and show that 1-bit Adam enables up to 3.3x higher throughput for …

Deep AUC (area under the ROC curve) Maximization (DAM) has attracted much attention recently due to its great potential for imbalanced data classification. However, the research on Federated Deep AUC Maximization (FDAM) is still limited. Compared with standard federated learning (FL) approaches that focus on decomposable minimization objectives, FDAM is more complicated due to its minimization objective is non-decomposable over individual examples. In this paper, we propose improved FDAM algorithms for heterogeneous data by solving the popular non-convex strongly-concave min-max formulation of DAM in a distributed fashion, which can also be applied to a class of non-convex strongly-concave min-max problems. A striking result of this paper is that the communication complexity of the proposed algorithm is a constant independent of the number of machines and also independent of the accuracy level, which improves an existing result by orders of magnitude. The experiments have demonstrated the effectiveness of our FDAM algorithm on benchmark datasets, and on medical chest X-ray images from different organizations. Our experiment shows that the performance of FDAM using data from multiple hospitals can improve the AUC score on testing data from a single hospital for detecting life-threatening diseases based on chest radiographs.

Fairness and robustness are two important concerns for federated learning systems. In this work, we identify that robustness to data and model poisoning attacks and fairness, measured as the uniformity of performance across devices, are competing constraints in statistically heterogeneous networks. To address these constraints, we propose employing a simple, general framework for personalized federated learning, Ditto, that can inherently provide fairness and robustness benefits, and develop a scalable solver for it. Theoretically, we analyze the ability of Ditto to achieve fairness and robustness simultaneously on a class of linear problems. Empirically, across a suite of federated datasets, we show that Ditto not only achieves competitive performance relative to recent personalization methods, but also enables more accurate, robust, and fair models relative to state-of-the-art fair or robust baselines.
Oral: AutoML and Neural Network Architectures 2 Wed 21 Jul 04:00 a.m.

Weight-sharing neural architecture search (NAS) is an effective technique for automating efficient neural architecture design. Weight-sharing NAS builds a supernet that assembles all the architectures as its sub-networks and jointly trains the supernet with the sub-networks. The success of weight-sharing NAS heavily relies on distilling the knowledge of the supernet to the sub-networks. However, we find that the widely used distillation divergence, i.e., KL divergence, may lead to student sub-networks that over-estimate or under-estimate the uncertainty of the teacher supernet, leading to inferior performance of the sub-networks. In this work, we propose to improve the supernet training with a more generalized alpha-divergence. By adaptively selecting the alpha-divergence, we simultaneously prevent the over-estimation or under-estimation of the uncertainty of the teacher model. We apply the proposed alpha-divergence based supernets training to both slimmable neural networks and weight-sharing NAS, and demonstrate significant improvements. Specifically, our discovered model family, AlphaNet, outperforms prior-art models on a wide range of FLOPs regimes, including BigNAS, Once-for-All networks, and AttentiveNAS. We achieve ImageNet top-1 accuracy of 80.0% with only 444M FLOPs. Our code and pretrained models are available at https://github.com/facebookresearch/AlphaNet.

Transformer architectures are widely used, but training them is non-trivial, requiring custom learning rate schedules, scaling terms, residual connections, careful placement of submodules such as normalization, and so on. In this paper, we improve upon recent analysis of Transformers and formalize a notion of sensitivity to capture the difficulty of training. Sensitivity characterizes how the variance of activation and gradient norms change in expectation when parameters are randomly perturbed. We analyze the sensitivity of previous Transformer architectures and design a new architecture, the Catformer, which replaces residual connections or RNN-based gating mechanisms with concatenation. We prove that Catformers are less sensitive than other Transformer variants and demonstrate that this leads to more stable training. On DMLab30, a suite of high-dimension reinforcement tasks, Catformer outperforms other transformers, including Gated Transformer-XL---the state-of-the-art architecture designed to address stability---by 13%.
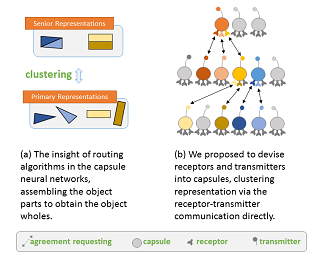
In previous Capsule Neural Networks (CapsNets), routing algorithms often performed clustering processes to assemble the child capsules' representations into parent capsules. Such routing algorithms were typically implemented with iterative processes and incurred high computing complexity. This paper presents a new capsule structure, which contains a set of optimizable receptors and a transmitter is devised on the capsule's representation. Specifically, child capsules' representations are sent to the parent capsules whose receptors match well the transmitters of the child capsules' representations, avoiding applying computationally complex routing algorithms. To ensure the receptors in a CapsNet work cooperatively, we build a skeleton to organize the receptors in different capsule layers in a CapsNet. The receptor skeleton assigns a share-out objective for each receptor, making the CapsNet perform as a hierarchical agglomerative clustering process. Comprehensive experiments verify that our approach facilitates efficient clustering processes, and CapsNets with our approach significantly outperform CapsNets with previous routing algorithms on image classification, affine transformation generalization, overlapped object recognition, and representation semantic decoupling.

Human beings acquire the ability of image classification through visual concept learning, in which the process of concept formation involves intertwined searches of common properties and concept descriptions. However, in most image classification algorithms using deep convolutional neural network (ConvNet), the representation space is constructed under the premise that concept descriptions are fixed as one-hot codes, which limits the mining of properties and the ability of identifying unseen samples. Inspired by this, we propose a learning strategy of visual concept formation (LSOVCF) based on the ConvNet, in which the two intertwined parts of concept formation, i.e. feature extraction and concept description, are learned together. First, LSOVCF takes sample response in the last layer of ConvNet to induct concept description being assumed as Gaussian distribution, which is part of the training process. Second, the exploration and experience loss is designed for optimization, which adopts experience cache pool to speed up convergence. Experiments show that LSOVCF improves the ability of identifying unseen samples on cifar10, STL10, flower17 and ImageNet based on several backbones, from the classic VGG to the SOTA Ghostnet. The code is available at \url{https://github.com/elvintanhust/LSOVCF}.


Batch normalization is a key component of most image classification models, but it has many undesirable properties stemming from its dependence on the batch size and interactions between examples. Although recent work has succeeded in training deep ResNets without normalization layers, these models do not match the test accuracies of the best batch-normalized networks, and are often unstable for large learning rates or strong data augmentations. In this work, we develop an adaptive gradient clipping technique which overcomes these instabilities, and design a significantly improved class of Normalizer-Free ResNets. Our smaller models match the test accuracy of an EfficientNet-B7 on ImageNet while being up to 8.7x faster to train, and our largest models attain a new state-of-the-art top-1 accuracy of 86.5%. In addition, Normalizer-Free models attain significantly better performance than their batch-normalized counterparts when fine-tuning on ImageNet after large-scale pre-training on a dataset of 300 million labeled images, with our best models obtaining an accuracy of 89.2%.

Attention based neural networks are state of the art in a large range of applications. However, their performance tends to degrade when the number of layers increases. In this work, we show that enforcing Lipschitz continuity by normalizing the attention scores can significantly improve the performance of deep attention models. First, we show that, for deep graph attention networks (GAT), gradient explosion appears during training, leading to poor performance of gradient-based training algorithms. To address this issue, we derive a theoretical analysis of the Lipschitz continuity of attention modules and introduce LipschitzNorm, a simple and parameter-free normalization for self-attention mechanisms that enforces the model to be Lipschitz continuous. We then apply LipschitzNorm to GAT and Graph Transformers and show that their performance is substantially improved in the deep setting (10 to 30 layers). More specifically, we show that a deep GAT model with LipschitzNorm achieves state of the art results for node label prediction tasks that exhibit long-range dependencies, while showing consistent improvements over their unnormalized counterparts in benchmark node classification tasks.
Oral: Deep Learning Algorithms 8 Wed 21 Jul 04:00 a.m.

Standard training via empirical risk minimization (ERM) can produce models that achieve low error on average but high error on minority groups, especially in the presence of spurious correlations between the input and label. Prior approaches to this problem, like group distributionally robust optimization (group DRO), generally require group annotations for every training point. On the other hand, approaches that do not use group annotations generally do not improve minority performance. For example, we find that joint DRO, which dynamically upweights examples with high training loss, tends to optimize for examples that are irrelevant to the specific groups we seek to do well on. In this paper, we propose a simple two-stage approach, JTT, that achieves comparable performance to group DRO while only requiring group annotations on a significantly smaller validation set. JTT first attempts to identify informative training examples, which are often minority examples, by training an initial ERM classifier and selecting the examples with high training loss. Then, it trains a final classifier by upsampling the selected examples. Crucially, unlike joint DRO, JTT does not iteratively upsample examples that have high loss under the final classifier. On four image classification and natural language processing tasks with spurious correlations, …

Graph Neural Networks (GNNs) have been studied through the lens of expressive power and generalization. However, their optimization properties are less well understood. We take the first step towards analyzing GNN training by studying the gradient dynamics of GNNs. First, we analyze linearized GNNs and prove that despite the non-convexity of training, convergence to a global minimum at a linear rate is guaranteed under mild assumptions that we validate on real-world graphs. Second, we study what may affect the GNNs' training speed. Our results show that the training of GNNs is implicitly accelerated by skip connections, more depth, and/or a good label distribution. Empirical results confirm that our theoretical results for linearized GNNs align with the training behavior of nonlinear GNNs. Our results provide the first theoretical support for the success of GNNs with skip connections in terms of optimization, and suggest that deep GNNs with skip connections would be promising in practice.

Normalization is known to help the optimization of deep neural networks. Curiously, different architectures require specialized normalization methods. In this paper, we study what normalization is effective for Graph Neural Networks (GNNs). First, we adapt and evaluate the existing methods from other domains to GNNs. Faster convergence is achieved with InstanceNorm compared to BatchNorm and LayerNorm. We provide an explanation by showing that InstanceNorm serves as a preconditioner for GNNs, but such preconditioning effect is weaker with BatchNorm due to the heavy batch noise in graph datasets. Second, we show that the shift operation in InstanceNorm results in an expressiveness degradation of GNNs for highly regular graphs. We address this issue by proposing GraphNorm with a learnable shift. Empirically, GNNs with GraphNorm converge faster compared to GNNs using other normalization. GraphNorm also improves the generalization of GNNs, achieving better performance on graph classification benchmarks.

Domain generalization is challenging due to the domain shift and the uncertainty caused by the inaccessibility of target domain data. In this paper, we address both challenges with a probabilistic framework based on variational Bayesian inference, by incorporating uncertainty into neural network weights. We couple domain invariance in a probabilistic formula with the variational Bayesian inference. This enables us to explore domain-invariant learning in a principled way. Specifically, we derive domain-invariant representations and classifiers, which are jointly established in a two-layer Bayesian neural network. We empirically demonstrate the effectiveness of our proposal on four widely used cross-domain visual recognition benchmarks. Ablation studies validate the synergistic benefits of our Bayesian treatment when jointly learning domain-invariant representations and classifiers for domain generalization. Further, our method consistently delivers state-of-the-art mean accuracy on all benchmarks.
Neural controlled differential equations (CDEs) are the continuous-time analogue of recurrent neural networks, as Neural ODEs are to residual networks, and offer a memory-efficient continuous-time way to model functions of potentially irregular time series. Existing methods for computing the forward pass of a Neural CDE involve embedding the incoming time series into path space, often via interpolation, and using evaluations of this path to drive the hidden state. Here, we use rough path theory to extend this formulation. Instead of directly embedding into path space, we instead represent the input signal over small time intervals through its \textit{log-signature}, which are statistics describing how the signal drives a CDE. This is the approach for solving \textit{rough differential equations} (RDEs), and correspondingly we describe our main contribution as the introduction of Neural RDEs. This extension has a purpose: by generalising the Neural CDE approach to a broader class of driving signals, we demonstrate particular advantages for tackling long time series. In this regime, we demonstrate efficacy on problems of length up to 17k observations and observe significant training speed-ups, improvements in model performance, and reduced memory requirements compared to existing approaches.

Machine learning is predicated on the concept of generalization: a model achieving low error on a sufficiently large training set should also perform well on novel samples from the same distribution. We show that both data whitening and second order optimization can harm or entirely prevent generalization. In general, model training harnesses information contained in the sample-sample second moment matrix of a dataset. For a general class of models, namely models with a fully connected first layer, we prove that the information contained in this matrix is the only information which can be used to generalize. Models trained using whitened data, or with certain second order optimization schemes, have less access to this information, resulting in reduced or nonexistent generalization ability. We experimentally verify these predictions for several architectures, and further demonstrate that generalization continues to be harmed even when theoretical requirements are relaxed. However, we also show experimentally that regularized second order optimization can provide a practical tradeoff, where training is accelerated but less information is lost, and generalization can in some circumstances even improve.

Deep neural networks have emerged as very successful tools for image restoration and reconstruction tasks. These networks are often trained end-to-end to directly reconstruct an image from a noisy or corrupted measurement of that image. To achieve state-of-the-art performance, training on large and diverse sets of images is considered critical. However, it is often difficult and/or expensive to collect large amounts of training images. Inspired by the success of Data Augmentation (DA) for classification problems, in this paper, we propose a pipeline for data augmentation for accelerated MRI reconstruction and study its effectiveness at reducing the required training data in a variety of settings. Our DA pipeline, MRAugment, is specifically designed to utilize the invariances present in medical imaging measurements as naive DA strategies that neglect the physics of the problem fail. Through extensive studies on multiple datasets we demonstrate that in the low-data regime DA prevents overfitting and can match or even surpass the state of the art while using significantly fewer training data, whereas in the high-data regime it has diminishing returns. Furthermore, our findings show that DA improves the robustness of the model against various shifts in the test distribution.
Oral: Optimization (Convex) 2 Wed 21 Jul 04:00 a.m.



We study the problem of minimizing a relatively-smooth convex function using stochastic Bregman gradient methods. We first prove the convergence of Bregman Stochastic Gradient Descent (BSGD) to a region that depends on the noise (magnitude of the gradients) at the optimum. In particular, BSGD quickly converges to the exact minimizer when this noise is zero (interpolation setting, in which the data is fit perfectly). Otherwise, when the objective has a finite sum structure, we show that variance reduction can be used to counter the effect of noise. In particular, fast convergence to the exact minimizer can be obtained under additional regularity assumptions on the Bregman reference function. We illustrate the effectiveness of our approach on two key applications of relative smoothness: tomographic reconstruction with Poisson noise and statistical preconditioning for distributed optimization.



Oral: Optimization 4 Wed 21 Jul 04:00 a.m.

Least squares estimators, when trained on few target domain samples, may predict poorly. Supervised domain adaptation aims to improve the predictive accuracy by exploiting additional labeled training samples from a source distribution that is close to the target distribution. Given available data, we investigate novel strategies to synthesize a family of least squares estimator experts that are robust with regard to moment conditions. When these moment conditions are specified using Kullback-Leibler or Wasserstein-type divergences, we can find the robust estimators efficiently using convex optimization. We use the Bernstein online aggregation algorithm on the proposed family of robust experts to generate predictions for the sequential stream of target test samples. Numerical experiments on real data show that the robust strategies systematically outperform non-robust interpolations of the empirical least squares estimators.


We consider the problem of optimizing hybrid structures (mixture of discrete and continuous input variables) via expensive black-box function evaluations. This problem arises in many real-world applications. For example, in materials design optimization via lab experiments, discrete and continuous variables correspond to the presence/absence of primitive elements and their relative concentrations respectively. The key challenge is to accurately model the complex interactions between discrete and continuous variables. In this paper, we propose a novel approach referred as Hybrid Bayesian Optimization (HyBO) by utilizing diffusion kernels, which are naturally defined over continuous and discrete variables. We develop a principled approach for constructing diffusion kernels over hybrid spaces by utilizing the additive kernel formulation, which allows additive interactions of all orders in a tractable manner. We theoretically analyze the modeling strength of additive hybrid kernels and prove that it has the universal approximation property. Our experiments on synthetic and six diverse real-world benchmarks show that HyBO significantly outperforms the state-of-the-art methods.
This paper presents new estimates of the score function and its gradient with respect to the model parameters in a general energy-based latent variable model (EBLVM). The score function and its gradient can be expressed as combinations of expectation and covariance terms over the (generally intractable) posterior of the latent variables. New estimates are obtained by introducing a variational posterior to approximate the true posterior in these terms. The variational posterior is trained to minimize a certain divergence (e.g., the KL divergence) between itself and the true posterior. Theoretically, the divergence characterizes upper bounds of the bias of the estimates. In principle, our estimates can be applied to a wide range of objectives, including kernelized Stein discrepancy (KSD), score matching (SM)-based methods and exact Fisher divergence with a minimal model assumption. In particular, these estimates applied to SM-based methods outperform existing methods in learning EBLVMs on several image datasets.

Videos of actions are complex signals containing rich compositional structure in space and time. Current video generation methods lack the ability to condition the generation on multiple coordinated and potentially simultaneous timed actions. To address this challenge, we propose to represent the actions in a graph structure called Action Graph and present the new "Action Graph To Video" synthesis task. Our generative model for this task (AG2Vid) disentangles motion and appearance features, and by incorporating a scheduling mechanism for actions facilitates a timely and coordinated video generation. We train and evaluate AG2Vid on CATER and Something-Something V2 datasets, which results in videos that have better visual quality and semantic consistency compared to baselines. Finally, our model demonstrates zero-shot abilities by synthesizing novel compositions of the learned actions.

Modeling the time-series of high-dimensional, longitudinal data is important for predicting patient disease progression. However, existing neural network based approaches that learn representations of patient state, while very flexible, are susceptible to overfitting. We propose a deep generative model that makes use of a novel attention-based neural architecture inspired by the physics of how treatments affect disease state. The result is a scalable and accurate model of high-dimensional patient biomarkers as they vary over time. Our proposed model yields significant improvements in generalization and, on real-world clinical data, provides interpretable insights into the dynamics of cancer progression.

We consider the problem of minimizing the sum of three functions, one of which is nonconvex but differentiable, and the other two are convex but possibly nondifferentiable. We investigate the Three Operator Splitting method (TOS) of Davis & Yin (2017) with an aim to extend its theoretical guarantees for this nonconvex problem template. In particular, we prove convergence of TOS with nonasymptotic bounds on its nonstationarity and infeasibility errors. In contrast with the existing work on nonconvex TOS, our guarantees do not require additional smoothness assumptions on the terms comprising the objective; hence they cover instances of particular interest where the nondifferentiable terms are indicator functions. We also extend our results to a stochastic setting where we have access only to an unbiased estimator of the gradient. Finally, we illustrate the effectiveness of the proposed method through numerical experiments on quadratic assignment problems.
Invited Talk: Xiao Cunde · Qin Dahe
Cryospheric Science and Emergence of Machine Learning
Cryosphere is the layer in a negative temperature state on earth, with continuous distribution and certain thickness. The earth's cryosphere can be divided into three types as continental, marine, and aerial cryosphere, which includes glacier/ice sheet, permafrost, snow cover, lake and river ice, sea ice, ice shelf, iceberg, and solid precipitation, etc. The cryosphere is one of the five major spheres of the climate system. It plays an important role in the earth system with its huge fresh water reserves, latent heat of phase transitions, carbon storage, and unique species habitats and cultural forms.
The presentation starts with an introduction of IPCC main conclusions on human induced climate change and its extremes since the Industrial Involution, especially recent decades. Cryosphere is a sensitive indicator of climate change. The impacts of rapid cryospheric changes have received increasing concerns since 21st century under the background of global warming, extending the research to the interactions between earth’s multi-spheres, including anthroposphere. As a result, cryospheric science has been rapidly developed into a new interdisciplinary, covering its formation, change processes and mechanism, its interactions with and among atmosphere/hydrosphere/biosphere/lithosphere, the influences and adaptations of cryosphere change impacts, the changing functions for serving regional and global economy and society. Cryospheric science is an inevitable scope of international research on the earth and environmental changes, as well as on human sustainable development.
The study on Chinese cryosphere has been developing rapidly following the scope of Cryospheric Science in the past 20 years, especially in the last decade. It has presented systematic achievements in terms of changes in the cryosphere and their impacts on ecology, hydrology, climate, environment, society and economy, and also obtain systematic understanding of the connotation and extension of the Cryospheric Science, made important contributions to the establishment and development of research framework and disciplinary system of the cryospheric science.
The presentation will also show some case studies on cryosphere using machine learning, such as data mining, permafrost mapping and soil organic carbon estimation, Arctic sea ice prediction, outlet glacier instability estimation of ice sheet, as well as paleoclimatic proxy reconstructions. Machine learning is a promising tool for studying both natural aspects and the socioeconomic aspects when studying cryospheric impacts such as services and hazards. There are complex linkages between cryospheric impacts and UN 2030s’ Sustainable Development Goals (SDGs) over the cryospheric influential regions, it is promising to use big data and machine learning to deepen our knowledge.
Key words: IPCC, cryospheric science, sustainable development, machine learning
Bio s:
Poster Session 2 Wed 21 Jul 06:00 a.m.
[ Virtual ]
Scalable training of large models (like BERT and GPT-3) requires careful optimization rooted in model design, architecture, and system capabilities. From a system standpoint, communication has become a major bottleneck, especially on commodity systems with standard TCP interconnects that offer limited network bandwidth. Communication compression is an important technique to reduce training time on such systems. One of the most effective ways to compress communication is via error compensation compression, which offers robust convergence speed, even under 1-bit compression. However, state-of-the-art error compensation techniques only work with basic optimizers like SGD and momentum SGD, which are linearly dependent on the gradients. They do not work with non-linear gradient-based optimizers like Adam, which offer state-of-the-art convergence efficiency and accuracy for models like BERT. In this paper, we propose 1-bit Adam that reduces the communication volume by up to 5x, offers much better scalability, and provides the same convergence speed as uncompressed Adam. Our key finding is that Adam's variance becomes stable (after a warmup phase) and can be used as a fixed precondition for the rest of the training (compression phase). We performed experiments on up to 256 GPUs and show that 1-bit Adam enables up to 3.3x higher throughput for …
[ Virtual ]
We consider the problem of learning useful robotic skills from previously collected offline data without access to manually specified rewards or additional online exploration, a setting that is becoming increasingly important for scaling robot learning by reusing past robotic data. In particular, we propose the objective of learning a functional understanding of the environment by learning to reach any goal state in a given dataset. We employ goal-conditioned Q-learning with hindsight relabeling and develop several techniques that enable training in a particularly challenging offline setting. We find that our method can operate on high-dimensional camera images and learn a variety of skills on real robots that generalize to previously unseen scenes and objects. We also show that our method can learn to reach long-horizon goals across multiple episodes through goal chaining, and learn rich representations that can help with downstream tasks through pre-training or auxiliary objectives.
[ Virtual ]
The increasing size of neural network models has been critical for improvements in their accuracy, but device memory is not growing at the same rate. This creates fundamental challenges for training neural networks within limited memory environments. In this work, we propose ActNN, a memory-efficient training framework that stores randomly quantized activations for back propagation. We prove the convergence of ActNN for general network architectures, and we characterize the impact of quantization on the convergence via an exact expression for the gradient variance. Using our theory, we propose novel mixed-precision quantization strategies that exploit the activation's heterogeneity across feature dimensions, samples, and layers. These techniques can be readily applied to existing dynamic graph frameworks, such as PyTorch, simply by substituting the layers. We evaluate ActNN on mainstream computer vision models for classification, detection, and segmentation tasks. On all these tasks, ActNN compresses the activation to 2 bits on average, with negligible accuracy loss. ActNN reduces the memory footprint of the activation by 12x, and it enables training with a 6.6x to 14x larger batch size.
[ Virtual ]
Weight-sharing neural architecture search (NAS) is an effective technique for automating efficient neural architecture design. Weight-sharing NAS builds a supernet that assembles all the architectures as its sub-networks and jointly trains the supernet with the sub-networks. The success of weight-sharing NAS heavily relies on distilling the knowledge of the supernet to the sub-networks. However, we find that the widely used distillation divergence, i.e., KL divergence, may lead to student sub-networks that over-estimate or under-estimate the uncertainty of the teacher supernet, leading to inferior performance of the sub-networks. In this work, we propose to improve the supernet training with a more generalized alpha-divergence. By adaptively selecting the alpha-divergence, we simultaneously prevent the over-estimation or under-estimation of the uncertainty of the teacher model. We apply the proposed alpha-divergence based supernets training to both slimmable neural networks and weight-sharing NAS, and demonstrate significant improvements. Specifically, our discovered model family, AlphaNet, outperforms prior-art models on a wide range of FLOPs regimes, including BigNAS, Once-for-All networks, and AttentiveNAS. We achieve ImageNet top-1 accuracy of 80.0% with only 444M FLOPs. Our code and pretrained models are available at https://github.com/facebookresearch/AlphaNet.
[ Virtual ]
[ Virtual ]
Reinforcement learning from large-scale offline datasets provides us with the ability to learn policies without potentially unsafe or impractical exploration. Significant progress has been made in the past few years in dealing with the challenge of correcting for differing behavior between the data collection and learned policies. However, little attention has been paid to potentially changing dynamics when transferring a policy to the online setting, where performance can be up to 90% reduced for existing methods. In this paper we address this problem with Augmented World Models (AugWM). We augment a learned dynamics model with simple transformations that seek to capture potential changes in physical properties of the robot, leading to more robust policies. We not only train our policy in this new setting, but also provide it with the sampled augmentation as a context, allowing it to adapt to changes in the environment. At test time we learn the context in a self-supervised fashion by approximating the augmentation which corresponds to the new environment. We rigorously evaluate our approach on over 100 different changed dynamics settings, and show that this simple approach can significantly improve the zero-shot generalization of a recent state-of-the-art baseline, often achieving successful policies where the …
[ Virtual ]
Multi-modal distributions are commonly used to model clustered data in statistical learning tasks. In this paper, we consider the Mixed Linear Regression (MLR) problem. We propose an optimal transport-based framework for MLR problems, Wasserstein Mixed Linear Regression (WMLR), which minimizes the Wasserstein distance between the learned and target mixture regression models. Through a model-based duality analysis, WMLR reduces the underlying MLR task to a nonconvex-concave minimax optimization problem, which can be provably solved to find a minimax stationary point by the Gradient Descent Ascent (GDA) algorithm. In the special case of mixtures of two linear regression models, we show that WMLR enjoys global convergence and generalization guarantees. We prove that WMLR’s sample complexity grows linearly with the dimension of data. Finally, we discuss the application of WMLR to the federated learning task where the training samples are collected by multiple agents in a network. Unlike the Expectation-Maximization algorithm, WMLR directly extends to the distributed, federated learning setting. We support our theoretical results through several numerical experiments, which highlight our framework’s ability to handle the federated learning setting with mixture models.
[ Virtual ]
Distributed learning has become a hot research topic due to its wide application in cluster-based large-scale learning, federated learning, edge computing and so on. Most traditional distributed learning methods typically assume no failure or attack. However, many unexpected cases, such as communication failure and even malicious attack, may happen in real applications. Hence, Byzantine learning (BL), which refers to distributed learning with failure or attack, has recently attracted much attention. Most existing BL methods are synchronous, which are impractical in some applications due to heterogeneous or offline workers. In these cases, asynchronous BL (ABL) is usually preferred. In this paper, we propose a novel method, called buffered asynchronous stochastic gradient descent (BASGD), for ABL. To the best of our knowledge, BASGD is the first ABL method that can resist malicious attack without storing any instances on server. Compared with those methods which need to store instances on server, BASGD has a wider scope of application. BASGD is proved to be convergent, and be able to resist failure or attack. Empirical results show that BASGD significantly outperforms vanilla asynchronous stochastic gradient descent (ASGD) and other ABL baselines when there exists failure or attack on workers.
[ Virtual ]
Recent works (White et al., 2020a; Yan et al., 2020) demonstrate the importance of architecture encodings in Neural Architecture Search (NAS). These encodings encode either structure or computation information of the neural architectures. Compared to structure-aware encodings, computation-aware encodings map architectures with similar accuracies to the same region, which improves the downstream architecture search performance (Zhang et al., 2019; White et al., 2020a). In this work, we introduce a Computation-Aware Transformer-based Encoding method called CATE. Different from existing computation-aware encodings based on fixed transformation (e.g. path encoding), CATE employs a pairwise pre-training scheme to learn computation-aware encodings using Transformers with cross-attention. Such learned encodings contain dense and contextualized computation information of neural architectures. We compare CATE with eleven encodings under three major encoding-dependent NAS subroutines in both small and large search spaces. Our experiments show that CATE is beneficial to the downstream search, especially in the large search space. Moreover, the outside search space experiment demonstrates its superior generalization ability beyond the search space on which it was trained. Our code is available at: https://github.com/MSU-MLSys-Lab/CATE.
[ Virtual ]
Humans are accustomed to environments that contain both regularities and exceptions. For example, at most gas stations, one pays prior to pumping, but the occasional rural station does not accept payment in advance. Likewise, deep neural networks can generalize across instances that share common patterns or structures, yet have the capacity to memorize rare or irregular forms. We analyze how individual instances are treated by a model via a consistency score. The score characterizes the expected accuracy for a held-out instance given training sets of varying size sampled from the data distribution. We obtain empirical estimates of this score for individual instances in multiple data sets, and we show that the score identifies out-of-distribution and mislabeled examples at one end of the continuum and strongly regular examples at the other end. We identify computationally inexpensive proxies to the consistency score using statistics collected during training. We apply the score toward understanding the dynamics of representation learning and to filter outliers during training.
[ Virtual ]
Bridging logical and algorithmic reasoning with modern machine learning techniques is a fundamental challenge with potentially transformative impact. On the algorithmic side, many NP-hard problems can be expressed as integer programs, in which the constraints play the role of their 'combinatorial specification'. In this work, we aim to integrate integer programming solvers into neural network architectures as layers capable of learning both the cost terms and the constraints. The resulting end-to-end trainable architectures jointly extract features from raw data and solve a suitable (learned) combinatorial problem with state-of-the-art integer programming solvers. We demonstrate the potential of such layers with an extensive performance analysis on synthetic data and with a demonstration on a competitive computer vision keypoint matching benchmark.
[ Virtual ]
Exploration is critical for good results in deep reinforcement learning and has attracted much attention. However, existing multi-agent deep reinforcement learning algorithms still use mostly noise-based techniques. Very recently, exploration methods that consider cooperation among multiple agents have been developed. However, existing methods suffer from a common challenge: agents struggle to identify states that are worth exploring, and hardly coordinate exploration efforts toward those states. To address this shortcoming, in this paper, we propose cooperative multi-agent exploration (CMAE): agents share a common goal while exploring. The goal is selected from multiple projected state spaces by a normalized entropy-based technique. Then, agents are trained to reach the goal in a coordinated manner. We demonstrate that CMAE consistently outperforms baselines on various tasks, including a sparse-reward version of multiple-particle environment (MPE) and the Starcraft multi-agent challenge (SMAC).
[ Virtual ]
Deep neural networks have emerged as very successful tools for image restoration and reconstruction tasks. These networks are often trained end-to-end to directly reconstruct an image from a noisy or corrupted measurement of that image. To achieve state-of-the-art performance, training on large and diverse sets of images is considered critical. However, it is often difficult and/or expensive to collect large amounts of training images. Inspired by the success of Data Augmentation (DA) for classification problems, in this paper, we propose a pipeline for data augmentation for accelerated MRI reconstruction and study its effectiveness at reducing the required training data in a variety of settings. Our DA pipeline, MRAugment, is specifically designed to utilize the invariances present in medical imaging measurements as naive DA strategies that neglect the physics of the problem fail. Through extensive studies on multiple datasets we demonstrate that in the low-data regime DA prevents overfitting and can match or even surpass the state of the art while using significantly fewer training data, whereas in the high-data regime it has diminishing returns. Furthermore, our findings show that DA improves the robustness of the model against various shifts in the test distribution.
[ Virtual ]
Conventional image classifiers are trained by randomly sampling mini-batches of images. To achieve state-of-the-art performance, practitioners use sophisticated data augmentation schemes to expand the amount of training data available for sampling. In contrast, meta-learning algorithms sample support data, query data, and tasks on each training step. In this complex sampling scenario, data augmentation can be used not only to expand the number of images available per class, but also to generate entirely new classes/tasks. We systematically dissect the meta-learning pipeline and investigate the distinct ways in which data augmentation can be integrated at both the image and class levels. Our proposed meta-specific data augmentation significantly improves the performance of meta-learners on few-shot classification benchmarks.
[ Virtual ]
In fully cooperative multi-agent reinforcement learning (MARL) settings, the environments are highly stochastic due to the partial observability of each agent and the continuously changing policies of the other agents. To address the above issues, we integrate distributional RL and value function factorization methods by proposing a Distributional Value Function Factorization (DFAC) framework to generalize expected value function factorization methods to their distributional variants. DFAC extends the individual utility functions from deterministic variables to random variables, and models the quantile function of the total return as a quantile mixture. To validate DFAC, we demonstrate DFAC's ability to factorize a simple two-step matrix game with stochastic rewards and perform experiments on all Super Hard tasks of StarCraft Multi-Agent Challenge, showing that DFAC is able to outperform expected value function factorization baselines.
[ Virtual ]
Sorting and ranking supervision is a method for training neural networks end-to-end based on ordering constraints. That is, the ground truth order of sets of samples is known, while their absolute values remain unsupervised. For that, we propose differentiable sorting networks by relaxing their pairwise conditional swap operations. To address the problems of vanishing gradients and extensive blurring that arise with larger numbers of layers, we propose mapping activations to regions with moderate gradients. We consider odd-even as well as bitonic sorting networks, which outperform existing relaxations of the sorting operation. We show that bitonic sorting networks can achieve stable training on large input sets of up to 1024 elements.
[ Virtual ]
We consider the problem of spatial path planning. In contrast to the classical solutions which optimize a new plan from scratch and assume access to the full map with ground truth obstacle locations, we learn a planner from the data in a differentiable manner that allows us to leverage statistical regularities from past data. We propose Spatial Planning Transformers (SPT), which given an obstacle map learns to generate actions by planning over long-range spatial dependencies, unlike prior data-driven planners that propagate information locally via convolutional structure in an iterative manner. In the setting where the ground truth map is not known to the agent, we leverage pre-trained SPTs in an end-to-end framework that has the structure of mapper and planner built into it which allows seamless generalization to out-of-distribution maps and goals. SPTs outperform prior state-of-the-art differentiable planners across all the setups for both manipulation and navigation tasks, leading to an absolute improvement of 7-19\%.
[ Virtual ]
Games are abstractions of the real world, where artificial agents learn to compete and cooperate with other agents. While significant achievements have been made in various perfect- and imperfect-information games, DouDizhu (a.k.a. Fighting the Landlord), a three-player card game, is still unsolved. DouDizhu is a very challenging domain with competition, collaboration, imperfect information, large state space, and particularly a massive set of possible actions where the legal actions vary significantly from turn to turn. Unfortunately, modern reinforcement learning algorithms mainly focus on simple and small action spaces, and not surprisingly, are shown not to make satisfactory progress in DouDizhu. In this work, we propose a conceptually simple yet effective DouDizhu AI system, namely DouZero, which enhances traditional Monte-Carlo methods with deep neural networks, action encoding, and parallel actors. Starting from scratch in a single server with four GPUs, DouZero outperformed all the existing DouDizhu AI programs in days of training and was ranked the first in the Botzone leaderboard among 344 AI agents. Through building DouZero, we show that classic Monte-Carlo methods can be made to deliver strong results in a hard domain with a complex action space. The code and an online demo are released at https://github.com/kwai/DouZero with the …
[ Virtual ]
Message passing neural networks have become a method of choice for learning on graphs, in particular the prediction of chemical properties and the acceleration of molecular dynamics studies. While they readily scale to large training data sets, previous approaches have proven to be less data efficient than kernel methods. We identify limitations of invariant representations as a major reason and extend the message passing formulation to rotationally equivariant representations. On this basis, we propose the polarizable atom interaction neural network (PaiNN) and improve on common molecule benchmarks over previous networks, while reducing model size and inference time. We leverage the equivariant atomwise representations obtained by PaiNN for the prediction of tensorial properties. Finally, we apply this to the simulation of molecular spectra, achieving speedups of 4-5 orders of magnitude compared to the electronic structure reference.
[ Virtual ]
We study the problem of minimizing a relatively-smooth convex function using stochastic Bregman gradient methods. We first prove the convergence of Bregman Stochastic Gradient Descent (BSGD) to a region that depends on the noise (magnitude of the gradients) at the optimum. In particular, BSGD quickly converges to the exact minimizer when this noise is zero (interpolation setting, in which the data is fit perfectly). Otherwise, when the objective has a finite sum structure, we show that variance reduction can be used to counter the effect of noise. In particular, fast convergence to the exact minimizer can be obtained under additional regularity assumptions on the Bregman reference function. We illustrate the effectiveness of our approach on two key applications of relative smoothness: tomographic reconstruction with Poisson noise and statistical preconditioning for distributed optimization.
[ Virtual ]
Federated Learning (FL) is a distributed learning paradigm that scales on-device learning collaboratively and privately. Standard FL algorithms such as FᴇᴅAᴠɢ are primarily geared towards smooth unconstrained settings. In this paper, we study the Federated Composite Optimization (FCO) problem, in which the loss function contains a non-smooth regularizer. Such problems arise naturally in FL applications that involve sparsity, low-rank, monotonicity, or more general constraints. We first show that straightforward extensions of primal algorithms such as FedAvg are not well-suited for FCO since they suffer from the "curse of primal averaging," resulting in poor convergence. As a solution, we propose a new primal-dual algorithm, Federated Dual Averaging (FedDualAvg), which by employing a novel server dual averaging procedure circumvents the curse of primal averaging. Our theoretical analysis and empirical experiments demonstrate that FedDualAvg outperforms the other baselines.
[ Virtual ]
Norm emergence is a process where agents in a multi-agent system establish self-enforcing conformity through repeated interactions. When such interactions are confined to a social topology, several self-reinforcing substructures (SRS) may emerge within the population. This prevents a formation of a global norm. We propose incremental social instruments (ISI) to dissolve these SRSs by creating ties between agents. Establishing ties requires some effort and cost. Hence, it is worth to design methods that build a small number of ties yet dissolve the SRSs. By using the notion of information entropy, we propose an indicator called the BA-ratio that measures the current SRSs. We find that by building ties with minimal BA-ratio, our ISI is effective in facilitating the global norm emergence. We explain this through our experiments and theoretical results. Furthermore, we propose the small-degree principle in minimising the BA-ratio that helps us to design efficient ISI algorithms for finding the optimal ties. Experiments on both synthetic and real-world network topologies demonstrate that our adaptive ISI is efficient at dissolving SRS.
[ Virtual ]
In this paper we investigate the Follow the Regularized Leader dynamics in sequential imperfect information games (IIG). We generalize existing results of Poincaré recurrence from normal-form games to zero-sum two-player imperfect information games and other sequential game settings. We then investigate how adapting the reward (by adding a regularization term) of the game can give strong convergence guarantees in monotone games. We continue by showing how this reward adaptation technique can be leveraged to build algorithms that converge exactly to the Nash equilibrium. Finally, we show how these insights can be directly used to build state-of-the-art model-free algorithms for zero-sum two-player Imperfect Information Games (IIG).
[ Virtual ]
Episodic memory-based methods can rapidly latch onto past successful strategies by a non-parametric memory and improve sample efficiency of traditional reinforcement learning. However, little effort is put into the continuous domain, where a state is never visited twice, and previous episodic methods fail to efficiently aggregate experience across trajectories. To address this problem, we propose Generalizable Episodic Memory (GEM), which effectively organizes the state-action values of episodic memory in a generalizable manner and supports implicit planning on memorized trajectories. GEM utilizes a double estimator to reduce the overestimation bias induced by value propagation in the planning process. Empirical evaluation shows that our method significantly outperforms existing trajectory-based methods on various MuJoCo continuous control tasks. To further show the general applicability, we evaluate our method on Atari games with discrete action space, which also shows a significant improvement over baseline algorithms.
[ Virtual ]
The high dimensionality of images presents architecture and sampling-efficiency challenges for likelihood-based generative models. Previous approaches such as VQ-VAE use deep autoencoders to obtain compact representations, which are more practical as inputs for likelihood-based models. We present an alternative approach, inspired by common image compression methods like JPEG, and convert images to quantized discrete cosine transform (DCT) blocks, which are represented sparsely as a sequence of DCT channel, spatial location, and DCT coefficient triples. We propose a Transformer-based autoregressive architecture, which is trained to sequentially predict the conditional distribution of the next element in such sequences, and which scales effectively to high resolution images. On a range of image datasets, we demonstrate that our approach can generate high quality, diverse images, with sample metric scores competitive with state of the art methods. We additionally show that simple modifications to our method yield effective image colorization and super-resolution models.
[ Virtual ]
In this paper, we devise a distributional framework on actor-critic as a solution to distributional instability, action type restriction, and conflation between samples and statistics. We propose a new method that minimizes the Cramér distance with the multi-step Bellman target distribution generated from a novel Sample-Replacement algorithm denoted SR(\lambda), which learns the correct value distribution under multiple Bellman operations. Parameterizing a value distribution with Gaussian Mixture Model further improves the efficiency and the performance of the method, which we name GMAC. We empirically show that GMAC captures the correct representation of value distributions and improves the performance of a conventional actor-critic method with low computational cost, in both discrete and continuous action spaces using Arcade Learning Environment (ALE) and PyBullet environment.
[ Virtual ]
Normalization is known to help the optimization of deep neural networks. Curiously, different architectures require specialized normalization methods. In this paper, we study what normalization is effective for Graph Neural Networks (GNNs). First, we adapt and evaluate the existing methods from other domains to GNNs. Faster convergence is achieved with InstanceNorm compared to BatchNorm and LayerNorm. We provide an explanation by showing that InstanceNorm serves as a preconditioner for GNNs, but such preconditioning effect is weaker with BatchNorm due to the heavy batch noise in graph datasets. Second, we show that the shift operation in InstanceNorm results in an expressiveness degradation of GNNs for highly regular graphs. We address this issue by proposing GraphNorm with a learnable shift. Empirically, GNNs with GraphNorm converge faster compared to GNNs using other normalization. GraphNorm also improves the generalization of GNNs, achieving better performance on graph classification benchmarks.
[ Virtual ]
[ Virtual ]
The predominant measure for the performance of an algorithm is its worst-case approximation guarantee. While worst-case approximations give desirable robustness guarantees, they can differ significantly from the performance of an algorithm in practice. For the problem of monotone submodular maximization under a cardinality constraint, the greedy algorithm is known to obtain a 1-1/e approximation guarantee, which is optimal for a polynomial-time algorithm. However, very little is known about the approximation achieved by greedy and other submodular maximization algorithms on real instances.
We develop an algorithm that gives an instance-specific approximation for any solution of an instance of monotone submodular maximization under a cardinality constraint. This algorithm uses a novel dual approach to submodular maximization. In particular, it relies on the construction of a lower bound to the dual objective that can also be exactly minimized. We use this algorithm to show that on a wide variety of real-world datasets and objectives, greedy and other algorithms find solutions that approximate the optimal solution significantly better than the 1-1/e ~ 0.63 worst-case approximation guarantee, often exceeding 0.9.
[ Virtual ]
We study offline reinforcement learning (RL), which aims to learn an optimal policy based on a dataset collected a priori. Due to the lack of further interactions with the environment, offline RL suffers from the insufficient coverage of the dataset, which eludes most existing theoretical analysis. In this paper, we propose a pessimistic variant of the value iteration algorithm (PEVI), which incorporates an uncertainty quantifier as the penalty function. Such a penalty function simply flips the sign of the bonus function for promoting exploration in online RL, which makes it easily implementable and compatible with general function approximators.
Without assuming the sufficient coverage of the dataset, we establish a data-dependent upper bound on the suboptimality of PEVI for general Markov decision processes (MDPs). When specialized to linear MDPs, it matches the information-theoretic lower bound up to multiplicative factors of the dimension and horizon. In other words, pessimism is not only provably efficient but also minimax optimal. In particular, given the dataset, the learned policy serves as the best effort'' among all policies, as no other policies can do better. Our theoretical analysis identifies the critical role of pessimism in eliminating a notion of spurious correlation, which emerges from theirrelevant'' …
[ Virtual ]
Standard training via empirical risk minimization (ERM) can produce models that achieve low error on average but high error on minority groups, especially in the presence of spurious correlations between the input and label. Prior approaches to this problem, like group distributionally robust optimization (group DRO), generally require group annotations for every training point. On the other hand, approaches that do not use group annotations generally do not improve minority performance. For example, we find that joint DRO, which dynamically upweights examples with high training loss, tends to optimize for examples that are irrelevant to the specific groups we seek to do well on. In this paper, we propose a simple two-stage approach, JTT, that achieves comparable performance to group DRO while only requiring group annotations on a significantly smaller validation set. JTT first attempts to identify informative training examples, which are often minority examples, by training an initial ERM classifier and selecting the examples with high training loss. Then, it trains a final classifier by upsampling the selected examples. Crucially, unlike joint DRO, JTT does not iteratively upsample examples that have high loss under the final classifier. On four image classification and natural language processing tasks with spurious correlations, …
[ Virtual ]
Face recognition is an important yet challenging problem in computer vision. A major challenge in practical face recognition applications lies in significant variations between profile and frontal faces. Traditional techniques address this challenge either by synthesizing frontal faces or by pose invariant learning. In this paper, we propose a novel method with Lie algebra theory to explore how face rotation in the 3D space affects the deep feature generation process of convolutional neural networks (CNNs). We prove that face rotation in the image space is equivalent to an additive residual component in the feature space of CNNs, which is determined solely by the rotation. Based on this theoretical finding, we further design a Lie Algebraic Residual Network (LARNet) for tackling pose robust face recognition. Our LARNet consists of a residual subnet for decoding rotation information from input face images, and a gating subnet to learn rotation magnitude for controlling the strength of the residual component contributing to the feature learning process. Comprehensive experimental evaluations on both frontal-profile face datasets and general face recognition datasets convincingly demonstrate that our method consistently outperforms the state-of-the-art ones.
[ Virtual ]
We introduce learning and planning algorithms for average-reward MDPs, including 1) the first general proven-convergent off-policy model-free control algorithm without reference states, 2) the first proven-convergent off-policy model-free prediction algorithm, and 3) the first off-policy learning algorithm that converges to the actual value function rather than to the value function plus an offset. All of our algorithms are based on using the temporal-difference error rather than the conventional error when updating the estimate of the average reward. Our proof techniques are a slight generalization of those by Abounadi, Bertsekas, and Borkar (2001). In experiments with an Access-Control Queuing Task, we show some of the difficulties that can arise when using methods that rely on reference states and argue that our new algorithms are significantly easier to use.
[ Virtual ]
We consider the problem of learning fair policies in (deep) cooperative multi-agent reinforcement learning (MARL). We formalize it in a principled way as the problem of optimizing a welfare function that explicitly encodes two important aspects of fairness: efficiency and equity. We provide a theoretical analysis of the convergence of policy gradient for this problem. As a solution method, we propose a novel neural network architecture, which is composed of two sub-networks specifically designed for taking into account these two aspects of fairness. In experiments, we demonstrate the importance of the two sub-networks for fair optimization. Our overall approach is general as it can accommodate any (sub)differentiable welfare function. Therefore, it is compatible with various notions of fairness that have been proposed in the literature (e.g., lexicographic maximin, generalized Gini social welfare function, proportional fairness). Our method is generic and can be implemented in various MARL settings: centralized training and decentralized execution, or fully decentralized. Finally, we experimentally validate our approach in various domains and show that it can perform much better than previous methods, both in terms of efficiency and equity.
[ Virtual ]
Attention based neural networks are state of the art in a large range of applications. However, their performance tends to degrade when the number of layers increases. In this work, we show that enforcing Lipschitz continuity by normalizing the attention scores can significantly improve the performance of deep attention models. First, we show that, for deep graph attention networks (GAT), gradient explosion appears during training, leading to poor performance of gradient-based training algorithms. To address this issue, we derive a theoretical analysis of the Lipschitz continuity of attention modules and introduce LipschitzNorm, a simple and parameter-free normalization for self-attention mechanisms that enforces the model to be Lipschitz continuous. We then apply LipschitzNorm to GAT and Graph Transformers and show that their performance is substantially improved in the deep setting (10 to 30 layers). More specifically, we show that a deep GAT model with LipschitzNorm achieves state of the art results for node label prediction tasks that exhibit long-range dependencies, while showing consistent improvements over their unnormalized counterparts in benchmark node classification tasks.
[ Virtual ]
[ Virtual ]
Exploration in reinforcement learning is, in general, a challenging problem. A common technique to make learning easier is providing demonstrations from a human supervisor, but such demonstrations can be expensive and time-consuming to acquire. In this work, we study a more tractable class of reinforcement learning problems defined simply by examples of successful outcome states, which can be much easier to provide while still making the exploration problem more tractable. In this problem setting, the reward function can be obtained automatically by training a classifier to categorize states as successful or not. However, as we will show, this requires the classifier to make uncertainty-aware predictions that are very difficult using standard techniques for training deep networks. To address this, we propose a novel mechanism for obtaining calibrated uncertainty based on an amortized technique for computing the normalized maximum likelihood (NML) distribution, leveraging tools from meta-learning to make this distribution tractable. We show that the resulting algorithm has a number of intriguing connections to both count-based exploration methods and prior algorithms for learning reward functions, while also providing more effective guidance towards the goal. We demonstrate that our algorithm solves a number of challenging navigation and robotic manipulation tasks which prove …
[ Virtual ]
[ Virtual ]
Despite the accomplishments of Generative Adversarial Networks (GANs) in modeling data distributions, training them remains a challenging task. A contributing factor to this difficulty is the non-intuitive nature of the GAN loss curves, which necessitates a subjective evaluation of the generated output to infer training progress. Recently, motivated by game theory, Duality Gap has been proposed as a domain agnostic measure to monitor GAN training. However, it is restricted to the setting when the GAN converges to a Nash equilibrium. But GANs need not always converge to a Nash equilibrium to model the data distribution. In this work, we extend the notion of duality gap to proximal duality gap that is applicable to the general context of training GANs where Nash equilibria may not exist. We show theoretically that the proximal duality gap can monitor the convergence of GANs to a broader spectrum of equilibria that subsumes Nash equilibria. We also theoretically establish the relationship between the proximal duality gap and the divergence between the real and generated data distributions for different GAN formulations. Our results provide new insights into the nature of GAN convergence. Finally, we validate experimentally the usefulness of proximal duality gap for monitoring and influencing GAN …
[ Virtual ]
[ Virtual ]
We consider the offline reinforcement learning (RL) setting where the agent aims to optimize the policy solely from the data without further environment interactions. In offline RL, the distributional shift becomes the primary source of difficulty, which arises from the deviation of the target policy being optimized from the behavior policy used for data collection. This typically causes overestimation of action values, which poses severe problems for model-free algorithms that use bootstrapping. To mitigate the problem, prior offline RL algorithms often used sophisticated techniques that encourage underestimation of action values, which introduces an additional set of hyperparameters that need to be tuned properly. In this paper, we present an offline RL algorithm that prevents overestimation in a more principled way. Our algorithm, OptiDICE, directly estimates the stationary distribution corrections of the optimal policy and does not rely on policy-gradients, unlike previous offline RL algorithms. Using an extensive set of benchmark datasets for offline RL, we show that OptiDICE performs competitively with the state-of-the-art methods.
[ Virtual ]
[ Virtual ]
Graph Neural Networks (GNNs) have been studied through the lens of expressive power and generalization. However, their optimization properties are less well understood. We take the first step towards analyzing GNN training by studying the gradient dynamics of GNNs. First, we analyze linearized GNNs and prove that despite the non-convexity of training, convergence to a global minimum at a linear rate is guaranteed under mild assumptions that we validate on real-world graphs. Second, we study what may affect the GNNs' training speed. Our results show that the training of GNNs is implicitly accelerated by skip connections, more depth, and/or a good label distribution. Empirical results confirm that our theoretical results for linearized GNNs align with the training behavior of nonlinear GNNs. Our results provide the first theoretical support for the success of GNNs with skip connections in terms of optimization, and suggest that deep GNNs with skip connections would be promising in practice.
[ Virtual ]
Modeling dependencies among features is fundamental for many machine learning tasks. Although there are often multiple related instances that may be leveraged to inform conditional dependencies, typical approaches only model conditional dependencies over individual instances. In this work, we propose a novel framework, partially observed exchangeable modeling (POEx) that takes in a set of related partially observed instances and infers the conditional distribution for the unobserved dimensions over multiple elements. Our approach jointly models the intra-instance (among features in a point) and inter-instance (among multiple points in a set) dependencies in data. POEx is a general framework that encompasses many existing tasks such as point cloud expansion and few-shot generation, as well as new tasks like few-shot imputation. Despite its generality, extensive empirical evaluations show that our model achieves state-of-the-art performance across a range of applications.
[ Virtual ]
In this paper, we introduce a two-level attention schema, Poolingformer, for long document modeling. Its first level uses a smaller sliding window pattern to aggregate information from neighbors. Its second level employs a larger window to increase receptive fields with pooling attention to reduce both computational cost and memory consumption. We first evaluate Poolingformer on two long sequence QA tasks: the monolingual NQ and the multilingual TyDi QA. Experimental results show that Poolingformer sits atop three official leaderboards measured by F1, outperforming previous state-of-the-art models by 1.9 points (79.8 vs. 77.9) on NQ long answer, 1.9 points (79.5 vs. 77.6) on TyDi QA passage answer, and 1.6 points (67.6 vs. 66.0) on TyDi QA minimal answer. We further evaluate Poolingformer on a long sequence summarization task. Experimental results on the arXiv benchmark continue to demonstrate its superior performance.
[ Virtual ]
Environments with procedurally generated content serve as important benchmarks for testing systematic generalization in deep reinforcement learning. In this setting, each level is an algorithmically created environment instance with a unique configuration of its factors of variation. Training on a prespecified subset of levels allows for testing generalization to unseen levels. What can be learned from a level depends on the current policy, yet prior work defaults to uniform sampling of training levels independently of the policy. We introduce Prioritized Level Replay (PLR), a general framework for selectively sampling the next training level by prioritizing those with higher estimated learning potential when revisited in the future. We show TD-errors effectively estimate a level's future learning potential and, when used to guide the sampling procedure, induce an emergent curriculum of increasingly difficult levels. By adapting the sampling of training levels, PLR significantly improves sample-efficiency and generalization on Procgen Benchmark—matching the previous state-of-the-art in test return—and readily combines with other methods. Combined with the previous leading method, PLR raises the state-of-the-art to over 76% improvement in test return relative to standard RL baselines.
[ Virtual ]
[ Virtual ]
Variational autoencoder (VAE) estimates the posterior parameters (mean and variance) of latent variables corresponding to each input data. While it is used for many tasks, the transparency of the model is still an underlying issue. This paper provides a quantitative understanding of VAE property through the differential geometric and information-theoretic interpretations of VAE. According to the Rate-distortion theory, the optimal transform coding is achieved by using an orthonormal transform with PCA basis where the transform space is isometric to the input. Considering the analogy of transform coding to VAE, we clarify theoretically and experimentally that VAE can be mapped to an implicit isometric embedding with a scale factor derived from the posterior parameter. As a result, we can estimate the data probabilities in the input space from the prior, loss metrics, and corresponding posterior parameters, and further, the quantitative importance of each latent variable can be evaluated like the eigenvalue of PCA.
[ Virtual ]
[ Virtual ]
[ Virtual ]
[ Virtual ]
An ambitious goal for machine learning is to create agents that behave ethically: The capacity to abide by human moral norms would greatly expand the context in which autonomous agents could be practically and safely deployed, e.g. fully autonomous vehicles will encounter charged moral decisions that complicate their deployment. While ethical agents could be trained by rewarding correct behavior under a specific moral theory (e.g. utilitarianism), there remains widespread disagreement about the nature of morality. Acknowledging such disagreement, recent work in moral philosophy proposes that ethical behavior requires acting under moral uncertainty, i.e. to take into account when acting that one's credence is split across several plausible ethical theories. This paper translates such insights to the field of reinforcement learning, proposes two training methods that realize different points among competing desiderata, and trains agents in simple environments to act under moral uncertainty. The results illustrate (1) how such uncertainty can help curb extreme behavior from commitment to single theories and (2) several technical complications arising from attempting to ground moral philosophy in RL (e.g. how can a principled trade-off between two competing but incomparable reward functions be reached). The aim is to catalyze progress towards morally-competent agents and highlight the …
[ Virtual ]
The recent success of supervised learning methods on ever larger offline datasets has spurred interest in the reinforcement learning (RL) field to investigate whether the same paradigms can be translated to RL algorithms. This research area, known as offline RL, has largely focused on offline policy optimization, aiming to find a return-maximizing policy exclusively from offline data. In this paper, we consider a slightly different approach to incorporating offline data into sequential decision-making. We aim to answer the question, what unsupervised objectives applied to offline datasets are able to learn state representations which elevate performance on downstream tasks, whether those downstream tasks be online RL, imitation learning from expert demonstrations, or even offline policy optimization based on the same offline dataset? Through a variety of experiments utilizing standard offline RL datasets, we find that the use of pretraining with unsupervised learning objectives can dramatically improve the performance of policy learning algorithms that otherwise yield mediocre performance on their own. Extensive ablations further provide insights into what components of these unsupervised objectives – e.g., reward prediction, continuous or discrete representations, pretraining or finetuning – are most important and in which settings.
[ Virtual ]
We introduce an approach for understanding control policies represented as recurrent neural networks. Recent work has approached this problem by transforming such recurrent policy networks into finite-state machines (FSM) and then analyzing the equivalent minimized FSM. While this led to interesting insights, the minimization process can obscure a deeper understanding of a machine's operation by merging states that are semantically distinct. To address this issue, we introduce an analysis approach that starts with an unminimized FSM and applies more-interpretable reductions that preserve the key decision points of the policy. We also contribute an attention tool to attain a deeper understanding of the role of observations in the decisions. Our case studies on 7 Atari games and 3 control benchmarks demonstrate that the approach can reveal insights that have not been previously noticed.
[ Virtual ]
[ Virtual ]
[ Virtual ]
Least squares estimators, when trained on few target domain samples, may predict poorly. Supervised domain adaptation aims to improve the predictive accuracy by exploiting additional labeled training samples from a source distribution that is close to the target distribution. Given available data, we investigate novel strategies to synthesize a family of least squares estimator experts that are robust with regard to moment conditions. When these moment conditions are specified using Kullback-Leibler or Wasserstein-type divergences, we can find the robust estimators efficiently using convex optimization. We use the Bernstein online aggregation algorithm on the proposed family of robust experts to generate predictions for the sequential stream of target test samples. Numerical experiments on real data show that the robust strategies systematically outperform non-robust interpolations of the empirical least squares estimators.
[ Virtual ]
We propose the k-Shortest-Path (k-SP) constraint: a novel constraint on the agent’s trajectory that improves the sample efficiency in sparse-reward MDPs. We show that any optimal policy necessarily satisfies the k-SP constraint. Notably, the k-SP constraint prevents the policy from exploring state-action pairs along the non-k-SP trajectories (e.g., going back and forth). However, in practice, excluding state-action pairs may hinder the convergence of RL algorithms. To overcome this, we propose a novel cost function that penalizes the policy violating SP constraint, instead of completely excluding it. Our numerical experiment in a tabular RL setting demonstrates that the SP-constraint can significantly reduce the trajectory space of policy. As a result, our constraint enables more sample efficient learning by suppressing redundant exploration and exploitation. Our experiments on MiniGrid, DeepMind Lab, Atari, and Fetch show that the proposed method significantly improves proximal policy optimization (PPO) and outperforms existing novelty-seeking exploration methods including count-based exploration even in continuous control tasks, indicating that it improves the sample efficiency by preventing the agent from taking redundant actions.
[ Virtual ]
Quantization is one of the core components in lossy image compression. For neural image compression, end-to-end optimization requires differentiable approximations of quantization, which can generally be grouped into three categories: additive uniform noise, straight-through estimator and soft-to-hard annealing. Training with additive uniform noise approximates the quantization error variationally but suffers from the train-test mismatch. The other two methods do not encounter this mismatch but, as shown in this paper, hurt the rate-distortion performance since the latent representation ability is weakened. We thus propose a novel soft-then-hard quantization strategy for neural image compression that first learns an expressive latent space softly, then closes the train-test mismatch with hard quantization. In addition, beyond the fixed integer-quantization, we apply scaled additive uniform noise to adaptively control the quantization granularity by deriving a new variational upper bound on actual rate. Experiments demonstrate that our proposed methods are easy to adopt, stable to train, and highly effective especially on complex compression models.
[ Virtual ]
Motivated by the needs from an airline crew scheduling application, we introduce structured convolutional kernel networks (Struct-CKN), which combine CKNs from Mairal et al. (2014) in a structured prediction framework that supports constraints on the outputs. CKNs are a particular kind of convolutional neural networks that approximate a kernel feature map on training data, thus combining properties of deep learning with the non-parametric flexibility of kernel methods. Extending CKNs to structured outputs allows us to obtain useful initial solutions on a flight-connection dataset that can be further refined by an airline crew scheduling solver. More specifically, we use a flight-based network modeled as a general conditional random field capable of incorporating local constraints in the learning process. Our experiments demonstrate that this approach yields significant improvements for the large-scale crew pairing problem (50,000 flights per month) over standard approaches, reducing the solution cost by 17% (a gain of millions of dollars) and the cost of global constraints by 97%.
[ Virtual ]
In practical reinforcement learning (RL), the discount factor used for estimating value functions often differs from that used for defining the evaluation objective. In this work, we study the effect that this discrepancy of discount factors has during learning, and discover a family of objectives that interpolate value functions of two distinct discount factors. Our analysis suggests new ways for estimating value functions and performing policy optimization updates, which demonstrate empirical performance gains. This framework also leads to new insights on commonly-used deep RL heuristic modifications to policy optimization algorithms.
[ Virtual ]
High-dimensional black-box optimisation remains an important yet notoriously challenging problem. Despite the success of Bayesian optimisation methods on continuous domains, domains that are categorical, or that mix continuous and categorical variables, remain challenging. We propose a novel solution---we combine local optimisation with a tailored kernel design, effectively handling high-dimensional categorical and mixed search spaces, whilst retaining sample efficiency. We further derive convergence guarantee for the proposed approach. Finally, we demonstrate empirically that our method outperforms the current baselines on a variety of synthetic and real-world tasks in terms of performance, computational costs, or both.
[ Virtual ]
Despite recent successes, most contrastive self-supervised learning methods are domain-specific, relying heavily on data augmentation techniques that require knowledge about a particular domain, such as image cropping and rotation. To overcome such limitation, we propose a domain-agnostic approach to contrastive learning, named DACL, that is applicable to problems where domain-specific data augmentations are not readily available. Key to our approach is the use of Mixup noise to create similar and dissimilar examples by mixing data samples differently either at the input or hidden-state levels. We theoretically analyze our method and show advantages over the Gaussian-noise based contrastive learning approach. To demonstrate the effectiveness of DACL, we conduct experiments across various domains such as tabular data, images, and graphs. Our results show that DACL not only outperforms other domain-agnostic noising methods, such as Gaussian-noise, but also combines well with domain-specific methods, such as SimCLR, to improve self-supervised visual representation learning.
[ Virtual ]
Deep graph neural networks (GNNs) have achieved excellent results on various tasks on increasingly large graph datasets with millions of nodes and edges. However, memory complexity has become a major obstacle when training deep GNNs for practical applications due to the immense number of nodes, edges, and intermediate activations. To improve the scalability of GNNs, prior works propose smart graph sampling or partitioning strategies to train GNNs with a smaller set of nodes or sub-graphs. In this work, we study reversible connections, group convolutions, weight tying, and equilibrium models to advance the memory and parameter efficiency of GNNs. We find that reversible connections in combination with deep network architectures enable the training of overparameterized GNNs that significantly outperform existing methods on multiple datasets. Our models RevGNN-Deep (1001 layers with 80 channels each) and RevGNN-Wide (448 layers with 224 channels each) were both trained on a single commodity GPU and achieve an ROC-AUC of 87.74 ± 0.13 and 88.14 ± 0.15 on the ogbn-proteins dataset. To the best of our knowledge, RevGNN-Deep is the deepest GNN in the literature by one order of magnitude.
[ Virtual ]
Neural networks (NNs) have been extremely successful across many tasks in machine learning. Quantization of NN weights has become an important topic due to its impact on their energy efficiency, inference time and deployment on hardware. Although post-training quantization is well-studied, training optimal quantized NNs involves combinatorial non-convex optimization problems which appear intractable. In this work, we introduce a convex optimization strategy to train quantized NNs with polynomial activations. Our method leverages hidden convexity in two-layer neural networks from the recent literature, semidefinite lifting, and Grothendieck's identity. Surprisingly, we show that certain quantized NN problems can be solved to global optimality provably in polynomial time in all relevant parameters via tight semidefinite relaxations. We present numerical examples to illustrate the effectiveness of our method.
[ Virtual ]
Unrolled computation graphs arise in many scenarios, including training RNNs, tuning hyperparameters through unrolled optimization, and training learned optimizers. Current approaches to optimizing parameters in such computation graphs suffer from high variance gradients, bias, slow updates, or large memory usage. We introduce a method called Persistent Evolution Strategies (PES), which divides the computation graph into a series of truncated unrolls, and performs an evolution strategies-based update step after each unroll. PES eliminates bias from these truncations by accumulating correction terms over the entire sequence of unrolls. PES allows for rapid parameter updates, has low memory usage, is unbiased, and has reasonable variance characteristics. We experimentally demonstrate the advantages of PES compared to several other methods for gradient estimation on synthetic tasks, and show its applicability to training learned optimizers and tuning hyperparameters.
[ Virtual ]
Learning to reach goal states and learning diverse skills through mutual information maximization have been proposed as principled frameworks for unsupervised reinforcement learning, allowing agents to acquire broadly applicable multi-task policies with minimal reward engineering. In this paper, we discuss how these two approaches — goal-conditioned RL (GCRL) and MI-based RL — can be generalized into a single family of methods, interpreting mutual information maximization and variational empowerment as representation learning methods that acquire function-ally aware state representations for goal reaching.Starting from a simple observation that the standard GCRL is encapsulated by the optimization objective of variational empowerment, we can derive novel variants of GCRL and variational empowerment under a single, unified optimization objective, such as adaptive-variance GCRL and linear-mapping GCRL, and study the characteristics of representation learning each variant provides. Furthermore, through the lens of GCRL, we show that adapting powerful techniques fromGCRL such as goal relabeling into the variationalMI context as well as proper regularization on the variational posterior provides substantial gains in algorithm performance, and propose a novel evaluation metric named latent goal reaching (LGR)as an objective measure for evaluating empowerment algorithms akin to goal-based RL. Through principled mathematical derivations and careful experimental validations, our work lays …
[ Virtual ]
Understanding classifier decision under novel environments is central to the community, and a common practice is evaluating it on labeled test sets. However, in real-world testing, image annotations are difficult and expensive to obtain, especially when the test environment is changing. A natural question then arises: given a trained classifier, can we evaluate its accuracy on varying unlabeled test sets? In this work, we train semantic classification and rotation prediction in a multi-task way. On a series of datasets, we report an interesting finding, i.e., the semantic classification accuracy exhibits a strong linear relationship with the accuracy of the rotation prediction task (Pearson's Correlation r > 0.88). This finding allows us to utilize linear regression to estimate classifier performance from the accuracy of rotation prediction which can be obtained on the test set through the freely generated rotation labels.
[ Virtual ]
Machine learning is predicated on the concept of generalization: a model achieving low error on a sufficiently large training set should also perform well on novel samples from the same distribution. We show that both data whitening and second order optimization can harm or entirely prevent generalization. In general, model training harnesses information contained in the sample-sample second moment matrix of a dataset. For a general class of models, namely models with a fully connected first layer, we prove that the information contained in this matrix is the only information which can be used to generalize. Models trained using whitened data, or with certain second order optimization schemes, have less access to this information, resulting in reduced or nonexistent generalization ability. We experimentally verify these predictions for several architectures, and further demonstrate that generalization continues to be harmed even when theoretical requirements are relaxed. However, we also show experimentally that regularized second order optimization can provide a practical tradeoff, where training is accelerated but less information is lost, and generalization can in some circumstances even improve.
Domain generalization is challenging due to the domain shift and the uncertainty caused by the inaccessibility of target domain data. In this paper, we address both challenges with a probabilistic framework based on variational Bayesian inference, by incorporating uncertainty into neural network weights. We couple domain invariance in a probabilistic formula with the variational Bayesian inference. This enables us to explore domain-invariant learning in a principled way. Specifically, we derive domain-invariant representations and classifiers, which are jointly established in a two-layer Bayesian neural network. We empirically demonstrate the effectiveness of our proposal on four widely used cross-domain visual recognition benchmarks. Ablation studies validate the synergistic benefits of our Bayesian treatment when jointly learning domain-invariant representations and classifiers for domain generalization. Further, our method consistently delivers state-of-the-art mean accuracy on all benchmarks.
Most neural network pruning methods, such as filter-level and layer-level prunings, prune the network model along one dimension (depth, width, or resolution) solely to meet a computational budget. However, such a pruning policy often leads to excessive reduction of that dimension, thus inducing a huge accuracy loss. To alleviate this issue, we argue that pruning should be conducted along three dimensions comprehensively. For this purpose, our pruning framework formulates pruning as an optimization problem. Specifically, it first casts the relationships between a certain model's accuracy and depth/width/resolution into a polynomial regression and then maximizes the polynomial to acquire the optimal values for the three dimensions. Finally, the model is pruned along the three optimal dimensions accordingly. In this framework, since collecting too much data for training the regression is very time-costly, we propose two approaches to lower the cost: 1) specializing the polynomial to ensure an accurate regression even with less training data; 2) employing iterative pruning and fine-tuning to collect the data faster. Extensive experiments show that our proposed algorithm surpasses state-of-the-art pruning algorithms and even neural architecture search-based algorithms.
Gradient staleness is a major side effect in decoupled learning when training convolutional neural networks asynchronously. Existing methods that ignore this effect might result in reduced generalization and even divergence. In this paper, we propose an accumulated decoupled learning (ADL), which includes a module-wise gradient accumulation in order to mitigate the gradient staleness. Unlike prior arts ignoring the gradient staleness, we quantify the staleness in such a way that its mitigation can be quantitatively visualized. As a new learning scheme, the proposed ADL is theoretically shown to converge to critical points in spite of its asynchronism. Extensive experiments on CIFAR-10 and ImageNet datasets are conducted, demonstrating that ADL gives promising generalization results while the state-of-the-art methods experience reduced generalization and divergence. In addition, our ADL is shown to have the fastest training speed among the compared methods.
Lately, post-training quantization methods have gained considerable attention, as they are simple to use, and require only a small unlabeled calibration set. This small dataset cannot be used to fine-tune the model without significant over-fitting. Instead, these methods only use the calibration set to set the activations' dynamic ranges. However, such methods always resulted in significant accuracy degradation, when used below 8-bits (except on small datasets). Here we aim to break the 8-bit barrier. To this end, we minimize the quantization errors of each layer or block separately by optimizing its parameters over the calibration set. We empirically demonstrate that this approach is: (1) much less susceptible to over-fitting than the standard fine-tuning approaches, and can be used even on a very small calibration set; and (2) more powerful than previous methods, which only set the activations' dynamic ranges. We suggest two flavors for our method, parallel and sequential aim for a fixed and flexible bit-width allocation. For the latter, we demonstrate how to optimally allocate the bit-widths for each layer, while constraining accuracy degradation or model compression by proposing a novel integer programming formulation. Finally, we suggest model global statistics tuning, to correct biases introduced during quantization. Together, these …
Marginalized importance sampling (MIS), which measures the density ratio between the state-action occupancy of a target policy and that of a sampling distribution, is a promising approach for off-policy evaluation. However, current state-of-the-art MIS methods rely on complex optimization tricks and succeed mostly on simple toy problems. We bridge the gap between MIS and deep reinforcement learning by observing that the density ratio can be computed from the successor representation of the target policy. The successor representation can be trained through deep reinforcement learning methodology and decouples the reward optimization from the dynamics of the environment, making the resulting algorithm stable and applicable to high-dimensional domains. We evaluate the empirical performance of our approach on a variety of challenging Atari and MuJoCo environments.
A large part of the literature on learning disentangled representations focuses on variational autoencoders (VAEs). Recent developments demonstrate that disentanglement cannot be obtained in a fully unsupervised setting without inductive biases on models and data. However, Khemakhem et al., AISTATS, 2020 suggest that employing a particular form of factorized prior, conditionally dependent on auxiliary variables complementing input observations, can be one such bias, resulting in an identifiable model with guarantees on disentanglement. Working along this line, we propose a novel VAE-based generative model with theoretical guarantees on identifiability. We obtain our conditional prior over the latents by learning an optimal representation, which imposes an additional strength on their regularization. We also extend our method to semi-supervised settings. Experimental results indicate superior performance with respect to state-of-the-art approaches, according to several established metrics proposed in the literature on disentanglement.
In previous Capsule Neural Networks (CapsNets), routing algorithms often performed clustering processes to assemble the child capsules' representations into parent capsules. Such routing algorithms were typically implemented with iterative processes and incurred high computing complexity. This paper presents a new capsule structure, which contains a set of optimizable receptors and a transmitter is devised on the capsule's representation. Specifically, child capsules' representations are sent to the parent capsules whose receptors match well the transmitters of the child capsules' representations, avoiding applying computationally complex routing algorithms. To ensure the receptors in a CapsNet work cooperatively, we build a skeleton to organize the receptors in different capsule layers in a CapsNet. The receptor skeleton assigns a share-out objective for each receptor, making the CapsNet perform as a hierarchical agglomerative clustering process. Comprehensive experiments verify that our approach facilitates efficient clustering processes, and CapsNets with our approach significantly outperform CapsNets with previous routing algorithms on image classification, affine transformation generalization, overlapped object recognition, and representation semantic decoupling.
We consider stochastic convex optimization problems, where several machines act asynchronously in parallel while sharing a common memory. We propose a robust training method for the constrained setting and derive non asymptotic convergence guarantees that do not depend on prior knowledge of update delays, objective smoothness, and gradient variance. Conversely, existing methods for this setting crucially rely on this prior knowledge, which render them unsuitable for essentially all shared-resources computational environments, such as clouds and data centers. Concretely, existing approaches are unable to accommodate changes in the delays which result from dynamic allocation of the machines, while our method implicitly adapts to such changes.
Softmax classifiers with a very large number of classes naturally occur in many applications such as natural language processing and information retrieval. The calculation of full softmax is costly from the computational and energy perspective. There have been various sampling approaches to overcome this challenge, popularly known as negative sampling (NS). Ideally, NS should sample negative classes from a distribution that is dependent on the input data, the current parameters, and the correct positive class. Unfortunately, due to the dynamically updated parameters and data samples, there is no sampling scheme that is provably adaptive and samples the negative classes efficiently. Therefore, alternative heuristics like random sampling, static frequency-based sampling, or learning-based biased sampling, which primarily trade either the sampling cost or the adaptivity of samples per iteration are adopted. In this paper, we show two classes of distributions where the sampling scheme is truly adaptive and provably generates negative samples in near-constant time. Our implementation in C++ on CPU is significantly superior, both in terms of wall-clock time and accuracy, compared to the most optimized TensorFlow implementations of other popular negative sampling approaches on powerful NVIDIA V100 GPU.
We propose a novel GAN training scheme that can handle any level of labeling in a unified manner. Our scheme introduces a form of artificial labeling that can incorporate manually defined labels, when available, and induce an alignment between them. To define the artificial labels, we exploit the assumption that neural network generators can be trained more easily to map nearby latent vectors to data with semantic similarities, than across separate categories. We use generated data samples and their corresponding artificial conditioning labels to train a classifier. The classifier is then used to self-label real data. To boost the accuracy of the self-labeling, we also use the exponential moving average of the classifier. However, because the classifier might still make mistakes, especially at the beginning of the training, we also refine the labels through self-attention, by using the labeling of real data samples only when the classifier outputs a high classification probability score. We evaluate our approach on CIFAR-10, STL-10 and SVHN, and show that both self-labeling and self-attention consistently improve the quality of generated data. More surprisingly, we find that the proposed scheme can even outperform class-conditional GANs.
Self-attention mechanisms have been widely adopted in many machine learning areas, including Natural Language Processing (NLP) and Graph Representation Learning (GRL), etc. However, existing works heavily rely on hand-crafted design to obtain customized attention mechanisms. In this paper, we automate Key, Query and Value representation design, which is one of the most important steps to obtain effective self-attentions. We propose an automated self-attention representation model, AutoAttend, which can automatically search powerful attention representations for downstream tasks leveraging Neural Architecture Search (NAS). In particular, we design a tailored search space for attention representation automation, which is flexible to produce effective attention representation designs. Based on the design prior obtained from attention representations in previous works, we further regularize our search space to reduce the space complexity without the loss of expressivity. Moreover, we propose a novel context-aware parameter sharing mechanism considering special characteristics of each sub-architecture to provide more accurate architecture estimations when conducting parameter sharing in our tailored search space. Experiments show the superiority of our proposed AutoAttend model over previous state-of-the-arts on eight text classification tasks in NLP and four node classification tasks in GRL.
While maximizing deep neural networks' (DNNs') acceleration efficiency requires a joint search/design of three different yet highly coupled aspects, including the networks, bitwidths, and accelerators, the challenges associated with such a joint search have not yet been fully understood and addressed. The key challenges include (1) the dilemma of whether to explode the memory consumption due to the huge joint space or achieve sub-optimal designs, (2) the discrete nature of the accelerator design space that is coupled yet different from that of the networks and bitwidths, and (3) the chicken and egg problem associated with network-accelerator co-search, i.e., co-search requires operation-wise hardware cost, which is lacking during search as the optimal accelerator depending on the whole network is still unknown during search. To tackle these daunting challenges towards optimal and fast development of DNN accelerators, we propose a framework dubbed Auto-NBA to enable jointly searching for the Networks, Bitwidths, and Accelerators, by efficiently localizing the optimal design within the huge joint design space for each target dataset and acceleration specification. Our Auto-NBA integrates a heterogeneous sampling strategy to achieve unbiased search with constant memory consumption, and a novel joint-search pipeline equipped with a generic differentiable accelerator search engine. Extensive experiments …
We consider the problem of optimizing hybrid structures (mixture of discrete and continuous input variables) via expensive black-box function evaluations. This problem arises in many real-world applications. For example, in materials design optimization via lab experiments, discrete and continuous variables correspond to the presence/absence of primitive elements and their relative concentrations respectively. The key challenge is to accurately model the complex interactions between discrete and continuous variables. In this paper, we propose a novel approach referred as Hybrid Bayesian Optimization (HyBO) by utilizing diffusion kernels, which are naturally defined over continuous and discrete variables. We develop a principled approach for constructing diffusion kernels over hybrid spaces by utilizing the additive kernel formulation, which allows additive interactions of all orders in a tractable manner. We theoretically analyze the modeling strength of additive hybrid kernels and prove that it has the universal approximation property. Our experiments on synthetic and six diverse real-world benchmarks show that HyBO significantly outperforms the state-of-the-art methods.
Bandit and reinforcement learning (RL) problems can often be framed as optimization problems where the goal is to maximize average performance while having access only to stochastic estimates of the true gradient. Traditionally, stochastic optimization theory predicts that learning dynamics are governed by the curvature of the loss function and the noise of the gradient estimates. In this paper we demonstrate that the standard view is too limited for bandit and RL problems. To allow our analysis to be interpreted in light of multi-step MDPs, we focus on techniques derived from stochastic optimization principles~(e.g., natural policy gradient and EXP3) and we show that some standard assumptions from optimization theory are violated in these problems. We present theoretical results showing that, at least for bandit problems, curvature and noise are not sufficient to explain the learning dynamics and that seemingly innocuous choices like the baseline can determine whether an algorithm converges. These theoretical findings match our empirical evaluation, which we extend to multi-state MDPs.
Transformer architectures are widely used, but training them is non-trivial, requiring custom learning rate schedules, scaling terms, residual connections, careful placement of submodules such as normalization, and so on. In this paper, we improve upon recent analysis of Transformers and formalize a notion of sensitivity to capture the difficulty of training. Sensitivity characterizes how the variance of activation and gradient norms change in expectation when parameters are randomly perturbed. We analyze the sensitivity of previous Transformer architectures and design a new architecture, the Catformer, which replaces residual connections or RNN-based gating mechanisms with concatenation. We prove that Catformers are less sensitive than other Transformer variants and demonstrate that this leads to more stable training. On DMLab30, a suite of high-dimension reinforcement tasks, Catformer outperforms other transformers, including Gated Transformer-XL---the state-of-the-art architecture designed to address stability---by 13%.
Humans show an innate ability to learn the regularities of the world through interaction. By performing experiments in our environment, we are able to discern the causal factors of variation and infer how they affect the dynamics of our world. Analogously, here we attempt to equip reinforcement learning agents with the ability to perform experiments that facilitate a categorization of the rolled-out trajectories, and to subsequently infer the causal factors of the environment in a hierarchical manner. We introduce a novel intrinsic reward, called causal curiosity, and show that it allows our agents to learn optimal sequences of actions, and to discover causal factors in the dynamics. The learned behavior allows the agent to infer a binary quantized representation for the ground-truth causal factors in every environment. Additionally, we find that these experimental behaviors are semantically meaningful (e.g., to differentiate between heavy and light blocks, our agents learn to lift them), and are learnt in a self-supervised manner with approximately 2.5 times less data than conventional supervised planners. We show that these behaviors can be re-purposed and fine-tuned (e.g., from lifting to pushing or other downstream tasks). Finally, we show that the knowledge of causal factor representations aids zero-shot learning …
Videos of actions are complex signals containing rich compositional structure in space and time. Current video generation methods lack the ability to condition the generation on multiple coordinated and potentially simultaneous timed actions. To address this challenge, we propose to represent the actions in a graph structure called Action Graph and present the new "Action Graph To Video" synthesis task. Our generative model for this task (AG2Vid) disentangles motion and appearance features, and by incorporating a scheduling mechanism for actions facilitates a timely and coordinated video generation. We train and evaluate AG2Vid on CATER and Something-Something V2 datasets, which results in videos that have better visual quality and semantic consistency compared to baselines. Finally, our model demonstrates zero-shot abilities by synthesizing novel compositions of the learned actions.
Recent research has recognized interpretability and robustness as essential properties of trustworthy classification. Curiously, a connection between robustness and interpretability was empirically observed, but the theoretical reasoning behind it remained elusive. In this paper, we rigorously investigate this connection. Specifically, we focus on interpretation using decision trees and robustness to l_{\infty}-perturbation. Previous works defined the notion of r-separation as a sufficient condition for robustness. We prove upper and lower bounds on the tree size in case the data is r-separated. We then show that a tighter bound on the size is possible when the data is linearly separated. We provide the first algorithm with provable guarantees both on robustness, interpretability, and accuracy in the context of decision trees. Experiments confirm that our algorithm yields classifiers that are both interpretable and robust and have high accuracy.
Monte-Carlo planning and Reinforcement Learning (RL) are essential to sequential decision making. The recent AlphaGo and AlphaZero algorithms have shown how to successfully combine these two paradigms to solve large-scale sequential decision problems. These methodologies exploit a variant of the well-known UCT algorithm to trade off the exploitation of good actions and the exploration of unvisited states, but their empirical success comes at the cost of poor sample-efficiency and high computation time. In this paper, we overcome these limitations by introducing the use of convex regularization in Monte-Carlo Tree Search (MCTS) to drive exploration efficiently and to improve policy updates. First, we introduce a unifying theory on the use of generic convex regularizers in MCTS, deriving the first regret analysis of regularized MCTS and showing that it guarantees an exponential convergence rate. Second, we exploit our theoretical framework to introduce novel regularized backup operators for MCTS, based on the relative entropy of the policy update and, more importantly, on the Tsallis entropy of the policy, for which we prove superior theoretical guarantees. We empirically verify the consequence of our theoretical results on a toy problem. Finally, we show how our framework can easily be incorporated in AlphaGo and we empirically …
Decentralized learning enables a group of collaborative agents to learn models using a distributed dataset without the need for a central parameter server. Recently, decentralized learning algorithms have demonstrated state-of-the-art results on benchmark data sets, comparable with centralized algorithms. However, the key assumption to achieve competitive performance is that the data is independently and identically distributed (IID) among the agents which, in real-life applications, is often not applicable. Inspired by ideas from continual learning, we propose Cross-Gradient Aggregation (CGA), a novel decentralized learning algorithm where (i) each agent aggregates cross-gradient information, i.e., derivatives of its model with respect to its neighbors' datasets, and (ii) updates its model using a projected gradient based on quadratic programming (QP). We theoretically analyze the convergence characteristics of CGA and demonstrate its efficiency on non-IID data distributions sampled from the MNIST and CIFAR-10 datasets. Our empirical comparisons show superior learning performance of CGA over existing state-of-the-art decentralized learning algorithms, as well as maintaining the improved performance under information compression to reduce peer-to-peer communication overhead. The code is available here on GitHub.
We propose to learn a generative model via entropy interpolation with a Schrödinger Bridge. The generative learning task can be formulated as interpolating between a reference distribution and a target distribution based on the Kullback-Leibler divergence. At the population level, this entropy interpolation is characterized via an SDE on [0,1] with a time-varying drift term. At the sample level, we derive our Schrödinger Bridge algorithm by plugging the drift term estimated by a deep score estimator and a deep density ratio estimator into the Euler-Maruyama method. Under some mild smoothness assumptions of the target distribution, we prove the consistency of both the score estimator and the density ratio estimator, and then establish the consistency of the proposed Schrödinger Bridge approach. Our theoretical results guarantee that the distribution learned by our approach converges to the target distribution. Experimental results on multimodal synthetic data and benchmark data support our theoretical findings and indicate that the generative model via Schrödinger Bridge is comparable with state-of-the-art GANs, suggesting a new formulation of generative learning. We demonstrate its usefulness in image interpolation and image inpainting.
That neural networks may be pruned to high sparsities and retain high accuracy is well established. Recent research efforts focus on pruning immediately after initialization so as to allow the computational savings afforded by sparsity to extend to the training process. In this work, we introduce a new `DCT plus Sparse' layer architecture, which maintains information propagation and trainability even with as little as 0.01% trainable parameters remaining. We show that standard training of networks built with these layers, and pruned at initialization, achieves state-of-the-art accuracy for extreme sparsities on a variety of benchmark network architectures and datasets. Moreover, these results are achieved using only simple heuristics to determine the locations of the trainable parameters in the network, and thus without having to initially store or compute with the full, unpruned network, as is required by competing prune-at-initialization algorithms. Switching from standard sparse layers to DCT plus Sparse layers does not increase the storage footprint of a network and incurs only a small additional computational overhead.
We study constrained reinforcement learning (CRL) from a novel perspective by setting constraints directly on state density functions, rather than the value functions considered by previous works. State density has a clear physical and mathematical interpretation, and is able to express a wide variety of constraints such as resource limits and safety requirements. Density constraints can also avoid the time-consuming process of designing and tuning cost functions required by value function-based constraints to encode system specifications. We leverage the duality between density functions and Q functions to develop an effective algorithm to solve the density constrained RL problem optimally and the constrains are guaranteed to be satisfied. We prove that the proposed algorithm converges to a near-optimal solution with a bounded error even when the policy update is imperfect. We use a set of comprehensive experiments to demonstrate the advantages of our approach over state-of-the-art CRL methods, with a wide range of density constrained tasks as well as standard CRL benchmarks such as Safety-Gym.
Deep reinforcement learning (DRL) has proven successful for many difficult control problems by learning policies represented by neural networks. However, the complexity of neural network-based policies—involving thousands of composed non-linear operators—can render them problematic to understand, trust, and deploy. In contrast, simple policies comprising short symbolic expressions can facilitate human understanding, while also being transparent and exhibiting predictable behavior. To this end, we propose deep symbolic policy, a novel approach to directly search the space of symbolic policies. We use an autoregressive recurrent neural network to generate control policies represented by tractable mathematical expressions, employing a risk-seeking policy gradient to maximize performance of the generated policies. To scale to environments with multi-dimensional action spaces, we propose an "anchoring" algorithm that distills pre-trained neural network-based policies into fully symbolic policies, one action dimension at a time. We also introduce two novel methods to improve exploration in DRL-based combinatorial optimization, building on ideas of entropy regularization and distribution initialization. Despite their dramatically reduced complexity, we demonstrate that discovered symbolic policies outperform seven state-of-the-art DRL algorithms in terms of average rank and average normalized episodic reward across eight benchmark environments.
Fairness and robustness are two important concerns for federated learning systems. In this work, we identify that robustness to data and model poisoning attacks and fairness, measured as the uniformity of performance across devices, are competing constraints in statistically heterogeneous networks. To address these constraints, we propose employing a simple, general framework for personalized federated learning, Ditto, that can inherently provide fairness and robustness benefits, and develop a scalable solver for it. Theoretically, we analyze the ability of Ditto to achieve fairness and robustness simultaneously on a class of linear problems. Empirically, across a suite of federated datasets, we show that Ditto not only achieves competitive performance relative to recent personalization methods, but also enables more accurate, robust, and fair models relative to state-of-the-art fair or robust baselines.
This paper introduces EfficientNetV2, a new family of convolutional networks that have faster training speed and better parameter efficiency than previous models. To develop these models, we use a combination of training-aware neural architecture search and scaling, to jointly optimize training speed and parameter efficiency. The models were searched from the search space enriched with new ops such as Fused-MBConv. Our experiments show that EfficientNetV2 models train much faster than state-of-the-art models while being up to 6.8x smaller. Our training can be further sped up by progressively increasing the image size during training, but it often causes a drop in accuracy. To compensate for this accuracy drop, we propose an improved method of progressive learning, which adaptively adjusts regularization (e.g. data augmentation) along with image size. With progressive learning, our EfficientNetV2 significantly outperforms previous models on ImageNet and CIFAR/Cars/Flowers datasets. By pretraining on the same ImageNet21k, our EfficientNetV2 achieves 87.3% top-1 accuracy on ImageNet ILSVRC2012, outperforming the recent ViT by 2.0% accuracy while training 5x-11x faster using the same computing resources.
Social learning is a key component of human and animal intelligence. By taking cues from the behavior of experts in their environment, social learners can acquire sophisticated behavior and rapidly adapt to new circumstances. This paper investigates whether independent reinforcement learning (RL) agents in a multi-agent environment can learn to use social learning to improve their performance. We find that in most circumstances, vanilla model-free RL agents do not use social learning. We analyze the reasons for this deficiency, and show that by imposing constraints on the training environment and introducing a model-based auxiliary loss we are able to obtain generalized social learning policies which enable agents to: i) discover complex skills that are not learned from single-agent training, and ii) adapt online to novel environments by taking cues from experts present in the new environment. In contrast, agents trained with model-free RL or imitation learning generalize poorly and do not succeed in the transfer tasks. By mixing multi-agent and solo training, we can obtain agents that use social learning to gain skills that they can deploy when alone, even out-performing agents trained alone from the start.
Off-policy learning allows us to learn about possible policies of behavior from experience generated by a different behavior policy. Temporal difference (TD) learning algorithms can become unstable when combined with function approximation and off-policy sampling---this is known as the ``deadly triad''. Emphatic temporal difference (ETD(λ)) algorithm ensures convergence in the linear case by appropriately weighting the TD(λ) updates. In this paper, we extend the use of emphatic methods to deep reinforcement learning agents. We show that naively adapting ETD(λ) to popular deep reinforcement learning algorithms, which use forward view multi-step returns, results in poor performance. We then derive new emphatic algorithms for use in the context of such algorithms, and we demonstrate that they provide noticeable benefits in small problems designed to highlight the instability of TD methods. Finally, we observed improved performance when applying these algorithms at scale on classic Atari games from the Arcade Learning Environment.
Human beings acquire the ability of image classification through visual concept learning, in which the process of concept formation involves intertwined searches of common properties and concept descriptions. However, in most image classification algorithms using deep convolutional neural network (ConvNet), the representation space is constructed under the premise that concept descriptions are fixed as one-hot codes, which limits the mining of properties and the ability of identifying unseen samples. Inspired by this, we propose a learning strategy of visual concept formation (LSOVCF) based on the ConvNet, in which the two intertwined parts of concept formation, i.e. feature extraction and concept description, are learned together. First, LSOVCF takes sample response in the last layer of ConvNet to induct concept description being assumed as Gaussian distribution, which is part of the training process. Second, the exploration and experience loss is designed for optimization, which adopts experience cache pool to speed up convergence. Experiments show that LSOVCF improves the ability of identifying unseen samples on cifar10, STL10, flower17 and ImageNet based on several backbones, from the classic VGG to the SOTA Ghostnet. The code is available at \url{https://github.com/elvintanhust/LSOVCF}.
Deep AUC (area under the ROC curve) Maximization (DAM) has attracted much attention recently due to its great potential for imbalanced data classification. However, the research on Federated Deep AUC Maximization (FDAM) is still limited. Compared with standard federated learning (FL) approaches that focus on decomposable minimization objectives, FDAM is more complicated due to its minimization objective is non-decomposable over individual examples. In this paper, we propose improved FDAM algorithms for heterogeneous data by solving the popular non-convex strongly-concave min-max formulation of DAM in a distributed fashion, which can also be applied to a class of non-convex strongly-concave min-max problems. A striking result of this paper is that the communication complexity of the proposed algorithm is a constant independent of the number of machines and also independent of the accuracy level, which improves an existing result by orders of magnitude. The experiments have demonstrated the effectiveness of our FDAM algorithm on benchmark datasets, and on medical chest X-ray images from different organizations. Our experiment shows that the performance of FDAM using data from multiple hospitals can improve the AUC score on testing data from a single hospital for detecting life-threatening diseases based on chest radiographs.
Efficient evaluation of a network architecture drawn from a large search space remains a key challenge in Neural Architecture Search (NAS). Vanilla NAS evaluates each architecture by training from scratch, which gives the true performance but is extremely time-consuming. Recently, one-shot NAS substantially reduces the computation cost by training only one supernetwork, a.k.a. supernet, to approximate the performance of every architecture in the search space via weight-sharing. However, the performance estimation can be very inaccurate due to the co-adaption among operations. In this paper, we propose few-shot NAS that uses multiple supernetworks, called sub-supernet, each covering different regions of the search space to alleviate the undesired co-adaption. Compared to one-shot NAS, few-shot NAS improves the accuracy of architecture evaluation with a small increase of evaluation cost. With only up to 7 sub-supernets, few-shot NAS establishes new SoTAs: on ImageNet, it finds models that reach 80.5% top-1 accuracy at 600 MB FLOPS and 77.5% top-1 accuracy at 238 MFLOPS; on CIFAR10, it reaches 98.72% top-1 accuracy without using extra data or transfer learning. In Auto-GAN, few-shot NAS outperforms the previously published results by up to 20%. Extensive experiments show that few-shot NAS significantly improves various one-shot methods, including 4 gradient-based and …
Value decomposition recently injects vigorous vitality into multi-agent actor-critic methods. However, existing decomposed actor-critic methods cannot guarantee the convergence of global optimum. In this paper, we present a novel multi-agent actor-critic method, FOP, which can factorize the optimal joint policy induced by maximum-entropy multi-agent reinforcement learning (MARL) into individual policies. Theoretically, we prove that factorized individual policies of FOP converge to the global optimum. Empirically, in the well-known matrix game and differential game, we verify that FOP can converge to the global optimum for both discrete and continuous action spaces. We also evaluate FOP on a set of StarCraft II micromanagement tasks, and demonstrate that FOP substantially outperforms state-of-the-art decomposed value-based and actor-critic methods.
Goal-conditioned reinforcement learning endows an agent with a large variety of skills, but it often struggles to solve tasks that require more temporally extended reasoning. In this work, we propose to incorporate imagined subgoals into policy learning to facilitate learning of complex tasks. Imagined subgoals are predicted by a separate high-level policy, which is trained simultaneously with the policy and its critic. This high-level policy predicts intermediate states halfway to the goal using the value function as a reachability metric. We don’t require the policy to reach these subgoals explicitly. Instead, we use them to define a prior policy, and incorporate this prior into a KL-constrained policy iteration scheme to speed up and regularize learning. Imagined subgoals are used during policy learning, but not during test time, where we only apply the learned policy. We evaluate our approach on complex robotic navigation and manipulation tasks and show that it outperforms existing methods by a large margin.
We present several classes of reinforcement learning algorithms that safely generalize to Markov decision processes (MDPs) not seen during training. Specifically, we study the setting in which some set of MDPs is accessible for training. The goal is to generalize safely to MDPs that are sampled from the same distribution, but which may not be in the set accessible for training. For various definitions of safety, our algorithms give probabilistic guarantees that agents can safely generalize to MDPs that are sampled from the same distribution but are not necessarily in the training set. These algorithms are a type of Seldonian algorithm (Thomas et al., 2019), which is a class of machine learning algorithms that return models with probabilistic safety guarantees for user-specified definitions of safety.
Batch normalization is a key component of most image classification models, but it has many undesirable properties stemming from its dependence on the batch size and interactions between examples. Although recent work has succeeded in training deep ResNets without normalization layers, these models do not match the test accuracies of the best batch-normalized networks, and are often unstable for large learning rates or strong data augmentations. In this work, we develop an adaptive gradient clipping technique which overcomes these instabilities, and design a significantly improved class of Normalizer-Free ResNets. Our smaller models match the test accuracy of an EfficientNet-B7 on ImageNet while being up to 8.7x faster to train, and our largest models attain a new state-of-the-art top-1 accuracy of 86.5%. In addition, Normalizer-Free models attain significantly better performance than their batch-normalized counterparts when fine-tuning on ImageNet after large-scale pre-training on a dataset of 300 million labeled images, with our best models obtaining an accuracy of 89.2%.
We address the issue of tuning hyperparameters (HPs) for imitation learning algorithms in the context of continuous-control, when the underlying reward function of the demonstrating expert cannot be observed at any time. The vast literature in imitation learning mostly considers this reward function to be available for HP selection, but this is not a realistic setting. Indeed, would this reward function be available, it could then directly be used for policy training and imitation would not be necessary. To tackle this mostly ignored problem, we propose a number of possible proxies to the external reward. We evaluate them in an extensive empirical study (more than 10'000 agents across 9 environments) and make practical recommendations for selecting HPs. Our results show that while imitation learning algorithms are sensitive to HP choices, it is often possible to select good enough HPs through a proxy to the reward function.
Differentiable ARchiTecture Search(DARTS) has recently become the mainstream in the neural architecture search (NAS) due to its efficiency and simplicity. With a gradient-based bi-level optimization, DARTS alternately optimizes the inner model weights and the outer architecture parameter in a weight-sharing supernet. A key challenge to the scalability and quality of the learned architectures is the need for differentiating through the inner-loop optimisation. While much has been discussed about several potentially fatal factors in DARTS, the architecture gradient, a.k.a. hypergradient, has received less attention. In this paper, we tackle the hypergradient computation in DARTS based on the implicit function theorem, making it only depends on the obtained solution to the inner-loop optimization and agnostic to the optimization path. To further reduce the computational requirements, we formulate a stochastic hypergradient approximation for differentiable NAS, and theoretically show that the architecture optimization with the proposed method is expected to converge to a stationary point. Comprehensive experiments on two NAS benchmark search spaces and the common NAS search space verify the effectiveness of our proposed method. It leads to architectures outperforming, with large margins, those learned by the baseline methods.
Contrastive divergence is a popular method of training energy-based models, but is known to have difficulties with training stability. We propose an adaptation to improve contrastive divergence training by scrutinizing a gradient term that is difficult to calculate and is often left out for convenience. We show that this gradient term is numerically significant and in practice is important to avoid training instabilities, while being tractable to estimate. We further highlight how data augmentation and multi-scale processing can be used to improve model robustness and generation quality. Finally, we empirically evaluate stability of model architectures and show improved performance on a host of benchmarks and use cases, such as image generation, OOD detection, and compositional generation.
In this work, we focus on the ability of graph neural networks (GNNs) to learn long-range patterns in graphs with edge features. Learning patterns that involve longer paths in the graph, requires using deeper GNNs. However, GNNs suffer from a drop in performance with increasing network depth. To improve the performance of deeper GNNs, previous works have investigated normalization techniques and various types of skip connections. While they are designed to improve depth-wise backpropagation between the representations of the same node in successive layers, they do not improve breadth-wise backpropagation between representations of neighbouring nodes. To analyse the consequences, we design synthetic datasets serving as a testbed for the ability of GNNs to learn long-range patterns. Our analysis shows that several commonly used GNN variants with only depth-wise skip connections indeed have problems learning long-range patterns. They are clearly outperformed by an attention-based GNN architecture that we propose for improving both depth- and breadth-wise backpropagation. We also verify that the presented architecture is competitive on real-world data.
While the advent of Graph Neural Networks (GNNs) has greatly improved node and graph representation learning in many applications, the neighborhood aggregation scheme exposes additional vulnerabilities to adversaries seeking to extract node-level information about sensitive attributes. In this paper, we study the problem of protecting sensitive attributes by information obfuscation when learning with graph structured data. We propose a framework to locally filter out pre-determined sensitive attributes via adversarial training with the total variation and the Wasserstein distance. Our method creates a strong defense against inference attacks, while only suffering small loss in task performance. Theoretically, we analyze the effectiveness of our framework against a worst-case adversary, and characterize an inherent trade-off between maximizing predictive accuracy and minimizing information leakage. Experiments across multiple datasets from recommender systems, knowledge graphs and quantum chemistry demonstrate that the proposed approach provides a robust defense across various graph structures and tasks, while producing competitive GNN encoders for downstream tasks.
Decision analysis deals with modeling and enhancing decision processes. A principal challenge in improving behavior is in obtaining a transparent description of existing behavior in the first place. In this paper, we develop an expressive, unifying perspective on inverse decision modeling: a framework for learning parameterized representations of sequential decision behavior. First, we formalize the forward problem (as a normative standard), subsuming common classes of control behavior. Second, we use this to formalize the inverse problem (as a descriptive model), generalizing existing work on imitation/reward learning---while opening up a much broader class of research problems in behavior representation. Finally, we instantiate this approach with an example (inverse bounded rational control), illustrating how this structure enables learning (interpretable) representations of (bounded) rationality---while naturally capturing intuitive notions of suboptimal actions, biased beliefs, and imperfect knowledge of environments.
Most, if not all, modern deep learning systems restrict themselves to a single dataset for neural network training and inference. In this article, we are interested in systematic ways to join datasets that are made of similar purposes. Unlike previous published works that ubiquitously conduct the dataset joining in the uninterpretable latent vectorial space, the core to our method is an augmentation procedure in the label space. The primary challenge to address the label space for dataset joining is the discrepancy between labels: non-overlapping label annotation sets, different labeling granularity or hierarchy and etc. Notably we propose a new technique leveraging artificially created knowledge graph, recurrent neural networks and policy gradient that successfully achieve the dataset joining in the label space. Empirical results on both image and text classification justify the validity of our approach.
Data poisoning and backdoor attacks manipulate training data in order to cause models to fail during inference. A recent survey of industry practitioners found that data poisoning is the number one concern among threats ranging from model stealing to adversarial attacks. However, it remains unclear exactly how dangerous poisoning methods are and which ones are more effective considering that these methods, even ones with identical objectives, have not been tested in consistent or realistic settings. We observe that data poisoning and backdoor attacks are highly sensitive to variations in the testing setup. Moreover, we find that existing methods may not generalize to realistic settings. While these existing works serve as valuable prototypes for data poisoning, we apply rigorous tests to determine the extent to which we should fear them. In order to promote fair comparison in future work, we develop standardized benchmarks for data poisoning and backdoor attacks.
Imitation learning trains control policies by mimicking pre-recorded expert demonstrations. In partially observable settings, imitation policies must rely on observation histories, but many seemingly paradoxical results show better performance for policies that only access the most recent observation. Recent solutions ranging from causal graph learning to deep information bottlenecks have shown promising results, but failed to scale to realistic settings such as visual imitation. We propose a solution that outperforms these prior approaches by upweighting demonstration keyframes corresponding to expert action changepoints. This simple approach easily scales to complex visual imitation settings. Our experimental results demonstrate consistent performance improvements over all baselines on image-based Gym MuJoCo continuous control tasks. Finally, on the CARLA photorealistic vision-based urban driving simulator, we resolve a long-standing issue in behavioral cloning for driving by demonstrating effective imitation from observation histories. Supplementary materials and code at: \url{https://tinyurl.com/imitation-keyframes}.
Deep domain adaptation (DDA) approaches have recently been shown to perform better than their shallow rivals with better modeling capacity on complex domains (e.g., image, structural data, and sequential data). The underlying idea is to learn domain invariant representations on a latent space that can bridge the gap between source and target domains. Several theoretical studies have established insightful understanding and the benefit of learning domain invariant features; however, they are usually limited to the case where there is no label shift, hence hindering its applicability. In this paper, we propose and study a new challenging setting that allows us to use a Wasserstein distance (WS) to not only quantify the data shift but also to define the label shift directly. We further develop a theory to demonstrate that minimizing the WS of the data shift leads to closing the gap between the source and target data distributions on the latent space (e.g., an intermediate layer of a deep net), while still being able to quantify the label shift with respect to this latent space. Interestingly, our theory can consequently explain certain drawbacks of learning domain invariant features on the latent space. Finally, grounded on the results and guidance of …
Recent observations have advanced our understanding of the neural network optimization landscape, revealing the existence of (1) paths of high accuracy containing diverse solutions and (2) wider minima offering improved performance. Previous methods observing diverse paths require multiple training runs. In contrast we aim to leverage both property (1) and (2) with a single method and in a single training run. With a similar computational cost as training one model, we learn lines, curves, and simplexes of high-accuracy neural networks. These neural network subspaces contain diverse solutions that can be ensembled, approaching the ensemble performance of independently trained networks without the training cost. Moreover, using the subspace midpoint boosts accuracy, calibration, and robustness to label noise, outperforming Stochastic Weight Averaging.
This paper investigates how to weight imperfect expert demonstrations for generative adversarial imitation learning (GAIL). The agent is expected to perform behaviors demonstrated by experts. But in many applications, experts could also make mistakes and their demonstrations would mislead or slow the learning process of the agent. Recently, existing methods for imitation learning from imperfect demonstrations mostly focus on using the preference or confidence scores to distinguish imperfect demonstrations. However, these auxiliary information needs to be collected with the help of an oracle, which is usually hard and expensive to afford in practice. In contrast, this paper proposes a method of learning to weight imperfect demonstrations in GAIL without imposing extensive prior information. We provide a rigorous mathematical analysis, presenting that the weights of demonstrations can be exactly determined by combining the discriminator and agent policy in GAIL. Theoretical analysis suggests that with the estimated weights the agent can learn a better policy beyond those plain expert demonstrations. Experiments in the Mujoco and Atari environments demonstrate that the proposed algorithm outperforms baseline methods in handling imperfect expert demonstrations.
We study reinforcement learning in mean-field games. To achieve the Nash equilibrium, which consists of a policy and a mean-field state, existing algorithms require obtaining the optimal policy while fixing any mean-field state. In practice, however, the policy and the mean-field state evolve simultaneously, as each agent is learning while playing. To bridge such a gap, we propose a fictitious play algorithm, which alternatively updates the policy (learning) and the mean-field state (playing) by one step of policy optimization and gradient descent, respectively. Despite the nonstationarity induced by such an alternating scheme, we prove that the proposed algorithm converges to the Nash equilibrium with an explicit convergence rate. To the best of our knowledge, it is the first provably efficient algorithm that achieves learning while playing via alternating updates.
Inductive program synthesis, or inferring programs from examples of desired behavior, offers a general paradigm for building interpretable, robust, andgeneralizable machine learning systems. Effective program synthesis depends on two key ingredients: a strong library of functions from which to build programs, and an efficient search strategy for finding programs that solve a given task. We introduce LAPS (Language for Abstraction and Program Search), a technique for using natural language annotations to guide joint learning of libraries and neurally-guided search models for synthesis. When integrated into a state-of-the-art library learning system (DreamCoder), LAPS produces higher-quality libraries and improves search efficiency and generalization on three domains – string editing, image composition, and abstract reasoning about scenes – even when no natural language hints are available at test time.
While designing inductive bias in neural architectures has been widely studied, we hypothesize that transformer networks are flexible enough to learn inductive bias from suitable generic tasks. Here, we replace architecture engineering by encoding inductive bias in the form of datasets. Inspired by Peirce's view that deduction, induction, and abduction are the primitives of reasoning, we design three synthetic tasks that are intended to require the model to have these three abilities. We specifically design these tasks to be synthetic and devoid of mathematical knowledge to ensure that only the fundamental reasoning biases can be learned from these tasks. This defines a new pre-training methodology called "LIME" (Learning Inductive bias for Mathematical rEasoning). Models trained with LIME significantly outperform vanilla transformers on four very different large mathematical reasoning benchmarks. Unlike dominating the computation cost as traditional pre-training approaches, LIME requires only a small fraction of the computation cost of the typical downstream task. The code for generating LIME tasks is available at https://github.com/tonywu95/LIME.
A major challenge in reinforcement learning is the design of exploration strategies, especially for environments with sparse reward structures and continuous state and action spaces. Intuitively, if the reinforcement signal is very scarce, the agent should rely on some form of short-term memory in order to cover its environment efficiently. We propose a new exploration method, based on two intuitions: (1) the choice of the next exploratory action should depend not only on the (Markovian) state of the environment, but also on the agent's trajectory so far, and (2) the agent should utilize a measure of spread in the state space to avoid getting stuck in a small region. Our method leverages concepts often used in statistical physics to provide explanations for the behavior of simplified (polymer) chains in order to generate persistent (locally self-avoiding) trajectories in state space. We discuss the theoretical properties of locally self-avoiding walks and their ability to provide a kind of short-term memory through a decaying temporal correlation within the trajectory. We provide empirical evaluations of our approach in a simulated 2D navigation task, as well as higher-dimensional MuJoCo continuous control locomotion tasks with sparse rewards.
In deep model compression, the recent finding "Lottery Ticket Hypothesis" (LTH) pointed out that there could exist a winning ticket (i.e., a properly pruned sub-network together with original weight initialization) that can achieve competitive performance than the original dense network. However, it is not easy to observe such winning property in many scenarios, where for example, a relatively large learning rate is used even if it benefits training the original dense model. In this work, we investigate the underlying condition and rationale behind the winning property, and find that the underlying reason is largely attributed to the correlation between initialized weights and final-trained weights when the learning rate is not sufficiently large. Thus, the existence of winning property is correlated with an insufficient DNN pretraining, and is unlikely to occur for a well-trained DNN. To overcome this limitation, we propose the "pruning & fine-tuning" method that consistently outperforms lottery ticket sparse training under the same pruning algorithm and the same total training epochs. Extensive experiments over multiple deep models (VGG, ResNet, MobileNet-v2) on different datasets have been conducted to justify our proposals.
Low-precision training has become a popular approach to reduce compute requirements, memory footprint, and energy consumption in supervised learning. In contrast, this promising approach has not yet enjoyed similarly widespread adoption within the reinforcement learning (RL) community, partly because RL agents can be notoriously hard to train even in full precision. In this paper we consider continuous control with the state-of-the-art SAC agent and demonstrate that a na\"ive adaptation of low-precision methods from supervised learning fails. We propose a set of six modifications, all straightforward to implement, that leaves the underlying agent and its hyperparameters unchanged but improves the numerical stability dramatically. The resulting modified SAC agent has lower memory and compute requirements while matching full-precision rewards, demonstrating that low-precision training can substantially accelerate state-of-the-art RL without parameter tuning.
In recent years, methods were proposed for assigning feature importance scores to measure the contribution of individual features. While in some cases the goal is to understand a specific model, in many cases the goal is to understand the contribution of certain properties (features) to a real-world phenomenon. Thus, a distinction has been made between feature importance scores that explain a model and scores that explain the data. When explaining the data, machine learning models are used as proxies in settings where conducting many real-world experiments is expensive or prohibited. While existing feature importance scores show great success in explaining models, we demonstrate their limitations when explaining the data, especially in the presence of correlations between features. Therefore, we develop a set of axioms to capture properties expected from a feature importance score when explaining data and prove that there exists only one score that satisfies all of them, the Marginal Contribution Feature Importance (MCI). We analyze the theoretical properties of this score function and demonstrate its merits empirically.
With rapid progress in neural text-to-speech (TTS) models, personalized speech generation is now in high demand for many applications. For practical applicability, a TTS model should generate high-quality speech with only a few audio samples from the given speaker, that are also short in length. However, existing methods either require to fine-tune the model or achieve low adaptation quality without fine-tuning. In this work, we propose StyleSpeech, a new TTS model which not only synthesizes high-quality speech but also effectively adapts to new speakers. Specifically, we propose Style-Adaptive Layer Normalization (SALN) which aligns gain and bias of the text input according to the style extracted from a reference speech audio. With SALN, our model effectively synthesizes speech in the style of the target speaker even from a single speech audio. Furthermore, to enhance StyleSpeech's adaptation to speech from new speakers, we extend it to Meta-StyleSpeech by introducing two discriminators trained with style prototypes, and performing episodic training. The experimental results show that our models generate high-quality speech which accurately follows the speaker's voice with single short-duration (1-3 sec) speech audio, significantly outperforming baselines.
State-of-the-art deep reinforcement learning (DRL) algorithms tend to overfit due to the model discrepancy between source and target environments. Though applying domain randomization during training can improve the average performance by randomly generating a sufficient diversity of environments in simulator, the worst-case environment is still neglected without any performance guarantee. Since the average and worst-case performance are both important for generalization in RL, in this paper, we propose a policy optimization approach for concurrently improving the policy's performance in the average and worst-case environment. We theoretically derive a lower bound for the worst-case performance of a given policy by relating it to the expected performance. Guided by this lower bound, we formulate an optimization problem to jointly optimize the policy and sampling distribution, and prove that by iteratively solving it the worst-case performance is monotonically improved. We then develop a practical algorithm, named monotonic robust policy optimization (MRPO). Experimental evaluations in several robot control tasks demonstrate that MRPO can generally improve both the average and worst-case performance in the source environments for training, and facilitate in all cases the learned policy with a better generalization capability in some unseen testing environments.
https://drive.google.com/file/d/1lRV72XaKoxZjgQrLXBJhsM82x54_1Vc4/view?usp=sharing
Influence maximization is the task of selecting a small number of seed nodes in a social network to maximize the spread of the influence from these seeds, and it has been widely investigated in the past two decades. In the canonical setting, the whole social network as well as its diffusion parameters is given as input. In this paper, we consider the more realistic sampling setting where the network is unknown and we only have a set of passively observed cascades that record the set of activated nodes at each diffusion step. We study the task of influence maximization from these cascade samples (IMS), and present constant approximation algorithms for this task under mild conditions on the seed set distribution. To achieve the optimization goal, we also provide a novel solution to the network inference problem, that is, learning diffusion parameters and the network structure from the cascade data. Comparing with prior solutions, our network inference algorithm requires weaker assumptions and does not rely on maximum-likelihood estimation and convex programming. Our IMS algorithms enhance the learning-and-then-optimization approach by allowing a constant approximation ratio even when the diffusion parameters are hard to learn, and we do not need any assumption related …
Neural controlled differential equations (CDEs) are the continuous-time analogue of recurrent neural networks, as Neural ODEs are to residual networks, and offer a memory-efficient continuous-time way to model functions of potentially irregular time series. Existing methods for computing the forward pass of a Neural CDE involve embedding the incoming time series into path space, often via interpolation, and using evaluations of this path to drive the hidden state. Here, we use rough path theory to extend this formulation. Instead of directly embedding into path space, we instead represent the input signal over small time intervals through its \textit{log-signature}, which are statistics describing how the signal drives a CDE. This is the approach for solving \textit{rough differential equations} (RDEs), and correspondingly we describe our main contribution as the introduction of Neural RDEs. This extension has a purpose: by generalising the Neural CDE approach to a broader class of driving signals, we demonstrate particular advantages for tackling long time series. In this regime, we demonstrate efficacy on problems of length up to 17k observations and observe significant training speed-ups, improvements in model performance, and reduced memory requirements compared to existing approaches.
Many modern approaches to offline Reinforcement Learning (RL) utilize behavior regularization, typically augmenting a model-free actor critic algorithm with a penalty measuring divergence of the policy from the offline data. In this work, we propose an alternative approach to encouraging the learned policy to stay close to the data, namely parameterizing the critic as the log-behavior-policy, which generated the offline data, plus a state-action value offset term, which can be learned using a neural network. Behavior regularization then corresponds to an appropriate regularizer on the offset term. We propose using a gradient penalty regularizer for the offset term and demonstrate its equivalence to Fisher divergence regularization, suggesting connections to the score matching and generative energy-based model literature. We thus term our resulting algorithm Fisher-BRC (Behavior Regularized Critic). On standard offline RL benchmarks, Fisher-BRC achieves both improved performance and faster convergence over existing state-of-the-art methods.
Latent variable models have been playing a central role in statistics, econometrics, machine learning with applications to repeated observation study, panel data inference, user behavior analysis, etc. In many modern applications, the inference based on latent variable models involves one or several of the following features: the presence of complex latent structure, the observed and latent variables being continuous or discrete, constraints on parameters, and data size being large. Therefore, solving an estimation problem for general latent variable models is highly non-trivial. In this paper, we consider a gradient based method via using variance reduction technique to accelerate estimation procedure. Theoretically, we show the convergence results for the proposed method under general and mild model assumptions. The algorithm has better computational complexity compared with the classical gradient methods and maintains nice statistical properties. Various numerical results corroborate our theory.
We consider the problem of explaining the predictions of graph neural networks (GNNs), which otherwise are considered as black boxes. Existing methods invariably focus on explaining the importance of graph nodes or edges but ignore the substructures of graphs, which are more intuitive and human-intelligible. In this work, we propose a novel method, known as SubgraphX, to explain GNNs by identifying important subgraphs. Given a trained GNN model and an input graph, our SubgraphX explains its predictions by efficiently exploring different subgraphs with Monte Carlo tree search. To make the tree search more effective, we propose to use Shapley values as a measure of subgraph importance, which can also capture the interactions among different subgraphs. To expedite computations, we propose efficient approximation schemes to compute Shapley values for graph data. Our work represents the first attempt to explain GNNs via identifying subgraphs explicitly and directly. Experimental results show that our SubgraphX achieves significantly improved explanations, while keeping computations at a reasonable level.
Dictionary learning is a key tool for representation learning, that explains the data as linear combination of few basic elements. Yet, this analysis is not amenable in the context of graph learning, as graphs usually belong to different metric spaces. We fill this gap by proposing a new online Graph Dictionary Learning approach, which uses the Gromov Wasserstein divergence for the data fitting term. In our work, graphs are encoded through their nodes' pairwise relations and modeled as convex combination of graph atoms, i.e. dictionary elements, estimated thanks to an online stochastic algorithm, which operates on a dataset of unregistered graphs with potentially different number of nodes. Our approach naturally extends to labeled graphs, and is completed by a novel upper bound that can be used as a fast approximation of Gromov Wasserstein in the embedding space. We provide numerical evidences showing the interest of our approach for unsupervised embedding of graph datasets and for online graph subspace estimation and tracking.
We develop theory and algorithms for average-reward on-policy Reinforcement Learning (RL). We first consider bounding the difference of the long-term average reward for two policies. We show that previous work based on the discounted return (Schulman et al. 2015, Achiam et al. 2017) results in a non-meaningful lower bound in the average reward setting. By addressing the average-reward criterion directly, we then derive a novel bound which depends on the average divergence between the policies and on Kemeny's constant. Based on this bound, we develop an iterative procedure which produces a sequence of monotonically improved policies for the average reward criterion. This iterative procedure can then be combined with classic Deep Reinforcement Learning (DRL) methods, resulting in practical DRL algorithms that target the long-run average reward criterion. In particular, we demonstrate that Average-Reward TRPO (ATRPO), which adapts the on-policy TRPO algorithm to the average-reward criterion, significantly outperforms TRPO in the most challenging MuJuCo environments.
Modern policy gradient algorithms such as Proximal Policy Optimization (PPO) rely on an arsenal of heuristics, including loss clipping and gradient clipping, to ensure successful learning. These heuristics are reminiscent of techniques from robust statistics, commonly used for estimation in outlier-rich ("heavy-tailed") regimes. In this paper, we present a detailed empirical study to characterize the heavy-tailed nature of the gradients of the PPO surrogate reward function. We demonstrate that the gradients, especially for the actor network, exhibit pronounced heavy-tailedness and that it increases as the agent's policy diverges from the behavioral policy (i.e., as the agent goes further off policy). Further examination implicates the likelihood ratios and advantages in the surrogate reward as the main sources of the observed heavy-tailedness. We then highlight issues arising due to the heavy-tailed nature of the gradients. In this light, we study the effects of the standard PPO clipping heuristics, demonstrating that these tricks primarily serve to offset heavy-tailedness in gradients. Thus motivated, we propose incorporating GMOM, a high-dimensional robust estimator, into PPO as a substitute for three clipping tricks. Despite requiring less hyperparameter tuning, our method matches the performance of PPO (with all heuristics enabled) on a battery of MuJoCo continuous control tasks.
We show that the error of iteratively magnitude-pruned networks empirically follows a scaling law with interpretable coefficients that depend on the architecture and task. We functionally approximate the error of the pruned networks, showing it is predictable in terms of an invariant tying width, depth, and pruning level, such that networks of vastly different pruned densities are interchangeable. We demonstrate the accuracy of this approximation over orders of magnitude in depth, width, dataset size, and density. We show that the functional form holds (generalizes) for large scale data (e.g., ImageNet) and architectures (e.g., ResNets). As neural networks become ever larger and costlier to train, our findings suggest a framework for reasoning conceptually and analytically about a standard method for unstructured pruning.
Neural architecture search (NAS) automates the design of deep neural networks. One of the main challenges in searching complex and non-continuous architectures is to compare the similarity of networks that the conventional Euclidean metric may fail to capture. Optimal transport (OT) is resilient to such complex structure by considering the minimal cost for transporting a network into another. However, the OT is generally not negative definite which may limit its ability to build the positive-definite kernels required in many kernel-dependent frameworks. Building upon tree-Wasserstein (TW), which is a negative definite variant of OT, we develop a novel discrepancy for neural architectures, and demonstrate it within a Gaussian process surrogate model for the sequential NAS settings. Furthermore, we derive a novel parallel NAS, using quality k-determinantal point process on the GP posterior, to select diverse and high-performing architectures from a discrete set of candidates. Empirically, we demonstrate that our TW-based approaches outperform other baselines in both sequential and parallel NAS.
Distributional shift is one of the major obstacles when transferring machine learning prediction systems from the lab to the real world. To tackle this problem, we assume that variation across training domains is representative of the variation we might encounter at test time, but also that shifts at test time may be more extreme in magnitude. In particular, we show that reducing differences in risk across training domains can reduce a model’s sensitivity to a wide range of extreme distributional shifts, including the challenging setting where the input contains both causal and anti-causal elements. We motivate this approach, Risk Extrapolation (REx), as a form of robust optimization over a perturbation set of extrapolated domains (MM-REx), and propose a penalty on the variance of training risks (V-REx) as a simpler variant. We prove that variants of REx can recover the causal mechanisms of the targets, while also providing robustness to changes in the input distribution (``covariate shift''). By appropriately trading-off robustness to causally induced distributional shifts and covariate shift, REx is able to outperform alternative methods such as Invariant Risk Minimization in situations where these types of shift co-occur.
This paper introduces an alternative approach to sampling from autoregressive models. Autoregressive models are typically sampled sequentially, according to the transition dynamics defined by the model. Instead, we propose a sampling procedure that initializes a sequence with white noise and follows a Markov chain defined by Langevin dynamics on the global log-likelihood of the sequence. This approach parallelizes the sampling process and generalizes to conditional sampling. Using an autoregressive model as a Bayesian prior, we can steer the output of a generative model using a conditional likelihood or constraints. We apply these techniques to autoregressive models in the visual and audio domains, with competitive results for audio source separation, super-resolution, and inpainting.
Conveying complex objectives to reinforcement learning (RL) agents can often be difficult, involving meticulous design of reward functions that are sufficiently informative yet easy enough to provide. Human-in-the-loop RL methods allow practitioners to instead interactively teach agents through tailored feedback; however, such approaches have been challenging to scale since human feedback is very expensive. In this work, we aim to make this process more sample- and feedback-efficient. We present an off-policy, interactive RL algorithm that capitalizes on the strengths of both feedback and off-policy learning. Specifically, we learn a reward model by actively querying a teacher's preferences between two clips of behavior and use it to train an agent. To enable off-policy learning, we relabel all the agent's past experience when its reward model changes. We additionally show that pre-training our agents with unsupervised exploration substantially increases the mileage of its queries. We demonstrate that our approach is capable of learning tasks of higher complexity than previously considered by human-in-the-loop methods, including a variety of locomotion and robotic manipulation skills. We also show that our method is able to utilize real-time human feedback to effectively prevent reward exploitation and learn new behaviors that are difficult to specify with standard reward …
The difficulty in specifying rewards for many real-world problems has led to an increased focus on learning rewards from human feedback, such as demonstrations. However, there are often many different reward functions that explain the human feedback, leaving agents with uncertainty over what the true reward function is. While most policy optimization approaches handle this uncertainty by optimizing for expected performance, many applications demand risk-averse behavior. We derive a novel policy gradient-style robust optimization approach, PG-BROIL, that optimizes a soft-robust objective that balances expected performance and risk. To the best of our knowledge, PG-BROIL is the first policy optimization algorithm robust to a distribution of reward hypotheses which can scale to continuous MDPs. Results suggest that PG-BROIL can produce a family of behaviors ranging from risk-neutral to risk-averse and outperforms state-of-the-art imitation learning algorithms when learning from ambiguous demonstrations by hedging against uncertainty, rather than seeking to uniquely identify the demonstrator's reward function.
Progress in deep reinforcement learning (RL) research is largely enabled by benchmark task environments. However, analyzing the nature of those environments is often overlooked. In particular, we still do not have agreeable ways to measure the difficulty or solvability of a task, given that each has fundamentally different actions, observations, dynamics, rewards, and can be tackled with diverse RL algorithms. In this work, we propose policy information capacity (PIC) -- the mutual information between policy parameters and episodic return -- and policy-optimal information capacity (POIC) -- between policy parameters and episodic optimality -- as two environment-agnostic, algorithm-agnostic quantitative metrics for task difficulty. Evaluating our metrics across toy environments as well as continuous control benchmark tasks from OpenAI Gym and DeepMind Control Suite, we empirically demonstrate that these information-theoretic metrics have higher correlations with normalized task solvability scores than a variety of alternatives. Lastly, we show that these metrics can also be used for fast and compute-efficient optimizations of key design parameters such as reward shaping, policy architectures, and MDP properties for better solvability by RL algorithms without ever running full RL experiments.
We consider a best arm identification (BAI) problem for stochastic bandits with adversarial corruptions in the fixed-budget setting of T steps. We design a novel randomized algorithm, Probabilistic Sequential Shrinking(u) (PSS(u)), which is agnostic to the amount of corruptions. When the amount of corruptions per step (CPS) is below a threshold, PSS(u) identifies the best arm or item with probability tending to 1 as T→∞. Otherwise, the optimality gap of the identified item degrades gracefully with the CPS.We argue that such a bifurcation is necessary. In PSS(u), the parameter u serves to balance between the optimality gap and success probability. The injection of randomization is shown to be essential to mitigate the impact of corruptions. To demonstrate this, we design two attack strategies that are applicable to any algorithm. We apply one of them to a deterministic analogue of PSS(u) known as Successive Halving (SH) by Karnin et al. (2013). The attack strategy results in a high failure probability for SH, but PSS(u) remains robust. In the absence of corruptions, PSS(2)'s performance guarantee matches SH's. We show that when the CPS is sufficiently large, no algorithm can achieve a BAI probability tending to 1 as T→∞. Numerical experiments corroborate our …
Multi-agent settings in the real world often involve tasks with varying types and quantities of agents and non-agent entities; however, common patterns of behavior often emerge among these agents/entities. Our method aims to leverage these commonalities by asking the question: What is the expected utility of each agent when only considering a randomly selected sub-group of its observed entities?'' By posing this counterfactual question, we can recognize state-action trajectories within sub-groups of entities that we may have encountered in another task and use what we learned in that task to inform our prediction in the current one. We then reconstruct a prediction of the full returns as a combination of factors considering these disjoint groups of entities and train thisrandomly factorized" value function as an auxiliary objective for value-based multi-agent reinforcement learning. By doing so, our model can recognize and leverage similarities across tasks to improve learning efficiency in a multi-task setting. Our approach, Randomized Entity-wise Factorization for Imagined Learning (REFIL), outperforms all strong baselines by a significant margin in challenging multi-task StarCraft micromanagement settings.
Learning to flexibly follow task instructions in dynamic environments poses interesting challenges for reinforcement learning agents. We focus here on the problem of learning control flow that deviates from a strict step-by-step execution of instructions—that is, control flow that may skip forward over parts of the instructions or return backward to previously completed or skipped steps. Demand for such flexible control arises in two fundamental ways: explicitly when control is specified in the instructions themselves (such as conditional branching and looping) and implicitly when stochastic environment dynamics require re-completion of instructions whose effects have been perturbed, or opportunistic skipping of instructions whose effects are already present. We formulate an attention-based architecture that meets these challenges by learning, from task reward only, to flexibly attend to and condition behavior on an internal encoding of the instructions. We test the architecture's ability to learn both explicit and implicit control in two illustrative domains---one inspired by Minecraft and the other by StarCraft---and show that the architecture exhibits zero-shot generalization to novel instructions of length greater than those in a training set, at a performance level unmatched by three baseline recurrent architectures and one ablation architecture.
The recent work by Rendle et al. (2020), based on empirical observations, argues that matrix-factorization collaborative filtering (MCF) compares favorably to neural collaborative filtering (NCF), and conjectures the dot product's superiority over the feed-forward neural network as similarity function. In this paper, we address the comparison rigorously by answering the following questions: 1. what is the limiting expressivity of each model; 2. under the practical gradient descent, to which solution does each optimization path converge; 3. how would the models generalize under the inductive and transductive learning setting. Our results highlight the similar expressivity for the overparameterized NCF and MCF as kernelized predictors, and reveal the relation between their optimization paths. We further show their different generalization behaviors, where MCF and NCF experience specific tradeoff and comparison in the transductive and inductive collaborative filtering setting. Lastly, by showing a novel generalization result, we reveal the critical role of correcting exposure bias for model evaluation in the inductive setting. Our results explain some of the previously observed conflicts, and we provide synthetic and real-data experiments to shed further insights to this topic.
Boundary discontinuity and its inconsistency to the final detection metric have been the bottleneck for rotating detection regression loss design. In this paper, we propose a novel regression loss based on Gaussian Wasserstein distance as a fundamental approach to solve the problem. Specifically, the rotated bounding box is converted to a 2-D Gaussian distribution, which enables to approximate the indifferentiable rotational IoU induced loss by the Gaussian Wasserstein distance (GWD) which can be learned efficiently by gradient back-propagation. GWD can still be informative for learning even there is no overlapping between two rotating bounding boxes which is often the case for small object detection. Thanks to its three unique properties, GWD can also elegantly solve the boundary discontinuity and square-like problem regardless how the bounding box is defined. Experiments on five datasets using different detectors show the effectiveness of our approach, and codes are available at https://github.com/yangxue0827/RotationDetection.
Policies for partially observed Markov decision processes can be efficiently learned by imitating expert policies generated using asymmetric information. Unfortunately, existing approaches for this kind of imitation learning have a serious flaw: the expert does not know what the trainee cannot see, and as a result may encourage actions that are sub-optimal or unsafe under partial information. To address this issue, we derive an update which, when applied iteratively to an expert, maximizes the expected reward of the trainee's policy. Using this update, we construct a computationally efficient algorithm, adaptive asymmetric DAgger (A2D), that jointly trains the expert and trainee policies. We then show that A2D allows the trainee to safely imitate the modified expert, and outperforms policies learned either by imitating a fixed expert or through direct reinforcement learning.
The ability to autonomously learn behaviors via direct interactions in uninstrumented environments can lead to generalist robots capable of enhancing productivity or providing care in unstructured settings like homes. Such uninstrumented settings warrant operations only using the robot’s proprioceptive sensor such as onboard cameras, joint encoders, etc which can be challenging for policy learning owing to the high dimensionality and partial observability issues. We propose RRL: Resnet as representation for Reinforcement Learning – a straightforward yet effective approach that can learn complex behaviors directly from proprioceptive inputs. RRL fuses features extracted from pre-trained Resnet into the standard reinforcement learning pipeline and delivers results comparable to learning directly from the state. In a simulated dexterous manipulation benchmark, where the state of the art methods fails to make significant progress, RRL delivers contact rich behaviors. The appeal of RRL lies in its simplicity in bringing together progress from the fields of Representation Learning, Imitation Learning, and Reinforcement Learning. Its effectiveness in learning behaviors directly from visual inputs with performance and sample efficiency matching learning directly from the state, even in complex high dimensional domains, is far from obvious.
Modeling sets is an important problem in machine learning since this type of data can be found in many domains. A promising approach defines a family of permutation invariant densities with continuous normalizing flows. This allows us to maximize the likelihood directly and sample new realizations with ease. In this work, we demonstrate how calculating the trace, a crucial step in this method, raises issues that occur both during training and inference, limiting its practicality. We propose an alternative way of defining permutation equivariant transformations that give closed form trace. This leads not only to improvements while training, but also to better final performance. We demonstrate the benefits of our approach on point processes and general set modeling.
AlphaStar, the AI that reaches GrandMaster level in StarCraft II, is a remarkable milestone demonstrating what deep reinforcement learning can achieve in complex Real-Time Strategy (RTS) games. However, the complexities of the game, algorithms and systems, and especially the tremendous amount of computation needed are big obstacles for the community to conduct further research in this direction. We propose a deep reinforcement learning agent, StarCraft Commander (SCC). With order of magnitude less computation, it demonstrates top human performance defeating GrandMaster players in test matches and top professional players in a live event. Moreover, it shows strong robustness to various human strategies and discovers novel strategies unseen from human plays. In this paper, we’ll share the key insights and optimizations on efficient imitation learning and reinforcement learning for StarCraft II full game.
Generalization has been a long-standing challenge for reinforcement learning (RL). Visual RL, in particular, can be easily distracted by irrelevant factors in high-dimensional observation space. In this work, we consider robust policy learning which targets zero-shot generalization to unseen visual environments with large distributional shift. We propose SECANT, a novel self-expert cloning technique that leverages image augmentation in two stages to decouple robust representation learning from policy optimization. Specifically, an expert policy is first trained by RL from scratch with weak augmentations. A student network then learns to mimic the expert policy by supervised learning with strong augmentations, making its representation more robust against visual variations compared to the expert. Extensive experiments demonstrate that SECANT significantly advances the state of the art in zero-shot generalization across 4 challenging domains. Our average reward improvements over prior SOTAs are: DeepMind Control (+26.5%), robotic manipulation (+337.8%), vision-based autonomous driving (+47.7%), and indoor object navigation (+15.8%). Code release and video are available at https://linxifan.github.io/secant-site/.
Existing deep learning methods for solving mean-field games (MFGs) with common noise fix the sampling common noise paths and then solve the corresponding MFGs. This leads to a nested loop structure with millions of simulations of common noise paths in order to produce accurate solutions, which results in prohibitive computational cost and limits the applications to a large extent. In this paper, based on the rough path theory, we propose a novel single-loop algorithm, named signatured deep fictitious play (Sig-DFP), by which we can work with the unfixed common noise setup to avoid the nested loop structure and reduce the computational complexity significantly. The proposed algorithm can accurately capture the effect of common uncertainty changes on mean-field equilibria without further training of neural networks, as previously needed in the existing machine learning algorithms. The efficiency is supported by three applications, including linear-quadratic MFGs, mean-field portfolio game, and mean-field game of optimal consumption and investment. Overall, we provide a new point of view from the rough path theory to solve MFGs with common noise with significantly improved efficiency and an extensive range of applications. In addition, we report the first deep learning work to deal with extended MFGs (a mean-field interaction …
Deep equilibrium networks (DEQs) are a new class of models that eschews traditional depth in favor of finding the fixed point of a single non-linear layer. These models have been shown to achieve performance competitive with the state-of-the-art deep networks while using significantly less memory. Yet they are also slower, brittle to architectural choices, and introduce potential instability to the model. In this paper, we propose a regularization scheme for DEQ models that explicitly regularizes the Jacobian of the fixed-point update equations to stabilize the learning of equilibrium models. We show that this regularization adds only minimal computational cost, significantly stabilizes the fixed-point convergence in both forward and backward passes, and scales well to high-dimensional, realistic domains (e.g., WikiText-103 language modeling and ImageNet classification). Using this method, we demonstrate, for the first time, an implicit-depth model that runs with approximately the same speed and level of performance as popular conventional deep networks such as ResNet-101, while still maintaining the constant memory footprint and architectural simplicity of DEQs. Code is available https://github.com/locuslab/deq.
Recent works apply Graph Neural Networks (GNNs) to graph matching tasks and show promising results. Considering that model outputs are complex matchings, we devise several techniques to improve the learning of GNNs and obtain a new model, Stochastic Iterative Graph MAtching (SIGMA). Our model predicts a distribution of matchings, instead of a single matching, for a graph pair so the model can explore several probable matchings. We further introduce a novel multi-step matching procedure, which learns how to refine a graph pair's matching results incrementally. The model also includes dummy nodes so that the model does not have to find matchings for nodes without correspondence. We fit this model to data via scalable stochastic optimization. We conduct extensive experiments across synthetic graph datasets as well as biochemistry and computer vision applications. Across all tasks, our results show that SIGMA can produce significantly improved graph matching results compared to state-of-the-art models. Ablation studies verify that each of our components (stochastic training, iterative matching, and dummy nodes) offers noticeable improvement.
Sequence learning has attracted much research attention from the machine learning community in recent years. In many applications, a sequence learning task is usually associated with multiple temporally correlated auxiliary tasks, which are different in terms of how much input information to use or which future step to predict. For example, (i) in simultaneous machine translation, one can conduct translation under different latency (i.e., how many input words to read/wait before translation); (ii) in stock trend forecasting, one can predict the price of a stock in different future days (e.g., tomorrow, the day after tomorrow). While it is clear that those temporally correlated tasks can help each other, there is a very limited exploration on how to better leverage multiple auxiliary tasks to boost the performance of the main task. In this work, we introduce a learnable scheduler to sequence learning, which can adaptively select auxiliary tasks for training depending on the model status and the current training data. The scheduler and the model for the main task are jointly trained through bi-level optimization. Experiments show that our method significantly improves the performance of simultaneous machine translation and stock trend forecasting.
Model parallelism has become a necessity for training modern large-scale deep language models. In this work, we identify a new and orthogonal dimension from existing model parallel approaches: it is possible to perform pipeline parallelism within a single training sequence for Transformer-based language models thanks to its autoregressive property. This enables a more fine-grained pipeline compared with previous work. With this key idea, we design TeraPipe, a high-performance token-level pipeline parallel algorithm for synchronous model-parallel training of Transformer-based language models. We develop a novel dynamic programming-based algorithm to calculate the optimal pipelining execution scheme given a specific model and cluster configuration. We show that TeraPipe can speed up the training by 5.0x for the largest GPT-3 model with 175 billion parameters on an AWS cluster with 48 p3.16xlarge instances compared with state-of-the-art model-parallel methods. The code for reproduction can be found at https://github.com/zhuohan123/terapipe
Individuality is essential in human society. It induces the division of labor and thus improves the efficiency and productivity. Similarly, it should also be a key to multi-agent cooperation. Inspired by that individuality is of being an individual separate from others, we propose a simple yet efficient method for the emergence of individuality (EOI) in multi-agent reinforcement learning (MARL). EOI learns a probabilistic classifier that predicts a probability distribution over agents given their observation and gives each agent an intrinsic reward of being correctly predicted by the classifier. The intrinsic reward encourages the agents to visit their own familiar observations, and learning the classifier by such observations makes the intrinsic reward signals stronger and in turn makes the agents more identifiable. To further enhance the intrinsic reward and promote the emergence of individuality, two regularizers are proposed to increase the discriminability of the classifier. We implement EOI on top of popular MARL algorithms. Empirically, we show that EOI outperforms existing methods in a variety of multi-agent cooperative scenarios.
In the stochastic submodular cover problem, the goal is to select a subset of stochastic items of minimum expected cost to cover a submodular function. Solutions in this setting correspond to a sequential decision process that selects items one by one ``adaptively'' (depending on prior observations). While such adaptive solutions achieve the best objective, the inherently sequential nature makes them undesirable in many applications. We ask: \emph{how well can solutions with only a few adaptive rounds approximate fully-adaptive solutions?} We consider both cases where the stochastic items are independent, and where they are correlated. For both situations, we obtain nearly tight answers, establishing smooth tradeoffs between the number of adaptive rounds and the solution quality, relative to fully adaptive solutions. Experiments on synthetic and real datasets validate the practical performance of our algorithms, showing qualitative improvements in the solutions as we allow more rounds of adaptivity; in practice, solutions using just a few rounds of adaptivity are nearly as good as fully adaptive solutions.
We consider the problem of minimizing the sum of three functions, one of which is nonconvex but differentiable, and the other two are convex but possibly nondifferentiable. We investigate the Three Operator Splitting method (TOS) of Davis & Yin (2017) with an aim to extend its theoretical guarantees for this nonconvex problem template. In particular, we prove convergence of TOS with nonasymptotic bounds on its nonstationarity and infeasibility errors. In contrast with the existing work on nonconvex TOS, our guarantees do not require additional smoothness assumptions on the terms comprising the objective; hence they cover instances of particular interest where the nondifferentiable terms are indicator functions. We also extend our results to a stochastic setting where we have access only to an unbiased estimator of the gradient. Finally, we illustrate the effectiveness of the proposed method through numerical experiments on quadratic assignment problems.
The Laplacian representation recently gains increasing attention for reinforcement learning as it provides succinct and informative representation for states, by taking the eigenvectors of the Laplacian matrix of the state-transition graph as state embeddings. Such representation captures the geometry of the underlying state space and is beneficial to RL tasks such as option discovery and reward shaping. To approximate the Laplacian representation in large (or even continuous) state spaces, recent works propose to minimize a spectral graph drawing objective, which however has infinitely many global minimizers other than the eigenvectors. As a result, their learned Laplacian representation may differ from the ground truth. To solve this problem, we reformulate the graph drawing objective into a generalized form and derive a new learning objective, which is proved to have eigenvectors as its unique global minimizer. It enables learning high-quality Laplacian representations that faithfully approximate the ground truth. We validate this via comprehensive experiments on a set of gridworld and continuous control environments. Moreover, we show that our learned Laplacian representations lead to more exploratory options and better reward shaping.
We study the problem of zero-shot coordination (ZSC), where agents must independently produce strategies for a collaborative game that are compatible with novel partners not seen during training. Our first contribution is to consider the need for diversity in generating such agents. Because self-play (SP) agents control their own trajectory distribution during training, each policy typically only performs well on this exact distribution. As a result, they achieve low scores in ZSC, since playing with another agent is likely to put them in situations they have not encountered during training. To address this issue, we train a common best response (BR) to a population of agents, which we regulate to be diverse. To this end, we introduce \textit{Trajectory Diversity} (TrajeDi) -- a differentiable objective for generating diverse reinforcement learning policies. We derive TrajeDi as a generalization of the Jensen-Shannon divergence between policies and motivate it experimentally in two simple settings. We then focus on the collaborative card game Hanabi, demonstrating the scalability of our method and improving upon the cross-play scores of both independently trained SP agents and BRs to unregularized populations.
Offline Reinforcement Learning promises to learn effective policies from previously-collected, static datasets without the need for exploration. However, existing Q-learning and actor-critic based off-policy RL algorithms fail when bootstrapping from out-of-distribution (OOD) actions or states. We hypothesize that a key missing ingredient from the existing methods is a proper treatment of uncertainty in the offline setting. We propose Uncertainty Weighted Actor-Critic (UWAC), an algorithm that detects OOD state-action pairs and down-weights their contribution in the training objectives accordingly. Implementation-wise, we adopt a practical and effective dropout-based uncertainty estimation method that introduces very little overhead over existing RL algorithms. Empirically, we observe that UWAC substantially improves model stability during training. In addition, UWAC out-performs existing offline RL methods on a variety of competitive tasks, and achieves significant performance gains over the state-of-the-art baseline on datasets with sparse demonstrations collected from human experts.
Deep generative models (DGMs) seem a natural fit for detecting out-of-distribution (OOD) inputs, but such models have been shown to assign higher probabilities or densities to OOD images than images from the training distribution. In this work, we explain why this behavior should be attributed to model misestimation. We first prove that no method can guarantee performance beyond random chance without assumptions on which out-distributions are relevant. We then interrogate the typical set hypothesis, the claim that relevant out-distributions can lie in high likelihood regions of the data distribution, and that OOD detection should be defined based on the data distribution's typical set. We highlight the consequences implied by assuming support overlap between in- and out-distributions, as well as the arbitrariness of the typical set for OOD detection. Our results suggest that estimation error is a more plausible explanation than the misalignment between likelihood-based OOD detection and out-distributions of interest, and we illustrate how even minimal estimation error can lead to OOD detection failures, yielding implications for future work in deep generative modeling and OOD detection.
This paper presents new estimates of the score function and its gradient with respect to the model parameters in a general energy-based latent variable model (EBLVM). The score function and its gradient can be expressed as combinations of expectation and covariance terms over the (generally intractable) posterior of the latent variables. New estimates are obtained by introducing a variational posterior to approximate the true posterior in these terms. The variational posterior is trained to minimize a certain divergence (e.g., the KL divergence) between itself and the true posterior. Theoretically, the divergence characterizes upper bounds of the bias of the estimates. In principle, our estimates can be applied to a wide range of objectives, including kernelized Stein discrepancy (KSD), score matching (SM)-based methods and exact Fisher divergence with a minimal model assumption. In particular, these estimates applied to SM-based methods outperform existing methods in learning EBLVMs on several image datasets.
Stochastic Neural Networks (SNNs) that inject noise into their hidden layers have recently been shown to achieve strong robustness against adversarial attacks. However, existing SNNs are usually heuristically motivated, and often rely on adversarial training, which is computationally costly. We propose a new SNN that achieves state-of-the-art performance without relying on adversarial training, and enjoys solid theoretical justification. Specifically, while existing SNNs inject learned or hand-tuned isotropic noise, our SNN learns an anisotropic noise distribution to optimize a learning-theoretic bound on adversarial robustness. We evaluate our method on a number of popular benchmarks, show that it can be applied to different architectures, and that it provides robustness to a variety of white-box and black-box attacks, while being simple and fast to train compared to existing alternatives.
Object detection has recently achieved a breakthrough for removing the last one non-differentiable component in the pipeline, Non-Maximum Suppression (NMS), and building up an end-to-end system. However, what makes for its one-to-one prediction has not been well understood. In this paper, we first point out that one-to-one positive sample assignment is the key factor, while, one-to-many assignment in previous detectors causes redundant predictions in inference. Second, we surprisingly find that even training with one-to-one assignment, previous detectors still produce redundant predictions. We identify that classification cost in matching cost is the main ingredient: (1) previous detectors only consider location cost, (2) by additionally introducing classification cost, previous detectors immediately produce one-to-one prediction during inference. We introduce the concept of score gap to explore the effect of matching cost. Classification cost enlarges the score gap by choosing positive samples as those of highest score in the training iteration and reducing noisy positive samples brought by only location cost. Finally, we demonstrate the advantages of end-to-end object detection on crowded scenes.
Text-to-image generation has traditionally focused on finding better modeling assumptions for training on a fixed dataset. These assumptions might involve complex architectures, auxiliary losses, or side information such as object part labels or segmentation masks supplied during training. We describe a simple approach for this task based on a transformer that autoregressively models the text and image tokens as a single stream of data. With sufficient data and scale, our approach is competitive with previous domain-specific models when evaluated in a zero-shot fashion.
Oral: Deep Learning Theory 2 Wed 21 Jul 02:00 p.m.

Energy-based models (EBMs) are a simple yet powerful framework for generative modeling. They are based on a trainable energy function which defines an associated Gibbs measure, and they can be trained and sampled from via well-established statistical tools, such as MCMC. Neural networks may be used as energy function approximators, providing both a rich class of expressive models as well as a flexible device to incorporate data structure. In this work we focus on shallow neural networks. Building from the incipient theory of overparametrized neural networks, we show that models trained in the so-called 'active' regime provide a statistical advantage over their associated 'lazy' or kernel regime, leading to improved adaptivity to hidden low-dimensional structure in the data distribution, as already observed in supervised learning. Our study covers both the maximum likelihood and Stein Discrepancy estimators, and we validate our theoretical results with numerical experiments on synthetic data.

The compelling synthesis results of Generative Adversarial Networks (GANs) demonstrate rich semantic knowledge in their latent codes. To obtain this knowledge for downstream applications, encoding GANs has been proposed to learn encoders, such that real world data can be encoded to latent codes, which can be fed to generators to reconstruct those data.
However, despite the theoretical guarantees of precise reconstruction in previous works, current algorithms generally reconstruct inputs with non-negligible deviations from inputs. In this paper we study this predicament of encoding GANs, which is indispensable research for the GAN community. We prove three uncertainty principles of encoding GANs in practice: a) the perfect' encoder and generator cannot be continuous at the same time, which implies that current framework of encoding GANs is ill-posed and needs rethinking; b) neural networks cannot approximate the underlying encoder and generator precisely at the same time, which explains why we cannot getperfect' encoders and generators as promised in previous theories; c) neural networks cannot be stable and accurate at the same time, which demonstrates the difficulty of training and trade-off between fidelity and disentanglement encountered in previous works. Our work may eliminate gaps between previous theories and empirical results, promote the understanding …


Recent work demonstrated the benefits of studying continuous-time dynamics governing the GAN training. However, this dynamics is analyzed in the model parameter space, which results in finite-dimensional dynamical systems. We propose a novel perspective where we study the local dynamics of adversarial training in the general functional space and show how it can be represented as a system of partial differential equations. Thus, the convergence properties can be inferred from the eigenvalues of the resulting differential operator. We show that these eigenvalues can be efficiently estimated from the target dataset before training. Our perspective reveals several insights on the practical tricks commonly used to stabilize GANs, such as gradient penalty, data augmentation, and advanced integration schemes. As an immediate practical benefit, we demonstrate how one can a priori select an optimal data augmentation strategy for a particular generation task.


We consider a one-hidden-layer leaky ReLU network of arbitrary width trained by stochastic gradient descent (SGD) following an arbitrary initialization. We prove that SGD produces neural networks that have classification accuracy competitive with that of the best halfspace over the distribution for a broad class of distributions that includes log-concave isotropic and hard margin distributions. Equivalently, such networks can generalize when the data distribution is linearly separable but corrupted with adversarial label noise, despite the capacity to overfit. To the best of our knowledge, this is the first work to show that overparameterized neural networks trained by SGD can generalize when the data is corrupted with adversarial label noise.
Oral: Learning Theory 1 Wed 21 Jul 02:00 p.m.


We make progress in a long-standing problem of batch reinforcement learning (RL): learning Q* from an exploratory and polynomial-sized dataset, using a realizable and otherwise arbitrary function class. In fact, all existing algorithms demand function-approximation assumptions stronger than realizability, and the mounting negative evidence has led to a conjecture that sample-efficient learning is impossible in this setting (Chen & Jiang, 2019). Our algorithm, BVFT, breaks the hardness conjecture (albeit under a stronger notion of exploratory data) via a tournament procedure that reduces the learning problem to pairwise comparison, and solves the latter with the help of a state-action-space partition constructed from the compared functions. We also discuss how BVFT can be applied to model selection among other extensions and open problems.


When decision-makers can directly intervene, policy evaluation algorithms give valid causal estimates. In off-policy evaluation (OPE), there may exist unobserved variables that both impact the dynamics and are used by the unknown behavior policy. These ``confounders'' will introduce spurious correlations and naive estimates for a new policy will be biased. We develop worst-case bounds to assess sensitivity to these unobserved confounders in finite horizons when confounders are drawn iid each period. We demonstrate that a model-based approach with robust MDPs gives sharper lower bounds by exploiting domain knowledge about the dynamics. Finally, we show that when unobserved confounders are persistent over time, OPE is far more difficult and existing techniques produce extremely conservative bounds.
Bootstrapping provides a flexible and effective approach for assessing the quality of batch reinforcement learning, yet its theoretical properties are poorly understood. In this paper, we study the use of bootstrapping in off-policy evaluation (OPE), and in particular, we focus on the fitted Q-evaluation (FQE) that is known to be minimax-optimal in the tabular and linear-model cases. We propose a bootstrapping FQE method for inferring the distribution of the policy evaluation error and show that this method is asymptotically efficient and distributionally consistent for off-policy statistical inference. To overcome the computation limit of bootstrapping, we further adapt a subsampling procedure that improves the runtime by an order of magnitude. We numerically evaluate the bootrapping method in classical RL environments for confidence interval estimation, estimating the variance of off-policy evaluator, and estimating the correlation between multiple off-policy evaluators.

Deep learning empirically achieves high performance in many applications, but its training dynamics has not been fully understood theoretically. In this paper, we explore theoretical analysis on training two-layer ReLU neural networks in a teacher-student regression model, in which a student network learns an unknown teacher network through its outputs. We show that with a specific regularization and sufficient over-parameterization, the student network can identify the parameters of the teacher network with high probability via gradient descent with a norm dependent stepsize even though the objective function is highly non-convex. The key theoretical tool is the measure representation of the neural networks and a novel application of a dual certificate argument for sparse estimation on a measure space. We analyze the global minima and global convergence property in the measure space.

Graph sparsification is a powerful tool to approximate an arbitrary graph and has been used in machine learning over graphs. As real-world networks are becoming very large and naturally distributed, distributed graph sparsification has drawn considerable attention. In this work, we design communication-efficient distributed algorithms for constructing spectral vertex sparsifiers, which closely preserve effective resistance distances on a subset of vertices of interest in the original graphs, under the well-established message passing communication model. We prove that the communication cost approximates the lower bound with only a small gap. We further provide algorithms for constructing pair-wise spanners which approximate the shortest distances between each pair of vertices in a target set, instead of all pairs, and incur communication costs that are much smaller than those of existing algorithms in the message passing model. Experiments are performed to validate the communication efficiency of the proposed algorithms under the guarantee that the constructed sparsifiers have a good approximation quality.
Oral: Supervised Learning 1 Wed 21 Jul 02:00 p.m.


Deep extreme multi-label learning (XML) requires training deep architectures that can tag a data point with its most relevant subset of labels from an extremely large label set. XML applications such as ad and product recommendation involve labels rarely seen during training but which nevertheless hold the key to recommendations that delight users. Effective utilization of label metadata and high quality predictions for rare labels at the scale of millions of labels are thus key challenges in contemporary XML research. To address these, this paper develops the SiameseXML framework based on a novel probabilistic model that naturally motivates a modular approach melding Siamese architectures with high-capacity extreme classifiers, and a training pipeline that effortlessly scales to tasks with 100 million labels. SiameseXML offers predictions 2--13% more accurate than leading XML methods on public benchmark datasets, as well as in live A/B tests on the Bing search engine, it offers significant gains in click-through-rates, coverage, revenue and other online metrics over state-of-the-art techniques currently in production. Code for SiameseXML is available at https://github.com/Extreme-classification/siamesexml

Negative sampling schemes enable efficient training given a large number of classes, by offering a means to approximate a computationally expensive loss function that takes all labels into account. In this paper, we present a new connection between these schemes and loss modification techniques for countering label imbalance. We show that different negative sampling schemes implicitly trade-off performance on dominant versus rare labels. Further, we provide a unified means to explicitly tackle both sampling bias, arising from working with a subset of all labels, and labeling bias, which is inherent to the data due to label imbalance. We empirically verify our findings on long-tail classification and retrieval benchmarks.
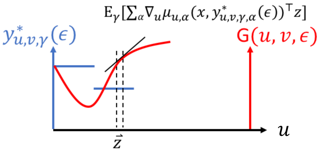
Direct loss minimization is a popular approach for learning predictors over structured label spaces. This approach is computationally appealing as it replaces integration with optimization and allows to propagate gradients in a deep net using loss-perturbed prediction. Recently, this technique was extended to generative models, by introducing a randomized predictor that samples a structure from a randomly perturbed score function. In this work, we interpolate between these techniques by learning the variance of randomized structured predictors as well as their mean, in order to balance between the learned score function and the randomized noise. We demonstrate empirically the effectiveness of learning this balance in structured discrete spaces.

Rationalizing which parts of a molecule drive the predictions of a molecular graph convolutional neural network (GCNN) can be difficult. To help, we propose two simple regularization techniques to apply during the training of GCNNs: Batch Representation Orthonormalization (BRO) and Gini regularization. BRO, inspired by molecular orbital theory, encourages graph convolution operations to generate orthonormal node embeddings. Gini regularization is applied to the weights of the output layer and constrains the number of dimensions the model can use to make predictions. We show that Gini and BRO regularization can improve the accuracy of state-of-the-art GCNN attribution methods on artificial benchmark datasets. In a real-world setting, we demonstrate that medicinal chemists significantly prefer explanations extracted from regularized models. While we only study these regularizers in the context of GCNNs, both can be applied to other types of neural networks.

Dirichlet-based uncertainty (DBU) models are a recent and promising class of uncertainty-aware models. DBU models predict the parameters of a Dirichlet distribution to provide fast, high-quality uncertainty estimates alongside with class predictions. In this work, we present the first large-scale, in-depth study of the robustness of DBU models under adversarial attacks. Our results suggest that uncertainty estimates of DBU models are not robust w.r.t. three important tasks: (1) indicating correctly and wrongly classified samples; (2) detecting adversarial examples; and (3) distinguishing between in-distribution (ID) and out-of-distribution (OOD) data. Additionally, we explore the first approaches to make DBU mod- els more robust. While adversarial training has a minor effect, our median smoothing based ap- proach significantly increases robustness of DBU models.

The surrogate that predicts the performance of hyperparameters has been a key component for sequential model-based hyperparameter optimization. In practical applications, a trial of a hyper-parameter configuration may be so costly that a surrogate is expected to return an optimal configuration with as few trials as possible. Observing that human experts draw on their expertise in a machine learning model by trying configurations that once performed well on other datasets, we are inspired to build a trial-efficient surrogate by transferring the meta-knowledge learned from historical trials on other datasets. We propose an end-to-end surrogate named as Transfer NeuralProcesses (TNP) that learns a comprehensive set of meta-knowledge, including the parameters of historical surrogates, historical trials, and initial configurations for other datasets. Experiments on extensive OpenML datasets and three computer vision datasets demonstrate that the proposed algorithm achieves state-of-the-art performance in at least one order of magnitude less trials.
Oral: Reinforcement Learning 11 Wed 21 Jul 02:00 p.m.

We introduce a new unsupervised pretraining objective for reinforcement learning. During the unsupervised reward-free pretraining phase, the agent maximizes mutual information between tasks and states induced by the policy. Our key contribution is a novel lower bound of this intractable quantity. We show that by reinterpreting and combining variational successor features~\citep{Hansen2020Fast} with nonparametric entropy maximization~\citep{liu2021behavior}, the intractable mutual information can be efficiently optimized. The proposed method Active Pretraining with Successor Feature (APS) explores the environment via nonparametric entropy maximization, and the explored data can be efficiently leveraged to learn behavior by variational successor features. APS addresses the limitations of existing mutual information maximization based and entropy maximization based unsupervised RL, and combines the best of both worlds. When evaluated on the Atari 100k data-efficiency benchmark, our approach significantly outperforms previous methods combining unsupervised pretraining with task-specific finetuning.

Solving sparse reward tasks through exploration is one of the major challenges in deep reinforcement learning, especially in three-dimensional, partially-observable environments. Critically, the algorithm proposed in this article is capable of using a single human demonstration to solve hard-exploration problems. We train an agent on a combination of demonstrations and own experience to solve problems with variable initial conditions and we integrate it with proximal policy optimization (PPO). The agent is also able to increase its performance and to tackle harder problems by replaying its own past trajectories prioritizing them based on the obtained reward and the maximum value of the trajectory. We finally compare variations of this algorithm to different imitation learning algorithms on a set of hard-exploration tasks in the Animal-AI Olympics environment. To the best of our knowledge, learning a task in a three-dimensional environment with comparable difficulty has never been considered before using only one human demonstration.

Reinforcement learning (RL) has made a lot of advances for solving a single problem in a given environment; but learning policies that generalize to unseen variations of a problem remains challenging. To improve sample efficiency for learning on such instances of a problem domain, we present Self-Paced Context Evaluation (SPaCE). Based on self-paced learning, SPaCE automatically generates instance curricula online with little computational overhead. To this end, SPaCE leverages information contained in state values during training to accelerate and improve training performance as well as generalization capabilities to new \tasks from the same problem domain. Nevertheless, SPaCE is independent of the problem domain at hand and can be applied on top of any RL agent with state-value function approximation. We demonstrate SPaCE's ability to speed up learning of different value-based RL agents on two environments, showing better generalization capabilities and up to 10x faster learning compared to naive approaches such as round robin or SPDRL, as the closest state-of-the-art approach.

Having the ability to acquire inherent skills from environments without any external rewards or supervision like humans is an important problem. We propose a novel unsupervised skill discovery method named Information Bottleneck Option Learning (IBOL). On top of the linearization of environments that promotes more various and distant state transitions, IBOL enables the discovery of diverse skills. It provides the abstraction of the skills learned with the information bottleneck framework for the options with improved stability and encouraged disentanglement. We empirically demonstrate that IBOL outperforms multiple state-of-the-art unsupervised skill discovery methods on the information-theoretic evaluations and downstream tasks in MuJoCo environments, including Ant, HalfCheetah, Hopper and D'Kitty. Our code is available at https://vision.snu.ac.kr/projects/ibol.
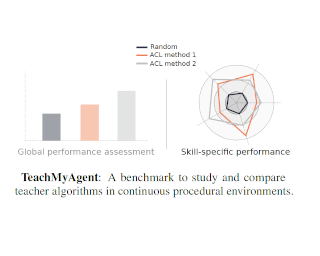
Training autonomous agents able to generalize to multiple tasks is a key target of Deep Reinforcement Learning (DRL) research. In parallel to improving DRL algorithms themselves, Automatic Curriculum Learning (ACL) study how teacher algorithms can train DRL agents more efficiently by adapting task selection to their evolving abilities. While multiple standard benchmarks exist to compare DRL agents, there is currently no such thing for ACL algorithms. Thus, comparing existing approaches is difficult, as too many experimental parameters differ from paper to paper. In this work, we identify several key challenges faced by ACL algorithms. Based on these, we present TeachMyAgent (TA), a benchmark of current ACL algorithms leveraging procedural task generation. It includes 1) challenge-specific unit-tests using variants of a procedural Box2D bipedal walker environment, and 2) a new procedural Parkour environment combining most ACL challenges, making it ideal for global performance assessment. We then use TeachMyAgent to conduct a comparative study of representative existing approaches, showcasing the competitiveness of some ACL algorithms that do not use expert knowledge. We also show that the Parkour environment remains an open problem. We open-source our environments, all studied ACL algorithms (collected from open-source code or re-implemented), and DRL students in a Python …

We investigate the use of natural language to drive the generalization of control policies and introduce the new multi-task environment Messenger with free-form text manuals describing the environment dynamics. Unlike previous work, Messenger does not assume prior knowledge connecting text and state observations — the control policy must simultaneously ground the game manual to entity symbols and dynamics in the environment. We develop a new model, EMMA (Entity Mapper with Multi-modal Attention) which uses an entity-conditioned attention module that allows for selective focus over relevant descriptions in the manual for each entity in the environment. EMMA is end-to-end differentiable and learns a latent grounding of entities and dynamics from text to observations using only environment rewards. EMMA achieves successful zero-shot generalization to unseen games with new dynamics, obtaining a 40% higher win rate compared to multiple baselines. However, win rate on the hardest stage of Messenger remains low (10%), demonstrating the need for additional work in this direction.

We introduce Hindsight Off-policy Options (HO2), a data-efficient option learning algorithm. Given any trajectory, HO2 infers likely option choices and backpropagates through the dynamic programming inference procedure to robustly train all policy components off-policy and end-to-end. The approach outperforms existing option learning methods on common benchmarks. To better understand the option framework and disentangle benefits from both temporal and action abstraction, we evaluate ablations with flat policies and mixture policies with comparable optimization. The results highlight the importance of both types of abstraction as well as off-policy training and trust-region constraints, particularly in challenging, simulated 3D robot manipulation tasks from raw pixel inputs. Finally, we intuitively adapt the inference step to investigate the effect of increased temporal abstraction on training with pre-trained options and from scratch.
Oral: Probabilistic Methods 1 Wed 21 Jul 02:00 p.m.

Latent variable models have been successfully applied in lossless compression with the bits-back coding algorithm. However, bits-back suffers from an increase in the bitrate equal to the KL divergence between the approximate posterior and the true posterior. In this paper, we show how to remove this gap asymptotically by deriving bits-back coding algorithms from tighter variational bounds. The key idea is to exploit extended space representations of Monte Carlo estimators of the marginal likelihood. Naively applied, our schemes would require more initial bits than the standard bits-back coder, but we show how to drastically reduce this additional cost with couplings in the latent space. When parallel architectures can be exploited, our coders can achieve better rates than bits-back with little additional cost. We demonstrate improved lossless compression rates in a variety of settings, especially in out-of-distribution or sequential data compression.

Hierarchical topic models such as the gamma belief network (GBN) have delivered promising results in mining multi-layer document representations and discovering interpretable topic taxonomies. However, they often assume in the prior that the topics at each layer are independently drawn from the Dirichlet distribution, ignoring the dependencies between the topics both at the same layer and across different layers. To relax this assumption, we propose sawtooth factorial topic embedding guided GBN, a deep generative model of documents that captures the dependencies and semantic similarities between the topics in the embedding space. Specifically, both the words and topics are represented as embedding vectors of the same dimension. The topic matrix at a layer is factorized into the product of a factor loading matrix and a topic embedding matrix, the transpose of which is set as the factor loading matrix of the layer above. Repeating this particular type of factorization, which shares components between adjacent layers, leads to a structure referred to as sawtooth factorization. An auto-encoding variational inference network is constructed to optimize the model parameter via stochastic gradient descent. Experiments on big corpora show that our models outperform other neural topic models on extracting deeper interpretable topics and deriving better …

This paper introduces kernel continual learning, a simple but effective variant of continual learning that leverages the non-parametric nature of kernel methods to tackle catastrophic forgetting. We deploy an episodic memory unit that stores a subset of samples for each task to learn task-specific classifiers based on kernel ridge regression. This does not require memory replay and systematically avoids task interference in the classifiers. We further introduce variational random features to learn a data-driven kernel for each task. To do so, we formulate kernel continual learning as a variational inference problem, where a random Fourier basis is incorporated as the latent variable. The variational posterior distribution over the random Fourier basis is inferred from the coreset of each task. In this way, we are able to generate more informative kernels specific to each task, and, more importantly, the coreset size can be reduced to achieve more compact memory, resulting in more efficient continual learning based on episodic memory. Extensive evaluation on four benchmarks demonstrates the effectiveness and promise of kernels for continual learning.

We propose XOR-Contrastive Divergence learning (XOR-CD), a provable approach for constrained structure generation, which remains difficult for state-of-the-art neural network and constraint reasoning approaches. XOR-CD harnesses XOR-Sampling to generate samples from the model distribution in CD learning and is guaranteed to generate valid structures. In addition, XOR-CD has a linear convergence rate towards the global maximum of the likelihood function within a vanishing constant in learning exponential family models. Constraint satisfaction enabled by XOR-CD also boosts its learning performance. Our real-world experiments on data-driven experimental design, dispatching route generation, and sequence-based protein homology detection demonstrate the superior performance of XOR-CD compared to baseline approaches in generating valid structures as well as capturing the inductive bias in the training set.

Estimating the gradients for binary variables is a task that arises frequently in various domains, such as training discrete latent variable models. What has been commonly used is a REINFORCE based Monte Carlo estimation method that uses either independent samples or pairs of negatively correlated samples. To better utilize more than two samples, we propose ARMS, an Antithetic REINFORCE-based Multi-Sample gradient estimator. ARMS uses a copula to generate any number of mutually antithetic samples. It is unbiased, has low variance, and generalizes both DisARM, which we show to be ARMS with two samples, and the leave-one-out REINFORCE (LOORF) estimator, which is ARMS with uncorrelated samples. We evaluate ARMS on several datasets for training generative models, and our experimental results show that it outperforms competing methods. We also develop a version of ARMS for optimizing the multi-sample variational bound, and show that it outperforms both VIMCO and DisARM. The code is publicly available.

Given an inverse problem with a normalizing flow prior, we wish to estimate the distribution of the underlying signal conditioned on the observations. We approach this problem as a task of conditional inference on the pre-trained unconditional flow model. We first establish that this is computationally hard for a large class of flow models. Motivated by this, we propose a framework for approximate inference that estimates the target conditional as a composition of two flow models. This formulation leads to a stable variational inference training procedure that avoids adversarial training. Our method is evaluated on a variety of inverse problems and is shown to produce high-quality samples with uncertainty quantification. We further demonstrate that our approach can be amortized for zero-shot inference.

Probabilistic programming uses programs to express generative models whose posterior probability is then computed by built-in inference engines. A challenging goal is to develop general purpose inference algorithms that work out-of-the-box for arbitrary programs in a universal probabilistic programming language (PPL). The densities defined by such programs, which may use stochastic branching and recursion, are (in general) nonparametric, in the sense that they correspond to models on an infinite-dimensional parameter space. However standard inference algorithms, such as the Hamiltonian Monte Carlo (HMC) algorithm, target distributions with a fixed number of parameters. This paper introduces the Nonparametric Hamiltonian Monte Carlo (NP-HMC) algorithm which generalises HMC to nonparametric models. Inputs to NP-HMC are a new class of measurable functions called “tree representable”, which serve as a language-independent representation of the density functions of probabilistic programs in a universal PPL. We provide a correctness proof of NP-HMC, and empirically demonstrate significant performance improvements over existing approaches on several nonparametric examples.
Oral: Reinforcement Learning 10 Wed 21 Jul 02:00 p.m.

Imitation learning seeks to circumvent the difficulty in designing proper reward functions for training agents by utilizing expert behavior. With environments modeled as Markov Decision Processes (MDP), most of the existing imitation algorithms are contingent on the availability of expert demonstrations in the same MDP as the one in which a new imitation policy is to be learned. In this paper, we study the problem of how to imitate tasks when discrepancies exist between the expert and agent MDP. These discrepancies across domains could include differing dynamics, viewpoint, or morphology; we present a novel framework to learn correspondences across such domains. Importantly, in contrast to prior works, we use unpaired and unaligned trajectories containing only states in the expert domain, to learn this correspondence. We utilize a cycle-consistency constraint on both the state space and a domain agnostic latent space to do this. In addition, we enforce consistency on the temporal position of states via a normalized position estimator function, to align the trajectories across the two domains. Once this correspondence is found, we can directly transfer the demonstrations on one domain to the other and use it for imitation. Experiments across a wide variety of challenging domains demonstrate the …
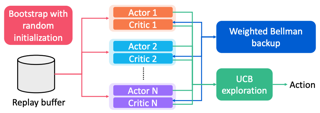
Off-policy deep reinforcement learning (RL) has been successful in a range of challenging domains. However, standard off-policy RL algorithms can suffer from several issues, such as instability in Q-learning and balancing exploration and exploitation. To mitigate these issues, we present SUNRISE, a simple unified ensemble method, which is compatible with various off-policy RL algorithms. SUNRISE integrates two key ingredients: (a) ensemble-based weighted Bellman backups, which re-weight target Q-values based on uncertainty estimates from a Q-ensemble, and (b) an inference method that selects actions using the highest upper-confidence bounds for efficient exploration. By enforcing the diversity between agents using Bootstrap with random initialization, we show that these different ideas are largely orthogonal and can be fruitfully integrated, together further improving the performance of existing off-policy RL algorithms, such as Soft Actor-Critic and Rainbow DQN, for both continuous and discrete control tasks on both low-dimensional and high-dimensional environments.

The goal of meta-reinforcement learning (meta-RL) is to build agents that can quickly learn new tasks by leveraging prior experience on related tasks. Learning a new task often requires both exploring to gather task-relevant information and exploiting this information to solve the task. In principle, optimal exploration and exploitation can be learned end-to-end by simply maximizing task performance. However, such meta-RL approaches struggle with local optima due to a chicken-and-egg problem: learning to explore requires good exploitation to gauge the exploration’s utility, but learning to exploit requires information gathered via exploration. Optimizing separate objectives for exploration and exploitation can avoid this problem, but prior meta-RL exploration objectives yield suboptimal policies that gather information irrelevant to the task. We alleviate both concerns by constructing an exploitation objective that automatically identifies task-relevant information and an exploration objective to recover only this information. This avoids local optima in end-to-end training, without sacrificing optimal exploration. Empirically, DREAM substantially outperforms existing approaches on complex meta-RL problems, such as sparse-reward 3D visual navigation. Videos of DREAM: https://ezliu.github.io/dream/

Many real-world situations allow for the acquisition of additional relevant information when making an assessment with limited or uncertain data. However, traditional ML approaches either require all features to be acquired beforehand or regard part of them as missing data that cannot be acquired. In this work, we consider models that perform active feature acquisition (AFA) and query the environment for unobserved features to improve the prediction assessments at evaluation time. Our work reformulates the Markov decision process (MDP) that underlies the AFA problem as a generative modeling task and optimizes a policy via a novel model-based approach. We propose learning a generative surrogate model (GSM) that captures the dependencies among input features to assess potential information gain from acquisitions. The GSM is leveraged to provide intermediate rewards and auxiliary information to aid the agent navigate a complicated high-dimensional action space and sparse rewards. Furthermore, we extend AFA in a task we coin active instance recognition (AIR) for the unsupervised case where the target variables are the unobserved features themselves and the goal is to collect information for a particular instance in a cost-efficient way. Empirical results demonstrate that our approach achieves considerably better performance than previous state of the …

Actor-critic (AC) methods are ubiquitous in reinforcement learning. Although it is understood that AC methods are closely related to policy gradient (PG), their precise connection has not been fully characterized previously. In this paper, we explain the gap between AC and PG methods by identifying the exact adjustment to the AC objective/gradient that recovers the true policy gradient of the cumulative reward objective (PG). Furthermore, by viewing the AC method as a two-player Stackelberg game between the actor and critic, we show that the Stackelberg policy gradient can be recovered as a special case of our more general analysis. Based on these results, we develop practical algorithms, Residual Actor-Critic and Stackelberg Actor-Critic, for estimating the correction between AC and PG and use these to modify the standard AC algorithm. Experiments on popular tabular and continuous environments show the proposed corrections can improve both the sample efficiency and final performance of existing AC methods.

Most of the recent deep reinforcement learning advances take an RL-centric perspective and focus on refinements of the training objective. We diverge from this view and show we can recover the performance of these developments not by changing the objective, but by regularising the value-function estimator. Constraining the Lipschitz constant of a single layer using spectral normalisation is sufficient to elevate the performance of a Categorical-DQN agent to that of a more elaborated agent on the challenging Atari domain. We conduct ablation studies to disentangle the various effects normalisation has on the learning dynamics and show that is sufficient to modulate the parameter updates to recover most of the performance of spectral normalisation. These findings hint towards the need to also focus on the neural component and its learning dynamics to tackle the peculiarities of Deep Reinforcement Learning.

We consider the problem of reinforcement learning when provided with (1) a baseline control policy and (2) a set of constraints that the learner must satisfy. The baseline policy can arise from demonstration data or a teacher agent and may provide useful cues for learning, but it might also be sub-optimal for the task at hand, and is not guaranteed to satisfy the specified constraints, which might encode safety, fairness or other application-specific requirements. In order to safely learn from baseline policies, we propose an iterative policy optimization algorithm that alternates between maximizing expected return on the task, minimizing distance to the baseline policy, and projecting the policy onto the constraint-satisfying set. We analyze our algorithm theoretically and provide a finite-time convergence guarantee. In our experiments on five different control tasks, our algorithm consistently outperforms several state-of-the-art baselines, achieving 10 times fewer constraint violations and 40% higher reward on average.
Oral: Optimization (Nonconvex) Wed 21 Jul 02:00 p.m.

Solving optimization tasks based on functions and losses with a topological flavor is a very active and growing field of research in data science and Topological Data Analysis, with applications in non-convex optimization, statistics and machine learning. However, the approaches proposed in the literature are usually anchored to a specific application and/or topological construction, and do not come with theoretical guarantees. To address this issue, we study the differentiability of a general map associated with the most common topological construction, that is, the persistence map. Building on real analytic geometry arguments, we propose a general framework that allows us to define and compute gradients for persistence-based functions in a very simple way. We also provide a simple, explicit and sufficient condition for convergence of stochastic subgradient methods for such functions. This result encompasses all the constructions and applications of topological optimization in the literature. Finally, we provide associated code, that is easy to handle and to mix with other non-topological methods and constraints, as well as some experiments showcasing the versatility of our approach.



This paper develops a methodology for regret minimization with stochastic first-order oracle feedback in online, constrained, non-smooth, non-convex problems. In this setting, the minimization of external regret is beyond reach for first-order methods, and there are no gradient-based algorithmic frameworks capable of providing a solution. On that account, we propose a conceptual approach that leverages non-convex optimality measures, leading to a suitable generalization of the learner's local regret. We focus on a local regret measure defined via a proximal-gradient mapping, that also encompasses the original notion proposed by Hazan et al. (2017). To achieve no local regret in this setting, we develop a proximal-gradient method based on stochastic first-order feedback, and a simpler method for when access to a perfect first-order oracle is possible. Both methods are order-optimal (in the min-max sense), and we also establish a bound on the number of proximal-gradient queries these methods require. As an important application of our results, we also obtain a link between online and offline non-convex stochastic optimization manifested as a new proximal-gradient scheme with complexity guarantees matching those obtained via variance reduction techniques.

We develop and analyze MARINA: a new communication efficient method for non-convex distributed learning over heterogeneous datasets. MARINA employs a novel communication compression strategy based on the compression of gradient differences that is reminiscent of but different from the strategy employed in the DIANA method of Mishchenko et al. (2019). Unlike virtually all competing distributed first-order methods, including DIANA, ours is based on a carefully designed biased gradient estimator, which is the key to its superior theoretical and practical performance. The communication complexity bounds we prove for MARINA are evidently better than those of all previous first-order methods. Further, we develop and analyze two variants of MARINA: VR-MARINA and PP-MARINA. The first method is designed for the case when the local loss functions owned by clients are either of a finite sum or of an expectation form, and the second method allows for a partial participation of clients – a feature important in federated learning. All our methods are superior to previous state-of-the-art methods in terms of oracle/communication complexity. Finally, we provide a convergence analysis of all methods for problems satisfying the Polyak-Łojasiewicz condition.


Byzantine robustness has received significant attention recently given its importance for distributed and federated learning. In spite of this, we identify severe flaws in existing algorithms even when the data across the participants is identically distributed. First, we show realistic examples where current state of the art robust aggregation rules fail to converge even in the absence of any Byzantine attackers. Secondly, we prove that even if the aggregation rules may succeed in limiting the influence of the attackers in a single round, the attackers can couple their attacks across time eventually leading to divergence. To address these issues, we present two surprisingly simple strategies: a new robust iterative clipping procedure, and incorporating worker momentum to overcome time-coupled attacks. This is the first provably robust method for the standard stochastic optimization setting.
Oral: Learning Theory 2 Wed 21 Jul 02:00 p.m.

In contrast to the empirical mean, the Median-of-Means (MoM) is an estimator of the mean θ of a square integrable r.v. Z, around which accurate nonasymptotic confidence bounds can be built, even when Z does not exhibit a sub-Gaussian tail behavior. Thanks to the high confidence it achieves on heavy-tailed data, MoM has found various applications in machine learning, where it is used to design training procedures that are not sensitive to atypical observations. More recently, a new line of work is now trying to characterize and leverage MoM’s ability to deal with corrupted data. In this context, the present work proposes a general study of MoM’s concentration properties under the contamination regime, that provides a clear understanding on the impact of the outlier proportion and the number of blocks chosen. The analysis is extended to (multisample) U-statistics, i.e. averages over tuples of observations, that raise additional challenges due to the dependence induced. Finally, we show that the latter bounds can be used in a straightforward fashion to derive generalization guarantees for pairwise learning in a contaminated setting, and propose an algorithm to compute provably reliable decision functions.


We propose a residual randomization procedure designed for robust inference using Lasso estimates in the high-dimensional setting. Compared to earlier work that focuses on sub-Gaussian errors, the proposed procedure is designed to work robustly in settings that also include heavy-tailed covariates and errors. Moreover, our procedure can be valid under clustered errors, which is important in practice, but has been largely overlooked by earlier work. Through extensive simulations, we illustrate our method's wider range of applicability as suggested by theory. In particular, we show that our method outperforms state-of-art methods in challenging, yet more realistic, settings where the distribution of covariates is heavy-tailed or the sample size is small, while it remains competitive in standard, ``well behaved" settings previously studied in the literature.

Modern machine learning models with high accuracy are often miscalibrated---the predicted top probability does not reflect the actual accuracy, and tends to be \emph{over-confident}. It is commonly believed that such over-confidence is mainly due to \emph{over-parametrization}, in particular when the model is large enough to memorize the training data and maximize the confidence.
In this paper, we show theoretically that over-parametrization is not the only reason for over-confidence. We prove that \emph{logistic regression is inherently over-confident}, in the realizable, under-parametrized setting where the data is generated from the logistic model, and the sample size is much larger than the number of parameters. Further, this over-confidence happens for general well-specified binary classification problems as long as the activation is symmetric and concave on the positive part. Perhaps surprisingly, we also show that over-confidence is not always the case---there exists another activation function (and a suitable loss function) under which the learned classifier is \emph{under-confident} at some probability values. Overall, our theory provides a precise characterization of calibration in realizable binary classification, which we verify on simulations and real data experiments.

Neural Architecture Search (NAS) is a popular method for automatically designing optimized deep-learning architectures. NAS methods commonly use bilevel optimization where one optimizes the weights over the training data (lower-level problem) and hyperparameters - such as the architecture - over the validation data (upper-level problem). This paper explores the statistical aspects of such problems with train-validation splits. In practice, the lower-level problem is often overparameterized and can easily achieve zero loss. Thus, a-priori, it seems impossible to distinguish the right hyperparameters based on training loss alone which motivates a better understanding of train-validation split. To this aim, we first show that refined properties of the validation loss such as risk and hyper-gradients are indicative of those of the true test loss and help prevent overfitting with a near-minimal validation sample size. Importantly, this is established for continuous search spaces which are relevant for differentiable search schemes. We then establish generalization bounds for NAS problems with an emphasis on an activation search problem and gradient-based methods. Finally, we show rigorous connections between NAS and low-rank matrix learning which leads to algorithmic insights where the solution of the upper problem can be accurately learned via spectral methods to achieve near-minimal risk.

Oral: Learning Theory 3 Wed 21 Jul 02:00 p.m.

Compared to minimization, the min-max optimization in machine learning applications is considerably more convoluted because of the existence of cycles and similar phenomena. Such oscillatory behaviors are well-understood in the convex-concave regime, and many algorithms are known to overcome them. In this paper, we go beyond this basic setting and characterize the convergence properties of many popular methods in solving non-convex/non-concave problems. In particular, we show that a wide class of state-of-the-art schemes and heuristics may converge with arbitrarily high probability to attractors that are in no way min-max optimal or even stationary. Our work thus points out a potential pitfall among many existing theoretical frameworks, and we corroborate our theoretical claims by explicitly showcasing spurious attractors in simple two-dimensional problems.

Spectral method is a commonly used scheme to cluster data points lying close to Union of Subspaces, a task known as Subspace Clustering. The typical usage is to construct a Random Geometry Graph first and then apply spectral method to the graph to obtain clustering result. The latter step has been coined the name Spectral Clustering. As far as we know, in spite of the significance of both steps in spectral-method-based Subspace Clustering, all existing theoretical results focus on the first step of constructing the graph, but ignore the final step to correct false connections through spectral clustering. This paper establishes a theory to show the power of this method for the first time, in which we demonstrate the mechanism of spectral clustering by analyzing a simplified algorithm under the widely used semi-random model. Based on this theory, we prove the efficiency of Subspace Clustering in fairly broad conditions. The insights and analysis techniques developed in this paper might also have implications for other random graph problems.

We consider a novel challenge: approximating a distribution without the ability to randomly sample from that distribution. We study how such an approximation can be obtained using weight queries. Given some data set of examples, a weight query presents one of the examples to an oracle, which returns the probability, according to the target distribution, of observing examples similar to the presented example. This oracle can represent, for instance, counting queries to a database of the target population, or an interface to a search engine which returns the number of results that match a given search.
We propose an interactive algorithm that iteratively selects data set examples and performs corresponding weight queries. The algorithm finds a reweighting of the data set that approximates the weights according to the target distribution, using a limited number of weight queries. We derive an approximation bound on the total variation distance between the reweighting found by the algorithm and the best achievable reweighting. Our algorithm takes inspiration from the UCB approach common in multi-armed bandits problems, and combines it with a new discrepancy estimator and a greedy iterative procedure. In addition to our theoretical guarantees, we demonstrate in experiments the advantages of the …


Online advertisements are primarily sold via repeated auctions with reserve prices. In this paper, we study how to set reserves to boost revenue based on the historical bids of strategic buyers, while controlling the impact of such a policy on the incentive compatibility of the repeated auctions. Adopting an incentive compatibility metric which quantifies the incentives to shade bids, we propose a novel class of reserve pricing policies and provide analytical tradeoffs between their revenue performance and bid-shading incentives. The policies are inspired by the exponential mechanism from the literature on differential privacy, but our study uncovers mechanisms with significantly better revenue-incentive tradeoffs than the exponential mechanism in practice. We further empirically evaluate the tradeoffs on synthetic data as well as real ad auction data from a major ad exchange to verify and support our theoretical findings.
As machine learning black boxes are increasingly being deployed in critical domains such as healthcare and criminal justice, there has been a growing emphasis on developing techniques for explaining these black boxes in a post hoc manner. In this work, we analyze two popular post hoc interpretation techniques: SmoothGrad which is a gradient based method, and a variant of LIME which is a perturbation based method. More specifically, we derive explicit closed form expressions for the explanations output by these two methods and show that they both converge to the same explanation in expectation, i.e., when the number of perturbed samples used by these methods is large. We then leverage this connection to establish other desirable properties, such as robustness, for these techniques. We also derive finite sample complexity bounds for the number of perturbations required for these methods to converge to their expected explanation. Finally, we empirically validate our theory using extensive experimentation on both synthetic and real-world datasets.

A recent series of theoretical works showed that the dynamics of neural networks with a certain initialisation are well-captured by kernel methods. Concurrent empirical work demonstrated that kernel methods can come close to the performance of neural networks on some image classification tasks. These results raise the question of whether neural networks only learn successfully if kernels also learn successfully, despite being the more expressive function class. Here, we show that two-layer neural networks with only a few neurons achieve near-optimal performance on high-dimensional Gaussian mixture classification while lazy training approaches such as random features and kernel methods do not. Our analysis is based on the derivation of a set of ordinary differential equations that exactly track the dynamics of the network and thus allow to extract the asymptotic performance of the network as a function of regularisation or signal-to-noise ratio. We also show how over-parametrising the neural network leads to faster convergence, but does not improve its final performance.
Oral: Algorithms and Applications Wed 21 Jul 03:00 p.m.


Semantic understanding of programs is a fundamental problem for programming language processing (PLP). Recent works that learn representations of code based on pre-training techniques in NLP have pushed the frontiers in this direction. However, the semantics of PL and NL have essential differences. These being ignored, we believe it is difficult to build a model to better understand programs, by either directly applying off-the-shelf NLP pre-training techniques to the source code, or adding features to the model by the heuristic. In fact, the semantics of a program can be rigorously defined by formal semantics in PL theory. For example, the operational semantics, describes the meaning of a valid program as updating the environment (i.e., the memory address-value function) through fundamental operations, such as memory I/O and conditional branching. Inspired by this, we propose a novel program semantics learning paradigm, that the model should learn from information composed of (1) the representations which align well with the fundamental operations in operational semantics, and (2) the information of environment transition, which is indispensable for program understanding. To validate our proposal, we present a hierarchical Transformer-based pre-training model called OSCAR to better facilitate the understanding of programs. OSCAR learns from intermediate representation (IR) …
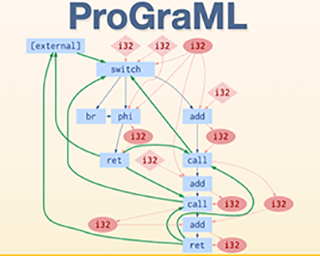
Machine learning (ML) is increasingly seen as a viable approach for building compiler optimization heuristics, but many ML methods cannot replicate even the simplest of the data flow analyses that are critical to making good optimization decisions. We posit that if ML cannot do that, then it is insufficiently able to reason about programs. We formulate data flow analyses as supervised learning tasks and introduce a large open dataset of programs and their corresponding labels from several analyses. We use this dataset to benchmark ML methods and show that they struggle on these fundamental program reasoning tasks. We propose ProGraML - Program Graphs for Machine Learning - a language-independent, portable representation of program semantics. ProGraML overcomes the limitations of prior works and yields improved performance on downstream optimization tasks.

The best performing Binary Neural Networks (BNNs) are usually attained using Adam optimization and its multi-step training variants. However, to the best of our knowledge, few studies explore the fundamental reasons why Adam is superior to other optimizers like SGD for BNN optimization or provide analytical explanations that support specific training strategies. To address this, in this paper we first investigate the trajectories of gradients and weights in BNNs during the training process. We show the regularization effect of second-order momentum in Adam is crucial to revitalize the weights that are dead due to the activation saturation in BNNs. We find that Adam, through its adaptive learning rate strategy, is better equipped to handle the rugged loss surface of BNNs and reaches a better optimum with higher generalization ability. Furthermore, we inspect the intriguing role of the real-valued weights in binary networks, and reveal the effect of weight decay on the stability and sluggishness of BNN optimization. Through extensive experiments and analysis, we derive a simple training scheme, building on existing Adam-based optimization, which achieves 70.5% top-1 accuracy on the ImageNet dataset using the same architecture as the state-of-the-art ReActNet while achieving 1.1% higher accuracy. Code and models are available …

Anomaly estimation, or the problem of finding a subset of a dataset that differs from the rest of the dataset, is a classic problem in machine learning and data mining. In both theoretical work and in applications, the anomaly is assumed to have a specific structure defined by membership in an anomaly family. For example, in temporal data the anomaly family may be time intervals, while in network data the anomaly family may be connected subgraphs. The most prominent approach for anomaly estimation is to compute the Maximum Likelihood Estimator (MLE) of the anomaly; however, it was recently observed that for normally distributed data, the MLE is a biased estimator for some anomaly families. In this work, we demonstrate that in the normal means setting, the bias of the MLE depends on the size of the anomaly family. We prove that if the number of sets in the anomaly family that contain the anomaly is sub-exponential, then the MLE is asymptotically unbiased. We also provide empirical evidence that the converse is true: if the number of such sets is exponential, then the MLE is asymptotically biased. Our analysis unifies a number of earlier results on the bias of the MLE …

Many of real-world data, e.g., the VGGFace2 dataset, which is a collection of multiple portraits of individuals, come with nested structures due to grouped observation. The Ornstein auto-encoder (OAE) is an emerging framework for representation learning from nested data, based on an optimal transport distance between random processes. An attractive feature of OAE is its ability to generate new variations nested within an observational unit, whether or not the unit is known to the model. A previously proposed algorithm for OAE, termed the random-intercept OAE (RIOAE), showed an impressive performance in learning nested representations, yet lacks theoretical justification. In this work, we show that RIOAE minimizes a loose upper bound of the employed optimal transport distance. After identifying several issues with RIOAE, we present the product-space OAE (PSOAE) that minimizes a tighter upper bound of the distance and achieves orthogonality in the representation space. PSOAE alleviates the instability of RIOAE and provides more flexible representation of nested data. We demonstrate the high performance of PSOAE in the three key tasks of generative models: exemplar generation, style transfer, and new concept generation.

Oral: Learning Theory 4 Wed 21 Jul 03:00 p.m.

We analyze the properties of gradient descent on convex surrogates for the zero-one loss for the agnostic learning of halfspaces. We show that when a quantity we refer to as the \textit{soft margin} is well-behaved---a condition satisfied by log-concave isotropic distributions among others---minimizers of convex surrogates for the zero-one loss are approximate minimizers for the zero-one loss itself. As standard convex optimization arguments lead to efficient guarantees for minimizing convex surrogates of the zero-one loss, our methods allow for the first positive guarantees for the classification error of halfspaces learned by gradient descent using the binary cross-entropy or hinge loss in the presence of agnostic label noise.

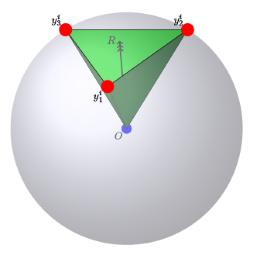


Detecting influential features in non-linear and/or high-dimensional data is a challenging and increasingly important task in machine learning. Variable selection methods have thus been gaining much attention as well as post-selection inference. Indeed, the selected features can be significantly flawed when the selection procedure is not accounted for. We propose a selective inference procedure using the so-called model-free "HSIC-Lasso" based on the framework of truncated Gaussians combined with the polyhedral lemma. We then develop an algorithm, which allows for low computational costs and provides a selection of the regularisation parameter. The performance of our method is illustrated by both artificial and real-world data based experiments, which emphasise a tight control of the type-I error, even for small sample sizes.


We prove calibration guarantees for the popular histogram binning (also called uniform-mass binning) method of Zadrozny and Elkan (2001). Histogram binning has displayed strong practical performance, but theoretical guarantees have only been shown for sample split versions that avoid 'double dipping' the data. We demonstrate that the statistical cost of sample splitting is practically significant on a credit default dataset. We then prove calibration guarantees for the original method that double dips the data, using a certain Markov property of order statistics. Based on our results, we make practical recommendations for choosing the number of bins in histogram binning. In our illustrative simulations, we propose a new tool for assessing calibration---validity plots---which provide more information than an ECE estimate.
Oral: Game Theory and Econ Wed 21 Jul 03:00 p.m.

The display advertising industry has recently transitioned from second- to first-price auctions as its primary mechanism for ad allocation and pricing. In light of this, publishers need to re-evaluate and optimize their auction parameters, notably reserve prices. In this paper, we propose a gradient-based algorithm to adaptively update and optimize reserve prices based on estimates of bidders' responsiveness to experimental shocks in reserves. Our key innovation is to draw on the inherent structure of the revenue objective in order to reduce the variance of gradient estimates and improve convergence rates in both theory and practice. We show that revenue in a first-price auction can be usefully decomposed into a \emph{demand} component and a \emph{bidding} component, and introduce techniques to reduce the variance of each component. We characterize the bias-variance trade-offs of these techniques and validate the performance of our proposed algorithm through experiments on synthetic data and real display ad auctions data from a major ad exchange.

Direct Feedback Alignment (DFA) is emerging as an efficient and biologically plausible alternative to backpropagation for training deep neural networks. Despite relying on random feedback weights for the backward pass, DFA successfully trains state-of-the-art models such as Transformers. On the other hand, it notoriously fails to train convolutional networks. An understanding of the inner workings of DFA to explain these diverging results remains elusive. Here, we propose a theory of feedback alignment algorithms. We first show that learning in shallow networks proceeds in two steps: an alignment phase, where the model adapts its weights to align the approximate gradient with the true gradient of the loss function, is followed by a memorisation phase, where the model focuses on fitting the data. This two-step process has a degeneracy breaking effect: out of all the low-loss solutions in the landscape, a net-work trained with DFA naturally converges to the solution which maximises gradient alignment. We also identify a key quantity underlying alignment in deep linear networks: the conditioning of the alignment matrices. The latter enables a detailed understanding of the impact of data structure on alignment, and suggests a simple explanation for the well-known failure of DFA to train convolutional neural networks. …
We focus on the problem of finding an optimal strategy for a team of players that faces an opponent in an imperfect-information zero-sum extensive-form game. Team members are not allowed to communicate during play but can coordinate before the game. In this setting, it is known that the best the team can do is sample a profile of potentially randomized strategies (one per player) from a joint (a.k.a. correlated) probability distribution at the beginning of the game. In this paper, we first provide new modeling results about computing such an optimal distribution by drawing a connection to a different literature on extensive-form correlation. Second, we provide an algorithm that allows one for capping the number of profiles employed in the solution. This begets an anytime algorithm by increasing the cap. We find that often a handful of well-chosen such profiles suffices to reach optimal utility for the team. This enables team members to reach coordination through a simple and understandable plan. Finally, inspired by this observation and leveraging theoretical concepts that we introduce, we develop an efficient column-generation algorithm for finding an optimal distribution for the team. We evaluate it on a suite of common benchmark games. It is three …

In the Learning to Price setting, a seller posts prices over time with the goal of maximizing revenue while learning the buyer's valuation. This problem is very well understood when values are stationary (fixed or iid). Here we study the problem where the buyer's value is a moving target, i.e., they change over time either by a stochastic process or adversarially with bounded variation. In either case, we provide matching upper and lower bounds on the optimal revenue loss. Since the target is moving, any information learned soon becomes out-dated, which forces the algorithms to keep switching between exploring and exploiting phases.
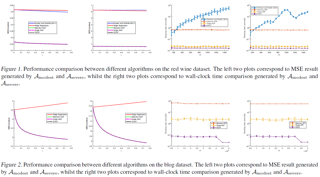
The Stackelberg prediction game (SPG) has been extensively used to model the interactions between the learner and data provider in the training process of various machine learning algorithms. Particularly, SPGs played prominent roles in cybersecurity applications, such as intrusion detection, banking fraud detection, spam filtering, and malware detection. Often formulated as NP-hard bi-level optimization problems, it is generally computationally intractable to find global solutions to SPGs. As an interesting progress in this area, a special class of SPGs with the least squares loss (SPG-LS) have recently been shown polynomially solvable by a bisection method. However, in each iteration of this method, a semidefinite program (SDP) needs to be solved. The resulted high computational costs prevent its applications for large-scale problems. In contrast, we propose a novel approach that reformulates a SPG-LS as a single SDP of a similar form and the same dimension as those solved in the bisection method. Our SDP reformulation is, evidenced by our numerical experiments, orders of magnitude faster than the existing bisection method. We further show that the obtained SDP can be reduced to a second order cone program (SOCP). This allows us to provide real-time response to large-scale SPG-LS problems. Numerical results on both …


Randomized experiments can be susceptible to selection bias due to potential non-compliance by the participants. While much of the existing work has studied compliance as a static behavior, we propose a game-theoretic model to study compliance as dynamic behavior that may change over time. In rounds, a social planner interacts with a sequence of heterogeneous agents who arrive with their unobserved private type that determines both their prior preferences across the actions (e.g., control and treatment) and their baseline rewards without taking any treatment. The planner provides each agent with a randomized recommendation that may alter their beliefs and their action selection. We develop a novel recommendation mechanism that views the planner's recommendation as a form of instrumental variable (IV) that only affects an agents' action selection, but not the observed rewards. We construct such IVs by carefully mapping the history --the interactions between the planner and the previous agents-- to a random recommendation. Even though the initial agents may be completely non-compliant, our mechanism can incentivize compliance over time, thereby enabling the estimation of the treatment effect of each treatment, and minimizing the cumulative regret of the planner whose goal is to identify the optimal treatment.
Oral: Reinforcement Learning Theory 1 Wed 21 Jul 03:00 p.m.

This work introduces Bilinear Classes, a new structural framework, which permit generalization in reinforcement learning in a wide variety of settings through the use of function approximation. The framework incorporates nearly all existing models in which a polynomial sample complexity is achievable, and, notably, also includes new models, such as the Linear Q/V model in which both the optimal Q-function and the optimal V-function are linear in some known feature space. Our main result provides an RL algorithm which has polynomial sample complexity for Bilinear Classes; notably, this sample complexity is stated in terms of a reduction to the generalization error of an underlying supervised learning sub-problem. These bounds nearly match the best known sample complexity bounds for existing models. Furthermore, this framework also extends to the infinite dimensional (RKHS) setting: for the the Linear Q/V model, linear MDPs, and linear mixture MDPs, we provide sample complexities that have no explicit dependence on the explicit feature dimension (which could be infinite), but instead depends only on information theoretic quantities.

This paper considers batch Reinforcement Learning (RL) with general value function approximation. Our study investigates the minimal assumptions to reliably estimate/minimize Bellman error, and characterizes the generalization performance by (local) Rademacher complexities of general function classes, which makes initial steps in bridging the gap between statistical learning theory and batch RL. Concretely, we view the Bellman error as a surrogate loss for the optimality gap, and prove the followings: (1) In double sampling regime, the excess risk of Empirical Risk Minimizer (ERM) is bounded by the Rademacher complexity of the function class. (2) In the single sampling regime, sample-efficient risk minimization is not possible without further assumptions, regardless of algorithms. However, with completeness assumptions, the excess risk of FQI and a minimax style algorithm can be again bounded by the Rademacher complexity of the corresponding function classes. (3) Fast statistical rates can be achieved by using tools of local Rademacher complexity. Our analysis covers a wide range of function classes, including finite classes, linear spaces, kernel spaces, sparse linear features, etc.
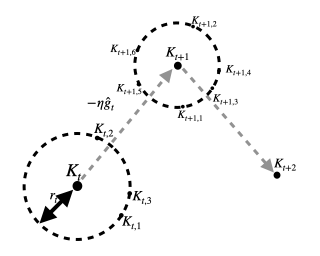
We consider the task of learning to control a linear dynamical system under fixed quadratic costs, known as the Linear Quadratic Regulator (LQR) problem. While model-free approaches are often favorable in practice, thus far only model-based methods, which rely on costly system identification, have been shown to achieve regret that scales with the optimal dependence on the time horizon T. We present the first model-free algorithm that achieves similar regret guarantees. Our method relies on an efficient policy gradient scheme, and a novel and tighter analysis of the cost of exploration in policy space in this setting.
We study the problem of reward identifiability in the context of Inverse Reinforcement Learning (IRL). The reward identifiability question is critical to answer when reasoning about the effectiveness of using Markov Decision Processes (MDPs) as computational models of real world decision makers in order to understand complex decision making behavior and perform counterfactual reasoning. While identifiability has been acknowledged as a fundamental theoretical question in IRL, little is known about the types of MDPs for which rewards are identifiable, or even if there exist such MDPs. In this work, we formalize the reward identification problem in IRL and study how identifiability relates to properties of the MDP model. For deterministic MDP models with the MaxEntRL objective, we prove necessary and sufficient conditions for identifiability. Building on these results, we present efficient algorithms for testing whether or not an MDP model is identifiable.

We present a novel control-theoretic understanding of online optimization and learning in games, via the notion of passivity. Passivity is a fundamental concept in control theory, which abstracts energy conservation and dissipation in physical systems. It has become a standard tool in analysis of general feedback systems, to which game dynamics belong. Our starting point is to show that all continuous-time Follow-the-Regularized-Leader (FTRL) dynamics, which include the well-known Replicator Dynamic, are lossless, i.e. it is passive with no energy dissipation. Interestingly, we prove that passivity implies bounded regret, connecting two fundamental primitives of control theory and online optimization.
The observation of energy conservation in FTRL inspires us to present a family of lossless learning dynamics, each of which has an underlying energy function with a simple gradient structure. This family is closed under convex combination; as an immediate corollary, any convex combination of FTRL dynamics is lossless and thus has bounded regret. This allows us to extend the framework of Fox & Shamma [Games 2013] to prove not just global asymptotic stability results for game dynamics, but Poincaré recurrence results as well. Intuitively, when a lossless game (e.g. graphical constant-sum game) is coupled with lossless learning dynamic, their interconnection is …

We consider large-scale Markov decision processes with an unknown cost function and address the problem of learning a policy from a finite set of expert demonstrations. We assume that the learner is not allowed to interact with the expert and has no access to reinforcement signal of any kind. Existing inverse reinforcement learning methods come with strong theoretical guarantees, but are computationally expensive, while state-of-the-art policy optimization algorithms achieve significant empirical success, but are hampered by limited theoretical understanding. To bridge the gap between theory and practice, we introduce a novel bilinear saddle-point framework using Lagrangian duality. The proposed primal-dual viewpoint allows us to develop a model-free provably efficient algorithm through the lens of stochastic convex optimization. The method enjoys the advantages of simplicity of implementation, low memory requirements, and computational and sample complexities independent of the number of states. We further present an equivalent no-regret online-learning interpretation.

This paper addresses the problem of model-free reinforcement learning for Robust Markov Decision Process (RMDP) with large state spaces. The goal of the RMDPs framework is to find a policy that is robust against the parameter uncertainties due to the mismatch between the simulator model and real-world settings. We first propose the Robust Least Squares Policy Evaluation algorithm, which is a multi-step online model-free learning algorithm for policy evaluation. We prove the convergence of this algorithm using stochastic approximation techniques. We then propose Robust Least Squares Policy Iteration (RLSPI) algorithm for learning the optimal robust policy. We also give a general weighted Euclidean norm bound on the error (closeness to optimality) of the resulting policy. Finally, we demonstrate the performance of our RLSPI algorithm on some benchmark problems from OpenAI Gym.
Oral: Optimization and Algorithms 3 Wed 21 Jul 03:00 p.m.

The connection between training deep neural networks (DNNs) and optimal control theory (OCT) has attracted considerable attention as a principled tool of algorithmic design. Despite few attempts being made, they have been limited to architectures where the layer propagation resembles a Markovian dynamical system. This casts doubts on their flexibility to modern networks that heavily rely on non-Markovian dependencies between layers (e.g. skip connections in residual networks). In this work, we propose a novel dynamic game perspective by viewing each layer as a player in a dynamic game characterized by the DNN itself. Through this lens, different classes of optimizers can be seen as matching different types of Nash equilibria, depending on the implicit information structure of each (p)layer. The resulting method, called Dynamic Game Theoretic Neural Optimizer (DGNOpt), not only generalizes OCT-inspired optimizers to richer network class; it also motivates a new training principle by solving a multi-player cooperative game. DGNOpt shows convergence improvements over existing methods on image classification datasets with residual and inception networks. Our work marries strengths from both OCT and game theory, paving ways to new algorithmic opportunities from robust optimal control and bandit-based optimization.

Knowledge distillation (KD) is a successful approach for deep neural network acceleration, with which a compact network (student) is trained by mimicking the softmax output of a pre-trained high-capacity network (teacher). In tradition, KD usually relies on access to the training samples and the parameters of the white-box teacher to acquire the transferred knowledge. However, these prerequisites are not always realistic due to storage costs or privacy issues in real-world applications. Here we propose the concept of decision-based black-box (DB3) knowledge distillation, with which the student is trained by distilling the knowledge from a black-box teacher (parameters are not accessible) that only returns classes rather than softmax outputs. We start with the scenario when the training set is accessible. We represent a sample's robustness against other classes by computing its distances to the teacher's decision boundaries and use it to construct the soft label for each training sample. After that, the student can be trained via standard KD. We then extend this approach to a more challenging scenario in which even accessing the training data is not feasible. We propose to generate pseudo samples that are distinguished by the decision boundaries of the DB3 teacher to the largest extent and …


Choosing the optimizer is considered to be among the most crucial design decisions in deep learning, and it is not an easy one. The growing literature now lists hundreds of optimization methods. In the absence of clear theoretical guidance and conclusive empirical evidence, the decision is often made based on anecdotes. In this work, we aim to replace these anecdotes, if not with a conclusive ranking, then at least with evidence-backed heuristics. To do so, we perform an extensive, standardized benchmark of fifteen particularly popular deep learning optimizers while giving a concise overview of the wide range of possible choices. Analyzing more than 50,000 individual runs, we contribute the following three points: (i) Optimizer performance varies greatly across tasks. (ii) We observe that evaluating multiple optimizers with default parameters works approximately as well as tuning the hyperparameters of a single, fixed optimizer. (iii) While we cannot discern an optimization method clearly dominating across all tested tasks, we identify a significantly reduced subset of specific optimizers and parameter choices that generally lead to competitive results in our experiments: Adam remains a strong contender, with newer methods failing to significantly and consistently outperform it. Our open-sourced results are available as challenging and …

Natural-gradient descent (NGD) on structured parameter spaces (e.g., low-rank covariances) is computationally challenging due to difficult Fisher-matrix computations. We address this issue by using \emph{local-parameter coordinates} to obtain a flexible and efficient NGD method that works well for a wide-variety of structured parameterizations. We show four applications where our method (1) generalizes the exponential natural evolutionary strategy, (2) recovers existing Newton-like algorithms, (3) yields new structured second-order algorithms, and (4) gives new algorithms to learn covariances of Gaussian and Wishart-based distributions. We show results on a range of problems from deep learning, variational inference, and evolution strategies. Our work opens a new direction for scalable structured geometric methods.

Feature attribution is often loosely presented as the process of selecting a subset of relevant features as a rationale of a prediction. Task-dependent by nature, precise definitions of "relevance" encountered in the literature are however not always consistent. This lack of clarity stems from the fact that we usually do not have access to any notion of ground-truth attribution and from a more general debate on what good interpretations are. In this paper we propose to formalise feature selection/attribution based on the concept of relaxed functional dependence. In particular, we extend our notions to the instance-wise setting and derive necessary properties for candidate selection solutions, while leaving room for task-dependence. By computing ground-truth attributions on synthetic datasets, we evaluate many state-of-the-art attribution methods and show that, even when optimised, some fail to verify the proposed properties and provide wrong solutions.
Oral: Supervised Learning 2 Wed 21 Jul 03:00 p.m.

This paper aims to provide understandings for the effect of an over-parameterized model, e.g. a deep neural network, memorizing instance-dependent noisy labels. We first quantify the harms caused by memorizing noisy instances, and show the disparate impacts of noisy labels for sample instances with different representation frequencies. We then analyze how several popular solutions for learning with noisy labels mitigate this harm at the instance level. Our analysis reveals that existing approaches lead to disparate treatments when handling noisy instances. While higher-frequency instances often enjoy a high probability of an improvement by applying these solutions, lower-frequency instances do not. Our analysis reveals new understandings for when these approaches work, and provides theoretical justifications for previously reported empirical observations. This observation requires us to rethink the distribution of label noise across instances and calls for different treatments for instances in different regimes.

Machine learning models trained with purely observational data and the principle of empirical risk minimization (Vapnik 1992) can fail to generalize to unseen domains. In this paper, we focus on the case where the problem arises through spurious correlation between the observed domains and the actual task labels. We find that many domain generalization methods do not explicitly take this spurious correlation into account. Instead, especially in more application-oriented research areas like medical imaging or robotics, data augmentation techniques that are based on heuristics are used to learn domain invariant features. To bridge the gap between theory and practice, we develop a causal perspective on the problem of domain generalization. We argue that causal concepts can be used to explain the success of data augmentation by describing how they can weaken the spurious correlation between the observed domains and the task labels. We demonstrate that data augmentation can serve as a tool for simulating interventional data. We use these theoretical insights to derive a simple algorithm that is able to select data augmentation techniques that will lead to better domain generalization.


Democratization of machine learning requires architectures that automatically adapt to new problems. Neural Differential Equations (NDEs) have emerged as a popular modeling framework by removing the need for ML practitioners to choose the number of layers in a recurrent model. While we can control the computational cost by choosing the number of layers in standard architectures, in NDEs the number of neural network evaluations for a forward pass can depend on the number of steps of the adaptive ODE solver. But, can we force the NDE to learn the version with the least steps while not increasing the training cost? Current strategies to overcome slow prediction require high order automatic differentiation, leading to significantly higher training time. We describe a novel regularization method that uses the internal cost heuristics of adaptive differential equation solvers combined with discrete adjoint sensitivities to guide the training process towards learning NDEs that are easier to solve. This approach opens up the blackbox numerical analysis behind the differential equation solver's algorithm and directly uses its local error estimates and stiffness heuristics as cheap and accurate cost estimates. We incorporate our method without any change in the underlying NDE framework and show that our method extends …


The performance of modern algorithms on certain computer vision tasks such as object recognition is now close to that of humans. This success was achieved at the price of complicated architectures depending on millions of parameters and it has become quite challenging to understand how particular predictions are made. Interpretability methods propose to give us this understanding. In this paper, we study LIME, perhaps one of the most popular. On the theoretical side, we show that when the number of generated examples is large, LIME explanations are concentrated around a limit explanation for which we give an explicit expression. We further this study for elementary shape detectors and linear models. As a consequence of this analysis, we uncover a connection between LIME and integrated gradients, another explanation method. More precisely, the LIME explanations are similar to the sum of integrated gradients over the superpixels used in the preprocessing step of LIME.

Oral: Reinforcement Learning and Optimization Wed 21 Jul 03:00 p.m.


We present Megaverse, a new 3D simulation platform for reinforcement learning and embodied AI research. The efficient design of our engine enables physics-based simulation with high-dimensional egocentric observations at more than 1,000,000 actions per second on a single 8-GPU node. Megaverse is up to 70x faster than DeepMind Lab in fully-shaded 3D scenes with interactive objects. We achieve this high simulation performance by leveraging batched simulation, thereby taking full advantage of the massive parallelism of modern GPUs. We use Megaverse to build a new benchmark that consists of several single-agent and multi-agent tasks covering a variety of cognitive challenges. We evaluate model-free RL on this benchmark to provide baselines and facilitate future research.

Sharing parameters in multi-agent deep reinforcement learning has played an essential role in allowing algorithms to scale to a large number of agents. Parameter sharing between agents significantly decreases the number of trainable parameters, shortening training times to tractable levels, and has been linked to more efficient learning. However, having all agents share the same parameters can also have a detrimental effect on learning. We demonstrate the impact of parameter sharing methods on training speed and converged returns, establishing that when applied indiscriminately, their effectiveness is highly dependent on the environment. We propose a novel method to automatically identify agents which may benefit from sharing parameters by partitioning them based on their abilities and goals. Our approach combines the increased sample efficiency of parameter sharing with the representational capacity of multiple independent networks to reduce training time and increase final returns.

Ad hoc teamwork is the challenging problem of designing an autonomous agent which can adapt quickly to collaborate with teammates without prior coordination mechanisms, including joint training. Prior work in this area has focused on closed teams in which the number of agents is fixed. In this work, we consider open teams by allowing agents with different fixed policies to enter and leave the environment without prior notification. Our solution builds on graph neural networks to learn agent models and joint-action value models under varying team compositions. We contribute a novel action-value computation that integrates the agent model and joint-action value model to produce action-value estimates. We empirically demonstrate that our approach successfully models the effects other agents have on the learner, leading to policies that robustly adapt to dynamic team compositions and significantly outperform several alternative methods.



In real-world tasks, reinforcement learning (RL) agents frequently encounter situations that are not present during training time. To ensure reliable performance, the RL agents need to exhibit robustness to such worst-case situations. The robust-RL framework addresses this challenge via a minimax optimization between an agent and an adversary. Previous robust RL algorithms are either sample inefficient, lack robustness guarantees, or do not scale to large problems. We propose the Robust Hallucinated Upper-Confidence RL (RH-UCRL) algorithm to provably solve this problem while attaining near-optimal sample complexity guarantees. RH-UCRL is a model-based reinforcement learning (MBRL) algorithm that effectively distinguishes between epistemic and aleatoric uncertainty and efficiently explores both the agent and the adversary decision spaces during policy learning. We scale RH-UCRL to complex tasks via neural networks ensemble models as well as neural network policies. Experimentally we demonstrate that RH-UCRL outperforms other robust deep RL algorithms in a variety of adversarial environments.
Oral: Reinforcement Learning 12 Wed 21 Jul 03:00 p.m.


One principled approach for provably efficient exploration is incorporating the upper confidence bound (UCB) into the value function as a bonus. However, UCB is specified to deal with linear and tabular settings and is incompatible with Deep Reinforcement Learning (DRL). In this paper, we propose a principled exploration method for DRL through Optimistic Bootstrapping and Backward Induction (OB2I). OB2I constructs a general-purpose UCB-bonus through non-parametric bootstrap in DRL. The UCB-bonus estimates the epistemic uncertainty of state-action pairs for optimistic exploration. We build theoretical connections between the proposed UCB-bonus and the LSVI-UCB in linear setting. We propagate future uncertainty in a time-consistent manner through episodic backward update, which exploits the theoretical advantage and empirically improves the sample-efficiency. Our experiments in MNIST maze and Atari suit suggest that OB2I outperforms several state-of-the-art exploration approaches.

Q-learning (QL), a common reinforcement learning algorithm, suffers from over-estimation bias due to the maximization term in the optimal Bellman operator. This bias may lead to sub-optimal behavior. Double-Q-learning tackles this issue by utilizing two estimators, yet results in an under-estimation bias. Similar to over-estimation in Q-learning, in certain scenarios, the under-estimation bias may degrade performance. In this work, we introduce a new bias-reduced algorithm called Ensemble Bootstrapped Q-Learning (EBQL), a natural extension of Double-Q-learning to ensembles. We analyze our method both theoretically and empirically. Theoretically, we prove that EBQL-like updates yield lower MSE when estimating the maximal mean of a set of independent random variables. Empirically, we show that there exist domains where both over and under-estimation result in sub-optimal performance. Finally, We demonstrate the superior performance of a deep RL variant of EBQL over other deep QL algorithms for a suite of ATARI games.


We consider the setting of iterative learning control, or model-based policy learning in the presence of uncertain, time-varying dynamics. In this setting, we propose a new performance metric, planning regret, which replaces the standard stochastic uncertainty assumptions with worst case regret. Based on recent advances in non-stochastic control, we design a new iterative algorithm for minimizing planning regret that is more robust to model mismatch and uncertainty. We provide theoretical and empirical evidence that the proposed algorithm outperforms existing methods on several benchmarks.

Reinforcement learning is a powerful approach to learn behaviour through interactions with an environment. However, behaviours are usually learned in a purely reactive fashion, where an appropriate action is selected based on an observation. In this form, it is challenging to learn when it is necessary to execute new decisions. This makes learning inefficient especially in environments that need various degrees of fine and coarse control. To address this, we propose a proactive setting in which the agent not only selects an action in a state but also for how long to commit to that action. Our TempoRL approach introduces skip connections between states and learns a skip-policy for repeating the same action along these skips. We demonstrate the effectiveness of TempoRL on a variety of traditional and deep RL environments, showing that our approach is capable of learning successful policies up to an order of magnitude faster than vanilla Q-learning.

Importance sampling-based estimators for off-policy evaluation (OPE) are valued for their simplicity, unbiasedness, and reliance on relatively few assumptions. However, the variance of these estimators is often high, especially when trajectories are of different lengths. In this work, we introduce Omitting-States-Irrelevant-to-Return Importance Sampling (OSIRIS), an estimator which reduces variance by strategically omitting likelihood ratios associated with certain states. We formalize the conditions under which OSIRIS is unbiased and has lower variance than ordinary importance sampling, and we demonstrate these properties empirically.
Oral: Online Learning 1 Wed 21 Jul 03:00 p.m.


Many inference problems, such as sequential decision problems like A/B testing, adaptive sampling schemes like bandit selection, are often online in nature. The fundamental problem for online inference is to provide a sequence of confidence intervals that are valid uniformly over the growing-into-infinity sample sizes. To address this question, we provide a near-optimal confidence sequence for bounded random variables by utilizing Bentkus' concentration results. We show that it improves on the existing approaches that use the Cram{\'e}r-Chernoff technique such as the Hoeffding, Bernstein, and Bennett inequalities. The resulting confidence sequence is confirmed to be favorable in synthetic coverage problems, adaptive stopping algorithms, and multi-armed bandit problems.



There is growing awareness and concern about fairness in machine learning and algorithm design. This is particularly true in online selection problems where decisions are often biased, for example, when assessing credit risks or hiring staff. We address the issues of fairness and bias in online selection by introducing multi-color versions of the classic secretary and prophet problem. Interestingly, existing algorithms for these problems are either very unfair or very inefficient, so we develop optimal fair algorithms for these new problems and provide tight bounds on their competitiveness. We validate our theoretical findings on real-world data.

We propose the ChaCha (Champion-Challengers) algorithm for making an online choice of hyperparameters in online learning settings. ChaCha handles the process of determining a champion and scheduling a set of `live' challengers over time based on sample complexity bounds. It is guaranteed to have sublinear regret after the optimal configuration is added into consideration by an application-dependent oracle based on the champions. Empirically, we show that ChaCha provides good performance across a wide array of datasets when optimizing over featurization and hyperparameter decisions.

Affinity Workshop: Women in Machine Learning (WiML) Un-Workshop Wed 21 Jul 03:40 p.m.
The Women in Machine Learning (WiML) workshop was founded in 2006 to forge connections within the relatively small community of women working in machine learning, to encourage mentorship, exchange of ideas, and promote communication. The program features 4 invited talks, 4 breakout sessions each having 2-8 parallel webinars, a panel with discussions on “industry/academic research, how to choose your path” and “post-pandemic adjustment and tips”, a mentoring social and 4 sponsor expo talks. Please refer to https://wimlworkshop.org/icml2021/program/ for more information.
The workshop attracts representatives from both academia and industry, whose contributed talks showcase some of the cutting-edge research done by women. In addition to technical presentations and discussion, the workshop aims to incite debate on promising research avenues and career choices for machine learning professionals. Details about WiML’s history and past events can be found at www.wimlworkshop.org. WiML workshops are overseen by the WiML Board of Directors, who select and oversee the organizing committee for each year’s workshop.
Oral: Applications (Bio) 1 Wed 21 Jul 04:00 p.m.

An important problem in systems neuroscience is to identify the latent dynamics underlying neural population activity. Here we address this problem by introducing a low-dimensional nonlinear model for latent neural population dynamics using neural ordinary differential equations (neural ODEs), with noisy sensory inputs and Poisson spike train outputs. We refer to this as the Poisson Latent Neural Differential Equations (PLNDE) model. We apply the PLNDE framework to a variety of synthetic datasets, and show that it accurately infers the phase portraits and fixed points of nonlinear systems augmented to produce spike train data, including the FitzHugh-Nagumo oscillator, a 3-dimensional nonlinear spiral, and a nonlinear sensory decision-making model with attractor dynamics. Our model significantly outperforms existing methods at inferring single-trial neural firing rates and the corresponding latent trajectories that generated them, especially in the regime where the spike counts and number of trials are low. We then apply our model to multi-region neural population recordings from medial frontal cortex of rats performing an auditory decision-making task. Our model provides a general, interpretable framework for investigating the neural mechanisms of decision-making and other cognitive computations through the lens of dynamical systems.

Organ transplantation is often the last resort for treating end-stage illnesses, but managing transplant wait-lists is challenging because of organ scarcity and the complexity of assessing donor-recipient compatibility. In this paper, we develop a data-driven model for (real-time) organ allocation using observational data for transplant outcomes. Our model integrates a queuing-theoretic framework with unsupervised learning to cluster the organs into ``organ types'', and then construct priority queues (associated with each organ type) wherein incoming patients are assigned. To reason about organ allocations, the model uses synthetic controls to infer a patient's survival outcomes under counterfactual allocations to the different organ types– the model is trained end-to-end to optimise the trade-off between patient waiting time and expected survival time. The usage of synthetic controls enable patient-level interpretations of allocation decisions that can be presented and understood by clinicians. We test our model on multiple data sets, and show that it outperforms other organ-allocation policies in terms of added life-years, and death count. Furthermore, we introduce a novel organ-allocation simulator to accurately test new policies.

CNNs and computational models of biological vision share some fundamental principles, which opened new avenues of research. However, fruitful cross-field research is hampered by conventional CNN architectures being based on spatially and depthwise discrete representations, which cannot accommodate certain aspects of biological complexity such as continuously varying receptive field sizes and dynamics of neuronal responses. Here we propose deep continuous networks (DCNs), which combine spatially continuous filters, with the continuous depth framework of neural ODEs. This allows us to learn the spatial support of the filters during training, as well as model the continuous evolution of feature maps, linking DCNs closely to biological models. We show that DCNs are versatile and highly applicable to standard image classification and reconstruction problems, where they improve parameter and data efficiency, and allow for meta-parametrization. We illustrate the biological plausibility of the scale distributions learned by DCNs and explore their performance in a neuroscientifically inspired pattern completion task. Finally, we investigate an efficient implementation of DCNs by changing input contrast.

In this paper, we propose a conceptually simple but very effective attention module for Convolutional Neural Networks (ConvNets). In contrast to existing channel-wise and spatial-wise attention modules, our module instead infers 3-D attention weights for the feature map in a layer without adding parameters to the original networks. Specifically, we base on some well-known neuroscience theories and propose to optimize an energy function to find the importance of each neuron. We further derive a fast closed-form solution for the energy function, and show that the solution can be implemented in less than ten lines of code. Another advantage of the module is that most of the operators are selected based on the solution to the defined energy function, avoiding too many efforts for structure tuning. Quantitative evaluations on various visual tasks demonstrate that the proposed module is flexible and effective to improve the representation ability of many ConvNets. Our code is available at Pytorch-SimAM.

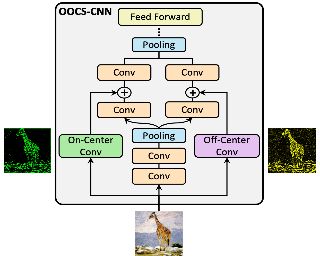
Robustness to variations in lighting conditions is a key objective for any deep vision system. To this end, our paper extends the receptive field of convolutional neural networks with two residual components, ubiquitous in the visual processing system of vertebrates: On-center and off-center pathways, with an excitatory center and inhibitory surround; OOCS for short. The On-center pathway is excited by the presence of a light stimulus in its center, but not in its surround, whereas the Off-center pathway is excited by the absence of a light stimulus in its center, but not in its surround. We design OOCS pathways via a difference of Gaussians, with their variance computed analytically from the size of the receptive fields. OOCS pathways complement each other in their response to light stimuli, ensuring this way a strong edge-detection capability, and as a result an accurate and robust inference under challenging lighting conditions. We provide extensive empirical evidence showing that networks supplied with OOCS pathways gain accuracy and illumination-robustness from the novel edge representation, compared to other baselines.
For machine agents to successfully interact with humans in real-world settings, they will need to develop an understanding of human mental life. Intuitive psychology, the ability to reason about hidden mental variables that drive observable actions, comes naturally to people: even pre-verbal infants can tell agents from objects, expecting agents to act efficiently to achieve goals given constraints. Despite recent interest in machine agents that reason about other agents, it is not clear if such agents learn or hold the core psychology principles that drive human reasoning. Inspired by cognitive development studies on intuitive psychology, we present a benchmark consisting of a large dataset of procedurally generated 3D animations, AGENT (Action, Goal, Efficiency, coNstraint, uTility), structured around four scenarios (goal preferences, action efficiency, unobserved constraints, and cost-reward trade-offs) that probe key concepts of core intuitive psychology. We validate AGENT with human-ratings, propose an evaluation protocol emphasizing generalization, and compare two strong baselines built on Bayesian inverse planning and a Theory of Mind neural network. Our results suggest that to pass the designed tests of core intuitive psychology at human levels, a model must acquire or have built-in representations of how agents plan, combining utility computations and core knowledge of objects …
Oral: Reinforcement Learning 13 Wed 21 Jul 04:00 p.m.

Learning composable policies for environments with complex rules and tasks is a challenging problem. We introduce a hierarchical reinforcement learning framework called the Logical Options Framework (LOF) that learns policies that are satisfying, optimal, and composable. LOF efficiently learns policies that satisfy tasks by representing the task as an automaton and integrating it into learning and planning. We provide and prove conditions under which LOF will learn satisfying, optimal policies. And lastly, we show how LOF's learned policies can be composed to satisfy unseen tasks with only 10-50 retraining steps on our benchmarks. We evaluate LOF on four tasks in discrete and continuous domains, including a 3D pick-and-place environment.


It has been a challenge to learning skills for an agent from long-horizon unannotated demonstrations. Existing approaches like Hierarchical Imitation Learning(HIL) are prone to compounding errors or suboptimal solutions. In this paper, we propose Option-GAIL, a novel method to learn skills at long horizon. The key idea of Option-GAIL is modeling the task hierarchy by options and train the policy via generative adversarial optimization. In particular, we propose an Expectation-Maximization(EM)-style algorithm: an E-step that samples the options of expert conditioned on the current learned policy, and an M-step that updates the low- and high-level policies of agent simultaneously to minimize the newly proposed option-occupancy measurement between the expert and the agent. We theoretically prove the convergence of the proposed algorithm. Experiments show that Option-GAIL outperforms other counterparts consistently across a variety of tasks.

Classical value iteration approaches are not applicable to environments with continuous states and actions. For such environments the states and actions must be discretized, which leads to an exponential increase in computational complexity. In this paper, we propose continuous fitted value iteration (cFVI). This algorithm enables dynamic programming for continuous states and actions with a known dynamics model. Exploiting the continuous time formulation, the optimal policy can be derived for non-linear control-affine dynamics. This closed-form solution enables the efficient extension of value iteration to continuous environments. We show in non-linear control experiments that the dynamic programming solution obtains the same quantitative performance as deep reinforcement learning methods in simulation but excels when transferred to the physical system.The policy obtained by cFVI is more robust to changes in the dynamics despite using only a deterministic model and without explicitly incorporating robustness in the optimization
Oral: Kernel Methods Wed 21 Jul 04:00 p.m.


We propose to analyse the conditional distributional treatment effect (CoDiTE), which, in contrast to the more common conditional average treatment effect (CATE), is designed to encode a treatment's distributional aspects beyond the mean. We first introduce a formal definition of the CoDiTE associated with a distance function between probability measures. Then we discuss the CoDiTE associated with the maximum mean discrepancy via kernel conditional mean embeddings, which, coupled with a hypothesis test, tells us whether there is any conditional distributional effect of the treatment. Finally, we investigate what kind of conditional distributional effect the treatment has, both in an exploratory manner via the conditional witness function, and in a quantitative manner via U-statistic regression, generalising the CATE to higher-order moments. Experiments on synthetic, semi-synthetic and real datasets demonstrate the merits of our approach.

The problem of adversarial examples has highlighted the need for a theory of regularisation that is general enough to apply to exotic function classes, such as universal approximators. In response, we have been able to significantly sharpen existing results regarding the relationship between distributional robustness and regularisation, when defined with a transportation cost uncertainty set. The theory allows us to characterise the conditions under which the distributional robustness equals a Lipschitz-regularised model, and to tightly quantify, for the first time, the slackness under very mild assumptions. As a theoretical application we show a new result explicating the connection between adversarial learning and distributional robustness. We then give new results for how to achieve Lipschitz regularisation of kernel classifiers, which are demonstrated experimentally.

In many applications, we encounter data on Riemannian manifolds such as torus and rotation groups. Standard statistical procedures for multivariate data are not applicable to such data. In this study, we develop goodness-of-fit testing and interpretable model criticism methods for general distributions on Riemannian manifolds, including those with an intractable normalization constant. The proposed methods are based on extensions of kernel Stein discrepancy, which are derived from Stein operators on Riemannian manifolds. We discuss the connections between the proposed tests with existing ones and provide a theoretical analysis of their asymptotic Bahadur efficiency. Simulation results and real data applications show the validity and usefulness of the proposed methods.

Recent empirical evidence suggests that the Weston-Watkins support vector machine is among the best performing multiclass extensions of the binary SVM. Current state-of-the-art solvers repeatedly solve a particular subproblem approximately using an iterative strategy. In this work, we propose an algorithm that solves the subproblem exactly using a novel reparametrization of the Weston-Watkins dual problem. For linear WW-SVMs, our solver shows significant speed-up over the state-of-the-art solver when the number of classes is large. Our exact subproblem solver also allows us to prove linear convergence of the overall solver.

We address the problem of causal effect estima-tion in the presence of unobserved confounding,but where proxies for the latent confounder(s) areobserved. We propose two kernel-based meth-ods for nonlinear causal effect estimation in thissetting: (a) a two-stage regression approach, and(b) a maximum moment restriction approach. Wefocus on the proximal causal learning setting, butour methods can be used to solve a wider classof inverse problems characterised by a Fredholmintegral equation. In particular, we provide a uni-fying view of two-stage and moment restrictionapproaches for solving this problem in a nonlin-ear setting. We provide consistency guaranteesfor each algorithm, and demonstrate that these ap-proaches achieve competitive results on syntheticdata and data simulating a real-world task. In par-ticular, our approach outperforms earlier methodsthat are not suited to leveraging proxy variables.

We study fast algorithms for computing basic properties of an n x n positive semidefinite kernel matrix K corresponding to n points x1,...,xn in R^d. In particular, we consider the estimating the sum of kernel matrix entries, along with its top eigenvalue and eigenvector. These are some of the most basic problems defined over kernel matrices.
We show that the sum of matrix entries can be estimated up to a multiplicative factor of 1+\epsilon in time sublinear in n and linear in d for many popular kernel functions, including the Gaussian, exponential, and rational quadratic kernels. For these kernels, we also show that the top eigenvalue (and a witnessing approximate eigenvector) can be approximated to a multiplicative factor of 1+\epsilon in time sub-quadratic in n and linear in d.
Our algorithms represent significant advances in the best known runtimes for these problems. They leverage the positive definiteness of the kernel matrix, along with a recent line of work on efficient kernel density estimation.
Oral: Time Series 1 Wed 21 Jul 04:00 p.m.
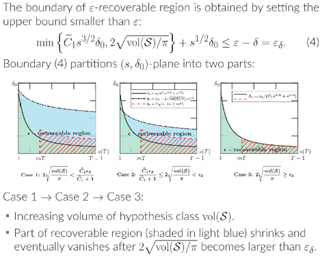
Sequential data with serial correlation and an unknown, unstructured, and dynamic background is ubiquitous in neuroscience, psychology, and econometrics. Inferring serial correlation for such data is a fundamental challenge in statistics. We propose a Total Variation (TV) constrained least square estimator coupled with hypothesis tests to infer the serial correlation in the presence of unknown and unstructured dynamic background. The TV constraint on the dynamic background encourages a piecewise constant structure, which can approximate a wide range of dynamic backgrounds. The tuning parameter is selected via the Ljung-Box test to control the bias-variance trade-off. We establish a non-asymptotic upper bound for the estimation error through variational inequalities. We also derive a lower error bound via Fano's method and show the proposed method is near-optimal. Numerical simulation and a real study in psychology demonstrate the excellent performance of our proposed method compared with the state-of-the-art.

In large-scale time series forecasting, one often encounters the situation where the temporal patterns of time series, while drifting over time, differ from one another in the same dataset. In this paper, we provably show under such heterogeneity, training a forecasting model with commonly used stochastic optimizers (e.g. SGD) potentially suffers large variance on gradient estimation, and thus incurs long-time training. We show that this issue can be efficiently alleviated via stratification, which allows the optimizer to sample from pre-grouped time series strata. For better trading-off gradient variance and computation complexity, we further propose SCott (Stochastic Stratified Control Variate Gradient Descent), a variance reduced SGD-style optimizer that utilizes stratified sampling via control variate. In theory, we provide the convergence guarantee of SCott on smooth non-convex objectives. Empirically, we evaluate SCott and other baseline optimizers on both synthetic and real-world time series forecasting problems, and demonstrate SCott converges faster with respect to both iterations and wall clock time.
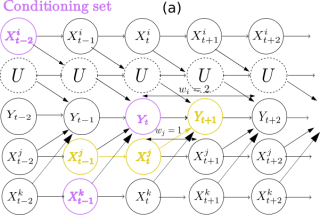
We study the identification of direct and indirect causes on time series with latent variables, and provide a constrained-based causal feature selection method, which we prove that is both sound and complete under some graph constraints. Our theory and estimation algorithm require only two conditional independence tests for each observed candidate time series to determine whether or not it is a cause of an observed target time series. Furthermore, our selection of the conditioning set is such that it improves signal to noise ratio. We apply our method on real data, and on a wide range of simulated experiments, which yield very low false positive and relatively low false negative rates.

Multiplying matrices is among the most fundamental and most computationally demanding operations in machine learning and scientific computing. Consequently, the task of efficiently approximating matrix products has received significant attention.
We introduce a learning-based algorithm for this task that greatly outperforms existing methods. Experiments using hundreds of matrices from diverse domains show that it often runs 10x faster than alternatives at a given level of error, as well as 100x faster than exact matrix multiplication. In the common case that one matrix is known ahead of time, our method also has the interesting property that it requires zero multiply-adds.
These results suggest that a mixture of hashing, averaging, and byte shuffling—the core operations of our method—could be a more promising building block for machine learning than the sparsified, factorized, and/or scalar quantized matrix products that have recently been the focus of substantial research and hardware investment.

We propose a model for multiclass classification of time series to make a prediction as early and as accurate as possible. The matrix sequential probability ratio test (MSPRT) is known to be asymptotically optimal for this setting, but contains a critical assumption that hinders broad real-world applications; the MSPRT requires the underlying probability density. To address this problem, we propose to solve density ratio matrix estimation (DRME), a novel type of density ratio estimation that consists of estimating matrices of multiple density ratios with constraints and thus is more challenging than the conventional density ratio estimation. We propose a log-sum-exp-type loss function (LSEL) for solving DRME and prove the following: (i) the LSEL provides the true density ratio matrix as the sample size of the training set increases (consistency); (ii) it assigns larger gradients to harder classes (hard class weighting effect); and (iii) it provides discriminative scores even on class-imbalanced datasets (guess-aversion). Our overall architecture for early classification, MSPRT-TANDEM, statistically significantly outperforms baseline models on four datasets including action recognition, especially in the early stage of sequential observations. Our code and datasets are publicly available.

We consider the learning and prediction of nonlinear time series generated by a latent symplectic map. A special case is (not necessarily separable) Hamiltonian systems, whose solution flows give such symplectic maps. For this special case, both generic approaches based on learning the vector field of the latent ODE and specialized approaches based on learning the Hamiltonian that generates the vector field exist. Our method, however, is different as it does not rely on the vector field nor assume its existence; instead, it directly learns the symplectic evolution map in discrete time. Moreover, we do so by representing the symplectic map via a generating function, which we approximate by a neural network (hence the name GFNN). This way, our approximation of the evolution map is always \emph{exactly} symplectic. This additional geometric structure allows the local prediction error at each step to accumulate in a controlled fashion, and we will prove, under reasonable assumptions, that the global prediction error grows at most \emph{linearly} with long prediction time, which significantly improves an otherwise exponential growth. In addition, as a map-based and thus purely data-driven method, GFNN avoids two additional sources of inaccuracies common in vector-field based approaches, namely the error in approximating …

Learning nonlinear dynamics from aggregate data is a challenging problem because the full trajectory of each individual is not available, namely, the individual observed at one time may not be observed at the next time point, or the identity of individual is unavailable. This is in sharp contrast to learning dynamics with full trajectory data, on which the majority of existing methods are based. We propose a novel method using the weak form of Fokker Planck Equation (FPE) --- a partial differential equation --- to describe the density evolution of data in a sampled form, which is then combined with Wasserstein generative adversarial network (WGAN) in the training process. In such a sample-based framework we are able to learn the nonlinear dynamics from aggregate data without explicitly solving the partial differential equation (PDE) FPE. We demonstrate our approach in the context of a series of synthetic and real-world data sets.
Oral: Sparsity and Compressed Sensing Wed 21 Jul 04:00 p.m.

Deep neural networks give state-of-the-art accuracy for reconstructing images from few and noisy measurements, a problem arising for example in accelerated magnetic resonance imaging (MRI). However, recent works have raised concerns that deep-learning-based image reconstruction methods are sensitive to perturbations and are less robust than traditional methods: Neural networks (i) may be sensitive to small, yet adversarially-selected perturbations, (ii) may perform poorly under distribution shifts, and (iii) may fail to recover small but important features in an image. In order to understand the sensitivity to such perturbations, in this work, we measure the robustness of different approaches for image reconstruction including trained and un-trained neural networks as well as traditional sparsity-based methods. We find, contrary to prior works, that both trained and un-trained methods are vulnerable to adversarial perturbations. Moreover, both trained and un-trained methods tuned for a particular dataset suffer very similarly from distribution shifts. Finally, we demonstrate that an image reconstruction method that achieves higher reconstruction quality, also performs better in terms of accurately recovering fine details. Our results indicate that the state-of-the-art deep-learning-based image reconstruction methods provide improved performance than traditional methods without compromising robustness.

We characterize the measurement complexity of compressed sensing of signals drawn from a known prior distribution, even when the support of the prior is the entire space (rather than, say, sparse vectors). We show for Gaussian measurements and \emph{any} prior distribution on the signal, that the posterior sampling estimator achieves near-optimal recovery guarantees. Moreover, this result is robust to model mismatch, as long as the distribution estimate (e.g., from an invertible generative model) is close to the true distribution in Wasserstein distance. We implement the posterior sampling estimator for deep generative priors using Langevin dynamics, and empirically find that it produces accurate estimates with more diversity than MAP.

Much of the theory for classical sparse recovery is based on conditions on the dictionary that are both necessary and sufficient (e.g., nullspace property) or only sufficient (e.g., incoherence and restricted isometry). In contrast, much of the theory for subspace-preserving recovery, the theoretical underpinnings for sparse subspace classification and clustering methods, is based on conditions on the subspaces and the data that are only sufficient (e.g., subspace incoherence and data inner-radius). This paper derives a necessary and sufficient condition for subspace-preserving recovery that is inspired by the classical nullspace property.Based on this novel condition, called here the subspace nullspace property, we derive equivalent characterizations that either admit a clear geometric interpretation that relates data distribution and subspace separation to the recovery success, or can be verified using a finite set of extreme points of a properly defined set. We further exploit these characterizations to derive new sufficient conditions, based on inner-radius and outer-radius measures and dual bounds, that generalize existing conditions and preserve the geometric interpretations. These results fill an important gap in the subspace-preserving recovery literature.

\emph{Unlabeled sensing} is a recent problem encompassing many data science and engineering applications and typically formulated as solving linear equations whose right-hand side vector has undergone an unknown permutation. It was generalized to the \emph{homomorphic sensing} problem by replacing the unknown permutation with an unknown linear map from a given finite set of linear maps. In this paper we present tighter and simpler conditions for the homomorphic sensing problem to admit a unique solution. We show that this solution is locally stable under noise, while under a sparsity assumption it remains unique under less demanding conditions. Sparsity in the context of unlabeled sensing leads to the problem of \textit{unlabeled compressed sensing}, and a consequence of our general theory is the existence under mild conditions of a unique sparsest solution. On the algorithmic level, we solve unlabeled compressed sensing by an iterative algorithm validated by synthetic data experiments. Finally, under the unifying homomorphic sensing framework we connect unlabeled sensing to other important practical problems.

Subsampling a signal of interest can reduce costly data transfer, battery drain, radiation exposure and acquisition time in a wide range of problems. The recently proposed Deep Probabilistic Subsampling (DPS) method effectively integrates subsampling in an end-to-end deep learning model, but learns a static pattern for all datapoints. We generalize DPS to a sequential method that actively picks the next sample based on the information acquired so far; dubbed Active-DPS (A-DPS). We validate that A-DPS improves over DPS for MNIST classification at high subsampling rates. Moreover, we demonstrate strong performance in active acquisition Magnetic Resonance Image (MRI) reconstruction, outperforming DPS and other deep learning methods.

Obtaining a useful estimate of an object from highly incomplete imaging measurements remains a holy grail of imaging science. Deep learning methods have shown promise in learning object priors or constraints to improve the conditioning of an ill-posed imaging inverse problem. In this study, a framework for estimating an object of interest that is semantically related to a known prior image, is proposed. An optimization problem is formulated in the disentangled latent space of a style-based generative model, and semantically meaningful constraints are imposed using the disentangled latent representation of the prior image. Stable recovery from incomplete measurements with the help of a prior image is theoretically analyzed. Numerical experiments demonstrating the superior performance of our approach as compared to related methods are presented.

We propose Intermediate Layer Optimization (ILO), a novel optimization algorithm for solving inverse problems with deep generative models. Instead of optimizing only over the initial latent code, we progressively change the input layer obtaining successively more expressive generators. To explore the higher dimensional spaces, our method searches for latent codes that lie within a small l1 ball around the manifold induced by the previous layer. Our theoretical analysis shows that by keeping the radius of the ball relatively small, we can improve the established error bound for compressed sensing with deep generative models. We empirically show that our approach outperforms state-of-the-art methods introduced in StyleGAN2 and PULSE for a wide range of inverse problems including inpainting, denoising, super-resolution and compressed sensing.
Spotlight: Reinforcement Learning and Bandits Wed 21 Jul 04:00 p.m.

In offline reinforcement learning (RL), we seek to utilize offline data to evaluate (or learn) policies in scenarios where the data are collected from a distribution that substantially differs from that of the target policy to be evaluated. Recent theoretical advances have shown that such sample-efficient offline RL is indeed possible provided certain strong representational conditions hold, else there are lower bounds exhibiting exponential error amplification (in the problem horizon) unless the data collection distribution has only a mild distribution shift relative to the target policy. This work studies these issues from an empirical perspective to gauge how stable offline RL methods are. In particular, our methodology explores these ideas when using features from pre-trained neural networks, in the hope that these representations are powerful enough to permit sample efficient offline RL. Through extensive experiments on a range of tasks, we see that substantial error amplification does occur even when using such pre-trained representations (trained on the same task itself); we find offline RL is stable only under extremely mild distribution shift. The implications of these results, both from a theoretical and an empirical perspective, are that successful offline RL (where we seek to go beyond the low distribution shift …
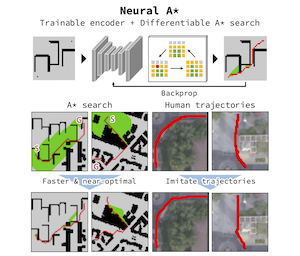
We present Neural A, a novel data-driven search method for path planning problems. Despite the recent increasing attention to data-driven path planning, machine learning approaches to search-based planning are still challenging due to the discrete nature of search algorithms. In this work, we reformulate a canonical A search algorithm to be differentiable and couple it with a convolutional encoder to form an end-to-end trainable neural network planner. Neural A* solves a path planning problem by encoding a problem instance to a guidance map and then performing the differentiable A* search with the guidance map. By learning to match the search results with ground-truth paths provided by experts, Neural A* can produce a path consistent with the ground truth accurately and efficiently. Our extensive experiments confirmed that Neural A* outperformed state-of-the-art data-driven planners in terms of the search optimality and efficiency trade-off. Furthermore, Neural A* successfully predicted realistic human trajectories by directly performing search-based planning on natural image inputs.

Sparse regression has recently been applied to enable transfer learning from very limited data. We study an extension of this approach to unsupervised learning---in particular, learning word embeddings from unstructured text corpora using low-rank matrix factorization. Intuitively, when transferring word embeddings to a new domain, we expect that the embeddings change for only a small number of words---e.g., the ones with novel meanings in that domain. We propose a novel group-sparse penalty that exploits this sparsity to perform transfer learning when there is very little text data available in the target domain---e.g., a single article of text. We prove generalization bounds for our algorithm. Furthermore, we empirically evaluate its effectiveness, both in terms of prediction accuracy in downstream tasks as well as in terms of interpretability of the results.


Training agents to autonomously control anthropomorphic robotic hands has the potential to lead to systems capable of performing a multitude of complex manipulation tasks in unstructured and uncertain environments. In this work, we first introduce a suite of challenging simulated manipulation tasks where current reinforcement learning and trajectory optimisation techniques perform poorly. These include environments where two simulated hands have to pass or throw objects between each other, as well as an environment where the agent must learn to spin a long pen between its fingers. We then introduce a simple trajectory optimisation algorithm that performs significantly better than existing methods on these environments. Finally, on the most challenging ``PenSpin" task, we combine sub-optimal demonstrations generated through trajectory optimisation with off-policy reinforcement learning, obtaining performance that far exceeds either of these approaches individually. Videos of all of our results are available at: https://dexterous-manipulation.github.io

Model-based reinforcement learning (MBRL) approaches rely on discrete-time state transition models whereas physical systems and the vast majority of control tasks operate in continuous-time. To avoid time-discretization approximation of the underlying process, we propose a continuous-time MBRL framework based on a novel actor-critic method. Our approach also infers the unknown state evolution differentials with Bayesian neural ordinary differential equations (ODE) to account for epistemic uncertainty. We implement and test our method on a new ODE-RL suite that explicitly solves continuous-time control systems. Our experiments illustrate that the model is robust against irregular and noisy data, and can solve classic control problems in a sample-efficient manner.

We introduce and analyze a best arm identification problem in the rested bandit setting, wherein arms are themselves learning algorithms whose expected losses decrease with the number of times the arm has been played. The shape of the expected loss functions is similar across arms, and is assumed to be available up to unknown parameters that have to be learned on the fly. We define a novel notion of regret for this problem, where we compare to the policy that always plays the arm having the smallest expected loss at the end of the game. We analyze an arm elimination algorithm whose regret vanishes as the time horizon increases. The actual rate of convergence depends in a detailed way on the postulated functional form of the expected losses. We complement our analysis with lower bounds, indicating strengths and limitations of the proposed solution.

Recent years have witnessed the success of multi-agent reinforcement learning, which has motivated new research directions for mean-field control (MFC) and mean-field game (MFG), as the multi-agent system can be well approximated by a mean-field problem when the number of agents grows to be very large. In this paper, we study the policy gradient (PG) method for the linear-quadratic mean-field control and game, where we assume each agent has identical linear state transitions and quadratic cost functions. While most recent works on policy gradient for MFC and MFG are based on discrete-time models, we focus on a continuous-time model where some of our analyzing techniques could be valuable to the interested readers. For both the MFC and the MFG, we provide PG update and show that it converges to the optimal solution at a linear rate, which is verified by a synthetic simulation. For the MFG, we also provide sufficient conditions for the existence and uniqueness of the Nash equilibrium.
Oral: Learning Theory 6 Wed 21 Jul 04:00 p.m.

The study of strategic or adversarial manipulation of testing data to fool a classifier has attracted much recent attention. Most previous works have focused on two extreme situations where any testing data point either is completely adversarial or always equally prefers the positive label. In this paper, we generalize both of these through a unified framework for strategic classification and introduce the notion of strategic VC-dimension (SVC) to capture the PAC-learnability in our general strategic setup. SVC provably generalizes the recent concept of adversarial VC-dimension (AVC) introduced by Cullina et al. (2018). We instantiate our framework for the fundamental strategic linear classification problem. We fully characterize: (1) the statistical learnability of linear classifiers by pinning down its SVC; (2) it's computational tractability by pinning down the complexity of the empirical risk minimization problem. Interestingly, the SVC of linear classifiers is always upper bounded by its standard VC-dimension. This characterization also strictly generalizes the AVC bound for linear classifiers in (Cullina et al., 2018).



Choosing the right parameters for optimization algorithms is often the key to their success in practice. Solving this problem using a learning-to-learn approach---using meta-gradient descent on a meta-objective based on the trajectory that the optimizer generates---was recently shown to be effective. However, the meta-optimization problem is difficult. In particular, the meta-gradient can often explode/vanish, and the learned optimizer may not have good generalization performance if the meta-objective is not chosen carefully. In this paper we give meta-optimization guarantees for the learning-to-learn approach on a simple problem of tuning the step size for quadratic loss. Our results show that the na\"ive objective suffers from meta-gradient explosion/vanishing problem. Although there is a way to design the meta-objective so that the meta-gradient remains polynomially bounded, computing the meta-gradient directly using backpropagation leads to numerical issues. We also characterize when it is necessary to compute the meta-objective on a separate validation set to ensure the generalization performance of the learned optimizer. Finally, we verify our results empirically and show that a similar phenomenon appears even for more complicated learned optimizers parametrized by neural networks.

In this paper we present a scalable deep learning framework for finding Markovian Nash Equilibria in multi-agent stochastic games using fictitious play. The motivation is inspired by theoretical analysis of Forward Backward Stochastic Differential Equations and their implementation in a deep learning setting, which is the source of our algorithm's sample efficiency improvement. By taking advantage of the permutation-invariant property of agents in symmetric games, the scalability and performance is further enhanced significantly. We showcase superior performance of our framework over the state-of-the-art deep fictitious play algorithm on an inter-bank lending/borrowing problem in terms of multiple metrics. More importantly, our approach scales up to 3000 agents in simulation, a scale which, to the best of our knowledge, represents a new state-of-the-art. We also demonstrate the applicability of our framework in robotics on a belief space autonomous racing problem.


In recent years, federated learning has been embraced as an approach for bringing about collaboration across large populations of learning agents. However, little is known about how collaboration protocols should take agents' incentives into account when allocating individual resources for communal learning in order to maintain such collaborations. Inspired by game theoretic notions, this paper introduces a framework for incentive-aware learning and data sharing in federated learning. Our stable and envy-free equilibria capture notions of collaboration in the presence of agents interested in meeting their learning objectives while keeping their own sample collection burden low. For example, in an envy-free equilibrium, no agent would wish to swap their sampling burden with any other agent and in a stable equilibrium, no agent would wish to unilaterally reduce their sampling burden.
In addition to formalizing this framework, our contributions include characterizing the structural properties of such equilibria, proving when they exist, and showing how they can be computed. Furthermore, we compare the sample complexity of incentive-aware collaboration with that of optimal collaboration when one ignores agents' incentives.
Oral: Deep Learning Theory 3 Wed 21 Jul 04:00 p.m.
Recent work has highlighted the role of initialization scale in determining the structure of the solutions that gradient methods converge to. In particular, it was shown that large initialization leads to the neural tangent kernel regime solution, whereas small initialization leads to so called ``rich regimes''. However, the initialization structure is richer than the overall scale alone and involves relative magnitudes of different weights and layers in the network. Here we show that these relative scales, which we refer to as initialization shape, play an important role in determining the learned model. We develop a novel technique for deriving the inductive bias of gradient-flow and use it to obtain closed-form implicit regularizers for multiple cases of interest.

Knowledge distillation is a technique for improving a student'' model by replacing its one-hot training labels with a label distribution obtained from ateacher'' model. Despite its broad success, several basic questions --- e.g., Why does distillation help? Why do more accurate teachers not necessarily distill better? --- have received limited formal study. In this paper, we present a statistical perspective on distillation which provides an answer to these questions. Our core observation is that a Bayes teacher'' providing the true class-probabilities can lower the variance of the student objective, and thus improve performance. We then establish a bias-variance tradeoff that quantifies the value of teachers that approximate the Bayes class-probabilities. This provides a formal criterion as to what constitutes agood'' teacher, namely, the quality of its probability estimates. Finally, we illustrate how our statistical perspective facilitates novel applications of distillation to bipartite ranking and multiclass retrieval.

Lipschitz constants of neural networks have been explored in various contexts in deep learning, such as provable adversarial robustness, estimating Wasserstein distance, stabilising training of GANs, and formulating invertible neural networks. Such works have focused on bounding the Lipschitz constant of fully connected or convolutional networks, composed of linear maps and pointwise non-linearities. In this paper, we investigate the Lipschitz constant of self-attention, a non-linear neural network module widely used in sequence modelling. We prove that the standard dot-product self-attention is not Lipschitz for unbounded input domain, and propose an alternative L2 self-attention that is Lipschitz. We derive an upper bound on the Lipschitz constant of L2 self-attention and provide empirical evidence for its asymptotic tightness. To demonstrate the practical relevance of our theoretical work, we formulate invertible self-attention and use it in a Transformer-based architecture for a character-level language modelling task.
We study regularized deep neural networks (DNNs) and introduce a convex analytic framework to characterize the structure of the hidden layers. We show that a set of optimal hidden layer weights for a norm regularized DNN training problem can be explicitly found as the extreme points of a convex set. For the special case of deep linear networks, we prove that each optimal weight matrix aligns with the previous layers via duality. More importantly, we apply the same characterization to deep ReLU networks with whitened data and prove the same weight alignment holds. As a corollary, we also prove that norm regularized deep ReLU networks yield spline interpolation for one-dimensional datasets which was previously known only for two-layer networks. Furthermore, we provide closed-form solutions for the optimal layer weights when data is rank-one or whitened. The same analysis also applies to architectures with batch normalization even for arbitrary data. Therefore, we obtain a complete explanation for a recent empirical observation termed Neural Collapse where class means collapse to the vertices of a simplex equiangular tight frame.


We formally study how contrastive learning learns the feature representations for neural networks by investigating its feature learning process. We consider the case where our data are comprised of two types of features: the sparse features which we want to learn from, and the dense features we want to get rid of. Theoretically, we prove that contrastive learning using ReLU networks provably learns the desired features if proper augmentations are adopted. We present an underlying principle called feature decoupling to explain the effects of augmentations, where we theoretically characterize how augmentations can reduce the correlations of dense features between positive samples while keeping the correlations of sparse features intact, thereby forcing the neural networks to learn from the self-supervision of sparse features. Empirically, we verified that the feature decoupling principle matches the underlying mechanism of contrastive learning in practice.

In this work we develop a quantum field theory formalism for deep learning, where input signals are encoded in Gaussian states, a generalization of Gaussian processes which encode the agent's uncertainty about the input signal. We show how to represent linear and non-linear layers as unitary quantum gates, and interpret the fundamental excitations of the quantum model as particles, dubbed ``Hintons''. On top of opening a new perspective and techniques for studying neural networks, the quantum formulation is well suited for optical quantum computing, and provides quantum deformations of neural networks that can be run efficiently on those devices. Finally, we discuss a semi-classical limit of the quantum deformed models which is amenable to classical simulation.
Oral: Bandits 1 Wed 21 Jul 04:00 p.m.
In recent years methods from optimal linear experimental design have been leveraged to obtain state of the art results for linear bandits.
A design returned from an objective such as G-optimal design is actually a probability distribution over a pool of potential measurement vectors.
Consequently, one nuisance of the approach is the task of converting this continuous probability distribution into a discrete assignment of N measurements.
While sophisticated rounding techniques have been proposed, in d dimensions they require N to be at least d, d log(log(d)), or d^2 based on the sub-optimality of the solution.
In this paper we are interested in settings where N may be much less than d, such as in experimental design in an RKHS where d may be effectively infinite.
In this work, we propose a rounding procedure that frees N of any dependence on the dimension d, while achieving nearly the same performance guarantees of existing rounding procedures.
We evaluate the procedure against a baseline that projects the problem to a lower dimensional space and performs rounding there, which requires N to just be at least a notion of the effective dimension. We also leverage our new approach in a new algorithm for kernelized …

In this paper we address a variant of the continuous multi-armed bandits problem, called the threshold estimation problem, which is at the heart of many psychometric experiments. Here, the objective is to estimate the sensitivity threshold for an unknown psychometric function Psi, which is assumed to be non decreasing and continuous. Our algorithm, Dichotomous Optimistic Search (DOS), efficiently solves this task by taking inspiration from hierarchical multi-armed bandits and Black-box optimization. Compared to previous approaches, DOS is model free and only makes minimal assumption on Psi smoothness, while having strong theoretical guarantees that compares favorably to recent methods from both Psychophysics and Global Optimization. We also empirically evaluate DOS and show that it significantly outperforms these methods, both in experiments that mimics the conduct of a psychometric experiment, and in tests with large pulls budgets that illustrate the faster convergence rate.


We study the stochastic Multi-Armed Bandit~(MAB) problem with random delays in the feedback received by the algorithm. We consider two settings: the {\it reward dependent} delay setting, where realized delays may depend on the stochastic rewards, and the {\it reward-independent} delay setting. Our main contribution is algorithms that achieve near-optimal regret in each of the settings, with an additional additive dependence on the quantiles of the delay distribution. Our results do not make any assumptions on the delay distributions: in particular, we do not assume they come from any parametric family of distributions and allow for unbounded support and expectation; we further allow for the case of infinite delays where the algorithm might occasionally not observe any feedback.
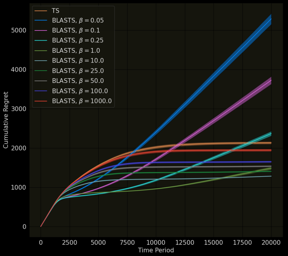
Agents that learn to select optimal actions represent a prominent focus of the sequential decision-making literature. In the face of a complex environment or constraints on time and resources, however, aiming to synthesize such an optimal policy can become infeasible. These scenarios give rise to an important trade-off between the information an agent must acquire to learn and the sub-optimality of the resulting policy. While an agent designer has a preference for how this trade-off is resolved, existing approaches further require that the designer translate these preferences into a fixed learning target for the agent. In this work, leveraging rate-distortion theory, we automate this process such that the designer need only express their preferences via a single hyperparameter and the agent is endowed with the ability to compute its own learning targets that best achieve the desired trade-off. We establish a general bound on expected discounted regret for an agent that decides what to learn in this manner along with computational experiments that illustrate the expressiveness of designer preferences and even show improvements over Thompson sampling in identifying an optimal policy.

Inhomogeneous Poisson point processes are widely used models of event occurrences. We address \emph{adaptive sensing of Poisson Point processes}, namely, maximizing the number of captured events subject to sensing costs. We encode prior assumptions on the rate function by modeling it as a member of a known \emph{reproducing kernel Hilbert space} (RKHS). By partitioning the domain into separate small regions, and using heteroscedastic linear regression, we propose a tractable estimator of Poisson process rates for two feedback models: \emph{count-record}, where exact locations of events are observed, and \emph{histogram} feedback, where only counts of events are observed. We derive provably accurate anytime confidence estimates for our estimators for sequentially acquired Poisson count data. Using these, we formulate algorithms based on optimism that provably incur sublinear count-regret. We demonstrate the practicality of the method on problems from crime modeling, revenue maximization as well as environmental monitoring.

Oral: Learning Theory 5 Wed 21 Jul 04:00 p.m.

Promoting behavioural diversity is critical for solving games with non-transitive dynamics where strategic cycles exist, and there is no consistent winner (e.g., Rock-Paper-Scissors). Yet, there is a lack of rigorous treatment for defining diversity and constructing diversity-aware learning dynamics. In this work, we offer a geometric interpretation of behavioural diversity in games and introduce a novel diversity metric based on \emph{determinantal point processes} (DPP). By incorporating the diversity metric into best-response dynamics, we develop \emph{diverse fictitious play} and \emph{diverse policy-space response oracle} for solving normal-form games and open-ended games. We prove the uniqueness of the diverse best response and the convergence of our algorithms on two-player games. Importantly, we show that maximising the DPP-based diversity metric guarantees to enlarge the \emph{gamescape} -- convex polytopes spanned by agents' mixtures of strategies. To validate our diversity-aware solvers, we test on tens of games that show strong non-transitivity. Results suggest that our methods achieve at least the same, and in most games, lower exploitability than PSRO solvers by finding effective and diverse strategies.

We study the emergence of chaotic behavior of Follow-the-Regularized Leader (FoReL) dynamics in games. We focus on the effects of increasing the population size or the scale of costs in congestion games, and generalize recent results on unstable, chaotic behaviors in the Multiplicative Weights Update dynamics to a much larger class of FoReL dynamics. We establish that, even in simple linear non-atomic congestion games with two parallel links and \emph{any} fixed learning rate, unless the game is fully symmetric, increasing the population size or the scale of costs causes learning dynamics to becomes unstable and eventually chaotic, in the sense of Li-Yorke and positive topological entropy. Furthermore, we prove the existence of novel non-standard phenomena such as the coexistence of stable Nash equilibria and chaos in the same game. We also observe the simultaneous creation of a chaotic attractor as another chaotic attractor gets destroyed. Lastly, although FoReL dynamics can be strange and non-equilibrating, we prove that the time average still converges to an \emph{exact} equilibrium for any choice of learning rate and any scale of costs.

Performative distribution shift captures the setting where the choice of which ML model is deployed changes the data distribution. For example, a bank which uses the number of open credit lines to determine a customer's risk of default on a loan may induce customers to open more credit lines in order to improve their chances of being approved. Because of the interactions between the model and data distribution, finding the optimal model parameters is challenging. Works in this area have focused on finding stable points, which can be far from optimal. Here we introduce \emph{performative gradient descent} (PerfGD), an algorithm for computing performatively optimal points. Under regularity assumptions on the performative loss, PerfGD is the first algorithm which provably converges to an optimal point. PerfGD explicitly captures how changes in the model affects the data distribution and is simple to use. We support our findings with theory and experiments.

Current deep reinforcement learning (RL) algorithms are still highly task-specific and lack the ability to generalize to new environments. Lifelong learning (LLL), however, aims at solving multiple tasks sequentially by efficiently transferring and using knowledge between tasks. Despite a surge of interest in lifelong RL in recent years, the lack of a realistic testbed makes robust evaluation of LLL algorithms difficult. Multi-agent RL (MARL), on the other hand, can be seen as a natural scenario for lifelong RL due to its inherent non-stationarity, since the agents’ policies change over time. In this work, we introduce a multi-agent lifelong learning testbed that supports both zero-shot and few-shot settings. Our setup is based on Hanabi — a partially-observable, fully cooperative multi-agent game that has been shown to be challenging for zero-shot coordination. Its large strategy space makes it a desirable environment for lifelong RL tasks. We evaluate several recent MARL methods, and benchmark state-of-the-art LLL algorithms in limited memory and computation regimes to shed light on their strengths and weaknesses. This continual learning paradigm also provides us with a pragmatic way of going beyond centralized training which is the most commonly used training protocol in MARL. We empirically show that the agents …

Hindsight rationality is an approach to playing general-sum games that prescribes no-regret learning dynamics for individual agents with respect to a set of deviations, and further describes jointly rational behavior among multiple agents with mediated equilibria. To develop hindsight rational learning in sequential decision-making settings, we formalize behavioral deviations as a general class of deviations that respect the structure of extensive-form games. Integrating the idea of time selection into counterfactual regret minimization (CFR), we introduce the extensive-form regret minimization (EFR) algorithm that achieves hindsight rationality for any given set of behavioral deviations with computation that scales closely with the complexity of the set. We identify behavioral deviation subsets, the partial sequence deviation types, that subsume previously studied types and lead to efficient EFR instances in games with moderate lengths. In addition, we present a thorough empirical analysis of EFR instantiated with different deviation types in benchmark games, where we find that stronger types typically induce better performance.
Bayesian optimization (BO) is a popular tool for optimizing complex and costly-to-evaluate black-box objective functions. To further reduce the number of function evaluations, any party performing BO may be interested to collaborate with others to optimize the same objective function concurrently. To do this, existing BO algorithms have considered optimizing a batch of input queries in parallel and provided theoretical bounds on their cumulative regret reflecting inefficiency. However, when the objective function values are correlated with real-world rewards (e.g., money), parties may be hesitant to collaborate if they risk incurring larger cumulative regret (i.e., smaller real-world reward) than others. This paper shows that fairness and efficiency are both necessary for the collaborative BO setting. Inspired by social welfare concepts from economics, we propose a new notion of regret capturing these properties and a collaborative BO algorithm whose convergence rate can be theoretically guaranteed by bounding the new regret, both of which share an adjustable parameter for trading off between fairness vs. efficiency. We empirically demonstrate the benefits (e.g., increased fairness) of our algorithm using synthetic and real-world datasets.

Quantum Neural Networks (QNNs), or the so-called variational quantum circuits, are important quantum applications both because of their similar promises as classical neural networks and because of the feasibility of their implementation on near-term intermediate-size noisy quantum machines (NISQ). However, the training task of QNNs is challenging and much less understood. We conduct a quantitative investigation on the landscape of loss functions of QNNs and identify a class of simple yet extremely hard QNN instances for training. Specifically, we show for typical under-parameterized QNNs, there exists a dataset that induces a loss function with the number of spurious local minima depending exponentially on the number of parameters. Moreover, we show the optimality of our construction by providing an almost matching upper bound on such dependence. While local minima in classical neural networks are due to non-linear activations, in quantum neural networks local minima appear as a result of the quantum interference phenomenon. Finally, we empirically confirm that our constructions can indeed be hard instances in practice with typical gradient-based optimizers, which demonstrates the practical value of our findings.
Invited Talk: Esther Duflo
Esther Duflo, Plumbers and Mechanics: How ML can complement RCT in policy experiments
In this talk, I discuss how approaches that may seem very different (randomized controlled trials and Machine Learning) can in fact be complementary. RCT can serve as a useful benchmark to evaluate the real world performance of ML strategies to recover causal effects. ML methods can be used to investigate treatment effect heterogeneity, sort through a large number of possible treatments, etc. The talk concludes with a wish list for Machine learning specialists.
Bio :
Social: Zeitgeist in NLP Wed 21 Jul 06:00 p.m.
From hunting mythical creatures, transcribing TV shows, compositionality and explainability in Deep Visual Learning to task descriptions for language models – Join us for our two-part meeting on Natural Language Processing! We will start with a panel and audience discussion including elevator pitches given by researchers and international partners of the German competence centers on AI. Afterwards we move to Gather Town, where we will have topical corners, room for further discussions, and a hang-out space for conversations in an informal atmosphere.
Poster Session 3 Wed 21 Jul 06:00 p.m.
[ Virtual ]
Many real-world situations allow for the acquisition of additional relevant information when making an assessment with limited or uncertain data. However, traditional ML approaches either require all features to be acquired beforehand or regard part of them as missing data that cannot be acquired. In this work, we consider models that perform active feature acquisition (AFA) and query the environment for unobserved features to improve the prediction assessments at evaluation time. Our work reformulates the Markov decision process (MDP) that underlies the AFA problem as a generative modeling task and optimizes a policy via a novel model-based approach. We propose learning a generative surrogate model (GSM) that captures the dependencies among input features to assess potential information gain from acquisitions. The GSM is leveraged to provide intermediate rewards and auxiliary information to aid the agent navigate a complicated high-dimensional action space and sparse rewards. Furthermore, we extend AFA in a task we coin active instance recognition (AIR) for the unsupervised case where the target variables are the unobserved features themselves and the goal is to collect information for a particular instance in a cost-efficient way. Empirical results demonstrate that our approach achieves considerably better performance than previous state of the …
[ Virtual ]
For machine agents to successfully interact with humans in real-world settings, they will need to develop an understanding of human mental life. Intuitive psychology, the ability to reason about hidden mental variables that drive observable actions, comes naturally to people: even pre-verbal infants can tell agents from objects, expecting agents to act efficiently to achieve goals given constraints. Despite recent interest in machine agents that reason about other agents, it is not clear if such agents learn or hold the core psychology principles that drive human reasoning. Inspired by cognitive development studies on intuitive psychology, we present a benchmark consisting of a large dataset of procedurally generated 3D animations, AGENT (Action, Goal, Efficiency, coNstraint, uTility), structured around four scenarios (goal preferences, action efficiency, unobserved constraints, and cost-reward trade-offs) that probe key concepts of core intuitive psychology. We validate AGENT with human-ratings, propose an evaluation protocol emphasizing generalization, and compare two strong baselines built on Bayesian inverse planning and a Theory of Mind neural network. Our results suggest that to pass the designed tests of core intuitive psychology at human levels, a model must acquire or have built-in representations of how agents plan, combining utility computations and core knowledge of objects …
[ Virtual ]
We analyze the properties of gradient descent on convex surrogates for the zero-one loss for the agnostic learning of halfspaces. We show that when a quantity we refer to as the \textit{soft margin} is well-behaved---a condition satisfied by log-concave isotropic distributions among others---minimizers of convex surrogates for the zero-one loss are approximate minimizers for the zero-one loss itself. As standard convex optimization arguments lead to efficient guarantees for minimizing convex surrogates of the zero-one loss, our methods allow for the first positive guarantees for the classification error of halfspaces learned by gradient descent using the binary cross-entropy or hinge loss in the presence of agnostic label noise.
[ Virtual ]
Recent empirical evidence suggests that the Weston-Watkins support vector machine is among the best performing multiclass extensions of the binary SVM. Current state-of-the-art solvers repeatedly solve a particular subproblem approximately using an iterative strategy. In this work, we propose an algorithm that solves the subproblem exactly using a novel reparametrization of the Weston-Watkins dual problem. For linear WW-SVMs, our solver shows significant speed-up over the state-of-the-art solver when the number of classes is large. Our exact subproblem solver also allows us to prove linear convergence of the overall solver.
[ Virtual ]
We consider a novel challenge: approximating a distribution without the ability to randomly sample from that distribution. We study how such an approximation can be obtained using weight queries. Given some data set of examples, a weight query presents one of the examples to an oracle, which returns the probability, according to the target distribution, of observing examples similar to the presented example. This oracle can represent, for instance, counting queries to a database of the target population, or an interface to a search engine which returns the number of results that match a given search.
We propose an interactive algorithm that iteratively selects data set examples and performs corresponding weight queries. The algorithm finds a reweighting of the data set that approximates the weights according to the target distribution, using a limited number of weight queries. We derive an approximation bound on the total variation distance between the reweighting found by the algorithm and the best achievable reweighting. Our algorithm takes inspiration from the UCB approach common in multi-armed bandits problems, and combines it with a new discrepancy estimator and a greedy iterative procedure. In addition to our theoretical guarantees, we demonstrate in experiments the advantages of the …
[ Virtual ]
We introduce a new unsupervised pretraining objective for reinforcement learning. During the unsupervised reward-free pretraining phase, the agent maximizes mutual information between tasks and states induced by the policy. Our key contribution is a novel lower bound of this intractable quantity. We show that by reinterpreting and combining variational successor features~\citep{Hansen2020Fast} with nonparametric entropy maximization~\citep{liu2021behavior}, the intractable mutual information can be efficiently optimized. The proposed method Active Pretraining with Successor Feature (APS) explores the environment via nonparametric entropy maximization, and the explored data can be efficiently leveraged to learn behavior by variational successor features. APS addresses the limitations of existing mutual information maximization based and entropy maximization based unsupervised RL, and combines the best of both worlds. When evaluated on the Atari 100k data-efficiency benchmark, our approach significantly outperforms previous methods combining unsupervised pretraining with task-specific finetuning.
[ Virtual ]
We consider the setting of iterative learning control, or model-based policy learning in the presence of uncertain, time-varying dynamics. In this setting, we propose a new performance metric, planning regret, which replaces the standard stochastic uncertainty assumptions with worst case regret. Based on recent advances in non-stochastic control, we design a new iterative algorithm for minimizing planning regret that is more robust to model mismatch and uncertainty. We provide theoretical and empirical evidence that the proposed algorithm outperforms existing methods on several benchmarks.
[ Virtual ]
Estimating the gradients for binary variables is a task that arises frequently in various domains, such as training discrete latent variable models. What has been commonly used is a REINFORCE based Monte Carlo estimation method that uses either independent samples or pairs of negatively correlated samples. To better utilize more than two samples, we propose ARMS, an Antithetic REINFORCE-based Multi-Sample gradient estimator. ARMS uses a copula to generate any number of mutually antithetic samples. It is unbiased, has low variance, and generalizes both DisARM, which we show to be ARMS with two samples, and the leave-one-out REINFORCE (LOORF) estimator, which is ARMS with uncorrelated samples. We evaluate ARMS on several datasets for training generative models, and our experimental results show that it outperforms competing methods. We also develop a version of ARMS for optimizing the multi-sample variational bound, and show that it outperforms both VIMCO and DisARM. The code is publicly available.
[ Virtual ]
Knowledge distillation is a technique for improving a student'' model by replacing its one-hot training labels with a label distribution obtained from ateacher'' model. Despite its broad success, several basic questions --- e.g., Why does distillation help? Why do more accurate teachers not necessarily distill better? --- have received limited formal study. In this paper, we present a statistical perspective on distillation which provides an answer to these questions. Our core observation is that a Bayes teacher'' providing the true class-probabilities can lower the variance of the student objective, and thus improve performance. We then establish a bias-variance tradeoff that quantifies the value of teachers that approximate the Bayes class-probabilities. This provides a formal criterion as to what constitutes agood'' teacher, namely, the quality of its probability estimates. Finally, we illustrate how our statistical perspective facilitates novel applications of distillation to bipartite ranking and multiclass retrieval.
[ Virtual ]
We make progress in a long-standing problem of batch reinforcement learning (RL): learning Q* from an exploratory and polynomial-sized dataset, using a realizable and otherwise arbitrary function class. In fact, all existing algorithms demand function-approximation assumptions stronger than realizability, and the mounting negative evidence has led to a conjecture that sample-efficient learning is impossible in this setting (Chen & Jiang, 2019). Our algorithm, BVFT, breaks the hardness conjecture (albeit under a stronger notion of exploratory data) via a tournament procedure that reduces the learning problem to pairwise comparison, and solves the latter with the help of a state-action-space partition constructed from the compared functions. We also discuss how BVFT can be applied to model selection among other extensions and open problems.
[ Virtual ]
We introduce and analyze a best arm identification problem in the rested bandit setting, wherein arms are themselves learning algorithms whose expected losses decrease with the number of times the arm has been played. The shape of the expected loss functions is similar across arms, and is assumed to be available up to unknown parameters that have to be learned on the fly. We define a novel notion of regret for this problem, where we compare to the policy that always plays the arm having the smallest expected loss at the end of the game. We analyze an arm elimination algorithm whose regret vanishes as the time horizon increases. The actual rate of convergence depends in a detailed way on the postulated functional form of the expected losses. We complement our analysis with lower bounds, indicating strengths and limitations of the proposed solution.
[ Virtual ]
[ Virtual ]
This work introduces Bilinear Classes, a new structural framework, which permit generalization in reinforcement learning in a wide variety of settings through the use of function approximation. The framework incorporates nearly all existing models in which a polynomial sample complexity is achievable, and, notably, also includes new models, such as the Linear Q/V model in which both the optimal Q-function and the optimal V-function are linear in some known feature space. Our main result provides an RL algorithm which has polynomial sample complexity for Bilinear Classes; notably, this sample complexity is stated in terms of a reduction to the generalization error of an underlying supervised learning sub-problem. These bounds nearly match the best known sample complexity bounds for existing models. Furthermore, this framework also extends to the infinite dimensional (RKHS) setting: for the the Linear Q/V model, linear MDPs, and linear mixture MDPs, we provide sample complexities that have no explicit dependence on the explicit feature dimension (which could be infinite), but instead depends only on information theoretic quantities.
[ Virtual ]
In real-world tasks, reinforcement learning (RL) agents frequently encounter situations that are not present during training time. To ensure reliable performance, the RL agents need to exhibit robustness to such worst-case situations. The robust-RL framework addresses this challenge via a minimax optimization between an agent and an adversary. Previous robust RL algorithms are either sample inefficient, lack robustness guarantees, or do not scale to large problems. We propose the Robust Hallucinated Upper-Confidence RL (RH-UCRL) algorithm to provably solve this problem while attaining near-optimal sample complexity guarantees. RH-UCRL is a model-based reinforcement learning (MBRL) algorithm that effectively distinguishes between epistemic and aleatoric uncertainty and efficiently explores both the agent and the adversary decision spaces during policy learning. We scale RH-UCRL to complex tasks via neural networks ensemble models as well as neural network policies. Experimentally we demonstrate that RH-UCRL outperforms other robust deep RL algorithms in a variety of adversarial environments.
[ Virtual ]
We propose to analyse the conditional distributional treatment effect (CoDiTE), which, in contrast to the more common conditional average treatment effect (CATE), is designed to encode a treatment's distributional aspects beyond the mean. We first introduce a formal definition of the CoDiTE associated with a distance function between probability measures. Then we discuss the CoDiTE associated with the maximum mean discrepancy via kernel conditional mean embeddings, which, coupled with a hypothesis test, tells us whether there is any conditional distributional effect of the treatment. Finally, we investigate what kind of conditional distributional effect the treatment has, both in an exploratory manner via the conditional witness function, and in a quantitative manner via U-statistic regression, generalising the CATE to higher-order moments. Experiments on synthetic, semi-synthetic and real datasets demonstrate the merits of our approach.
[ Virtual ]
Current deep reinforcement learning (RL) algorithms are still highly task-specific and lack the ability to generalize to new environments. Lifelong learning (LLL), however, aims at solving multiple tasks sequentially by efficiently transferring and using knowledge between tasks. Despite a surge of interest in lifelong RL in recent years, the lack of a realistic testbed makes robust evaluation of LLL algorithms difficult. Multi-agent RL (MARL), on the other hand, can be seen as a natural scenario for lifelong RL due to its inherent non-stationarity, since the agents’ policies change over time. In this work, we introduce a multi-agent lifelong learning testbed that supports both zero-shot and few-shot settings. Our setup is based on Hanabi — a partially-observable, fully cooperative multi-agent game that has been shown to be challenging for zero-shot coordination. Its large strategy space makes it a desirable environment for lifelong RL tasks. We evaluate several recent MARL methods, and benchmark state-of-the-art LLL algorithms in limited memory and computation regimes to shed light on their strengths and weaknesses. This continual learning paradigm also provides us with a pragmatic way of going beyond centralized training which is the most commonly used training protocol in MARL. We empirically show that the agents …
[ Virtual ]
The goal of meta-reinforcement learning (meta-RL) is to build agents that can quickly learn new tasks by leveraging prior experience on related tasks. Learning a new task often requires both exploring to gather task-relevant information and exploiting this information to solve the task. In principle, optimal exploration and exploitation can be learned end-to-end by simply maximizing task performance. However, such meta-RL approaches struggle with local optima due to a chicken-and-egg problem: learning to explore requires good exploitation to gauge the exploration’s utility, but learning to exploit requires information gathered via exploration. Optimizing separate objectives for exploration and exploitation can avoid this problem, but prior meta-RL exploration objectives yield suboptimal policies that gather information irrelevant to the task. We alleviate both concerns by constructing an exploitation objective that automatically identifies task-relevant information and an exploration objective to recover only this information. This avoids local optima in end-to-end training, without sacrificing optimal exploration. Empirically, DREAM substantially outperforms existing approaches on complex meta-RL problems, such as sparse-reward 3D visual navigation. Videos of DREAM: https://ezliu.github.io/dream/
[ Virtual ]
CNNs and computational models of biological vision share some fundamental principles, which opened new avenues of research. However, fruitful cross-field research is hampered by conventional CNN architectures being based on spatially and depthwise discrete representations, which cannot accommodate certain aspects of biological complexity such as continuously varying receptive field sizes and dynamics of neuronal responses. Here we propose deep continuous networks (DCNs), which combine spatially continuous filters, with the continuous depth framework of neural ODEs. This allows us to learn the spatial support of the filters during training, as well as model the continuous evolution of feature maps, linking DCNs closely to biological models. We show that DCNs are versatile and highly applicable to standard image classification and reconstruction problems, where they improve parameter and data efficiency, and allow for meta-parametrization. We illustrate the biological plausibility of the scale distributions learned by DCNs and explore their performance in a neuroscientifically inspired pattern completion task. Finally, we investigate an efficient implementation of DCNs by changing input contrast.
[ Virtual ]
[ Virtual ]
We prove calibration guarantees for the popular histogram binning (also called uniform-mass binning) method of Zadrozny and Elkan (2001). Histogram binning has displayed strong practical performance, but theoretical guarantees have only been shown for sample split versions that avoid 'double dipping' the data. We demonstrate that the statistical cost of sample splitting is practically significant on a credit default dataset. We then prove calibration guarantees for the original method that double dips the data, using a certain Markov property of order statistics. Based on our results, we make practical recommendations for choosing the number of bins in histogram binning. In our illustrative simulations, we propose a new tool for assessing calibration---validity plots---which provide more information than an ECE estimate.
[ Virtual ]
The connection between training deep neural networks (DNNs) and optimal control theory (OCT) has attracted considerable attention as a principled tool of algorithmic design. Despite few attempts being made, they have been limited to architectures where the layer propagation resembles a Markovian dynamical system. This casts doubts on their flexibility to modern networks that heavily rely on non-Markovian dependencies between layers (e.g. skip connections in residual networks). In this work, we propose a novel dynamic game perspective by viewing each layer as a player in a dynamic game characterized by the DNN itself. Through this lens, different classes of optimizers can be seen as matching different types of Nash equilibria, depending on the implicit information structure of each (p)layer. The resulting method, called Dynamic Game Theoretic Neural Optimizer (DGNOpt), not only generalizes OCT-inspired optimizers to richer network class; it also motivates a new training principle by solving a multi-player cooperative game. DGNOpt shows convergence improvements over existing methods on image classification datasets with residual and inception networks. Our work marries strengths from both OCT and game theory, paving ways to new algorithmic opportunities from robust optimal control and bandit-based optimization.
[ Virtual ]
Hindsight rationality is an approach to playing general-sum games that prescribes no-regret learning dynamics for individual agents with respect to a set of deviations, and further describes jointly rational behavior among multiple agents with mediated equilibria. To develop hindsight rational learning in sequential decision-making settings, we formalize behavioral deviations as a general class of deviations that respect the structure of extensive-form games. Integrating the idea of time selection into counterfactual regret minimization (CFR), we introduce the extensive-form regret minimization (EFR) algorithm that achieves hindsight rationality for any given set of behavioral deviations with computation that scales closely with the complexity of the set. We identify behavioral deviation subsets, the partial sequence deviation types, that subsume previously studied types and lead to efficient EFR instances in games with moderate lengths. In addition, we present a thorough empirical analysis of EFR instantiated with different deviation types in benchmark games, where we find that stronger types typically induce better performance.
[ Virtual ]
[ Virtual ]
Q-learning (QL), a common reinforcement learning algorithm, suffers from over-estimation bias due to the maximization term in the optimal Bellman operator. This bias may lead to sub-optimal behavior. Double-Q-learning tackles this issue by utilizing two estimators, yet results in an under-estimation bias. Similar to over-estimation in Q-learning, in certain scenarios, the under-estimation bias may degrade performance. In this work, we introduce a new bias-reduced algorithm called Ensemble Bootstrapped Q-Learning (EBQL), a natural extension of Double-Q-learning to ensembles. We analyze our method both theoretically and empirically. Theoretically, we prove that EBQL-like updates yield lower MSE when estimating the maximal mean of a set of independent random variables. Empirically, we show that there exist domains where both over and under-estimation result in sub-optimal performance. Finally, We demonstrate the superior performance of a deep RL variant of EBQL over other deep QL algorithms for a suite of ATARI games.
[ Virtual ]
[ Virtual ]
[ Virtual ]
There is growing awareness and concern about fairness in machine learning and algorithm design. This is particularly true in online selection problems where decisions are often biased, for example, when assessing credit risks or hiring staff. We address the issues of fairness and bias in online selection by introducing multi-color versions of the classic secretary and prophet problem. Interestingly, existing algorithms for these problems are either very unfair or very inefficient, so we develop optimal fair algorithms for these new problems and provide tight bounds on their competitiveness. We validate our theoretical findings on real-world data.
[ Virtual ]
The problem of adversarial examples has highlighted the need for a theory of regularisation that is general enough to apply to exotic function classes, such as universal approximators. In response, we have been able to significantly sharpen existing results regarding the relationship between distributional robustness and regularisation, when defined with a transportation cost uncertainty set. The theory allows us to characterise the conditions under which the distributional robustness equals a Lipschitz-regularised model, and to tightly quantify, for the first time, the slackness under very mild assumptions. As a theoretical application we show a new result explicating the connection between adversarial learning and distributional robustness. We then give new results for how to achieve Lipschitz regularisation of kernel classifiers, which are demonstrated experimentally.
[ Virtual ]
In contrast to the empirical mean, the Median-of-Means (MoM) is an estimator of the mean θ of a square integrable r.v. Z, around which accurate nonasymptotic confidence bounds can be built, even when Z does not exhibit a sub-Gaussian tail behavior. Thanks to the high confidence it achieves on heavy-tailed data, MoM has found various applications in machine learning, where it is used to design training procedures that are not sensitive to atypical observations. More recently, a new line of work is now trying to characterize and leverage MoM’s ability to deal with corrupted data. In this context, the present work proposes a general study of MoM’s concentration properties under the contamination regime, that provides a clear understanding on the impact of the outlier proportion and the number of blocks chosen. The analysis is extended to (multisample) U-statistics, i.e. averages over tuples of observations, that raise additional challenges due to the dependence induced. Finally, we show that the latter bounds can be used in a straightforward fashion to derive generalization guarantees for pairwise learning in a contaminated setting, and propose an algorithm to compute provably reliable decision functions.
[ Virtual ]
We investigate the use of natural language to drive the generalization of control policies and introduce the new multi-task environment Messenger with free-form text manuals describing the environment dynamics. Unlike previous work, Messenger does not assume prior knowledge connecting text and state observations — the control policy must simultaneously ground the game manual to entity symbols and dynamics in the environment. We develop a new model, EMMA (Entity Mapper with Multi-modal Attention) which uses an entity-conditioned attention module that allows for selective focus over relevant descriptions in the manual for each entity in the environment. EMMA is end-to-end differentiable and learns a latent grounding of entities and dynamics from text to observations using only environment rewards. EMMA achieves successful zero-shot generalization to unseen games with new dynamics, obtaining a 40% higher win rate compared to multiple baselines. However, win rate on the hardest stage of Messenger remains low (10%), demonstrating the need for additional work in this direction.
[ Virtual ]
Sparse regression has recently been applied to enable transfer learning from very limited data. We study an extension of this approach to unsupervised learning---in particular, learning word embeddings from unstructured text corpora using low-rank matrix factorization. Intuitively, when transferring word embeddings to a new domain, we expect that the embeddings change for only a small number of words---e.g., the ones with novel meanings in that domain. We propose a novel group-sparse penalty that exploits this sparsity to perform transfer learning when there is very little text data available in the target domain---e.g., a single article of text. We prove generalization bounds for our algorithm. Furthermore, we empirically evaluate its effectiveness, both in terms of prediction accuracy in downstream tasks as well as in terms of interpretability of the results.
[ Virtual ]
Choosing the right parameters for optimization algorithms is often the key to their success in practice. Solving this problem using a learning-to-learn approach---using meta-gradient descent on a meta-objective based on the trajectory that the optimizer generates---was recently shown to be effective. However, the meta-optimization problem is difficult. In particular, the meta-gradient can often explode/vanish, and the learned optimizer may not have good generalization performance if the meta-objective is not chosen carefully. In this paper we give meta-optimization guarantees for the learning-to-learn approach on a simple problem of tuning the step size for quadratic loss. Our results show that the na\"ive objective suffers from meta-gradient explosion/vanishing problem. Although there is a way to design the meta-objective so that the meta-gradient remains polynomially bounded, computing the meta-gradient directly using backpropagation leads to numerical issues. We also characterize when it is necessary to compute the meta-objective on a separate validation set to ensure the generalization performance of the learned optimizer. Finally, we verify our results empirically and show that a similar phenomenon appears even for more complicated learned optimizers parametrized by neural networks.
[ Virtual ]
The best performing Binary Neural Networks (BNNs) are usually attained using Adam optimization and its multi-step training variants. However, to the best of our knowledge, few studies explore the fundamental reasons why Adam is superior to other optimizers like SGD for BNN optimization or provide analytical explanations that support specific training strategies. To address this, in this paper we first investigate the trajectories of gradients and weights in BNNs during the training process. We show the regularization effect of second-order momentum in Adam is crucial to revitalize the weights that are dead due to the activation saturation in BNNs. We find that Adam, through its adaptive learning rate strategy, is better equipped to handle the rugged loss surface of BNNs and reaches a better optimum with higher generalization ability. Furthermore, we inspect the intriguing role of the real-valued weights in binary networks, and reveal the effect of weight decay on the stability and sluggishness of BNN optimization. Through extensive experiments and analysis, we derive a simple training scheme, building on existing Adam-based optimization, which achieves 70.5% top-1 accuracy on the ImageNet dataset using the same architecture as the state-of-the-art ReActNet while achieving 1.1% higher accuracy. Code and models are available …
[ Virtual ]
[ Virtual ]
We characterize the measurement complexity of compressed sensing of signals drawn from a known prior distribution, even when the support of the prior is the entire space (rather than, say, sparse vectors). We show for Gaussian measurements and \emph{any} prior distribution on the signal, that the posterior sampling estimator achieves near-optimal recovery guarantees. Moreover, this result is robust to model mismatch, as long as the distribution estimate (e.g., from an invertible generative model) is close to the true distribution in Wasserstein distance. We implement the posterior sampling estimator for deep generative priors using Langevin dynamics, and empirically find that it produces accurate estimates with more diversity than MAP.
[ Virtual ]
We propose Intermediate Layer Optimization (ILO), a novel optimization algorithm for solving inverse problems with deep generative models. Instead of optimizing only over the initial latent code, we progressively change the input layer obtaining successively more expressive generators. To explore the higher dimensional spaces, our method searches for latent codes that lie within a small l1 ball around the manifold induced by the previous layer. Our theoretical analysis shows that by keeping the radius of the ball relatively small, we can improve the established error bound for compressed sensing with deep generative models. We empirically show that our approach outperforms state-of-the-art methods introduced in StyleGAN2 and PULSE for a wide range of inverse problems including inpainting, denoising, super-resolution and compressed sensing.
[ Virtual ]
In many applications, we encounter data on Riemannian manifolds such as torus and rotation groups. Standard statistical procedures for multivariate data are not applicable to such data. In this study, we develop goodness-of-fit testing and interpretable model criticism methods for general distributions on Riemannian manifolds, including those with an intractable normalization constant. The proposed methods are based on extensions of kernel Stein discrepancy, which are derived from Stein operators on Riemannian manifolds. We discuss the connections between the proposed tests with existing ones and provide a theoretical analysis of their asymptotic Bahadur efficiency. Simulation results and real data applications show the validity and usefulness of the proposed methods.
[ Virtual ]
[ Virtual ]
[ Virtual ]
Byzantine robustness has received significant attention recently given its importance for distributed and federated learning. In spite of this, we identify severe flaws in existing algorithms even when the data across the participants is identically distributed. First, we show realistic examples where current state of the art robust aggregation rules fail to converge even in the absence of any Byzantine attackers. Secondly, we prove that even if the aggregation rules may succeed in limiting the influence of the attackers in a single round, the attackers can couple their attacks across time eventually leading to divergence. To address these issues, we present two surprisingly simple strategies: a new robust iterative clipping procedure, and incorporating worker momentum to overcome time-coupled attacks. This is the first provably robust method for the standard stochastic optimization setting.
[ Virtual ]
Direct loss minimization is a popular approach for learning predictors over structured label spaces. This approach is computationally appealing as it replaces integration with optimization and allows to propagate gradients in a deep net using loss-perturbed prediction. Recently, this technique was extended to generative models, by introducing a randomized predictor that samples a structure from a randomly perturbed score function. In this work, we interpolate between these techniques by learning the variance of randomized structured predictors as well as their mean, in order to balance between the learned score function and the randomized noise. We demonstrate empirically the effectiveness of learning this balance in structured discrete spaces.
[ Virtual ]
We develop and analyze MARINA: a new communication efficient method for non-convex distributed learning over heterogeneous datasets. MARINA employs a novel communication compression strategy based on the compression of gradient differences that is reminiscent of but different from the strategy employed in the DIANA method of Mishchenko et al. (2019). Unlike virtually all competing distributed first-order methods, including DIANA, ours is based on a carefully designed biased gradient estimator, which is the key to its superior theoretical and practical performance. The communication complexity bounds we prove for MARINA are evidently better than those of all previous first-order methods. Further, we develop and analyze two variants of MARINA: VR-MARINA and PP-MARINA. The first method is designed for the case when the local loss functions owned by clients are either of a finite sum or of an expectation form, and the second method allows for a partial participation of clients – a feature important in federated learning. All our methods are superior to previous state-of-the-art methods in terms of oracle/communication complexity. Finally, we provide a convergence analysis of all methods for problems satisfying the Polyak-Łojasiewicz condition.
[ Virtual ]
We present Megaverse, a new 3D simulation platform for reinforcement learning and embodied AI research. The efficient design of our engine enables physics-based simulation with high-dimensional egocentric observations at more than 1,000,000 actions per second on a single 8-GPU node. Megaverse is up to 70x faster than DeepMind Lab in fully-shaded 3D scenes with interactive objects. We achieve this high simulation performance by leveraging batched simulation, thereby taking full advantage of the massive parallelism of modern GPUs. We use Megaverse to build a new benchmark that consists of several single-agent and multi-agent tasks covering a variety of cognitive challenges. We evaluate model-free RL on this benchmark to provide baselines and facilitate future research.
[ Virtual ]
[ Virtual ]
[ Virtual ]
Energy-based models (EBMs) are a simple yet powerful framework for generative modeling. They are based on a trainable energy function which defines an associated Gibbs measure, and they can be trained and sampled from via well-established statistical tools, such as MCMC. Neural networks may be used as energy function approximators, providing both a rich class of expressive models as well as a flexible device to incorporate data structure. In this work we focus on shallow neural networks. Building from the incipient theory of overparametrized neural networks, we show that models trained in the so-called 'active' regime provide a statistical advantage over their associated 'lazy' or kernel regime, leading to improved adaptivity to hidden low-dimensional structure in the data distribution, as already observed in supervised learning. Our study covers both the maximum likelihood and Stein Discrepancy estimators, and we validate our theoretical results with numerical experiments on synthetic data.
[ Virtual ]
[ Virtual ]
We present Neural A, a novel data-driven search method for path planning problems. Despite the recent increasing attention to data-driven path planning, machine learning approaches to search-based planning are still challenging due to the discrete nature of search algorithms. In this work, we reformulate a canonical A search algorithm to be differentiable and couple it with a convolutional encoder to form an end-to-end trainable neural network planner. Neural A* solves a path planning problem by encoding a problem instance to a guidance map and then performing the differentiable A* search with the guidance map. By learning to match the search results with ground-truth paths provided by experts, Neural A* can produce a path consistent with the ground truth accurately and efficiently. Our extensive experiments confirmed that Neural A* outperformed state-of-the-art data-driven planners in terms of the search optimality and efficiency trade-off. Furthermore, Neural A* successfully predicted realistic human trajectories by directly performing search-based planning on natural image inputs.
[ Virtual ]
Detecting influential features in non-linear and/or high-dimensional data is a challenging and increasingly important task in machine learning. Variable selection methods have thus been gaining much attention as well as post-selection inference. Indeed, the selected features can be significantly flawed when the selection procedure is not accounted for. We propose a selective inference procedure using the so-called model-free "HSIC-Lasso" based on the framework of truncated Gaussians combined with the polyhedral lemma. We then develop an algorithm, which allows for low computational costs and provides a selection of the regularisation parameter. The performance of our method is illustrated by both artificial and real-world data based experiments, which emphasise a tight control of the type-I error, even for small sample sizes.
[ Virtual ]
Obtaining a useful estimate of an object from highly incomplete imaging measurements remains a holy grail of imaging science. Deep learning methods have shown promise in learning object priors or constraints to improve the conditioning of an ill-posed imaging inverse problem. In this study, a framework for estimating an object of interest that is semantically related to a known prior image, is proposed. An optimization problem is formulated in the disentangled latent space of a style-based generative model, and semantically meaningful constraints are imposed using the disentangled latent representation of the prior image. Stable recovery from incomplete measurements with the help of a prior image is theoretically analyzed. Numerical experiments demonstrating the superior performance of our approach as compared to related methods are presented.
[ Virtual ]
We consider a one-hidden-layer leaky ReLU network of arbitrary width trained by stochastic gradient descent (SGD) following an arbitrary initialization. We prove that SGD produces neural networks that have classification accuracy competitive with that of the best halfspace over the distribution for a broad class of distributions that includes log-concave isotropic and hard margin distributions. Equivalently, such networks can generalize when the data distribution is linearly separable but corrupted with adversarial label noise, despite the capacity to overfit. To the best of our knowledge, this is the first work to show that overparameterized neural networks trained by SGD can generalize when the data is corrupted with adversarial label noise.
[ Virtual ]
Anomaly estimation, or the problem of finding a subset of a dataset that differs from the rest of the dataset, is a classic problem in machine learning and data mining. In both theoretical work and in applications, the anomaly is assumed to have a specific structure defined by membership in an anomaly family. For example, in temporal data the anomaly family may be time intervals, while in network data the anomaly family may be connected subgraphs. The most prominent approach for anomaly estimation is to compute the Maximum Likelihood Estimator (MLE) of the anomaly; however, it was recently observed that for normally distributed data, the MLE is a biased estimator for some anomaly families. In this work, we demonstrate that in the normal means setting, the bias of the MLE depends on the size of the anomaly family. We prove that if the number of sets in the anomaly family that contain the anomaly is sub-exponential, then the MLE is asymptotically unbiased. We also provide empirical evidence that the converse is true: if the number of such sets is exponential, then the MLE is asymptotically biased. Our analysis unifies a number of earlier results on the bias of the MLE …
[ Virtual ]
[ Virtual ]
We study regularized deep neural networks (DNNs) and introduce a convex analytic framework to characterize the structure of the hidden layers. We show that a set of optimal hidden layer weights for a norm regularized DNN training problem can be explicitly found as the extreme points of a convex set. For the special case of deep linear networks, we prove that each optimal weight matrix aligns with the previous layers via duality. More importantly, we apply the same characterization to deep ReLU networks with whitened data and prove the same weight alignment holds. As a corollary, we also prove that norm regularized deep ReLU networks yield spline interpolation for one-dimensional datasets which was previously known only for two-layer networks. Furthermore, we provide closed-form solutions for the optimal layer weights when data is rank-one or whitened. The same analysis also applies to architectures with batch normalization even for arbitrary data. Therefore, we obtain a complete explanation for a recent empirical observation termed Neural Collapse where class means collapse to the vertices of a simplex equiangular tight frame.
[ Virtual ]
We study the problem of reward identifiability in the context of Inverse Reinforcement Learning (IRL). The reward identifiability question is critical to answer when reasoning about the effectiveness of using Markov Decision Processes (MDPs) as computational models of real world decision makers in order to understand complex decision making behavior and perform counterfactual reasoning. While identifiability has been acknowledged as a fundamental theoretical question in IRL, little is known about the types of MDPs for which rewards are identifiable, or even if there exist such MDPs. In this work, we formalize the reward identification problem in IRL and study how identifiability relates to properties of the MDP model. For deterministic MDP models with the MaxEntRL objective, we prove necessary and sufficient conditions for identifiability. Building on these results, we present efficient algorithms for testing whether or not an MDP model is identifiable.
[ Virtual ]
This paper considers batch Reinforcement Learning (RL) with general value function approximation. Our study investigates the minimal assumptions to reliably estimate/minimize Bellman error, and characterizes the generalization performance by (local) Rademacher complexities of general function classes, which makes initial steps in bridging the gap between statistical learning theory and batch RL. Concretely, we view the Bellman error as a surrogate loss for the optimality gap, and prove the followings: (1) In double sampling regime, the excess risk of Empirical Risk Minimizer (ERM) is bounded by the Rademacher complexity of the function class. (2) In the single sampling regime, sample-efficient risk minimization is not possible without further assumptions, regardless of algorithms. However, with completeness assumptions, the excess risk of FQI and a minimax style algorithm can be again bounded by the Rademacher complexity of the corresponding function classes. (3) Fast statistical rates can be achieved by using tools of local Rademacher complexity. Our analysis covers a wide range of function classes, including finite classes, linear spaces, kernel spaces, sparse linear features, etc.
[ Virtual ]
This paper addresses the problem of model-free reinforcement learning for Robust Markov Decision Process (RMDP) with large state spaces. The goal of the RMDPs framework is to find a policy that is robust against the parameter uncertainties due to the mismatch between the simulator model and real-world settings. We first propose the Robust Least Squares Policy Evaluation algorithm, which is a multi-step online model-free learning algorithm for policy evaluation. We prove the convergence of this algorithm using stochastic approximation techniques. We then propose Robust Least Squares Policy Iteration (RLSPI) algorithm for learning the optimal robust policy. We also give a general weighted Euclidean norm bound on the error (closeness to optimality) of the resulting policy. Finally, we demonstrate the performance of our RLSPI algorithm on some benchmark problems from OpenAI Gym.
[ Virtual ]
Hierarchical topic models such as the gamma belief network (GBN) have delivered promising results in mining multi-layer document representations and discovering interpretable topic taxonomies. However, they often assume in the prior that the topics at each layer are independently drawn from the Dirichlet distribution, ignoring the dependencies between the topics both at the same layer and across different layers. To relax this assumption, we propose sawtooth factorial topic embedding guided GBN, a deep generative model of documents that captures the dependencies and semantic similarities between the topics in the embedding space. Specifically, both the words and topics are represented as embedding vectors of the same dimension. The topic matrix at a layer is factorized into the product of a factor loading matrix and a topic embedding matrix, the transpose of which is set as the factor loading matrix of the layer above. Repeating this particular type of factorization, which shares components between adjacent layers, leads to a structure referred to as sawtooth factorization. An auto-encoding variational inference network is constructed to optimize the model parameter via stochastic gradient descent. Experiments on big corpora show that our models outperform other neural topic models on extracting deeper interpretable topics and deriving better …
[ Virtual ]
Machine learning models trained with purely observational data and the principle of empirical risk minimization (Vapnik 1992) can fail to generalize to unseen domains. In this paper, we focus on the case where the problem arises through spurious correlation between the observed domains and the actual task labels. We find that many domain generalization methods do not explicitly take this spurious correlation into account. Instead, especially in more application-oriented research areas like medical imaging or robotics, data augmentation techniques that are based on heuristics are used to learn domain invariant features. To bridge the gap between theory and practice, we develop a causal perspective on the problem of domain generalization. We argue that causal concepts can be used to explain the success of data augmentation by describing how they can weaken the spurious correlation between the observed domains and the task labels. We demonstrate that data augmentation can serve as a tool for simulating interventional data. We use these theoretical insights to derive a simple algorithm that is able to select data augmentation techniques that will lead to better domain generalization.
[ Virtual ]
Reinforcement learning (RL) has made a lot of advances for solving a single problem in a given environment; but learning policies that generalize to unseen variations of a problem remains challenging. To improve sample efficiency for learning on such instances of a problem domain, we present Self-Paced Context Evaluation (SPaCE). Based on self-paced learning, SPaCE automatically generates instance curricula online with little computational overhead. To this end, SPaCE leverages information contained in state values during training to accelerate and improve training performance as well as generalization capabilities to new \tasks from the same problem domain. Nevertheless, SPaCE is independent of the problem domain at hand and can be applied on top of any RL agent with state-value function approximation. We demonstrate SPaCE's ability to speed up learning of different value-based RL agents on two environments, showing better generalization capabilities and up to 10x faster learning compared to naive approaches such as round robin or SPDRL, as the closest state-of-the-art approach.
[ Virtual ]
[ Virtual ]
Most of the recent deep reinforcement learning advances take an RL-centric perspective and focus on refinements of the training objective. We diverge from this view and show we can recover the performance of these developments not by changing the objective, but by regularising the value-function estimator. Constraining the Lipschitz constant of a single layer using spectral normalisation is sufficient to elevate the performance of a Categorical-DQN agent to that of a more elaborated agent on the challenging Atari domain. We conduct ablation studies to disentangle the various effects normalisation has on the learning dynamics and show that is sufficient to modulate the parameter updates to recover most of the performance of spectral normalisation. These findings hint towards the need to also focus on the neural component and its learning dynamics to tackle the peculiarities of Deep Reinforcement Learning.
[ Virtual ]
Off-policy deep reinforcement learning (RL) has been successful in a range of challenging domains. However, standard off-policy RL algorithms can suffer from several issues, such as instability in Q-learning and balancing exploration and exploitation. To mitigate these issues, we present SUNRISE, a simple unified ensemble method, which is compatible with various off-policy RL algorithms. SUNRISE integrates two key ingredients: (a) ensemble-based weighted Bellman backups, which re-weight target Q-values based on uncertainty estimates from a Q-ensemble, and (b) an inference method that selects actions using the highest upper-confidence bounds for efficient exploration. By enforcing the diversity between agents using Bootstrap with random initialization, we show that these different ideas are largely orthogonal and can be fruitfully integrated, together further improving the performance of existing off-policy RL algorithms, such as Soft Actor-Critic and Rainbow DQN, for both continuous and discrete control tasks on both low-dimensional and high-dimensional environments.
[ Virtual ]
Training autonomous agents able to generalize to multiple tasks is a key target of Deep Reinforcement Learning (DRL) research. In parallel to improving DRL algorithms themselves, Automatic Curriculum Learning (ACL) study how teacher algorithms can train DRL agents more efficiently by adapting task selection to their evolving abilities. While multiple standard benchmarks exist to compare DRL agents, there is currently no such thing for ACL algorithms. Thus, comparing existing approaches is difficult, as too many experimental parameters differ from paper to paper. In this work, we identify several key challenges faced by ACL algorithms. Based on these, we present TeachMyAgent (TA), a benchmark of current ACL algorithms leveraging procedural task generation. It includes 1) challenge-specific unit-tests using variants of a procedural Box2D bipedal walker environment, and 2) a new procedural Parkour environment combining most ACL challenges, making it ideal for global performance assessment. We then use TeachMyAgent to conduct a comparative study of representative existing approaches, showcasing the competitiveness of some ACL algorithms that do not use expert knowledge. We also show that the Parkour environment remains an open problem. We open-source our environments, all studied ACL algorithms (collected from open-source code or re-implemented), and DRL students in a Python …
[ Virtual ]
Reinforcement learning is a powerful approach to learn behaviour through interactions with an environment. However, behaviours are usually learned in a purely reactive fashion, where an appropriate action is selected based on an observation. In this form, it is challenging to learn when it is necessary to execute new decisions. This makes learning inefficient especially in environments that need various degrees of fine and coarse control. To address this, we propose a proactive setting in which the agent not only selects an action in a state but also for how long to commit to that action. Our TempoRL approach introduces skip connections between states and learns a skip-policy for repeating the same action along these skips. We demonstrate the effectiveness of TempoRL on a variety of traditional and deep RL environments, showing that our approach is capable of learning successful policies up to an order of magnitude faster than vanilla Q-learning.
[ Virtual ]
In this work we develop a quantum field theory formalism for deep learning, where input signals are encoded in Gaussian states, a generalization of Gaussian processes which encode the agent's uncertainty about the input signal. We show how to represent linear and non-linear layers as unitary quantum gates, and interpret the fundamental excitations of the quantum model as particles, dubbed ``Hintons''. On top of opening a new perspective and techniques for studying neural networks, the quantum formulation is well suited for optical quantum computing, and provides quantum deformations of neural networks that can be run efficiently on those devices. Finally, we discuss a semi-classical limit of the quantum deformed models which is amenable to classical simulation.
[ Virtual ]
Learning composable policies for environments with complex rules and tasks is a challenging problem. We introduce a hierarchical reinforcement learning framework called the Logical Options Framework (LOF) that learns policies that are satisfying, optimal, and composable. LOF efficiently learns policies that satisfy tasks by representing the task as an automaton and integrating it into learning and planning. We provide and prove conditions under which LOF will learn satisfying, optimal policies. And lastly, we show how LOF's learned policies can be composed to satisfy unseen tasks with only 10-50 retraining steps on our benchmarks. We evaluate LOF on four tasks in discrete and continuous domains, including a 3D pick-and-place environment.
[ Virtual ]
We propose a model for multiclass classification of time series to make a prediction as early and as accurate as possible. The matrix sequential probability ratio test (MSPRT) is known to be asymptotically optimal for this setting, but contains a critical assumption that hinders broad real-world applications; the MSPRT requires the underlying probability density. To address this problem, we propose to solve density ratio matrix estimation (DRME), a novel type of density ratio estimation that consists of estimating matrices of multiple density ratios with constraints and thus is more challenging than the conventional density ratio estimation. We propose a log-sum-exp-type loss function (LSEL) for solving DRME and prove the following: (i) the LSEL provides the true density ratio matrix as the sample size of the training set increases (consistency); (ii) it assigns larger gradients to harder classes (hard class weighting effect); and (iii) it provides discriminative scores even on class-imbalanced datasets (guess-aversion). Our overall architecture for early classification, MSPRT-TANDEM, statistically significantly outperforms baseline models on four datasets including action recognition, especially in the early stage of sequential observations. Our code and datasets are publicly available.
[ Virtual ]
Ad hoc teamwork is the challenging problem of designing an autonomous agent which can adapt quickly to collaborate with teammates without prior coordination mechanisms, including joint training. Prior work in this area has focused on closed teams in which the number of agents is fixed. In this work, we consider open teams by allowing agents with different fixed policies to enter and leave the environment without prior notification. Our solution builds on graph neural networks to learn agent models and joint-action value models under varying team compositions. We contribute a novel action-value computation that integrates the agent model and joint-action value model to produce action-value estimates. We empirically demonstrate that our approach successfully models the effects other agents have on the learner, leading to policies that robustly adapt to dynamic team compositions and significantly outperform several alternative methods.
[ Virtual ]
Feature attribution is often loosely presented as the process of selecting a subset of relevant features as a rationale of a prediction. Task-dependent by nature, precise definitions of "relevance" encountered in the literature are however not always consistent. This lack of clarity stems from the fact that we usually do not have access to any notion of ground-truth attribution and from a more general debate on what good interpretations are. In this paper we propose to formalise feature selection/attribution based on the concept of relaxed functional dependence. In particular, we extend our notions to the instance-wise setting and derive necessary properties for candidate selection solutions, while leaving room for task-dependence. By computing ground-truth attributions on synthetic datasets, we evaluate many state-of-the-art attribution methods and show that, even when optimised, some fail to verify the proposed properties and provide wrong solutions.
[ Virtual ]
Natural-gradient descent (NGD) on structured parameter spaces (e.g., low-rank covariances) is computationally challenging due to difficult Fisher-matrix computations. We address this issue by using \emph{local-parameter coordinates} to obtain a flexible and efficient NGD method that works well for a wide-variety of structured parameterizations. We show four applications where our method (1) generalizes the exponential natural evolutionary strategy, (2) recovers existing Newton-like algorithms, (3) yields new structured second-order algorithms, and (4) gives new algorithms to learn covariances of Gaussian and Wishart-based distributions. We show results on a range of problems from deep learning, variational inference, and evolution strategies. Our work opens a new direction for scalable structured geometric methods.
[ Virtual ]
[ Virtual ]
We consider the problem of reinforcement learning when provided with (1) a baseline control policy and (2) a set of constraints that the learner must satisfy. The baseline policy can arise from demonstration data or a teacher agent and may provide useful cues for learning, but it might also be sub-optimal for the task at hand, and is not guaranteed to satisfy the specified constraints, which might encode safety, fairness or other application-specific requirements. In order to safely learn from baseline policies, we propose an iterative policy optimization algorithm that alternates between maximizing expected return on the task, minimizing distance to the baseline policy, and projecting the policy onto the constraint-satisfying set. We analyze our algorithm theoretically and provide a finite-time convergence guarantee. In our experiments on five different control tasks, our algorithm consistently outperforms several state-of-the-art baselines, achieving 10 times fewer constraint violations and 40% higher reward on average.
Subsampling a signal of interest can reduce costly data transfer, battery drain, radiation exposure and acquisition time in a wide range of problems. The recently proposed Deep Probabilistic Subsampling (DPS) method effectively integrates subsampling in an end-to-end deep learning model, but learns a static pattern for all datapoints. We generalize DPS to a sequential method that actively picks the next sample based on the information acquired so far; dubbed Active-DPS (A-DPS). We validate that A-DPS improves over DPS for MNIST classification at high subsampling rates. Moreover, we demonstrate strong performance in active acquisition Magnetic Resonance Image (MRI) reconstruction, outperforming DPS and other deep learning methods.
It has been a challenge to learning skills for an agent from long-horizon unannotated demonstrations. Existing approaches like Hierarchical Imitation Learning(HIL) are prone to compounding errors or suboptimal solutions. In this paper, we propose Option-GAIL, a novel method to learn skills at long horizon. The key idea of Option-GAIL is modeling the task hierarchy by options and train the policy via generative adversarial optimization. In particular, we propose an Expectation-Maximization(EM)-style algorithm: an E-step that samples the options of expert conditioned on the current learned policy, and an M-step that updates the low- and high-level policies of agent simultaneously to minimize the newly proposed option-occupancy measurement between the expert and the agent. We theoretically prove the convergence of the proposed algorithm. Experiments show that Option-GAIL outperforms other counterparts consistently across a variety of tasks.
Direct Feedback Alignment (DFA) is emerging as an efficient and biologically plausible alternative to backpropagation for training deep neural networks. Despite relying on random feedback weights for the backward pass, DFA successfully trains state-of-the-art models such as Transformers. On the other hand, it notoriously fails to train convolutional networks. An understanding of the inner workings of DFA to explain these diverging results remains elusive. Here, we propose a theory of feedback alignment algorithms. We first show that learning in shallow networks proceeds in two steps: an alignment phase, where the model adapts its weights to align the approximate gradient with the true gradient of the loss function, is followed by a memorisation phase, where the model focuses on fitting the data. This two-step process has a degeneracy breaking effect: out of all the low-loss solutions in the landscape, a net-work trained with DFA naturally converges to the solution which maximises gradient alignment. We also identify a key quantity underlying alignment in deep linear networks: the conditioning of the alignment matrices. The latter enables a detailed understanding of the impact of data structure on alignment, and suggests a simple explanation for the well-known failure of DFA to train convolutional neural networks. …
Much of the theory for classical sparse recovery is based on conditions on the dictionary that are both necessary and sufficient (e.g., nullspace property) or only sufficient (e.g., incoherence and restricted isometry). In contrast, much of the theory for subspace-preserving recovery, the theoretical underpinnings for sparse subspace classification and clustering methods, is based on conditions on the subspaces and the data that are only sufficient (e.g., subspace incoherence and data inner-radius). This paper derives a necessary and sufficient condition for subspace-preserving recovery that is inspired by the classical nullspace property.Based on this novel condition, called here the subspace nullspace property, we derive equivalent characterizations that either admit a clear geometric interpretation that relates data distribution and subspace separation to the recovery success, or can be verified using a finite set of extreme points of a properly defined set. We further exploit these characterizations to derive new sufficient conditions, based on inner-radius and outer-radius measures and dual bounds, that generalize existing conditions and preserve the geometric interpretations. These results fill an important gap in the subspace-preserving recovery literature.
Bootstrapping provides a flexible and effective approach for assessing the quality of batch reinforcement learning, yet its theoretical properties are poorly understood. In this paper, we study the use of bootstrapping in off-policy evaluation (OPE), and in particular, we focus on the fitted Q-evaluation (FQE) that is known to be minimax-optimal in the tabular and linear-model cases. We propose a bootstrapping FQE method for inferring the distribution of the policy evaluation error and show that this method is asymptotically efficient and distributionally consistent for off-policy statistical inference. To overcome the computation limit of bootstrapping, we further adapt a subsampling procedure that improves the runtime by an order of magnitude. We numerically evaluate the bootrapping method in classical RL environments for confidence interval estimation, estimating the variance of off-policy evaluator, and estimating the correlation between multiple off-policy evaluators.
We propose the ChaCha (Champion-Challengers) algorithm for making an online choice of hyperparameters in online learning settings. ChaCha handles the process of determining a champion and scheduling a set of `live' challengers over time based on sample complexity bounds. It is guaranteed to have sublinear regret after the optimal configuration is added into consideration by an application-dependent oracle based on the champions. Empirically, we show that ChaCha provides good performance across a wide array of datasets when optimizing over featurization and hyperparameter decisions.
Actor-critic (AC) methods are ubiquitous in reinforcement learning. Although it is understood that AC methods are closely related to policy gradient (PG), their precise connection has not been fully characterized previously. In this paper, we explain the gap between AC and PG methods by identifying the exact adjustment to the AC objective/gradient that recovers the true policy gradient of the cumulative reward objective (PG). Furthermore, by viewing the AC method as a two-player Stackelberg game between the actor and critic, we show that the Stackelberg policy gradient can be recovered as a special case of our more general analysis. Based on these results, we develop practical algorithms, Residual Actor-Critic and Stackelberg Actor-Critic, for estimating the correction between AC and PG and use these to modify the standard AC algorithm. Experiments on popular tabular and continuous environments show the proposed corrections can improve both the sample efficiency and final performance of existing AC methods.
A recent series of theoretical works showed that the dynamics of neural networks with a certain initialisation are well-captured by kernel methods. Concurrent empirical work demonstrated that kernel methods can come close to the performance of neural networks on some image classification tasks. These results raise the question of whether neural networks only learn successfully if kernels also learn successfully, despite being the more expressive function class. Here, we show that two-layer neural networks with only a few neurons achieve near-optimal performance on high-dimensional Gaussian mixture classification while lazy training approaches such as random features and kernel methods do not. Our analysis is based on the derivation of a set of ordinary differential equations that exactly track the dynamics of the network and thus allow to extract the asymptotic performance of the network as a function of regularisation or signal-to-noise ratio. We also show how over-parametrising the neural network leads to faster convergence, but does not improve its final performance.
Bayesian optimization (BO) is a popular tool for optimizing complex and costly-to-evaluate black-box objective functions. To further reduce the number of function evaluations, any party performing BO may be interested to collaborate with others to optimize the same objective function concurrently. To do this, existing BO algorithms have considered optimizing a batch of input queries in parallel and provided theoretical bounds on their cumulative regret reflecting inefficiency. However, when the objective function values are correlated with real-world rewards (e.g., money), parties may be hesitant to collaborate if they risk incurring larger cumulative regret (i.e., smaller real-world reward) than others. This paper shows that fairness and efficiency are both necessary for the collaborative BO setting. Inspired by social welfare concepts from economics, we propose a new notion of regret capturing these properties and a collaborative BO algorithm whose convergence rate can be theoretically guaranteed by bounding the new regret, both of which share an adjustable parameter for trading off between fairness vs. efficiency. We empirically demonstrate the benefits (e.g., increased fairness) of our algorithm using synthetic and real-world datasets.
Given an inverse problem with a normalizing flow prior, we wish to estimate the distribution of the underlying signal conditioned on the observations. We approach this problem as a task of conditional inference on the pre-trained unconditional flow model. We first establish that this is computationally hard for a large class of flow models. Motivated by this, we propose a framework for approximate inference that estimates the target conditional as a composition of two flow models. This formulation leads to a stable variational inference training procedure that avoids adversarial training. Our method is evaluated on a variety of inverse problems and is shown to produce high-quality samples with uncertainty quantification. We further demonstrate that our approach can be amortized for zero-shot inference.
We focus on the problem of finding an optimal strategy for a team of players that faces an opponent in an imperfect-information zero-sum extensive-form game. Team members are not allowed to communicate during play but can coordinate before the game. In this setting, it is known that the best the team can do is sample a profile of potentially randomized strategies (one per player) from a joint (a.k.a. correlated) probability distribution at the beginning of the game. In this paper, we first provide new modeling results about computing such an optimal distribution by drawing a connection to a different literature on extensive-form correlation. Second, we provide an algorithm that allows one for capping the number of profiles employed in the solution. This begets an anytime algorithm by increasing the cap. We find that often a handful of well-chosen such profiles suffices to reach optimal utility for the team. This enables team members to reach coordination through a simple and understandable plan. Finally, inspired by this observation and leveraging theoretical concepts that we introduce, we develop an efficient column-generation algorithm for finding an optimal distribution for the team. We evaluate it on a suite of common benchmark games. It is three …
Model-based reinforcement learning (MBRL) approaches rely on discrete-time state transition models whereas physical systems and the vast majority of control tasks operate in continuous-time. To avoid time-discretization approximation of the underlying process, we propose a continuous-time MBRL framework based on a novel actor-critic method. Our approach also infers the unknown state evolution differentials with Bayesian neural ordinary differential equations (ODE) to account for epistemic uncertainty. We implement and test our method on a new ODE-RL suite that explicitly solves continuous-time control systems. Our experiments illustrate that the model is robust against irregular and noisy data, and can solve classic control problems in a sample-efficient manner.
Imitation learning seeks to circumvent the difficulty in designing proper reward functions for training agents by utilizing expert behavior. With environments modeled as Markov Decision Processes (MDP), most of the existing imitation algorithms are contingent on the availability of expert demonstrations in the same MDP as the one in which a new imitation policy is to be learned. In this paper, we study the problem of how to imitate tasks when discrepancies exist between the expert and agent MDP. These discrepancies across domains could include differing dynamics, viewpoint, or morphology; we present a novel framework to learn correspondences across such domains. Importantly, in contrast to prior works, we use unpaired and unaligned trajectories containing only states in the expert domain, to learn this correspondence. We utilize a cycle-consistency constraint on both the state space and a domain agnostic latent space to do this. In addition, we enforce consistency on the temporal position of states via a normalized position estimator function, to align the trajectories across the two domains. Once this correspondence is found, we can directly transfer the demonstrations on one domain to the other and use it for imitation. Experiments across a wide variety of challenging domains demonstrate the …
We consider the learning and prediction of nonlinear time series generated by a latent symplectic map. A special case is (not necessarily separable) Hamiltonian systems, whose solution flows give such symplectic maps. For this special case, both generic approaches based on learning the vector field of the latent ODE and specialized approaches based on learning the Hamiltonian that generates the vector field exist. Our method, however, is different as it does not rely on the vector field nor assume its existence; instead, it directly learns the symplectic evolution map in discrete time. Moreover, we do so by representing the symplectic map via a generating function, which we approximate by a neural network (hence the name GFNN). This way, our approximation of the evolution map is always \emph{exactly} symplectic. This additional geometric structure allows the local prediction error at each step to accumulate in a controlled fashion, and we will prove, under reasonable assumptions, that the global prediction error grows at most \emph{linearly} with long prediction time, which significantly improves an otherwise exponential growth. In addition, as a map-based and thus purely data-driven method, GFNN avoids two additional sources of inaccuracies common in vector-field based approaches, namely the error in approximating …
We introduce Hindsight Off-policy Options (HO2), a data-efficient option learning algorithm. Given any trajectory, HO2 infers likely option choices and backpropagates through the dynamic programming inference procedure to robustly train all policy components off-policy and end-to-end. The approach outperforms existing option learning methods on common benchmarks. To better understand the option framework and disentangle benefits from both temporal and action abstraction, we evaluate ablations with flat policies and mixture policies with comparable optimization. The results highlight the importance of both types of abstraction as well as off-policy training and trust-region constraints, particularly in challenging, simulated 3D robot manipulation tasks from raw pixel inputs. Finally, we intuitively adapt the inference step to investigate the effect of increased temporal abstraction on training with pre-trained options and from scratch.
Agents that learn to select optimal actions represent a prominent focus of the sequential decision-making literature. In the face of a complex environment or constraints on time and resources, however, aiming to synthesize such an optimal policy can become infeasible. These scenarios give rise to an important trade-off between the information an agent must acquire to learn and the sub-optimality of the resulting policy. While an agent designer has a preference for how this trade-off is resolved, existing approaches further require that the designer translate these preferences into a fixed learning target for the agent. In this work, leveraging rate-distortion theory, we automate this process such that the designer need only express their preferences via a single hyperparameter and the agent is endowed with the ability to compute its own learning targets that best achieve the desired trade-off. We establish a general bound on expected discounted regret for an agent that decides what to learn in this manner along with computational experiments that illustrate the expressiveness of designer preferences and even show improvements over Thompson sampling in identifying an optimal policy.
Choosing the optimizer is considered to be among the most crucial design decisions in deep learning, and it is not an easy one. The growing literature now lists hundreds of optimization methods. In the absence of clear theoretical guidance and conclusive empirical evidence, the decision is often made based on anecdotes. In this work, we aim to replace these anecdotes, if not with a conclusive ranking, then at least with evidence-backed heuristics. To do so, we perform an extensive, standardized benchmark of fifteen particularly popular deep learning optimizers while giving a concise overview of the wide range of possible choices. Analyzing more than 50,000 individual runs, we contribute the following three points: (i) Optimizer performance varies greatly across tasks. (ii) We observe that evaluating multiple optimizers with default parameters works approximately as well as tuning the hyperparameters of a single, fixed optimizer. (iii) While we cannot discern an optimization method clearly dominating across all tested tasks, we identify a significantly reduced subset of specific optimizers and parameter choices that generally lead to competitive results in our experiments: Adam remains a strong contender, with newer methods failing to significantly and consistently outperform it. Our open-sourced results are available as challenging and …
In this paper we address a variant of the continuous multi-armed bandits problem, called the threshold estimation problem, which is at the heart of many psychometric experiments. Here, the objective is to estimate the sensitivity threshold for an unknown psychometric function Psi, which is assumed to be non decreasing and continuous. Our algorithm, Dichotomous Optimistic Search (DOS), efficiently solves this task by taking inspiration from hierarchical multi-armed bandits and Black-box optimization. Compared to previous approaches, DOS is model free and only makes minimal assumption on Psi smoothness, while having strong theoretical guarantees that compares favorably to recent methods from both Psychophysics and Global Optimization. We also empirically evaluate DOS and show that it significantly outperforms these methods, both in experiments that mimics the conduct of a psychometric experiment, and in tests with large pulls budgets that illustrate the faster convergence rate.
Negative sampling schemes enable efficient training given a large number of classes, by offering a means to approximate a computationally expensive loss function that takes all labels into account. In this paper, we present a new connection between these schemes and loss modification techniques for countering label imbalance. We show that different negative sampling schemes implicitly trade-off performance on dominant versus rare labels. Further, we provide a unified means to explicitly tackle both sampling bias, arising from working with a subset of all labels, and labeling bias, which is inherent to the data due to label imbalance. We empirically verify our findings on long-tail classification and retrieval benchmarks.
Modern machine learning models with high accuracy are often miscalibrated---the predicted top probability does not reflect the actual accuracy, and tends to be \emph{over-confident}. It is commonly believed that such over-confidence is mainly due to \emph{over-parametrization}, in particular when the model is large enough to memorize the training data and maximize the confidence.
In this paper, we show theoretically that over-parametrization is not the only reason for over-confidence. We prove that \emph{logistic regression is inherently over-confident}, in the realizable, under-parametrized setting where the data is generated from the logistic model, and the sample size is much larger than the number of parameters. Further, this over-confidence happens for general well-specified binary classification problems as long as the activation is symmetric and concave on the positive part. Perhaps surprisingly, we also show that over-confidence is not always the case---there exists another activation function (and a suitable loss function) under which the learned classifier is \emph{under-confident} at some probability values. Overall, our theory provides a precise characterization of calibration in realizable binary classification, which we verify on simulations and real data experiments.
We consider large-scale Markov decision processes with an unknown cost function and address the problem of learning a policy from a finite set of expert demonstrations. We assume that the learner is not allowed to interact with the expert and has no access to reinforcement signal of any kind. Existing inverse reinforcement learning methods come with strong theoretical guarantees, but are computationally expensive, while state-of-the-art policy optimization algorithms achieve significant empirical success, but are hampered by limited theoretical understanding. To bridge the gap between theory and practice, we introduce a novel bilinear saddle-point framework using Lagrangian duality. The proposed primal-dual viewpoint allows us to develop a model-free provably efficient algorithm through the lens of stochastic convex optimization. The method enjoys the advantages of simplicity of implementation, low memory requirements, and computational and sample complexities independent of the number of states. We further present an equivalent no-regret online-learning interpretation.
Dirichlet-based uncertainty (DBU) models are a recent and promising class of uncertainty-aware models. DBU models predict the parameters of a Dirichlet distribution to provide fast, high-quality uncertainty estimates alongside with class predictions. In this work, we present the first large-scale, in-depth study of the robustness of DBU models under adversarial attacks. Our results suggest that uncertainty estimates of DBU models are not robust w.r.t. three important tasks: (1) indicating correctly and wrongly classified samples; (2) detecting adversarial examples; and (3) distinguishing between in-distribution (ID) and out-of-distribution (OOD) data. Additionally, we explore the first approaches to make DBU mod- els more robust. While adversarial training has a minor effect, our median smoothing based ap- proach significantly increases robustness of DBU models.
Quantum Neural Networks (QNNs), or the so-called variational quantum circuits, are important quantum applications both because of their similar promises as classical neural networks and because of the feasibility of their implementation on near-term intermediate-size noisy quantum machines (NISQ). However, the training task of QNNs is challenging and much less understood. We conduct a quantitative investigation on the landscape of loss functions of QNNs and identify a class of simple yet extremely hard QNN instances for training. Specifically, we show for typical under-parameterized QNNs, there exists a dataset that induces a loss function with the number of spurious local minima depending exponentially on the number of parameters. Moreover, we show the optimality of our construction by providing an almost matching upper bound on such dependence. While local minima in classical neural networks are due to non-linear activations, in quantum neural networks local minima appear as a result of the quantum interference phenomenon. Finally, we empirically confirm that our constructions can indeed be hard instances in practice with typical gradient-based optimizers, which demonstrates the practical value of our findings.
The Stackelberg prediction game (SPG) has been extensively used to model the interactions between the learner and data provider in the training process of various machine learning algorithms. Particularly, SPGs played prominent roles in cybersecurity applications, such as intrusion detection, banking fraud detection, spam filtering, and malware detection. Often formulated as NP-hard bi-level optimization problems, it is generally computationally intractable to find global solutions to SPGs. As an interesting progress in this area, a special class of SPGs with the least squares loss (SPG-LS) have recently been shown polynomially solvable by a bisection method. However, in each iteration of this method, a semidefinite program (SDP) needs to be solved. The resulted high computational costs prevent its applications for large-scale problems. In contrast, we propose a novel approach that reformulates a SPG-LS as a single SDP of a similar form and the same dimension as those solved in the bisection method. Our SDP reformulation is, evidenced by our numerical experiments, orders of magnitude faster than the existing bisection method. We further show that the obtained SDP can be reduced to a second order cone program (SOCP). This allows us to provide real-time response to large-scale SPG-LS problems. Numerical results on both …
We study fast algorithms for computing basic properties of an n x n positive semidefinite kernel matrix K corresponding to n points x1,...,xn in R^d. In particular, we consider the estimating the sum of kernel matrix entries, along with its top eigenvalue and eigenvector. These are some of the most basic problems defined over kernel matrices.
We show that the sum of matrix entries can be estimated up to a multiplicative factor of 1+\epsilon in time sublinear in n and linear in d for many popular kernel functions, including the Gaussian, exponential, and rational quadratic kernels. For these kernels, we also show that the top eigenvalue (and a witnessing approximate eigenvector) can be approximated to a multiplicative factor of 1+\epsilon in time sub-quadratic in n and linear in d.
Our algorithms represent significant advances in the best known runtimes for these problems. They leverage the positive definiteness of the kernel matrix, along with a recent line of work on efficient kernel density estimation.
We study the emergence of chaotic behavior of Follow-the-Regularized Leader (FoReL) dynamics in games. We focus on the effects of increasing the population size or the scale of costs in congestion games, and generalize recent results on unstable, chaotic behaviors in the Multiplicative Weights Update dynamics to a much larger class of FoReL dynamics. We establish that, even in simple linear non-atomic congestion games with two parallel links and \emph{any} fixed learning rate, unless the game is fully symmetric, increasing the population size or the scale of costs causes learning dynamics to becomes unstable and eventually chaotic, in the sense of Li-Yorke and positive topological entropy. Furthermore, we prove the existence of novel non-standard phenomena such as the coexistence of stable Nash equilibria and chaos in the same game. We also observe the simultaneous creation of a chaotic attractor as another chaotic attractor gets destroyed. Lastly, although FoReL dynamics can be strange and non-equilibrating, we prove that the time average still converges to an \emph{exact} equilibrium for any choice of learning rate and any scale of costs.
Recent work demonstrated the benefits of studying continuous-time dynamics governing the GAN training. However, this dynamics is analyzed in the model parameter space, which results in finite-dimensional dynamical systems. We propose a novel perspective where we study the local dynamics of adversarial training in the general functional space and show how it can be represented as a system of partial differential equations. Thus, the convergence properties can be inferred from the eigenvalues of the resulting differential operator. We show that these eigenvalues can be efficiently estimated from the target dataset before training. Our perspective reveals several insights on the practical tricks commonly used to stabilize GANs, such as gradient penalty, data augmentation, and advanced integration schemes. As an immediate practical benefit, we demonstrate how one can a priori select an optimal data augmentation strategy for a particular generation task.
Neural Architecture Search (NAS) is a popular method for automatically designing optimized deep-learning architectures. NAS methods commonly use bilevel optimization where one optimizes the weights over the training data (lower-level problem) and hyperparameters - such as the architecture - over the validation data (upper-level problem). This paper explores the statistical aspects of such problems with train-validation splits. In practice, the lower-level problem is often overparameterized and can easily achieve zero loss. Thus, a-priori, it seems impossible to distinguish the right hyperparameters based on training loss alone which motivates a better understanding of train-validation split. To this aim, we first show that refined properties of the validation loss such as risk and hyper-gradients are indicative of those of the true test loss and help prevent overfitting with a near-minimal validation sample size. Importantly, this is established for continuous search spaces which are relevant for differentiable search schemes. We then establish generalization bounds for NAS problems with an emphasis on an activation search problem and gradient-based methods. Finally, we show rigorous connections between NAS and low-rank matrix learning which leads to algorithmic insights where the solution of the upper problem can be accurately learned via spectral methods to achieve near-minimal risk.
Recent years have witnessed the success of multi-agent reinforcement learning, which has motivated new research directions for mean-field control (MFC) and mean-field game (MFG), as the multi-agent system can be well approximated by a mean-field problem when the number of agents grows to be very large. In this paper, we study the policy gradient (PG) method for the linear-quadratic mean-field control and game, where we assume each agent has identical linear state transitions and quadratic cost functions. While most recent works on policy gradient for MFC and MFG are based on discrete-time models, we focus on a continuous-time model where some of our analyzing techniques could be valuable to the interested readers. For both the MFC and the MFG, we provide PG update and show that it converges to the optimal solution at a linear rate, which is verified by a synthetic simulation. For the MFG, we also provide sufficient conditions for the existence and uniqueness of the Nash equilibrium.
Solving sparse reward tasks through exploration is one of the major challenges in deep reinforcement learning, especially in three-dimensional, partially-observable environments. Critically, the algorithm proposed in this article is capable of using a single human demonstration to solve hard-exploration problems. We train an agent on a combination of demonstrations and own experience to solve problems with variable initial conditions and we integrate it with proximal policy optimization (PPO). The agent is also able to increase its performance and to tackle harder problems by replaying its own past trajectories prioritizing them based on the obtained reward and the maximum value of the trajectory. We finally compare variations of this algorithm to different imitation learning algorithms on a set of hard-exploration tasks in the Animal-AI Olympics environment. To the best of our knowledge, learning a task in a three-dimensional environment with comparable difficulty has never been considered before using only one human demonstration.
In recent years methods from optimal linear experimental design have been leveraged to obtain state of the art results for linear bandits.
A design returned from an objective such as G-optimal design is actually a probability distribution over a pool of potential measurement vectors.
Consequently, one nuisance of the approach is the task of converting this continuous probability distribution into a discrete assignment of N measurements.
While sophisticated rounding techniques have been proposed, in d dimensions they require N to be at least d, d log(log(d)), or d^2 based on the sub-optimality of the solution.
In this paper we are interested in settings where N may be much less than d, such as in experimental design in an RKHS where d may be effectively infinite.
In this work, we propose a rounding procedure that frees N of any dependence on the dimension d, while achieving nearly the same performance guarantees of existing rounding procedures.
We evaluate the procedure against a baseline that projects the problem to a lower dimensional space and performs rounding there, which requires N to just be at least a notion of the effective dimension. We also leverage our new approach in a new algorithm for kernelized …
\emph{Unlabeled sensing} is a recent problem encompassing many data science and engineering applications and typically formulated as solving linear equations whose right-hand side vector has undergone an unknown permutation. It was generalized to the \emph{homomorphic sensing} problem by replacing the unknown permutation with an unknown linear map from a given finite set of linear maps. In this paper we present tighter and simpler conditions for the homomorphic sensing problem to admit a unique solution. We show that this solution is locally stable under noise, while under a sparsity assumption it remains unique under less demanding conditions. Sparsity in the context of unlabeled sensing leads to the problem of \textit{unlabeled compressed sensing}, and a consequence of our general theory is the existence under mild conditions of a unique sparsest solution. On the algorithmic level, we solve unlabeled compressed sensing by an iterative algorithm validated by synthetic data experiments. Finally, under the unifying homomorphic sensing framework we connect unlabeled sensing to other important practical problems.
Semantic understanding of programs is a fundamental problem for programming language processing (PLP). Recent works that learn representations of code based on pre-training techniques in NLP have pushed the frontiers in this direction. However, the semantics of PL and NL have essential differences. These being ignored, we believe it is difficult to build a model to better understand programs, by either directly applying off-the-shelf NLP pre-training techniques to the source code, or adding features to the model by the heuristic. In fact, the semantics of a program can be rigorously defined by formal semantics in PL theory. For example, the operational semantics, describes the meaning of a valid program as updating the environment (i.e., the memory address-value function) through fundamental operations, such as memory I/O and conditional branching. Inspired by this, we propose a novel program semantics learning paradigm, that the model should learn from information composed of (1) the representations which align well with the fundamental operations in operational semantics, and (2) the information of environment transition, which is indispensable for program understanding. To validate our proposal, we present a hierarchical Transformer-based pre-training model called OSCAR to better facilitate the understanding of programs. OSCAR learns from intermediate representation (IR) …
Performative distribution shift captures the setting where the choice of which ML model is deployed changes the data distribution. For example, a bank which uses the number of open credit lines to determine a customer's risk of default on a loan may induce customers to open more credit lines in order to improve their chances of being approved. Because of the interactions between the model and data distribution, finding the optimal model parameters is challenging. Works in this area have focused on finding stable points, which can be far from optimal. Here we introduce \emph{performative gradient descent} (PerfGD), an algorithm for computing performatively optimal points. Under regularity assumptions on the performative loss, PerfGD is the first algorithm which provably converges to an optimal point. PerfGD explicitly captures how changes in the model affects the data distribution and is simple to use. We support our findings with theory and experiments.
Latent variable models have been successfully applied in lossless compression with the bits-back coding algorithm. However, bits-back suffers from an increase in the bitrate equal to the KL divergence between the approximate posterior and the true posterior. In this paper, we show how to remove this gap asymptotically by deriving bits-back coding algorithms from tighter variational bounds. The key idea is to exploit extended space representations of Monte Carlo estimators of the marginal likelihood. Naively applied, our schemes would require more initial bits than the standard bits-back coder, but we show how to drastically reduce this additional cost with couplings in the latent space. When parallel architectures can be exploited, our coders can achieve better rates than bits-back with little additional cost. We demonstrate improved lossless compression rates in a variety of settings, especially in out-of-distribution or sequential data compression.
Rationalizing which parts of a molecule drive the predictions of a molecular graph convolutional neural network (GCNN) can be difficult. To help, we propose two simple regularization techniques to apply during the training of GCNNs: Batch Representation Orthonormalization (BRO) and Gini regularization. BRO, inspired by molecular orbital theory, encourages graph convolution operations to generate orthonormal node embeddings. Gini regularization is applied to the weights of the output layer and constrains the number of dimensions the model can use to make predictions. We show that Gini and BRO regularization can improve the accuracy of state-of-the-art GCNN attribution methods on artificial benchmark datasets. In a real-world setting, we demonstrate that medicinal chemists significantly prefer explanations extracted from regularized models. While we only study these regularizers in the context of GCNNs, both can be applied to other types of neural networks.
Randomized experiments can be susceptible to selection bias due to potential non-compliance by the participants. While much of the existing work has studied compliance as a static behavior, we propose a game-theoretic model to study compliance as dynamic behavior that may change over time. In rounds, a social planner interacts with a sequence of heterogeneous agents who arrive with their unobserved private type that determines both their prior preferences across the actions (e.g., control and treatment) and their baseline rewards without taking any treatment. The planner provides each agent with a randomized recommendation that may alter their beliefs and their action selection. We develop a novel recommendation mechanism that views the planner's recommendation as a form of instrumental variable (IV) that only affects an agents' action selection, but not the observed rewards. We construct such IVs by carefully mapping the history --the interactions between the planner and the previous agents-- to a random recommendation. Even though the initial agents may be completely non-compliant, our mechanism can incentivize compliance over time, thereby enabling the estimation of the treatment effect of each treatment, and minimizing the cumulative regret of the planner whose goal is to identify the optimal treatment.
An important problem in systems neuroscience is to identify the latent dynamics underlying neural population activity. Here we address this problem by introducing a low-dimensional nonlinear model for latent neural population dynamics using neural ordinary differential equations (neural ODEs), with noisy sensory inputs and Poisson spike train outputs. We refer to this as the Poisson Latent Neural Differential Equations (PLNDE) model. We apply the PLNDE framework to a variety of synthetic datasets, and show that it accurately infers the phase portraits and fixed points of nonlinear systems augmented to produce spike train data, including the FitzHugh-Nagumo oscillator, a 3-dimensional nonlinear spiral, and a nonlinear sensory decision-making model with attractor dynamics. Our model significantly outperforms existing methods at inferring single-trial neural firing rates and the corresponding latent trajectories that generated them, especially in the regime where the spike counts and number of trials are low. We then apply our model to multi-region neural population recordings from medial frontal cortex of rats performing an auditory decision-making task. Our model provides a general, interpretable framework for investigating the neural mechanisms of decision-making and other cognitive computations through the lens of dynamical systems.
Sequential data with serial correlation and an unknown, unstructured, and dynamic background is ubiquitous in neuroscience, psychology, and econometrics. Inferring serial correlation for such data is a fundamental challenge in statistics. We propose a Total Variation (TV) constrained least square estimator coupled with hypothesis tests to infer the serial correlation in the presence of unknown and unstructured dynamic background. The TV constraint on the dynamic background encourages a piecewise constant structure, which can approximate a wide range of dynamic backgrounds. The tuning parameter is selected via the Ljung-Box test to control the bias-variance trade-off. We establish a non-asymptotic upper bound for the estimation error through variational inequalities. We also derive a lower error bound via Fano's method and show the proposed method is near-optimal. Numerical simulation and a real study in psychology demonstrate the excellent performance of our proposed method compared with the state-of-the-art.
In offline reinforcement learning (RL), we seek to utilize offline data to evaluate (or learn) policies in scenarios where the data are collected from a distribution that substantially differs from that of the target policy to be evaluated. Recent theoretical advances have shown that such sample-efficient offline RL is indeed possible provided certain strong representational conditions hold, else there are lower bounds exhibiting exponential error amplification (in the problem horizon) unless the data collection distribution has only a mild distribution shift relative to the target policy. This work studies these issues from an empirical perspective to gauge how stable offline RL methods are. In particular, our methodology explores these ideas when using features from pre-trained neural networks, in the hope that these representations are powerful enough to permit sample efficient offline RL. Through extensive experiments on a range of tasks, we see that substantial error amplification does occur even when using such pre-trained representations (trained on the same task itself); we find offline RL is stable only under extremely mild distribution shift. The implications of these results, both from a theoretical and an empirical perspective, are that successful offline RL (where we seek to go beyond the low distribution shift …
This paper introduces kernel continual learning, a simple but effective variant of continual learning that leverages the non-parametric nature of kernel methods to tackle catastrophic forgetting. We deploy an episodic memory unit that stores a subset of samples for each task to learn task-specific classifiers based on kernel ridge regression. This does not require memory replay and systematically avoids task interference in the classifiers. We further introduce variational random features to learn a data-driven kernel for each task. To do so, we formulate kernel continual learning as a variational inference problem, where a random Fourier basis is incorporated as the latent variable. The variational posterior distribution over the random Fourier basis is inferred from the coreset of each task. In this way, we are able to generate more informative kernels specific to each task, and, more importantly, the coreset size can be reduced to achieve more compact memory, resulting in more efficient continual learning based on episodic memory. Extensive evaluation on four benchmarks demonstrates the effectiveness and promise of kernels for continual learning.
In this paper we present a scalable deep learning framework for finding Markovian Nash Equilibria in multi-agent stochastic games using fictitious play. The motivation is inspired by theoretical analysis of Forward Backward Stochastic Differential Equations and their implementation in a deep learning setting, which is the source of our algorithm's sample efficiency improvement. By taking advantage of the permutation-invariant property of agents in symmetric games, the scalability and performance is further enhanced significantly. We showcase superior performance of our framework over the state-of-the-art deep fictitious play algorithm on an inter-bank lending/borrowing problem in terms of multiple metrics. More importantly, our approach scales up to 3000 agents in simulation, a scale which, to the best of our knowledge, represents a new state-of-the-art. We also demonstrate the applicability of our framework in robotics on a belief space autonomous racing problem.
Many of real-world data, e.g., the VGGFace2 dataset, which is a collection of multiple portraits of individuals, come with nested structures due to grouped observation. The Ornstein auto-encoder (OAE) is an emerging framework for representation learning from nested data, based on an optimal transport distance between random processes. An attractive feature of OAE is its ability to generate new variations nested within an observational unit, whether or not the unit is known to the model. A previously proposed algorithm for OAE, termed the random-intercept OAE (RIOAE), showed an impressive performance in learning nested representations, yet lacks theoretical justification. In this work, we show that RIOAE minimizes a loose upper bound of the employed optimal transport distance. After identifying several issues with RIOAE, we present the product-space OAE (PSOAE) that minimizes a tighter upper bound of the distance and achieves orthogonality in the representation space. PSOAE alleviates the instability of RIOAE and provides more flexible representation of nested data. We demonstrate the high performance of PSOAE in the three key tasks of generative models: exemplar generation, style transfer, and new concept generation.
Organ transplantation is often the last resort for treating end-stage illnesses, but managing transplant wait-lists is challenging because of organ scarcity and the complexity of assessing donor-recipient compatibility. In this paper, we develop a data-driven model for (real-time) organ allocation using observational data for transplant outcomes. Our model integrates a queuing-theoretic framework with unsupervised learning to cluster the organs into ``organ types'', and then construct priority queues (associated with each organ type) wherein incoming patients are assigned. To reason about organ allocations, the model uses synthetic controls to infer a patient's survival outcomes under counterfactual allocations to the different organ types– the model is trained end-to-end to optimise the trade-off between patient waiting time and expected survival time. The usage of synthetic controls enable patient-level interpretations of allocation decisions that can be presented and understood by clinicians. We test our model on multiple data sets, and show that it outperforms other organ-allocation policies in terms of added life-years, and death count. Furthermore, we introduce a novel organ-allocation simulator to accurately test new policies.
Learning nonlinear dynamics from aggregate data is a challenging problem because the full trajectory of each individual is not available, namely, the individual observed at one time may not be observed at the next time point, or the identity of individual is unavailable. This is in sharp contrast to learning dynamics with full trajectory data, on which the majority of existing methods are based. We propose a novel method using the weak form of Fokker Planck Equation (FPE) --- a partial differential equation --- to describe the density evolution of data in a sampled form, which is then combined with Wasserstein generative adversarial network (WGAN) in the training process. In such a sample-based framework we are able to learn the nonlinear dynamics from aggregate data without explicitly solving the partial differential equation (PDE) FPE. We demonstrate our approach in the context of a series of synthetic and real-world data sets.
In the Learning to Price setting, a seller posts prices over time with the goal of maximizing revenue while learning the buyer's valuation. This problem is very well understood when values are stationary (fixed or iid). Here we study the problem where the buyer's value is a moving target, i.e., they change over time either by a stochastic process or adversarially with bounded variation. In either case, we provide matching upper and lower bounds on the optimal revenue loss. Since the target is moving, any information learned soon becomes out-dated, which forces the algorithms to keep switching between exploring and exploiting phases.
Deep neural networks give state-of-the-art accuracy for reconstructing images from few and noisy measurements, a problem arising for example in accelerated magnetic resonance imaging (MRI). However, recent works have raised concerns that deep-learning-based image reconstruction methods are sensitive to perturbations and are less robust than traditional methods: Neural networks (i) may be sensitive to small, yet adversarially-selected perturbations, (ii) may perform poorly under distribution shifts, and (iii) may fail to recover small but important features in an image. In order to understand the sensitivity to such perturbations, in this work, we measure the robustness of different approaches for image reconstruction including trained and un-trained neural networks as well as traditional sparsity-based methods. We find, contrary to prior works, that both trained and un-trained methods are vulnerable to adversarial perturbations. Moreover, both trained and un-trained methods tuned for a particular dataset suffer very similarly from distribution shifts. Finally, we demonstrate that an image reconstruction method that achieves higher reconstruction quality, also performs better in terms of accurately recovering fine details. Our results indicate that the state-of-the-art deep-learning-based image reconstruction methods provide improved performance than traditional methods without compromising robustness.
The surrogate that predicts the performance of hyperparameters has been a key component for sequential model-based hyperparameter optimization. In practical applications, a trial of a hyper-parameter configuration may be so costly that a surrogate is expected to return an optimal configuration with as few trials as possible. Observing that human experts draw on their expertise in a machine learning model by trying configurations that once performed well on other datasets, we are inspired to build a trial-efficient surrogate by transferring the meta-knowledge learned from historical trials on other datasets. We propose an end-to-end surrogate named as Transfer NeuralProcesses (TNP) that learns a comprehensive set of meta-knowledge, including the parameters of historical surrogates, historical trials, and initial configurations for other datasets. Experiments on extensive OpenML datasets and three computer vision datasets demonstrate that the proposed algorithm achieves state-of-the-art performance in at least one order of magnitude less trials.
When decision-makers can directly intervene, policy evaluation algorithms give valid causal estimates. In off-policy evaluation (OPE), there may exist unobserved variables that both impact the dynamics and are used by the unknown behavior policy. These ``confounders'' will introduce spurious correlations and naive estimates for a new policy will be biased. We develop worst-case bounds to assess sensitivity to these unobserved confounders in finite horizons when confounders are drawn iid each period. We demonstrate that a model-based approach with robust MDPs gives sharper lower bounds by exploiting domain knowledge about the dynamics. Finally, we show that when unobserved confounders are persistent over time, OPE is far more difficult and existing techniques produce extremely conservative bounds.
Promoting behavioural diversity is critical for solving games with non-transitive dynamics where strategic cycles exist, and there is no consistent winner (e.g., Rock-Paper-Scissors). Yet, there is a lack of rigorous treatment for defining diversity and constructing diversity-aware learning dynamics. In this work, we offer a geometric interpretation of behavioural diversity in games and introduce a novel diversity metric based on \emph{determinantal point processes} (DPP). By incorporating the diversity metric into best-response dynamics, we develop \emph{diverse fictitious play} and \emph{diverse policy-space response oracle} for solving normal-form games and open-ended games. We prove the uniqueness of the diverse best response and the convergence of our algorithms on two-player games. Importantly, we show that maximising the DPP-based diversity metric guarantees to enlarge the \emph{gamescape} -- convex polytopes spanned by agents' mixtures of strategies. To validate our diversity-aware solvers, we test on tens of games that show strong non-transitivity. Results suggest that our methods achieve at least the same, and in most games, lower exploitability than PSRO solvers by finding effective and diverse strategies.
Multiplying matrices is among the most fundamental and most computationally demanding operations in machine learning and scientific computing. Consequently, the task of efficiently approximating matrix products has received significant attention.
We introduce a learning-based algorithm for this task that greatly outperforms existing methods. Experiments using hundreds of matrices from diverse domains show that it often runs 10x faster than alternatives at a given level of error, as well as 100x faster than exact matrix multiplication. In the common case that one matrix is known ahead of time, our method also has the interesting property that it requires zero multiply-adds.
These results suggest that a mixture of hashing, averaging, and byte shuffling—the core operations of our method—could be a more promising building block for machine learning than the sparsified, factorized, and/or scalar quantized matrix products that have recently been the focus of substantial research and hardware investment.
Many inference problems, such as sequential decision problems like A/B testing, adaptive sampling schemes like bandit selection, are often online in nature. The fundamental problem for online inference is to provide a sequence of confidence intervals that are valid uniformly over the growing-into-infinity sample sizes. To address this question, we provide a near-optimal confidence sequence for bounded random variables by utilizing Bentkus' concentration results. We show that it improves on the existing approaches that use the Cram{\'e}r-Chernoff technique such as the Hoeffding, Bernstein, and Bennett inequalities. The resulting confidence sequence is confirmed to be favorable in synthetic coverage problems, adaptive stopping algorithms, and multi-armed bandit problems.
We study the identification of direct and indirect causes on time series with latent variables, and provide a constrained-based causal feature selection method, which we prove that is both sound and complete under some graph constraints. Our theory and estimation algorithm require only two conditional independence tests for each observed candidate time series to determine whether or not it is a cause of an observed target time series. Furthermore, our selection of the conditioning set is such that it improves signal to noise ratio. We apply our method on real data, and on a wide range of simulated experiments, which yield very low false positive and relatively low false negative rates.
Probabilistic programming uses programs to express generative models whose posterior probability is then computed by built-in inference engines. A challenging goal is to develop general purpose inference algorithms that work out-of-the-box for arbitrary programs in a universal probabilistic programming language (PPL). The densities defined by such programs, which may use stochastic branching and recursion, are (in general) nonparametric, in the sense that they correspond to models on an infinite-dimensional parameter space. However standard inference algorithms, such as the Hamiltonian Monte Carlo (HMC) algorithm, target distributions with a fixed number of parameters. This paper introduces the Nonparametric Hamiltonian Monte Carlo (NP-HMC) algorithm which generalises HMC to nonparametric models. Inputs to NP-HMC are a new class of measurable functions called “tree representable”, which serve as a language-independent representation of the density functions of probabilistic programs in a universal PPL. We provide a correctness proof of NP-HMC, and empirically demonstrate significant performance improvements over existing approaches on several nonparametric examples.
Inhomogeneous Poisson point processes are widely used models of event occurrences. We address \emph{adaptive sensing of Poisson Point processes}, namely, maximizing the number of captured events subject to sensing costs. We encode prior assumptions on the rate function by modeling it as a member of a known \emph{reproducing kernel Hilbert space} (RKHS). By partitioning the domain into separate small regions, and using heteroscedastic linear regression, we propose a tractable estimator of Poisson process rates for two feedback models: \emph{count-record}, where exact locations of events are observed, and \emph{histogram} feedback, where only counts of events are observed. We derive provably accurate anytime confidence estimates for our estimators for sequentially acquired Poisson count data. Using these, we formulate algorithms based on optimism that provably incur sublinear count-regret. We demonstrate the practicality of the method on problems from crime modeling, revenue maximization as well as environmental monitoring.
In recent years, federated learning has been embraced as an approach for bringing about collaboration across large populations of learning agents. However, little is known about how collaboration protocols should take agents' incentives into account when allocating individual resources for communal learning in order to maintain such collaborations. Inspired by game theoretic notions, this paper introduces a framework for incentive-aware learning and data sharing in federated learning. Our stable and envy-free equilibria capture notions of collaboration in the presence of agents interested in meeting their learning objectives while keeping their own sample collection burden low. For example, in an envy-free equilibrium, no agent would wish to swap their sampling burden with any other agent and in a stable equilibrium, no agent would wish to unilaterally reduce their sampling burden.
In addition to formalizing this framework, our contributions include characterizing the structural properties of such equilibria, proving when they exist, and showing how they can be computed. Furthermore, we compare the sample complexity of incentive-aware collaboration with that of optimal collaboration when one ignores agents' incentives.
Deep learning empirically achieves high performance in many applications, but its training dynamics has not been fully understood theoretically. In this paper, we explore theoretical analysis on training two-layer ReLU neural networks in a teacher-student regression model, in which a student network learns an unknown teacher network through its outputs. We show that with a specific regularization and sufficient over-parameterization, the student network can identify the parameters of the teacher network with high probability via gradient descent with a norm dependent stepsize even though the objective function is highly non-convex. The key theoretical tool is the measure representation of the neural networks and a novel application of a dual certificate argument for sparse estimation on a measure space. We analyze the global minima and global convergence property in the measure space.
We present a novel control-theoretic understanding of online optimization and learning in games, via the notion of passivity. Passivity is a fundamental concept in control theory, which abstracts energy conservation and dissipation in physical systems. It has become a standard tool in analysis of general feedback systems, to which game dynamics belong. Our starting point is to show that all continuous-time Follow-the-Regularized-Leader (FTRL) dynamics, which include the well-known Replicator Dynamic, are lossless, i.e. it is passive with no energy dissipation. Interestingly, we prove that passivity implies bounded regret, connecting two fundamental primitives of control theory and online optimization.
The observation of energy conservation in FTRL inspires us to present a family of lossless learning dynamics, each of which has an underlying energy function with a simple gradient structure. This family is closed under convex combination; as an immediate corollary, any convex combination of FTRL dynamics is lossless and thus has bounded regret. This allows us to extend the framework of Fox & Shamma [Games 2013] to prove not just global asymptotic stability results for game dynamics, but Poincaré recurrence results as well. Intuitively, when a lossless game (e.g. graphical constant-sum game) is coupled with lossless learning dynamic, their interconnection is …
We consider the task of learning to control a linear dynamical system under fixed quadratic costs, known as the Linear Quadratic Regulator (LQR) problem. While model-free approaches are often favorable in practice, thus far only model-based methods, which rely on costly system identification, have been shown to achieve regret that scales with the optimal dependence on the time horizon T. We present the first model-free algorithm that achieves similar regret guarantees. Our method relies on an efficient policy gradient scheme, and a novel and tighter analysis of the cost of exploration in policy space in this setting.
Robustness to variations in lighting conditions is a key objective for any deep vision system. To this end, our paper extends the receptive field of convolutional neural networks with two residual components, ubiquitous in the visual processing system of vertebrates: On-center and off-center pathways, with an excitatory center and inhibitory surround; OOCS for short. The On-center pathway is excited by the presence of a light stimulus in its center, but not in its surround, whereas the Off-center pathway is excited by the absence of a light stimulus in its center, but not in its surround. We design OOCS pathways via a difference of Gaussians, with their variance computed analytically from the size of the receptive fields. OOCS pathways complement each other in their response to light stimuli, ensuring this way a strong edge-detection capability, and as a result an accurate and robust inference under challenging lighting conditions. We provide extensive empirical evidence showing that networks supplied with OOCS pathways gain accuracy and illumination-robustness from the novel edge representation, compared to other baselines.
Recent work has highlighted the role of initialization scale in determining the structure of the solutions that gradient methods converge to. In particular, it was shown that large initialization leads to the neural tangent kernel regime solution, whereas small initialization leads to so called ``rich regimes''. However, the initialization structure is richer than the overall scale alone and involves relative magnitudes of different weights and layers in the network. Here we show that these relative scales, which we refer to as initialization shape, play an important role in determining the learned model. We develop a novel technique for deriving the inductive bias of gradient-flow and use it to obtain closed-form implicit regularizers for multiple cases of interest.
Democratization of machine learning requires architectures that automatically adapt to new problems. Neural Differential Equations (NDEs) have emerged as a popular modeling framework by removing the need for ML practitioners to choose the number of layers in a recurrent model. While we can control the computational cost by choosing the number of layers in standard architectures, in NDEs the number of neural network evaluations for a forward pass can depend on the number of steps of the adaptive ODE solver. But, can we force the NDE to learn the version with the least steps while not increasing the training cost? Current strategies to overcome slow prediction require high order automatic differentiation, leading to significantly higher training time. We describe a novel regularization method that uses the internal cost heuristics of adaptive differential equation solvers combined with discrete adjoint sensitivities to guide the training process towards learning NDEs that are easier to solve. This approach opens up the blackbox numerical analysis behind the differential equation solver's algorithm and directly uses its local error estimates and stiffness heuristics as cheap and accurate cost estimates. We incorporate our method without any change in the underlying NDE framework and show that our method extends …
Solving optimization tasks based on functions and losses with a topological flavor is a very active and growing field of research in data science and Topological Data Analysis, with applications in non-convex optimization, statistics and machine learning. However, the approaches proposed in the literature are usually anchored to a specific application and/or topological construction, and do not come with theoretical guarantees. To address this issue, we study the differentiability of a general map associated with the most common topological construction, that is, the persistence map. Building on real analytic geometry arguments, we propose a general framework that allows us to define and compute gradients for persistence-based functions in a very simple way. We also provide a simple, explicit and sufficient condition for convergence of stochastic subgradient methods for such functions. This result encompasses all the constructions and applications of topological optimization in the literature. Finally, we provide associated code, that is easy to handle and to mix with other non-topological methods and constraints, as well as some experiments showcasing the versatility of our approach.
The study of strategic or adversarial manipulation of testing data to fool a classifier has attracted much recent attention. Most previous works have focused on two extreme situations where any testing data point either is completely adversarial or always equally prefers the positive label. In this paper, we generalize both of these through a unified framework for strategic classification and introduce the notion of strategic VC-dimension (SVC) to capture the PAC-learnability in our general strategic setup. SVC provably generalizes the recent concept of adversarial VC-dimension (AVC) introduced by Cullina et al. (2018). We instantiate our framework for the fundamental strategic linear classification problem. We fully characterize: (1) the statistical learnability of linear classifiers by pinning down its SVC; (2) it's computational tractability by pinning down the complexity of the empirical risk minimization problem. Interestingly, the SVC of linear classifiers is always upper bounded by its standard VC-dimension. This characterization also strictly generalizes the AVC bound for linear classifiers in (Cullina et al., 2018).
One principled approach for provably efficient exploration is incorporating the upper confidence bound (UCB) into the value function as a bonus. However, UCB is specified to deal with linear and tabular settings and is incompatible with Deep Reinforcement Learning (DRL). In this paper, we propose a principled exploration method for DRL through Optimistic Bootstrapping and Backward Induction (OB2I). OB2I constructs a general-purpose UCB-bonus through non-parametric bootstrap in DRL. The UCB-bonus estimates the epistemic uncertainty of state-action pairs for optimistic exploration. We build theoretical connections between the proposed UCB-bonus and the LSVI-UCB in linear setting. We propagate future uncertainty in a time-consistent manner through episodic backward update, which exploits the theoretical advantage and empirically improves the sample-efficiency. Our experiments in MNIST maze and Atari suit suggest that OB2I outperforms several state-of-the-art exploration approaches.
Machine learning (ML) is increasingly seen as a viable approach for building compiler optimization heuristics, but many ML methods cannot replicate even the simplest of the data flow analyses that are critical to making good optimization decisions. We posit that if ML cannot do that, then it is insufficiently able to reason about programs. We formulate data flow analyses as supervised learning tasks and introduce a large open dataset of programs and their corresponding labels from several analyses. We use this dataset to benchmark ML methods and show that they struggle on these fundamental program reasoning tasks. We propose ProGraML - Program Graphs for Machine Learning - a language-independent, portable representation of program semantics. ProGraML overcomes the limitations of prior works and yields improved performance on downstream optimization tasks.
We address the problem of causal effect estima-tion in the presence of unobserved confounding,but where proxies for the latent confounder(s) areobserved. We propose two kernel-based meth-ods for nonlinear causal effect estimation in thissetting: (a) a two-stage regression approach, and(b) a maximum moment restriction approach. Wefocus on the proximal causal learning setting, butour methods can be used to solve a wider classof inverse problems characterised by a Fredholmintegral equation. In particular, we provide a uni-fying view of two-stage and moment restrictionapproaches for solving this problem in a nonlin-ear setting. We provide consistency guaranteesfor each algorithm, and demonstrate that these ap-proaches achieve competitive results on syntheticdata and data simulating a real-world task. In par-ticular, our approach outperforms earlier methodsthat are not suited to leveraging proxy variables.
This paper develops a methodology for regret minimization with stochastic first-order oracle feedback in online, constrained, non-smooth, non-convex problems. In this setting, the minimization of external regret is beyond reach for first-order methods, and there are no gradient-based algorithmic frameworks capable of providing a solution. On that account, we propose a conceptual approach that leverages non-convex optimality measures, leading to a suitable generalization of the learner's local regret. We focus on a local regret measure defined via a proximal-gradient mapping, that also encompasses the original notion proposed by Hazan et al. (2017). To achieve no local regret in this setting, we develop a proximal-gradient method based on stochastic first-order feedback, and a simpler method for when access to a perfect first-order oracle is possible. Both methods are order-optimal (in the min-max sense), and we also establish a bound on the number of proximal-gradient queries these methods require. As an important application of our results, we also obtain a link between online and offline non-convex stochastic optimization manifested as a new proximal-gradient scheme with complexity guarantees matching those obtained via variance reduction techniques.

The display advertising industry has recently transitioned from second- to first-price auctions as its primary mechanism for ad allocation and pricing. In light of this, publishers need to re-evaluate and optimize their auction parameters, notably reserve prices. In this paper, we propose a gradient-based algorithm to adaptively update and optimize reserve prices based on estimates of bidders' responsiveness to experimental shocks in reserves. Our key innovation is to draw on the inherent structure of the revenue objective in order to reduce the variance of gradient estimates and improve convergence rates in both theory and practice. We show that revenue in a first-price auction can be usefully decomposed into a \emph{demand} component and a \emph{bidding} component, and introduce techniques to reduce the variance of each component. We characterize the bias-variance trade-offs of these techniques and validate the performance of our proposed algorithm through experiments on synthetic data and real display ad auctions data from a major ad exchange.
Online advertisements are primarily sold via repeated auctions with reserve prices. In this paper, we study how to set reserves to boost revenue based on the historical bids of strategic buyers, while controlling the impact of such a policy on the incentive compatibility of the repeated auctions. Adopting an incentive compatibility metric which quantifies the incentives to shade bids, we propose a novel class of reserve pricing policies and provide analytical tradeoffs between their revenue performance and bid-shading incentives. The policies are inspired by the exponential mechanism from the literature on differential privacy, but our study uncovers mechanisms with significantly better revenue-incentive tradeoffs than the exponential mechanism in practice. We further empirically evaluate the tradeoffs on synthetic data as well as real ad auction data from a major ad exchange to verify and support our theoretical findings.
We propose a residual randomization procedure designed for robust inference using Lasso estimates in the high-dimensional setting. Compared to earlier work that focuses on sub-Gaussian errors, the proposed procedure is designed to work robustly in settings that also include heavy-tailed covariates and errors. Moreover, our procedure can be valid under clustered errors, which is important in practice, but has been largely overlooked by earlier work. Through extensive simulations, we illustrate our method's wider range of applicability as suggested by theory. In particular, we show that our method outperforms state-of-art methods in challenging, yet more realistic, settings where the distribution of covariates is heavy-tailed or the sample size is small, while it remains competitive in standard, ``well behaved" settings previously studied in the literature.
Sharing parameters in multi-agent deep reinforcement learning has played an essential role in allowing algorithms to scale to a large number of agents. Parameter sharing between agents significantly decreases the number of trainable parameters, shortening training times to tractable levels, and has been linked to more efficient learning. However, having all agents share the same parameters can also have a detrimental effect on learning. We demonstrate the impact of parameter sharing methods on training speed and converged returns, establishing that when applied indiscriminately, their effectiveness is highly dependent on the environment. We propose a novel method to automatically identify agents which may benefit from sharing parameters by partitioning them based on their abilities and goals. Our approach combines the increased sample efficiency of parameter sharing with the representational capacity of multiple independent networks to reduce training time and increase final returns.
Deep extreme multi-label learning (XML) requires training deep architectures that can tag a data point with its most relevant subset of labels from an extremely large label set. XML applications such as ad and product recommendation involve labels rarely seen during training but which nevertheless hold the key to recommendations that delight users. Effective utilization of label metadata and high quality predictions for rare labels at the scale of millions of labels are thus key challenges in contemporary XML research. To address these, this paper develops the SiameseXML framework based on a novel probabilistic model that naturally motivates a modular approach melding Siamese architectures with high-capacity extreme classifiers, and a training pipeline that effortlessly scales to tasks with 100 million labels. SiameseXML offers predictions 2--13% more accurate than leading XML methods on public benchmark datasets, as well as in live A/B tests on the Bing search engine, it offers significant gains in click-through-rates, coverage, revenue and other online metrics over state-of-the-art techniques currently in production. Code for SiameseXML is available at https://github.com/Extreme-classification/siamesexml
In this paper, we propose a conceptually simple but very effective attention module for Convolutional Neural Networks (ConvNets). In contrast to existing channel-wise and spatial-wise attention modules, our module instead infers 3-D attention weights for the feature map in a layer without adding parameters to the original networks. Specifically, we base on some well-known neuroscience theories and propose to optimize an energy function to find the importance of each neuron. We further derive a fast closed-form solution for the energy function, and show that the solution can be implemented in less than ten lines of code. Another advantage of the module is that most of the operators are selected based on the solution to the defined energy function, avoiding too many efforts for structure tuning. Quantitative evaluations on various visual tasks demonstrate that the proposed module is flexible and effective to improve the representation ability of many ConvNets. Our code is available at Pytorch-SimAM.
Training agents to autonomously control anthropomorphic robotic hands has the potential to lead to systems capable of performing a multitude of complex manipulation tasks in unstructured and uncertain environments. In this work, we first introduce a suite of challenging simulated manipulation tasks where current reinforcement learning and trajectory optimisation techniques perform poorly. These include environments where two simulated hands have to pass or throw objects between each other, as well as an environment where the agent must learn to spin a long pen between its fingers. We then introduce a simple trajectory optimisation algorithm that performs significantly better than existing methods on these environments. Finally, on the most challenging ``PenSpin" task, we combine sub-optimal demonstrations generated through trajectory optimisation with off-policy reinforcement learning, obtaining performance that far exceeds either of these approaches individually. Videos of all of our results are available at: https://dexterous-manipulation.github.io
Graph sparsification is a powerful tool to approximate an arbitrary graph and has been used in machine learning over graphs. As real-world networks are becoming very large and naturally distributed, distributed graph sparsification has drawn considerable attention. In this work, we design communication-efficient distributed algorithms for constructing spectral vertex sparsifiers, which closely preserve effective resistance distances on a subset of vertices of interest in the original graphs, under the well-established message passing communication model. We prove that the communication cost approximates the lower bound with only a small gap. We further provide algorithms for constructing pair-wise spanners which approximate the shortest distances between each pair of vertices in a target set, instead of all pairs, and incur communication costs that are much smaller than those of existing algorithms in the message passing model. Experiments are performed to validate the communication efficiency of the proposed algorithms under the guarantee that the constructed sparsifiers have a good approximation quality.
Importance sampling-based estimators for off-policy evaluation (OPE) are valued for their simplicity, unbiasedness, and reliance on relatively few assumptions. However, the variance of these estimators is often high, especially when trajectories are of different lengths. In this work, we introduce Omitting-States-Irrelevant-to-Return Importance Sampling (OSIRIS), an estimator which reduces variance by strategically omitting likelihood ratios associated with certain states. We formalize the conditions under which OSIRIS is unbiased and has lower variance than ordinary importance sampling, and we demonstrate these properties empirically.
We study the stochastic Multi-Armed Bandit~(MAB) problem with random delays in the feedback received by the algorithm. We consider two settings: the {\it reward dependent} delay setting, where realized delays may depend on the stochastic rewards, and the {\it reward-independent} delay setting. Our main contribution is algorithms that achieve near-optimal regret in each of the settings, with an additional additive dependence on the quantiles of the delay distribution. Our results do not make any assumptions on the delay distributions: in particular, we do not assume they come from any parametric family of distributions and allow for unbounded support and expectation; we further allow for the case of infinite delays where the algorithm might occasionally not observe any feedback.
Compared to minimization, the min-max optimization in machine learning applications is considerably more convoluted because of the existence of cycles and similar phenomena. Such oscillatory behaviors are well-understood in the convex-concave regime, and many algorithms are known to overcome them. In this paper, we go beyond this basic setting and characterize the convergence properties of many popular methods in solving non-convex/non-concave problems. In particular, we show that a wide class of state-of-the-art schemes and heuristics may converge with arbitrarily high probability to attractors that are in no way min-max optimal or even stationary. Our work thus points out a potential pitfall among many existing theoretical frameworks, and we corroborate our theoretical claims by explicitly showcasing spurious attractors in simple two-dimensional problems.
Lipschitz constants of neural networks have been explored in various contexts in deep learning, such as provable adversarial robustness, estimating Wasserstein distance, stabilising training of GANs, and formulating invertible neural networks. Such works have focused on bounding the Lipschitz constant of fully connected or convolutional networks, composed of linear maps and pointwise non-linearities. In this paper, we investigate the Lipschitz constant of self-attention, a non-linear neural network module widely used in sequence modelling. We prove that the standard dot-product self-attention is not Lipschitz for unbounded input domain, and propose an alternative L2 self-attention that is Lipschitz. We derive an upper bound on the Lipschitz constant of L2 self-attention and provide empirical evidence for its asymptotic tightness. To demonstrate the practical relevance of our theoretical work, we formulate invertible self-attention and use it in a Transformer-based architecture for a character-level language modelling task.
Spectral method is a commonly used scheme to cluster data points lying close to Union of Subspaces, a task known as Subspace Clustering. The typical usage is to construct a Random Geometry Graph first and then apply spectral method to the graph to obtain clustering result. The latter step has been coined the name Spectral Clustering. As far as we know, in spite of the significance of both steps in spectral-method-based Subspace Clustering, all existing theoretical results focus on the first step of constructing the graph, but ignore the final step to correct false connections through spectral clustering. This paper establishes a theory to show the power of this method for the first time, in which we demonstrate the mechanism of spectral clustering by analyzing a simplified algorithm under the widely used semi-random model. Based on this theory, we prove the efficiency of Subspace Clustering in fairly broad conditions. The insights and analysis techniques developed in this paper might also have implications for other random graph problems.
As machine learning black boxes are increasingly being deployed in critical domains such as healthcare and criminal justice, there has been a growing emphasis on developing techniques for explaining these black boxes in a post hoc manner. In this work, we analyze two popular post hoc interpretation techniques: SmoothGrad which is a gradient based method, and a variant of LIME which is a perturbation based method. More specifically, we derive explicit closed form expressions for the explanations output by these two methods and show that they both converge to the same explanation in expectation, i.e., when the number of perturbed samples used by these methods is large. We then leverage this connection to establish other desirable properties, such as robustness, for these techniques. We also derive finite sample complexity bounds for the number of perturbations required for these methods to converge to their expected explanation. Finally, we empirically validate our theory using extensive experimentation on both synthetic and real-world datasets.
We formally study how contrastive learning learns the feature representations for neural networks by investigating its feature learning process. We consider the case where our data are comprised of two types of features: the sparse features which we want to learn from, and the dense features we want to get rid of. Theoretically, we prove that contrastive learning using ReLU networks provably learns the desired features if proper augmentations are adopted. We present an underlying principle called feature decoupling to explain the effects of augmentations, where we theoretically characterize how augmentations can reduce the correlations of dense features between positive samples while keeping the correlations of sparse features intact, thereby forcing the neural networks to learn from the self-supervision of sparse features. Empirically, we verified that the feature decoupling principle matches the underlying mechanism of contrastive learning in practice.
The compelling synthesis results of Generative Adversarial Networks (GANs) demonstrate rich semantic knowledge in their latent codes. To obtain this knowledge for downstream applications, encoding GANs has been proposed to learn encoders, such that real world data can be encoded to latent codes, which can be fed to generators to reconstruct those data.
However, despite the theoretical guarantees of precise reconstruction in previous works, current algorithms generally reconstruct inputs with non-negligible deviations from inputs. In this paper we study this predicament of encoding GANs, which is indispensable research for the GAN community. We prove three uncertainty principles of encoding GANs in practice: a) the perfect' encoder and generator cannot be continuous at the same time, which implies that current framework of encoding GANs is ill-posed and needs rethinking; b) neural networks cannot approximate the underlying encoder and generator precisely at the same time, which explains why we cannot getperfect' encoders and generators as promised in previous theories; c) neural networks cannot be stable and accurate at the same time, which demonstrates the difficulty of training and trade-off between fidelity and disentanglement encountered in previous works. Our work may eliminate gaps between previous theories and empirical results, promote the understanding …
This paper aims to provide understandings for the effect of an over-parameterized model, e.g. a deep neural network, memorizing instance-dependent noisy labels. We first quantify the harms caused by memorizing noisy instances, and show the disparate impacts of noisy labels for sample instances with different representation frequencies. We then analyze how several popular solutions for learning with noisy labels mitigate this harm at the instance level. Our analysis reveals that existing approaches lead to disparate treatments when handling noisy instances. While higher-frequency instances often enjoy a high probability of an improvement by applying these solutions, lower-frequency instances do not. Our analysis reveals new understandings for when these approaches work, and provides theoretical justifications for previously reported empirical observations. This observation requires us to rethink the distribution of label noise across instances and calls for different treatments for instances in different regimes.
Having the ability to acquire inherent skills from environments without any external rewards or supervision like humans is an important problem. We propose a novel unsupervised skill discovery method named Information Bottleneck Option Learning (IBOL). On top of the linearization of environments that promotes more various and distant state transitions, IBOL enables the discovery of diverse skills. It provides the abstraction of the skills learned with the information bottleneck framework for the options with improved stability and encouraged disentanglement. We empirically demonstrate that IBOL outperforms multiple state-of-the-art unsupervised skill discovery methods on the information-theoretic evaluations and downstream tasks in MuJoCo environments, including Ant, HalfCheetah, Hopper and D'Kitty. Our code is available at https://vision.snu.ac.kr/projects/ibol.
Classical value iteration approaches are not applicable to environments with continuous states and actions. For such environments the states and actions must be discretized, which leads to an exponential increase in computational complexity. In this paper, we propose continuous fitted value iteration (cFVI). This algorithm enables dynamic programming for continuous states and actions with a known dynamics model. Exploiting the continuous time formulation, the optimal policy can be derived for non-linear control-affine dynamics. This closed-form solution enables the efficient extension of value iteration to continuous environments. We show in non-linear control experiments that the dynamic programming solution obtains the same quantitative performance as deep reinforcement learning methods in simulation but excels when transferred to the physical system.The policy obtained by cFVI is more robust to changes in the dynamics despite using only a deterministic model and without explicitly incorporating robustness in the optimization
In large-scale time series forecasting, one often encounters the situation where the temporal patterns of time series, while drifting over time, differ from one another in the same dataset. In this paper, we provably show under such heterogeneity, training a forecasting model with commonly used stochastic optimizers (e.g. SGD) potentially suffers large variance on gradient estimation, and thus incurs long-time training. We show that this issue can be efficiently alleviated via stratification, which allows the optimizer to sample from pre-grouped time series strata. For better trading-off gradient variance and computation complexity, we further propose SCott (Stochastic Stratified Control Variate Gradient Descent), a variance reduced SGD-style optimizer that utilizes stratified sampling via control variate. In theory, we provide the convergence guarantee of SCott on smooth non-convex objectives. Empirically, we evaluate SCott and other baseline optimizers on both synthetic and real-world time series forecasting problems, and demonstrate SCott converges faster with respect to both iterations and wall clock time.
The performance of modern algorithms on certain computer vision tasks such as object recognition is now close to that of humans. This success was achieved at the price of complicated architectures depending on millions of parameters and it has become quite challenging to understand how particular predictions are made. Interpretability methods propose to give us this understanding. In this paper, we study LIME, perhaps one of the most popular. On the theoretical side, we show that when the number of generated examples is large, LIME explanations are concentrated around a limit explanation for which we give an explicit expression. We further this study for elementary shape detectors and linear models. As a consequence of this analysis, we uncover a connection between LIME and integrated gradients, another explanation method. More precisely, the LIME explanations are similar to the sum of integrated gradients over the superpixels used in the preprocessing step of LIME.
We propose XOR-Contrastive Divergence learning (XOR-CD), a provable approach for constrained structure generation, which remains difficult for state-of-the-art neural network and constraint reasoning approaches. XOR-CD harnesses XOR-Sampling to generate samples from the model distribution in CD learning and is guaranteed to generate valid structures. In addition, XOR-CD has a linear convergence rate towards the global maximum of the likelihood function within a vanishing constant in learning exponential family models. Constraint satisfaction enabled by XOR-CD also boosts its learning performance. Our real-world experiments on data-driven experimental design, dispatching route generation, and sequence-based protein homology detection demonstrate the superior performance of XOR-CD compared to baseline approaches in generating valid structures as well as capturing the inductive bias in the training set.
Knowledge distillation (KD) is a successful approach for deep neural network acceleration, with which a compact network (student) is trained by mimicking the softmax output of a pre-trained high-capacity network (teacher). In tradition, KD usually relies on access to the training samples and the parameters of the white-box teacher to acquire the transferred knowledge. However, these prerequisites are not always realistic due to storage costs or privacy issues in real-world applications. Here we propose the concept of decision-based black-box (DB3) knowledge distillation, with which the student is trained by distilling the knowledge from a black-box teacher (parameters are not accessible) that only returns classes rather than softmax outputs. We start with the scenario when the training set is accessible. We represent a sample's robustness against other classes by computing its distances to the teacher's decision boundaries and use it to construct the soft label for each training sample. After that, the student can be trained via standard KD. We then extend this approach to a more challenging scenario in which even accessing the training data is not feasible. We propose to generate pseudo samples that are distinguished by the decision boundaries of the DB3 teacher to the largest extent and …
Indigenous in AI Social Wed 21 Jul 10:00 p.m.
Papa Reo (papareo.nz) is a multilingual language initiative grounded in Indigenous knowledge and ways of thinking and powered by cutting edge data science. We will present our work on the importance of indigenous sovereignty over data, platforms, and technologies used in the preservation, promotion, and revitalisation of language and culture. We will also cover some of our latest tools such as a real time pronunciation model which aims to decolonise the sound of te reo Māori. Papa Reo is led by Te Reo Irirangi o Te Hiku o Te Ika (Te Hiku Media), a charitable media organisation, collectively belonging to the Far North iwi of Ngāti Kuri, Te Aupouri, Ngai Takoto, Te Rārawa and Ngāti Kahu. Te Hiku Media is an iwi communications hub for radio, online video and media services. Māori language revitalisation is a core focus, and Te Hiku Media’s vision and mission were confirmed by a meeting of kaumātua (elders) and other native speakers of Te Reo Māori.
A QA and informal social will follow this talk